kafka3.x详解
kafka
- 一、简介
- 1.1、场景选择,与其他mq相比
- 1.2、应用场景
- 1.2.1、流量消峰
- 1.2.2、解耦
- 1.2.3、异步通讯
- 1.3、消息队列的两种模式
- 1.3.1、点对点模式
- 1.3.2、发布/订阅模式
- 1.4、Kafka 基础架构
- 二、安装部署
- 2.1、安装包方式
- 2.2、docker安装方式
- 2.3、docker安装kafka-map图形化管理工具
- 三、Kafka 命令行操作
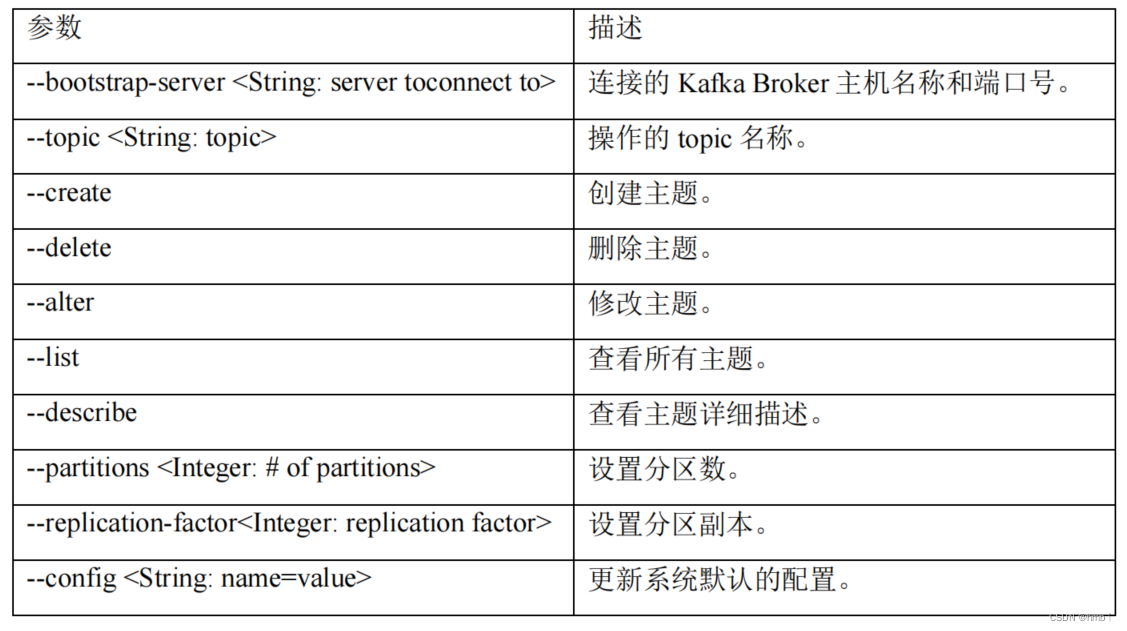
- 3.1、主题命令行操作
- 3.2、生产者命令行操作
- 3.3、消费者命令行操作
- 四、Springboot整合Kafka
- 4.1、依赖配置
- 4.2、代码示例
- 4.2.1、简单的生产、消费
- 4.2.2、指定分区生产、消费
- 4.2.3、消息确认
一、简介
1.1、场景选择,与其他mq相比
1、目前企业中比较常见的消息队列产品主 要有 Kafka、ActiveMQ 、RabbitMQ 、RocketMQ 等。
在大数据场景主要采用 Kafka 作为消息队列。在 JavaEE 开发中主要采用 ActiveMQ、RabbitMQ、RocketMQ。
2、Kafka与其他消息队列MQ(如ActiveMQ、RabbitMQ等)相比,有以下几个区别:
-
磁盘存储:
Kafka将所有消息都保存在磁盘上,并使用内存映射文件进行读写。这种存储方式可以支持大量的消息数据,而且数据还可以保留很长时间,比如几个月甚至几年。而其他MQ的存储方式多是基于内存,不适合存储大量的数据。 -
分布式设计:Kafka是作为分布式系统设计的,可以在多个节点之间实现消息的高效传输和处理。其他MQ也支持分布式部署,但Kafka在这方面更加优秀。
-
发布/订阅模式:Kafka采用发布/订阅模式,允许多个消费者同时订阅同一个主题,而且
Kafka消费者可以自定义从哪个位置开始消费消息。其他MQ中,消费者一般需要通过消费者组来进行负载均衡,而且其他MQ消费者只能从当前位置开始消费。 -
大数据处理:
Kafka最初是为大数据处理而设计的,它可以非常高效地处理海量数据,适合用于数据仓库、日志处理、统计分析等场景。其他MQ则更多用于异步通信、任务调度、实时通知等领域。 -
