基于Hebb学习的深度学习方法总结
基于Hebb学习的深度学习方法总结
- 0 引言
- 1 前置知识
- 1.1 Hebb学习规则
- 1.2 Delta学习规则
- 2 SoftHebb学习算法
- 2.1 WTA(Winner Take All)
- 2.2 SoftHebb
- 2.3 多层Hebb网络
- 2.4 Hebb学习的性能测评
- 3 参考文献
0 引言
总所周知,反向传播算法(back-propagating, BP)存在四个缺点:
- 权重传输(weight transport):即误差的反向传播与生物脑中突触信号的单向传递矛盾,目前也没有在生物脑中发现BP的实验证据;并且BP过程需要前向连接权重矩阵的转置,这在生物神经网络上是不可能的。
- 非局部可塑性(non-local plasticity):指BP学习需要输出端传回的全局误差信号,无法仅通过时间和神经元的局部信号更新权重。相反,生物神经网络仅根据权重连接的两个神经元的即时激活即可完成学习。BP的非局部可塑性不仅需要储存前馈计算过程中的所有变量,还必须计算并传播反向信号,大幅增加了存储需求和额外的计算开销。
- 更新锁定(update locking):指BP网络的前馈过程与梯度反向传播过程不能同步进行,即在前馈过程中,权重更新将被锁定,导致学习速度降低,学习延迟增加。
- 全局损失函数(global loss function):在监督学习中,损失函数的计算依赖于人为给定的标签。由于这类数据获取成本高,基于监督的BP学习难以对所有数据进行充分利用。尽管自监督学习可使用模型本身的信号计算全局损失,BP网络依旧容易过拟合于特定映射并对对抗攻击十分敏感(具体见文献:Towards deep learning models resistant to adversarial attacks. ArXiv:1706.06083, 2017;Softhebb: Bayesian inference in unsupervised hebbian soft winner-take-all networks. ArXiv:2107.05747, 2021),学习的特征也难以泛化于其他数据和任务。
由于上述问题的存在,目前广泛使用的BP算法难以直接应用于在线学习领域。针对该问题,大量工作致力于寻找低功耗、低延时、低计算量、低内存需求的可在线更新的网络学习算法。目前,该领域的工作可大致分为两类:
- 基于BP算法,利用网络特性和数学近似改善BP算法,降低内存需求,提高学习效率;
- 采用仿生算法,模拟神经科学中神经细胞的生物特性实现网络参数更新和学习。
许多仿生学习算法基于Hebb理论,研究并发展出了一套仿生的人工神经网络学习算法。本文主要介绍Hebb学习算法在深层网络上的应用方法。
1 前置知识
1.1 Hebb学习规则
唐纳德·赫布(1904-1985)是加拿大著名生理心理学家。Hebb学习规则与“条件反射”机理一致,并且已经得到了神经细胞学说的证实。
巴甫洛夫的条件反射实验:每次给狗喂食前都先响铃,时间一长,狗就会将铃声和食物联系起来。以后如果响铃但是不给食物,狗也会流口水。
受该实验的启发,Hebb的理论认为在同一时间被激发的神经元间的联系会被强化。比如,铃声响时一个神经元被激发,在同一时间食物的出现会激发附近的另一个神经元,那么这两个神经元间的联系就会强化,从而记住这两个事物之间存在着联系。相反,如果两个神经元总是不能同步激发,那么它们间的联系将会越来越弱。用数学公式可表示为:
W i j t + 1 = W i j t + r ⋅ y i ⋅ y j W_{ij}^{t+1} = W_{ij}^t + r\cdot y_i \cdot y_j Wijt+1=Wijt+r⋅yi⋅yj
其中,
W i j t W_{ij}^t Wijt为突触前一个神经元 i i i和突触后一个神经元 j j j的连接权重在第t步迭代时的权重, W i j t + 1 W_{ij}^{t+1} Wijt+1为在第t+1步的权重,突触即连接关系;
