DiffDock源码解析
DiffDock源码解析
数据预处理
数据输入方式
df = pd.read_csv(args.protein_ligand_csv), 使用的是csv的方式输入,
格式:

不管受体还是配体, 输入可以是序列或者3维结构的文件
如果蛋白输入的是序列,需要计算蛋白的三维结构(ESM模型):
def generate_ESM_structure(model, filename, sequence):model.set_chunk_size(256)chunk_size = 256output = Nonewhile output is None:with torch.no_grad():output = model.infer_pdb(sequence)with open(filename, "w") as f:f.write(output)print("saved", filename)。。。。。。return output is not None
计算蛋白Embedding
蛋白序列embedding使用了google ESM框架,
def compute_ESM_embeddings(model, alphabet, labels, sequences):# settings usedtoks_per_batch = 4096repr_layers = [33]include = "per_tok"truncation_seq_length = 1022dataset = FastaBatchedDataset(labels, sequences)batches = dataset.get_batch_indices(toks_per_batch, extra_toks_per_seq=1)data_loader = torch.utils.data.DataLoader(dataset, collate_fn=alphabet.get_batch_converter(truncation_seq_length), batch_sampler=batches)assert all(-(model.num_layers + 1) <= i <= model.num_layers for i in repr_layers)repr_layers = [(i + model.num_layers + 1) % (model.num_layers + 1) for i in repr_layers]embeddings = {}with torch.no_grad():for batch_idx, (labels, strs, toks) in enumerate(data_loader):print(f"Processing {batch_idx + 1} of {len(batches)} batches ({toks.size(0)} sequences)")if torch.cuda.is_available():toks = toks.to(device="cuda", non_blocking=True)out = model(toks, repr_layers=repr_layers, return_contacts=False)representations = {layer: t.to(device="cpu") for layer, t in out["representations"].items()}for i, label in enumerate(labels):truncate_len = min(truncation_seq_length, len(strs[i]))embeddings[label] = representations[33][i, 1: truncate_len + 1].clone()return embeddings
配体预处理
mol = read_molecule(ligand_description, remove_hs=False, sanitize=True)
mol.RemoveAllConformers() # 移除所有的构象信息
mol = AddHs(mol) ## 加氢
generate_conformer(mol) ## 随机3D位置信息
配体特征提取
异构图分子整体信息
complex_graph['ligand'].x = atom_feats
complex_graph['ligand'].pos = lig_coords
complex_graph['ligand', 'lig_bond', 'ligand'].edge_index = edge_index
complex_graph['ligand', 'lig_bond', 'ligand'].edge_attr = edge_attr
- 配体信息特征
allowable_features = {'possible_atomic_num_list': list(range(1, 119)) + ['misc'],'possible_chirality_list': ['CHI_UNSPECIFIED','CHI_TETRAHEDRAL_CW','CHI_TETRAHEDRAL_CCW','CHI_OTHER'],'possible_degree_list': [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 'misc'],'possible_numring_list': [0, 1, 2, 3, 4, 5, 6, 'misc'],'possible_implicit_valence_list': [0, 1, 2, 3, 4, 5, 6, 'misc'],'possible_formal_charge_list': [-5, -4, -3, -2, -1, 0, 1, 2, 3, 4, 5, 'misc'],'possible_numH_list': [0, 1, 2, 3, 4, 5, 6, 7, 8, 'misc'],'possible_number_radical_e_list': [0, 1, 2, 3, 4, 'misc'],'possible_hybridization_list': ['SP', 'SP2', 'SP3', 'SP3D', 'SP3D2', 'misc'],'possible_is_aromatic_list': [False, True],'possible_is_in_ring3_list': [False, True],'possible_is_in_ring4_list': [False, True],'possible_is_in_ring5_list': [False, True],'possible_is_in_ring6_list': [False, True],'possible_is_in_ring7_list': [False, True],'possible_is_in_ring8_list': [False, True],'possible_atom_type_2': ['C*', 'CA', 'CB', 'CD', 'CE', 'CG', 'CH', 'CZ', 'N*', 'ND', 'NE', 'NH', 'NZ', 'O*', 'OD','OE', 'OG', 'OH', 'OX', 'S*', 'SD', 'SG', 'misc'],'possible_atom_type_3': ['C', 'CA', 'CB', 'CD', 'CD1', 'CD2', 'CE', 'CE1', 'CE2', 'CE3', 'CG', 'CG1', 'CG2', 'CH2','CZ', 'CZ2', 'CZ3', 'N', 'ND1', 'ND2', 'NE', 'NE1', 'NE2', 'NH1', 'NH2', 'NZ', 'O', 'OD1','OD2', 'OE1', 'OE2', 'OG', 'OG1', 'OH', 'OXT', 'SD', 'SG', 'misc'],
}
- 配体位置特征
lig_coords = torch.from_numpy(mol.GetConformer().GetPositions()).float() # 配体的分子位置信息
- 边信息, 键, 无向,键类型作为边属性特征
for bond in mol.GetBonds():start, end = bond.GetBeginAtomIdx(), bond.GetEndAtomIdx()row += [start, end]col += [end, start]edge_type += 2 * [bonds[bond.GetBondType()]] if bond.GetBondType() != BT.UNSPECIFIED else [0, 0]
受体蛋白特征提取
受体信息提取主要是空间信息,原子空间坐标(coords), 残基CA原子(c_alpha_coords), 残基N原子(n_coords), 残基CB原子(c_coords), 残基嵌入信息(lm_embeddings)
