《斯坦福数据挖掘教程·第三版》读书笔记(英文版) Chapter 2 MapReduce and the New Software Stack
来源:《斯坦福数据挖掘教程·第三版》对应的公开英文书和PPT
Chapter 2 MapReduce and the New Software Stack
Computing cluster means large collections of commodity hardware, including conventional processors (“compute nodes”) connected by Ethernet cables or inexpensive switches.
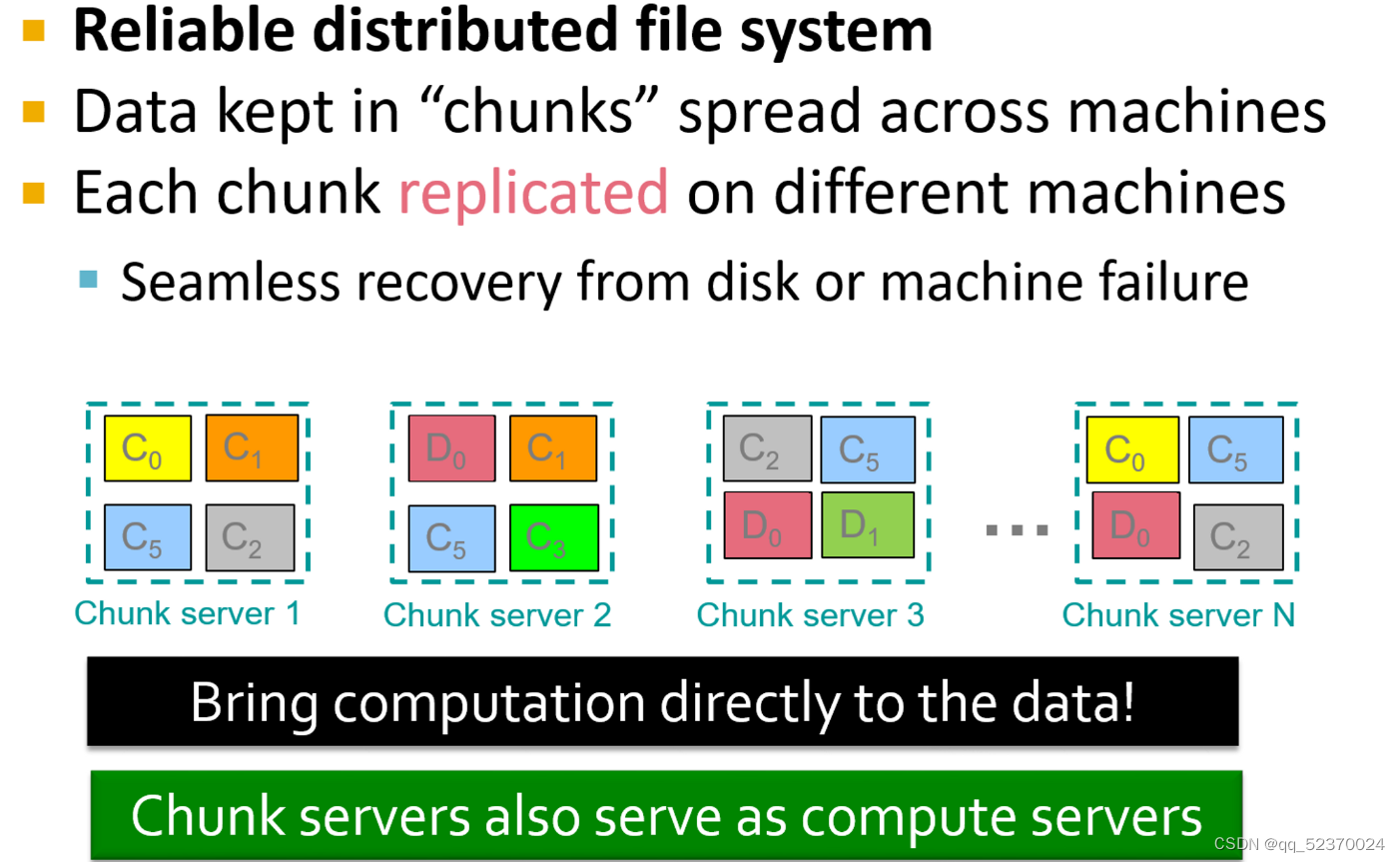
The software stack begins with a new form of file system, called a “distributed file system,” which features much larger units than the disk blocks in a conventional operating system. Distributed file systems also provide replication of data or redundancy to protect against the frequent media failures that occur when data is distributed over thousands of low-cost compute nodes.
Compute nodes are stored on racks, perhaps 8–64 on a rack. The nodes on a single rack are connected by a network, typically gigabit Ethernet. There can be many racks of compute nodes, and racks are connected by another level of network or a switch. The bandwidth