VariantAutoencoder(VAE)中使用生成好的模型进行声音生成
文章目录
- 概述
- 一、soundgenerator.py文件
- soundgenerator.py实现代码
- 一、convert_spectrogram_to_audio方法
- librosa.db_to_amplitude
- librosa.istft
- generate方法
- 二、generate.py文件
- 实现代码
- load_fsdd函数说明
- select_spectrogram函数说明
- save_signals函数说明
- main函数说明
- 三、运行异常
- File Not Found
- KeyError: '/root/PycharmProjects/VAEGenerate/Mycode/fsdd/spectrogram/6_nicolas_15.wav.npy'
- 总结
概述
- 这部分主要是在已经训练好的模型的基础上,利用模型生成声音,主要是两个py文件,分别是soundgenerator.py和generate.py,
- 前一个文件是声明一个SoundGenerator类,实现如下功能
- 将频谱图中的db转为振幅
- 将频谱图转为波形图
- 后一个是具体调用的已经训练好的模型和SoundGenerator类,进行声音生成的文件。
- 前一个文件是声明一个SoundGenerator类,实现如下功能
- 下面是针对各个模块进行的说明,并展示最后的执行效果。
一、soundgenerator.py文件
soundgenerator.py实现代码
import librosafrom preprocess import MinMaxNormaliserclass SoundGenerator:""" Soundgenerator负责从频谱图生成对应的声音 """def __init__(self, vae, hop_length):self.vae = vaeself.hop_length = hop_lengthself._min_max_normaliser = MinMaxNormaliser(0, 1)def generate(self, spectrograms, min_max_values):generated_spectrograms, latent_representations = \self.vae.reconstruct(spectrograms)signals = self.convert_spectrograms_to_audio(generated_spectrograms, min_max_values)return signals, latent_representationsdef convert_spectrograms_to_audio(self, spectrograms, min_max_values):signals = []for spectrogram, min_max_value in zip(spectrograms, min_max_values):# reshape the log spectrogramlog_spectrogram = spectrogram[:, :, 0]# apply denormalisationdenorm_log_spec = self._min_max_normaliser.denormalise(log_spectrogram, min_max_value["min"], min_max_value["max"])# log spectrogram -> spectrogramspec = librosa.db_to_amplitude(denorm_log_spec)# apply Griffin-Limsignal = librosa.istft(spec, hop_length=self.hop_length)# append signal to "signals"signals.append(signal)return signals
一、convert_spectrogram_to_audio方法
def convert_spectrograms_to_audio(self, spectrograms, min_max_values):signals = []for spectrogram, min_max_value in zip(spectrograms, min_max_values):log_spectrogram = spectrogram[:, :, 0] # 对频谱图进行调整denorm_log_spec = self._min_max_normaliser.denormalise(log_spectrogram, min_max_value["min"], min_max_value["max"]) # 对数据进行反正则化,进行恢复spec = librosa.db_to_amplitude(denorm_log_spec) # 将分贝图转成振幅signal = librosa.istft(spec, hop_length=self.hop_length) # 使用反短傅立叶变化,将数据恢复到频域signals.append(signal) # 将数据加载signal中,并进行返回return signals
- 这部分是负责将频谱图转成音频文件,基本流程图下
- 对生成的数据,进行逆正则化,还原成原来的范围下的数据
- 将分贝频域图,转成振幅的数据模式librosa.db_to_amplitude
- 将时频图还原成,线性的,时间域的波形图
librosa.db_to_amplitude
参考连接
- 功能描述:将dB尺度下的频谱图转变成振幅频谱图,使用分贝来衡量振幅
- 原理:下面的公式知道就行了,不用记着
- d b t o a m p l i t u d e ( S d b ) = 10.0 ∗ ∗ ( 0.5 ∗ S d b / 10 + l o g 10 ( r e f ) ) db_to_amplitude(S_db) ~= 10.0**(0.5 * S_db/10 + log10(ref)) dbtoamplitude(Sdb) =10.0∗∗(0.5∗Sdb/10+log10(ref))
- 输入:
- 有分贝构成的数组
- 输出
- 是一个np.ndarray
- 线性振幅频谱图
librosa.istft
- 功能描述:
- 短时傅立叶变换的逆函数,将时频领域的频谱图转成时间序列的频域图
- 输入
- stft_matrix:需要转换的频谱图数组
- hop_length:窗口移动的步长
- 输出
- ynp.ndarray
- 有原来的stft_matrix重建之后的,时间序列的信号
generate方法
def generate(self, spectrograms, min_max_values):generated_spectrograms, latent_representations = \self.vae.reconstruct(spectrograms)signals = self.convert_spectrograms_to_audio(generated_spectrograms, min_max_values)return signals, latent_representations
- 这是生成函数的总函数,具体流程如下
- 调用vae模型的重建方法,根据潜在特征模型,生成新的频谱图
- 然后调用上一节将的函数,将频谱图转成波形,返回波形图和对应的特征表示
二、generate.py文件
实现代码
- 调用函数如下
- load_fsdd:加载频谱文件
- select_spectrograms:选择频谱文件
- save_signals:保存生成的文件
- main主要的执行函数
import os
import pickleimport numpy as np
import soundfile as sffrom soundgenerator import SoundGenerator
from vae import VAE
from train_vae import SPECTROGRAMS_PATHHOP_LENGTH = 256
SAVE_DIR_ORIGINAL = "samples/original/"
SAVE_DIR_GENERATED = "samples/generated/"
