自然语言处理与其Mix-up数据增强方法报告
自然语言处理与其Mix-up数据增强方法
- 1绪论
- 1.课题背景与意义
- 1.2国内外研究现状
- 2 自然语言经典知识简介
- 2.1 贝叶斯算法
- 2.2 最大熵模型
- 2.3神经网络模型
- 3 Data Augmentation for Neural Machine Translation with Mix-up
- 3.1 数据增强
- 3.2 对于神经机器翻译的软上下文的数据增强
- 3.3 序列对序列的Mix-up数据增强
- 4 文章实验结果展示
- 4.1论文①介绍的实验结果展示分析
- 4.2 论文②的实验结果展示分析
- 5总结与展望
- 5.1总结
- 5.2展望
- 参考文献
1绪论
1.课题背景与意义
自然语言处理(Natural Language Processing,简称NLP)是人工智能领域与计算机科学领域中的一个重要方向。它研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法。自然语言处理是一门融语言学、计算机科学、数学于一体的科学。我们所学习的NLP课程通过教授自然语言处理的基本概念与技术,帮助我们了解并掌握这一领域的核心知识与方法。
在课程的开篇,我们首先学习了自然语言的基本概念,区分于计算机语言,自然语言是人类发展过程中形成的一种信息交流的方式,包括口语及书面语,反映了人类的思维,都是以自然语言的形式表达。我们学习了自然语言的预处理,其中包括了去除噪声和对文本进行分词等操作。在数据处理的过程中,文本中会存在各种噪声或无用数据,这些数据会对后续处理带来麻烦,因此需要对其进行处理,以获得更好的处理结果。在自然语言处理中,文本数据需要被转换成计算机可操作的形式,这一过程称为文本的表示。我们学习了常见的文本表示方法,包括词袋模型(Bag-of-Words),TF-IDF方法等。情感分析是NLP领域的热门应用之一,其目的是对文本的情感色彩进行分类,通常可以分为正面、负面和中性情绪。我们通过学习情感分析的基本流程及技术,掌握了如何对文本进行情感分析的方法和技巧。
自然语言处理(Natural Language Processing, NLP)是计算机科学领域与人工智能领域中的一个重要方向。它研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法。随着互联网的快速发展,海量的自然语言数据不断涌现,如何挖掘和利用这些数据成为了自然语言处理面临的重大挑战,也为其带来了更广阔的发展前景。在当今信息时代,自然语言处理已被广泛应用于机器翻译、智能问答、信息检索、情感分析等领域,进一步提高了人们从文本数据中获取有用信息的效率和质量,对人类的生产生活产生了积极的影响。而随着技术的不断发展,自然语言处理将会在更多领域得到应用。
1.2国内外研究现状
近年来,自然语言处理在国内外的研究越来越受到重视,涉及的应用领域也越来越广泛。以下是对国内外自然语言处理研究现状的简要介绍:
词向量表示在NLP中,将单词转换为连续的向量表示已成为处理自然语言数据的主流方法。近年来,Word2Vec和GloVe等模型被开发出来,许多深度学习模型,如卷积神经网络(CNN)和循环神经网络(RNN)也被设计用于自然语言处理任务。
情感分析是NLP的一个热门应用,其主要目的是对文本进行情感分类,例如正面、负面和中性情绪。目前,一些支持向量机(SVM)和神经网络模型被用于情感分析任务中。
机器翻译(Machine Translation,MT)是利用计算机程序将一种自然语言翻译成另一种自然语言的过程。近年来,基于统计机器翻译和神经机器翻译的方法得到了广泛应用。
文本分类是将文本分为不同类别的任务,例如垃圾邮件识别、新闻分类等。近年来,基于深度学习的文本分类方法在自然语言处理中得到了广泛使用。
问答系统是指向用户提供自然语言界面,并通过回答用户问题来获取所需信息的系统。目前,基于深度学习的问答系统越来越受到关注,例如Google的BERT模型以及Facebook的DrQA模型等。
综上所述,自然语言处理在国内外的研究已经涉及到了众多领域,并且在各个领域中都具有广阔的应用前景。
2 自然语言经典知识简介
2.1 贝叶斯算法
贝叶斯算法有两个基本的原理:先验概率和条件概率。首先,我们需要根据已知的数据或经验,估计每个分类的先验概率。然后,我们需要根据新的样本评估每个可能的分类的条件概率,选择概率最大的分类作为预测结果。朴素贝叶斯 (Naive Bayes) 是贝叶斯分类算法中最简单的一个,一般用于处理二分类或多分类任务。该算法围绕着一个核心进行展开:贝叶斯定理。