r r r为学习率;
y i y_i yi为神经元 i i i的输出, y j y_j yj为神经元 j j j的输出, 根据连接关系, y i y_i yi也是神经元 j j j的输入;
可见,当神经元和同时为正或者为负时,说明二者的激活状态的是同步的,因此连接权重增加;反之,若两个神经元输出为一正一负时,说明二者为异步激活状态,连接权重降低。若某一个神经元的输出为0,说明该神经元处于未激活状态,相应的,权重不进行更新。
原始的赫布学习仅考虑了两个神经元之间的关系,因此难以有效提取出不同维度的特征,即当网络退化为一个特定的模式时,经典赫布学习将不断强化单一模式,导致偏差增大。
1.2 Delta学习规则
Delta学习规则是一种简单的有监督学习算法,该算法根据神经元的实际输出与期望输出差别来调整连接权。即若神经元实际输出比期望输出大,则减少输入为正的连接的权重,增大所有输入为负的连接的权重。反之,则增大所有输入为正的连接权的权重,减少所有输入为负的连接权的权重。用数学公式可表示为:
W i j t + 1 = W i j t − r ⋅ f ′ ( d j , y j ) W_{ij}^{t+1} = W_{ij}^t - r \cdot f'(d_j, y_j) Wijt+1=Wijt−r⋅f′(dj,yj)
其中,
W i j t W_{ij}^t Wijt为突触前一个神经元 i i i和突触后一个神经元 j j j的连接权重在第t步迭代时的权重, W i j t + 1 W_{ij}^{t+1} Wijt+1为在第t+1步的权重,突触即连接关系; W i j W_{ij} Wij是沿着负梯度方向更新的。
r r r为学习率;
y j y_j yj为神经元 j j j的输出;
f ′ ( d j , y j ) f'(d_j, y_j) f′(dj,yj)为 f ( d j , y j ) f(d_j, y_j) f(dj,yj)关于 W i j W_{ij} Wij的偏导数值, f ( d j , y j ) f(d_j, y_j) f(dj,yj)为实际输出 d j d_j dj与期望输出 y j y_j yj的误差计算函数。
2 SoftHebb学习算法
多层Hebb学习网络是以WTA和SoftHebb学习规则为基础改进而来。
2.1 WTA(Winner Take All)
由于相邻神经元之间具有竞争性,不同神经元之间的连接也是相互影响的,如已在哺乳动物的大脑皮层中发现神经元通过抑制侧向神经元以竞争神经元间连接的回路,这种神经元之间的竞争现象被称为winner-take-all (WTA)。
假设将某一层视作竞争层,有p个神经元,对于一个特定输入值,所有p个神经元均有输出,其中响应的同步性最大的神经元为 j ∗ j^* j∗,WTA的更新方法用数学公式可表示为:
W j ∗ t ⋅ X j ∗ = max i = 1 , 2 , . . , p ( W i t ⋅ X ) W_{j^*}^{t} \cdot X_{j^*} = \max_{i=1,2,..,p}(W_i^{t} \cdot X) Wj∗t⋅Xj∗=i=1,2,..,pmax(Wit⋅X)
W j ∗ t + 1 = W j ∗ t + r ⋅ ( X − W j ∗ t ) W_{j^*}^{t+1} = W_{j^*}^t + r\cdot (X - W_{j^*}^{t}) Wj∗t+1=Wj∗t+r⋅(X−Wj∗t)
其中,
W j ∗ t W_{j^*}^t Wj∗t为神经元 j ∗ j^* j∗与所有输入神经元的连接权重在第t步迭代时的权重, W i j t + 1 W_{ij}^{t+1} Wijt+1为在第t+1步的权重;
r r r为学习率;