MIN_MAX_VALUES_PATH = "/home/valerio/datasets/fsdd/min_max_values.pkl"def load_fsdd(spectrograms_path):x_train = []file_paths = []for root, _, file_names in os.walk(spectrograms_path):for file_name in file_names:file_path = os.path.join(root, file_name)spectrogram = np.load(file_path) # (n_bins, n_frames, 1)""" 这部分不是很懂,需要了解一下,确定具体的一些要求 """x_train.append(spectrogram)file_paths.append(file_path)x_train = np.array(x_train)x_train = x_train[..., np.newaxis] # -> (3000, 256, 64, 1)return x_train, file_pathsdef select_spectrograms(spectrograms,file_paths,min_max_values,num_spectrograms=2):sampled_indexes = np.random.choice(range(len(spectrograms)), num_spectrograms)sampled_spectrogrmas = spectrograms[sampled_indexes]file_paths = [file_paths[index] for index in sampled_indexes]sampled_min_max_values = [min_max_values[file_path] for file_path infile_paths]print(file_paths)print(sampled_min_max_values)return sampled_spectrogrmas, sampled_min_max_valuesdef save_signals(signals, save_dir, sample_rate=22050):for i, signal in enumerate(signals):save_path = os.path.join(save_dir, str(i) + ".wav")sf.write(save_path, signal, sample_rate)if __name__ == "__main__":# initialise sound generatorvae = VAE.load("model")sound_generator = SoundGenerator(vae, HOP_LENGTH)# load spectrograms + min max valueswith open(MIN_MAX_VALUES_PATH, "rb") as f:min_max_values = pickle.load(f)specs, file_paths = load_fsdd(SPECTROGRAMS_PATH)# sample spectrograms + min max valuessampled_specs, sampled_min_max_values = select_spectrograms(specs,file_paths,min_max_values,5)# generate audio for sampled spectrogramssignals, _ = sound_generator.generate(sampled_specs,sampled_min_max_values)# convert spectrogram samples to audiooriginal_signals = sound_generator.convert_spectrograms_to_audio(sampled_specs, sampled_min_max_values)# save audio signalssave_signals(signals, SAVE_DIR_GENERATED)save_signals(original_signals, SAVE_DIR_ORIGINAL)
load_fsdd函数说明
def load_fsdd(spectrograms_path):x_train = []file_paths = []for root, _, file_names in os.walk(spectrograms_path):for file_name in file_names:file_path = os.path.join(root, file_name)spectrogram = np.load(file_path) # (n_bins, n_frames, 1)x_train.append(spectrogram)file_paths.append(file_path)x_train = np.array(x_train)x_train = x_train[..., np.newaxis] # -> (3000, 256, 64, 1)return x_train, file_paths
- 这部分是用来加载频谱图的,spectrograms_path保存的是频谱文件的地址,并将单个数据合并成数据集。
- 因为处理之后的频谱图是二维的,[n_bins,n_frames],但是模型是需要输入三维的数据,所以增加一个最后的维度,为1,充当channel数据
- 同时获取对应频谱文件的保存路径。
select_spectrogram函数说明
def select_spectrograms(spectrograms,file_paths,min_max_values,num_spectrograms=2):"""在加载的频谱文件数据spectrograms中,随机抽取num_specctrograms个频谱,并返回对应的min_max_values,以便进行逆正则化:param spectrograms:处理过之后的频谱文件:param file_paths:每一个频谱图的对应的文件路径,用于获取对应的最大最小值:param min_max_values:每一个频谱文件对应的最值:param num_spectrograms:需要提取的频谱图数量:return:"""sampled_indexes = np.random.choice(range(len(spectrograms)), num_spectrograms) # 随机采样sampled_spectrogrmas = spectrograms[sampled_indexes] # 获取抽样之后的数据图file_paths = [file_paths[index] for index in sampled_indexes] # 获取对应索引的文件路径sampled_min_max_values = [min_max_values[file_path] for file_path in # 获取对应频谱图的最大最小值索引file_paths]print(file_paths)print(sampled_min_max_values)return sampled_spectrogrmas, sampled_min_max_values # 返回采样之后频谱图以及对应的最值
- 在频谱图中随机抽样特定数量的样本数据,用于生成模型,并返回对应样本的最值,以便进行逆正则化
save_signals函数说明
import soundfile as sf
def save_signals(signals, save_dir, sample_rate=22050):"""将波形信号保存为对应wav文件:param signals:生成的波形信号:param save_dir:保存的路径:param sample_rate:采样率:return:"""for i, signal in enumerate(signals):save_path = os.path.join(save_dir, str(i) + ".wav")sf.write(save_path, signal, sample_rate)
- 这部分是将数据保存为对应的波形图,用到了soundfile包,这个python自带的包,用于保存对应的数据
main函数说明
"""
主要步骤
1、初始化一个sound generator实例
2、加载对应文件下的频谱图文件和最值文件
3、从频谱图和最值文件进行对应采样
4、生成与采样样例针对的音频
5、将生成的频谱图转成波形图
6、保存对应的音频信号
"""
# 初始化对应
vae = VAE.load("model")
sound_generator = SoundGenerator(vae, HOP_LENGTH)# load spectrograms + min max values
with open(MIN_MAX_VALUES_PATH, "rb") as f:min_max_values = pickle.load(f)specs, file_paths = load_fsdd(SPECTROGRAMS_PATH)# sample spectrograms + min max values
sampled_specs, sampled_min_max_values = select_spectrograms(specs,file_paths,min_max_values,5)# generate audio for sampled spectrograms
# 这里不仅仅生成了对应的信号,还返回了对应的特征空间,所以需要提前保存一下
signals, _ = sound_generator.generate(sampled_specs,sampled_min_max_values)# convert spectrogram samples to audio
# 注意这里是原来的频谱图也转成了对应的声音,主要是和生成的声音进行对比
original_signals = sound_generator.convert_spectrograms_to_audio(sampled_specs, sampled_min_max_values)# save audio signals
save_signals(signals, SAVE_DIR_GENERATED)
save_signals(original_signals, SAVE_DIR_ORIGINAL)
- 这个main函数串联起了soundgenerator.py文件和generate.py文件,包含了完整的生成函数的流程

