实验10 人工神经网络(1)
1. 实验目的
①理解并掌握误差反向传播算法;
②能够使用单层和多层神经网络,完成多分类任务;
③了解常用的激活函数。
2. 实验内容
①设计单层和多层神经网络结构,并使用TensorFlow建立模型,完成多分类任务;
②调试程序,通过调整超参数和训练模型参数,使模型在测试集上达到最优性能;
③测试模型,使用MatPlotlib对结果进行可视化呈现。
3. 实验过程
题目一:
分别使用单层神经网络和多层神经网络,对Iris数据集中的三种鸢尾花分类,并测试模型性能,以恰当的形式展现训练过程和结果。
要求:
⑴编写代码实现上述功能;
⑵记录实验过程和结果:
改变隐含层层数、隐含层中节点数等超参数,综合考虑准确率、交叉熵损失、和训练时间等,使模型在测试集达到最优的性能,并以恰当的方式记录和展示实验结果;
⑶分析和总结:
这个模型中的超参数有哪些?简要说明你寻找最佳超参数的过程,请分析它们对结果准确性和训练时间的影响,以表格或其他合适的图表形式展示。通过以上结果,可以得到什么结论,或对你有什么启发。
① 代码
单层神经网络:
import tensorflow as tf
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.family'] = "SimHei"#设置gpu
gpus = tf.config.experimental.list_physical_devices('GPU')
tf.config.experimental.set_memory_growth(gpus[0],True)
for gpu in gpus:tf.config.experimental.set_memory_growth(gpu,True)#下载数据集
TRAIN_URL = "http://download.tensorflow.org/data/iris_training.csv"
train_path = tf.keras.utils.get_file(TRAIN_URL.split('/')[-1],TRAIN_URL)TEST_URL = "http://download.tensorflow.org/data/iris_test.csv"
test_path = tf.keras.utils.get_file(TEST_URL.split("/")[-1],TEST_URL)df_iris_train = pd.read_csv(train_path,header=0)
df_iris_test = pd.read_csv(test_path,header=0)iris_train = np.array(df_iris_train) #(120,5)
iris_test = np.array(df_iris_test) #(30,5)#拆
x_train = iris_train[:,0:4]#(120,4)
y_train = iris_train[:,4]#(120,)
x_test = iris_test[:,0:4]
y_test = iris_test[:,4]#中心化
x_train = x_train - np.mean(x_train,axis=0)#(dtype(float64))
x_test = x_test - np.mean(x_test,axis=0)
#独热编码
X_train = tf.cast(x_train,tf.float32)
Y_train = tf.one_hot(tf.constant(y_train,dtype=tf.int32),3)
X_test = tf.cast(x_test,tf.float32)
Y_test = tf.one_hot(tf.constant(y_test,dtype=tf.int32),3)#超参数
learn_rate = 0.5
iter = 100
display_step = 5
#初始化
np.random.seed(612)
W = tf.Variable(np.random.randn(4,3),dtype=tf.float32) #权值矩阵
B = tf.Variable(np.zeros([3]),dtype=tf.float32) #偏置值
acc_train = []
acc_test = []
cce_train = []