of inter-rack communication is somewhat greater than the inter-rack Ethernet, but given the number of pairs of nodes that might need to communicate between racks, this bandwidth may be essential.
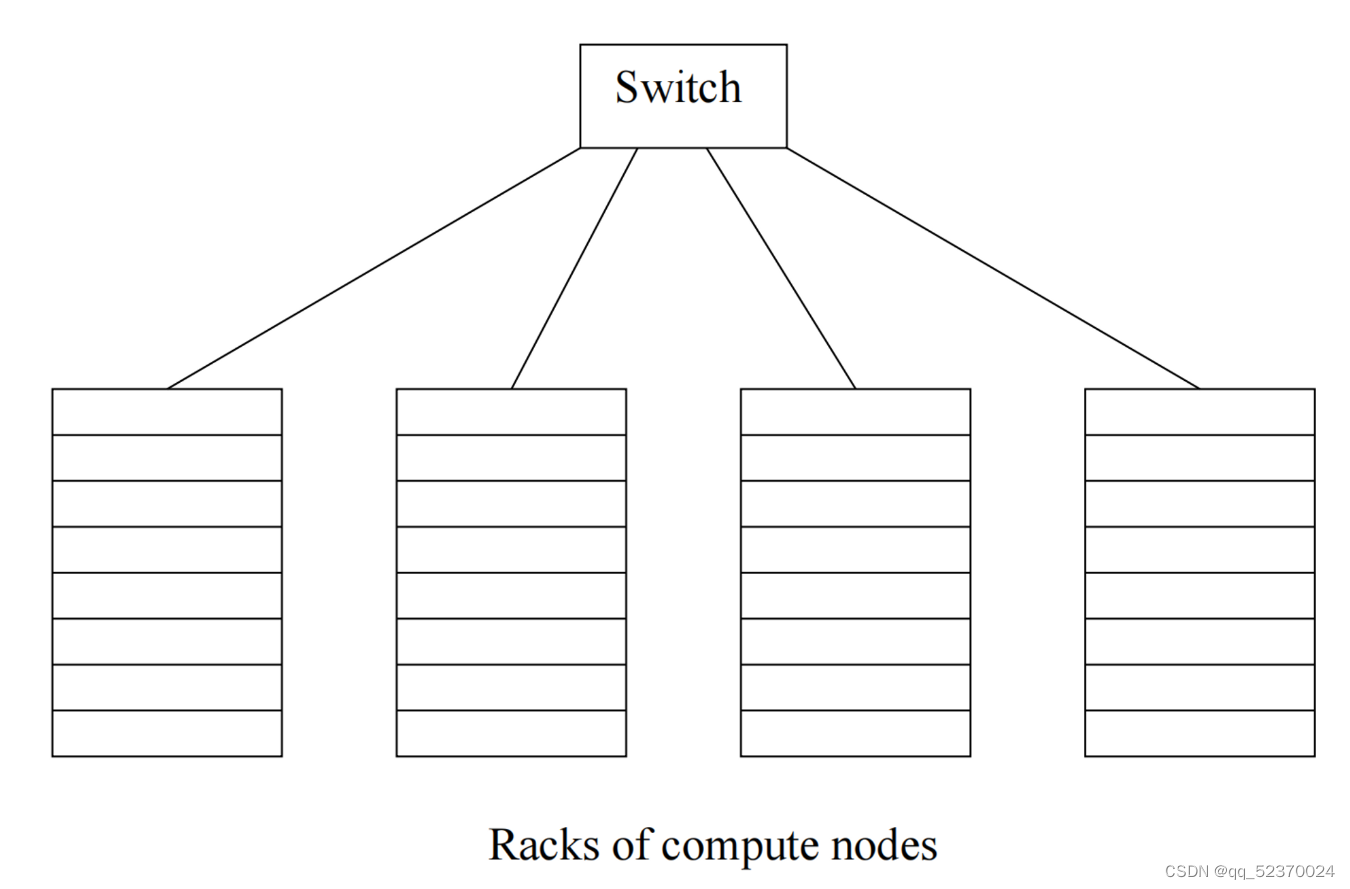
Some important calculations take minutes or even hours on thousands of compute nodes. If we had to abort and restart the computation every time one component failed, then the computation might never complete successfully.
The solution to this problem takes two forms:
- Files must be stored redundantly. If we did not duplicate the file at several compute nodes, then if one node failed, all its files would be unavailable until the node is replaced. If we did not back up the files at all, and the disk crashes, the files would be lost forever.
- Computations must be divided into tasks, such that if any one task fails to execute to completion, it can be restarted without affecting other tasks. This strategy is followed by the MapReduce programming system.


