hive的详细使用文档和使用案例
目录
- Hive 简介
- 安装
- 连接到Hive
- 创建数据库
- 创建表
- 加载数据
- 查询数据
- 修改表
- 删除表
- 使用案例
- 结论
Hive 简介
Hive是一个基于Hadoop的数据仓库工具,可以将结构化数据映射到Hadoop HDFS上,并提供SQL查询功能。Hive的设计目标是让那些熟悉SQL语言的用户能够在Hadoop上轻松执行数据查询和分析任务,无需编写MapReduce程序。
Hive使用HiveQL(类似于SQL)作为查询语言,支持各种数据源,如Hadoop HDFS、HBase、MySQL等,同时也支持多种格式的数据,如文本、序列化、ORC等。
安装
在使用Hive之前,需要将其安装在本地计算机上。Hive与Hadoop密切相关,因此需要先安装Hadoop。Hive通常作为Hadoop的一部分提供,因此可以通过Hadoop分发中的bin目录访问Hive二进制文件。或者,您也可以从Hive官方网站下载压缩包并手动安装。
连接到Hive
Hive提供了不同的方式来连接到Hive,包括使用命令行界面、JDBC、ODBC等。以下是一个使用命令行界面连接到Hive的示例:
hive
这个命令将启动Hive命令行界面,并连接到默认的Hive数据库。
创建数据库
以下是一个使用Hive创建数据库的示例:
CREATE DATABASE mydatabase;
这个命令将创建名为“mydatabase”的数据库。
创建表
以下是一个使用Hive创建表的示例:
CREATE TABLE mytable (id INT,name STRING,age INT
);
这个命令将创建名为“mytable”的表,并定义了三个列:id、name和age。
加载数据
以下是一个使用Hive加载数据到表中的示例:
LOAD DATA LOCAL INPATH '/path/to/data' INTO TABLE mytable;
这个命令将从本地文件系统中的“/path/to/data”目录中加载数据,并将数据插入到“mytable”表中。
查询数据
以下是一个使用Hive查询数据的示例:
SELECT * FROM mytable WHERE age > 18;
这个命令将从“mytable”表中选择所有列,并仅返回age列大于18的行。
修改表
以下是一些使用Hive修改表的示例:
- 添加列:ALTER TABLE mytable ADD COLUMN email STRING;
- 更改列名:ALTER TABLE mytable CHANGE COLUMN name first_name STRING;
- 更改列类型:ALTER TABLE mytable CHANGE COLUMN age age STRING;
删除表
以下是一个使用Hive删除表的示例:
DROP TABLE mytable;
这个命令将删除名为“mytable”的表。
使用案例
以下是一个使用Hive的示例案例,展示如何从Hadoop HDFS中的文本文件中查询数据。
假设我们有一个存储在Hadoop HDFS中的文本文件,其中包含有关人员的信息,每行一个记录,每行包含id、名称、年龄和电子邮件地址。我们可以使用Hive查询这个文件中的数据。
首先,我们需要在Hive中创建一个表,用于存储这些数据:
CREATE EXTERNAL TABLE people (id INT,name STRING,age INT,email STRING
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
LOCATION '/path/to/people';
这个命令将创建一个名为“people”的表,该表包含id、name、age和email列,并且数据存储在Hadoop HDFS的“/path/to/people”位置。我们使用ROW FORMAT DELIMITED和FIELDS TERMINATED BY '\t’来指定数据的格式。
接下来,我们可以使用SELECT语句来查询这个表中的数据:
SELECT name, age FROM people WHERE age > 18;
这个命令将从“people”表中选择name和age列,并仅返回age列大于18的行。我们可以使用其他SQL函数和操作符来进一步处理和分析数据。
结论
Hive是一个非常有用的工具,它可以将结构化数据映射到Hadoop HDFS上,并提供SQL查询功能。本文提供了Hive的详细使用文档和使用案例,希望能够帮助您更好地使用Hive。请注意,本文只提供了Hive的部分功能和用法,更多详细信息请参考Hive官方文档。
相关文章:

hive的详细使用文档和使用案例
目录 Hive 简介安装连接到Hive创建数据库创建表加载数据查询数据修改表删除表 使用案例结论 Hive 简介 Hive是一个基于Hadoop的数据仓库工具,可以将结构化数据映射到Hadoop HDFS上,并提供SQL查询功能。Hive的设计目标是让那些熟悉SQL语言的用户能够在Ha…...