贝叶斯网络实际上是一种模拟人类推理过程中因果关系的不确定性处理模型,其网络拓扑结构是一个有向无环图(DAG)。节点表示随机变量,它们可以是可观察到的变量,或隐变量、未知参数等。认为有因果关系(或非条件独立)的变量或命题则用箭头来连接。若两个节点间以一个单箭头连接在一起,表示其中一个节点是"因 (parents)“,另一个是"果 (children)”,两节点就会产生一个条件概率值。总体上来说,连接两个节点的箭头代表此两个随机变量是具有因果关系的,或者非条件独立。例如,假设节点E直接会影响到节点H,即E→H,则用从E指向H的箭头建立结点E到结点H的有向弧 (E,H),权值(即连接强度)用条件概率P(H|E)来表示。
2.2 最大熵模型
最大熵模型(Maximum Entropy Model)是利用信息论的一些概念和方法,从训练集中学习得到一个概率模型,它在所有可能的概率模型中熵最大的模型。最大熵模型的基本思想是:在满足已知约束条件下,选择不确定性最大(即:不确定的部分是等可能的)的模型。最大熵模型的学习过程就是求解最大熵模型的过程,也就是要确定一个参数向量,使得训练数据的经验熵最大化。
最大熵模型可以用于分类、回归、序列标注等各种机器学习任务。在自然语言处理领域中,最大熵模型常被用于自然语言处理中的词性标注、命名实体识别等任务。在最大熵模型中,采用拉格朗日乘子法将最大熵模型由一个带约束的最优化问题转化为一个与之等价的无约束的最优化问题,它是一个min max问题。通过迭代算法求解这个最优化问题,可以得到最大熵模型中的权重参数。
综上所述,最大熵模型是一种常用的概率模型,其基本思想是在已知约束条件下选择不确定性最大的模型。该模型在自然语言处理中应用广泛,并能够解决多种机器学习任务。
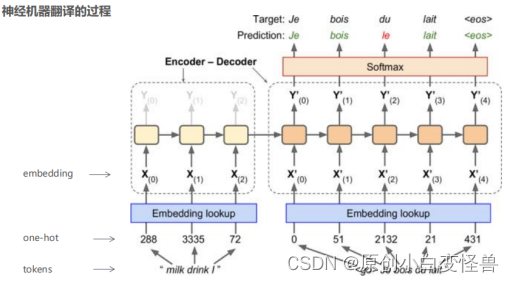
图1神经机器的翻译过程
2.3神经网络模型
神经网络是一种计算模型,它通过多层神经元之间的连接模拟人脑的神经系统,能够自动学习和识别数据模式,并在以后的任务中应用这些模式。神经网络可以被用于分类、回归、聚类、图像处理等各种机器学习任务,甚至可以被用于人工智能。神经网络拥有复杂的结构和参数,通常包括输入层、隐藏层和输出层等组成。其中输入层接收外部输入数据,隐藏层对输入数据进行加工处理,并将结果传递到下一层,最终输出层给出神经网络的输出结果。通过训练神经网络,优化神经网络的参数使得神经网络的输出与实际结果尽可能地接近。
目前常用的神经网络包括感知机、多层感知机、卷积神经网络、循环神经网络等。其中,感知机是最简单的神经网络模型,只包含输入层和输出层;多层感知机(MLP)是一种前馈神经网络,包含至少一个隐藏层,可以解决非线性问题;卷积神经网络(CNN)是一种专门用于图像和语音处理的神经网络模型,它通过卷积操作提取图像和语音的特征信息;循环神经网络(RNN)则是一种专门用于处理序列数据的神经网络模型,它的隐藏层可以传递给下一个时间步骤,从而实现对序列数据的记忆和处理。
综上所述,神经网络是一种计算模型,能够自动学习和识别数据模式并应用于各种机器学习任务。常用的神经网络模型包括感知机、多层感知机、卷积神经网络和循环神经网络等。
3 Data Augmentation for Neural Machine Translation with Mix-up
3.1 数据增强
数据增强(Data Augmentation,简称DA),是指根据现有数据,合成新数
据的一类方法。毕竟数据才是真正的效果天花板,有了更多数据后可以提升效
果、增强模型泛化能力、提高鲁棒性等。
数据增强(Data Augmentation)是指通过在原始数据集上应用一系列变换方法,生成新的训练样本来增强数据集的规模和多样性,从而提高深度学习模型的泛化能力。这一技术已经被广泛运用于图像处理、自然语言处理等领域。
数据增强主要分为两种类型:线下增强(offline augmentation)和线上增强(online augmentation)。线下增强适用于较小的数据集,可以通过对原始数据进行一些变换,比如旋转、裁剪、平移、镜像翻转等方式,增加一定倍数的数据集;而线上增强则是在网络训练过程中随机应用一定变换方式,每个迭代过程都产生新的数据。
除此之外,数据增强也可以应用于信号处理领域,如时间序列数据。通过使用统计方法如残差或块自助法,也可以增强数据集。在处理高维度、稀疏的生物信号数据时,人工合成数据通常是非常重要的。
3.2 对于神经机器翻译的软上下文的数据增强
下面要介绍的文章是来自于ACL2019的名叫Soft Contextual Data Augmentation for Neural Machine Translation.文章的主要思想是,将句子中的某个单词在句子的翻译解释中,将其替换为与相近的多个单词的词向量的distribution,从而使输入样例在机器翻译的过程中可以更好地识别翻译句子,提升了模型的鲁棒性,且是在自然语言处理领域引入Mix-up思想的具有代表性创作的一篇文章,在研究领域内意义重大。接下来介绍一下文章的具体工作。