complex_graph['receptor'].x = torch.cat([node_feat, torch.tensor(lm_embeddings)], axis=1) if lm_embeddings is not None else node_featcomplex_graph['receptor'].pos = torch.from_numpy(c_alpha_coords).float()complex_graph['receptor'].mu_r_norm = mu_r_normcomplex_graph['receptor'].side_chain_vecs = side_chain_vecs.float()complex_graph['receptor', 'rec_contact', 'receptor'].edge_index = torch.from_numpy(np.asarray([src_list, dst_list])) # 出节点 -> 入节点 cutoff 15.0
- 空间信息特征
n_rel_pos = n_coords - c_alpha_coords # N -> CA
c_rel_pos = c_coords - c_alpha_coords # CB -> CA
mu_r_norm = torch.from_numpy(np.array(mean_norm_list).astype(np.float32))
side_chain_vecs = torch.from_numpy(np.concatenate([np.expand_dims(n_rel_pos, axis=1), np.expand_dims(c_rel_pos, axis=1)], axis=1))
- 受体信息特征
只使用了残基标签one-hot 与残基序列embedding的拼接
def rec_residue_featurizer(rec):feature_list = []for residue in rec.get_residues():feature_list.append([safe_index(allowable_features['possible_amino_acids'], residue.get_resname())])return torch.tensor(feature_list, dtype=torch.float32) # (N_res, 1)'possible_amino_acids': ['ALA', 'ARG', 'ASN', 'ASP', 'CYS', 'GLN', 'GLU', 'GLY', 'HIS', 'ILE', 'LEU', 'LYS', 'MET','PHE', 'PRO', 'SER', 'THR', 'TRP', 'TYR', 'VAL', 'HIP', 'HIE', 'TPO', 'HID', 'LEV', 'MEU','PTR', 'GLV', 'CYT', 'SEP', 'HIZ', 'CYM', 'GLM', 'ASQ', 'TYS', 'CYX', 'GLZ', 'misc'],
模型
模型有两种,一种是全原子特征, 另一种是CA原子特征
##
def get_model(args, device, t_to_sigma, no_parallel=False, confidence_mode=False):if 'all_atoms' in args and args.all_atoms:model_class = AAScoreModelelse:model_class = CGScoreModel
节点表征
class AtomEncoder(torch.nn.Module):# feature_dims元组的第一个元素是包含每个分类特征长度的列表,第二个元素是标量特征的数量def __init__(self, emb_dim, feature_dims, sigma_embed_dim, lm_embedding_type= None):# first element of feature_dims tuple is a list with the lenght of each categorical feature and the second is the number of scalar featuressuper(AtomEncoder, self).__init__()self.atom_embedding_list = torch.nn.ModuleList()self.num_categorical_features = len(feature_dims[0])self.num_scalar_features = feature_dims[1] + sigma_embed_dimself.lm_embedding_type = lm_embedding_typefor i, dim in enumerate(feature_dims[0]):emb = torch.nn.Embedding(dim, emb_dim)torch.nn.init.xavier_uniform_(emb.weight.data)self.atom_embedding_list.append(emb)if self.num_scalar_features > 0:self.linear = torch.nn.Linear(self.num_scalar_features, emb_dim)if self.lm_embedding_type is not None:if self.lm_embedding_type == 'esm':self.lm_embedding_dim = 1280else: raise ValueError('LM Embedding type was not correctly determined. LM embedding type: ', self.lm_embedding_type)self.lm_embedding_layer = torch.nn.Linear(self.lm_embedding_dim + emb_dim, emb_dim)def forward(self, x):x_embedding = 0if self.lm_embedding_type is not None:assert x.shape[1] == self.num_categorical_features + self.num_scalar_features + self.lm_embedding_dimelse:assert x.shape[1] == self.num_categorical_features + self.num_scalar_featuresfor i in range(self.num_categorical_features):x_embedding += self.atom_embedding_list[i](x[:, i].long())if self.num_scalar_features > 0:x_embedding += self.linear(x[:, self.num_categorical_features:self.num_categorical_features + self.num_scalar_features])if self.lm_embedding_type is not None:x_embedding = self.lm_embedding_layer(torch.cat([x_embedding, x[:, -self.lm_embedding_dim:]], axis=1))return x_embedding
边表征
就是MLP映射层
nn.Sequential(nn.Linear(in_lig_edge_features + sigma_embed_dim + distance_embed_dim, ns),nn.ReLU(), nn.Dropout(dropout),nn.Linear(ns, ns))
原子距离分布表征
class GaussianSmearing(torch.nn.Module):# used to embed the edge distances 用于嵌入边缘距离def __init__(self, start=0.0, stop=5.0, num_gaussians=50):super().__init__()offset = torch.linspace(start, stop, num_gaussians)self.coeff = -0.5 / (offset[1] - offset[0]).item() ** 2self.register_buffer('offset', offset)def forward(self, dist):dist = dist.view(-1, 1) - self.offset.view(1, -1)return torch.exp(self.coeff * torch.pow(dist, 2))
等变卷积(旋转平移不变性)
作者等变卷积使用的是e3nn框架
使用e3nn实现一个等变卷积 o3.FullyConnectedTensorProduct(in_irreps, sh_irreps, out_irreps, shared_weights=False)。
我们将执行这个公式:
f j ⊗ ( h ( ∥ x i j ∥ ) ) Y ( x i j / ∥ x i j ∥ ) f_j \otimes\left(h\left(\left\|x_{i j}\right\|\right)\right) Y\left(x_{i j} /\left\|x_{i j}\right\|\right) fj⊗(h(∥xij∥))Y(xij/∥xij∥)