KL散度
KL散度(Kullback-Leibler divergence),也称为相对熵(relative entropy),是用来衡量两个概率分布之间差异的一种指标。在机器学习中,KL散度常常用于度量两个概率分布之间的相似度或差异性。 具体…...

Java基础学习(16)多线程
Java基础学习多线程 一、多线程1.1 什么是多线程1.2 多线程的两个概念1.2.1 并发 1.3 多线程的实现方式1.4 多线程的成员方法1.5 线程的生命周期 二、线程安全1.6 同步方法1.7 锁lock1.8 死锁1.8 生产者和消费者 (等待唤醒机制)1.9 等待唤醒机制(阻塞队列方式实现)1…...

【一起啃书】《机器学习》第五章 神经网络
文章目录 第五章 神经网络5.1 神经元模型5.2 感知机与多层网络5.3 误差逆传播算法5.4 全局最小与局部极小5.5 其他常见神经网络5.6 深度学习 第五章 神经网络 5.1 神经元模型 神经网络是由具有适应性简单单元组成的广泛并行互连的网络,它的组织能够模拟生物神经系统…...
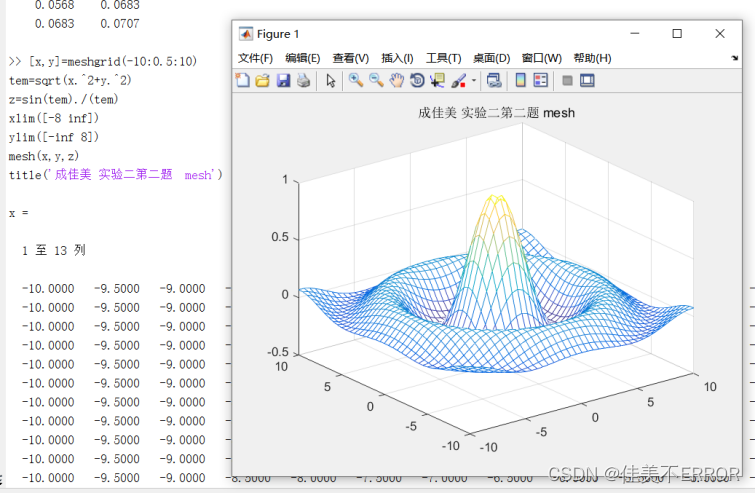
matlab实验二可视化
学聪明点,自己改,别把我卖了 一、实验目的及要求 要求 1、掌握 MATLAB常用的二维和三维绘图函数 2、掌握MATLAB的图形注释 3、熟悉MATLAB常用的图形修饰 4、熟悉MATLAB的图形动画 实验原理 1、MATLAB二维绘图:plot,fplot,fimplicit…...
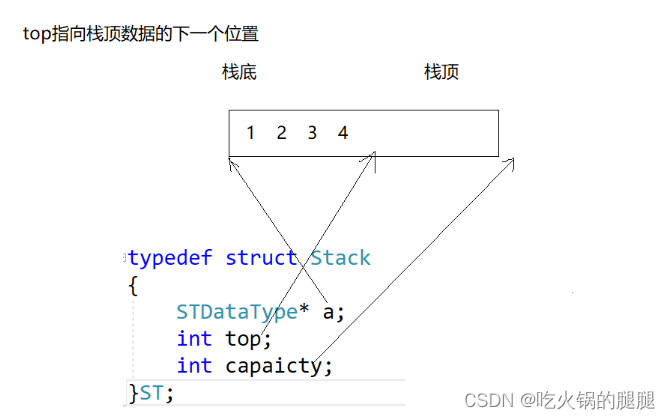
(数据结构)栈的实现——再一次保姆级教学
目录 1. 栈 编辑 1.2 栈的实现 2. 代码的实现 2.1 初始化栈和销毁栈 2.2栈顶元素的插入 2.3栈顶元素的删除 栈元素删除 2.4栈顶元素的获取和栈元素的个数 1. 栈 1.1 栈的概念和结构 栈(Stack)是一种线性存储结构,它具有如下特点: ࿰…...