图2 ACL2019
在对词转化为词向量的工作中对于一组数据对< x, y >,x代表训练集而y代表标签,经典的one-hot编码将一个词翻译为只有一个分量为1其余都为0的词向量
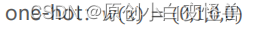
而在本文的方法中,我们将one-hot编码进行了平滑,使其变成一个向量和为1但部分分量都不为0的词向量(0.2,0.4,0.3,0.1)。在现实意义中,对用的例子就是“打”这个词把它的意义以distribution的形式给到了“打”,“敲”,“击”,“拍”上,且概率分别是0.2,0.4,0.3,0.1。因为打是直接对应于原单词的意思,所以其占比也最高,为0.4。平滑后的词向量接入正常的翻译工作,乘embedding矩阵得到e,具体如下
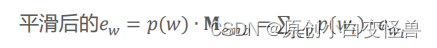
此时的e不仅仅表示w自身的含义,而是多个单词含义的加权和。
下面我们给出模型的理论公式
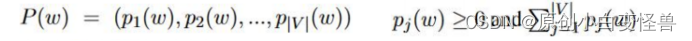
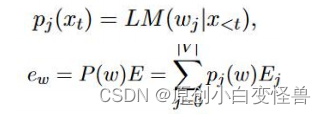
这样做是具有意义的,在训练集中的各个单词在训练后可以进行更好地翻译,在原有训练集的组合问题翻译上具有更高的准确率,拉近了近义词的含义,同时提高了模型的鲁棒性。实验和实验结果在后面的部分进行介绍。
3.3 序列对序列的Mix-up数据增强