生态系统:Kafka拥有非常丰富的生态系统,包括Kafka Connect、Kafka Streams等工具和框架,可以方便地与大数据处理平台(如Hadoop、Spark、Flink等)进行集成。其他MQ的生态系统相对较小。
1.2、应用场景
1.2.1、流量消峰
如双十一秒杀期间,参与用户:10亿人/s,但是我们的系统只能支持处理能力:1千万人/s,为了避免服务挂掉或者请求超时等等问题,我们可以将10亿的请求都写入到消息队列中,我们系统再去取消息队列上的消息消费,达到流量消峰的效果。
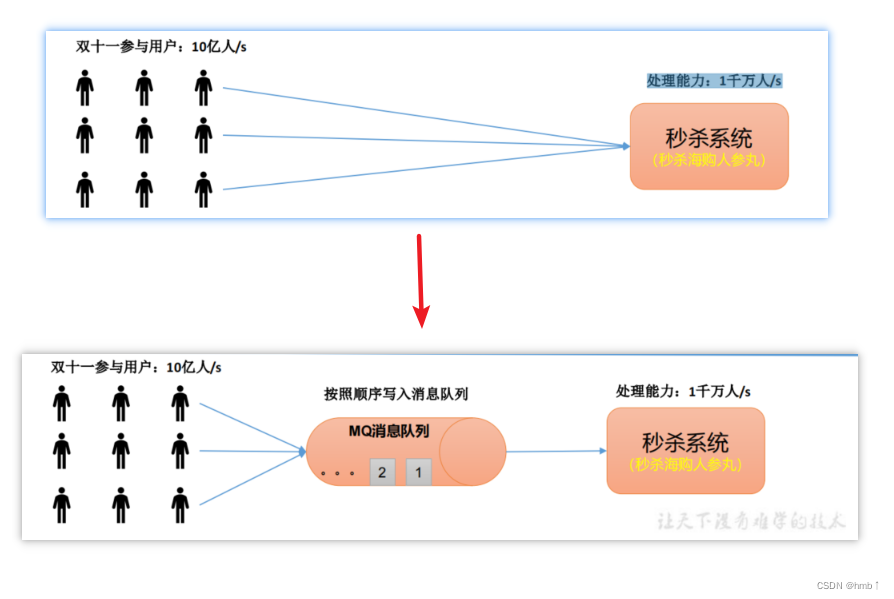
1.2.2、解耦
我们的数据源来源可能非常多,不可能都全部去集成。例如场景:我们要去买东西,不用去知道他是在哪里进货的,我们只需要去超市买就可以,消息队列也是如此,那么多的数据让他们全部写入到kafka消息队列中即可,我们再去消息队列中获取我们的数据。
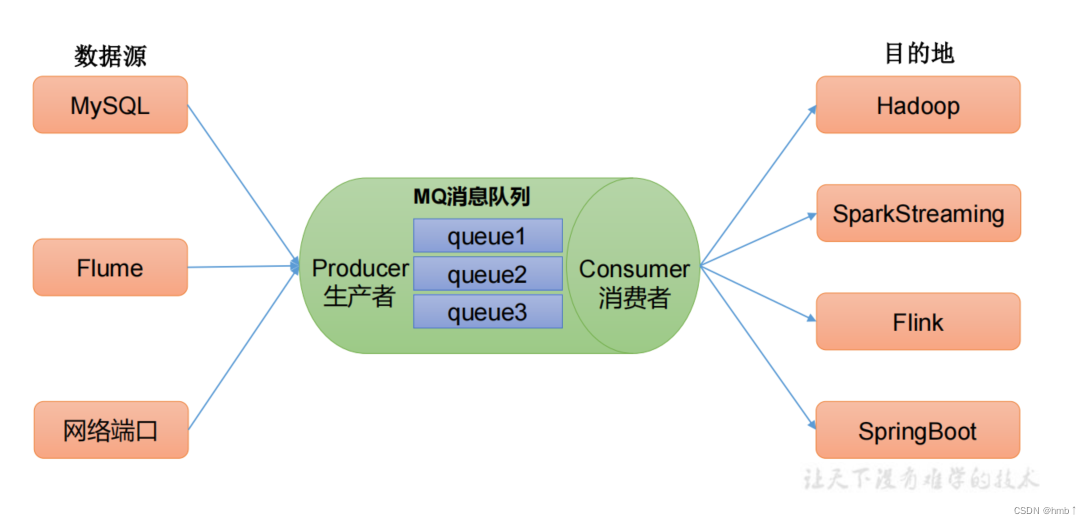
1.2.3、异步通讯
通常我们写代码,如注册完,要发短信,如果同步处理,等到发短信成功后再返回结果给用户,这样请求时间太久了。
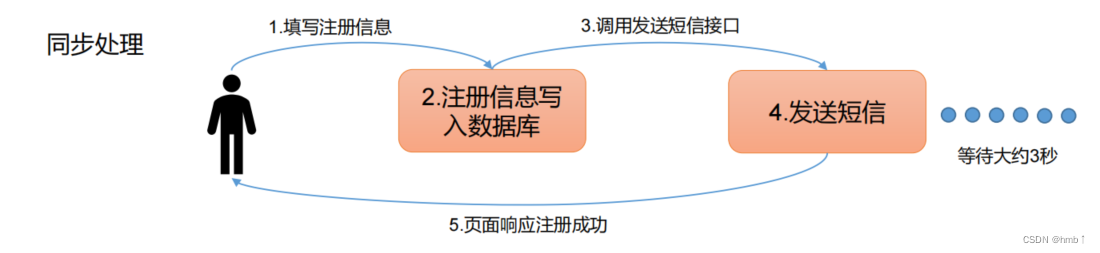
消息队列的方式,可以再注册的时候,发送给队列,我们这时候就可以返回给用户注册成功了,然后消费者再去消费发送短信的队列,达到异步的效果。
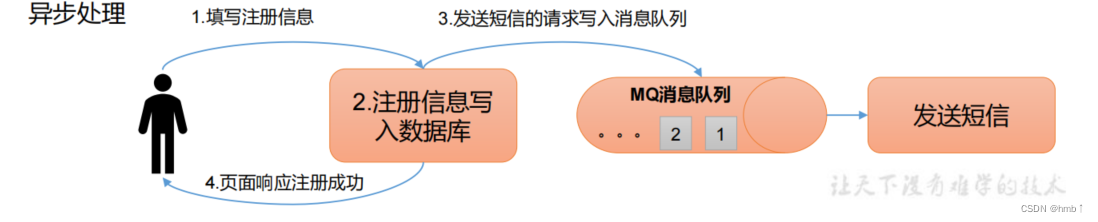
很多人可能会问,多线程的方式不是也能实现?到底选择多线程还是消息队列呢?
-
当需要进行任务处理,并且任务处理之间
没有明显的依赖关系时,使用消息队列更适合。将任务发送到消息队列中,由消费者进行消费,这样可以实现解耦、提高可靠性和系统的扩展性。例如,一个网站需要生成大量的报告,将报告生成请求通过消息队列进行异步处理是一个不错的选择。 -
当需要对任务进行精细控制,并且任务处理之间存在
明显的依赖关系时,使用多线程更适合。多线程可以实现更加细粒度的任务处理,可以控制任务的执行顺序、进行资源的共享等。例如,一个电商网站需要实时监控库存的变化,需要在某个商品的库存下降到一定数量时进行补货,在这种情况下使用多线程处理更加合适。
总之,消息队列和多线程都有自己的优势和劣势,要根据具体的场景选择合适的方式,才能更好地提高系统效率和可靠性。
1.3、消息队列的两种模式
1.3.1、点对点模式
消费者主动拉取数据,消息收到后清除消息

