Python垃圾回收机制
Python 运行过程中会不停的创建各种变量,而这些变量是需要存储在内存中的,随着程序的不断运行,变量数量越来越多,所占用的空间势必越来越大,如果对变量所占用的内存空间管理不当的话,那么肯定会出现 out of memory。程序大概率会被异常终止。
因此,对于内存空间的有效合理管理变得尤为重要,那么 Python 是怎么解决这个问题的呢。其实很简单,对不不可能再使用到的内存进行回收即可,像 C 语言中需要程序员手动释放内存就是这个道理。但问题是如何确定哪些内存不再会被使用到呢?这就是我们今天要说的垃圾回收了。
目前垃圾回收比较通用的解决办法有三种,引用计数,标记清除以及分代回收。
引用计数
引用计数也是一种最直观,最简单的垃圾收集技术。在 Python 中,大多数对象的生命周期都是通过对象的引用计数来管理的。其原理非常简单,我们为每个对象维护一个 ref 的字段用来记录对象被引用的次数,每当对象被创建或者被引用时将该对象的引用次数加一,当对象的引用被销毁时该对象的引用次数减一,当对象的引用次数减到零时说明程序中已经没有任何对象持有该对象的引用,换言之就是在以后的程序运行中不会再次使用到该对象了,那么其所占用的空间也就可以被释放了了。
我们来看看下面的例子。
import osimport psutil# 打印当前程序占用的内存大小def print_memory_info(name):pid = os.getpid()p = psutil.Process(pid)info = p.memory_full_info()MB = 1024 * 1024memory = info.uss / MBprint('%s used %d MB' % (name, memory))# 测试函数def foo():print_memory_info("foo start")length = 1000 * 1000list = [i for i in range(length)]print_memory_info("foo end")foo()print_memory_info("main end")### 输出结果foo start used 6 MBfoo end used 55 MBmain end used 10 MB
函数 print_memory_info 用来获取程序占用的内存空间大小,在 foo 函数中创建一个包含一百万个整数的列表。从打印结果我们可以看出,创建完列表之后程序耗用的内存空间上升到了 55 MB。而当函数 foo 调用完毕之后内存消耗又恢复正常。
这是因为我们在函数 foo 中创建的 list 变量是局部变量,其作用域是当前函数内部,一旦函数执行完毕,局部变量的引用会被自动销毁,即其引用次数会变为零,所占用的内存空间也会被回收。
为了验证我们的想法,我们对函数 foo 稍加改造。代码如下:
def foo():print_memory_info("foo start")length = 1000 * 1000list = [i for i in range(length)]print_memory_info("foo end")return list### 输出结果foo start used 6 MBfoo end used 55 MBmain end used 55 MB
稍加改造之后,即使 foo 函数调用结束其所消耗的内存也未被释放。
主要是因为我们将函数 foo 内部产生的列表返回并在主程序中接收之后,这样就会导致该列表的引用依然存在,该对象后续仍有可能被使用到,垃圾回收便不会回收该对象。
那么,什么时候对象的引用次数才会增加呢。下面四种情况都会导致对象引用次数加一。
-
对象被创建(num=2)
-
对象被引用(count=num)
-
对象作为参数传递到函数内部
-
对象作为一个元素添加到容器中
同理,对象引用次数减一的情况也有四种。
-
对象的别名被显式销毁(del num)
-
对象的别名被赋予新的对象(num=30)
-
对象离开它的作用域(函数局部变量)
-
从容器中删除对象,或者容器被销毁
引用计数看起来非常简单,实现起来也不复杂,只需要维护一个字段保存对象被引用的次数即可,那么是不是就代表这种算法没有缺点了呢。实则不然,我们知道引用次数为零的对象所占用的内存空间肯定是需要被回收的。那引用次数不为零的对象呢,是不是就一定不能回收呢?