【5G RRC】RSRP、RSRQ以及SINR含义、计算过程详细介绍
博主未授权任何人或组织机构转载博主任何原创文章,感谢各位对原创的支持! 博主链接 本人就职于国际知名终端厂商,负责modem芯片研发。 在5G早期负责终端数据业务层、核心网相关的开发工作,目前牵头6G算力网络技术标准研究。 博客…...

K8s(Kubernetes)学习(一):k8s概念及组件
Kubernetes中文文档:https://kubernetes.io/zh-cn/docs/home/ Kubernetes源码地址:https://github.com/kubernetes/kubernetes 一:Kubernetes是什么 首先要了解应用程序部署经历了以下几个时代: 传统部署时代:在物理服务器上运…...

Web3 常用语和黑话你知道吗?
My friend Dave used to be a bagholder, but he FOMO’d and bought even more BTC. Now, he’s a big whale HODLing for that moon. …that’s a lot to take in for just two sentences. If you’re new to Bitcoin and the world of cryptocurrencies, we understand if …...

物联网和边缘计算:如何将数据处理和决策推向设备边缘
第一章:引言 当我们谈论物联网(IoT)时,我们通常指的是将各种设备连接到互联网,并通过数据交换来实现智能化的网络。然而,传统的物联网模型通常涉及将数据发送到云端进行处理和分析。然而,随着技…...