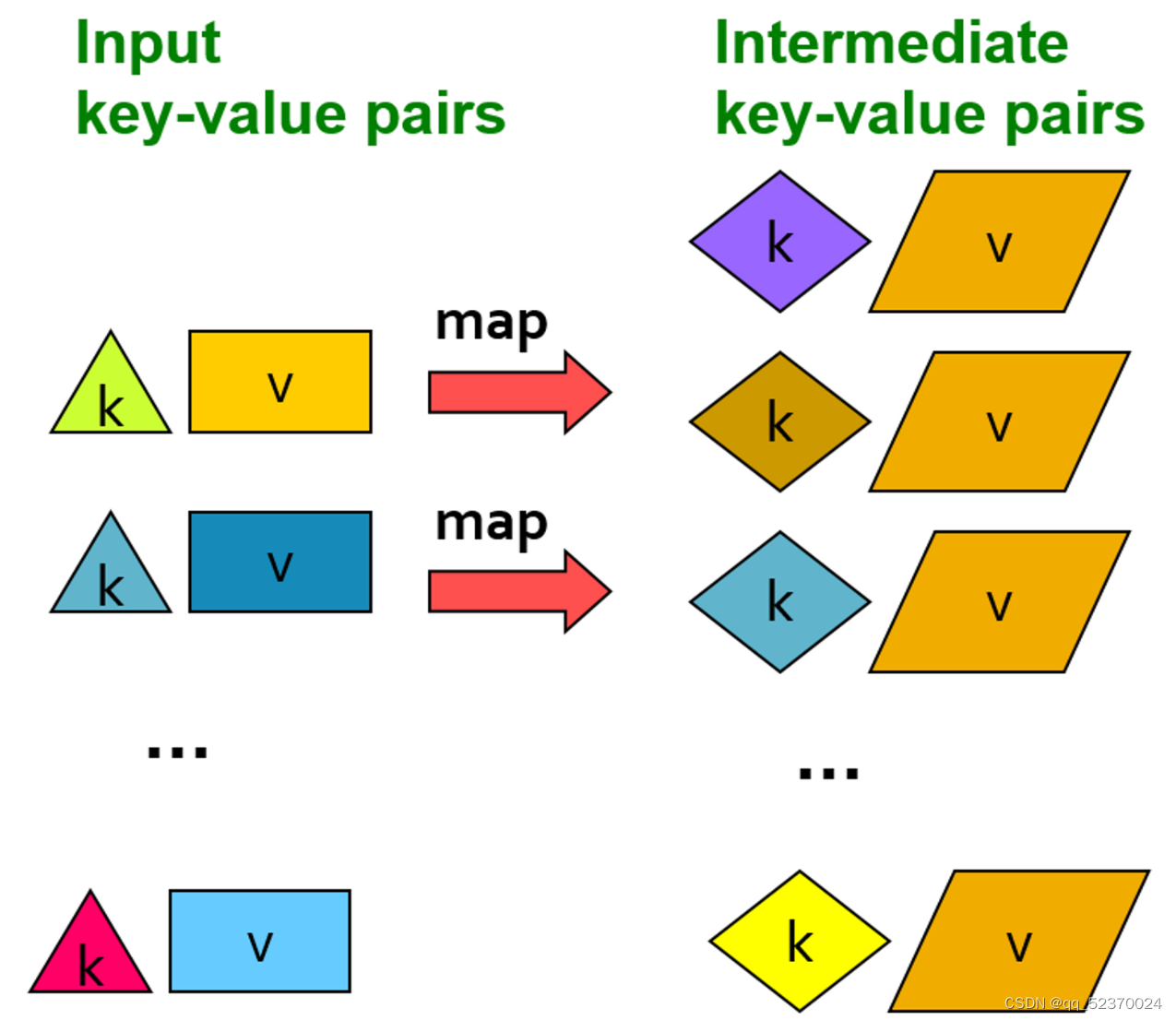
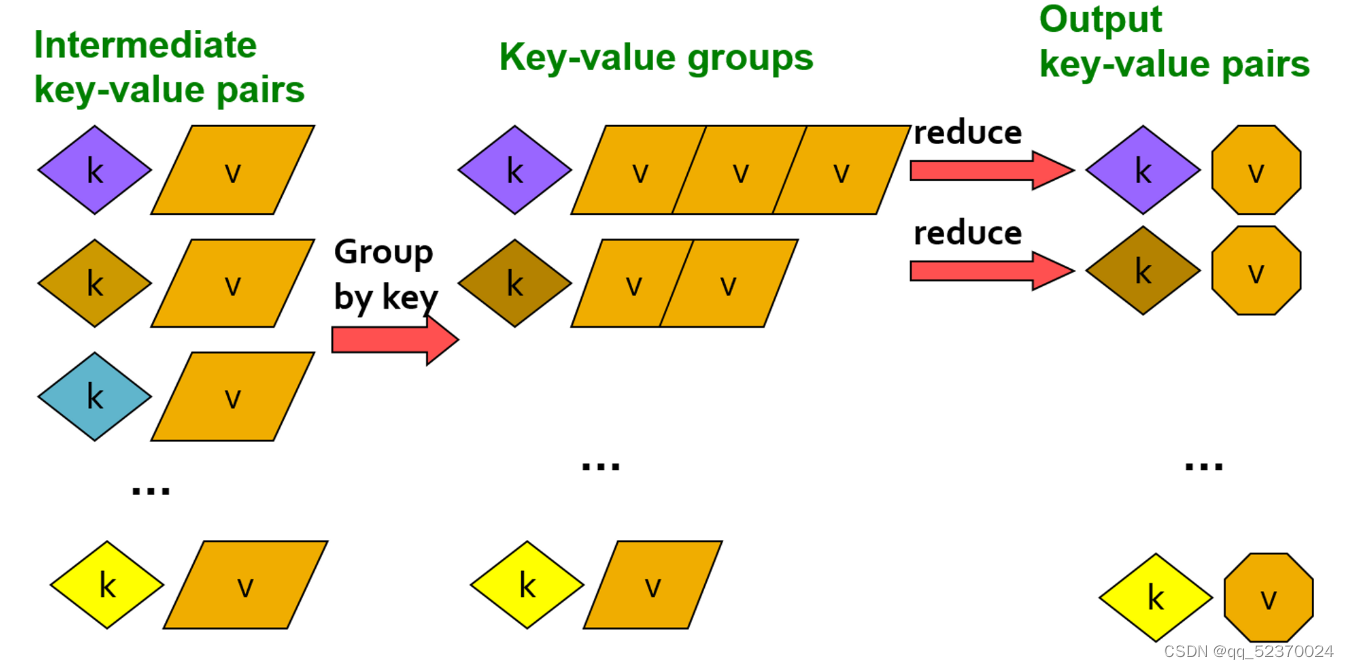