图3 EMNLP2020
下面介绍的这篇关于序列到序列的Mix-up数据增强是来自于EMNLP2020,文章的核心思想是随机从sequence-to-sequence的训练样本集中取出两对样本和标签,对它们进行线性加权从而产生新的样本集,在数据增强之后(获得了更多的训练样本和标签,虽然这些样本和标签有可能不是真实存在的)进行模型训练,在原有baseline等对比实验中都取得了显著的效果,说明Seq-Mix(文章中提出的方法)是有效值得应用和研究的。
一个好的模型应该具有好的泛化性,相对于文本来说在替换了句子中的部分主语和状语等情况下,文章更希望学习到句子中词组(combination)的含义,使得在句子进行了替换之后仍然能够学习到词组的意思,但这在之前的研究工作中是尚待很好地解决,本文也是希望通过提出Seq-Mix方法来对combination的情况提出较好的解决方案。

在原有的hard替换中,只是通过强制替换掉单词的部分来产生增强数据集且有如下的数学模型:



相对于文章的Seq-Mix方法则是对其进行线性加权,对生硬的hard替换进行了平滑操作,这也是为什么模型具有更强泛化性和鲁棒性的原因。

在原有的Mixup方法中,λ是一个只关于分量为0,1的向量,而在本文提出的SeqMix方法中,λ是一个可调的超参数,将样本X,Y(矩阵表示)进行加权求和,同时对标签也进行替换,得到新的样本然后进行学习,实验结果表明,这种方法是创新且有效的。
4 文章实验结果展示
4.1论文①介绍的实验结果展示分析
在实验中我们进行对比的算法有Base,Swap,Dropout,Blank,Smooth和LM,它们的意义分别是:不做数据增强;将句子里面的单词在范围k内随机交换位置;随机丢弃单词;使用占位符替换随机单词;从词库中随机选择单词替换原单词,词库中每个单词被选择的概率与其在语料库中的词频成正比;从词库中随机选择单词替换原单词,每个单词被选择的概率符合单语言模型输出的分布。
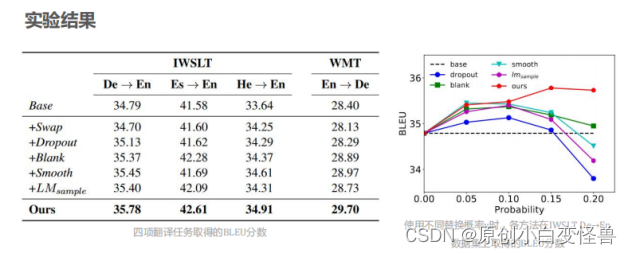
图4 第一篇论文介绍的实验结果与分析
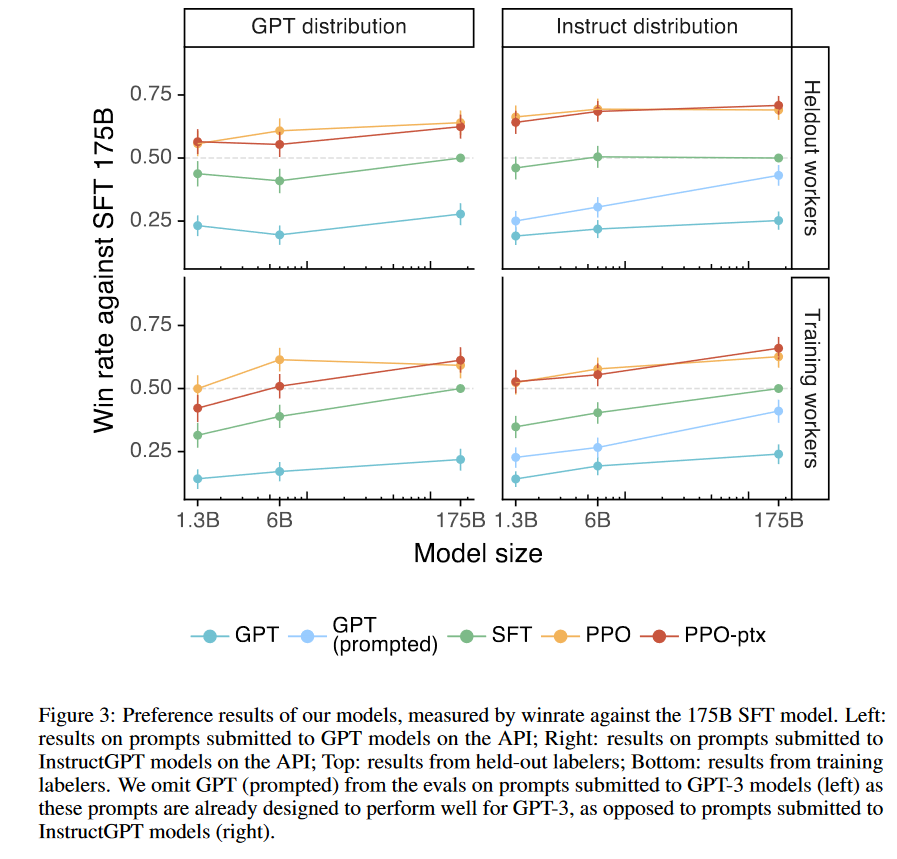
图中论文在德语转英语,西班牙语转英语等四个任务上将提出的软替换数据增强算法与baseline等进行对比,结果在各项指标上均有提升。注意在第二幅图中,当增大软替换的概率时,实验的精准度随着概率的增大呈现先增后减的趋势,这是因为部分小概率的替换可以很好地发挥软体换算法思想的作用,去完成翻译工作模型的泛化,但是当替换的程度增大时,句子的意思与原句子的意思发生了较为的改变,使得模型的训练结果在替换概率增大时结果又呈现出了下降的趋势。
4.2 论文②的实验结果展示分析
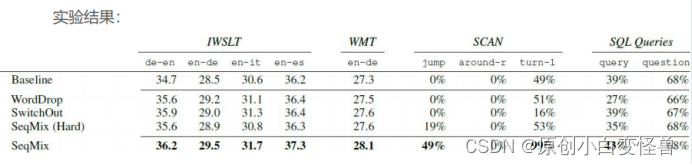
图5 第二篇论文介绍的实验结果与分析
Mix-up通过sequence to sequence的数据增强,将实验结果与baseline进行对比,在德语转英语,英语转德语,英语转意大利语和英语转西班牙语中,result都取得了sota的结果,另外在WMT中,SeqMix的结果达到了28.1;在SCAN和数据库查询(SQL Queries)中的junmp、turn-1和query的子实验中都取得了不错的改进效果。
5总结与展望
5.1总结
报告通过介绍自然语言处理的相关背景知识,如神经网络、贝叶斯算法和最大熵模型,自然语言处理的一些研究方向如:机器翻译、文本分类和国内外研究现状等等对自然语言处理研究领域进行了大致的介绍,然后又介绍了关于数据增强的有关概念。接着讲解了19年和20年两篇关于Mix-up思想的文本翻译文章。文章大致阐述了cv领域中的Mix-up方法思想的延申拓展到文本领域同样也有不错的效果,在训练样本集上经过词向量替换和线性加权的训练方法,使模型对已有的组合程度更复杂的文本集上进行翻译的工作可以取得好的效果和鲁棒性。本文主要探讨了自然语言处理在文本分类任务中的应用。通过对比不同模型的性能表现,我们发现随着模型训练量的增加,模型的准确率也得到了显著提升。同时,对于特定领域的文本分类任务,使用预训练模型和引入领域知识也能够有效提高模型的性能。