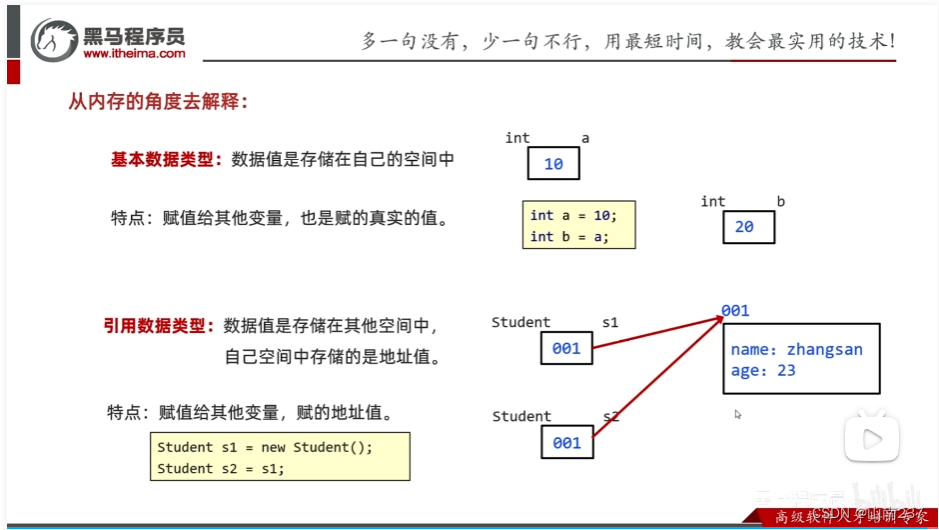
【Android学习专题】java基本语法和概念(学习记录)
学习记录来自菜鸟教程 Java 变量 Java 中主要有如下几种类型的变量 局部变量 在方法、构造方法或者语句块中定义的变量被称为局部变量。变量声明和初始化都是在方法中,方法结束后,变量就会自动销毁类变量(静态变量) 类变量也声…...
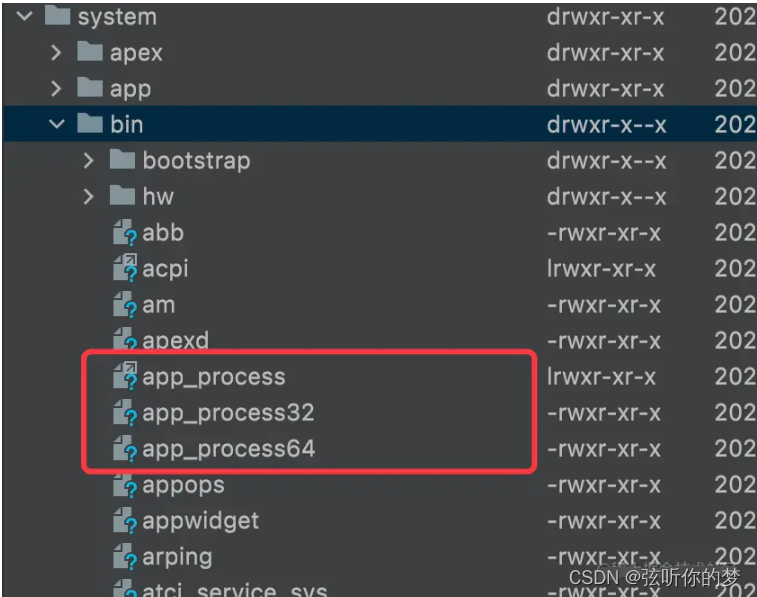
Android系统启动全流程分析
当我们买了一个手机或者平板,按下电源键的那一刻,到进入Launcher,选择我们想要使用的某个App进入,这个过程中,系统到底在做了什么事,伙伴们有仔细的研究过吗?可能对于Framework这块晦涩难懂的专…...
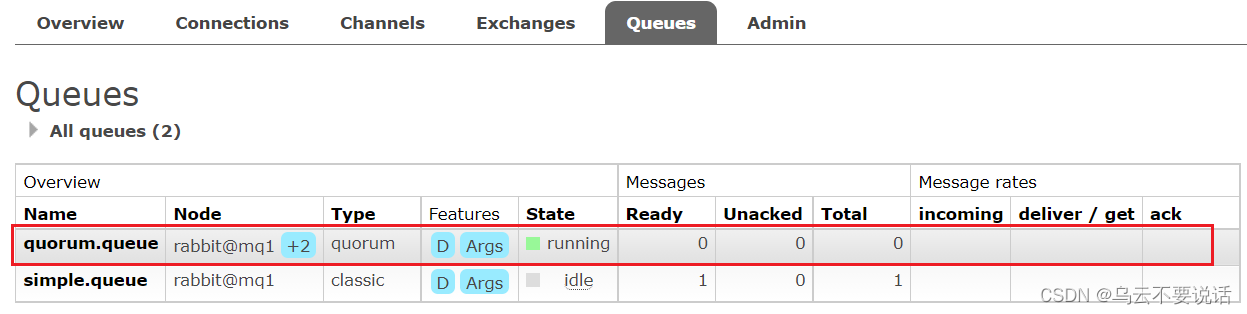
RabbitMQ --- 惰性队列、MQ集群
一、惰性队列 1.1、消息堆积问题 当生产者发送消息的速度超过了消费者处理消息的速度,就会导致队列中的消息堆积,直到队列存储消息达到上限。之后发送的消息就会成为死信,可能会被丢弃,这就是消息堆积问题。 解决消息堆积有三种…...

1.Buffer_Overflow-1.Basic_Jump
github上面的练习题 git clone https://github.com/Adamkadaban/LearnPwn 然后开始做 先进行 readelf 然后进行执行看看 是怎么回事 ./buf1发现就是一个输入和输出 我们checksec看看 发现stack 保护关闭 开启了NX保护 我们进入ida64看看反汇编 我习惯先看看字符串 SHITF…...