Summary of Chapter 2
- Cluster Computing: A common architecture for very large-scale applications is a cluster of compute nodes (processor chip, main memory, and disk). Compute nodes are mounted in racks, and the nodes on a rack are connected, typically by gigabit Ethernet. Racks are also connected by a high-speed network or switch.
- Distributed File Systems: An architecture for very large-scale file systems has developed recently. Files are composed of chunks of about 64 megabytes, and each chunk is replicated several times, on different compute nodes or racks.
- MapReduce: This programming system allows one to exploit parallelism inherent in cluster computing, and manages the hardware failures that can occur during a long computation on many nodes. Many Map tasks and many Reduce tasks are managed by a Master process. Tasks on a failed compute node are rerun by the Master.
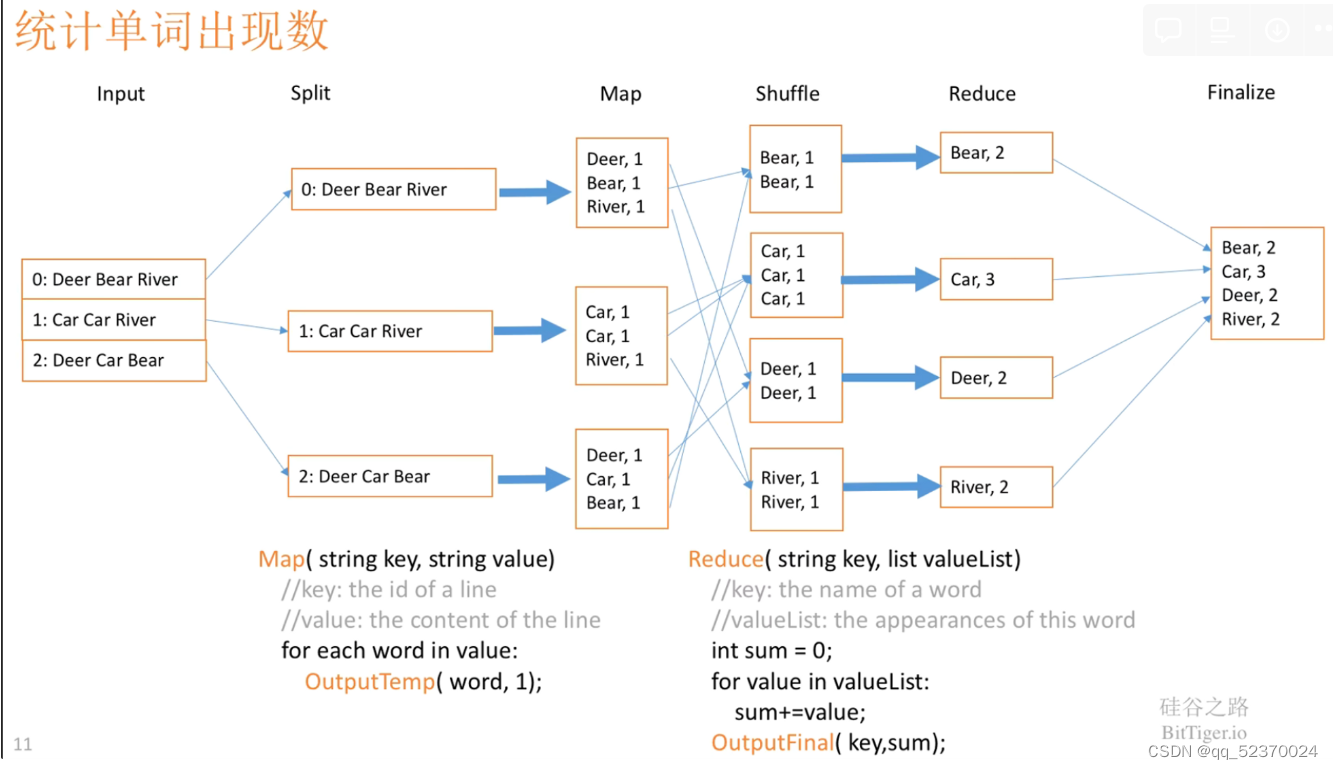
- The Map Function: This function is written by the user. It takes a collection of input objects and turns each into zero or more key-value pairs. Keys are not necessarily unique.
- The Reduce Function: A MapReduce programming system sorts all the key-value pairs produced by all the Map tasks, forms all the values associated with a given key into a list and distributes key-list pairs to Reduce tasks. Each Reduce task combines the elements on each list, by applying the function written by the user. The results produced by all the Reduce tasks form the output of the MapReduce process.
- Reducers: It is often convenient to refer to the application of the Reduce function to a single key and its associated value list as a “reducer.”
- Hadoop: This programming system is an open-source implementation of a distributed file system (HDFS, the Hadoop Distributed File System) and MapReduce (Hadoop itself). It is available through the Apache Foundation.
- Managing Compute-Node Failures: MapReduce systems support restart of tasks that fail because their compute node, or the rack containing that node, fail. Because Map and Reduce tasks deliver their output only after they finish (the blocking property), it is possible to restart a failed task without concern for possible repetition of the effects of that task. It is necessary to restart the entire job only if the node at which the Master
executes fails. - Applications of MapReduce: While not all parallel algorithms are suitable for implementation in the MapReduce framework, there are simple implementations of matrix-vector and matrix-matrix multiplication. Also, the principal operators of relational algebra are easily implemented in MapReduce.
- Workflow Systems: MapReduce has been generalized to systems that support any acyclic collection of functions, each of which can be instantiated by any number of tasks, each responsible for executing that function on a portion of the data.
- Spark: This popular workflow system introduces Resilient, Distributed Datasets (RDD’s) and a language in which many common operations on RDD’s can be written. Spark has a number of efficiencies, including lazy evaluation of RDD’s to avoid secondary storage of intermediate results and the recording of lineage for RDD’s so they can be reconstructed as needed.
- TensorFlow: This workflow system is specifically designed to support machine-learning. Data is represented as multidimensional arrays, or tensors, and built-in operations perform many powerful operations, such as linear algebra and model training.