在WTA算法中,每次更新仅有同步性最高的神经元之间的连接会被加强。即多个神经元竞争对响应最强的神经元作为胜者(权重向量 W i W_i Wi与输入 X X X的内积最大)。仅有胜者神经元 j ∗ j^* j∗可以在当次学习中更新参数,增强其与 X X X的响应。当下次收到相似的输入信号时,神经元的响应将会更强,更容易在神经元竞争中胜出,并通过权重更新进一步加强对该信号的响应能力。这一特点使WTA能够更容易提取到输入信号的显著特征。
在WTA算法的更新规则下,不同神经元权重向量将会逐渐靠近不同的输入信号。在反复的竞争学习过程中,各神经元的权重将逐渐调整为神经元的输入向量的聚类中心。
2.2 SoftHebb
文献[1]在WTA算法基础上使用softmax和余弦距离控制不同神经元之间的更新权重,提出了SoftHebb算法,并且为网络的学习过程提供了贝叶斯解释。其仿Hebb可塑性规则能够最小化模型概率分布与输入的K-L散度,同时,在特定假设下,最小化与标签的交叉熵。在单层网络中,SoftHebb可以显著提高学习速度和鲁棒性,大幅提升应对对抗攻击的能力。其更新过程如下:
Δ w i k t + 1 = η ⋅ y k ⋅ ( x i − u k ⋅ w i k t ) \begin{equation} \begin{split} \Delta w_{ik}^{t+1} = \eta \cdot y_k \cdot (x_i - u_k \cdot w_{ik}^{t}) \end{split} \end{equation} Δwikt+1=η⋅yk⋅(xi−uk⋅wikt)
w i k t + 1 = w i k t + Δ w i k t + 1 \begin{equation} \begin{split} w_{ik}^{t+1} = w_{ik}^{t} + \Delta w_{ik}^{t+1} \end{split} \end{equation} wikt+1=wikt+Δwikt+1
y k = softmax ( u k + w 0 k t τ ) = exp u k + w 0 k t τ ∑ l = 0 K exp u l + w 0 k t τ \begin{equation} \begin{split} y_k &= \text{softmax} (\frac{u_k+w_{0k}^{t}}{\tau}) \\ &= \frac {\exp ^{\frac{u_k+w_{0k}^{t}}{\tau}}} {\sum _{l=0}^{K} \exp ^{\frac{u_l+w_{0k}^{t}}{\tau}}} \end{split} \end{equation} yk=softmax(τuk+w0kt)=∑l=0Kexpτul+w0ktexpτuk+w0kt
u k = w i k t ⋅ x i \begin{equation} \begin{split} u_k = w_{ik}^{t} \cdot x_i \end{split} \end{equation} uk=wikt⋅xi
其中,
u k ⋅ w i k t u_k \cdot w_{ik}^{t} uk⋅wikt表示突触前神经元i与突触后神经元k的连接权重的第t次迭代值 w i k t w_{ik}^{t} wikt与神经元k的带权重输入 u k u_k uk之间的余弦距离(两个向量归一化后就是余弦距离,否则与余弦距离成比例关系); u k u_k uk值只是该层神经元输入X向量的一个分量 x i x_i xi与权重变量 w i k w_{ik} wik的乘积,是个中间临时定义的变量,见图1中的右侧的网络结构。
w 0 k t w_{0k}^{t} w0kt是神经元k的偏置参数在第t次迭代时的取值,其更新方法与式(1)(2)类似,具体可以见下图2 SoftHebb learning伪代码 的17-18行;
y k y_k yk则是神经元的输出经过softmax非线性运算后的结果。
注:下图中数学符号和变量定义比较多,完整的描述请查阅文献[1]。
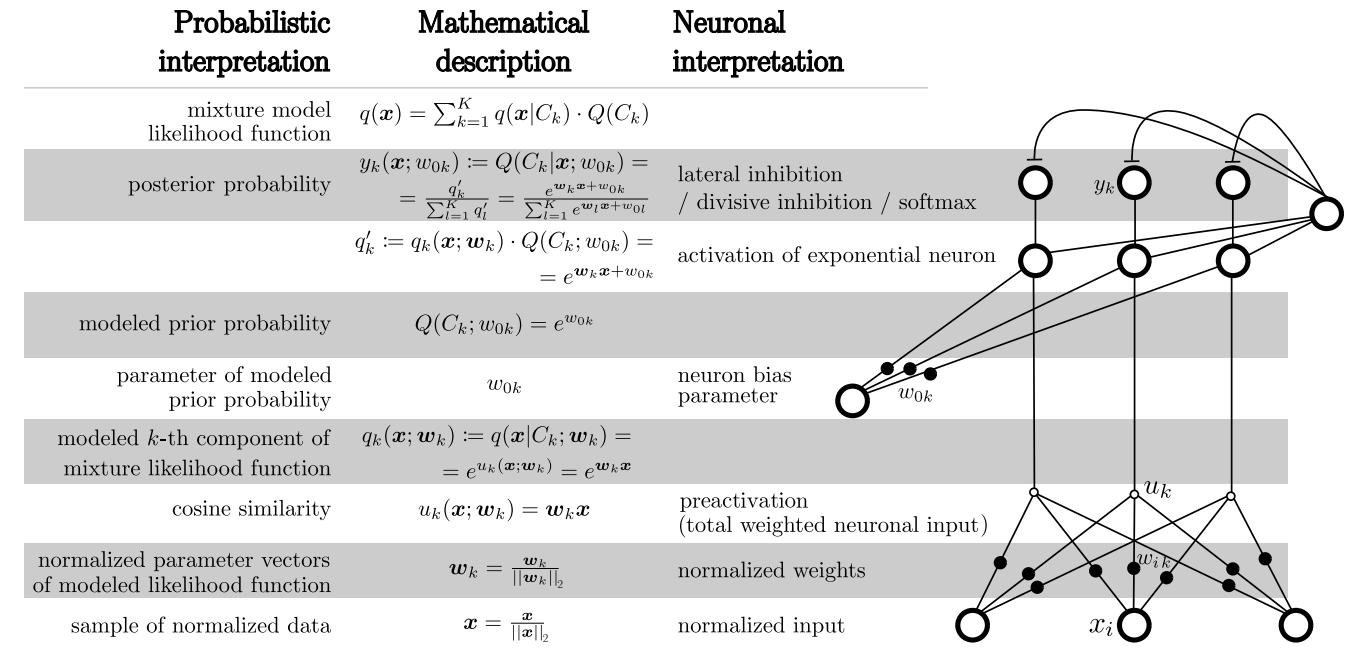
图1 变量定义和网络结构