MySQL入门语法第三课:表结构的创建
数据表结构 定点数类型decimal(m,d) m表示数字总位数 d表示小数位数 ★创建数据表先要选择数据库 1 . CREATE TABLE 表名称 创建数据表 (字段名1 数据类型1 [,字段名2 数据名2] [, .....] ); 一个字段写一行 修改表名 alter table 旧表名 rename 新表名…...
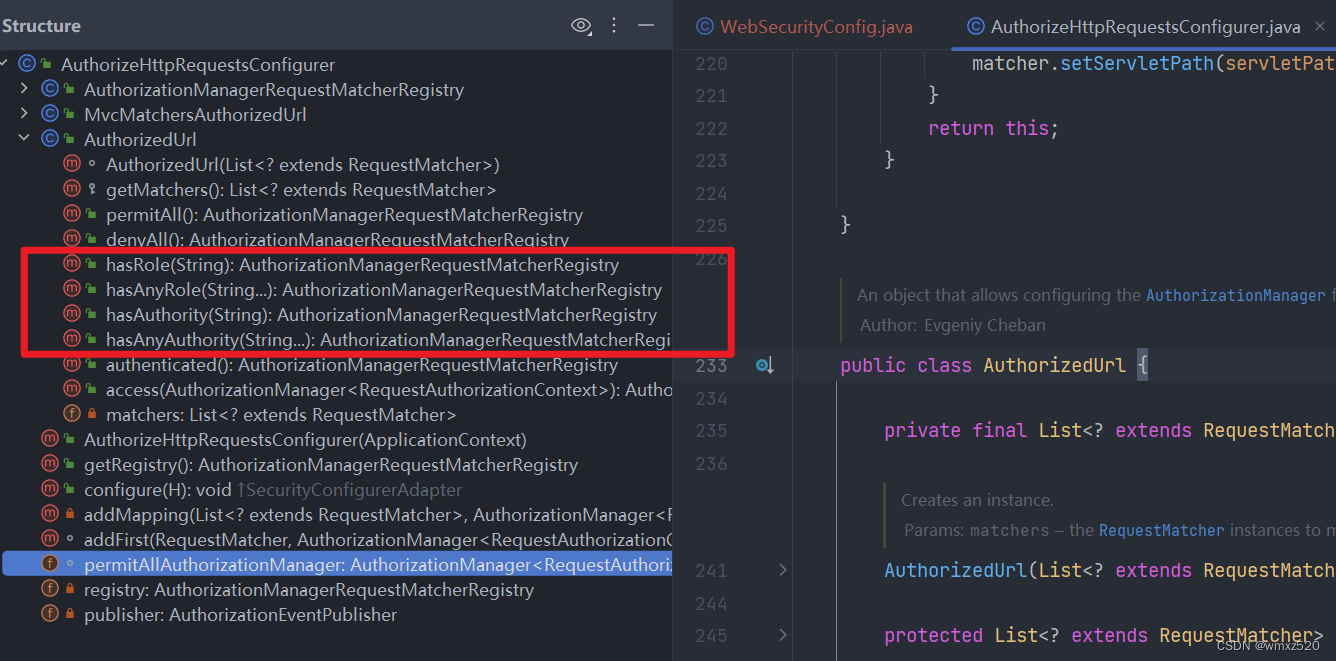
SpringSecurity框架学习与使用
SpringSecurity框架学习与使用 SpringSecurity学习SpringSecurity入门SpringSecurity深入认证授权自定义授权失败页面权限注解SecuredPreAuthorizePostAuthorizePostFilterPreFilter 参考 SpringSecurity学习 SpringSecurity入门 引入相关的依赖,SpringBoot的版本…...