三、运行异常
File Not Found
- 代码中,需要在当前的工程项目中创建两个文件

KeyError: ‘/root/PycharmProjects/VAEGenerate/Mycode/fsdd/spectrogram/6_nicolas_15.wav.npy’


- 这个字典是有问题的,说明是preprocess的问题,所以重新回过去修改代码。preprocess pipeline中save_feature中并没有返回对应的路径。


- 运行成功,生成对应的数据
总结
- 这部分已经根据给的声音成功生成了相关的声音,如果只讲这个,估计时间不够,所以我还需要将这部分的代码应用到对应的自动编码器中,然后对比一下对应的生成效果,同时,还需要看一下相关的理论知识,尝试使用不同的特征进行生成。
- 我在怀疑自己,这样写有什么意义?本来就不是那么复杂的东西,不过我自己太差了,还是得好好看吧。那我花那么久的时间,去实现这个,真的有意义吗?自己的研究方向又是什么那?哎,现在就是我想做,那就做。
相关文章:
VariantAutoencoder(VAE)中使用生成好的模型进行声音生成
文章目录 概述一、soundgenerator.py文件soundgenerator.py实现代码一、convert_spectrogram_to_audio方法librosa.db_to_amplitudelibrosa.istft generate方法 二、generate.py文件实现代码load_fsdd函数说明select_spectrogram函数说明save_signals函数说明main函数说明 三、…...
C++数据封装以及定义结构的详细讲解鸭~
名字:阿玥的小东东 博客主页:阿玥的小东东的博客_CSDN博客-python&&c高级知识,过年必备,C/C知识讲解领域博主 目录 定义结构 访问结构成员 结构作为函数参数 指向结构的指针 typedef 关键字 C 数据封装 数据封装的实例 设计策略 C 类 &…...