- Recursive Workflows: When implementing a recursive collection of functions, it is not always possible to preserve the ability to restart any failed task, because recursive tasks may have produced output that was consumed by another task before the failure. A number of schemes for checkpointing parts of the computation to allow restart of single tasks, or restart all tasks from a recent point, have been proposed.
- Communication-Cost: Many applications of MapReduce or similar systems do very simple things for each task. Then, the dominant cost is usually the cost of transporting data from where it is created to where it is used. In these cases, efficiency of a MapReduce algorithm can be estimated by calculating the sum of the sizes of the inputs to all the tasks.
- Multiway Joins: It is sometimes more efficient to replicate tuples of the relations involved in a join and have the join of three or more relations computed as a single MapReduce job. The technique of Lagrangean multipliers can be used to optimize the degree of replication for each of the participating relations.
- Star Joins: Analytic queries often involve a very large fact table joined with smaller dimension tables. These joins can always be done efficiently by the multiway-join technique. An alternative is to distribute the fact table and replicate the dimension tables permanently, using the same strategy as would be used if we were taking the multiway join of the fact table and every dimension table.
- Replication Rate and Reducer Size: It is often convenient to measure communication by the replication rate, which is the communication per input. Also, the reducer size is the maximum number of inputs associated with any reducer. For many problems, it is possible to derive a lower bound on replication rate as a function of the reducer size.
- Representing Problems as Graphs: It is possible to represent many problems that are amenable to MapReduce computation by a graph in which nodes represent inputs and outputs. An output is connected to all the inputs that are needed to compute that output.
- Mapping Schemas: Given the graph of a problem, and given a reducer size, a mapping schema is an assignment of the inputs to one or more reducers so that no reducer is assigned more inputs than the reducer size permits, and yet for every output there is some reducer that gets all the inputs needed to compute that output. The requirement that there be a mapping schema for any MapReduce algorithm is a good expression of what makes MapReduce algorithms different from general parallel computations.
- Matrix Multiplication by MapReduce: There is a family of one-pass MapReduce algorithms that performs multiplication of n × n matrices with the minimum possible replication rate r = 2 n 2 q r =\frac {2n^2}q r=q2n2, where q is the reducer size. On the other hand, a two-pass MapReduce algorithm for the same problem with the same reducer size can use up to a factor of n less communication.
END
相关文章:
《斯坦福数据挖掘教程·第三版》读书笔记(英文版) Chapter 2 MapReduce and the New Software Stack
来源:《斯坦福数据挖掘教程第三版》对应的公开英文书和PPT Chapter 2 MapReduce and the New Software Stack Computing cluster means large collections of commodity hardware, including conventional processors (“compute nodes”) connected by Ethernet …...