5.2展望
自然语言处理技术在各行各业中的应用越来越多,未来将继续迎来更广泛的应用场景。未来自然语言处理研究及应用的发展方向包括但不限于以下几个方面:1)进一步优化基于深度学习的自然语言处理技术,如自然语言生成、问答系统等;2)加强跨语言自然语言处理的研究,提高不同语言之间的交互体验;3)发挥自然语言处理在智能客服、社交媒体分析、情感分析等领域的应用,并探索更多应用场景。我们相信,未来自然语言处理技术的发展将会为人类社会带来更多机遇与挑战。
参考文献
[1] Li B, Hou Y, Che W. Data Augmentation Approaches in Natural Language Processing: A Survey[J]. AI Open, 2022, 3: 71-90.
[2] Gao F, Zhu J, Wu L, 等. Soft Contextual Data Augmentation for Neural Machine Translation[C]//Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2019: 5539-5544.
[3] Guo D, Kim Y, Rush A. Sequence-Level Mixed Sample Data Augmentation[C]//Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2020: 5547-5552.
[4] Zhang H, Cisse M, Dauphin Y N, et al. mixup: Beyond Empirical Risk Minimization[C]//International Conference on Learning Representations. 2023.
[5] Yun S, Han D, Oh S J, 等. CutMix: Regularization Strategy to Train Strong Classifiers With Localizable Features[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2019: 6023-6032.
[6] Uddin A F M S, Monira M S, Shin W, et al. SaliencyMix: A Saliency Guided Data Augmentation Strategy for Better Regularization[C]//International Conference on Learning Representations. 2023.
[7] Kim J, Choo W, Jeong H, et al. Co-Mixup: Saliency Guided Joint Mixup with Supermodular Diversity[C]//International Conference on Learning Representations. 2023.
相关文章:
自然语言处理与其Mix-up数据增强方法报告
自然语言处理与其Mix-up数据增强方法 1绪论1.课题背景与意义1.2国内外研究现状 2 自然语言经典知识简介2.1 贝叶斯算法2.2 最大熵模型2.3神经网络模型 3 Data Augmentation for Neural Machine Translation with Mix-up3.1 数据增强3.2 对于神经机器翻译的软上下文的数据增强3.…...

