SpringCloud概述
前言
什么是微服务?
微服务是一种面向服务的架构(SOA)风格,其中,应用程序被构建为多个不同的小型服务的集合而不是单个应用程序。与单个程序不同的是,微服务让你可以同时运行多个独立的应用程序,而这些独立的应用程序可以使用不同的编码或编程语言来创建。庞大而又复杂的应用程序可以由多个可自行执行的简单而又独立的程序所组成。这些较小的程序组合在一起,可以提供庞大的单程序所具备的所有功能。
什么是分布式服务?
分布式结构就是将一个完整的系统,按照业务功能,拆分成一个个独立的子系统,在分布式结构中,每个子系统就被称为“服务”。这些子系统能够独立运行在web容器中,它们之间通过RPC方式通信。
分布式服务与微服务的区别
1)微服务的各个服务都是独立的组件存在。
2)独立的组件形式,方便模块改造优化,或集群部署部署用于应对高并发。
3)系统之间的耦合度降低,非常容易扩展。
4)复用性强。
介绍
Spring Cloud是一个基于Spring Boot实现的云应用开发工具,也是微服务系统架构的一站式解决方案。它为基于JVM的云应用开发中的服务发现注册 、配置中心 、消息总线 、负载均衡 、断路器 、数据监控 等操作提供了一种简单的开发方式。通俗地讲,Spring Cloud 就是用于构建微服务开发和治理的框架集合。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HMAx7fmZ-1684303939304)(/Users/zhaoyanhong/Library/Application Support/typora-user-images/image-20220906153940245.png)]
微服务的特征:
1)微服务单元按照数据结构特性或者领域来划分
2)微服务通过HTTP来通讯,数据格式为json或者xml。
3)微服务的数据库相对独立
4)微服务的自动化部署。可使用jenkins、Docker、Kubernetes
5)服务集中管理。Eureka、Zookeeper、Consul、Nacos、Etcd(服务注册发现组件)
6)分布式架构(集群部署)。
7)熔断机制/防止雪崩。Hystrix
8)链路跟踪。Sleuth 、Skywalking
9)完整的安全机制。用户验证、权限验证、资源保护等
10)完整的实时日志。
Zookeeper/Eureka/nacos:服务注册与发现
**服务注册中心本质上是为了解耦服务提供者和服务消费者。**对于任何一个微服务,原则上都应存在或者支持多个提供者,这是由微服务的分布式属性决定的。更进一步,为了支持弹性扩缩容特性,一个微服务的提供者的数量和分布往往是动态变化的,也是无法预先确定的。因此,原本在单体应用阶段常用的静态LB机制就不再适用了,需要引入额外的组件来管理微服务提供者的注册与发现,而这个组件就是服务注册中心。
服务注册需要具备的能力:
- 服务提供者把自己的协议地址注册到Nacos server
- 服务消费者需要从Nacos Server上去查询服务提供者的地址(根据服务名称)
- Nacos Server需要感知到服务提供者的上下线的变化
- 服务消费者需要动态感知到Nacos Server端服务地址的变化
Zookeeper
Zookeeper 是分布式应用程序协调服务, 用于维护配置信息、命名、提供分布式同步和提供组服务。客户端注册是服务自身要负责注册与注销的工作。**当服务启动后向注册中心注册自身,当服务下线时注销自己,期间还需要和注册中心保持心跳。**心跳不一定要客户端来做,也可以由注册中心负责(这个过程叫探活)。这种方式的缺点是注册工作与服务耦合在一起,不同语言都要实现一套注册逻辑。
Zookeeper数据模型的结构类似文件系统。
Zookeeper提供了什么服务
1)文件系统
每个子目录项如 NameService 都被称作为znode,和文件系统一样,我们能够自由的增加、删除znode,在一个znode下增加、删除子znode,唯一的不同在于znode是可以存储数据的。
有四种类型的znode:
1、PERSISTENT-持久化目录节点
客户端与zookeeper断开连接后,该节点依旧存在
2、PERSISTENT_SEQUENTIAL-持久化顺序编号目录节点
客户端与zookeeper断开连接后,该节点依旧存在,只是Zookeeper给该节点名称进行顺序编号
3、EPHEMERAL-临时目录节点
客户端与zookeeper断开连接后,该节点被删除
4、EPHEMERAL_SEQUENTIAL-临时顺序编号目录节点
客户端与zookeeper断开连接后,该节点被删除,只是Zookeeper给该节点名称进行顺序编号
2)通知机制。
客户端注册监听它关心的目录节点,当目录节点发生变化(数据改变、被删除、子目录节点增加删除)时,zookeeper会通知客户端。
功能特性
1.命名服务 2.配置管理 3.集群管理 4.分布式锁 5.队列管理
命名服务
在zookeeper的文件系统里创建一个目录,即有唯一的path。在我们使用tborg无法确定上游程序的部署机器时即可与下游程序约定好path,通过path即能互相探索发现。
配置管理
服务配置通常变动大,利用zookeeper特性,保存在 Zookeeper 的某个目录节点中,然后所有相关应用程序对这个目录节点进行监听,一旦配置信息发生变化,每个应用程序就会收到 Zookeeper 的通知,然后从 Zookeeper 获取新的配置信息应用到系统,无需代码变更。
Zookeeper集群管理
Zookeeper内部可以组成集群。一个Zookeeper集群通常由一组机器构成,组成Zookeeper集群的而每台机器都会在内存中维护当前服务器状态,并且每台机器之间都相互通信。集群是选举机制(第一次启动选举机制、非第一次启动选举机制/任意服务器故障),股适合安装奇数服务器,至少3台。
分布式锁
Zookeeper 是基于临时顺序节点以及 Watcher 监听器机制实现分布式锁的,且它的每个节点的变更都是原子性的。它的每一个节点都是一个天然的顺序发号器。ZooKeeper 节点的递增有序性可以确保锁的公平。ZooKeeper 的节点监听机制,可以保障占有锁的传递有序而且高效。ZooKeeper 的节点监听机制,能避免羊群效应。
队列管理
两种类型的队列:
1、同步队列,当一个队列的成员都聚齐时,这个队列才可用,否则一直等待所有成员到达。
2、队列按照 FIFO 方式进行入队和出队操作。 和分布式锁服务中的控制时序场景基本原理一致,入列有编号,出列按编号。
分布式与数据复制
Zookeeper作为一个集群提供一致的数据服务,自然,它要在所有机器间做数据复制。数据复制的好处:
1、容错:一个节点出错,不致于让整个系统停止工作,别的节点可以接管它的工作;
2、提高系统的扩展能力 :把负载分布到多个节点上,或者增加节点来提高系统的负载能力;
3、提高性能:让客户端本地访问就近的节点,提高用户访问速度。
从客户端读写访问的透明度来看,数据复制集群系统分下面两种:
1、写主(WriteMaster) :对数据的修改提交给指定的节点。读无此限制,可以读取任何一个节点。这种情况下客户端需要对读与写进行区别,俗称读写分离;
2、写任意(Write Any):对数据的修改可提交给任意的节点,跟读一样。这种情况下,客户端对集群节点的角色与变化透明。 对zookeeper来说,它采用的方式是写任意。通过增加机器,它的读吞吐能力和响应能力扩展性非常好,而写,随着机器的增多吞吐能力肯定下降(这也是它建立observer的原因),而响应能力则取决于具体实现方式,是延迟复制保持最终一致性,还是立即复制快速响应。
Zookeeper工作原理
Zookeeper 的核心是原子广播,这个机制保证了各个Server之间的同步。实现这个机制的协议叫做Zab协议。Zab协议有两种模式,它们分别是恢复模式(选主)和广播模式(同步)。当服务启动或者在领导者崩溃后,Zab就进入了恢复模式,当领导者被选举出来,且大多数Server完成了和 leader的状态同步以后,恢复模式就结束了。状态同步保证了leader和Server具有相同的系统状态。
**为了保证事务的顺序一致性,zookeeper采用了递增的事务id号(zxid)来标识事务。**所有的提议(proposal)都在被提出的时候加上了zxid。实现中zxid是一个64位的数字,它高32位是epoch用来标识leader关系是否改变,每次一个leader被选出来,它都会有一个新的epoch,标识当前属于那个leader的统治时期。低32位用于递增计数。
如何实现服务注册与发现
服务提供方(用户服务)启动成功后将服务信息注册到Zookeeper,服务信息包括实例的 ip、端口等元信息。注册成功 Zookeeper 还可以通过心跳监测来动态感知实例变化。
服务消费方(订单服务)需要调用用户服务的接口,但因为不知道实例的 ip、端口等信息,只能从 Zookeeper 中获取调用地址列表,然后进行调用,这个过程成为服务的订阅。
订阅成功后服务消费方可以将调用列表缓存在本地,这样不用每次都去调用 Zookeeper 获取。一旦 Zookeeper感知到用户服务实例变化后就会通知给服务消费方,服务消费方拿到结果后就会更新本地缓存,这个过程称之为通知。
Zookeeper的重点特性
1)集群只能一个领导+多个跟随者 ;奇数 ;并且只要半数以上节点存活,集群就才能正常服务
2)全局数据一致,每个server保存一份相同的数据副本,
3)同一个Client更新请求顺序执行
4)数据更行原子性
5)树状目录结构
6)实时性。一定时间访问内,客户端读到最新数据
7)持久节点。即使断开连接,节点也不会被删除
8)持久有序节点。注册节点的时候存在序号
9)临时节点注册之后,与Zookeeper服务端断开连接后,该节点被删除
10)节点监听机制,用于消息通知。
Eureka
Eureka 就是 Netflix 的 服务发现框架 。Eureka是一个基于REST的服务,用于定位服务,以实现云端中间层服务发现和故障转移。服务注册与发现对于微服务架构来说是非常重要的,有了服务发现与注册,只需要使用服务的标识符,就可以访问到服务,而不需要修改服务调用的配置文件了。
服务发现:其实就是一个“中介”,整个过程中有三个角色:服务提供者(卖房子出租房子的)、服务消费者(租客买主)、服务中介(房屋中介)。
服务提供者: 就是提供一些自己能够执行的一些服务给外界。
服务消费者: 就是需要使用一些服务的“用户”。
服务中介: 其实就是服务提供者和服务消费者之间的“桥梁”,服务提供者可以把自己注册到服务中介那里,而服务消费者如需要消费一些服务(使用一些功能)就可以在服务中介中寻找注册在服务中介的服务提供者。
基础概念
服务注册 Register:
当 Eureka 客户端向 Eureka Server 注册时,它提供自身的元数据,比如IP地址、端口,运行状况指示符URL,主页等。
服务续约 Renew:
Eureka 客户会每隔30秒(默认情况下)发送一次心跳来续约。 通过续约来告知 Eureka Server 该 Eureka 客户仍然存在,没有出现问题。 正常情况下,如果 Eureka Server 在90秒没有收到 Eureka 客户的续约,它会将实例从其注册表中删除。
获取注册列表信息 Fetch Registries:
Eureka 客户端从服务器获取注册表信息,并将其缓存在本地。客户端会使用该信息查找其他服务,从而进行远程调用。该注册列表信息定期(每30秒钟)更新一次。每次返回注册列表信息可能与 Eureka 客户端的缓存信息不同, Eureka 客户端自动处理。如果由于某种原因导致注册列表信息不能及时匹配,Eureka 客户端则会重新获取整个注册表信息。
Eureka 服务器缓存注册列表信息,整个注册表以及每个应用程序的信息进行了压缩,压缩内容和没有压缩的内容完全相同。Eureka 客户端和 Eureka 服务器可以使用JSON / XML格式进行通讯。在默认的情况下 Eureka 客户端使用压缩 JSON 格式来获取注册列表的信息。
服务下线 Cancel:
Eureka客户端在程序关闭时向Eureka服务器发送取消请求。 发送请求后,该客户端实例信息将从服务器的实例注册表中删除。该下线请求不会自动完成,它需要调用以下内容:DiscoveryManager.getInstance().shutdownComponent();
服务剔除 Eviction:
在默认的情况下,当Eureka客户端连续90秒(3个续约周期)没有向Eureka服务器发送服务续约,即心跳,Eureka服务器会将该服务实例从服务注册列表删除,即服务剔除。
续约机制
1)服务注册。客户端要向服务端注册时,需提供自身的元数据(IP、端口等)
2)服务续约。每隔30秒发送一次心跳来进行服务续约。(缓冲)
3)获取服务注册列表。从服务器获取服务列表,并缓冲到本地
4)服务下线。客户端关闭时向服务端发送下线请求,服务做下线处理
5)服务剔除。客户端连续90秒如果没有向服务端进行续约就会被剔除。
Eureka的保护模式
当新的Server出现,从相邻peer节点读取所有服务实例,如果从相邻peer获取信息失败,会尝试从其他peer节点获取。
server拥有所有的服务实例后,会根据配置设置服务续约的阈值。在任何时间,如果接收到的服务续约低于该值配置的百分比(默认15分钟,百分比为85%),就开启自我保护模式,不在剔除注册服务的信息。
选择的原因:完全开源、而且跟其他组件很容易实现服务注册、负载均衡、熔断、路由等功能。
服务端配置
另外还需要在启动类中设置 @EnableEurekaServer 注解开启 Eureka 服务
eureka:instance:hostname: xxxxx # 主机名称prefer-ip-address: true/false # 注册时显示ipserver:enableSelfPreservation: true # 启动自我保护renewalPercentThreshold: 0.85 # 续约配置百分比
客户端配置