1.3.2、发布/订阅模式
- 可以有多个topic主题(浏览、点赞、收藏、评论等)
- 消费者消费数据之后,不删除数据(可以控制什么时候删除)
- 每个消费者相互独立,都可以消费到数据
这个方式用的多,它可以处理更多复杂的场景。

1.4、Kafka 基础架构
1、海量数据分而置之,为方便扩展,并提高吞吐量,一个topic分为多个partition分区。
如100T的数据,我可以分成3个区,每个区三十几G,可以提高吞吐量。
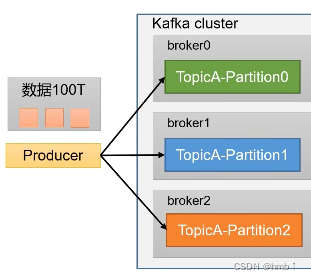
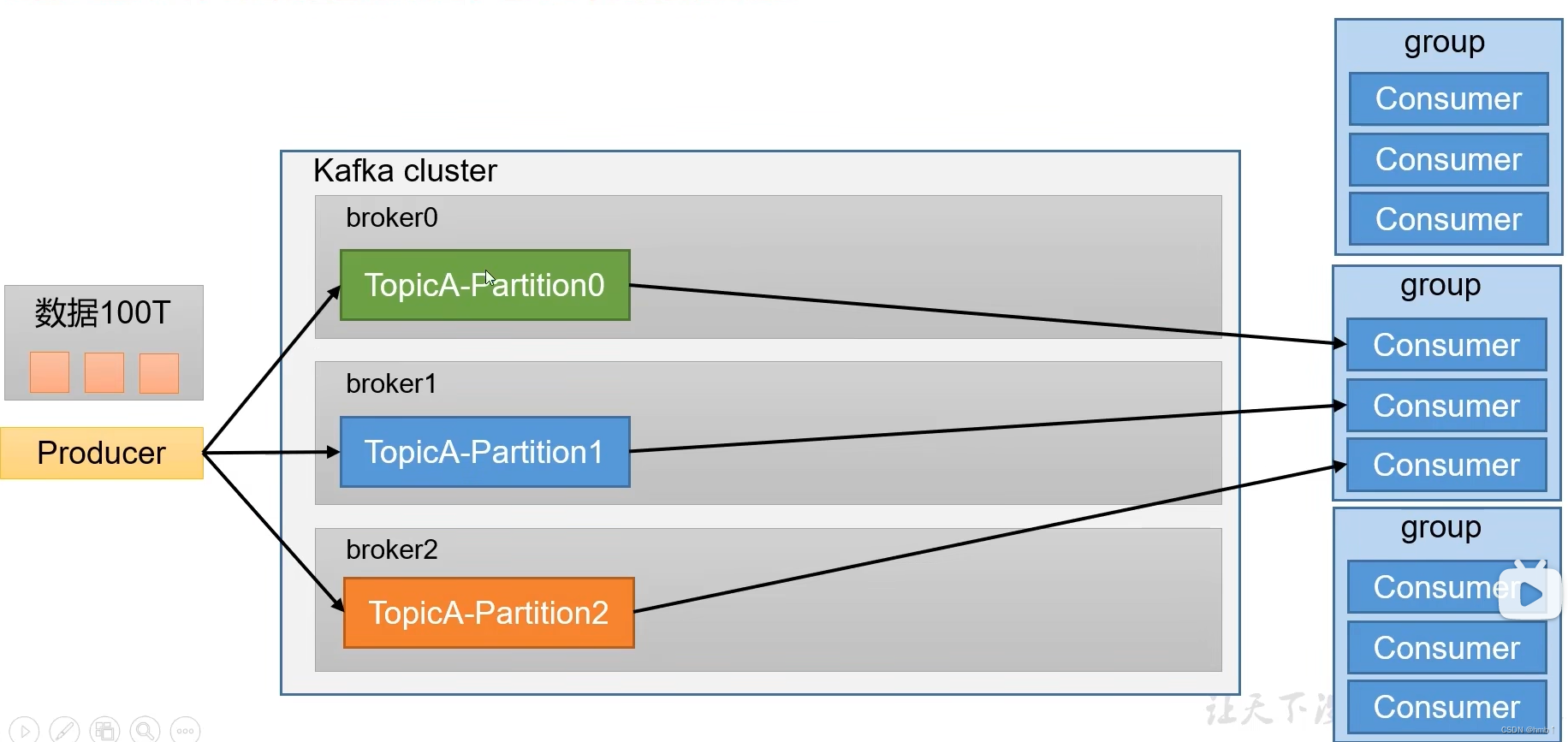
2、配合分区的设计,提出消费者组的概念,组内每个消费者并行消费
一个分区的数据,只能由一个消费者处理,如有两个消费者消费不知道由第一个还是第二个来消费。
 3、为提高可用性,为每个partition增加若干副本,防止一个分区挂了,类似NameNode HA
3、为提高可用性,为每个partition增加若干副本,防止一个分区挂了,类似NameNode HA
副本分为leader和fallower之分,follower不做被消费,只是为了防止leader副本挂了后,follower有条件成为leader,提高可用性。
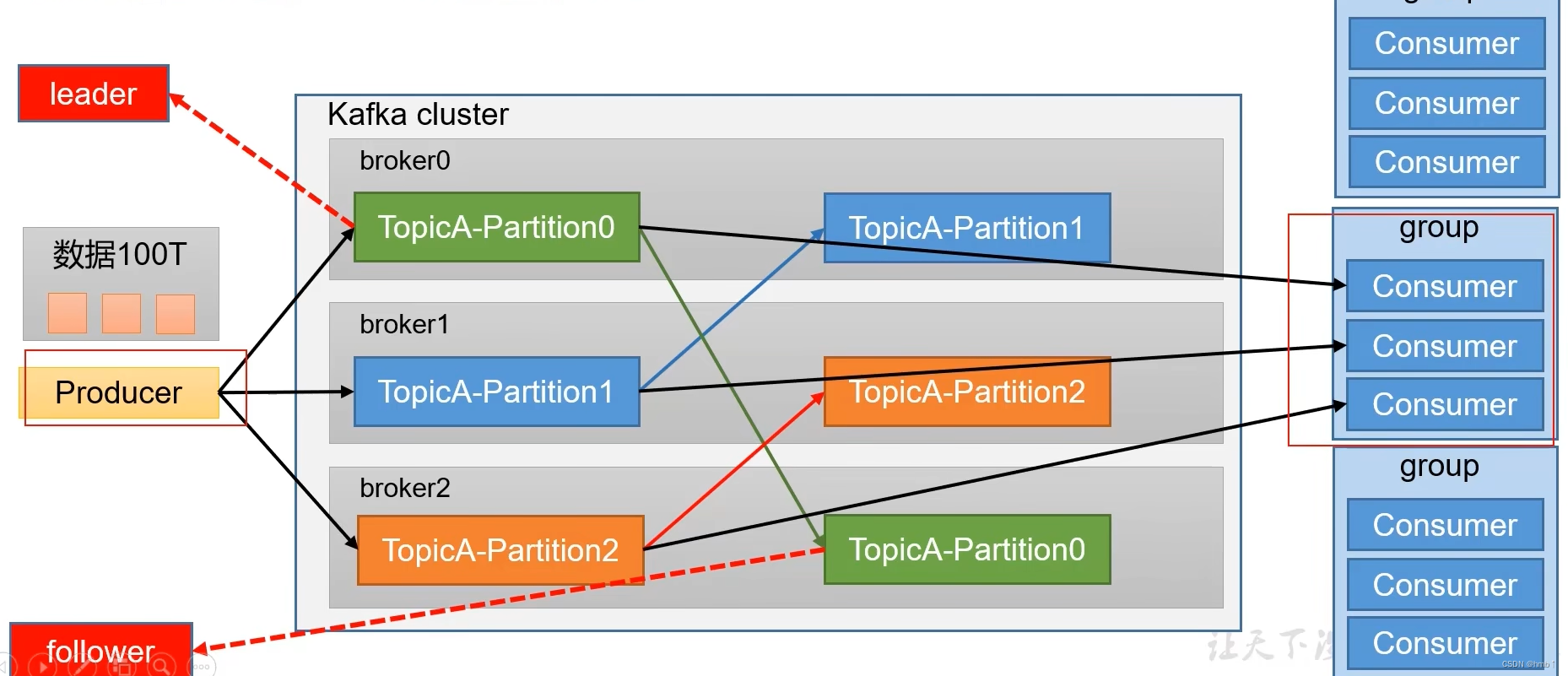
zookeeper中记录谁是leader和整个集群中哪些服务器正在工作,Kafka2.8.0以后也可以配置不采用ZK,安装包已内置ZK

- Producer:消息生产者,就是向 Kafka broker 发消息的客户端。
- Consumer:消息消费者,向 Kafka broker 取消息的客户端。
- Consumer Group(CG):消费者组,由多个 consumer 组成。消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费;消费者组之间互不影响。所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。
- Broker:一台 Kafka 服务器就是一个 broker。一个集群由多个 broker 组成。一个broker 可以容纳多个 topic。
- Topic:可以理解为一个队列,生产者和消费者面向的都是一个 topic。
- Partition:为了实现扩展性,一个非常大的 topic 可以分布到多个 broker(即服务器)上,一个 topic 可以分为多个 partition,每个 partition 是一个有序的队列。
- Replica:副本。一个 topic 的每个分区都有若干个副本,一个 Leader 和若干个Follower。
- Leader:每个分区多个副本的“主”,生产者发送数据的对象,以及消费者消费数据的对象都是 Leader。
- Follower:每个分区多个副本中的“从”,实时从 Leader 中同步数据,保持和Leader 数据的同步。Leader 发生故障时,某个 Follower 会成为新的 Leader。
二、安装部署
2.1、安装包方式
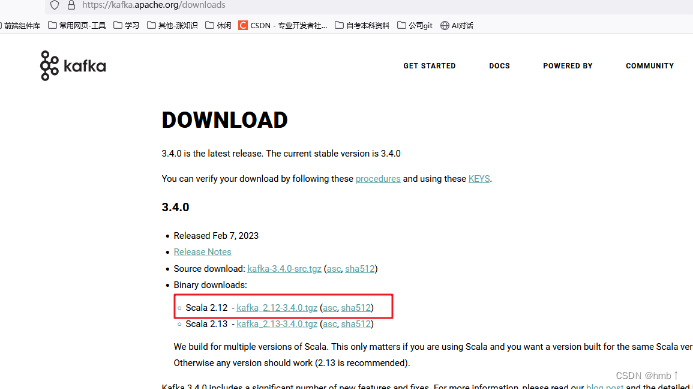
官网下载链接: https://kafka.apache.org/downloads
1、选择你要的版本进行下载
2、将安装包上传服务器,并解压
tar -xzf kafka_2.12-3.4.0.tgz
进入目录
3、修改config目录下的server.properties配置文件
vim server.properties
修改log.dirs的路径,这个是kafka存储数据的地方,默认放在了临时文件夹里,容易被删除,我们需改成我们服务器可以存放的目录,如我放在home底下