图2 SoftHebb learning伪代码
2.3 多层Hebb网络
尽管已有很多工作为Hebb学习的发展和完善做出了贡献,但大部分工作主要考虑单层网络的特性分析,Hebb网络在训练过程中依旧非常容易饱和,很难应用在多层网络中。文献[2]在前人工作的基础上做了系列改进,可以使网络扩展到3-5层,但是相比于DNN的深度,仍然有很多研究和提升的空间。具体的改进措施:
- 加入了反赫布可塑性(soft anti-hebb plasticity)学习。简而言之就是使非同步激活的神经元连接权重降低,结合SoftHebb的思路,通过softmax对异步激活值进行加权,使得同步性最差的神经元连接具有更高的更新权重。而在前面提到的WTA算法中,非同步激活的神经元是不更新权重的。
- 自适应学习率。在训练中根据连接权值的大小自动调整学习步长。根据上述权重更新规则,随着学习的进行,神经元间的权重向量模长将趋向于1。因此,当权重向量模大于1时,学习步长应该更大。计算公式: l r i = l r ⋅ ( r i − 1 ) l r p lr_i = lr · (r_i − 1)^{lrp} lri=lr⋅(ri−1)lrp,其中, l r lr lr其中为初始学习率, l r p lrp lrp为控制学习率变化的超参数。
- 尺度变换。这是应用在CNN中的,使得图像每经过一个SoftHebb层,将通过池化操作进行一次下采样,使得网络能够获得更高的感受野,从而统合更大尺度的信息。
2.4 Hebb学习的性能测评
由于仅考虑局部突触的可塑性,赫布学习规避了基于BP算法的四大局限性,具有更好的生物可解释性。尽管已有大量工作对赫布学习进行了研究,为其在深度学习框架下的应用提供了宝贵的经验, 赫布学习仍然有尚未解决的问题。首先,现有的赫布网络均为浅层网络。随着网络深度的增加,赫布网络将迅速饱和,其特征提取能力几乎不再增加。其次,赫布网络的特征提取能力目前仍逊色于BP网络。表1展示了6层采用不用训练方法得到的网络在CIFAR-10上的分类结果。其中“G”表示使用随机梯度下降(SGD)训练;“H”表示使用赫布理论更新层参数;“R”表示该层是未经训练的随机初始化状态。当网络全层采用SGD更新时,分类正确率最高。随着使用赫布更新的层数的增加,网络的分类正确率逐渐下降,但仍然优于未经训练的随机初始化状态。从该表格和图3可以看出,目前基于赫布理论的学习方法具有一定的有效特征提取能力,但仍然不如BP方法。
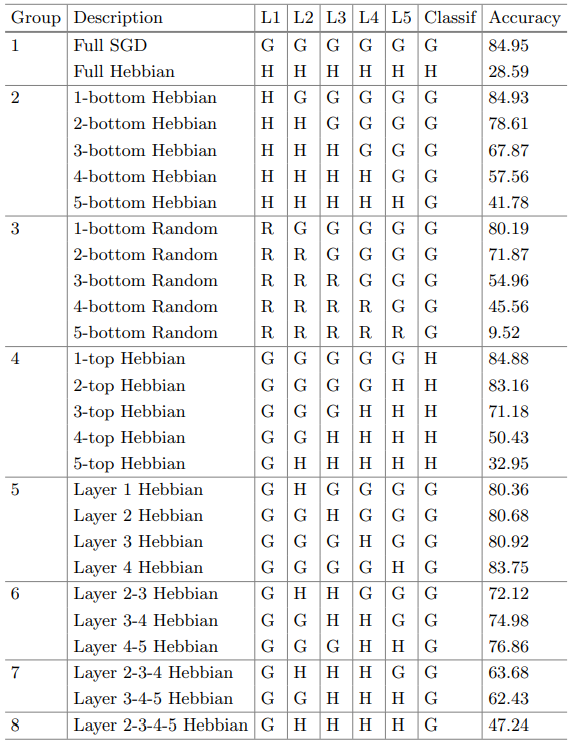
表1 不同参数更新方法对网络分类能力的影响
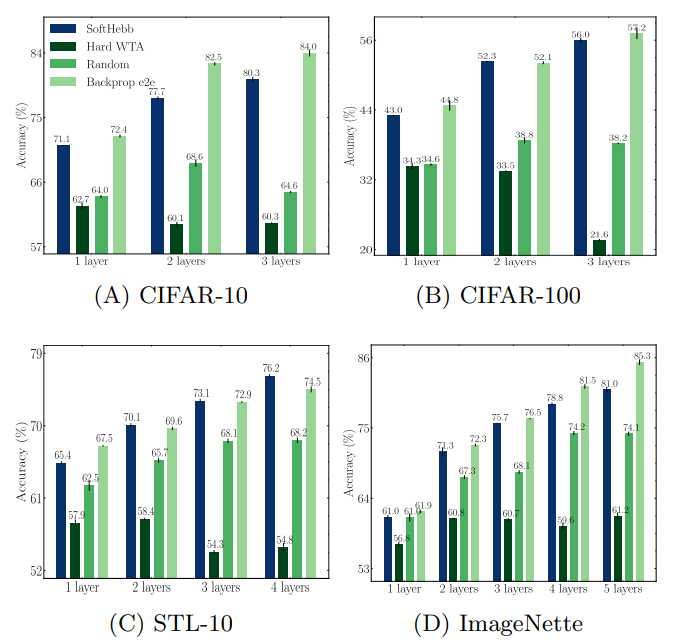
图3 不同深度在不同数据集上的分类精度的表现
3 参考文献
[1]. SoftHebb:Bayesian inference in unsupervised hebbian soft winner-take-all networks. ArXiv:2107.05747, 2021.
[2]. Hebbian Deep Learning Without Feedback. ArXiv: 2209.11883, 2022.
[3]. https://bat.sjtu.edu.cn/zh/hbstudy20230222/#post-3103-_Toc123147898
相关文章:
基于Hebb学习的深度学习方法总结
基于Hebb学习的深度学习方法总结 0 引言1 前置知识1.1 Hebb学习规则1.2 Delta学习规则 2 SoftHebb学习算法2.1 WTA(Winner Take All)2.2 SoftHebb2.3 多层Hebb网络2.4 Hebb学习的性能测评 3 参考文献 0 引言 总所周知,反向传播算法(back-propagating, B…...