Vue(组件化编程:非单文件组件、单文件组件)
一、组件化编程 1. 对比传统编写与组件化编程(下面两个解释图对比可以直观了解) 传统组件编写:不同的HTML引入不同的样式和行为文件 组件方式编写:组件单独,复用率高(前提组件拆分十分细致) 理…...
【MATLAB数据处理实用案例详解(22)】——基于BP神经网络的PID参数整定
目录 一、问题描述二、算法仿真2.1 BP_PID参数整定初始化2.2 优化PID2.3 绘制图像 三、运行结果四、完整程序 一、问题描述 基于BP神经网络的PID控制的系统结构如下图所示: 考虑仿真对象,输入为r(k)1.0,输入层为4,隐藏层为5&…...

第11章 项目人力资源管理
文章目录 项目人力资源管理 过程11.2.1 编制项目人力资源计划的工具与技术(1)层次结构图(工作、组织、资源 分解结构)(2)矩阵图(责任分配矩阵,RAM)(3…...
07-Vue技术栈之(组件之间的通信方式)
目录 1、组件的自定义事件1.1 绑定自定义事件:1.1.1 第一种方式1.1.2 第二种方式1.1.3 自定义事件只触发一次 1.2 解绑自定义事件1.3绑定原生DOM事件1.4 总结 2、全局事件总线(GlobalEventBus)2.1 应用全局事件总线 3、 消息订阅与发布&#…...

度量学习Metirc Learning和基于负例的对比学习Contrastive Learning的异同点思考
参考:对比学习(Contrastive Learning):研究进展精要 - 知乎 参考:对比学习论文综述【论文精读】_哔哩哔哩_bilibili 参考:度量学习DML之Contrastive Loss及其变种_对比损失的变种_胖胖大海的博客-CSDN博客 参考&…...

3.编写油猴脚本之-helloword
3.编写油猴脚本之-helloword Start 通过上一篇文章的学习,我们安装完毕了油猴插件。今天我们来编写一个helloword的脚步,体验一下油猴。 1. 开始 点击油猴插件>添加新脚本 默认生成的脚本 // UserScript // name New Userscript // name…...

openwrt的openclash提示【更新失败,请确认设备闪存空间足够后再试】
网上搜索了一下,问题应该是出在“无法从网络下载内核更新包”或者“无法识别内核的版本号” 解决办法:手动下载(我是只搞了DEV内核就搞定了TUN和Meta没有动) --> 上传到路由器上 --> 解压缩 --> 回到openclash界面更新配…...

torch.nn.Module
它是所有的神经网络的根父类! 你的神经网络必然要继承 可以看一下这篇文章...

论文解析-基于 Unity3D 游戏人工智能的研究与应用
1.重写 AgentAction 方法 1.1 重写 AgentAction 方法 这段代码是一个重写了 AgentAction 方法的方法。以下是对每行代码解释: ①public override void AgentAction(float[] vectorAction) 这行代码声明了一个公共的、重写了父类的 AgentAction 方法的方法。它接受…...
6、Flutterr聊天界面网络请求
一、准备网络数据 1.1 数据准备工作 来到网络数据制造的网址,注册登录后,新建仓库,名为WeChat_flutter;点击进入该仓库,删掉左侧的示例接口,新建接口. 3. 接着点击右上角‘编辑’按钮,新建响应内容,类型为Array,一次生成50条 4. 点击chat_list左侧添加按钮,新建chat_list中的…...