HTML零基础快速入门(详细教程)
1,HTML代码特点 <html><head></head><body>hello world!</body> </html>HTML代码有以下特点: html代码是通过标签来组织的,而标签是由尖括号< >组织的,也可被叫作元素(ele…...

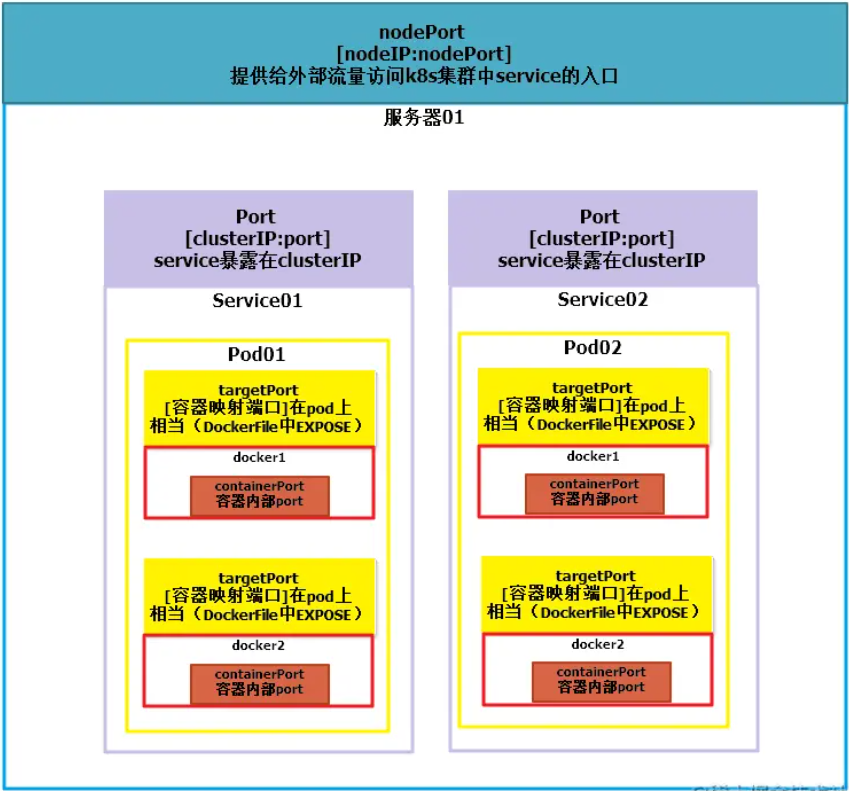
Kubernetes第5天
第七章 Service详解 本章节主要介绍kubernetes的流量负载组件:Service和Ingress。 Service介绍 在kubernetes中,pod是应用程序的载体,我们可以通过pod的ip来访问应用程序,但是pod的ip地址不是固定的,这也就意味着…...
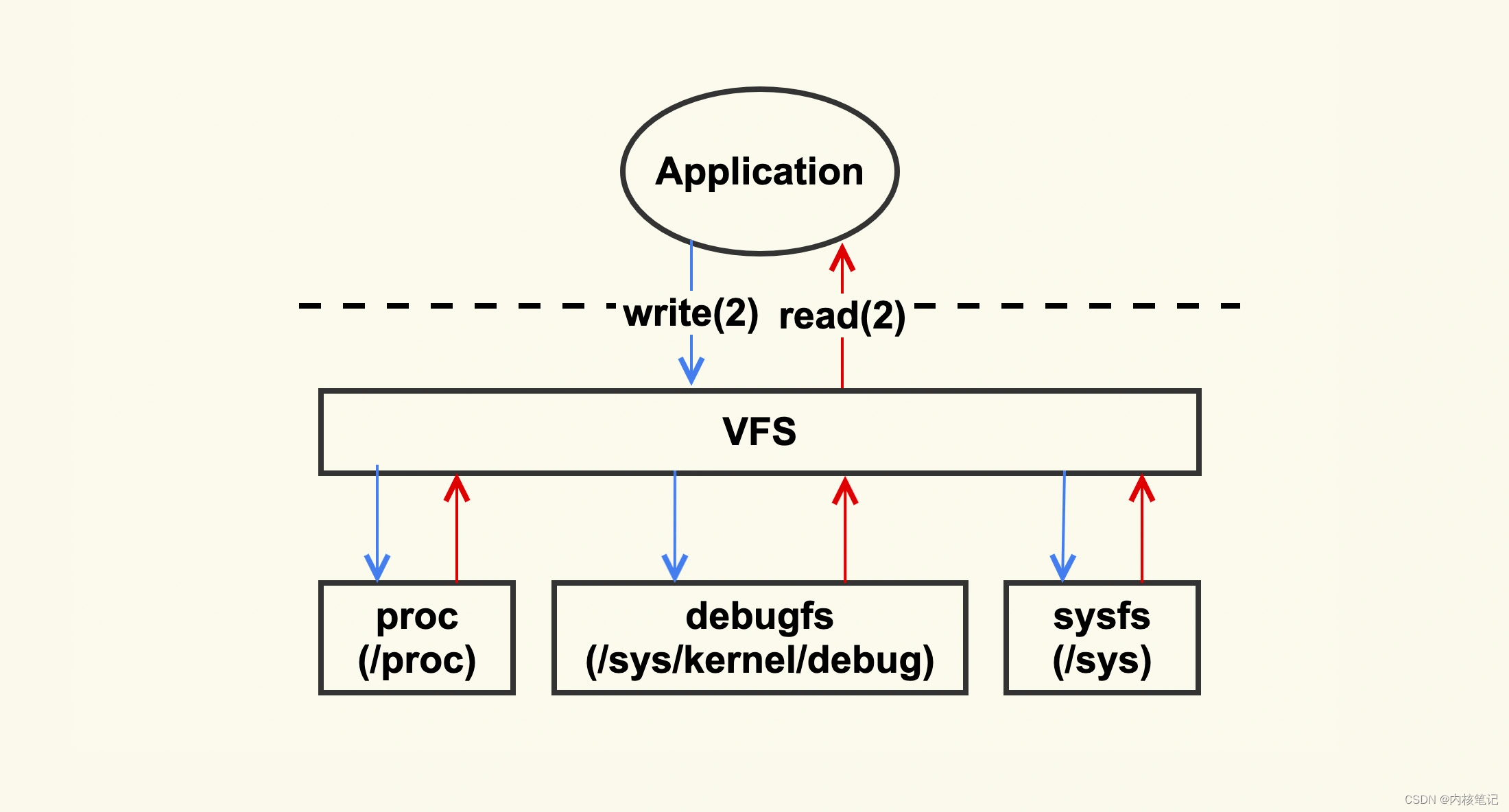
RK3568平台开发系列讲解(调试篇)debugfs 分析手段
🚀返回专栏总目录 文章目录 一、enable debugfs二、debugfs API三、使用示例沉淀、分享、成长,让自己和他人都能有所收获!😄 📢Linux 上有一些典型的问题分析手段,从这些基本的分析方法入手,你可以一步步判断出问题根因。这些分析手段,可以简单地归纳为下图: 从这…...
【Spring框架全系列】SpringBoot配置日志文件
🍧🍧哈喽,大家好,我是小浪。那么上篇博客我们学习了SpringBoot配置文件的相关操作,本篇博客我们将学习一个新的知识点,SpringBoot日志文件。🖥🖥 📲目录 一、日志是什么…...
事务 ---MySQL的总结(六)
事务 多进程进行并改变同一个数据,如果没有进行版本控制,就会出现数据不确定的问题,为此引入了事务的概念。可以进行数据回滚,解决潜在的问题。 事务的概念 一组的DML组成,这一些的DML要么同时成功,要么同…...