cce_test = []for i in range(iter + 1):with tf.GradientTape() as tape:PRED_train = tf.nn.softmax(tf.matmul(X_train,W) + B)Loss_train = tf.reduce_mean(tf.keras.losses.categorical_crossentropy(y_true=Y_train,y_pred=PRED_train))PRED_test = tf.nn.softmax(tf.matmul(X_test,W) + B)Loss_test = tf.reduce_mean(tf.keras.losses.categorical_crossentropy(y_true=Y_test,y_pred=PRED_test))accuracy_train = tf.reduce_mean(tf.cast(tf.equal(tf.argmax(PRED_train.numpy(),axis=1),y_train),tf.float32))accuracy_test = tf.reduce_mean(tf.cast(tf.equal(tf.argmax(PRED_test.numpy(),axis=1),y_test),tf.float32))acc_train.append(accuracy_train)acc_test.append(accuracy_test)cce_train.append(Loss_train)cce_test.append(Loss_test)grads = tape.gradient(Loss_train,[W,B])W.assign_sub(learn_rate*grads[0])#dL_dW (4,3)B.assign_sub(learn_rate*grads[1])#dL_dW (3,)if i % display_step == 0:print("i:%d,TrainAcc:%f,TrainLoss:%f,TestAcc:%f,TestLoss:%f" % (i, accuracy_train, Loss_train, accuracy_test, Loss_test))#绘制图像
plt.figure(figsize=(10,3))
plt.suptitle("训练集和测试集的损失曲线和迭代率曲线",fontsize = 20)
plt.subplot(121)
plt.plot(cce_train,color="b",label="train")
plt.plot(cce_test,color="r",label="test")
plt.xlabel("Iteration")
plt.ylabel("Loss")
#plt.title("训练集和测试集的损失曲线",fontsize = 18)
plt.legend()plt.subplot(122)
plt.plot(acc_train,color="b",label="train")
plt.plot(acc_test,color="r",label="test")
plt.xlabel("Iteration")
plt.ylabel("Accuracy")
#plt.title("训练集和测试集的迭代率曲线",fontsize = 18)
plt.legend()plt.show()多层神经网络
import pandas as pd
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
plt.rcParams['font.family'] = "SimHei"#下载数据集
TRAIN_URL = "http://download.tensorflow.org/data/iris_training.csv"
train_path = tf.keras.utils.get_file(TRAIN_URL.split('/')[-1],TRAIN_URL)TEST_URL = "http://download.tensorflow.org/data/iris_test.csv"
test_path = tf.keras.utils.get_file(TEST_URL.split("/")[-1],TEST_URL)
#表示第一行数据作为列标题
df_iris_train = pd.read_csv(train_path,header=0)
df_iris_test = pd.read_csv(test_path,header=0)iris_train = np.array(df_iris_train)#将二维数据表转换为numpy数组,(120,5),训练集有120条样本
iris_test = np.array(df_iris_test)
train_x = iris_train[:,0:4]
train_y = iris_train[:,4]
test_x = iris_test[:,0:4]
test_y = iris_test[:,4]train_x = train_x - np.mean(train_x,axis=0)
test_x = test_x - np.mean(test_x,axis=0)X_train = tf.cast(train_x,tf.float32)
Y_train = tf.one_hot(tf.constant(train_y,dtype=tf.int32),3) #将标签值转换为独热编码的形式(120,3)X_test = tf.cast(test_x,tf.float32)