放开注释,修改地址成你的ip


4、修改kafka的环境变量
#编辑配置文件
vi /etc/profile# KAFKA_HOME
export KAFKA_HOME=kafka根目录
export PATH=$PATH:$KAFKA_HOME/bin#例如笔者的文件路径
export KAFKA_HOME=/www/wwwroot/kafka_2.12-3.4.0/
export PATH=$PATH:$KAFKA_HOME/bin# 添加配置后重新加载配置文件
source /etc/profile
5、配置config下的zookeeper配置,同样也只是修改存储路径
vim zookeeper.properties将dataDir修改成你自己存储路径,如我的dataDir=/home/zookeeper
还有下面的advertised放开注释,更换ip,zookeeper连接也更换ip

6、启动,需先启动zookeeper
注意:要先有java环境
# 启动zookeeper,直接指定到你们自己的bin和config目录
nohup /www/wwwroot/kafka_2.12-3.4.0/bin/zookeeper-server-start.sh -daemon /www/wwwroot/kafka_2.12-3.4.0/config/zookeeper.properties# 启动kafka
nohup /www/wwwroot/kafka_2.12-3.4.0/bin/kafka-server-start.sh -daemon /www/wwwroot/kafka_2.12-3.4.0/config/server.properties
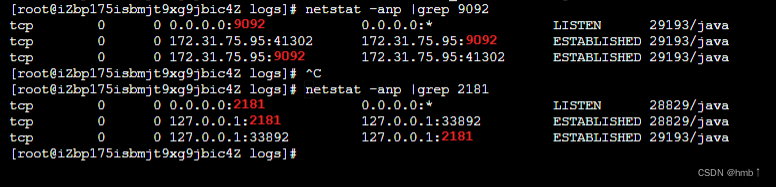
7、验证是否启动成功,查看端口是有被用,或者看日志文件
2.2、docker安装方式
1、docker 安装zookeeper
# 安装镜像
docker pull wurstmeister/zookeeper#启动容器
docker run -d --name zookeeper_server --restart always -p 2181:2181 wurstmeister/zookeeper# 查看端口是否启动成功
netstat -anp |grep 2181
2、docker 安装 kafka
# 安装镜像
docker pull wurstmeister/kafka#启动容器
docker run -d --name kafka_server --restart always -p 9092:9092 -e KAFKA_BROKER_ID=0 -e KAFKA_ZOOKEEPER_CONNECT=<这里换成你的zookeeper地址和端口> -e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://<这里换成你的kafka地址和端口> -e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092 wurstmeister/kafka-----------------------------------------------
# 发送消息与消费测试
docker exec -it kafka_server /bin/bash# 进入bin,注意你的版本号可能与我的不同
cd /opt/kafka_2.13-2.8.1/bin/# 发送消息
./kafka-console-producer.sh --broker-list 127.0.0.1:9092 --topic test# 另起窗口,进入容器
kafka-console-consumer.sh --bootstrap-server 127.0.0.1:9092 --topic test --from-beginning
启动参数解释:
KAFKA_BROKER_ID:该ID是集群的唯一标识
KAFKA_ADVERTISED_LISTENERS:kafka发布到zookeeper供客户端使用的服务地址。
KAFKA_ZOOKEEPER_CONNECT:zk的连接地址
KAFKA_LISTENERS:允许使用PLAINTEXT侦听器
如图:发送和接收都成功


2.3、docker安装kafka-map图形化管理工具
# 拉取镜像
docker pull dushixiang/kafka-map# 启动容器
docker run -d --name kafka-map -p 9080:8080 --restart always -v /home/kafka-map/data:/usr/local/kafka-map/data -e DEFAULT_USERNAME=admin -e DEFAULT_PASSWORD=admin --restart always dushixiang/kafka-map:latest
开发端口,访问界面http://ip:9080 账号密码都是设置的admin
图形化工具教程:
1、新建一个连接,连接你的kafka
 2、点击topic
2、点击topic
 3、进入topic,可以看到需要消费的信息与实时发送的消息
3、进入topic,可以看到需要消费的信息与实时发送的消息
 4、下拉消息
4、下拉消息
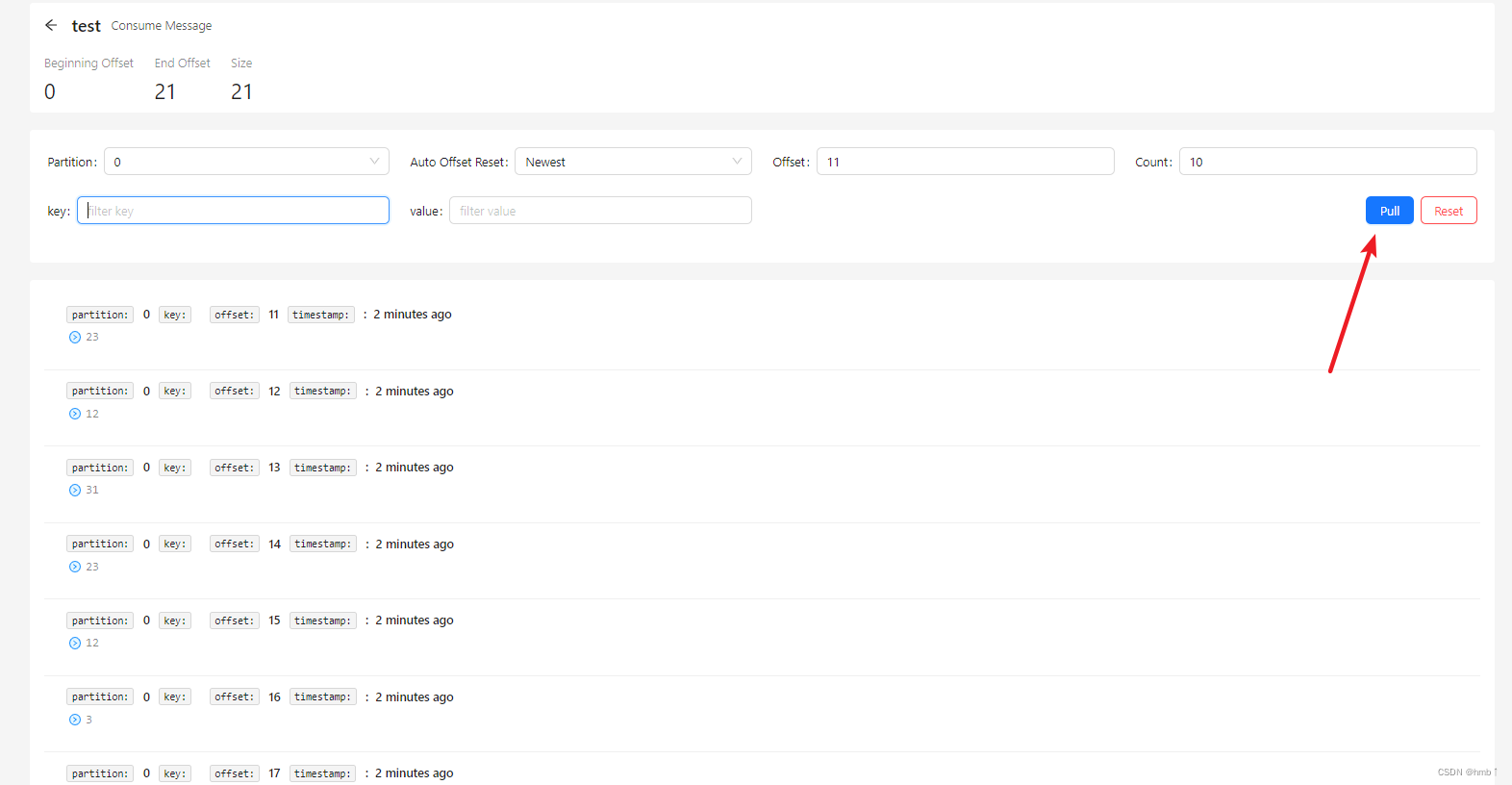
三、Kafka 命令行操作
3.1、主题命令行操作
进入kafka目录,如果是docker安装的,进入容器内的opt/kafka_版本号目录下
1)、查看操作主题命令参数
bin/kafka-topics.sh
 topic的命名都是有规律的,按上面的提示,固定前缀 bin/kafka-topics.sh --bootstrap-server ip:9092 加上面的提示,如下
topic的命名都是有规律的,按上面的提示,固定前缀 bin/kafka-topics.sh --bootstrap-server ip:9092 加上面的提示,如下
2)、查看当前服务器中的所有 topic
bin/kafka-topics.sh --bootstrap-server ip:9092 --list
3)、创建 topic 主题,topic名:first
bin/kafka-topics.sh --bootstrap-server localhost:9092 --create --partitions 1 --replication-factor 1 --topic first
4)、查看 first 主题的详情
bin/kafka-topics.sh --bootstrap-server localhost:9092 --describe --topic first
5)、修改分区数(注意:分区数只能增加,不能减少)
bin/kafka-topics.sh --bootstrap-server localhost:9092 --alter --topic first --partitions 3
6)、删除 topic
bin/kafka-topics.sh --bootstrap-server localhost:9092 --delete --topic first
3.2、生产者命令行操作
1)、查看操作生产者命令参数
bin/kafka-console-producer.sh