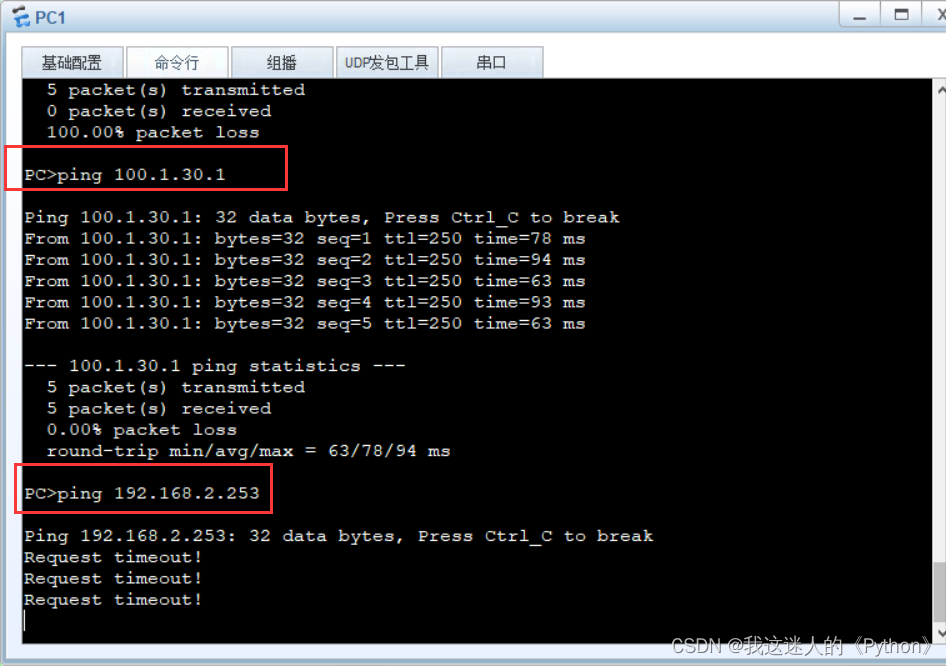
DHCP+链路聚合+NAT+ACL小型实验
实验要求: 1.按照拓扑图上标识规划网络。 2.使用0SPF协议进程100实现ISP互通。 3.私网内PC属于VLAN1O, FTP Server属于VLAN2O,网关分 别为所连接的接入交换机,其中PC要求通过DHCP动态获取 4:私网内部所有交换机都为三层交换机,请合理规划VLAN&#…...
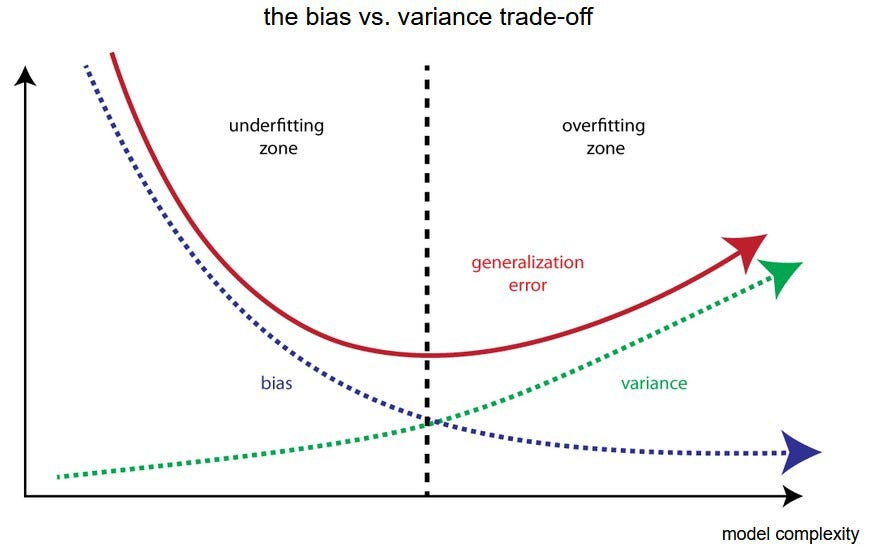
西瓜书读书笔记整理(三)—— 第二章 模型评估与选择
第二章 模型评估与选择 第 2 章 模型评估与选择2.1 经验误差与过拟合1. 错误率 / 精度 / 误差2. 训练误差 / 经验误差 / 泛化误差3. 过拟合 / 欠拟合4. 学习能力5. 模型选择 2.2 评估方法1. 评估方法概述2. 留出法3. 交叉验证法4. 自助法5. 调参 / 最终模型 2.3 性能度量1. 回归…...