我们来看看下面的例子,只是对函数 foo 进行了改造,其余未做更改。
def foo():print_memory_info("foo start")length = 1000 * 1000list_a = [i for i in range(length)]list_b = [i for i in range(length)]list_a.append(list_b)list_b.append(list_a)print_memory_info("foo end")return list### 输出结果foo start used 6 MBfoo end used 93 MBmain end used 93 MB
我们看到,在函数 foo 内部生成了两个列表 list_a 和 list_b,然后将两个列表分别添加到另外一个中。由结果可以看出,即使 foo 函数结束之后其所占用的内存空间依然未被释放。这是因为对于 list_a 和 list_b 来说虽然没有被任何外部对象引用,但因为二者之间交叉引用,以至于每个对象的引用计数都不为零,这也就造成了其所占用的空间永远不会被回收的尴尬局面。这个缺点是致命的。
为了解决交叉引用的问题,Python 引入了标记清除算法和分代回收算法。
标记清除
显然,可以包含其他对象引用的容器对象都有可能产生交叉引用问题,而标记清除算法就是为了解决交叉引用的问题的。
标记清除算法是一种基于对象可达性分析的回收算法,该算法分为两个步骤,分别是标记和清除。标记阶段,将所有活动对象进行标记,清除阶段将所有未进行标记的对象进行回收即可。那么现在的问题变为了 GC 是如何判定哪些是活动对象的?
事实上 GC 会从根结点出发,与根结点直接相连或者间接相连的对象我们将其标记为活动对象(该对象可达),之后进行回收阶段,将未标记的对象(不可达对象)进行清除。前面所说的根结点可以是全局变量,也可以是调用栈。
标记清除算法主要用来处理一些容器对象,虽说该方法完全可以做到不误杀不遗漏,但 GC 时必须扫描整个堆内存,即使只有少量的非可达对象需要回收也需要扫描全部对象。这是一种巨大的性能浪费。
分代回收
由于标记清除算法需要扫描整个堆的所有对象导致其性能有所损耗,而且当可以回收的对象越少时性能损耗越高。因此 Python 引入了分代回收算法,将系统中存活时间不同的对象划分到不同的内存区域,共三代,分别是 0 代,1 代 和 2 代。新生成的对象是 0 代,经过一次垃圾回收之后,还存活的对象将会升级到 1 代,以此类推,2 代中的对象是存活最久的对象。
那么什么时候触发进行垃圾回收算法呢。事实上随着程序的运行会不断的创建新的对象,同时也会因为引用计数为零而销毁大部分对象,Python 会保持对这些对象的跟踪,由于交叉引用的存在,以及程序中使用了长时间存活的对象,这就造成了新生成的对象的数量会大于被回收的对象数量,一旦二者之间的差值达到某个阈值就会启动垃圾回收机制,使用标记清除算法将死亡对象进行清除,同时将存活对象移动到 1 代。以此类推,当二者的差值再次达到阈值时又触发垃圾回收机制,将存活对象移动到 2 代。
这样通过对不同代的阈值做不同的设置,就可以做到在不同代使用不同的时间间隔进行垃圾回收,以追求性能最大。
事实上,所有的程序都有一个相似的现象,那就是大部分的对象生存周期都是相当短的,只有少量对象生命周期比较长,甚至会常驻内存,从程序开始运行持续到程序结束。而通过分代回收算法,做到了针对不同的区域采取不同的回收频率,节约了大量的计算从而提高 Python 的性能。
除了上面所说的差值达到一定阈值会触发垃圾回收之外,我们还可以显示的调用 gc.collect() 来触发垃圾回收,最后当程序退出时也会进行垃圾回收。
总结
本文介绍了 Python 的垃圾回收机制,垃圾回收是 Python 自带的功能,并不需要程序员去手动管理内存。
其中引用计数法是最简单直接的,但是需要维护一个字段且针对交叉引用无能为力。
标记清除算法主要是为了解决引用计数的交叉引用问题,该算法的缺点就是需要扫描整个堆的所有对象,有点浪费性能。
而分代回收算法的引入则完美解决了标记清除算法需要扫描整个堆对象的性能浪费问题。该算法也是建立在标记清除基础之上的。
最后我们可以通过 gc.collect() 手动触发 GC 的操作。
相关文章:

Python垃圾回收机制
Python 运行过程中会不停的创建各种变量,而这些变量是需要存储在内存中的,随着程序的不断运行,变量数量越来越多,所占用的空间势必越来越大,如果对变量所占用的内存空间管理不当的话,那么肯定会出现 out of…...
Grafana插件安装并接入zabbix数据源(03)
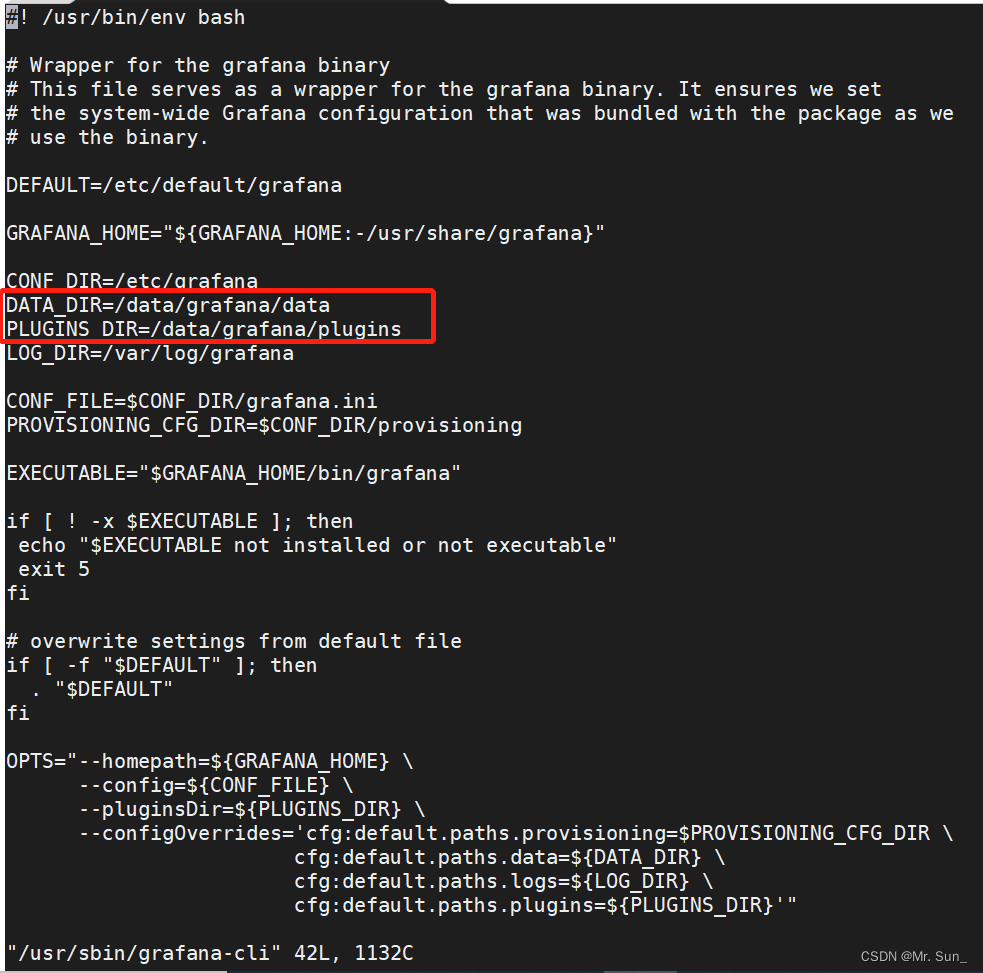
一、在线安装插件 如果不指定插件安装位置,则默认安装位置为/var/lib/grafana/plugins;插件安装后需要重启grafana-server 安装zabbix插件alexanderzobnin-zabbix-app # grafana-cli