2)、发送消息(发送到topic为first)
bin/kafka-console-producer.sh --bootstrap-server localhost:9092 --topic first
3.3、消费者命令行操作
1)、查看操作消费者命令参数
bin/kafka-console-consumer.sh
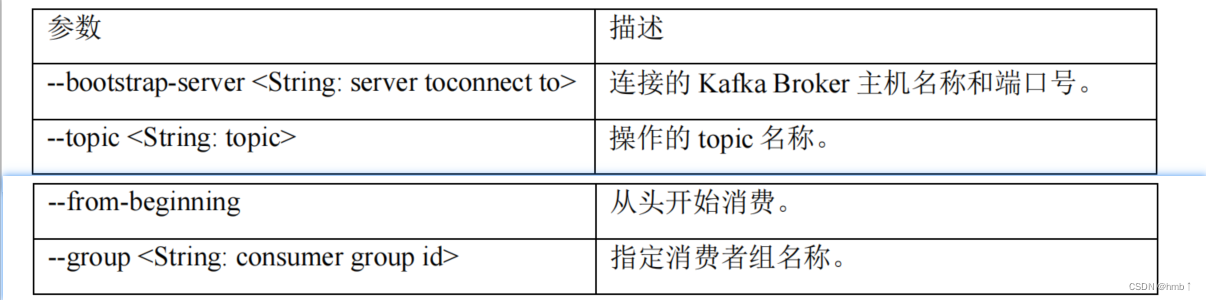
2)、消费消息(监听topic为first的)
只消费新的:
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic first
把主题中所有的数据都读取出来(包括历史数据):
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --from-beginning --topic first
四、Springboot整合Kafka
4.1、依赖配置
pom依赖
<dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka</artifactId></dependency>
yml配置
spring:# ======================== ↓↓↓↓↓↓ kafka相关配置 ↓↓↓↓↓↓ ===============================kafka:bootstrap-servers: ip:9092 # 指定kafka server地址,集群(多个逗号分隔)producer:# 指定消息key和消息体的编解码方式key-serializer: org.apache.kafka.common.serialization.StringSerializervalue-serializer: org.apache.kafka.common.serialization.StringSerializer# 写入失败时,重试次数。当leader节点失效,一个repli节点会替代成为leader节点,此时可能出现写入失败,# 当retris为0时,produce不会重复。retirs重发,此时repli节点完全成为leader节点,不会产生消息丢失。retries: 0# 每次批量发送消息的数量,produce积累到一定数据,一次发送batch-size: 16384# produce积累数据一次发送,缓存大小达到buffer.memory就发送数据buffer-memory: 33554432consumer:group-id: default_consumer_group # 指定默认消费者 群组IDenable-auto-commit: true # true自动提交auto-commit-interval: 1000# procedure要求leader在考虑完成请求之前收到的确认数,用于控制发送记录在服务端的持久化,其值可以为如下:# acks = 0 如果设置为零,则生产者将不会等待来自服务器的任何确认,该记录将立即添加到套接字缓冲区并视为已发送。在这种情况下,无法保证服务器已收到记录,并且重试配置将不会生效(因为客户端通常不会知道任何故障),为每条记录返回的偏移量始终设置为-1。# acks = 1 这意味着leader会将记录写入其本地日志,但无需等待所有副本服务器的完全确认即可做出回应,在这种情况下,如果leader在确认记录后立即失败,但在将数据复制到所有的副本服务器之前,则记录将会丢失。# acks = all 这意味着leader将等待完整的同步副本集以确认记录,这保证了只要至少一个同步副本服务器仍然存活,记录就不会丢失,这是最强有力的保证,这相当于acks = -1的设置。# 可以设置的值为:all, -1, 0, 1acks: 1# 指定消息key和消息体的编解码方式key-deserializer: org.apache.kafka.common.serialization.StringDeserializervalue-deserializer: org.apache.kafka.common.serialization.StringDeserializer
4.2、代码示例
4.2.1、简单的生产、消费
生产者
@RestController
public class Producer {@Resourceprivate KafkaTemplate kafkaTemplate;/*** 最简单的发送* @param msg*/@GetMapping("/test")public void test(String msg){kafkaTemplate.send("two", msg);}
消费者
/*** 消费监听 自动提交* 监听所有的分区* @param record*/@KafkaListener(topics = "two")public void listen(ConsumerRecord<?, ?> record) {log.info("topic: " + record.topic() + " <|============|> 消息内容:" + record.value());System.out.println("topic: " + record.topic() + " <|============|> 消息内容:" + record.value());}
4.2.2、指定分区生产、消费
在 Kafka 中,生产者可以指定消息的分区和键(Key)属性。指定分区和键属性可以带来以下好处:
- 控制消息的分发
通过指定分区,生产者可以控制消息被发送到哪个分区,从而控制消息的分发。例如,如果您想要按照时间戳对消息进行排序,可以将消息发送到同一个分区中。
- 提高消息的局部性
Kafka 会将同一个分区中的消息存储在同一个 Broker 上,这可以提高消息的局部性,从而提高消息的处理效率。
- 提高消息的可靠性
通过指定键属性,生产者可以确保具有相同键的消息被发送到同一个分区中。这可以确保消息按照顺序被处理,从而提高消息的可靠性。
生产者
/*** 指定分区发送* @param msg*/
@GetMapping("/test3")
public void test3(String msg){/*** 参数1:topic* 参数2:分区* 参数3:key* 参数4:消息内容*/// 有keykafkaTemplate.send("two",0,"111", msg+"0分区");kafkaTemplate.send("two",1,"222", msg+"1分区");// 没有keykafkaTemplate.send("two",2,null, msg+"2分区");// 发送另一个topic消费者测试用kafkaTemplate.send("first",0,"111", msg+"first");
}
消费者
/*** @Title 指定topic、partition、offset消费* @Description 同时监听two和first,监听two的0号和1号分区、first的 "0号和1号" 分区,指向1号分区的offset初始值为8**/@KafkaListener(topicPartitions = {@TopicPartition(topic = "two", partitions = { "0","1" }),@TopicPartition(topic = "first", partitions = "0", partitionOffsets = @PartitionOffset(partition = "1", initialOffset = "8"))})public void onMessage2(ConsumerRecord<?, ?> record) {System.out.println("topic:"+record.topic()+"|partition:"+record.partition()+"|offset:"+record.offset()+"|value:"+record.value());}// ↓↓↓↓↓↓↓说明示例↓↓↓↓↓↓↓↓↓// 如果没指定分区,就算你生产者发送了多个分区,我也全都能接收//@KafkaListener(topics = "two")//public void listen(ConsumerRecord<?, ?> record) {//log.info("topic: " + record.topic() + " <|============|> 消息内容:" + record.value());//System.out.println("topic: " + record.topic() + " <|============|> 消息内容:" + record.value());//}