Java 8 腰斩!Java 17 暴涨 430%!!(文末福利)
New Relic 最新发布了一份 “2023 年 Java 生态系统状况报告”,旨在提供有关当今 Java 生态系统状态的背景和见解。该报告基于从数百万个提供性能数据的应用程序中收集的数据,对生产中使用最多的版本、最受欢迎的 JDK 供应商、容器的兴起等多方面进行了调…...

如何手写一个支持H.265的高清播放器
概述 音视频编解码技术在当前的互联网行业中十分热门,特别是高清视频播放器的开发,其中包括4K、8K等超高清分辨率的播放器,具有极高的市场需求和广泛的应用场景。H265编码技术更是实现高清视频压缩的重要手段之一。如果想要掌握音视频编解码…...

Day 1 认识软件测试——(软件测试定义、目的、原则)
Day 1 认识软件测试——(软件测试定义、目的、原则) 文章目录 Day 1 认识软件测试——(软件测试定义、目的、原则)软件测试的定义软件测试的目的软件测试的经济学问题黑盒测试白盒测试软件测试原则小结所谓软件测试,就是一个过程或一系列过程,用来确定计算机代码完成了其…...
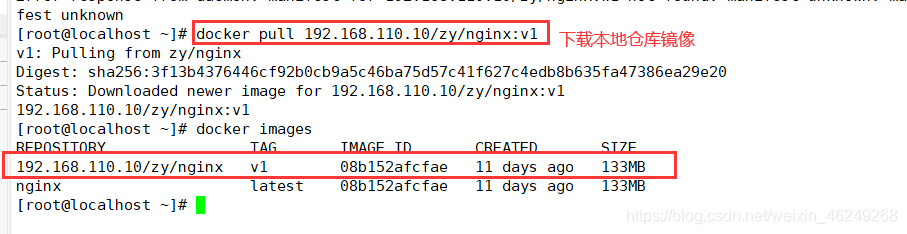
Docker Harbor
目录 一、Docker Harbor概述 1、Harbor的优势 2、Harbor知识点 3、Docker私有仓库架构 二、Harbor构建Docker私有仓库 1、环境配置 2、案例需求 3、部署docker-compose服务 4、部署harbor服务 5、启动harbor ① 访问 ② 添加项目并填写项目名称 ③ 通过127.0.0.1来…...

第三十四章 Unity人形动画(上)
在我们DirectX课程中,我们讲过一个模型最少拥有网格和材质,可以没有动画。游戏场景中的静态物体就可以是这样的模型,例如花草树木,建筑物等等,他们通过MeshRenderer就可以渲染。对于一个带有动画的FBX文件,…...

计算机图形学-GAMES101-7
引言 场景中有很多的三角形,如果实现可见性和遮挡呢? 一个简单的想法是,从远到近画,近处的物体自然会覆盖掉远处的物体,这种画法也叫画家算法。 但是实际绘制中物体的顺序是不容易确定的,比如如下图绘制…...

AndroidAuto 解决PCTS NF7
直接上代码 public void handleNavigationFocusRequest(int focusType) {// Always grant requested focus in this example.-mGal.galReceiver.sendNavigationFocusState(focusType);+mGal.galReceiver.sendNavigationFocusState...
GPT:你知道这五年我怎么过的么?
时间轴 GPT 首先最初版的GPT,来源于论文Improving Language Understanding by Generative Pre-Training(翻译过来就是:使用通用的预训练来提升语言的理解能力)。GPT这个名字其实并没有在论文中提到过,后人将论文名最后…...
Python一行命令搭建HTTP服务器并外网访问 - 内网穿透
文章目录 1.前言2.本地http服务器搭建2.1.Python的安装和设置2.2.Python服务器设置和测试 3.cpolar的安装和注册3.1 Cpolar云端设置3.2 Cpolar本地设置 4.公网访问测试5.结语 转载自远程内网穿透的文章:【Python】快速简单搭建HTTP服务器并公网访问「cpolar内网穿透…...