plugins install alexanderzobnin-zabbix-app 使用--pluginsDir指定安装路径 # grafana…...
简述 JavaScript 中 prototype
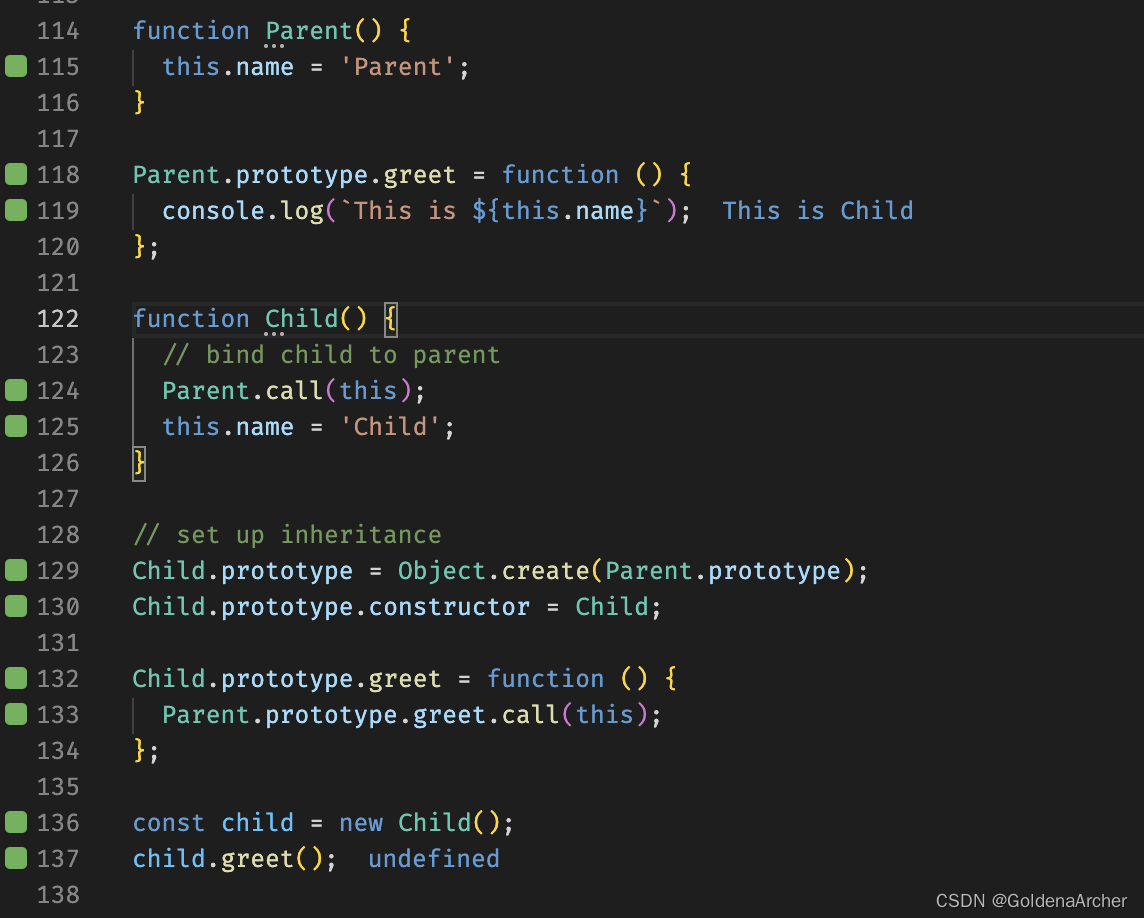
简述 JavaScript 中 prototype 这篇笔记主要捋一下这么几个概念: JS 的继承构造函数new 的作用及简易实现__proto__ & prototype同样的方法,class 和 prototype 中分别是怎么实现的 基础概念 JS 是通过 prototype chaining 实现继承的语言&#…...