eureka:client:register-with-eureka: true/false # 是否向注册中心注册自己fetch-registry: # 指定此客户端是否能获取eureka注册信息service-url: # 暴露服务中心地址defaultZone: http://xxxxxx # 默认配置instance:instance-id: xxxxx # 指定当前客户端在注册中心的名称
Nacos
Nacos 致力于发现、配置和管理微服务。Nacos 提供了一组简单易用的特性集,帮助快速实现动态服务发现、服务配置、服务元数据及流量管理。是Spring Cloud A 中的服务注册发现组件,类似于Consul、Eureka,同时它又提供了分布式配置中心的功能,这点和Consul的config类似,支持热加载。
实现原理
服务注册时在服务端本地会通过轮询注册中心集群节点地址进行服务得注册,在注册中心上,即Nacos Server上采用了Map保存实例信息,当然配置了持久化的服务会被保存到数据库中,在服务的调用方,为了保证本地服务实例列表的动态感知,Nacos与其他注册中心不同的是,采用了 Pull/Push同时运作的方式。
四大功能
1)服务发现与服务健康检查
Nacos 支持基于 DNS 和基于 RPC 的服务发现。服务提供者使用原生SDK、OpenAPI、或一个独立的Agent 注册 Service 后,服务消费者可以使用DNS或HTTP&API查找和发现服务。
Nacos 提供对服务的实时的健康检查,阻止向不健康的主机或服务实例发送请求。Nacos 支持传输层 (PING 或 TCP)和应用层(如 HTTP、MySQL、用户自定义)的健康检查。对于复杂的云环境和网络拓扑环境中(如 VPC、边缘网络等)服务的健康检查,Nacos提供了 agent 上报模式和服务端主动检测2种健康检查模式。Nacos还提供了统一的健康检查仪表盘,帮助您根据健康状态管理服务的可用性及流量。
2)动态配置管理
动态配置服务允许在所有环境中以几种和动态的方式管理所有服务的配置,Nacos消除了在更新配置时重新部署应用程序,这种配置的更改更加高效和灵活。
动态配置服务可以以中心化、外部化和动态化的方式管理所有环境的应用配置和服务配置。动态配置消除了配置变更时重新部署应用和服务的需要,让配置管理变得更加高效和敏捷。配置中心化管理让实现无状态服务变得更简单,让服务按需弹性扩展变得更容易。
Nacos 提供了一个简洁易用的UI帮助管理所有的服务和应用的配置。Nacos 还提供包括配置版本跟踪、金丝雀发布、一键回滚配置以及客户端配置更新状态跟踪在内的一系列开箱即用的配置管理特性,帮助您更安全地在生产环境中管理配置变更和降低配置变更带来的风险。
3)动态DNS服务
Nacos服务支持权重路由,可以用于实现中间层负载均衡、更灵活的路由策略、流量控制以及数据中心内网的简单DNS解析服务。动态DNS服务还能让您更容易地实现以DNS 协议为基础的服务发现,以帮助消除耦合到厂商私有服务发现 API 上的风险。
Nacos 提供了一些简单的 DNS APIs 帮助管理服务的关联域名和可用的 IP:PORT 列表.
4)服务和元数据管理
可以从微服务平台建设的视角管理数据中心的所有服务及元数据,包括管理服务的描述、生命周期、服务的静态依赖分析、服务的健康状态、服务的流量管理、路由及安全策略、服务的SLA 以及最首要的 metrics 统计数据。
Nacos原理
Nacos注册中心分为server与client,server采用Java编写,为client提供注册发现服务与配置服务。而client可以用多语言实现,client与微服务嵌套在一起,nacos提供sdk和openApi,如果没有sdk也可以根据openApi手动写服务注册与发现和配置拉取的逻辑。
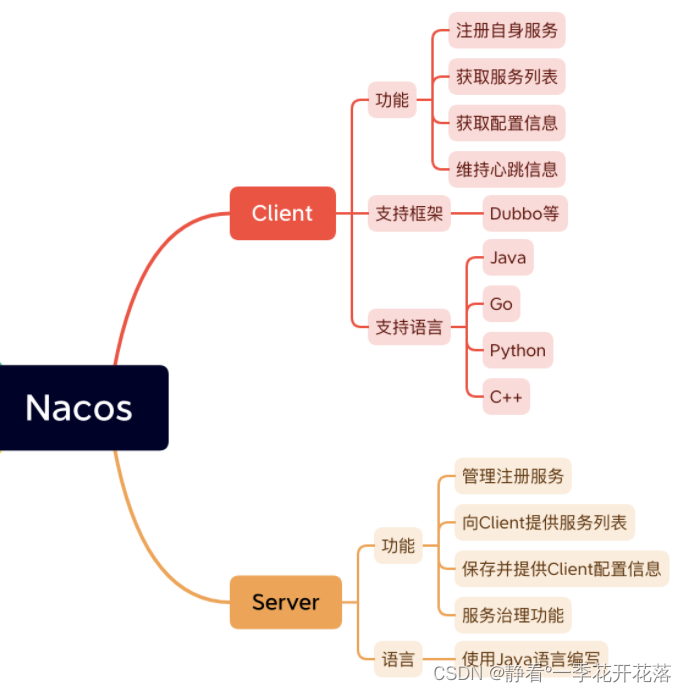
Nacos注册概括来说有6个步骤:
0、服务容器负责启动,加载,运行服务提供者。
1、服务提供者在启动时,向注册中心注册自己提供的服务。
2、服务消费者在启动时,向注册中心订阅自己所需的服务。
3、注册中心返回服务提供者地址列表给消费者,如果有变更,注册中心将基于长连接推送变更数据给消费者。
4、服务消费者,从提供者地址列表中,基于软负载均衡算法,选一台提供者进行调用,如果调用失败,再选另一台调用。
5、服务消费者和提供者,在内存中累计调用次数和调用时间,定时每分钟发送一次统计数据到监控中心。
Nacos 服务注册与订阅的完整流程
Nacos 客户端进行服务注册有两个部分组成,一个是将服务信息注册到服务端,另一个是像服务端发送心跳包,这两个操作都是通过 NamingProxy 和服务端进行数据交互的。
Nacos 客户端进行服务订阅时也有两部分组成,一个是不断从服务端查询可用服务实例的定时任务,另一个是不断从已变服务队列中取出服务并通知 EventListener 持有者的定时任务。服务消费方是通过RestTemplate调用提供方的服务。
心跳检测
1)服务注册的策略的是每5秒向nacos server发送一次心跳,心跳带上了服务名,服务ip,服务端口等信息。
2) nacos server也会向client 主动发起健康检查,支持tcp/http检查。如果15秒内无心跳且健康检查失败则认为实例不健康,如果30秒内健康检查失败则剔除实例。
服务领域模型
Nacos服务领域模型主要分为命名空间、集群、服务。
1)在服务级别,保存了健康检查开关、元数据、路由机制、保护阈值等设置,
2)集群保存了健康检查模式、元数据、同步机制等数据,
3)命名空间/实例保存了该实例的ip、端口、权重、健康检查状态、下线状态、元数据、响应时间。
其他
1)Nacos中的负责均衡底层是如何实现的?
通过内置的Ribbon实现的,nacos(部分版本)默认的负载均衡策略是轮询,然后基于这些算法从服务实例中获取一个实例为消费方法提供服务
2)Ribbon 内置的负载策略都有哪些?
8种,可以通过查看IRule接口的实现类进行分析
3)@LoadBalanced的作用是什么?
用于告诉Spring框架,在使用RestTempalte进行服务调用时,这个调用过程会被一个拦截器进行拦截,然后在拦截器内部,启动负载均衡策略。
4)我们可以自己定义负载均衡策略吗?
可以,基于IRule接口进行策略定义,也可以参考NacosRule进行实现
小结
Nacos除了服务的注册发现之外,还支持动态配置服务。动态配置服务可以让您以中心化、外部化和动态化的方式管理所有环境的应用配置和服务配置。动态配置消除了配置变更时重新部署应用和服务的需要,让配置管理变得更加高效和敏捷。配置中心化管理让实现无状态服务变得更简单,让服务按需弹性扩展变得更容易。一句话概括就是Nacos = Spring Cloud注册中心 + Spring Cloud配置中心。
服务发现产品对比
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SNdDbcNh-1684303939306)(/Users/zhaoyanhong/Library/Application Support/typora-user-images/image-20230516113253459.png)]
- Eureka: 符合AP原则 为了保证了可用性,
Eureka不会等待集群所有节点都已同步信息完成,它会无时无刻提供服务。 - Zookeeper: 符合CP原则 为了保证一致性,在所有节点同步完成之前是阻塞状态的。
- Nacos与eureka都支持服务注册和服务拉取以及提供者心跳方式做健康检测。
- Nacos 集群默认采用 AP 方式,当集群中存在非临时实例时,采用 CP 模式; Eureka 采用 AP 方式
Ribbon:基于客户端的负载均衡组件。
前言
Ribbon是Netflix发布的负载均衡器,他有助于控制http和TCP客户端的行为,为Ribbon配置服务提供者的地址列表后,ribbon就可基于某种负载均衡算法,自动的帮助服务消费者去请求。
Ribbon默认为我们提供了很多的负载均衡算法,例如轮询、随机等,我们也可为ribbon实现自定义的负载均衡算法。在spring cloud中,当ribbon与eureka/nacos配合使用时,ribbon可自动获取服务提供者的地址列表,并基于负载均衡算法,请求其中一个服务提供者的实例(为了服务的可靠性,一个微服务可能部署多个实例)。
RestTemplate是Spring Resource中一个访问第三方RESTful API接口的网络请求框架。可以说RestTemplate就是用来消费REST服务的。
负载均衡指的是将负载分摊到多个执行单元上。常见的负载均衡有两种方式:
1)是独立进程单元,通过负载均衡,将请求转发到不同的执行单元上,简单理解就是将所有请求都集中起来,然后再进行负载均衡。例如:Nginx;
2)是将负载均衡以代码的形式封装到服务消费者的客户端的进程里。消费服务的客户端有服务提供的信息列表,就可以根据负载均衡测罗将请求分摊到多个服务提供者 例如:Ribbon。
底层分析
可以说Ribbon的负载均衡是属于客户端级别以及消费者的负载均衡,它主要是通过LoadBalancerClient来实现的。而LoadBalancerClient的具体是交给了ILoadBalancer来处理,ILoadBalancer通过配置IRule策略、IPing 进行负载均衡。
RestTemplate加上@LoadBalancer就可以实现远程调用负载均衡。RestTemplate接口能实现,主要是添加了拦截器,只要是@LoadBalancer的就交给Ribbon的负载均衡器进行处理。
Ribbon 的几种负载均衡算法
负载均衡,不管 Nginx 还是 Ribbon 都需要其算法的支持, Nginx 使用的是 轮询和加权轮询算法。而在 Ribbon 中有更多的负载均衡调度算法,其默认是使用的 RoundRobinRule 轮询策略。
RoundRobinRule:轮询策略。Ribbon默认采用的策略。若经过一轮轮询没有找到可用的provider,其最多轮询 10 轮。若最终还没有找到,则返回null。RandomRule: 随机策略,从所有可用的provider中随机选择一个。RetryRule: 重试策略。先按照RoundRobinRule策略获取provider,若获取失败,则在指定的时限内重试。默认的时限为 500 毫秒。
当然,在 Ribbon 中你还可以自定义负载均衡算法,你只需要实现 IRule 接口,然后修改配置文件或者自定义 Java Config 类。
客户端负载均衡
多可用区+多地域的生产环境
地域(简称Region)是指物理的数据中心。可用区(简称Zone)是指在同一地域内,电力和网络互相独立的物理区域。同一个地域内的可用区之间使用低时延链路相连。
若client/server所处的可用区/地域不同,网络延时也不同:
- 同一可用区内的网络延时最低,可忽略不计
- 同一地域下,不同可用区之间的网络延时可以达到~1ms级别,具体看可用区之间的物理距离
- 不同地域之间的网络延时,可以达到几十ms级别,具体看地域之间的物理距离
出于容灾考虑,大部分互联网公司的业务会部署在多个可用区甚至多个地域。所以一个完善的负载均衡机制必须考虑多可用区+地域的运行环境,尽最大可能保证网络调用发生在同一个可用区,以达到最小的网络延时。
高可用性
微服务架构下,Server可能由于各种原因而不可用,比如网络问题,服务过载,依赖服务不可用导致的级联故障等等。出于可用性考虑,负载均衡要能够及时过滤不可用的Server。
源码分析
Ribbon的核心模块主要有4个:
- Rule:表示负载均衡的具体规则(或策略),比如round robin
- Ping:负责健康检测(Health Check)的模块,ribbon会启动一个后台线程执行健康检测
- ServerList:静态或者动态的服务器列表,如果是动态列表,ribbon会启动一个后台线程定期从指定数据源(比如eureka)更新服务器列表
- LoadBalancer:整合以上模块,提供完整的负载均衡服务
ILoadBalancer
ILoadBalancer接口定义了所有LoadBalancer子类需要实现的方法列表。其中最重要的就是chooseServer方法,也是负载均衡的核心。
BaseLoadBalancer
BaseLoadBalancer是ILoadBalancer的一个basic实现,允许用户自定义健康检测机制(IPing & IPingStrategy),和负载均衡策略(IRule)。
IRule
IRule接口表示负载均衡的规则或者策略,比如round robin或response time based等等。IRule的接口定义比较简单.
目前IRule的常用实现类有:
- RoundRobinRule:经典的round robin策略,它通常被用作默认规则或更高级规则的后备规则
- AvailabilityFilteringRule:在round robin的基础上,剔除不可用的节点(可用的定义参见下文源码分析)
- WeightedResponseTimeRule:根据response time赋予不同Server不同的权重,从而实现weighted round robin
IPing
IPing定义了Health Check子类必须实现的接口。
IPing的常用实现类有:
- DummyPing: 什么也不做
- PingUrl:根据配置的url,发起http请求,是标准的health check模式
- NIWDiscoveryPing:依赖服务发现机制(比如eureka)的in-memory cache,判断server是否alive。相比PingUrl,NIWDiscoveryPing效率更高,因为并不需要发起实际的http请求
IPingStrategy
IPingStrategy接口定义的是,给定IPing和Server列表,如何检测所有Server列表。
其他
以后补充…
Nginx
**Nginx是一个免费、开源、高性能、轻量级的 HTTP 和反向代理服务器,也是一个电子邮件(IMAP/POP3)代理服务器,其特点是占有内存少,并发能力强。**Nginx 可以作为静态页面的 web 服务器,同时还支持 CGI 协议的动态语言,比如 perl、php 等,但是不支持 java。Java 程序一般都通过与 Tomcat 配合完成。
核心模块:
HTTP 模块、EVENT 模块和 MAIL 模块
基础模块:
HTTP Access 模块、HTTP FastCGI 模块、HTTP Proxy 模块和 HTTP Rewrite 模块
第三方模块:
HTTP Upstream Request Hash 模块、Notice 模块和 HTTP Access Key 模块及用户自己开发的模块
为什么使用反向代理
- 保护和隐藏原始资源服务器
- 加密和SSL加速
- 通过缓存静态资源,加速Web请求
- 实现负载均衡
Load Balance
Open Feign(接口调用)
微服务之间通过rest接口通讯,springcloud提供fegin框架来支持rest的调用,fegin使得不同进程的rest接口调用得以用优雅的方式进行,这种优雅表现的就像同一个进程调用一样(简化微服务的通信过程)。
**feign采用的是基于接口的注解 ,feign整合了ribbon,具有负载均衡的能力;整合了Hystrix,具有熔断的能力。**feign被设计成插拔式,可以注入其他组件一起使用,常和Ribbon实现负载均衡。
Fegin是个伪 Http客户端,Fegin不做任何的请求处理。通过处理注解生成定制的Request模版,从而简化http开发。Client组件是负责发送Request请求和接收响应的。
Open Feign类似采用映射方式域名和 IP 地址的映射,可以将被调用的服务代码映射到消费者端。也就是说OpenFeign 是运行在消费者端的,也可以使用 Ribbon 进行负载均衡,通过@LoadBalancer启用负载均衡。所以 OpenFeign 直接内置了 Ribbon。
实现过程:
1)首先通过@EnableFeignClients注解开启FeignClient的功能,只有这个注解的存在,才会在程序启动的时候开启对@FeignClient注解的包的扫描。
2)根据Feign规则实现接口,并在接口上添加@FeignClient注解。
3)程序启动会把该注解下的类注入到IOC容器中,当接口调用时,生成RequestTemplate模版对象,再生成Request对象。
4)交由Client去处理,最后的被封装到LoadBalanceClient类,这个类可以结合Ribbon做到负载均衡(加负载均衡的注解@LoadBalancer)。
源码分析
Feign 是通过定义接口,并且在接口方法上使用注解定义请求模板,然后通过 Feign.builder() 进行构建后,即可像使用本地接口方法调用Http请求。
Feign 使用详解
接口注解
| 注解 | 目标 | 用法 |
|---|---|---|
| @RequestLine | 方法 | 定义请求 的HttpMethod。用大括号括起来的Expression使用它们对应的带注释的参数来解析。 |
| @Param | 参数 | 定义一个模板变量,其值将用于解析相应的模板Expression,按作为注释值提供的名称提供 |
| @Headers | 方法、接口 | 定义一个请求头模板,其中可以使用大括号括起来的表达式,将使用 @Param 注解的参数解析,标注在方法上只针对某个请求,标注在类上,表示作用的所有的请求上 |
| @QueryMap | 参数 | 定义Map名称-值对或 POJO,以扩展为查询字符串。 |
| @HeaderMap | 参数 | 定义一个Map名称-值对,展开成 请求头 |
| @Body | 方法 | 类似于一个 URI 模板,他使用 @Param 注解的参数来解析模板中的表达式 |
模板和表达式
**Feign 是由 URI 模板 Expressions 定义的简单字符串表达式,并且使用 @Param 注解的方法参数,进行解析。**表达式必须用大括号括起来,{}并且可以包含正则表达式模式,用冒号分隔: 以限制解析值。 示例 owner必须是字母。{owner:[a-zA-Z]*}
请求参数扩展
RequestLine和QueryMap模板遵循URI模板 规范,该规范指定以下内容:
- 未解析的表达式被省略。
- 所有文字和变量值都经过
pct-encoded编码,如果尚未encoded通过@Param注释编码或标记。
请求头扩展
在Feign 中可以通过 Headers 和HeaderMap 两个注解来扩展请求头,并且遵循以下规则,
- 未解析的表达式被忽略,如果请求头的值为空,这删除整个请求头。
- 不执行
pct-encoded编码
Headers
Headers 注解可以标注到 api 方法上,也可以标注到客户端即接口上,标注在接口上,表示对所有的请求都起作用,标注在 方法上 只对所标注的方法起作用。
HeaderMap
Headers 虽然也能动态设置头信息,但是,当请求头的键和个数不确定时,Headers 就不能满足了,此时我们可以使用 HeaderMap 注解的 方法参数来更灵活的动态指定请求头。
请求正文扩展
Body 模板遵循与请求参数扩展相同的扩展,但有一下更改
- 未解析的表达式被省略
- 扩展值在放置在正文之前不会被
Encoder进行编码 Content-Type请求头必须设置
解码器
在实际开发中,服务端返回的数据可能是个JSON字符串或者字节数组,在 Feign 中可以通过指定解码器,把响应数据解析为你想要的数据类型。一般都是默认使用feign-gson 进行解码的。
请求客户端扩展
Feign 底层默认使用的是 JDK 自带的 URLConnection 实现的网络请求。在Feign 中也可以在构建时指定自定的底层网络请求工具,比如常用的OkHttp 和 Apache HttpClient 等。Feign 也已经实现了 这两个客户端,只需要引入依赖就可以直接使用。
小结
Feign 是一个很好的框架工具,把繁琐的 Http 请求,抽象为以接口加注解的方式实现,也使开发者很好的面向接口编程。在目前微服务盛行的当下,Spring 也对 Feign 进行了封装,即OpenFeign 。这里把最底层、最基础的Feign的用法梳理一下,能够更好的理解 Spring 封装的 OpenFeign。
Hystrix:容错框架
前言
在分布式环境中,不可避免地会有许多服务依赖项中的某些失败。Hystrix 是一个库,可通过添加等待时间容限和容错逻辑来帮助控制这些分布式服务之间的交互。Hystrix 通过隔离服务之间的访问点,停止服务之间的级联故障并提供后备选项来实现此目的,所有这些都可以提高系统的整体弹性。
总体来说 Hystrix 就是一个能进行 熔断 和 降级 的库,通过使用它能提高整个系统的弹性。
为什么请求阻塞会崩溃?
因为这些请求会消耗占用系统的线程、IO 等资源,消耗完了这个系统服务器就会崩了。
介绍
所谓 熔断 就是服务雪崩的一种有效解决方案。当指定时间窗内的请求失败率达到设定阈值时,系统将通过 断路器 直接将此请求链路断开。熔断 就是指的 Hystrix 中的 断路器模式 ,你可以使用简单的 @HystrixCommand 注解来标注某个方法,这样 Hystrix 就会使用 断路器 来“包装”这个方法,每当调用时间超过指定时间时(默认为 1000ms),断路器将会中断对这个方法的调用。
而降级是为了更好的用户体验,当一个方法调用异常时,通过执行另一种代码逻辑来给用户友好的回复。对照着Hystrix 的 后备处理模式。可以通过设置 fallbackMethod 来给一个方法设置备用的代码逻辑。
另外Hystrix有提供 Hystrix 仪表盘,它是用来实时监控 Hystrix 的各项指标信息的
什么是舱壁模式?
在不使用舱壁模式的情况下,服务 A 调用服务 B,这种调用默认的是使用同一批线程来执行的,而在一个服务出现性能问题的时候,就会出现所有线程被刷爆并等待处理工作,同时阻塞新请求,最终导致程序崩溃。而舱壁模式会将远程资源调用隔离在他们自己的线程池中,以便可以控制单个表现不佳的服务,而不会使该程序崩溃。
**在SpringCloud框架里熔断机制通过Hystrix实现,Hystrix会监控微服务间调用的状况,当失败的调用到一定阈值,缺省是5秒内调用20次,如果失败,就会启动熔断机制。**服务降级,一般是从整体负荷考虑。就是当某个服务熔断之后,服务器将不再被调用,此时客户端可以自己准备一个本地的fallback回调,返回一个缺省值。这样做,虽然水平下降,但好歹可用,比直接挂掉强。
设计原则:
1)防止单个服务的故障耗尽整个服务的Servlet容器的线程资源
2)快速失败机制,如果某个服务出现了故障,则调用该服务的请求快速失败,而不是线程等待。
3)提供回退方案,在请求故障时,提供社会定好的回退方案。
4)使用熔断机制,防止故障扩散的服务。资源一直被占用,其他请求得不到资源,会导致服务故障更多。
5)提供熔断器的监控组件HystrixDashboard,可以实时监控熔断器的状态。
Hystrix的工作机制
当服务的某个API接口的失败次数在一定时间内小于设定的阈值(缺省是5秒内调用20次),熔断器处于关闭状态;如果失败次数大于阈值,就会判定API接口出现了故障,会打开熔断器。之后会执行设置的快速失败逻辑,不执行业务逻辑,请求线程就不会处于阻塞的状态。而处于打开状态的熔断器,在一段时间会处于半打开的状态,将一定的数量执行正常逻辑,其余的快速失败。若是执行业务逻辑成功,则熔断器关闭。
工作流程
- 构建
HystrixCommand或者HystrixObservableCommand对象 - 执行命令
- 是否有Response缓存
- 是否断路器打开
- 是否线程池或者队列或者信号量被消耗完
HystrixObservableCommand.construct()orHystrixCommand.run()- 计算链路的健康情况
- 获取fallback逻辑
- 返回成功的Respons
Sentinel 轻量级高可用流量控制组件
Sentinel 是阿里中间件团队开源的,面向分布式服务架构的轻量级高可用流量控制组件,主要以流量为切入点,从流量控制、熔断降级、系统负载保护等多个维度来帮助用户保护服务的稳定性。
Sentinel特征
- 丰富的应用场景:Sentinel 承接了阿里巴巴近 10 年的双十一大促流量的核心场景,例如秒杀(即突发流量控制在系统容量可以承受的范围)、消息削峰填谷、集群流量控制、实时熔断下游不可用应用等。
- 完备的实时监控:Sentinel 同时提供实时的监控功能。您可以在控制台中看到接入应用的单台机器秒级数据,甚至 500 台以下规模的集群的汇总运行情况。
- 广泛的开源生态:Sentinel 提供开箱即用的与其它开源框架/库的整合模块,例如与 Spring Cloud、Dubbo、gRPC 的整合。您只需要引入相应的依赖并进行简单的配置即可快速地接入 Sentinel。
- 完善的 SPI 扩展点:Sentinel 提供简单易用、完善的 SPI 扩展接口。您可以通过实现扩展接口来快速地定制逻辑。例如定制规则管理、适配动态数据源等。
Sentinel 的主要特性:
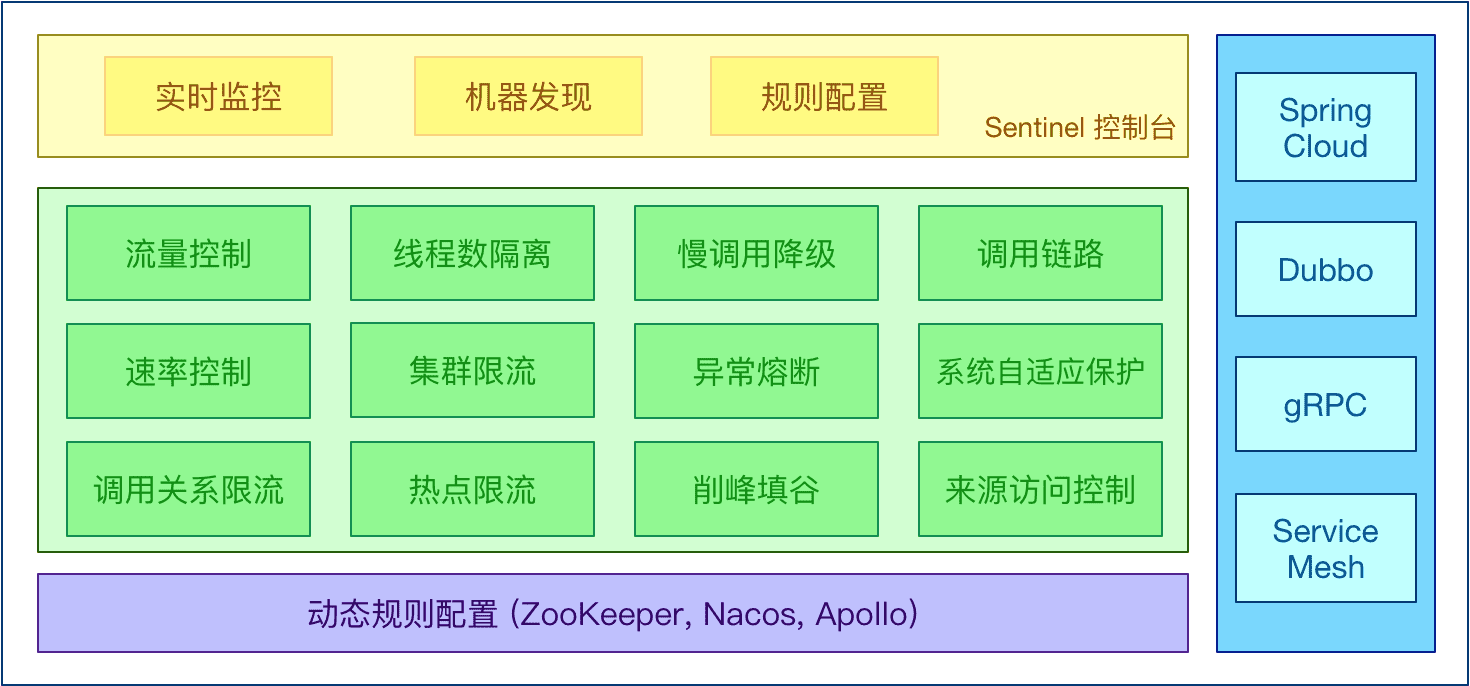
Sentinel 分为两个部分:
核心库(Java 客户端)
不依赖任何框架/库,能够运行于所有 Java 运行时环境,同时对 Dubbo / Spring Cloud 等框架也有较好的支持。
控制台(Dashboard)
基于 Spring Boot 开发,打包后可以直接运行,不需要额外的 Tomcat 等应用容器。
核心功能
流量控制
Sentinel作为一个调配器,可以根据需要把随机的请求调整成合适的形状。
熔断降级
当检测到调用链路中某个资源出现不稳定的表现,例如请求响应时间长或异常比例升高的时候,则对这个资源的调用进行限制,让请求快速失败,避免影响到其它的资源而导致级联故障。
Sentinel的规则
流量控制规则(流控模式为QPS)
若设置触发流控执行阈值为1,那么接口访问1次就被限流
熔断降级规则
降级规则的熔断策略有3种,分别是慢调用比例、异常比例、异常数。
系统保护规则
访问控制规则(gateway规则配置)
热点规则
热点即经常访问的数据。很多时候我们希望统计某个热点数据中访问频次最高的 Top K 数据,并对其访问进行限制。
Sentinel 适配了 Feign 组件
大概使用步骤如下:
1)需要在服务调用方加入依赖
2)服务调用方配置文件中开启Feign支持 sentinel
3)实现降级处理方案。
3-1)创建指定类用于实现熔断之后后置处理方案(不同接口不同的异常处理预案)。实现fallbackFactory接口。
3-2)在接口的注解上指定降级处理类(用于一类统一处理预案)。
Zuul 微服务网关
前言
API 网关,提供路由转发、请求过滤等功能。可以做认证、监控、流量监控等。网关的角色是作为一个 API 架构,用来保护、增强和控制对于 API 服务的访问。
API 网关是一个处于应用程序或服务(提供 REST API 接口服务)之前的系统,用来管理授权、访问控制和流量限制等,这样 REST API 接口服务就被 API 网关保护起来,对所有的调用者透明。 因此,隐藏在 API 网关后面的业务系统就可以专注于创建和管理服务,而不用去处理这些策略性的基础设施。
**服务网关内置了19中过滤器工厂,服务网关分为网关过滤器(Zuul/Gateway)和全局过滤器(实现 GlobalFilter 和 Ordered)。**网关过滤器通过配置文件,作用到所有路由上。
常见的限流算法:计数器算法、漏桶算法、令牌桶算法。
介绍
Zuul网关是是Netflflix开源的微服务网关,它可以和Eureka、Ribbon、Hystrix等组件配合使用,Zuul的底层基于Servlet,本质上就是一系列的filter过滤器,也是它的核心。Zuul2是采用Netty实现异步IO。 这些过滤器可以完成:
动态路由:动态将请求路由到不同后端集群
压力测试:逐渐增加指向集群的流量,以了解性能
负载分配:为每一种负载类型分配对应容量,并弃用超出限定值的请求
静态响应处理:边缘位置进行响应,避免转发到内部集群
身份认证和安全: 识别每一个资源的验证要求,并拒绝那些不符的请求。
Zuul网关过滤器
Zuul的路由功能实现了统一处理外部请求的功能,负责将外部请求转发到具体的微服务实例上,是实现外部访问统一入口的基础。zuul还提供过滤器功能,负责对请求的处理过程进行干预,是实现请求校验、服务聚合等功能的基础。