4.2.3、消息确认
修改手动确认配置
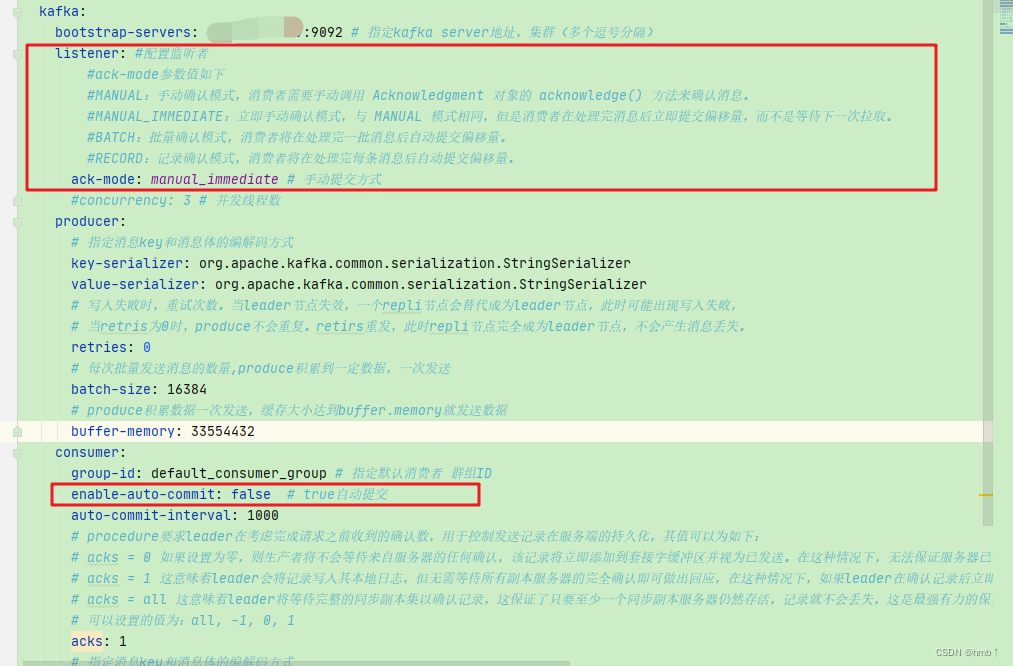
spring:# ======================== ↓↓↓↓↓↓ kafka相关配置 ↓↓↓↓↓↓ ===============================kafka:bootstrap-servers: 你的ip:9092 # 指定kafka server地址,集群(多个逗号分隔)listener: #配置监听者#ack-mode参数值如下#MANUAL:手动确认模式,消费者需要手动调用 Acknowledgment 对象的 acknowledge() 方法来确认消息。#MANUAL_IMMEDIATE:立即手动确认模式,与 MANUAL 模式相同,但是消费者在处理完消息后立即提交偏移量,而不是等待下一次拉取。#BATCH:批量确认模式,消费者将在处理完一批消息后自动提交偏移量。#RECORD:记录确认模式,消费者将在处理完每条消息后自动提交偏移量。ack-mode: manual # 手动提交方式#concurrency: 3 # 并发线程数producer:# 指定消息key和消息体的编解码方式key-serializer: org.apache.kafka.common.serialization.StringSerializervalue-serializer: org.apache.kafka.common.serialization.StringSerializer# 写入失败时,重试次数。当leader节点失效,一个repli节点会替代成为leader节点,此时可能出现写入失败,# 当retris为0时,produce不会重复。retirs重发,此时repli节点完全成为leader节点,不会产生消息丢失。retries: 0# 每次批量发送消息的数量,produce积累到一定数据,一次发送batch-size: 16384# produce积累数据一次发送,缓存大小达到buffer.memory就发送数据buffer-memory: 33554432consumer:group-id: default_consumer_group # 指定默认消费者 群组IDenable-auto-commit: false # true自动提交auto-commit-interval: 1000# procedure要求leader在考虑完成请求之前收到的确认数,用于控制发送记录在服务端的持久化,其值可以为如下:# acks = 0 如果设置为零,则生产者将不会等待来自服务器的任何确认,该记录将立即添加到套接字缓冲区并视为已发送。在这种情况下,无法保证服务器已收到记录,并且重试配置将不会生效(因为客户端通常不会知道任何故障),为每条记录返回的偏移量始终设置为-1。# acks = 1 这意味着leader会将记录写入其本地日志,但无需等待所有副本服务器的完全确认即可做出回应,在这种情况下,如果leader在确认记录后立即失败,但在将数据复制到所有的副本服务器之前,则记录将会丢失。# acks = all 这意味着leader将等待完整的同步副本集以确认记录,这保证了只要至少一个同步副本服务器仍然存活,记录就不会丢失,这是最强有力的保证,这相当于acks = -1的设置。# 可以设置的值为:all, -1, 0, 1acks: 1# 指定消息key和消息体的编解码方式key-deserializer: org.apache.kafka.common.serialization.StringDeserializervalue-deserializer: org.apache.kafka.common.serialization.StringDeserializer
生产者
/*** kafkaTemplate提供了一个回调方法addCallback,我们可以在回调方法中监控消息是否发送成功 或 失败时做补偿处理* @param msg*/
@GetMapping("test1")
public void test1( String msg) {kafkaTemplate.send("three", msg).addCallback(new ListenableFutureCallback<SendResult<String, Object>>() {@Overridepublic void onFailure(Throwable ex) {System.out.println("发送消息失败:"+ex.getMessage());}@Overridepublic void onSuccess(SendResult<String, Object> result) {System.out.println("发送消息成功:" + result.getRecordMetadata().topic() + "-"+ result.getRecordMetadata().partition() + "-" + result.getRecordMetadata().offset());}});
}
消费者
/*** 手动提交方式,需改配置为手动模式,需修改配置* 监听所有的分区* @param record* @param ack*/
@KafkaListener(topics = "three")
public void listen(ConsumerRecord<?, ?> record, Acknowledgment ack) {try {log.info("topic: " + record.topic() + " <|============|> 消息内容:" + record.value());System.out.println("topic: " + record.topic() + " <|============|> 消息内容:" + record.value());exception(); // 假设出现异常,没有走下面的提交//手动提交offsetack.acknowledge();} catch (Exception e) {e.printStackTrace();}
}private void exception() {throw new RuntimeException("异常了");
}
消费者异常了后,消息没有被确认,我们重启项目时,会再次出现那条未确认的消息
相关文章:
kafka3.x详解
kafka 一、简介1.1、场景选择,与其他mq相比1.2、应用场景1.2.1、流量消峰1.2.2、解耦1.2.3、异步通讯 1.3、消息队列的两种模式1.3.1、点对点模式1.3.2、发布/订阅模式 1.4、Kafka 基础架构 二、安装部署2.1、安装包方式2.2、docker安装方式2.3、docker安装kafka-ma…...

kubectl常用命令|pod生命周期|金丝雀发布|超详细
kubectl常用命令|pod生命周期|金丝雀发布|超详细 一 kubectl常用命令1.1 查看版本信息1.2查看资源对象简写1.3查看集群信息1.4 配置kubectl自动补全1.5node节点查看日志 二 k8s基本信息查看2.1 查看 master 节点状态2.2 查看命令空间2.3 创建和删除命名空间2.4 在命名空间kube-…...