思科模拟器 | 访问控制列表ACL实现网段精准隔绝
文章目录 一、ACL工作原理二、ACL分类初步介绍三、标准ACL1、标准ACL的决策过程2、标通配符掩码关键字3、标准ACL网络拓扑4、标准ACL演示5、实战讲解 四、扩展ACL1、基础语法明细2、扩展ACL示例3、扩展ACL网络拓扑4、实战讲解 五、总结与提炼 一、ACL工作原理 ACL(A…...

Python os模块详解
1. 简介 os就是“operating system”的缩写,顾名思义,os模块提供的就是各种 Python 程序与操作系统进行交互的接口。通过使用os模块,一方面可以方便地与操作系统进行交互,另一方面页也可以极大增强代码的可移植性。如果该模块中相…...

Oracle PL/SQL基础语法学习13:比较运算符
系列文章目录 Oracle PL/SQL基础语法学习12:短路求值 Oracle PL/SQL基础语法学习13:比较运算符 Oracle PL/SQL基础语法学习14:BOOLEAN表达式 文章目录 系列文章目录Oracle PL/SQL基础语法学习13:比较运算符比较运算符介绍官方文档…...

金仓数据库适配记录
金仓数据库适配记录 人大金仓数据库管理系统KingbaseES(简称:金仓数据库或KingbaseES)是北京人大金仓信息技术股份有限公司自主研制开发的具有自主知识产权的通用关系型数据库管理系统。 金仓数据库主要面向事务处理类应用,兼顾各类数据分析类应用,可用做管理信息系统、…...

ElasticSearch 学习 ==ELK== 进阶
二、ElasticSearch 学习 ELK 进阶 (1)文档局部更新 我们也说过文档是不可变的——它们不能被更改,只能被替换。 update API必须遵循相同的规则。表面看来,我们似乎是局部更新了文档的位置,内部却是像我们之前说的一样…...
【数据结构 -- C语言】 双向带头循环链表的实现
目录 1、双向带头循环链表的介绍 2、双向带头循环链表的接口 3、接口实现 3.1 开辟结点 3.2 创建返回链表的头结点 3.3 判断链表是否为空 3.4 打印 3.5 双向链表查找 3.6 双向链表在pos的前面进行插入 3.6.1 头插 3.6.2 尾插 3.6.3 更新头插、尾插写法 3.7 双向链…...
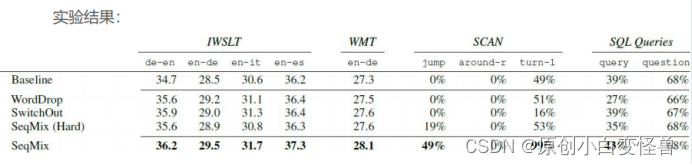
自然语言处理与其Mix-up数据增强方法报告
自然语言处理与其Mix-up数据增强方法 1绪论1.课题背景与意义1.2国内外研究现状 2 自然语言经典知识简介2.1 贝叶斯算法2.2 最大熵模型2.3神经网络模型 3 Data Augmentation for Neural Machine Translation with Mix-up3.1 数据增强3.2 对于神经机器翻译的软上下文的数据增强3.…...