只需自定义一个filter类并继承ZuulFilter重写四个方法即可定义一个zuul过滤器类
Zuul提供一个RequstContext上下文对象,它内部采用ThreadLocal保存每个请求的一些信息,包括请求路由、错误信息、HttpServletRequest、HttpServletResponse,这使得一些操作是十分可靠的,它还扩展了ConcurrentHashMap,目的是为了在处理过程中保存任何形式的信息
Zuul的工作原理
Zuul是通过Servlet来实现的,Zuul通过自定义的Servlet来对请求进行控制。Zuul的核心是一系列的过滤器,Zuul采用了动态读取、编译和运行这些过滤器,这些过滤器之间不能互相通讯,只能通过RequestContext对象来共享数据。用设计模式的角度来说是采用了策略模式。
四个过滤器:
1)PRE过滤器:可以做安全认证 比如身份验证、参数验证。
2)ROUTING过滤器:将请求路由到具体的微服务实例。默认使用HTTP请求
3)POST 过滤器:用作收集统计信息、指标,以及将响应传到客户端。
4)ERROR过滤器:在其他过滤器发生错误时进行执行。
过滤器的类型:
type:决定了过滤器在请求的哪个阶段起作用,例如 pre post。
Execution Order:过滤器的执行次序,越小越先执行
Criteria:过滤器执行所需的条件。
Action:如果符合执行条件,则执行Action(即逻辑代码)。
servlet就是一个组件,要求需要符合servlet规范,并且需要部署到servlet容器里面才能运行。
注:**容器:符合相应的规范,提供组件运行环境的程序。**比如Tomcat就是比较有名的servlet容器。jetty jboss weblogic都是servlet容器。这些servlet把网络相关的问题已经全部处理好,我们写servlet只需要关注业务逻辑即可。
如何写一个servlet?
1)写一个java类,需要实现Servlet接口或者继承HttpServlet类。
2)编译。
3)打包(将这个java类变成servlet组件)
一个请求的执行过程
进入到网关,先进入pre filter,进行一些列的验证、操作、判断。交给routing filter进行路由转发,转发到具体的服务实例进行逻辑处理;当处理完又post filter进行处理,该处理完将Respose返回给客户端。
Gateway网关
Spring Cloud Gateway基于 Spring 5.0,Spring Boot 2.0 和 Project Reactor 等技术开发的网关,它旨在为微服务架构提供一种简单有效的统一的 API 路由管理方式。基于 Filter 链的方式提供了网关基本的功能,例如:安全,监控/指标,和限流。底层使用了高性能的通信框架Netty,提供了异步支持,提供了抽象负载均衡,提供了抽象流控,并默认实现了RedisRateLimiter。
Spring Cloud Gateway 使用的是reactor-netty响应式编程组件(Reactor线程模型),底层使用了Netty通讯框架,Netty 是高性能中间件的通讯底座。与Zuul最大的区别是底层的通讯框架上,但是Zuul2.0也采用Netty做通讯底座,区别就相对小一点。
Springcloud Zuul 是基于servlet之上的一个阻塞式处理模型,即spring实现了处理所有request请求的一个servlet(DispatcherServlet),并由该servlet阻塞式处理处理。所以Springcloud Zuul无法摆脱servlet模型的弊端。虽然Zuul 2.0开始,使用了Netty,并且已经有了大规模Zuul 2.0集群部署的成熟案例,但是,Springcloud官方已经没有集成改版本的计划了。
SpringCloud Gateway 特征
(1)基于 Spring Framework 5,Project Reactor 和 Spring Boot 2.0
(2)可集成 Hystrix 、Sentinel实现熔断降级
(3)集成 Spring Cloud DiscoveryClient
(4)Predicates 和 Filters 作用于特定路由,易于编写的 Predicates 和 Filters
(5)具备一些网关的高级功能:动态路由、限流、路径重写
术语说明
Filter(过滤器):使用它拦截和修改请求,并且对上游的响应,进行二次处理
Route(路由):
网关配置的基本组成模块,和Zuul的路由配置模块类似。一个Route模块由一个 ID,一个目标 URI,一组断言和一组过滤器定义。如果断言为真,则路由匹配,目标URI会被访问。
Predicate(断言):
这是一个 Java 8 的 Predicate,可以使用它来匹配来自 HTTP 请求的任何内容,例如 headers 或参数。断言的输入类型是一个 ServerWebExchange
Spring Security
Spring Security是什么?
Spring Security 是Spring Resouurce社区的一个安全组件,可以在Controller、Service、DAO层等以加注解的方式来保护应用程序的安全。**提供了细粒度的权限控制,**可以精细到每个API接口、每个业务的方法、每个操作数据库的DAO层。Security提供的是应用层的安全解决方案,但是一个系统还需要考虑传输层、系统层的安全,例如:Http协议、服务器部署防火层、服务器集群隔离部署等。
向服务单元提供了用户验证、权限认证。一般组合OAuth2.0+JWT一起使用。
**在安全方面,主要有两个领域,一个是认证、而是授权。**认证是认证主体的过程,通常是可以在应用程序中执行操作的用户、设备或者其他系统。授权是指决定是否允许已认证的主体执行某一操作。Spring Security采用注解的方式控制权限,容易上手。Spring Security支持很多种认证方式,自带和第三方的。
原理分析
SpringSecurity本质是用一个Filter链实现认证的功能,利用过滤器过滤需要认证的Request,然后进行认证。然而SpringSecurity并不是直接把所有Filter直接注册到服务容器(比如Tomcat)上。而是使用了一个DelegatingFilterProxy 的Filter代理类。
使用代理的好处是:
- 一方面可以让Security的Filter交给spring管理,进而spring的一些功能(Filter注册肯定要在Listener调用前完成,而spring是通过
ContextLoaderListener加载Bean的,使用代理的话可以延迟加载,才不会在spring ioc没加载前使用它)。- 另外一方面,可以将Spring的Filter和其他Filter隔离开来。
由于
DelegatingFilterProxy是一个普通Filter,如果通过延迟加载所有Filter那也太麻烦了,而且不好弄,如果让一个注册到spring中的代理去操作具体的Filter,而DelegatingFilterProxy就只需要延迟加载这个代理(直接写死在配置文件中,通过读取配置security的web配置文件,然后从server中拿)。而这个被用来代理处理具体和spring交互的就是FilterChainProxy。FilterChainProxy杂负责拿到SecurityFilterChain,并负责调用。
实际上,可以不止一个FilterChain,比如要根据不同的服务划分不同的验证流程,就可以使用不同的Chain处理。FilterChainProxy根据请求路径,调用匹配到的SecurityFilterChain。(比如对外采用不同的模式进行认证)
SecurityContextHolder&SecurityContextHolderStrategy
SecurityContextHolder从名字就知道它是用来放SecurityContext的。在认证成功后,AbstractAuthenticationProcessingFilter 会将认证成功的Authentication 放到SecurityContext当中。可以从它获取到Authentication,由他得到用户的认证得到的信息,做进一步处理。在Web环境下默认情况下SecurityContextHolder使用ThreadLocal来保存这些信息。
可以设置不同的
SecurityContextHolderStrategy,有三种模式可选:
SecurityContextHolder.MODE_THREADLOCAL:只有当前线程可以访问SecurityContextHolder.MODE_INHERITABLETHREADLOCAL:继承关系,创建的新线程也可以访问(适用于开放平台)SecurityContextHolder.MODE_GLOBAL: 全局,非Web应用可能使用这个(内对)
权限控制的实现
通过注解
一般不使用,因为不够灵活,而且要把权限写死。
通过ExpressionInterceptUrlRegistry进行配置
SpringSecurity会把ExpressionInterceptUrlRegistry中配置的权限控制规则转换成SecurityMetadataSource。FilterSecurityInterceptor 利用SecurityMetadataSource 来进行权限的校验。FilterSecurityInterceptor 是默认SecurityFilterChain最后一个Filter,负责访问权限的判断。具体就是从SecurityContextHolder中获取Authentication对象,然后比对用户拥有的权限和资源所需的权限,具体见FilterSecurityInterceptor 的父类 AbstractSecurityInterceptor中的beforeInvocation方法。授权失败抛出AccessDeniedException 。
FilterSecurityInterceptor 有一个属性observeOncePerRequest ,控制一个请求是不是只进行一次鉴权。有时候一个请求并不止调用Filter链一次,因为能是forward过来的请求。BasicAuthenticationFilter通过继承 OncePerRequestFilter 强制一个请求只通过一次。而FilterSecurityInterceptor 是可以通过observeOncePerRequest 控制它的行为。有时候需要每次都进行鉴权就要将其设为false。
它父类**AbstractSecurityInterceptor 有一个属性alwaysReauthenticate 可以控制是否每次都重新鉴权**。在使用session保存context时,如果同一个session的请求再次到来,它是不用再鉴权的。如果将alwaysReauthenticate 设为true,那当来到FilterSecurityInterceptor 的时候,会调用AuthenticationManager的一个实例(它独立的一个AuthenticationManager)重新鉴权。
异常处理
AbstractAuthenticationProcessingFilter 使用模板模式,共同代码实现,关于认证留下一个attemptAuthentication的hook。子类要实现这个方法的认证功能。而它抛出的AuthenticationException 都是由AbstractAuthenticationProcessingFilter 处理。
ExceptionTranslationFilter 它是SecurityFilterChain中倒数第二个Filter,负责转换异常,其实转换的是FilterSecurityInterceptor 抛出的异常,并不是前面的一些Filter抛出的异常,更不是全局异常处理器(这一点很多人都弄错了)。
如果该过滤器检测到AuthenticationException,则将会交给内部的AuthenticationEntryPoint去处理,如果检测到AccessDeniedException,需要先判断当前用户是不是匿名用户,如果是匿名访问,则和前面一样运行AuthenticationEntryPoint,否则会委托给AccessDeniedHandler去处理,而AccessDeniedHandler的默认实现是AccessDeniedHandlerImpl。
可以通过自定义AuthenticationEntryPoint实现授权失败执行的逻辑,一般是直接响应401(带上一些信息)。
事件
在认证过程中,SpringSecurity会发布一些事件。件分为两大类,认证事件和授权事件。
事件发布
如果你要让SpringSecurity发布认证事件,你要注册一个AuthenticationEventPublisher 的bean(默认实现是DefaultAuthenticationEventPublisher ), 而关于授权事件你要注册一个AuthorizationEventPublisher 的bean(默认实现是SpringAuthorizationEventPublisher)。然后你就可以使用@EventListener监听对应事件。
使用默认的DefaultAuthenticationEventPublisher认证成功会发布AuthenticationSuccessEvent ,失败时,会发AbstractAuthenticationFailureEvent 。默认的DefaultAuthenticationEventPublisher 将会为下面的异常(事件)发布AbstractAuthenticationFailureEvent 事件。
异常与事件说明
如果你想改变事件发布这一行为,可以用setAdditionalExceptionMappings 设置,例子见官方文档。或者你也可以自定义事件一个发布器。
| 异常 | 事件 | 描述 |
|---|---|---|
| BadCredentialsException | AuthenticationFailureBadCredentialsEvent | 凭证错误 |