【Linux系统】Linux进程信号详解
Linux进程信号 0 引言1 认识信号1.1 什么是信号1.2 发送信号的本质1.3 信号的处理 2 信号的产生2.1 键盘产生2.2 调用系统函数向进程发送信号2.3 由软件条件产生信号2.4 硬件异常产生信号 3 信号的保存4 信号的处理5 总结 0 引言 本篇文章会从Linux信号的产生到信号的保存&…...

阿里云u1服务器通用算力型CPU处理器性能测评
阿里云服务器u1通用算力型Universal实例高性价比,CPU采用Intel(R) Xeon(R) Platinum,主频是2.5 GHz,云服务器U1实例的基准vCPU算力与5代企业级实例持平,最高vCPU算力与6代企业级实例持平,提供2c-32c规格和1:1/2/4/8丰富…...

hive的详细使用文档和使用案例
目录 Hive 简介安装连接到Hive创建数据库创建表加载数据查询数据修改表删除表 使用案例结论 Hive 简介 Hive是一个基于Hadoop的数据仓库工具,可以将结构化数据映射到Hadoop HDFS上,并提供SQL查询功能。Hive的设计目标是让那些熟悉SQL语言的用户能够在Ha…...

KL散度
KL散度(Kullback-Leibler divergence),也称为相对熵(relative entropy),是用来衡量两个概率分布之间差异的一种指标。在机器学习中,KL散度常常用于度量两个概率分布之间的相似度或差异性。 具体…...

Java基础学习(16)多线程
Java基础学习多线程 一、多线程1.1 什么是多线程1.2 多线程的两个概念1.2.1 并发 1.3 多线程的实现方式1.4 多线程的成员方法1.5 线程的生命周期 二、线程安全1.6 同步方法1.7 锁lock1.8 死锁1.8 生产者和消费者 (等待唤醒机制)1.9 等待唤醒机制(阻塞队列方式实现)1…...

【一起啃书】《机器学习》第五章 神经网络
文章目录 第五章 神经网络5.1 神经元模型5.2 感知机与多层网络5.3 误差逆传播算法5.4 全局最小与局部极小5.5 其他常见神经网络5.6 深度学习 第五章 神经网络 5.1 神经元模型 神经网络是由具有适应性简单单元组成的广泛并行互连的网络,它的组织能够模拟生物神经系统…...
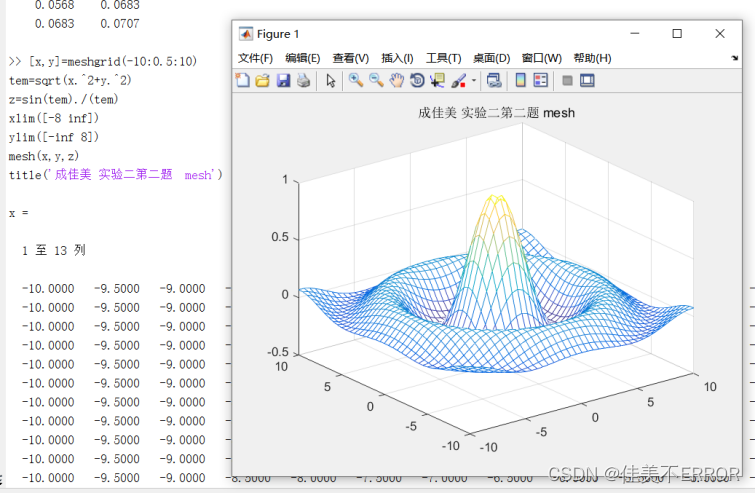
matlab实验二可视化
学聪明点,自己改,别把我卖了 一、实验目的及要求 要求 1、掌握 MATLAB常用的二维和三维绘图函数 2、掌握MATLAB的图形注释 3、熟悉MATLAB常用的图形修饰 4、熟悉MATLAB的图形动画 实验原理 1、MATLAB二维绘图:plot,fplot,fimplicit…...
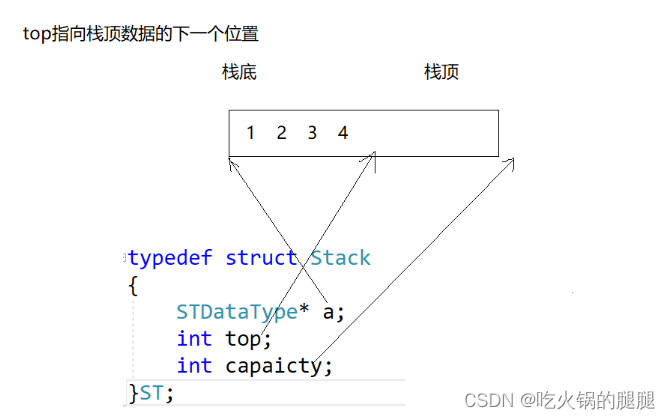
(数据结构)栈的实现——再一次保姆级教学
目录 1. 栈 编辑 1.2 栈的实现 2. 代码的实现 2.1 初始化栈和销毁栈 2.2栈顶元素的插入 2.3栈顶元素的删除 栈元素删除 2.4栈顶元素的获取和栈元素的个数 1. 栈 1.1 栈的概念和结构 栈(Stack)是一种线性存储结构,它具有如下特点: ࿰…...

【5G RRC】RSRP、RSRQ以及SINR含义、计算过程详细介绍
博主未授权任何人或组织机构转载博主任何原创文章,感谢各位对原创的支持! 博主链接 本人就职于国际知名终端厂商,负责modem芯片研发。 在5G早期负责终端数据业务层、核心网相关的开发工作,目前牵头6G算力网络技术标准研究。 博客…...

K8s(Kubernetes)学习(一):k8s概念及组件
Kubernetes中文文档:https://kubernetes.io/zh-cn/docs/home/ Kubernetes源码地址:https://github.com/kubernetes/kubernetes 一:Kubernetes是什么 首先要了解应用程序部署经历了以下几个时代: 传统部署时代:在物理服务器上运…...

Web3 常用语和黑话你知道吗?
My friend Dave used to be a bagholder, but he FOMO’d and bought even more BTC. Now, he’s a big whale HODLing for that moon. …that’s a lot to take in for just two sentences. If you’re new to Bitcoin and the world of cryptocurrencies, we understand if …...