一觉醒来Chat gpt就被淘汰了
目录 什么是Auto GPT? 与其他语言生成模型相比,Auto GPT具有以下优点 Auto GPT的能力 Auto GPT的能力非常强大,它可以应用于各种文本生成场景,包括但不限于以下几个方面 Auto GPT的历史 马斯克说:“ChatGPT 好得吓…...

13款JavaScript图像处理库,建议收藏备用
pica: 一个在浏览器中调整图像大小,而不会出现像素失真,处理速度非常快的图片处理库,仓库地址https://github.com/nodeca/picahtml2canvas: 强大的使用js开发的浏览器网页截图工具,仓库地址https://github.…...

uniapp m3u8格式视频加载
uniapp一:mui-player:三方 h5 web app uniapp 使用 mui-player 插件播放 m3u8/flv 视频流_翘翘红的博客-CSDN博客 uniapp 开发的h5项目,需要播放m3u8/flv后缀的视频,网上有很多视频插件,但是样式和效果不尽如人意&am…...
iOS描述文件(.mobileprovision)一键申请
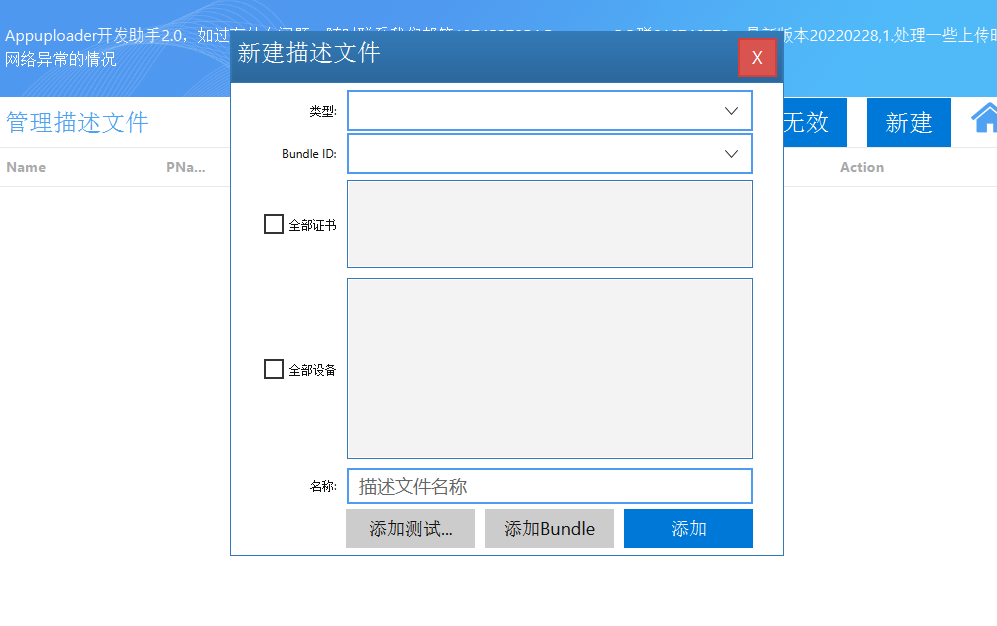
iOS描述文件(.mobileprovision)一键申请 在主界面上点击描述文件按钮。 新建ios描述文件 然后点击新建,然后输入描述文件名称,描述文件名称字符和数字,自己好辨识就可以。然后选择描述文件类型,再选择bundle ID,如果…...

进行性能压力测试的原因、目的和好处
性能压力测试是指在模拟高负载、高并发情况下对软件系统进行测试,以衡量系统在实际使用过程中的性能表现。这些测试可以为生产环境中的应用程序提供关键数据,并帮助开发人员从根本上了解系统的实际性能。在本文中,我们将探讨进行性能压力测试…...
【计算机视觉】如何利用 CLIP 做简单的人脸任务?(含源代码)
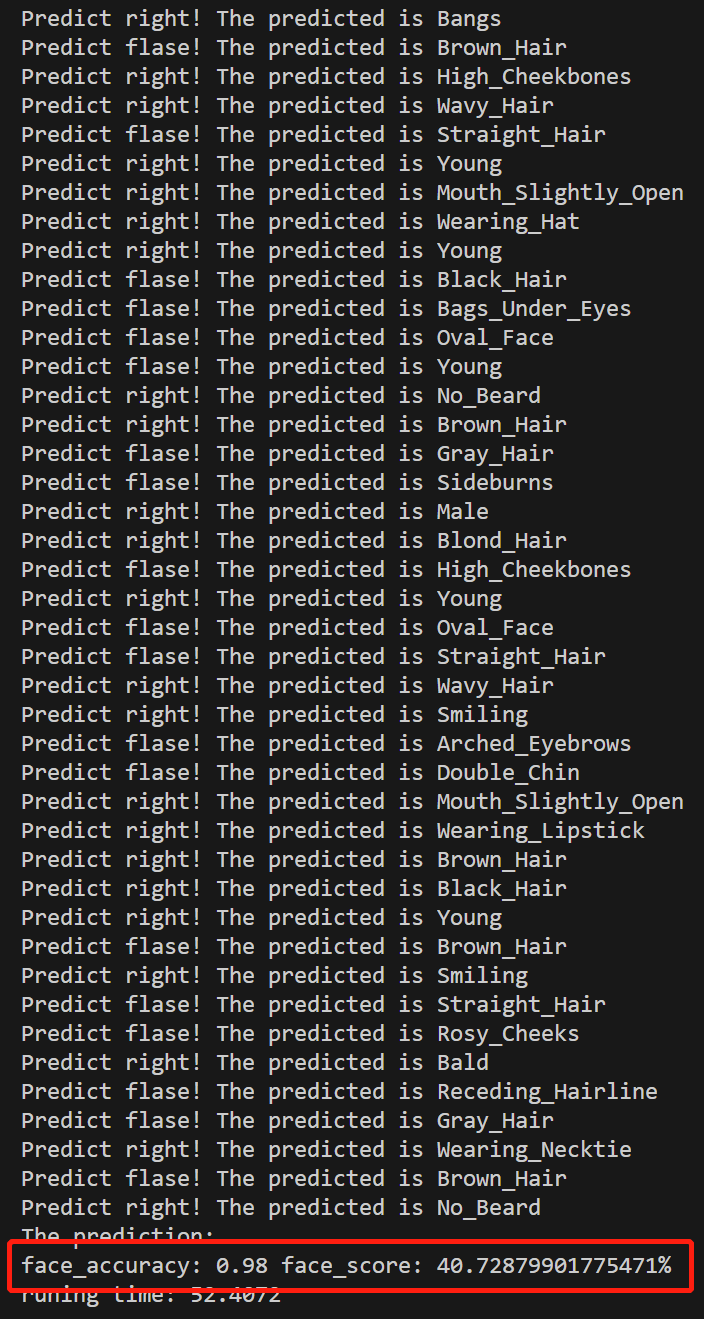
文章目录 一、数据集介绍二、源代码 结果三、代码逐行解读 一、数据集介绍 CELEBA 数据集(CelebFaces Attributes Dataset)是一个大规模的人脸图像数据集,旨在用于训练和评估人脸相关的计算机视觉模型。该数据集由众多名人的脸部图像组成&a…...