| UsernameNotFoundException | AuthenticationFailureBadCredentialsEvent | 用户名Not Found |
| AccountExpiredException | AuthenticationFailureExpiredEvent | 用户过期 |
| ProviderNotFoundException | AuthenticationFailureProviderNotFoundEvent | 找不到Provider |
| DisabledException | AuthenticationFailureDisabledEvent | 用户disable |
| LockedException | AuthenticationFailureLockedEvent | 用户被lock |
| AuthenticationServiceException | AuthenticationFailureServiceExceptionEvent | 系统错误 |
| CredentialsExpiredException | AuthenticationFailureCredentialsExpiredEvent | 凭证过期 |
| InvalidBearerTokenException | AuthenticationFailureBadCredentialsEvent | 无效令牌 |
授权成功后,发布AuthorizationGrantedEvent 事件,不过我没发现有哪里会发布这个事件,这个类时版本5.7加入的(有事件再测一下)。我发现源码中发布的是 AuthorizedEvent 事件。
授权失败时,会有AuthorizationDeniedEvent事件。
OAuth2.0
为什么都有了Spring Security了为什么还要Spring Security OAuth2.0 ?
OAuth认证流程,简单理解,就是允许我们将之前实现的认证和授权的过程交由一个独立的第三方来进行担保。而OAuth协议就是用来顶故意如何让这个第三方的担保有效且双方可信。 而不需要将用户名和密码提供给第三方应用或分享他们数据的所有内容。
介绍
**OAuth2.0是一个标准的授权协议,允许不同的客户端通过认证和授权的方式来访问被其保护起来的资源。**主要包含3个角色:服务提供者、资源持有者、客户端。
大致流程如下(认证、授权):
1)用户(资源持有者)打开客户端,客户端询问用户授权
2)用户同意授权
3)客户端向授权服务器申请授权。
4)授权服务器向客户端进行认证,也包括用户信息的认证,认证成功后授权给予令牌。
5)客户端获取令牌,携带令牌向资源服务器请求资源。
6)资源服务器确认令牌正确无误,向客户端释放资源。
**OAuth2.0分为两部分,分别是OAuth2 Provider和OAuth2 Client。**OAuth2 Provider负责公开被OAuth2保护起来的资源。OAuth2 Provider通过管理和验证OAuth2令牌来控制客户端是否有权限访问被其保护的资源。另外还为用户提供认证API接口。
**OAuth2 Provider角色分为资源服务和授权服务。可能一个授权服务对多个资源服务。**Spring OAuth2.0需配合Spring Security一起使用,所有请求经过控制器处理,并进过一些列的Spring Security过滤器。**Spring Security过滤器链中有2个节点用于获取验证和授权的。**如果资源服务和授权服务不在同一个服务中,则需要做额外的配置。
其他
请查看分布式认证授权篇
JWT
Spring Security OAuth2 保护了微服务系统,但是有个缺陷,每次请求都需要经过Uaa服务验证Token的合法性,并且需要查询该Token对应的用户的权限。针对此问题可以加入JWT的方式,Uaa服务只需要验证一次,返回JWT(用户的所有信息,包括用户权限)。
介绍
JWT是一种开放的标准,定义了一种紧凑且自包含的标准,该标准将各个主体的信息包装为JSON对象。主体信息是通过数字签名进行加密和验证的,常使用HMAC算法和RSA算法对JWT进行签名,安全性很高。
但是存在一个缺点,**权限变更之后需要重新登录获取新的Token。**之前的token如果没有过期的话,还是可以正常使用的。一种改进方式是登录成功之将token缓存到网关,如果权限发生变更,将网关的缓存Token删除,当请求经过网关,判断token在缓存中是否存在,不存在就提示重新登录。
JWT由3部分组成,Header(头)、Payload(有效负载)、Signature(签名)
使用场景:
1)认证:登录成功获取JWT,后续每个请求都携带JWT。
2)信息交换:JWT的在各方之间安全传输信息的一种方式。使用Header+Payload计算签名的时候还可以验证内容是否被篡改。
JWT认证过程
浏览器 ---------------》登录 ------------------》服务器------------》用密匙创建JWT -------------》返回JWT给浏览器 -------------》在header添加JWT---------------》检查JWT解密、获取用户信息-----------》给客户响应。
Config:分布式配置管理。
有客户端、服务端。服务端读取本地、服务端配置,客户端读取服务端配置,来达到同一管理。
在Spring Cloud中,有分布式配置中心组件spring cloud config ,它支持配置服务放在配置服务的内存中(即本地),也支持放在远程Git仓库中。在spring cloud config 组件中,分两个角色,一是config server,二是config client。
Config Server是一个可横向扩展、集中式的配置服务器,它用于集中管理应用程序各个环境下的配置,默认使用Git存储配置文件内容,也可以使用SVN存储,或者是本地文件存储。Config Client是Config Server的客户端,用于操作存储在Config Server中的配置内容。微服务在启动时会请求Config Server获取配置文件的内容,请求到后再启动容器。
Config Server支持从GIT仓库读取配置文件。配置变更后通过Bus去数据库刷新配置(/bus/refresh)。也可以将配置存储到mysql数据库。
其他
也有其他组件实现配置管理,原理大致相同,只是底层结构不一样,并且动态配置
Sleuth/Skywalking 服务链条/链路跟踪
Spring Cloud Sleuth为Spring Cloud实现了分布式跟踪解决方案,兼容Zipkin、HTrace等其它基于日志的追踪系统,例如ELK。目前主流的链路追踪工具:Google的Dapper,阿里的鹰眼,大众点评的CAT,Twitter的Zipkin,LINE的pinpoint,国产的skywalking。
· Zipkin****:****Twitter开源的调用链分析工具,目前基于springcloud sleuth得到了广泛的使用,特点是轻量,使用部署简单。Zipkin是通过RabbiitMQ来传输链路数据的,并可以将数据存储到数据库,也可以存储到ES上面。
· Pinpoint:韩国人开源的基于字节码注入的调用链分析,以及应用监控分析工具。特点是支持多种插件,UI功能强大,接入端无代码侵入。
· Skywalking:国产的优秀APM组件,是一个基于字节码注入的调用链分析,对JAVA分布式应用程序集群的业务运行情况进行追踪、告警和分析的系统。特点是支持多种插件,UI功能较强,接入端无代码侵入。目前已加入Apache孵化器。
· CAT:大众点评开源的基于编码和配置的调用链分析,应用监控分析,日志采集,监控报警等一系列的监控平台工具。
Sleuth特性
探针的性能
主要是agent对服务的吞吐量、CPU和内存的影响。微服务的规模和动态性使得数据收集的成本大幅度提高。 skywalking的探针对吞吐量的影响最小,zipkin的吞吐量居中。pinpoint的探针对吞吐量的影响较为明显。
collector的可扩展性
能够水平扩展以便支持大规模服务器集群。 zipkin支持多个实例订阅MQ,异步消费监控信息。skywalking支持单机和集群模式,使用gRPC通信。
全面的调用链路数据分析
提供代码级别的可见性以便轻松定位失败点和瓶颈。 zipkin的链路监控粒度到接口级别。skywalking 支持众多的中间件、框架、类库。pinpoint数据分析最完备,提供代码级别的可见性以便轻松定位失败点和瓶颈。
对于开发透明,容易开关
添加新功能而无需修改代码,容易启用或者禁用。 Zipkin它要求在需要时修改代码。skywalking和pinpoint基于字节码增强的方式,不需要修改代码,并且可以收集到字节码中的更多精确的信息 。
完整的调用链应用拓扑
自动检测应用拓扑,帮助你搞清楚应用的架构。 pinpoint界面显示的更加丰富,具体到调用的DB名,zipkin的拓扑局限于服务于服务之间 。
Skywalking是一个可观测性分析平台和应用性能管理系统,它也是基于OpenTracing规范、开源的AMP 系统。Skywalking提供分布式跟踪、服务网格遥测分析、度量聚合和可视化一体化解决方案。支持 Java, .Net Core, PHP, NodeJS, Golang, LUA, c++代理。支持Istio +特使服务网格访问官方提供的控制台。
xxljob:远程调度任务
XXL-JOB是一个分布式任务调度平台,其核心设计目标是开发迅速、学习简单、轻量级、易扩展。现已开放源代码并接入多家公司线上产品线,开箱即用。在众多XXL-Job平台的特征中,有如下几条需要关注的:
1、使用简单:支持通过Web页面对任务配置,降低操作任务的难度;
2、动态:支持动态修改任务状态、启动/停止任务,以及终止运行中任务,即时生效;
3、调度中心HA(中心式):调度采用中心式设计,“调度中心”自研调度组件并支持集群部署,可保证调度中心HA;
4、执行器HA(分布式):任务分布式执行,任务”执行器”支持集群部署,可保证任务执行HA;
5、注册中心: 执行器会周期性自动注册任务, 调度中心将会自动发现注册的任务并触发执行。同时,也支持手动录入执行器地址;
6、弹性扩容缩容:一旦有新执行器机器上线或者下线,下次调度时将会重新分配任务;
7、触发策略:提供丰富的任务触发策略,包括:Cron触发、固定间隔触发、固定延时触发、API(事件)触发、人工触发、父子任务触发;
Stream:构建消息驱动的微服务应用程序的框架。
Spring Cloud Stream 在 Spring Cloud 体系内用于构建高度可扩展的基于事件驱动的微服务,其目的是为了简化消息在 Spring Cloud 应用程序中的开发。
Bus:消息代理的集群消息总线。
Spring Cloud Bus 使用轻量级的消息代理来连接微服务架构中的各个服务。可以将其用于广播状态更改(例如配置中心配置更改)或其他管理指令 通常会使用消息代理来构建一个主题,然后把微服务架构中的所有服务都连接到这个主题上去,当我们向该主题发送消息时,所有订阅该主题的服务都会收到消息并进行消费。 使用Spring Cloud Bus 可以方便地构建起这套机制,所以 Spring Cloud Bus 又被称为消息总线。常用于MQ扩展
问题
问题一: 分布式事务问题一般如何解决 ?具体内部是怎么实现的?
常使用Seata方式来解决。底层是通过二阶段/三阶段提交。Seata有多种模式,常用于项目中都是采用AT/TCC模式,XA模式需要实现XA的数据源代理。而是SEATA提供的长事务解决方案,适用于流程化的长事务场景,例如:DDD领域驱动架构中的事务管理。
简单可以这么来说一台机器在执行本地事务的时候无法知道其他机器中的本地事务的执行结果。所以他也就不知道本次事务到底应该commit还是 roolback。常规的解决办法就是引入一个“协调者”的组件来统一调度所有分布式节点的执行。
但是AT模式也不能完整的保证事务的一致性,有可能在第三阶段提交失败。TCC模式就是解决为了这种场景,它有补偿方案。同时AT是引入性小,易上手。而TCC因为补偿方案则侵入性非常大,每个涉及到分布式事务的接口,都需要提供补偿方案。
**两阶段提交主要保证了分布式事务的原子性:即所有结点要么全做要么全不做)。所谓的两个阶段是指:第一阶段:准备阶段(投票阶段)和第二阶段:提交阶段(执行阶段)。**二阶段无法解决的问题:协调者再发出commit消息之后宕机,而唯一接收到这条消息的参与者同时也宕机了。
三阶段引入超时机制 (同时在协调者和参与者中都引入超时机制);在第一阶段和第二阶段中插入一个准备阶段。保证了在最后提交阶段之前各参与节点的状态是一致的;也就是说,除了引入超时机制之外,3PC把2PC的准备阶段再次一分为二,这样三阶段提交就有CanCommit、PreCommit、DoCommit三个阶段。3PC主要解决的单点故障问题,并减少阻塞,因为一旦参与者无法及时收到来自协调者的信息之后,他会默认执行commit,而不会一直持有事务资源并处于阻塞状态。
用mysql事务视图(Read View)的角度来讲:
同时查询到了一组数据。他们为什么隔离。因为mvcc是通过每个线程拿到自己的事务视图。这个事务视图。是私有的。在同一个事务里。再次查询下都是查询自身的事务视图。在提交前。都不会影响到数据库。自然不会影响到其他事务
查询的数据。都在自己的版本视图里。不会对其他事务造成影响。当提交的时候。如果发现有比自己的事务id更大的。代表有其他事务修改了。那自然就不能修改成功了。而协调者的作用主要用于通知双方进行回滚/提交。
问题二:分布式服务与微服务拆分原则?
分布式服务是根据业务进行切分
微服务主要是根据数据结构特性、DDD领域作为切分点。通过数据分析服务的划分边界和划分粒度。
相关文章:
SpringCloud概述
前言 什么是微服务? 微服务是一种面向服务的架构(SOA)风格,其中,应用程序被构建为多个不同的小型服务的集合而不是单个应用程序。与单个程序不同的是,微服务让你可以同时运行多个独立的应用程序,而这些独立的应用…...