Y_test = tf.one_hot(tf.constant(test_y,dtype=tf.int32),3)learn_rate = 0.55
iter = 70
display_step = 13np.random.seed(612)
#隐含层
W1 = tf.Variable(np.random.randn(4,16),dtype=tf.float32) #W1(4,16)
B1 = tf.Variable(tf.zeros(16),dtype=tf.float32)#输出层
W2 = tf.Variable(np.random.randn(16,3),dtype=tf.float32) #W2(16,3)
B2 = tf.Variable(np.zeros([3]),dtype=tf.float32)cross_train = [] #保存每一次迭代的交叉熵损失
acc_train = [] #存放训练集的分类准确率cross_test = []
acc_test = []for i in range(iter + 1):with tf.GradientTape() as tape:# 5.1定义网络结构# H= X * W1 + B1Hidden_train = tf.nn.relu(tf.matmul(X_train,W1) + B1)# Y = H * W2 + B2Pred_train = tf.nn.softmax(tf.matmul(Hidden_train,W2) + B2)#计算训练集的平均交叉熵损失函数0Loss_train = tf.reduce_mean(tf.keras.losses.categorical_crossentropy(y_true=Y_train,y_pred=Pred_train))#H = X * W1 + B1Hidden_test = tf.nn.relu(tf.matmul(X_test,W1) + B1)# Y = H * W2 + B2Pred_test = tf.nn.softmax(tf.matmul(Hidden_test,W2) + B2)#计算测试集的平均交叉熵损失函数Loss_test = tf.reduce_mean(tf.keras.losses.categorical_crossentropy(y_true=Y_test,y_pred=Pred_test))Accuarcy_train = tf.reduce_mean(tf.cast(tf.equal(tf.argmax(Pred_train.numpy(),axis=1),train_y),tf.float32))Accuarcy_test = tf.reduce_mean(tf.cast(tf.equal(tf.argmax(Pred_test.numpy(),axis=1),test_y),tf.float32))#记录每一次迭代的交叉熵损失和准确率cross_train.append(Loss_train)cross_test.append(Loss_test)acc_train.append(Accuarcy_train)acc_test.append(Accuarcy_test)#对交叉熵损失函数W和B求偏导grads = tape.gradient(Loss_train,[W1,B1,W2,B2])W1.assign_sub(learn_rate * grads[0])B1.assign_sub(learn_rate * grads[1])W2.assign_sub(learn_rate * grads[2])B2.assign_sub(learn_rate * grads[3])if i % display_step == 0:print("i:%d,TrainLoss:%f,TrainAcc:%f,TestLoss:%f,TestAcc:%f" % (i, Loss_train, Accuarcy_train, Loss_test, Accuarcy_test))plt.figure(figsize=(12,5))
plt.suptitle("训练集和测试集的损失曲线和迭代率曲线",fontsize = 20)
plt.subplot(121)
plt.plot(acc_train,color="b",label="train")
plt.plot(acc_test,color="r",label="test")
plt.xlabel("Iteration")
plt.ylabel("Loss")
#plt.title("训练集和测试集的损失曲线",fontsize = 18)
plt.legend()plt.subplot(122)
plt.plot(cross_train,color="b",label="train")
plt.plot(cross_test,color="r",label="test")