4阶段构建企业级离线文档处理平台:从问题诊断到性能优化全指南
4阶段构建企业级离线文档处理平台:从问题诊断到性能优化全指南 【免费下载链接】WeKnora LLM-powered framework for deep document understanding, semantic retrieval, and context-aware answers using RAG paradigm. 项目地址: https://gitcode.com/GitHub_Tr…...

Qwen3-14B推理速度实测:10核CPU+24GB显存下首token延迟<800ms
Qwen3-14B推理速度实测:10核CPU24GB显存下首token延迟<800ms 1. 测试环境与配置 1.1 硬件配置 本次测试使用的硬件配置完全匹配Qwen3-14B私有部署镜像的推荐规格: GPU:RTX 4090D 24GB显存(NVIDIA驱动550.90.07)…...

超越GUI:用Tcl命令流高效编辑Tessent DftSpecification的三种进阶玩法
超越GUI:用Tcl命令流高效编辑Tessent DftSpecification的三种进阶玩法 在大型SoC项目中,频繁修改IJTAG网络结构是每位资深DFT工程师的日常。当设计迭代进入深水区,图形界面操作和手动文本编辑的效率瓶颈会愈发明显——每次增减SIB、调整TDR位…...

大模型部署成本优化:面向测试从业者的云服务省钱技巧
随着大模型在自动化测试、缺陷智能分析、测试用例生成等领域的应用日益深入,其部署与调用成本已成为测试团队必须面对的核心挑战。高昂的GPU算力费用、未被充分利用的资源以及复杂的定价模型,都可能使技术创新的预算捉襟见肘。一、理解成本构成ÿ…...

Ostrakon-VL像素终端实战:为盲人顾客生成语音版货架导航
Ostrakon-VL像素终端实战:为盲人顾客生成语音版货架导航 1. 项目背景与价值 在零售场景中,视觉障碍顾客常常面临难以独立寻找商品的困境。传统解决方案依赖人工引导或专用盲道,成本高且灵活性不足。我们基于Ostrakon-VL-8B多模态大模型&…...

别再为UI动画发愁了!用Spine+Unity 2021制作丝滑2D动画的保姆级流程
SpineUnity 2021:打造专业级2D UI动画的完整实战指南 在独立游戏开发领域,UI动画的质量往往决定着玩家的第一印象。那些流畅的按钮反馈、生动的界面过渡,不仅提升了产品质感,更直接影响着用户的留存率。然而对于资源有限的中小团队…...

从大疆NAZA换到匿名P2飞控:一个DIY玩家的真实体验与参数调试避坑指南
从大疆NAZA到匿名P2飞控:一位DIY玩家的深度迁移指南 当我的F450机架在狭小卧室里显得笨拙不堪时,我意识到需要一次彻底的"瘦身计划"。这不是简单的机架更换,而是一次从商业飞控到开源系统的完整迁移——将大疆NAZA积累的经验移植到…...

新手福音:通过快马平台生成带详解代码,轻松完成openclaw首次本地部署
今天想和大家分享一个特别适合新手的实践项目——在本地部署openclaw。作为一个刚接触AI部署的小白,我最初看到各种复杂的配置步骤就头大,直到发现了InsCode(快马)平台,整个过程变得简单多了。下面就把我的经验整理成笔记,希望能帮…...

终极Galgame社区完整指南:从零开始构建你的视觉小说精神家园
终极Galgame社区完整指南:从零开始构建你的视觉小说精神家园 【免费下载链接】kun-touchgal-next TouchGAL是立足于分享快乐的一站式Galgame文化社区, 为Gal爱好者提供一片净土! 项目地址: https://gitcode.com/gh_mirrors/ku/kun-touchgal-next 还在为寻找纯…...
)
保姆级教程:用OpenAI Whisper给视频自动生成字幕(附Python代码)
视频创作者必备:用Whisper打造高效字幕工作流 每次剪辑视频最头疼的就是加字幕?作为过来人,我完全理解那种对着时间轴逐帧调整的痛苦。直到发现Whisper这个神器,我的工作效率直接翻了三倍。今天就把这套全自动字幕生成方案完整分享…...