Metal入门学习:GPU并行计算大数组相加
一、编程指南PDF下载链接(中英文档) 1、Metal编程指南PDF链接 https://github.com/dennie-lee/ios_tech_record/raw/main/Metal学习PDF/Metal 编程指南.pdf 2、Metal着色语言(Metal Shader Language:简称MSL)编程指南PDF链接 https://github.com/dennie-lee/ios_te…...

关于在spyder,jupyter notebook下创建虚拟环境(pytorch,tensorflow)均有效
anaconda下载地址 https://www.anaconda.com/download/ 下载完成后打开anaconda目录下的 anaconda prompt 在命令行中输入下面的命令创建一个叫tf2.0的虚拟环境(“tf2.0”是建立的Conda虚拟环境的名字,可以自拟) conda create -n tf2.0 p…...

oracle 闪回恢复
oracle 闪回恢复 闪回恢复区主要通过3个初始化参数来设置和管理: db_recovery_file_dest:指定闪回恢复区的位置 db_recovery_file_dest_size:指定闪回恢复区的可用空间大小 db_flashback_retention_target:指定数据库可以回退的时…...

LeetCode 322 零钱兑换
题目: 给你一个整数数组 coins ,表示不同面额的硬币;以及一个整数 amount ,表示总金额。计算并返回可以凑成总金额所需的 最少的硬币个数 。如果没有任何一种硬币组合能组成总金额,返回 -1 。你可以认为每种硬币的数量…...