22 标准模板库STL之容器适配器
概述 提到适配器,我们的第一印象是想到设计模式中的适配器模式:将一个类的接口转化为另一个类的接口,使原本不兼容而不能合作的两个类,可以一起工作。STL中的容器适配器与此类似,是一个封装了序列容器的类模板,它在一般序列容器的基础上提供了一些不同的功能和接口。之所…...

目标检测YOLO实战应用案例100讲-基于深度学习的自动驾驶目标检测算法研究
目录 基于深度学习的自动驾驶目标检测算法研究 相关理论基础 2.1 卷积神经网络基本原理...
服务网关Gateway
前言 API 网关出现的原因是微服务架构的出现,不同的微服务一般会有不同的网络地址,而外部客户端可能需要调用多个服务的接口才能完成一个业务需求,如果让客户端直接与各个微服务通信,会有以下的问题: 破坏了服务无状态…...
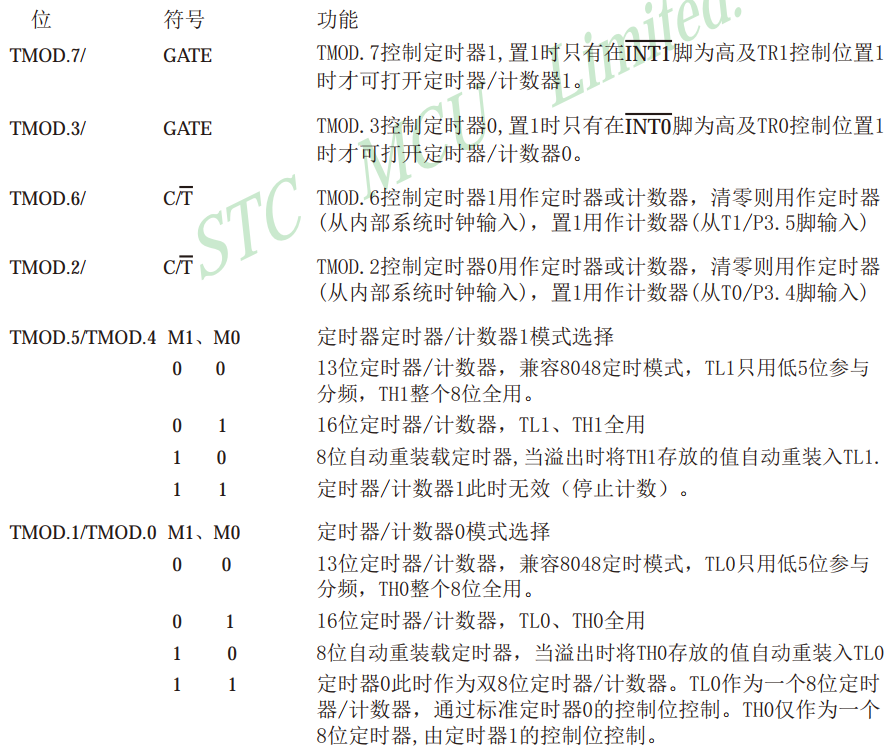
(4)定时器
51单片机的定时器属于单片机的内部资源,其电路的连接和运转均在单片机内部完成 作用: 用于计时系统替代长时间Delay,提高运行效率和速度任务切换 STC89C52定时器资源: 定时器个数:3个(T0,T1,T2…...

项目实现读写分离操作(mysql)
读写分离 1.问题说明 2.读写分离 Master(主库)----(数据同步)—> Slave(从库) Mysql主从复制 mysql主从复制 介绍 mysql主从复制是一个异步的复制过程,底层是基于mysql数据库自带的二进制日志功能。就是一台或多台…...
 A~D1)
VP记录:Educational Codeforces Round 148 (Rated for Div. 2) A~D1
传送门:CF 前题提要:本人临近期中,时间较紧,且关于D2暂时没有想到优化算法,因此准备留着以后有时间再继续解决 A题:A. New Palindrome 简单的模拟题,考虑记录每一个字母出现的次数.很容易发现奇数次的数字只能出现一次.因为最多只能在正中间放一个.并且因为不能和初始字符相…...
无线模块|如何选择天线和设计天线电路
无线模块的通信距离是一项重要指标,如何把有效通信距离最大化一直是大家疑惑的问题。本文根据调试经验及对天线的选择与使用方法做了一些说明,希望对工程师快速调试通信距离有所帮助。 一、天线的种类 随着技术的进步,为了节省研发周期&…...

(11)LCD1602液晶显示屏
LCD1602(Liquid Crystal Display)液晶显示屏是一种字符型液晶显示模块,可以显示ASCII码的标准字符和其它的一些内置特殊字符,还可以有8个自定义字符,自带芯片扫描 显示容量:162个字符,每个字符…...

类和对象下
文章目录 一、初始化列表1、语法:2、初始化顺序 二、static成员三、友元1、友元函数2、友元类 四、拷贝对象时的编译器优化例1、例2、例3、 一、初始化列表 1、语法: 初始化列表: 以一个冒号开始,接着是一个以逗号分隔的数据成员…...
【云计算•云原生】4.云原生之什么是Kubernetes
文章目录 Kubernetes概念Kubernetes核心概念集群podConfigMap Kubernetes架构master节点的组件worker节点组件 Kubernetes网络架构内部网络外部网络 k8s各端口含义 Kubernetes概念 K8S就是Kubernetes,Kubernetes首字母为K,末尾为s,中间一共有…...

云厂商降价潮背后:来中小企业战场「拼刺刀」
如果说过往云厂商的降价打响的是从C端进军B端的营销战,那么在这一轮降价潮背后,对应的则是云厂商从大型KA客户向中小企业进军的信号,强被集成,强获客。 云厂商又一轮降价潮袭来。 5月16日,移动云宣布部分产品线最高降…...