然后归一化以及聚合:
f i ′ = 1 z ∑ j ∈ ∂ ( i ) f j ⊗ ( h ( ∥ x i j ∥ ) ) Y ( x i j / ∥ x i j ∥ ) f_i^{\prime}=\frac{1}{\sqrt{z}} \sum_{j \in \partial(i)} f_j \otimes\left(h\left(\left\|x_{i j}\right\|\right)\right) Y\left(x_{i j} /\left\|x_{i j}\right\|\right) fi′=z1j∈∂(i)∑fj⊗(h(∥xij∥))Y(xij/∥xij∥)
其中:
- f j , f i ′ f_j, f_i^{\prime} fj,fi′节点是输入和输出
- z z z节点的平均度是多少
- ∂ ( i ) \partial(i) ∂(i)是节点 i i i的邻居集合
- x i j x_{i j} xij是相对向量
- h h h是一个多层感知机
- Y Y Y是球谐波
- x ⊗ ( w ) y x \otimes(w) y x⊗(w)y是 x x x和 y y y的张量积 y y y被一些权重 w w w参数化
e3nn详细教程可以参考blog
class TensorProductConvLayer(torch.nn.Module):def __init__(self, in_irreps, sh_irreps, out_irreps, n_edge_features, residual=True, batch_norm=True, dropout=0.0,hidden_features=None):super(TensorProductConvLayer, self).__init__()self.in_irreps = in_irrepsself.out_irreps = out_irrepsself.sh_irreps = sh_irrepsself.residual = residualif hidden_features is None:hidden_features = n_edge_features## 全连接向量积self.tp = tp = o3.FullyConnectedTensorProduct(in_irreps, sh_irreps, out_irreps, shared_weights=False) self.fc = nn.Sequential(nn.Linear(n_edge_features, hidden_features),nn.ReLU(),nn.Dropout(dropout),nn.Linear(hidden_features, tp.weight_numel))self.batch_norm = BatchNorm(out_irreps) if batch_norm else Nonedef forward(self, node_attr, edge_index, edge_attr, edge_sh, out_nodes=None, reduce='mean'):edge_src, edge_dst = edge_indextp = self.tp(node_attr[edge_dst], edge_sh, self.fc(edge_attr))out_nodes = out_nodes or node_attr.shape[0]out = scatter(tp, edge_src, dim=0, dim_size=out_nodes, reduce=reduce)if self.residual:padded = F.pad(node_attr, (0, out.shape[-1] - node_attr.shape[-1]))out = out + paddedif self.batch_norm:out = self.batch_norm(out)return out
质心平移和旋转(对接模型)
self.center_distance_expansion = GaussianSmearing(0.0, center_max_distance, distance_embed_dim)self.center_edge_embedding = nn.Sequential(nn.Linear(distance_embed_dim + sigma_embed_dim, ns),nn.ReLU(),nn.Dropout(dropout),nn.Linear(ns, ns))self.final_conv = TensorProductConvLayer(in_irreps=self.lig_conv_layers[-1].out_irreps,sh_irreps=self.sh_irreps,out_irreps=f'2x1o + 2x1e',n_edge_features=2 * ns,residual=False,dropout=dropout,batch_norm=batch_norm)self.tr_final_layer = nn.Sequential(nn.Linear(1 + sigma_embed_dim, ns),nn.Dropout(dropout), nn.ReLU(), nn.Linear(ns, 1))self.rot_final_layer = nn.Sequential(nn.Linear(1 + sigma_embed_dim, ns),nn.Dropout(dropout), nn.ReLU(), nn.Linear(ns, 1))if not no_torsion:# torsion angles componentsself.final_edge_embedding = nn.Sequential(nn.Linear(distance_embed_dim, ns),nn.ReLU(),nn.Dropout(dropout),nn.Linear(ns, ns))self.final_tp_tor = o3.FullTensorProduct(self.sh_irreps, "2e")self.tor_bond_conv = TensorProductConvLayer(in_irreps=self.lig_conv_layers[-1].out_irreps,sh_irreps=self.final_tp_tor.irreps_out,out_irreps=f'{ns}x0o + {ns}x0e',n_edge_features=3 * ns,residual=False,dropout=dropout,batch_norm=batch_norm)self.tor_final_layer = nn.Sequential(nn.Linear(2 * ns, ns, bias=False),nn.Tanh(),nn.Dropout(dropout),nn.Linear(ns, 1, bias=False))
置信度预测
置信度和亲和度预测层
self.confidence_predictor = nn.Sequential(nn.Linear(2 * self.ns if num_conv_layers >= 3 else self.ns, ns),nn.BatchNorm1d(ns) if not confidence_no_batchnorm else nn.Identity(),nn.ReLU(),nn.Dropout(confidence_dropout),nn.Linear(ns, ns),nn.BatchNorm1d(ns) if not confidence_no_batchnorm else nn.Identity(),nn.ReLU(),nn.Dropout(confidence_dropout),nn.Linear(ns, output_confidence_dim))
Diffusion模型
加噪过程
作者这里选择线性加噪过程, 其他加噪过程请参考blog
def get_t_schedule(inference_steps):return np.linspace(1, 0, inference_steps + 1)[:-1]
Time Embedding
timestep embedding作者使用了两种方法, 一个是DDPM中提到的正弦嵌入, 还有一个是高斯傅立叶嵌入
def get_timestep_embedding(embedding_type, embedding_dim, embedding_scale=10000):if embedding_type == 'sinusoidal':emb_func = (lambda x : sinusoidal_embedding(embedding_scale * x, embedding_dim))elif embedding_type == 'fourier':emb_func = GaussianFourierProjection(embedding_size=embedding_dim, scale=embedding_scale)else:raise NotImplementedreturn emb_func
forward diffusion