MySql 数据库的锁机制和原理
MySQL是一种流行的关系型数据库管理系统,广泛应用于各种Web应用程序和企业级应用程序中。在MySQL中,锁是一种用于控制并发访问的机制,它可以保证数据的一致性和完整性。本文将介绍MySQL的锁机制及原理,包括锁的类型、级别和实现原…...
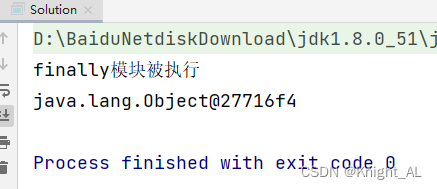
try catch finally 里面有return的执行顺序
目录 实例结论 实例 1.try和catch中有return时,finally里面的语句会被执行吗 我们可以来分别看看 (1)执行try中的return时 public class Solution {public static int show() {try {return 1;}finally{System.out.println("finally模块被执行");}}publi…...

美团前高级测试工程师教你如何使用web自动化测试
一、自动化测试基本介绍 1 自动化测试概述: 什么是自动化测试?一般说来所有能替代人工测试的方式都属于自动化测试,即通过工具和脚本来模拟人执行用例的过程。 2 自动化测试的作用 减少软件测试时间与成本改进软件质量 通过扩大测试覆盖率…...

MySql.Data.dll 因版本问题造成报错的处理
NetCore 链接MySQL 报 Character set ‘utf8mb3‘ is not supported by .Net Framework 异常解决_character set utf8mb3_csdn_aspnet的博客-CSDN博客 查看mysql版本号,两种办法: 第一种在数据库中执行查询:SELECT version; 第二种使用工具…...

囚徒困境——从博弈论的角度解释“美女配丑男”
前言 有一种很常见的现象,美女配丑男。其实这种现象背后是有一定科学原理的。本文将从博弈论的角度,从囚徒困境出发解释这一现象产生的原因。 囚徒困境 囚徒困境的经典案例 先来介绍一下经典的囚徒困境。 警方逮捕甲、乙两名嫌疑犯,但没有…...
运算符重载函数作为类的成员函数——有理数的约分
目录 一、题目 二、代码 三、算法分析 (一)数学表达式 (二) 代码实现 一)运算符重载函数 二)优化函数(实现有理数约分) 一、题目 通过运算符重载为类的成员函数来实现两个有…...

mysql数据库的内置函数--7
目录 内置函数 日期函数 字符串函数 数学函数 其它函数 内置函数 在mysql中这些函数用select进行使用 日期函数 函数描述NOW()返回当前的日期和时间CURDATE()返回当前的日期CURTIME()返回当前的时间DATE()从日期或日期/时间表达式中提取日期部分TIME()从日期或日期/时间…...

DS3800HPIB 有效执行任务的所有程序
DS3800HPIB是通用电气公司生产的Speedtronic Mark IV系列的一部分。这DS3800HPIB是一种大型电路板,具有八个连接端子,电路板两侧的尺寸各不相同。左下角有一个红色小方块,上面有一个拨动开关。这DS3800HPIB有大约50个天蓝色的小二极管。这DS3…...

图像比对、人像比对和人脸识别的区别是什么?
图像比对、人像比对和人脸识别都是图像处理技术,但是它们的实现方式和应用场景均有所不同。 图像比对 图像比对是指通过计算机视觉技术将两张或多张图片进行相似度比较。主要包括图像特征提取、匹配和评估等步骤,通常使用神经网络等深度学习技术来实现…...

python中的抽象基类
目录 协议和鸭子类型抽象基类定义抽象基类使用抽象基类直接继承通过注册(register) __subclasshook__魔法方法 协议和鸭子类型 python中有大量的魔法方法,python所谓基于协议编程,就是依赖这些魔法方法。 什么意思呢?…...