plt.xlabel("Iteration")
plt.ylabel("Accuracy")
#plt.title("训练集和测试集的迭代率曲线",fontsize = 18)
plt.legend()plt.show()
② 结果记录
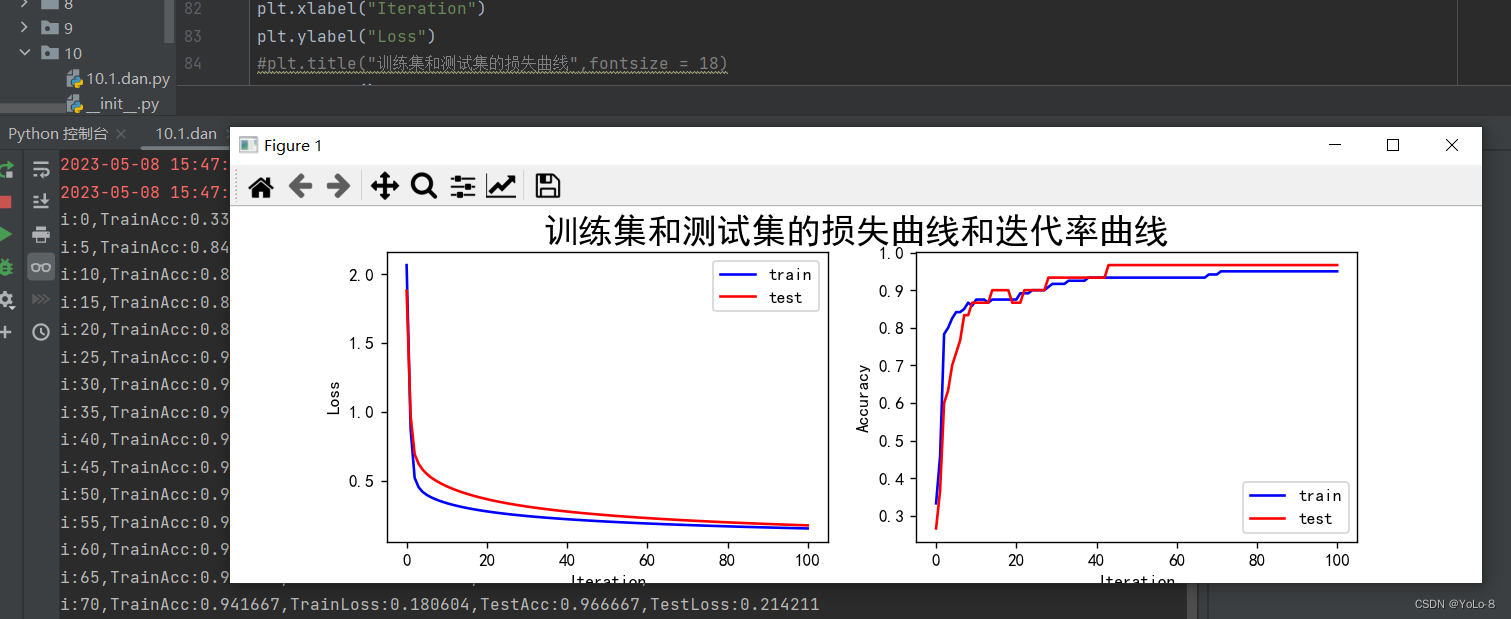
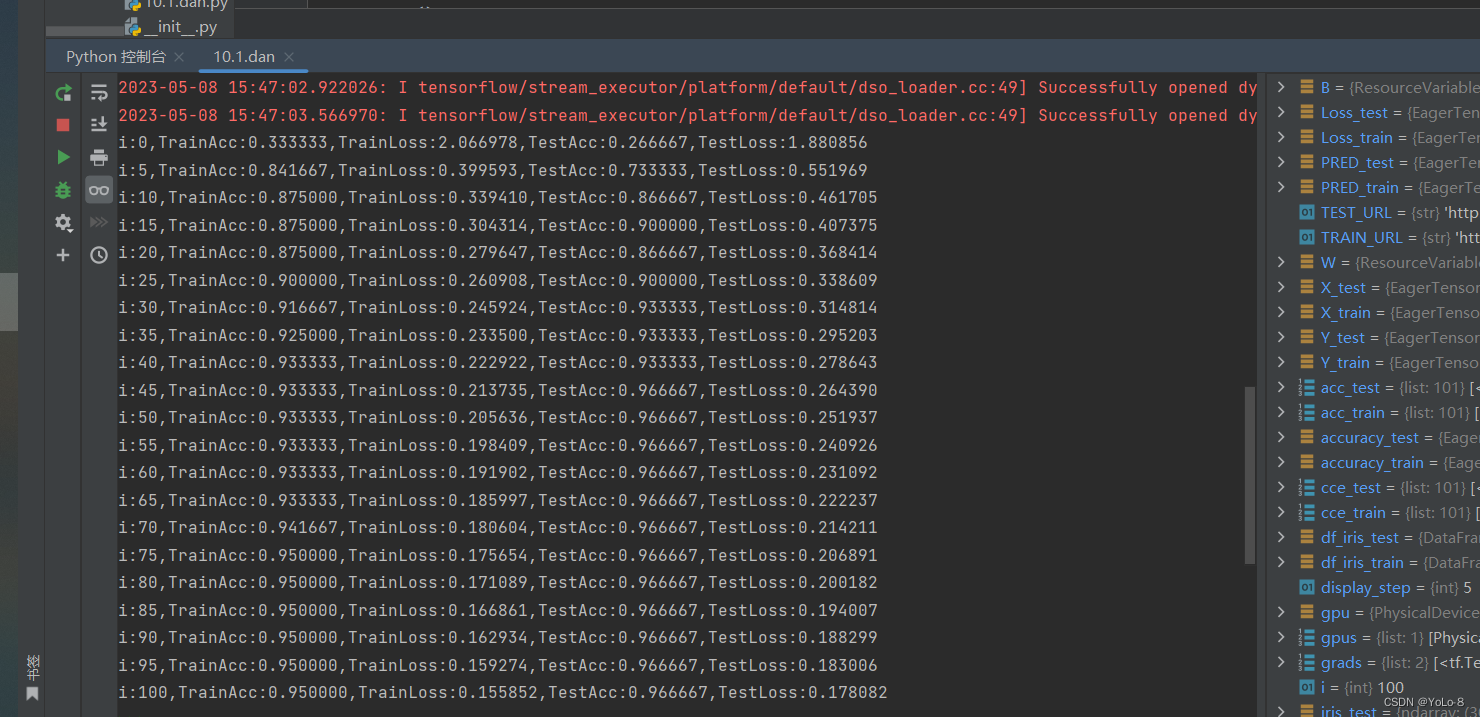
单层神经网络:
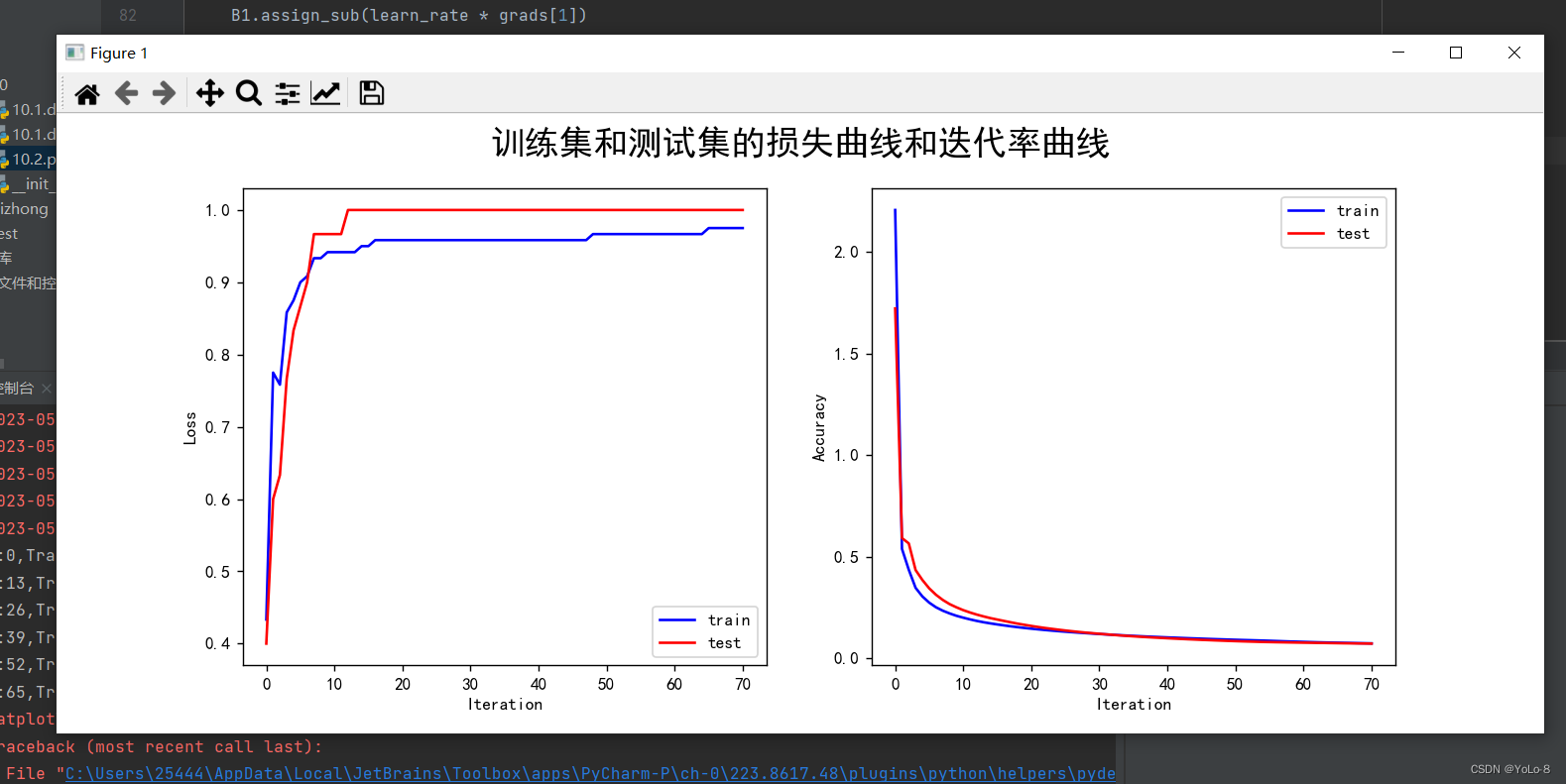
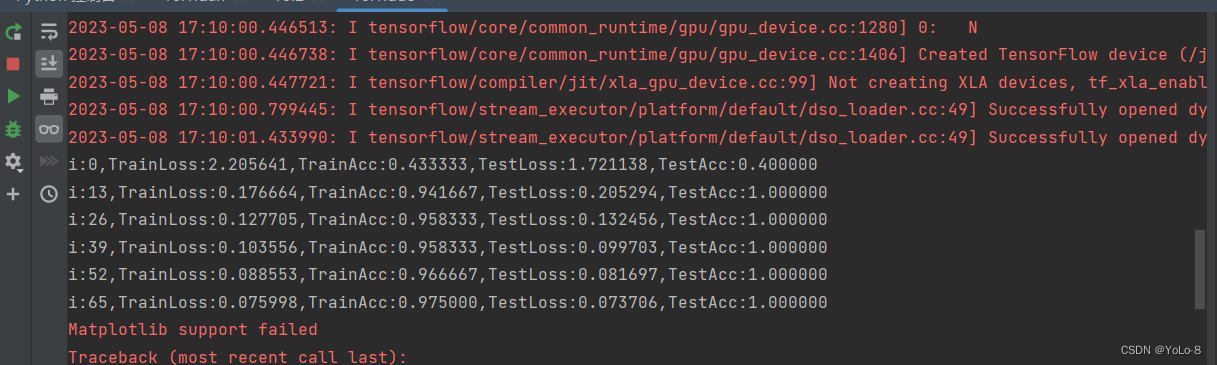
多层神经网络
③ 实验总结
参learn_rate = 0.5,iter = 100,display_step = 5其中神经网络的学习速度主要根据训练集上代价函数下降的快慢有关,而最后的分类的结果主要跟在验证集上的分类正确率有关。因此可以根据该参数主要影响代价函数还是影响分类正确率进行分类。超参数调节可以使用贝叶斯优化。
题目二:
使用低阶API实现Softmax函数和交叉熵损失函数,并使用它们修改题目一,看下结果是否相同。
① 代码
不同之处
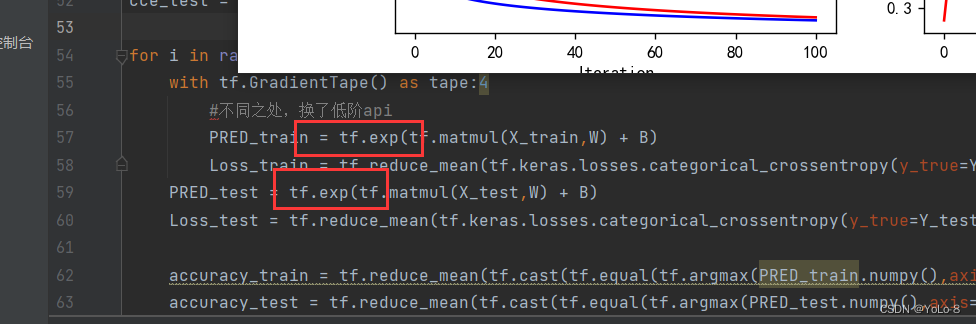
import tensorflow as tf
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.family'] = "SimHei"#设置gpu
gpus = tf.config.experimental.list_physical_devices('GPU')
tf.config.experimental.set_memory_growth(gpus[0],True)
for gpu in gpus:tf.config.experimental.set_memory_growth(gpu,True)#下载数据集
TRAIN_URL = "http://download.tensorflow.org/data/iris_training.csv"
train_path = tf.keras.utils.get_file(TRAIN_URL.split('/')[-1],TRAIN_URL)TEST_URL = "http://download.tensorflow.org/data/iris_test.csv"
test_path = tf.keras.utils.get_file(TEST_URL.split("/")[-1],TEST_URL)df_iris_train = pd.read_csv(train_path,header=0)
df_iris_test = pd.read_csv(test_path,header=0)iris_train = np.array(df_iris_train) #(120,5)
iris_test = np.array(df_iris_test) #(30,5)#拆
x_train = iris_train[:,0:4]#(120,4)
y_train = iris_train[:,4]#(120,)
x_test = iris_test[:,0:4]
y_test = iris_test[:,4]#中心化
x_train = x_train - np.mean(x_train,axis=0)#(dtype(float64))
x_test = x_test - np.mean(x_test,axis=0)
#独热编码
X_train = tf.cast(x_train,tf.float32)
Y_train = tf.one_hot(tf.constant(y_train,dtype=tf.int32),3)
X_test = tf.cast(x_test,tf.float32)
Y_test = tf.one_hot(tf.constant(y_test,dtype=tf.int32),3)#超参数
learn_rate = 0.5
iter = 100
display_step = 5
#初始化
np.random.seed(612)
W = tf.Variable(np.random.randn(4,3),dtype=tf.float32) #权值矩阵
B = tf.Variable(np.zeros([3]),dtype=tf.float32) #偏置值
acc_train = []
acc_test = []
cce_train = []