Vue(组件化编程:非单文件组件、单文件组件)
一、组件化编程 1. 对比传统编写与组件化编程(下面两个解释图对比可以直观了解) 传统组件编写:不同的HTML引入不同的样式和行为文件 组件方式编写:组件单独,复用率高(前提组件拆分十分细致) 理…...
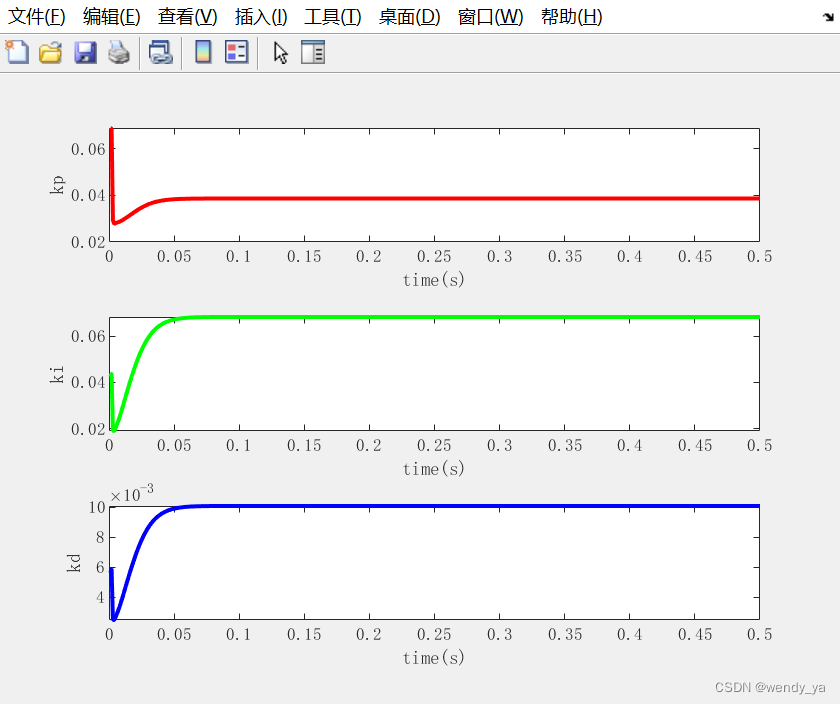
【MATLAB数据处理实用案例详解(22)】——基于BP神经网络的PID参数整定
目录 一、问题描述二、算法仿真2.1 BP_PID参数整定初始化2.2 优化PID2.3 绘制图像 三、运行结果四、完整程序 一、问题描述 基于BP神经网络的PID控制的系统结构如下图所示: 考虑仿真对象,输入为r(k)1.0,输入层为4,隐藏层为5&…...

第11章 项目人力资源管理
文章目录 项目人力资源管理 过程11.2.1 编制项目人力资源计划的工具与技术(1)层次结构图(工作、组织、资源 分解结构)(2)矩阵图(责任分配矩阵,RAM)(3…...
07-Vue技术栈之(组件之间的通信方式)
目录 1、组件的自定义事件1.1 绑定自定义事件:1.1.1 第一种方式1.1.2 第二种方式1.1.3 自定义事件只触发一次 1.2 解绑自定义事件1.3绑定原生DOM事件1.4 总结 2、全局事件总线(GlobalEventBus)2.1 应用全局事件总线 3、 消息订阅与发布&#…...

度量学习Metirc Learning和基于负例的对比学习Contrastive Learning的异同点思考
参考:对比学习(Contrastive Learning):研究进展精要 - 知乎 参考:对比学习论文综述【论文精读】_哔哩哔哩_bilibili 参考:度量学习DML之Contrastive Loss及其变种_对比损失的变种_胖胖大海的博客-CSDN博客 参考&…...

3.编写油猴脚本之-helloword
3.编写油猴脚本之-helloword Start 通过上一篇文章的学习,我们安装完毕了油猴插件。今天我们来编写一个helloword的脚步,体验一下油猴。 1. 开始 点击油猴插件>添加新脚本 默认生成的脚本 // UserScript // name New Userscript // name…...

openwrt的openclash提示【更新失败,请确认设备闪存空间足够后再试】
网上搜索了一下,问题应该是出在“无法从网络下载内核更新包”或者“无法识别内核的版本号” 解决办法:手动下载(我是只搞了DEV内核就搞定了TUN和Meta没有动) --> 上传到路由器上 --> 解压缩 --> 回到openclash界面更新配…...

torch.nn.Module
它是所有的神经网络的根父类! 你的神经网络必然要继承 可以看一下这篇文章...