耗时几个月,终于决定把原本想用于商业的系统开源了
前言 嗨,大家好,我是希留,一个被迫致力于全栈开发的老菜鸟。 今天又来给小伙伴们分享一个基于 SpringBoot Vue 实现的前后端分离后台管理系统项目; 简介 这个项目是基于xiliu-tenant脚手架项目搭建而成,原本是帮朋…...
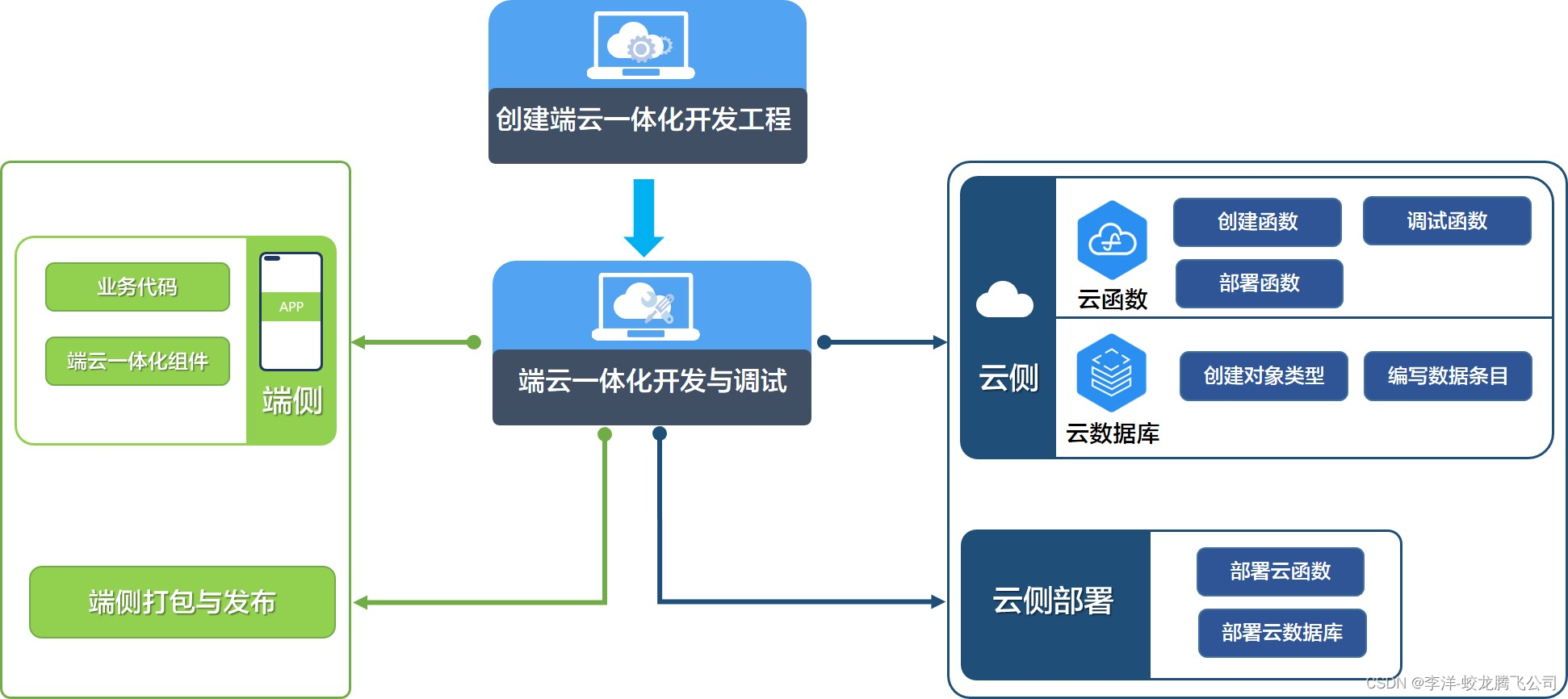
HarmonyOS应用端云一体化开发主要流程
图示 主要步骤 序号 阶段 任务 说明 1 创建端云一体化开发工程 选择工程类型与云开发模板 确定工程类型:选择“Application”或“Atomic Service”页签,确定创建的是HarmonyOS应用工程还是原子化服务工程。选择云开发模板,包括通用云开…...

NoSQL之 Redis配置与优化
NoSQL之 Redis配置与优化 ---------------------- 关系数据库与非关系型数据库 ---------------------------------------- ●关系型数据库: 关系型数据库是一个结构化的数据库,创建在关系模型(二维表格模型)基础上,一…...