物联网和边缘计算:如何将数据处理和决策推向设备边缘
第一章:引言 当我们谈论物联网(IoT)时,我们通常指的是将各种设备连接到互联网,并通过数据交换来实现智能化的网络。然而,传统的物联网模型通常涉及将数据发送到云端进行处理和分析。然而,随着技…...
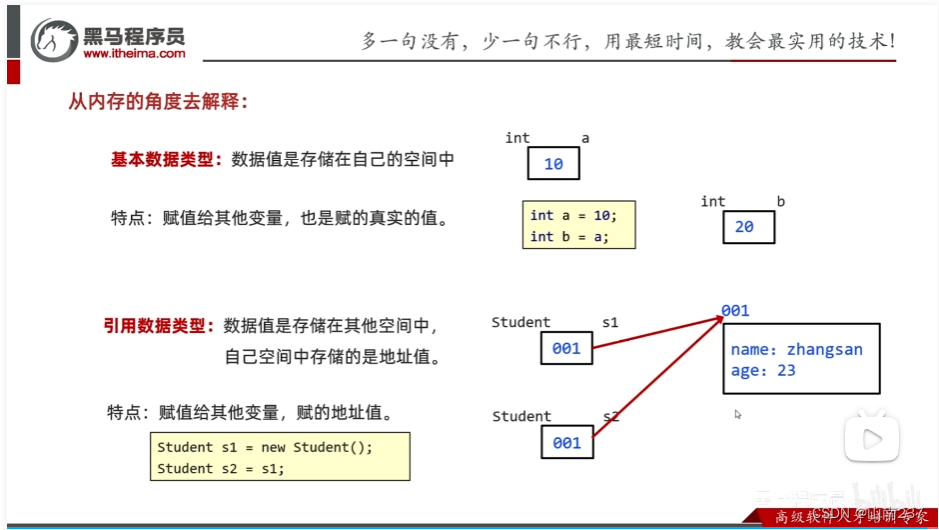
【Android学习专题】java基本语法和概念(学习记录)
学习记录来自菜鸟教程 Java 变量 Java 中主要有如下几种类型的变量 局部变量 在方法、构造方法或者语句块中定义的变量被称为局部变量。变量声明和初始化都是在方法中,方法结束后,变量就会自动销毁类变量(静态变量) 类变量也声…...
Android系统启动全流程分析
当我们买了一个手机或者平板,按下电源键的那一刻,到进入Launcher,选择我们想要使用的某个App进入,这个过程中,系统到底在做了什么事,伙伴们有仔细的研究过吗?可能对于Framework这块晦涩难懂的专…...
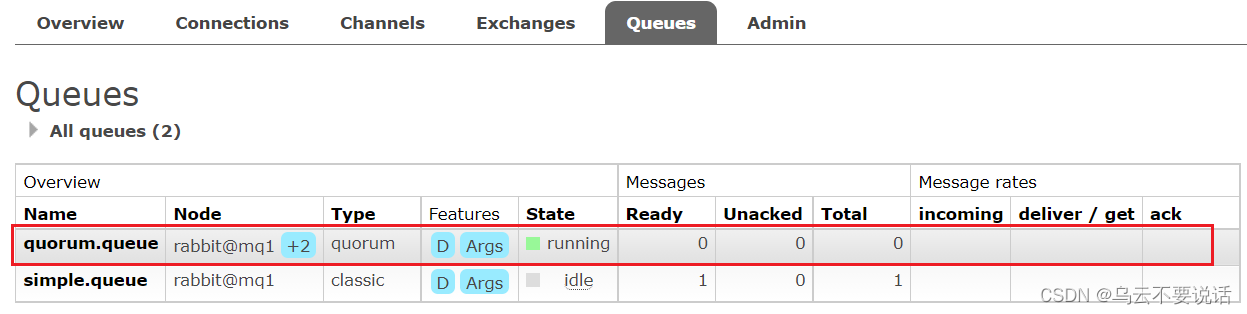
RabbitMQ --- 惰性队列、MQ集群
一、惰性队列 1.1、消息堆积问题 当生产者发送消息的速度超过了消费者处理消息的速度,就会导致队列中的消息堆积,直到队列存储消息达到上限。之后发送的消息就会成为死信,可能会被丢弃,这就是消息堆积问题。 解决消息堆积有三种…...

1.Buffer_Overflow-1.Basic_Jump
github上面的练习题 git clone https://github.com/Adamkadaban/LearnPwn 然后开始做 先进行 readelf 然后进行执行看看 是怎么回事 ./buf1发现就是一个输入和输出 我们checksec看看 发现stack 保护关闭 开启了NX保护 我们进入ida64看看反汇编 我习惯先看看字符串 SHITF…...

MySQL入门语法第三课:表结构的创建
数据表结构 定点数类型decimal(m,d) m表示数字总位数 d表示小数位数 ★创建数据表先要选择数据库 1 . CREATE TABLE 表名称 创建数据表 (字段名1 数据类型1 [,字段名2 数据名2] [, .....] ); 一个字段写一行 修改表名 alter table 旧表名 rename 新表名…...
SpringSecurity框架学习与使用
SpringSecurity框架学习与使用 SpringSecurity学习SpringSecurity入门SpringSecurity深入认证授权自定义授权失败页面权限注解SecuredPreAuthorizePostAuthorizePostFilterPreFilter 参考 SpringSecurity学习 SpringSecurity入门 引入相关的依赖,SpringBoot的版本…...

虚幻引擎Pico大空间VR实战:从原点校准到性能调优的完整避坑指南
1. 大空间VR原点校准:从理论到实战 第一次用Pico设备做大空间VR开发时,最让我头疼的就是原点校准问题。记得有个项目调试时,玩家戴上头显瞬间就"穿墙"了——因为现实世界的东南方向被错误识别为VR场景的正北。这种基础设置错误会导…...

LLaMA Factory数据集配置避坑指南:为什么你的自定义数据集总加载不出来?
LLaMA Factory数据集配置避坑指南:为什么你的自定义数据集总加载不出来? 第一次尝试在LLaMA Factory中使用自定义数据集时,那种反复修改配置却始终看不到数据集出现在下拉列表中的挫败感,相信很多开发者都深有体会。明明文件路径看…...

如何完整解锁Cursor Pro功能:一键激活与无限使用的终极指南
如何完整解锁Cursor Pro功能:一键激活与无限使用的终极指南 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached you…...

从零到一:在Ubuntu 22.04上构建Autoware.universe开发环境与实战演练
1. 环境准备:Ubuntu 22.04基础配置 在开始构建Autoware.universe开发环境之前,我们需要确保Ubuntu系统的基础环境已经正确配置。我建议使用全新安装的Ubuntu 22.04 LTS系统,这样可以避免很多潜在的依赖冲突问题。实测下来,8核CPU8…...

告别抖动与失步!用AccelStepper库为ESP32-S3步进电机实现丝滑梯形加减速
告别抖动与失步!用AccelStepper库为ESP32-S3步进电机实现丝滑梯形加减速 在3D打印机、CNC雕刻机或机器人关节控制项目中,步进电机的运动平稳性直接决定最终成品的质量。许多开发者在使用ESP32-S3驱动步进电机时,常会遇到启动时的机械抖动、高…...
)
Python新手必看:5分钟搞定BMI计算器(附完整代码及format函数详解)
Python新手实战:从零构建BMI计算器与字符串格式化深度解析 在编程学习的起步阶段,能够快速实现一个看得见、用得着的小工具,往往比学习抽象概念更能激发持续学习的动力。BMI(身体质量指数)计算器就是一个绝佳的练手项目…...

云原生实践总结
云原生实践数字化转型的核心引擎 在数字化转型浪潮中,云原生技术凭借其敏捷性、弹性和可扩展性,成为企业构建现代化应用的核心选择。云原生不仅是一种技术架构,更是一种方法论,涵盖容器化、微服务、DevOps、服务网格等关键技术。…...

【AI写代码】怎么用AI写代码
1、思路 先找到后端应该的脚本,让AI给编写对应的接口规范手册2、拖动接口规范手册,让AI给编写对应的接口测试用例 根据XXX接口规范手册,编写pytest框架的自动化测试用例...

TPFanCtrl2终极指南:ThinkPad风扇控制完全手册,打造静音高效的散热系统
TPFanCtrl2终极指南:ThinkPad风扇控制完全手册,打造静音高效的散热系统 【免费下载链接】TPFanCtrl2 ThinkPad Fan Control 2 (Dual Fan) for Windows 10 and 11 项目地址: https://gitcode.com/gh_mirrors/tp/TPFanCtrl2 作为ThinkPad用户&#…...

如何免费获得专业级Windows音效?Equalizer APO系统级均衡器终极指南
如何免费获得专业级Windows音效?Equalizer APO系统级均衡器终极指南 【免费下载链接】equalizerapo Equalizer APO mirror 项目地址: https://gitcode.com/gh_mirrors/eq/equalizerapo 你是否厌倦了每个音频应用都需要单独设置音效?是否希望游戏、…...