cce_test = []for i in range(iter + 1):with tf.GradientTape() as tape:#不同之处,换了低阶apiPRED_train = tf.exp(tf.matmul(X_train,W) + B)Loss_train = tf.reduce_mean(tf.keras.losses.categorical_crossentropy(y_true=Y_train,y_pred=PRED_train))PRED_test = tf.exp(tf.matmul(X_test,W) + B)Loss_test = tf.reduce_mean(tf.keras.losses.categorical_crossentropy(y_true=Y_test,y_pred=PRED_test))accuracy_train = tf.reduce_mean(tf.cast(tf.equal(tf.argmax(PRED_train.numpy(),axis=1),y_train),tf.float32))accuracy_test = tf.reduce_mean(tf.cast(tf.equal(tf.argmax(PRED_test.numpy(),axis=1),y_test),tf.float32))acc_train.append(accuracy_train)acc_test.append(accuracy_test)cce_train.append(Loss_train)cce_test.append(Loss_test)grads = tape.gradient(Loss_train,[W,B])W.assign_sub(learn_rate*grads[0])#dL_dW (4,3)B.assign_sub(learn_rate*grads[1])#dL_dW (3,)if i % display_step == 0:print("i:%d,TrainAcc:%f,TrainLoss:%f,TestAcc:%f,TestLoss:%f" % (i, accuracy_train, Loss_train, accuracy_test, Loss_test))#绘制图像
plt.figure(figsize=(10,3))
plt.suptitle("训练集和测试集的损失曲线和迭代率曲线",fontsize = 20)
plt.subplot(121)
plt.plot(cce_train,color="b",label="train")
plt.plot(cce_test,color="r",label="test")
plt.xlabel("Iteration")
plt.ylabel("Loss")
#plt.title("训练集和测试集的损失曲线",fontsize = 18)
plt.legend()plt.subplot(122)
plt.plot(acc_train,color="b",label="train")
plt.plot(acc_test,color="r",label="test")
plt.xlabel("Iteration")
plt.ylabel("Accuracy")
#plt.title("训练集和测试集的准确率曲线",fontsize = 18)
plt.legend()plt.show()② 实验结果
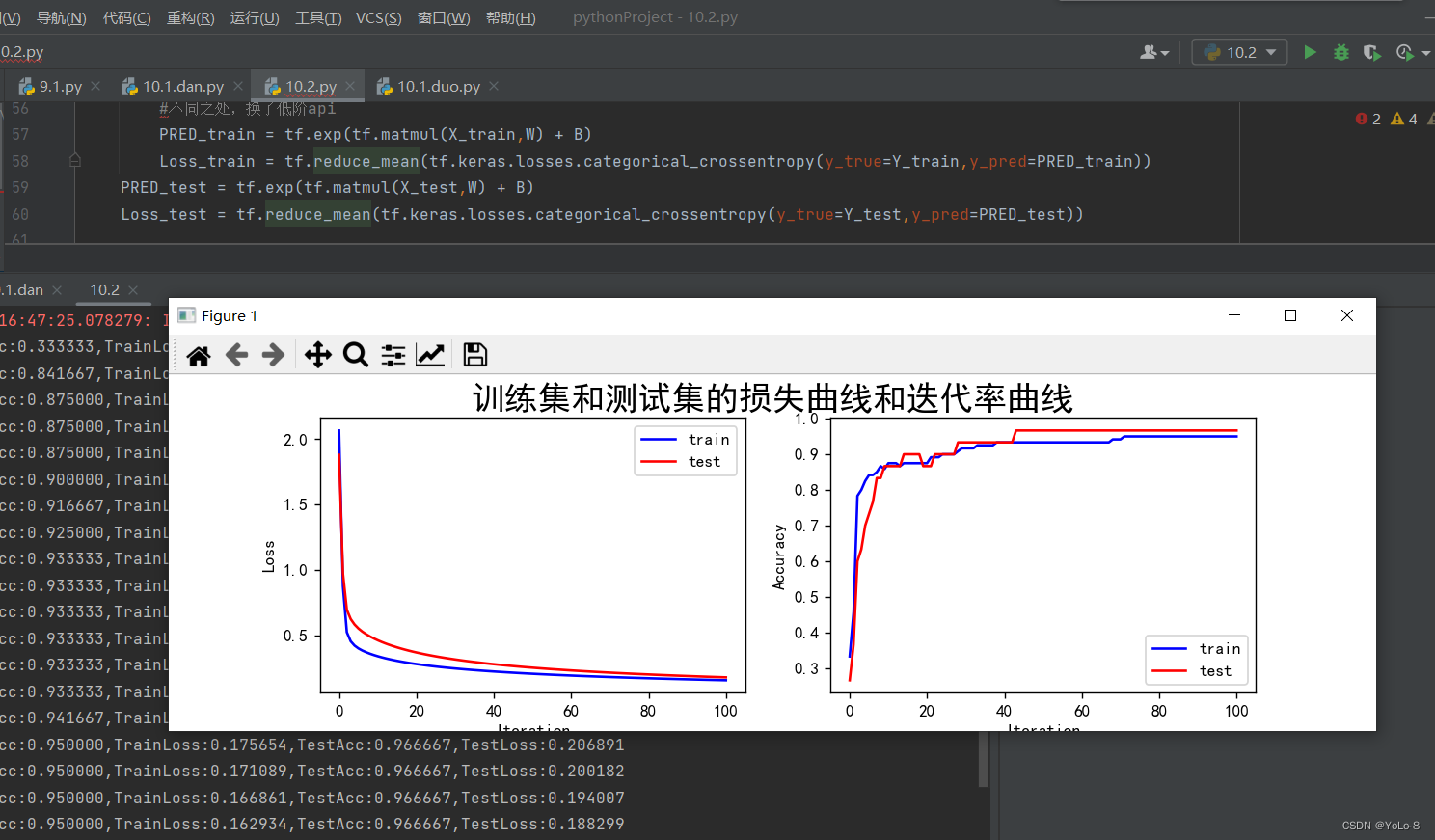
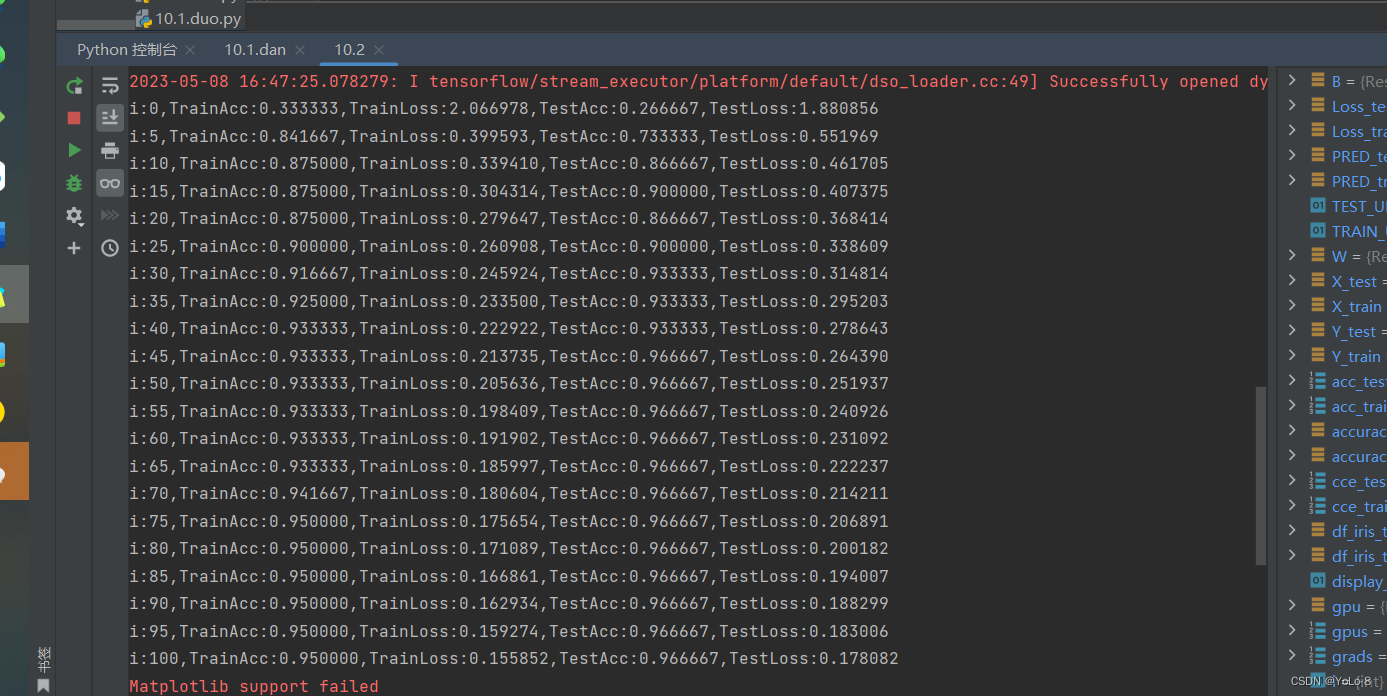
4. 实验小结&讨论题
①在神经网络中,激活函数的作用是什么?常用的激活函数有哪些?在多分类问题中,在输出层一般使用使用什么激活函数?隐含层一般使用使用什么激活函数?为什么?
答:激活函数的作用是去线性化;常用到激活函数:tanh,ReL,Sigmoid;Sigmoid函数用于输出层,tanh函数用于隐含层。
②什么是损失函数?在多分类问题中,一般使用什么损失函数?为什么?
答:损失函数是用来评估模型的预测值与真实值不一致的程度
(1)L1范数损失L1Loss
(2)均方误差损失MSELoss
(3)交叉熵损失CrossEntropyLoss
③神经网络的深度和宽度对网络性能有什么影响?
答:如果一个深层结构能够刚刚好解决问题,那么就不可能用一个更浅的同样紧凑的结构来解决,因此要解决复杂的问题,要么增加深度,要么增加宽度。但是神经网络一般来说不是越深越好,也不是越宽越好,并且由于计算量的限制或对于速度的需求,如何用更少的参数获得更好的准确率无疑是一个永恒的追求。
④训练数据和测试数据对神经网络的性能有何影响?在选择、使用和划分数据集时,应注意什么?
答:注意使用的范围和整体效果。
相关文章:
实验10 人工神经网络(1)
1. 实验目的 ①理解并掌握误差反向传播算法; ②能够使用单层和多层神经网络,完成多分类任务; ③了解常用的激活函数。 2. 实验内容 ①设计单层和多层神经网络结构,并使用TensorFlow建立模型,完成多分类任务…...
OPPO关停哲库业务,工程师造芯何去何从?
5月12日(上周五),新浪科技从OPPO处了解到,OPPO将终止ZEKU业务。3000多人团队突然原地解散,网上唏嘘声一片! ZEKU最初成立于2019年,是OPPO的全资子公司,欧加集团百分之百注资成立。总…...