Redis哨兵模式
1.哨兵模式是什么 解释一 哨兵巡查监控 master主机是否故障,如果故障了,根据投票数自动将一个从库转换为新数据库,继续对外服务。 解释二 监控redis 的运行状态,包括master和slave当master宕机后,能自动将slave切换…...
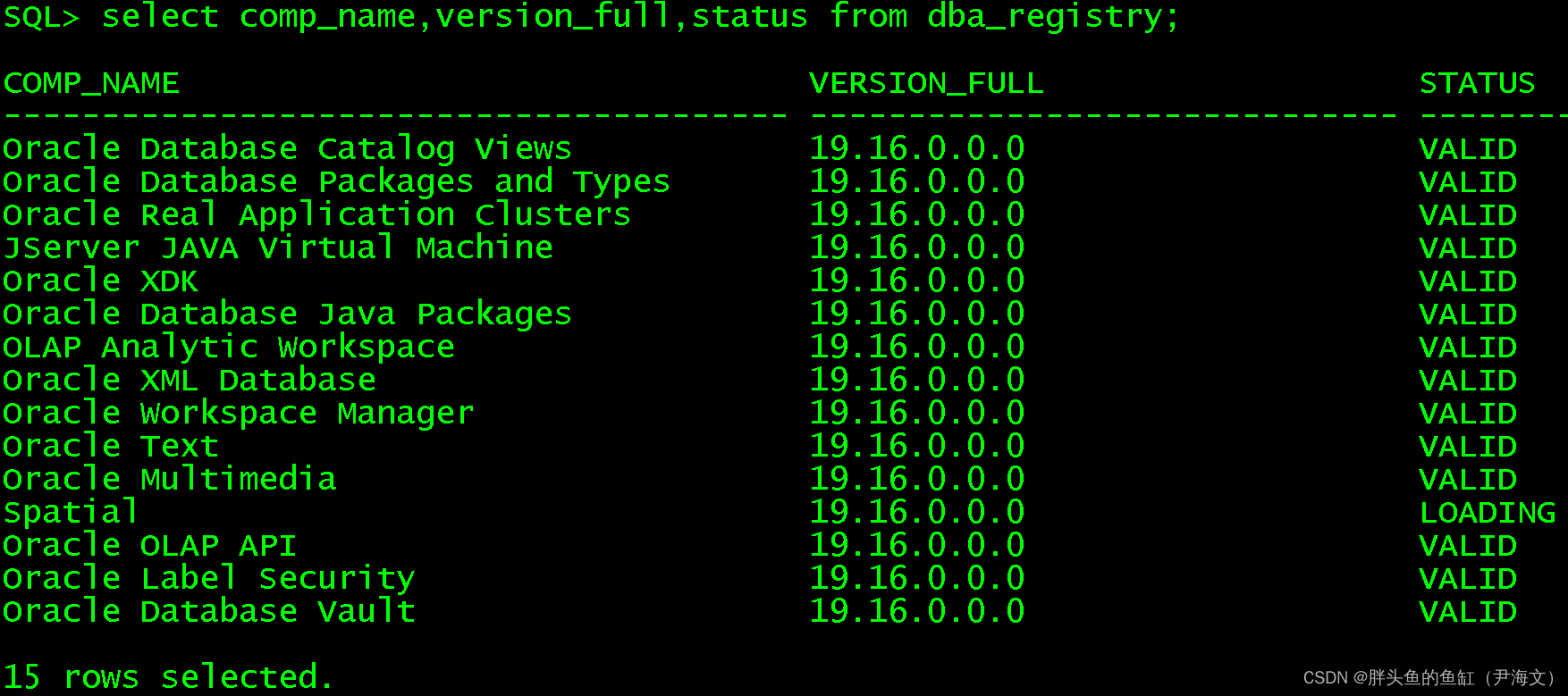
数据库管理-第七十六期 如何升级19c RAC(20230516)
数据库管理 2023-05-16 第七十六期 如何升级19c RAC1 回头处理2 升级AHF3 升级GI及DB3.1 拷贝所需文件3.2 升级OPatch3.3 升级GI与DB3.4 应用SQL变更 4 升级OJVM4.1 解压补丁4.2执行补丁冲突检查:4.3 升级OJVM4.4 应用SQL变更 5 最终验证总结 第七十六期 如何升级19…...
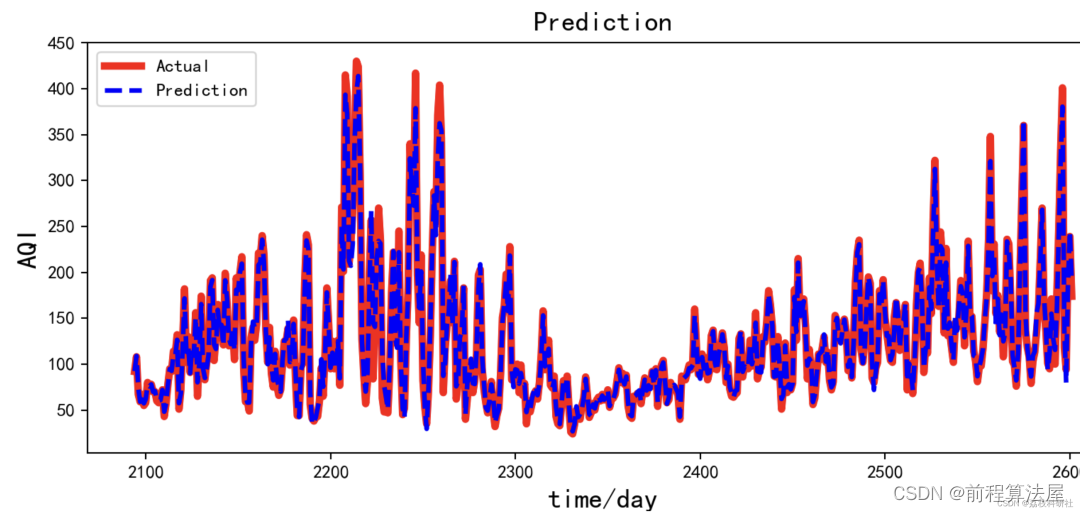
组合预测模型 | ARIMA-CNN-LSTM时间序列预测(Python)