基于显扬科技3D视觉相机的医疗试管分拣系统
行业现状: 医疗试管分拣是医疗行业中的一个重要环节,指将医疗实验室或生物技术研究中的试管按照一定的规则进行分拣,并对试管的类型、位置、数量等信息进行识别和管理。 随着医疗技术的不断发展和诊断治疗的精细化,医疗试管分拣…...
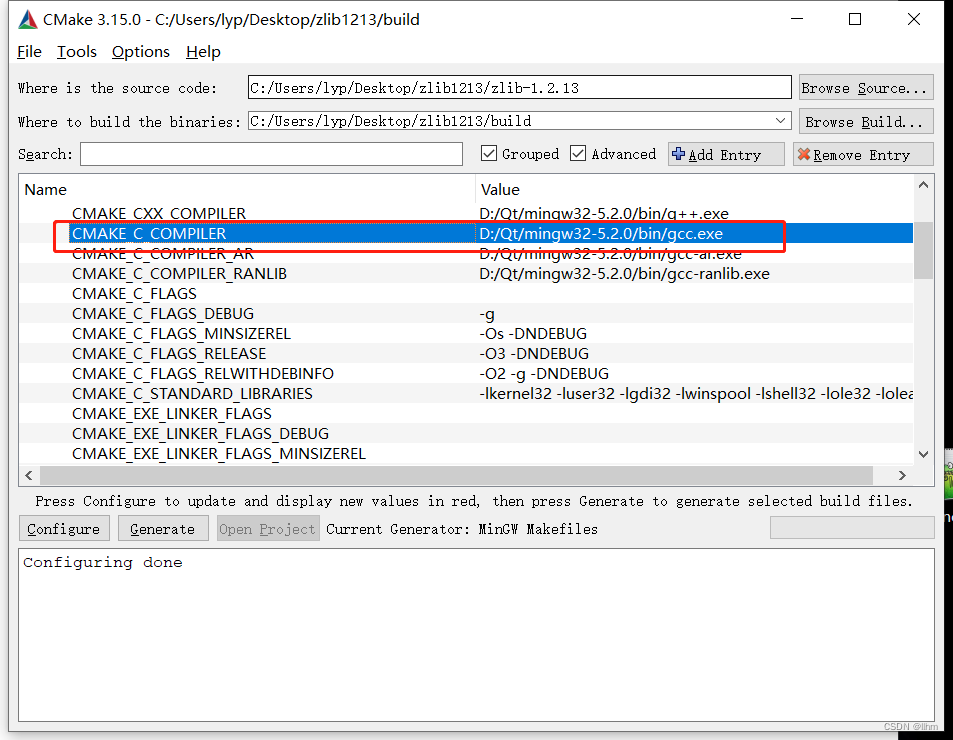
编译zlib
zlib被设计为一个免费的,通用的,法律上不受限制的-即不受任何专利保护的无损数据压缩库,几乎可以在任何计算机硬件和操作系统上使用。 官网:http://www.zlib.net/ 下载zlib源码:http://www.zlib.net/zlib1213.zip 备用地址&#x…...