论文解析-基于 Unity3D 游戏人工智能的研究与应用
1.重写 AgentAction 方法 1.1 重写 AgentAction 方法 这段代码是一个重写了 AgentAction 方法的方法。以下是对每行代码解释: ①public override void AgentAction(float[] vectorAction) 这行代码声明了一个公共的、重写了父类的 AgentAction 方法的方法。它接受…...
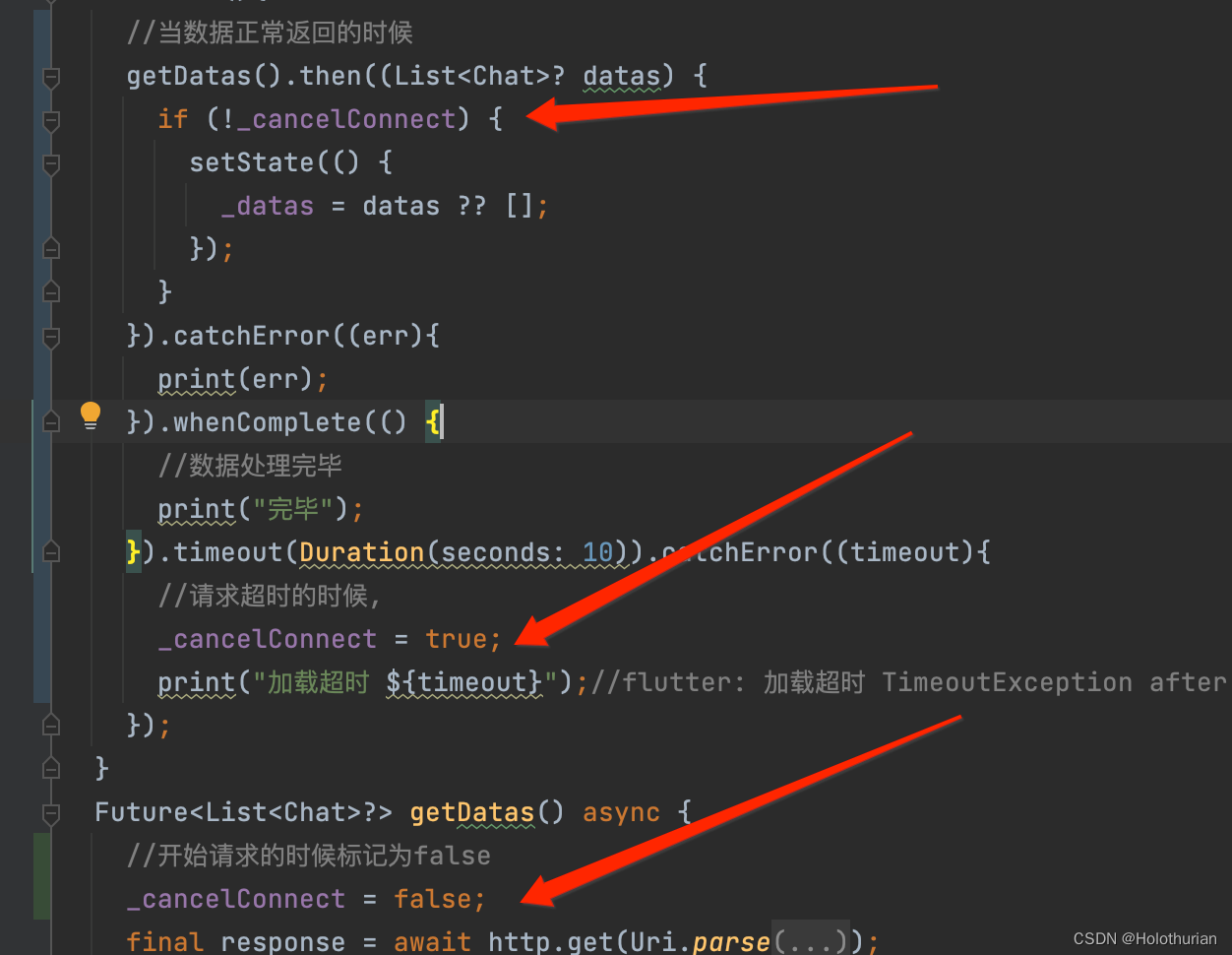
6、Flutterr聊天界面网络请求
一、准备网络数据 1.1 数据准备工作 来到网络数据制造的网址,注册登录后,新建仓库,名为WeChat_flutter;点击进入该仓库,删掉左侧的示例接口,新建接口. 3. 接着点击右上角‘编辑’按钮,新建响应内容,类型为Array,一次生成50条 4. 点击chat_list左侧添加按钮,新建chat_list中的…...