,配体的构象其实本质是也就是原子在三维坐标系上的集合,因此本质上也就是数据的分布。但与图片不同的是,小分子构象的正向扩散或者说是构象变化过程是存在一定限制的,配体在本身的键长和原子间的连接方式在构象转变过程中还是会保持基本不变。作者将配体构象变化的范围称为自由度,并将这个自由度划分为了三个部分。也就是文章标题中的steps,turns以及twist,分别对应着配体构象的位置变动,构象翻转以及键的扭转。这三个维度共同构成一个子空间,并且与实际上的配体构象空间相对应。这也就使得正向扩散从直接从配体构象空间采样变成了从 R ∧ 3 , S O ( 3 ) , T ∧ 3 \mathbb{R}^{\wedge} 3, \quad SO(3), \mathbb{T}^{\wedge} 3 R∧3,SO(3),T∧3者三个维度的采样。
def set_time(complex_graphs, t_tr, t_rot, t_tor, batchsize, all_atoms, device):complex_graphs['ligand'].node_t = {'tr': t_tr * torch.ones(complex_graphs['ligand'].num_nodes).to(device),'rot': t_rot * torch.ones(complex_graphs['ligand'].num_nodes).to(device),'tor': t_tor * torch.ones(complex_graphs['ligand'].num_nodes).to(device)}complex_graphs['receptor'].node_t = {'tr': t_tr * torch.ones(complex_graphs['receptor'].num_nodes).to(device),'rot': t_rot * torch.ones(complex_graphs['receptor'].num_nodes).to(device),'tor': t_tor * torch.ones(complex_graphs['receptor'].num_nodes).to(device)}complex_graphs.complex_t = {'tr': t_tr * torch.ones(batchsize).to(device),'rot': t_rot * torch.ones(batchsize).to(device),'tor': t_tor * torch.ones(batchsize).to(device)}if all_atoms:complex_graphs['atom'].node_t = {'tr': t_tr * torch.ones(complex_graphs['atom'].num_nodes).to(device),'rot': t_rot * torch.ones(complex_graphs['atom'].num_nodes).to(device),'tor': t_tor * torch.ones(complex_graphs['atom'].num_nodes).to(device)}
reverse diffusion
对steps,turns以及twist三个自由度进行采样
tr_sigma, rot_sigma, tor_sigma = t_to_sigma(t_tr, t_rot, t_tor)
噪声预测:
with torch.no_grad():tr_score, rot_score, tor_score = model(complex_graph_batch)
去噪过程:
tr_g = tr_sigma * torch.sqrt(torch.tensor(2 * np.log(model_args.tr_sigma_max / model_args.tr_sigma_min)))rot_g = 2 * rot_sigma * torch.sqrt(torch.tensor(np.log(model_args.rot_sigma_max / model_args.rot_sigma_min)))if ode:tr_perturb = (0.5 * tr_g ** 2 * dt_tr * tr_score.cpu()).cpu()rot_perturb = (0.5 * rot_score.cpu() * dt_rot * rot_g ** 2).cpu()