面试篇SpringMVC是什么以及工作原理
1,什么是SpringMVC呢? 它是Spring的一种设计模式,一款框架。 2,MVC分别代表什么? M代表模型即model的缩写,指业务逻辑层模型。V代表视图即View的缩写,指视图层。C则是controller的缩写ÿ…...

jQuery-层级选择器
<!DOCTYPE HTML> <html> <head> <meta http-equiv"Content-Type" content"text/html; charsetUTF-8"> <title>层级选择器</title> <style type"text/css"> …...

【Java数据结构】——第十节(下).选择排序与堆排序
作者简介:大家好,我是未央; 博客首页:未央.303 系列专栏:Java初阶数据结构 每日一句:人的一生,可以有所作为的时机只有一次,那就是现在!!! 文章目…...
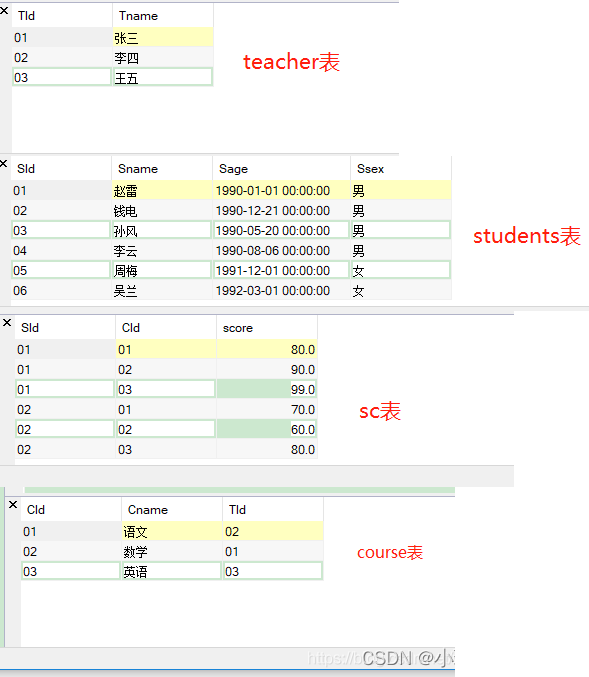
45道SQL题目陆续更新
文章目录 学习视频配置环境第一天内连接 外连接第二天第三天 学习视频 学习视频 配置环境 四张表 配置四张表的sql语句 #创建发据库 create database frogdata charsetutf8;use frogdata;# 学生表 Student create table Student( SId varchar(10), Sname var…...