AcWing算法提高课-1.3.6货币系统
宣传一下算法提高课整理 <— CSDN个人主页:更好的阅读体验 <— 本题链接(AcWing) 点这里 题目描述 给你一个n种面值的货币系统,求组成面值为m的货币有多少种方案。 输入格式 第一行,包含两个整数n和m。 接…...

vue3回到上一个路由页面
学习链接 Vue Router获取当前页面由哪个路由跳转 在Vue3的setup中如何使用this beforeRouteEnter 在这个路由方法中不能访问到组件实例this,但是可以使用next里面的vm访问到组件实例,并通过vm.$data获取组件实例上的data数据getCurrentInstance 是vue3提…...

如何用Citra在电脑上免费畅玩3DS游戏:从零开始的完整指南
如何用Citra在电脑上免费畅玩3DS游戏:从零开始的完整指南 【免费下载链接】citra A Nintendo 3DS Emulator 项目地址: https://gitcode.com/gh_mirrors/cit/citra 想要在个人电脑上重温《精灵宝可梦》、《塞尔达传说》等经典3DS游戏吗?Citra模拟器…...
 坑了!手把手教你正确配置 Python 本地 GEE API(附项目名查找指南))
别再被 ee.Initialize() 坑了!手把手教你正确配置 Python 本地 GEE API(附项目名查找指南)
别再被 ee.Initialize() 坑了!手把手教你正确配置 Python 本地 GEE API(附项目名查找指南) 如果你正在尝试在本地 Python 环境中使用 Google Earth Engine (GEE) API,很可能在 ee.Initialize() 这一步遇到了障碍。网上的许多教程…...

终极免费方案:一键重置Navicat Premium试用期完整指南
终极免费方案:一键重置Navicat Premium试用期完整指南 【免费下载链接】navicat-premium-reset-trial Reset macOS Navicat Premium 15/16/17 app remaining trial days 项目地址: https://gitcode.com/gh_mirrors/na/navicat-premium-reset-trial 你是否曾经…...

Simulink实战:用FCS-MPC搞定三相LC滤波逆变器,从建模到仿真避坑全流程
Simulink实战:FCS-MPC在三相LC滤波逆变器中的工程化实现 电力电子工程师们常开玩笑说,第一次在Simulink里实现MPC控制就像在迷宫里摸黑前行——明明论文里的公式推导得头头是道,一落地到仿真环境就遭遇各种"鬼打墙"。本文将用实验室…...

从理论到波形:基于Simulink的FOC SVPWM BLDC控制全流程仿真实践
1. 从零搭建BLDC控制仿真环境 第一次在Simulink里做BLDC的FOC控制仿真时,我花了整整三天才把环境搭好。不是理论有多难,而是那些隐藏的"坑"太折磨人。咱们先从最基础的软件准备说起。 装Matlab时建议选择R2020b以后的版本,这个时期…...

完整渗透学习路线图|零基础到渗透工程师进阶全攻略,收藏这篇就够了
前言 1/我是如何学习黑客和渗透? 我是如何学习黑客和渗透测试的,在这里,我就把我的学习路线写一下,让新手和小白们不再迷茫,少走弯路,拒绝时间上的浪费! 2/学习常见渗透工具的使用 注意&…...

Speechless:终极微博备份神器,5分钟掌握完整PDF导出指南
Speechless:终极微博备份神器,5分钟掌握完整PDF导出指南 【免费下载链接】Speechless 把新浪微博的内容,导出成 PDF 文件进行备份的 Chrome Extension。 项目地址: https://gitcode.com/gh_mirrors/sp/Speechless 你是否曾担心那些记录…...
入门:从高斯光束到衍射效应的实战解析)
Zemax物理光学传播(POP)入门:从高斯光束到衍射效应的实战解析
Zemax物理光学传播(POP)实战指南:从参数设置到衍射效应分析 在光学设计领域,几何光学和物理光学就像一枚硬币的两面。前者帮助我们快速勾勒出光路的基本轮廓,而后者则揭示了光波传播中那些精妙的波动特性。Zemax作为行业标杆的光学设计软件&a…...

小程序滚动加载优化:提升性能与用户体验的实践指南
1. 为什么需要滚动加载优化? 想象一下你打开一个电商小程序,首页一次性加载了1000件商品。页面卡顿不说,光是等待时间就让人抓狂。这就是典型的数据加载策略失误——**滚动加载(懒加载)**技术正是为解决这类问题而生。…...

如何在 Linux 系统安装 Nginx?附可视化安装与管理教程
很多人在刚接触服务器时,都会遇到一个非常实际的问题:如何在系统安装 Nginx? Nginx 作为目前最常用的 Web 服务软件之一,广泛应用于静态网站部署、反向代理、负载均衡、HTTPS 证书配置以及前后端项目发布。对于运维人员、站长或者…...