else:tr_z = torch.zeros((b, 3)) if no_random or (no_final_step_noise and t_idx == inference_steps - 1) \else torch.normal(mean=0, std=1, size=(b, 3))tr_perturb = (tr_g ** 2 * dt_tr * tr_score.cpu() + tr_g * np.sqrt(dt_tr) * tr_z).cpu()rot_z = torch.zeros((b, 3)) if no_random or (no_final_step_noise and t_idx == inference_steps - 1) \else torch.normal(mean=0, std=1, size=(b, 3))rot_perturb = (rot_score.cpu() * dt_rot * rot_g ** 2 + rot_g * np.sqrt(dt_rot) * rot_z).cpu()if not model_args.no_torsion:tor_g = tor_sigma * torch.sqrt(torch.tensor(2 * np.log(model_args.tor_sigma_max / model_args.tor_sigma_min)))if ode:tor_perturb = (0.5 * tor_g ** 2 * dt_tor * tor_score.cpu()).numpy()else:tor_z = torch.zeros(tor_score.shape) if no_random or (no_final_step_noise and t_idx == inference_steps - 1) \else torch.normal(mean=0, std=1, size=tor_score.shape)tor_perturb = (tor_g ** 2 * dt_tor * tor_score.cpu() + tor_g * np.sqrt(dt_tor) * tor_z).numpy()torsions_per_molecule = tor_perturb.shape[0] // b
else:tor_perturb = None
相关文章:
DiffDock源码解析
DiffDock源码解析 数据预处理 数据输入方式 df pd.read_csv(args.protein_ligand_csv), 使用的是csv的方式输入, 格式: 不管受体还是配体, 输入可以是序列或者3维结构的文件 如果蛋白输入的是序列,需要计算蛋白的三维结构&am…...
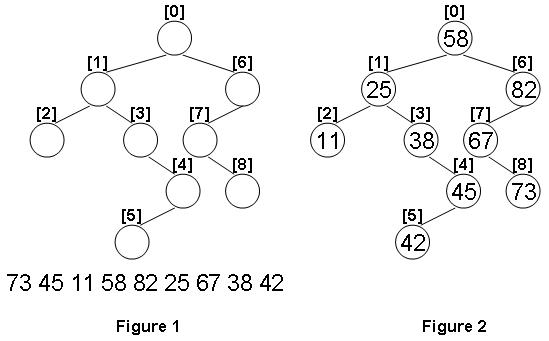
1099 Build A Binary Search Tree(超详细注解+38行代码)
分数 30 全屏浏览题目 作者 CHEN, Yue 单位 浙江大学 A Binary Search Tree (BST) is recursively defined as a binary tree which has the following properties: The left subtree of a node contains only nodes with keys less than the nodes key.The right subtree…...
[刷题]贪心入门
文章目录 贪心区间问题区间选点区间合并区间覆盖 哈夫曼树(堆)合并果子 排序不等式排队打水 绝对值不等式货仓选址 推出来的不等式耍杂技的牛 以前的题 贪心 贪心:每一步行动总是按某种指标选取最优的操作来进行, 该指标只看眼前&…...
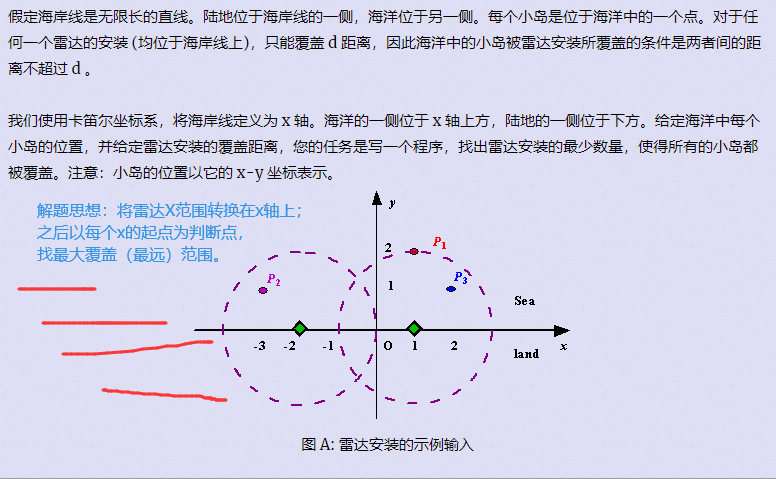
项目集战略一致性
项目集战略一致性是识别项目集输出和成果,以便与组织的目标和目的保持一致的绩效领域。 本章内容包括: 1 项目集商业论证 2 项目集章程 3 项目集路线图 4 环境评估 5 项目集风险管理战略 项目集应与组织战略保持一致,并促进组织效益的实现。为…...
Linux学习 Day3
目录 1. 时间相关的指令 2. cal指令 3. find指令:(灰常重要) -name 4. grep指令 5. zip/unzip指令 6. tar指令(重要):打包/解包,不打开它,直接看内容 7. bc指令 8. uname –…...