面试被问麻了....
前几天组了一个软件测试面试的群,没想到效果直接拉满,看来大家对面试这块的需求还是挺迫切的。昨天我就看到群友们发的一些面经,感觉非常有参考价值,于是我就问他还有没有。 结果他给我整理了一份非常硬核的面筋,打开…...

AspNetCore中的配置文件详解
1 配置文件 程序开发中,有些信息是要根据环境改变的,比如开发环境的数据库可能是本地数据,而生产环境下需要连接生产数据库,我们需要把这些信息放到程序外面,在程序运行时通过读取这些外部信息实现不改变程序代码适应…...

实时更新天气微信小程序开发
1.新建一个天气weather项目 2.在app.json中创建一个路由页面 当我们点击保存的时候,微信小程序会自动的帮我们创建好页面 3.在weather页面上书写我们的骨架 4.此时我们的页面很怪,因为没有给它添加样式和值。此时我们给它一个样式。(样式写在…...

css渐变
线性渐变 liner-gradient属性值用来设置线性渐变,第一个参数值是方向,默认是从上往下,往后就是渐变颜色的种类。 background-image:liner-gradient(方向,颜色1,颜色2...) .box {display: flex;width: 400px;height: …...

《斯坦福数据挖掘教程·第三版》读书笔记(英文版) Chapter 2 MapReduce and the New Software Stack
来源:《斯坦福数据挖掘教程第三版》对应的公开英文书和PPT Chapter 2 MapReduce and the New Software Stack Computing cluster means large collections of commodity hardware, including conventional processors (“compute nodes”) connected by Ethernet …...

HTML零基础快速入门(详细教程)
1,HTML代码特点 <html><head></head><body>hello world!</body> </html>HTML代码有以下特点: html代码是通过标签来组织的,而标签是由尖括号< >组织的,也可被叫作元素(ele…...