如何让“ChatGPT自己写出好的Prompt的“脚本在这里
写个好的Prompt太费力了 在网上,你可能会看到很多人告诉你如何写Prompt,需要遵循各种规则,扮演不同的角色,任务明确、要求详细,还需要不断迭代优化。写一个出色的Prompt需要投入大量的时间和精力。甚至有一些公开的Pr…...

菜单选择shell
[rootes3 data]# vi action.sh #!/bin/bash . /etc/init.d/functionsecho -en "\E[$[RANDOM%731];1m"cat <<EOF请选择:1) 备份数据库2)清理日志3)软件升级4)软件回滚5)删库跑路EOFecho -en \E[0mread -p "请选择上面的项对应的数字1-5…...
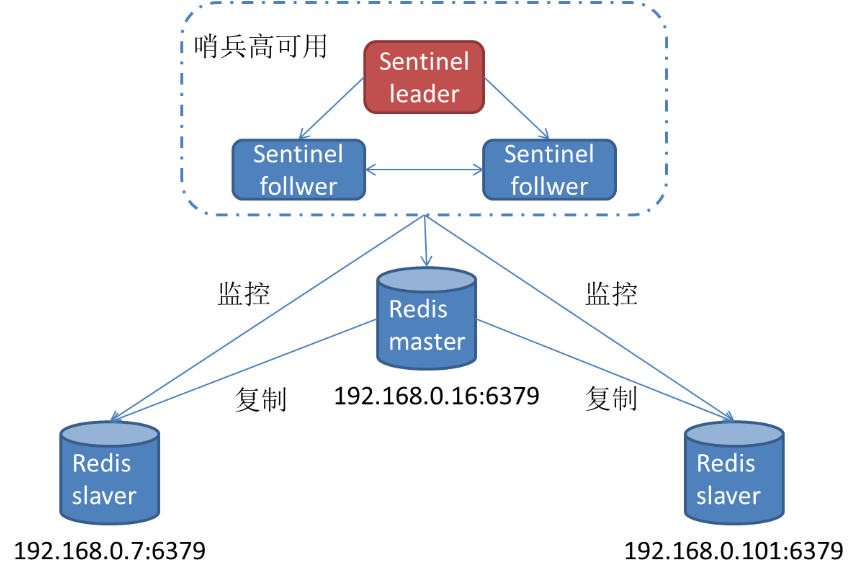
Redis高可用性详解
目录 编辑 高可用性: 主从复制(Master-Slave Replication): 主从复制的一般工作流程: 哨兵模式(Sentinel Mode): 哨兵模式的一般工作流程: 集群模式(…...
MySQL(1) ---- 数据库介绍与MySQL概述
介绍 1、什么是数据库? 数据库:DateBase(DB),是存储和管理数据的仓库。数据库管理系统:DataBase Management System(DBMS),操纵和管理数据库的大型软件。SQL࿱…...

面试题之软件测试流程
说说公司的软件测试流程,这,是常考的面试题之一。 不同公司的流程不一样,现状决定流程,没有绝对的对错。 以结果为导向,保证产品质量,提高测试效率,才是王道。 以下的流程为业界比较标准的流程&…...

MyBatis中#{}与${}的区别,与各自的应用场景
#{}和${}的区别: #{}: 底层使用PreparedStatement。特点:先进行SQL语句的编译,然后给SQL语句的占位符问号?传值。可以避免SQL注入的风险。 ${}:底层使用Statement。特点:先进行SQL语句的拼接,然后再对SQL语…...

泛型类相关
package com.test.test02;/* * GenericTest就是一个普通的类 * GenericTest<E>就是一个泛型类 * <>里面就是一个参数类型,但是这个类型是什么呢?这个类型现在是不确定的,相当于一个占位。 * 但是现在确定的是这个类型一定是一…...