前端开发推荐vscode安装什么插件?
前言 可以参考一下下面我推荐的插件,注意:插件的目的是用于提高开发的效率,节约开发的时间,像类似检查一些bug、拼写错误等这些可以使用插件快速的识别,避免在查找错误上浪费过多的时间,但切记不要过度依赖…...

如何打造完整的客户服务体系?
对于企业来说,提供优质的客户服务是保持竞争力和赢得市场份额的关键因素之一。一个高效、专业、人性化的客户服务体系,对于企业吸引和留住客户,提升品牌声誉,甚至增加销售额都有着不可忽视的作用。本文将从多个方面来阐述如何打造…...

裸奔时代,隐私何处寻?
随着互联网的普及,人工智能时代的大幕初启,数据作为人工智能的重要支撑,数据之争成为“兵家必争之地”,随之而来的就是,各种花式手段“收割”个人信息,用户隐私暴露程度越来越高,隐私保护早已成…...
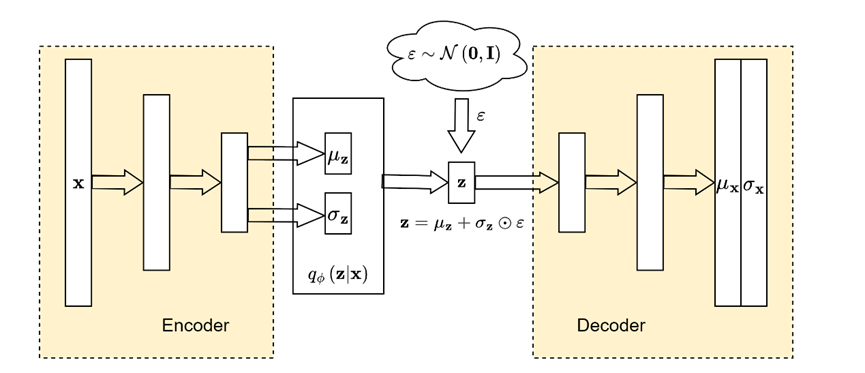
从期望最大化(EM)到变分自编码器(VAE)
本文主要记录了自己对变分自编码器论文的理解。 Kingma D P, Welling M. Auto-encoding variational bayes[J]. arXiv preprint arXiv:1312.6114, 2013. https://arxiv.org/abs/1312.6114 1 带有潜在变量的极大似然估计 假设我们有一个有限整数随机数发生器 z ∼ p θ ( z ) …...

【数学杂记】表达式中的 s.t. 是什么意思
今天写题的时候遇见了这个记号:s.t.,查了一下百度。 s.t.,全称 subject to,意思是“使得……满足”。 比如这个: 意思是存在 i i i,使得 i i i 满足 A i ≠ B i A_i\neq B_i AiBi. 运用这个记号…...

flink watermark介绍及watermark的窗口触发机制
Flink的三种时间 在谈watermark之前,首先需要了解flink的三种时间概念。在flink中,有三种时间戳概念:Event Time 、Processing Time 和 Ingestion Time。其中watermark只对Event Time类型的时间戳有用。这三种时间概念分别表示: …...