Kubernetes第5天
第七章 Service详解 本章节主要介绍kubernetes的流量负载组件:Service和Ingress。 Service介绍 在kubernetes中,pod是应用程序的载体,我们可以通过pod的ip来访问应用程序,但是pod的ip地址不是固定的,这也就意味着…...
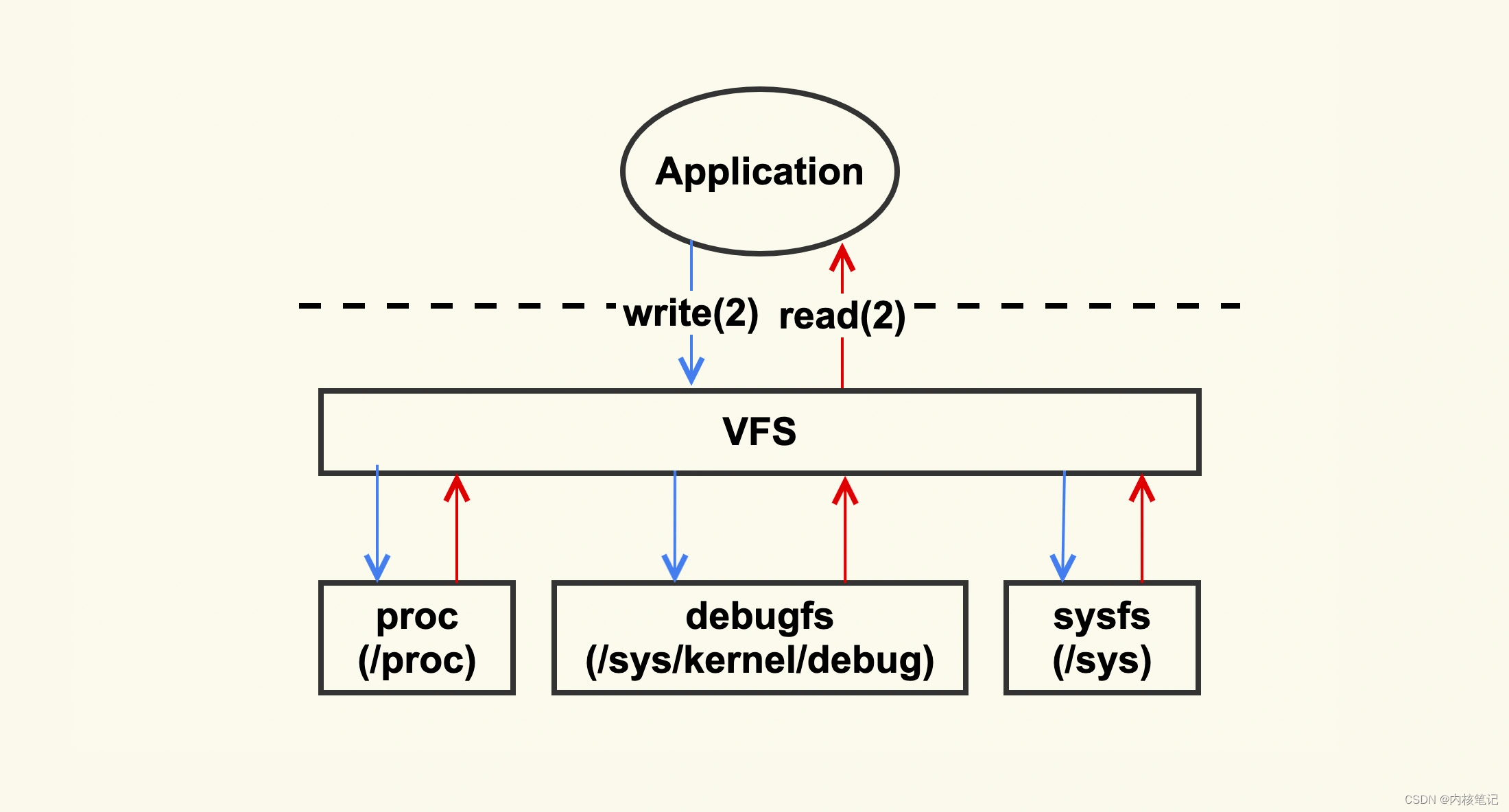
RK3568平台开发系列讲解(调试篇)debugfs 分析手段
🚀返回专栏总目录 文章目录 一、enable debugfs二、debugfs API三、使用示例沉淀、分享、成长,让自己和他人都能有所收获!😄 📢Linux 上有一些典型的问题分析手段,从这些基本的分析方法入手,你可以一步步判断出问题根因。这些分析手段,可以简单地归纳为下图: 从这…...
【Spring框架全系列】SpringBoot配置日志文件
🍧🍧哈喽,大家好,我是小浪。那么上篇博客我们学习了SpringBoot配置文件的相关操作,本篇博客我们将学习一个新的知识点,SpringBoot日志文件。🖥🖥 📲目录 一、日志是什么…...
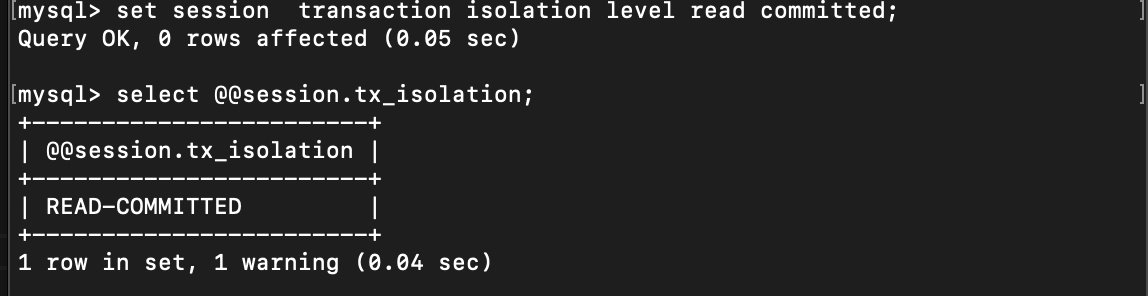
事务 ---MySQL的总结(六)
事务 多进程进行并改变同一个数据,如果没有进行版本控制,就会出现数据不确定的问题,为此引入了事务的概念。可以进行数据回滚,解决潜在的问题。 事务的概念 一组的DML组成,这一些的DML要么同时成功,要么同…...