组合预测模型 | ARIMA-CNN-LSTM时间序列预测(Python) 目录 组合预测模型 | ARIMA-CNN-LSTM时间序列预测(Python)预测结果基本介绍程序设计参考资料 预测结果 基本介绍 ARIMA-CNN-LSTM是一种结合了传统时间序列模型和深度学习模型的…...
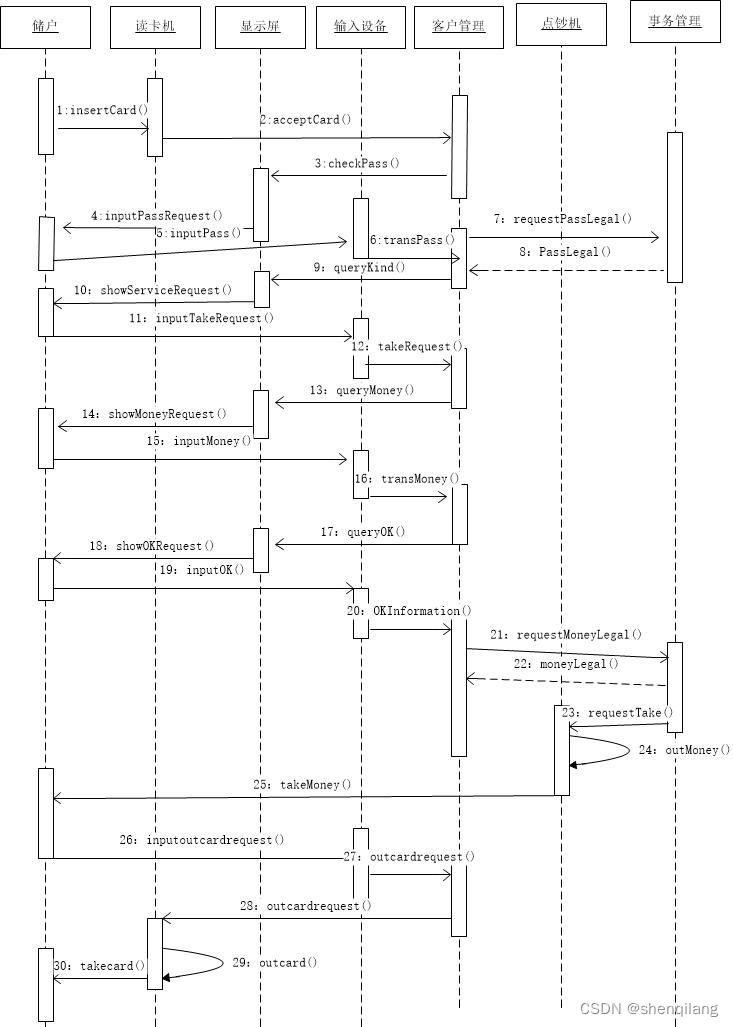
实验四 面向对象分析与设计——UML类图与时序图
一、实验目的: 掌握面向对象分析中静态结构模型与动态行为模型的基本思想。学会识别系统中的类、类的属性和操作以及类之间的关系,掌握UML类图的绘制方法。了解时序图的作用和组成元素,掌握UML时序图的绘制方法。 二、实验仪器及实验环境&a…...
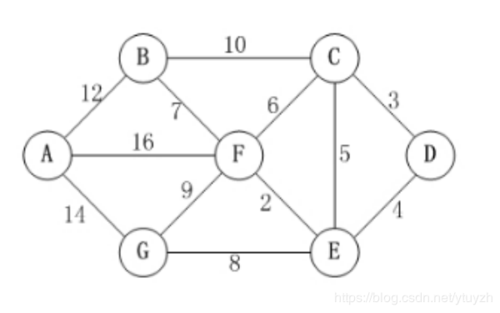
最短路径问题
如图,设定源点为D,终点为A,则D到A的最短路径是多少? 算法思路: 第一步,从源点D出发,此时能到达的选择是C和E,我们根据路径长度选择最少的作为下一个节点,于是选择C&…...