Spring Cloud: 云原生微服务实践
文章目录 1. Spring Cloud 简介2. Spring Cloud Eureka:服务注册与发现在Spring Cloud中使用Eureka 3. Spring Cloud Config:分布式配置中心在Spring Cloud中使用Config 4. Spring Cloud Hystrix:熔断器在Spring Cloud中使用Hystrix 5. Sprin…...

存bean和取bean
准备工作存bean获取bean三种方式 准备工作 bean:一个对象在多个地方使用。 spring和spring boot:spring和spring boot项目;spring相当于老版本 spring boot本质还是spring项目;为了方便spring项目的搭建;操作起来更加简单 spring…...

39. 组合总和
给你一个 无重复元素 的整数数组 candidates 和一个目标整数 target ,找出 candidates 中可以使数字和为目标数 target 的 所有 不同组合 ,并以列表形式返回。你可以按 任意顺序 返回这些组合。 candidates 中的 同一个 数字可以 无限制重复被选取 。如…...

100行以内Python能做那些事
Python100 找到一个很好的python教程分享出来---->非本人 B站视频连接 100行以内的Pyhton代码可以做哪些有意思的事 按照难度1-5颗星,分为五个文件夹 希望大家可以补充 关于运行环境的补充 Python3.7 Pycharm社区版2019 关于用到的Python库,有些是自带的&am…...

Android 电源键事件流程分析
Android 电源键事件流程分析 电源按键流程处理逻辑在 PhoneWindowManager.java类中的 dispatchUnhandledKey 方法中 frameworks/base/services/core/java/com/android/server/policy/PhoneWindowManager.java从dispatchUnhandledKey方法开始分析 Overridepublic KeyEvent dis…...

游戏搬砖简述-1
游戏搬砖是一种在游戏中通过重复性的任务来获取游戏内货币或物品的行为。这种行为在游戏中非常普遍,尤其是在一些MMORPG游戏中。虽然游戏搬砖看起来很无聊,但是它确实是一种可以赚钱的方式,而且对于一些玩家来说,游戏搬砖也是一种…...

多线程基础总结
1. 为什么要有多线程? 线程:线程是操作系统能够进行运算调度的最小单位。它被包含在进程之中,是进程中实际运行单位。 进程:进程是程序的基本执行实体。 什么是多线程? 有了多线程,我们就可以让程序同时做…...
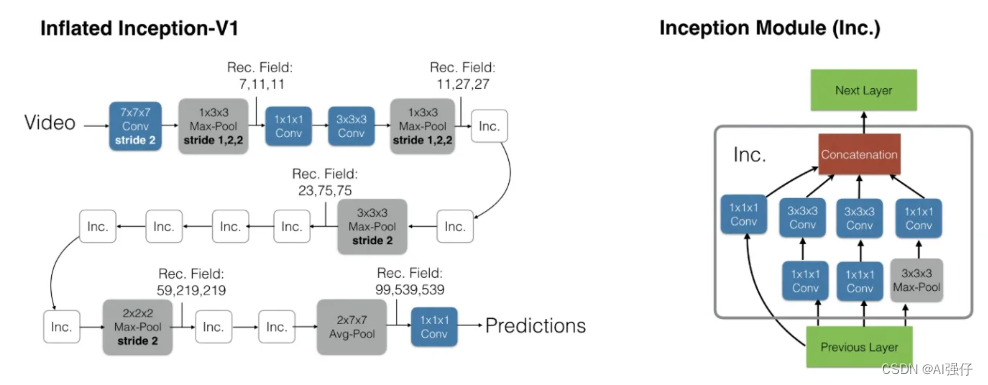
视频理解AI模型分类与汇总
人工智能领域视频模型大体也经历了从传统手工特征,到卷积神经网络、双流网络(2014年-2017年)、3D卷积网络、transformer的发展脉络。为了时序信息,有的模型也结合用LSTM。 视频的技术大多借鉴图像处理技术,只是视频比…...
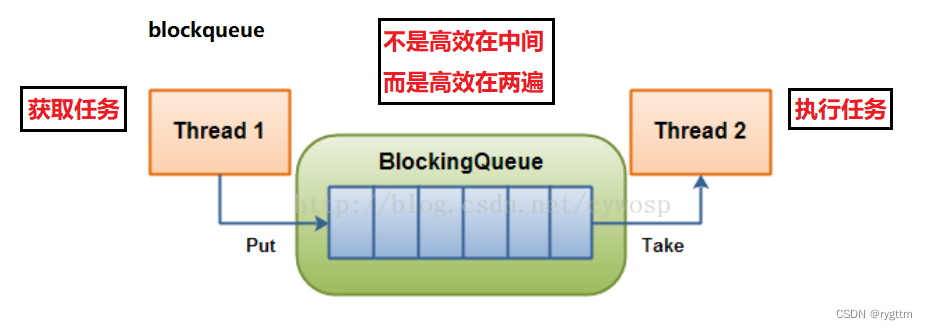
【Linux】多线程 --- 线程同步与互斥+生产消费模型
人生总是那么痛苦吗?还是只有小时候是这样? —总是如此 文章目录 一、线程互斥1.多线程共享资源访问的不安全问题2.提出解决方案:加锁(局部和静态锁的两种初始化/销毁方案)2.1 对于锁的初步理解和实现2.2 局部和全局锁…...
)
Verilog握手信号实战:如何用valid/ready搭建高效数据流水线(附完整代码)
Verilog握手信号实战:如何用valid/ready搭建高效数据流水线(附完整代码) 在FPGA开发中,数据流水线是实现高性能计算的关键架构。但当我们面对不同处理速度的模块时,如何确保数据既不丢失又不阻塞?valid/rea…...