22 标准模板库STL之容器适配器
概述 提到适配器,我们的第一印象是想到设计模式中的适配器模式:将一个类的接口转化为另一个类的接口,使原本不兼容而不能合作的两个类,可以一起工作。STL中的容器适配器与此类似,是一个封装了序列容器的类模板,它在一般序列容器的基础上提供了一些不同的功能和接口。之所…...

目标检测YOLO实战应用案例100讲-基于深度学习的自动驾驶目标检测算法研究
目录 基于深度学习的自动驾驶目标检测算法研究 相关理论基础 2.1 卷积神经网络基本原理...
服务网关Gateway
前言 API 网关出现的原因是微服务架构的出现,不同的微服务一般会有不同的网络地址,而外部客户端可能需要调用多个服务的接口才能完成一个业务需求,如果让客户端直接与各个微服务通信,会有以下的问题: 破坏了服务无状态…...
(4)定时器
51单片机的定时器属于单片机的内部资源,其电路的连接和运转均在单片机内部完成 作用: 用于计时系统替代长时间Delay,提高运行效率和速度任务切换 STC89C52定时器资源: 定时器个数:3个(T0,T1,T2…...

项目实现读写分离操作(mysql)
读写分离 1.问题说明 2.读写分离 Master(主库)----(数据同步)—> Slave(从库) Mysql主从复制 mysql主从复制 介绍 mysql主从复制是一个异步的复制过程,底层是基于mysql数据库自带的二进制日志功能。就是一台或多台…...
 A~D1)
VP记录:Educational Codeforces Round 148 (Rated for Div. 2) A~D1
传送门:CF 前题提要:本人临近期中,时间较紧,且关于D2暂时没有想到优化算法,因此准备留着以后有时间再继续解决 A题:A. New Palindrome 简单的模拟题,考虑记录每一个字母出现的次数.很容易发现奇数次的数字只能出现一次.因为最多只能在正中间放一个.并且因为不能和初始字符相…...
无线模块|如何选择天线和设计天线电路
无线模块的通信距离是一项重要指标,如何把有效通信距离最大化一直是大家疑惑的问题。本文根据调试经验及对天线的选择与使用方法做了一些说明,希望对工程师快速调试通信距离有所帮助。 一、天线的种类 随着技术的进步,为了节省研发周期&…...

(11)LCD1602液晶显示屏
LCD1602(Liquid Crystal Display)液晶显示屏是一种字符型液晶显示模块,可以显示ASCII码的标准字符和其它的一些内置特殊字符,还可以有8个自定义字符,自带芯片扫描 显示容量:162个字符,每个字符…...

招投标采购管理系统_采购管理软件_采购系统_招标采购系统源码+数据库BS架构
1. 供应商管理信息全量记录:系统全面留存供应商基础信息,涵盖公司全称、联系方式、主营产品/服务、资质文件等核心内容,实现信息集中管控,避免遗漏。多维综合评估:从资质合规性、过往合作表现、市场信誉度、履约能力等…...

LightOnOCR-2-1B快速上手指南:3步完成图片上传→文字提取→结果导出
LightOnOCR-2-1B快速上手指南:3步完成图片上传→文字提取→结果导出 你是否曾经遇到过需要从图片中提取文字,却不想手动输入的烦恼?无论是扫描文档、照片中的文字,还是截图中的信息,手动录入既费时又容易出错。现在&am…...
,轻松提升RAG系统召回率!)
大模型应用必看:分块策略详解(收藏版),轻松提升RAG系统召回率!
本文深入探讨了在RAG系统中,如何通过分块策略提升大模型的处理效率和召回率。文章详细介绍了固定大小、重叠、递归、文档特定、语义及混合等分块策略,并分析了每种策略的优缺点及适用场景。通过LangChain提供的多种文档分块方法,开发者可以轻…...

nli-distilroberta-base作品集:10组典型中文句子对推理结果与人工标注对比
nli-distilroberta-base作品集:10组典型中文句子对推理结果与人工标注对比 1. 项目概述 nli-distilroberta-base是一个基于DistilRoBERTa模型的自然语言推理(NLI)Web服务,专门用于分析两个句子之间的逻辑关系。这个轻量级模型继承了RoBERTa的强大性能&…...

YOLOv8与Qwen3-14B-Int4-AWQ联动:构建智能图像描述与问答系统
YOLOv8与Qwen3-14B-Int4-AWQ联动:构建智能图像描述与问答系统 1. 多模态AI的惊艳组合 当计算机视觉遇上自然语言处理,会擦出怎样的火花?YOLOv8与Qwen3-14B-Int4-AWQ的联动给出了令人惊喜的答案。这套组合不仅能"看懂"图像内容&am…...

代码随想录算法训练营第二十四天| 93、复原IP地址 78、子集 90、子集II
目录 93. 复原 IP 地址 - 力扣(LeetCode) 题目描述 解题思路 78. 子集 题目描述 解题思路 90. 子集 II 题目描述 解题思路 93. 复原 IP 地址 - 力扣(LeetCode) 题目描述 有效 IP 地址 正好由四个整数(每个整…...

如何快速修复老游戏兼容性:DDrawCompat终极使用指南
如何快速修复老游戏兼容性:DDrawCompat终极使用指南 【免费下载链接】DDrawCompat DirectDraw and Direct3D 1-7 compatibility, performance and visual enhancements for Windows Vista, 7, 8, 10 and 11 项目地址: https://gitcode.com/gh_mirrors/dd/DDrawCom…...

矽力杰 Silergy SY8024 双路同步降压转换器 规格书 佰祥电子
突破双路降压集成度低、小体积大电流、高频低纹波痛点!SY8024:双路 3A 输出 1.5MHz 高频的五大核心优势便携智能设备双路降压供电场景普遍存在双路供电需双芯片导致体积偏大、高频小体积方案转换效率偏低、双路独立控制与防护能力不足三大行业痛点。作为…...

2025届最火的降重复率平台推荐
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 在如今天日渐趋成熟的AI生成内容检测技术状况下,众多创作者都面临着内容被标记成…...

LIN一致性测试避坑指南:从电阻、电平到睡眠唤醒,实测CANoe外部设备集成那些事儿
LIN一致性测试实战避坑指南:从设备同步到脚本优化的全流程解析 当示波器波形与CANoe记录的时间轴对不上,当睡眠唤醒测试中的电源控制脚本频繁报错,当checksum错误让你在节点硬件与测试配置间反复排查——这些才是LIN一致性测试工程师的真实日…...