Java 8 腰斩!Java 17 暴涨 430%!!(文末福利)
New Relic 最新发布了一份 “2023 年 Java 生态系统状况报告”,旨在提供有关当今 Java 生态系统状态的背景和见解。该报告基于从数百万个提供性能数据的应用程序中收集的数据,对生产中使用最多的版本、最受欢迎的 JDK 供应商、容器的兴起等多方面进行了调…...

如何手写一个支持H.265的高清播放器
概述 音视频编解码技术在当前的互联网行业中十分热门,特别是高清视频播放器的开发,其中包括4K、8K等超高清分辨率的播放器,具有极高的市场需求和广泛的应用场景。H265编码技术更是实现高清视频压缩的重要手段之一。如果想要掌握音视频编解码…...

如何解决bilibili-api中BV号与AV号转换的技术难题?
如何解决bilibili-api中BV号与AV号转换的技术难题? 【免费下载链接】bilibili-api 哔哩哔哩常用API调用。支持视频、番剧、用户、频道、音频等功能。原仓库地址:https://github.com/MoyuScript/bilibili-api 项目地址: https://gitcode.com/gh_mirrors…...

QMCFLAC2MP3终极指南:一键解锁QQ音乐格式限制的完整解决方案
QMCFLAC2MP3终极指南:一键解锁QQ音乐格式限制的完整解决方案 【免费下载链接】qmcflac2mp3 直接将qmcflac文件转换成mp3文件,突破QQ音乐的格式限制 项目地址: https://gitcode.com/gh_mirrors/qm/qmcflac2mp3 你是否曾经从QQ音乐下载了心爱的歌曲…...

关于2026年6月14日PMI认证考试的报名通知
尊敬的各位考生: 经PMI和中国国际人才交流基金会研究决定,中国大陆地区2026年第二期PMI认证考试6月14日举办。在基金会网站报名参加本次PMI认证考试的考生须认真阅读下文,知悉考试安排及注意事项,并遵守考试有关规定。 一、 报名注…...

Pointer Network:如何解决序列生成中的动态词汇表问题
1. 为什么需要Pointer Network? 想象一下你正在玩一个拼图游戏,每次拿到的拼图块数量都不一样。传统的seq2seq模型就像是一个固定大小的收纳盒——如果这次拼图有50块,下次突然变成100块,你的收纳盒就装不下了。这就是传统序列生成…...

2025版等级保护测评报告模板:风险导向与合规深化的实践指南
1. 2025版等级保护测评报告模板的核心变革 如果你最近接触过等级保护测评工作,一定会注意到2025版报告模板带来的显著变化。这个版本最大的特点就是从过去的"得分导向"彻底转向了"风险导向"。在实际工作中,我发现很多企业安全负责人…...

QT6 + CMake + QML开发:你的图片和QML文件加载不出来?可能是.qrc没配对
QT6 CMake QML开发:资源加载失败的终极排查指南 当你花了几个小时精心设计了QML界面,却在运行时看到一片空白或"找不到文件"的错误提示时,那种挫败感每个QT开发者都深有体会。特别是在QT6和CMake的现代开发环境中,资源…...

如何用MouseClick鼠标连点器实现高效自动化点击:从游戏到办公的全场景指南
如何用MouseClick鼠标连点器实现高效自动化点击:从游戏到办公的全场景指南 【免费下载链接】MouseClick 🖱️ MouseClick 🖱️ 是一款功能强大的鼠标连点器和管理工具,采用 QT Widget 开发 ,具备跨平台兼容性 。软件界…...

实战应用:基于快马平台开发企业内网服务可用性监控系统
今天想和大家分享一个最近用InsCode(快马)平台快速实现的实用项目——企业内网服务可用性监控系统。这个需求来源于我们公司内部的实际痛点:随着服务器数量增加,经常出现某个服务端口异常但没人及时发现的情况。 1. 项目背景与需求分析 我们公司有几十…...

LangFlow问题解决:常见部署错误与连接Ollama配置详解
LangFlow问题解决:常见部署错误与连接Ollama配置详解 如果你正在尝试用LangFlow搭建自己的AI应用工作流,但卡在了部署和配置环节,这篇文章就是为你准备的。LangFlow作为一款低代码的可视化工具,理论上能让构建LangChain流水线变得…...

测试文章111
这是一篇测试的内容,要进行agent的测试...