【开题答辩全过程】以 个性化电影推荐系统为例,包含答辩的问题和答案
个人简介一名14年经验的资深毕设内行人,语言擅长Java、php、微信小程序、Python、Golang、安卓Android等开发项目包括大数据、深度学习、网站、小程序、安卓、算法。平常会做一些项目定制化开发、代码讲解、答辩教学、文档编写、也懂一些降重方面的技巧。感谢大家的…...

学术符号的生产与思想的停滞——评童世骏《“来往”与“交往”如何形成良性循环》
学术符号的生产与思想的停滞——评童世骏《“来往”与“交往”如何形成良性循环》摘要:本文以岐金兰对童世骏文章的批判为切入点,系统分析童文在学术生产体制中的位置与局限。研究发现,童文虽以哈贝马斯“交往理性”为理论资源,但…...
HyperFusion-DEIM:遥感影像中多路径关注与尺度感知融合的精确物体检测)
(论文速读)HyperFusion-DEIM:遥感影像中多路径关注与尺度感知融合的精确物体检测
论文题目:遥感影像中多路径关注与尺度感知融合的精确物体检测(Multi path attention and scale aware fusion for accurate object detection in remote sensing imagery)期刊:Scientific Reports摘要:在遥感图像中追求…...

如何用League-Toolkit提升30%游戏决策效率?完整指南
如何用League-Toolkit提升30%游戏决策效率?完整指南 【免费下载链接】League-Toolkit 兴趣使然的、简单易用的英雄联盟工具集。支持战绩查询、自动秒选等功能。基于 LCU API。 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit 价值定位…...

Clover Bootloader虚拟化环境部署终极指南:QEMU、KVM、Xen全平台支持
Clover Bootloader虚拟化环境部署终极指南:QEMU、KVM、Xen全平台支持 【免费下载链接】CloverBootloader Bootloader for macOS, Windows and Linux in UEFI and in legacy mode 项目地址: https://gitcode.com/gh_mirrors/cl/CloverBootloader Clover Bootl…...

MixText+BERT还能这么玩?手把手复现FPMT论文中的‘概率伪混合’黑科技
解密FPMT论文中的概率伪混合:BERT隐藏层的动态插值艺术 在自然语言处理领域,数据增强一直是提升模型泛化能力的关键技术。传统MixText方法通过线性插值在输入层混合样本,但这种"一刀切"的方式忽视了不同样本对模型训练的差异化价值…...

智能缓存加速:重新定义扩散模型推理效率
智能缓存加速:重新定义扩散模型推理效率 【免费下载链接】ComfyUI-TeaCache 项目地址: https://gitcode.com/gh_mirrors/co/ComfyUI-TeaCache 在AI创作领域,等待成为最大的创作阻力。当你使用扩散模型生成图像或视频时,是否曾因漫长的…...

Phi-4-reasoning-vision-15B在金融图表分析中的实战:趋势识别与异常定位
Phi-4-reasoning-vision-15B在金融图表分析中的实战:趋势识别与异常定位 1. 金融图表分析的挑战与机遇 金融从业者每天需要分析大量图表数据,从K线图到财务报表,从趋势分析到异常检测。传统的人工分析方法存在三个明显痛点: 效…...

CosyVoice-300M Lite实战案例:在线教育语音课件生成系统
CosyVoice-300M Lite实战案例:在线教育语音课件生成系统 1. 为什么在线教育需要专属语音合成系统? 你有没有遇到过这样的场景:一位初中物理老师想为“浮力原理”这节课制作配套音频讲解,但反复试了三款主流TTS工具——要么普通话…...