2-单片机GPIO相关知识点及流水灯和按键采集小实验
目录 小问题 :单片机上电后第一个执行的程序是? 【1】GPIO 1.定义 2.应用 I - Input 输入采集 O - Output 输出控制 3.GPIO结构框图 4.功能描述 输入功能 5.相关寄存器 【2】输出控制实验 实验:点亮一盏LED灯 1.实验…...

基础知识(王爽老师书第一章)
文章目录 基础知识1.1 引言1.2 机器语言1.2 引言汇编语言的产生1.3 汇编语言的组成1.4 存储器1.5 指令和数据1.6 存储单元1.7 CPU对存储器的读写1.8 地址总线1.9 数据总线1.10 控制总线小结检测点1.11.11 内存地址空间1.12 主板1.13 接口卡1.14 各类存储器芯片1.15 内存地址空间…...

非煤矿山电子封条建设算法 yolov8
非煤矿山电子封条建设算法模型通过yolov8网络模型AI视频智能分析技术,算法模型对作业状态以及出井入井人员数量变化、人员睡岗离岗等情况实时监测分析,及时发现异常动态,自动推送生成的违规截图报警信息。现代目标检测器大部分都会在正负样本…...

基于深度学习的yolo车辆特征属性识别 多特征检测+车辆颜色识别+车辆朝向识别+车辆检测+多标签属性识别
车辆检测和多标签属性识别:基于PyTorch的精简框架 在现代智能交通系统中,车辆检测和属性识别是至关重要的组成部分。它们能够帮助我们更好地理解和管理交通流量、优化城市规划,并提高道路安全。本文将介绍一个基于PyTorch构建的轻量级框架&am…...

雀魂Mod Plus终极指南:如何免费解锁全角色皮肤和装扮
雀魂Mod Plus终极指南:如何免费解锁全角色皮肤和装扮 【免费下载链接】majsoul_mod_plus 雀魂解锁全角色、皮肤、装扮等,支持全部服务器。 项目地址: https://gitcode.com/gh_mirrors/ma/majsoul_mod_plus 还在为雀魂游戏中无法获得心仪角色和皮肤…...

KCN-GenshinServer:5分钟搭建你的专属提瓦特世界,告别复杂配置烦恼
KCN-GenshinServer:5分钟搭建你的专属提瓦特世界,告别复杂配置烦恼 【免费下载链接】KCN-GenshinServer 基于GC制作的原神一键GUI多功能服务端。 项目地址: https://gitcode.com/gh_mirrors/kc/KCN-GenshinServer 你是否曾经想过拥有一个属于自己…...

springboot基于SpringBoot的艺术作品展示平台_z50di044_zl085
前言 在数字化浪潮推动下,艺术作品的传播与展示方式正经历深刻变革。传统艺术展览受限于场地、时间和地域,难以满足广大艺术爱好者和创作者的需求。基于SpringBoot的艺术作品展示平台旨在打破这些限制,构建一个集作品展示、交流互动、艺术教育…...

如何在 Linux 系统安装 Nginx?附可视化安装与管理教程
很多人在刚接触服务器时,都会遇到一个非常实际的问题:如何在系统安装 Nginx? Nginx 作为目前最常用的 Web 服务软件之一,广泛应用于静态网站部署、反向代理、负载均衡、HTTPS 证书配置以及前后端项目发布。对于运维人员、站长或者…...

Legacy-iOS-Kit终极指南:iOS设备降级、越狱与系统恢复完整解决方案
Legacy-iOS-Kit终极指南:iOS设备降级、越狱与系统恢复完整解决方案 【免费下载链接】Legacy-iOS-Kit An all-in-one tool to restore/downgrade, save SHSH blobs, jailbreak legacy iOS devices, and more 项目地址: https://gitcode.com/gh_mirrors/le/Legacy-i…...

部署Doris存算一体集群
部署Doris存算一体集群 1. 下载 doris安装包 https://doris.apache.org/zh-CN/download 2. 安装jdk(所有节点执行) 2.1 解压 tar -zxvf jdk-17.0.17_linux-x64_bin.tar.gz -C /data/java配置环境变量 vim /etc/profile增加如下配置 export JAV…...

Graphormer开源镜像多场景落地:国家实验室AI for Science基础设施建设案例
Graphormer开源镜像多场景落地:国家实验室AI for Science基础设施建设案例 1. 项目概述 Graphormer是一种基于纯Transformer架构的图神经网络模型,专门为分子图(原子-键结构)的全局结构建模与属性预测而设计。该模型在OGB、PCQM…...

Qwen3-0.6B-FP8部署教程:防火墙/代理环境下离线模型加载解决方案
Qwen3-0.6B-FP8部署教程:防火墙/代理环境下离线模型加载解决方案 你是不是也遇到过这种情况:想在公司内网或者网络受限的环境里部署一个大模型,结果第一步下载模型就卡住了?要么是网络代理设置太复杂,要么是防火墙直接…...

2026奇点大会闭门报告流出:图像描述生成正面临“语义坍缩”危机,这4类业务场景已触发告警
第一章:2026奇点智能技术大会:图像描述生成 2026奇点智能技术大会(https://ml-summit.org) 核心任务与技术演进 图像描述生成(Image Captioning)在2026奇点智能技术大会上被确立为多模态理解的关键落地范式。本届大会展示的最新…...