在线PS软件有哪些不错的推荐
许多新的UI设计合作伙伴非常关心在线ps工具的选择。现在市场上有各种各样的ps网页替代工具,数量众多,令人眼花缭乱。本文简要介绍了10个在线PS工具,我相信一定有一个适合你! 1.即时设计 即时设计是一款在线 UI 设计工具…...
Java实现天气预报功能
如果要实现类似百度天气、手机App这样的天气预报功能该如何实现?首先想到的是百度... 背景: 最近公司做了一个项目,天气预报的功能也做上去了,不仅有实时天气、未来7天预报的功能、还有气象预警的功能。 天气包括基本天气、白天夜…...

python循环语句
while循环 Python中,while循环只要在条件(表达式)为真的情况下,就会一直重复执行相应的循环代码块。 while语句的语法格式如下: while 条件表达式:代码块while语句执行的具体流程为:首先判断…...
线程基础信息、synchronized 锁概念)
多线程基础(一)线程基础信息、synchronized 锁概念
1. 基本概念: 程序: 程序是一些保存在磁盘上的指令的有序集合,是静态的。程序包括:内存资源、IO资源、信号处理等。(如:XX.exe) 进程: 进程是程序执行的过程,包括了动态…...

JAVA期末考内容知识点的梳理
作者的话 前言:这些都是很基本的,还有很多没有写出来,重点在于考试复习,包括后四章的内容 前面内容请参考JAVA阶段考内容知识点的梳理 一、集合、流 课堂总结1集合 集合概念: 保存和盛装数据的容器,将许多…...
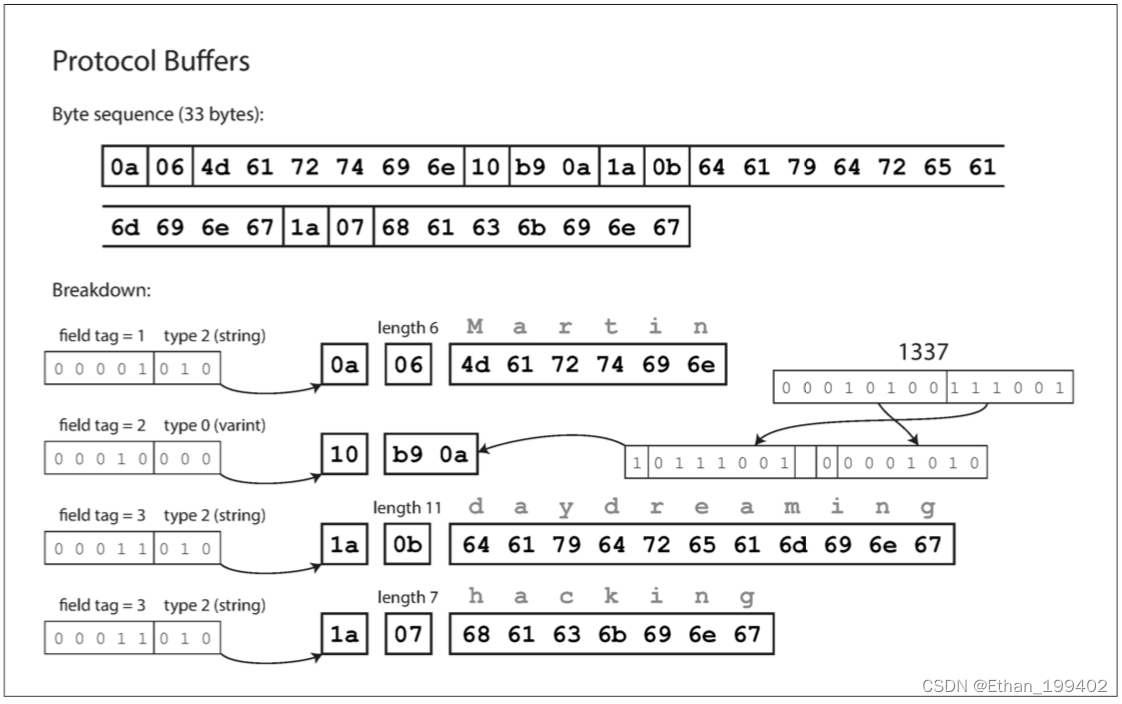
为什么要使用Thrift与Protocol Buffers?
编码数据的格式 程序通常(至少)使用两种形式的数据: 在内存中,数据保存在对象、结构体、列表、数组、散列表、树等中。 这些数据结构针对 CPU 的高效访问和操作进行了优化(通常使用指针)。如果要将数据写…...

oa是什么意思?oa系统哪个好用?
一、oa是什么意思 oa(Office Automation办公自动化)是一种将智能化科技应用于企业管理中的应用系统。它可以通过电脑网络、互联网等技术手段,将企业的各种业务流程、各种业务数据进行集成和处理,将各种业务流程和各种业务数据统一…...

Linq和C# Lambda表达式
什么是Linq 简介 Linq (Language Integrated Query) 是一种语言集成的查询技术,可以在C#和其他.NET语言中使用。Linq允许我们使用一种类SQL的语言来查询数据,这使得代码更加简洁和易于阅读。Linq提供了一种通用的查询接口,可以用于查询各种…...

蓝桥:前端开发笔面必刷题——Day2 数组(三)
文章目录 📋前言🎯两数之和 II📚题目内容✅解答 🎯移除元素📚题目内容✅解答 🎯有序数组的平方📚题目内容✅解答 🎯三数之和📚题目内容✅解答 📝最后 &#x…...

人工智能专栏第四讲——人工智能的未来展望与机遇
目录 一、人工智能的未来展望 二、人工智能在各领域的应用 三、人工智能的机遇 四、总结...
、Shadowmap)
Unity阴影(Shadow)、Shadowmap
Unity阴影(Shadow) 在Unity中,阴影(Shadow)是用于模拟场景中物体之间相互遮挡和光照效果的特性。阴影可以增加场景的真实感,并在视觉上提供深度和空间感。 Unity提供了几种阴影投射和接收的方法和技术&am…...

浅聊26上半年软考架构师
2026年上半年架构师考试已然落幕,大家都考的如何?架构师共有三门考试,上午综合知识(75道选择题)案例分析,时间为8.30-12.30;下午论文,时间为14.30-16.30。下面说说我整体的备考过程。…...

硬件答辩问题总结
一、电源纹波是什么,为什么LDO的小,DCDC的大1.电源纹波电源纹波 是指直流电源输出电压上叠加的 交流波动成分,表现为电压在理想直流值附近上下波动。2.LDO 纹波小原理LDO 内部是一个 调整管(可变电阻) 串联在输入和输出…...

自制射频功率计:基于AD8317芯片,成本43欧元实现1MHz-10GHz测量
1. 项目概述:为什么我要亲手打造一台射频功率计在无人机和模型飞行器的圈子里,尤其是在我们荷兰FMS Spaarnwoude俱乐部,合规飞行是头等大事。我给我的八轴飞行器加装了云台相机和图传系统,工作在5.8GHz频段。根据本地法规…...

MBTI性格测试
简介 MBTI(Myers‑Briggs Type Indicator,迈尔斯‑布里格斯类型指标)是基于荣格心理类型理论发展出的性格类型工具,由凯瑟琳库克布里格斯及其女儿伊莎贝尔布里格斯迈尔斯创建。它通过四对偏好维度将个体的认知与行为倾向归纳为 16…...

HarmonyOS ArkTS DateUtil 日期增减与日历计算完整指南
文章目录 背景一、引言二、日期增减方法详解使用示例 三、日历计算方法详解四、Demo 演示:日期增减结果展示五、Demo 演示:月历视图完整实现六、日历视图关键点解析为什么要填充前置空格?getLastDayOfMonth 的实现技巧 七、小结 背景 近期发现…...

终极键盘重映射解决方案:3分钟实现职业级游戏操作精度
终极键盘重映射解决方案:3分钟实现职业级游戏操作精度 【免费下载链接】socd Key remapper for epic gamers 项目地址: https://gitcode.com/gh_mirrors/so/socd 在激烈的游戏对抗中,你是否曾因键盘按键冲突而错失关键操作?当同时按下…...

微信小程序项目实战:从npm安装Vant Weapp到解决样式冲突的完整避坑指南
微信小程序工程化实战:Vant Weapp集成与样式冲突解决方案全解析 第一次在小程序里引入Vant Weapp时,我对着满屏错位的组件样式发呆了半小时——原本优雅的按钮变成了扭曲的色块,表单元素叠在一起像抽象画。这不是个例,根据社区反…...
)
DeepSeek安全测试辅助Prompt工程白皮书(含17个CVE靶场验证指令模板)
更多请点击: https://intelliparadigm.com 第一章:DeepSeek安全测试辅助 DeepSeek系列大模型在代码生成、漏洞模式识别与安全上下文理解方面展现出独特优势,可作为安全测试工程师的智能协作者。其对OWASP Top 10、CWE分类体系及常见PoC结构具…...

观察Taotoken在多模型聚合调用下的路由与失败重试效果
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察Taotoken在多模型聚合调用下的路由与失败重试效果 在构建依赖大模型能力的应用时,服务的稳定性是开发者关注的核心…...

sd卡分区了数据还能恢复吗,只需3种方法和视频教学,数据就能神奇地回来!
断开读写通信!锁死底层端口!你的sd卡在经历重新分区的一瞬间,其物理层面的扇区正在承受最严酷的逻辑改写。这并非介质烧毁,而是系统内核强行切断了旧有簇链的映射关系,将其标定为休克态。此时若任由操作系统自动加载缩…...