PA100K数据集实战:从下载到结构化解析全流程
1. PA100K数据集初探:为什么选择它?如果你正在研究行人属性识别,PA100K绝对是个绕不开的宝藏数据集。这个数据集包含了10万张真实监控场景下的行人图像,每张图都标注了26种常见属性——从衣着风格(比如是否穿T恤、裙子…...

D3KeyHelper:暗黑3玩家的智能按键助手,告别重复操作疲劳
D3KeyHelper:暗黑3玩家的智能按键助手,告别重复操作疲劳 【免费下载链接】D3keyHelper D3KeyHelper是一个有图形界面,可自定义配置的暗黑3鼠标宏工具。 项目地址: https://gitcode.com/gh_mirrors/d3/D3keyHelper 你是否曾在《暗黑破坏…...

为什么视频代剪辑会影响你的内容传播效果
为什么你精心拍的视频,发出去却没人看? 你有没有过这样的经历:花了一整天拍Vlog,素材画质高清、内容真实,可一剪出来就显得平淡无奇,点赞寥寥?或者婚礼当天感动全场,回看成片却像流水…...

双稳健机器学习:用正交性与交叉拟合解决因果推断中的ML偏差
1. 项目概述:当机器学习遇见因果推断的“干扰”难题在实证研究的日常工作中,我们常常面临一个核心矛盾:我们真正关心的,往往只是一个或几个关键参数——比如一项政策对就业率的平均影响(平均处理效应,ATE&a…...

国内大学生常用的AI写作辅助平台有哪些?
国内高校学生常用的 AI 写作辅助平台,以本土化全流程工具为主,结合通用大模型与专项功能模块,覆盖选题构思、大纲搭建、初稿撰写、语言润色、降重处理、查重检测及格式排版等关键环节,以下是主流平台详解与对比: 一、本…...

在Node.js服务中集成Taotoken实现稳定的大模型能力调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在Node.js服务中集成Taotoken实现稳定的大模型能力调用 对于需要在后端服务中集成AI功能的Node.js开发者而言,直接对接…...

告别手动预约:i茅台自动预约系统5分钟部署指南
告别手动预约:i茅台自动预约系统5分钟部署指南 【免费下载链接】campus-imaotai i茅台app自动预约,每日自动预约,支持docker一键部署(本项目不提供成品,使用的是已淘汰的算法) 项目地址: https://gitcode…...

AhMyth位置跟踪:GPS定位与地理围栏技术深度解析
AhMyth位置跟踪:GPS定位与地理围栏技术深度解析 【免费下载链接】AhMyth Cross-Platform Android Remote Administration Tool | The only maintained version of AhMyth on github | A revival of the original repository at https://GitHub.com/AhMyth/AhMyth-An…...

Python到Android的魔法之旅:5步将你的代码变成移动应用
Python到Android的魔法之旅:5步将你的代码变成移动应用 【免费下载链接】python-for-android Turn your Python application into an Android APK 项目地址: https://gitcode.com/gh_mirrors/py/python-for-android 想象一下,你花了几个月时间精心…...

3步解决英雄联盟回放难题:ROFL-Player终极使用指南
3步解决英雄联盟回放难题:ROFL-Player终极使用指南 【免费下载链接】ROFL-Player (No longer supported) One stop shop utility for viewing League of Legends replays! 项目地址: https://gitcode.com/gh_mirrors/ro/ROFL-Player 你是否曾经遇到过这样的烦…...