一文速学数模-季节性时序预测SARIMA模型详解+Python实现
目录 前言 一、季节时间序列模型概述 二、SARIMA模型定义 三.SARIMA模型算法原理...
)
二叉树与图(C++刷题笔记)
二叉树与图(C刷题笔记) 113. 路径总和 II 力扣 从根节点深度遍历二叉树,先序遍历时,将节点存储至path栈中,使用path_val累加节点值 当遍历到叶子节点,检查path_val是否为sum,若是,…...

硬件答辩问题总结
一、电源纹波是什么,为什么LDO的小,DCDC的大1.电源纹波电源纹波 是指直流电源输出电压上叠加的 交流波动成分,表现为电压在理想直流值附近上下波动。2.LDO 纹波小原理LDO 内部是一个 调整管(可变电阻) 串联在输入和输出…...

Yokogawa AAI835-H50/K4A00模拟输入/输出模块
Yokogawa AAI835-H50/K4A00 模拟输入/输出模块产品特点:通道配置:共8个通道,含4路模拟输入和4路模拟输出。信号类型:所有通道均支持4-20mA标准电流信号。HART通信:支持HART协议,可与智能现场设备双向数字通…...

Arduino PWM转4-20mA工业电流信号:二阶滤波与V/I转换电路设计
1. 项目概述:从PWM到工业标准电流信号在工业自动化、过程控制和传感器领域,4-20 mA电流环是一个几乎无处不在的标准。它用4 mA代表测量值的下限(如0C),20 mA代表上限(如100C),这种设…...

亚马逊 Rufus 关停,Alexa 正式上线:卖家必须读懂的6条新规则
2026年5月13日,亚马逊官方正式宣布,下线Rufus,推出全新AI购物助手:Alexa for Shopping。但是,这不是粗暴地直接下线 Rufus,而是一次购物AI底层架构的重组 —— 将 Rufus 的商品专长 与 Alexa的用户理解力&a…...

智慧无人机巡检-无人机可见光红外数据集 无人机多模态检测数据集 红外与可见光检测数据集
智慧无人机巡检-无人机可见光红外数据集,已完成标注,可导出各种常用数据集,yolo,voc,coco等格式。可见光33000张,红外16100张,目标一张一个 无人机可见光红外目标数据集项目详细信息数据集名称无…...

金融合规审核为何人力堆积却仍漏洞百出?2026年RegTech演进与Agent全链路闭环解决方案
在2026年的金融监管环境下,合规审核已不再是简单的“查漏补缺”,而是演变为一场高强度的算力与逻辑博弈。尽管金融机构在合规成本上的投入逐年攀升,甚至不惜以“人海战术”填补流程断点,但监管罚单的数额与频率却并未显著下降。这…...

基于Arduino的智能蓝调节拍器:DIY音乐练习伴侣
1. 项目概述:一个能“演奏”蓝调的低成本节拍器玩乐器的人,对节拍器这东西又爱又恨。它像一位严厉的监工,用单调的“嘀嗒”声强迫你跟上节奏。但你想过没有,这个监工其实可以很有趣?几年前,我在练习蓝调吉他…...

通过用量看板分析团队大模型API消耗发现优化调用策略的机会
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过用量看板分析团队大模型API消耗发现优化调用策略的机会 作为团队的技术负责人,确保大模型API调用在满足业务需求的…...

保姆级教程:在Windows 10上用QEMU+Kylin搭建可内外网访问的完整开发环境
在Windows 10上构建QEMUKylin全功能开发环境的终极指南当开发者需要在本地快速搭建一个隔离的国产操作系统开发环境时,QEMU虚拟化方案配合银河麒麟系统能提供高度灵活的沙箱体验。本文将手把手带你完成从零配置到内外网联通的完整工作流,涵盖虚拟化环境部…...
)
Windows开机自动全屏打开指定网页?一个快捷方式参数就搞定(Chrome/Edge/Firefox教程)
Windows开机自动全屏展示网页的终极方案每次开机都要手动打开浏览器、输入网址、切换全屏模式?这种重复操作不仅浪费时间,还容易在重要演示时手忙脚乱。想象一下:电脑启动后自动全屏显示你的仪表盘、会议日程或是监控大屏,整个过程…...