Hive的分区表与分桶表内部表外部表
文章目录
- 1 Hive分区表
- 1.1 Hive分区表的概念?
- 1.1.1 分区表注意事项
- 1.2 分区表物理存储结构
- 1.3 分区表使用场景
- 1.4 静态分区表是什么?
- 1.4.1 静态分区表案例
- 1.4.2 分区表练习一
- 1.4.3 分区操作
- 1.5 动态分区表是什么?
- 1.5.1 动态态分区表案例(如何实现动态分区)
- 2 Hive分桶表
- 2.1 Hive分桶表概念?
- 2.2 创建分桶表
- 2.3 分桶表物理存储结构
- 2.4 分桶表使用场景
- 2.5 如何抽样查询桶表的数据
- 3 内部表
- 3.1 创建表
- 3.2 导入数据
- 3.3 删除表
- 4 外部表
- 4.1 外部普通表
- 4.2 导入数据
- 4.3 删除表
- 4.4 创建表指定外部目录
- 5 内部表和外部表使用场景
- 5.1 内部表
- 5.2 外部表
- Hive的分区表与分桶表概念和使用场景
Hive将表划分为分区(partition)表和分桶(bucket)表。 分区表在加载数据的时候可以指定加载某一部分数据,并不是全量的数据,可以让数据的部分查询变得更快。分桶表通常是在原始数据中加入一些额外的结构,这些结构可以用于高效的查询,例如,基于ID的分桶可以使得用户的查询非常的块。
分区表与分桶表是可以一起使用的。
1 Hive分区表
1.1 Hive分区表的概念?
Hive分区是将数据表的某一个字段或多个字段进行统一归类,而后存储在在hdfs上的不同文件夹中。当查询过程中指定了分区条件时,只将该分区对应的目录作为Input,从而减少MapReduce的输入数据,提高查询效率,这也是数仓优化的一个列,也就是分区裁剪。分区表又分为静态分区表和动态分区表两种。这也是数仓性能优化的一个常用点,也就是分区裁剪。
分区表又分为静态分区表和动态分区表两种。
分区的概念提供了一种将Hive表数据分离为多个文件/目录的方法。不同分区对应着不同的文件夹,同一分区的数据存储在同一个文件夹下。只需要根据分区值找到对应的文件夹,扫描本分区下的文件即可,避免全表数据扫描。
1.1.1 分区表注意事项
-
分区表不是建表的必要语法规则,是一种优化手段表,可选;
-
分区字段不能是表中已有的字段,不能重复;
-
分区字段是虚拟字段,其数据并不存储在底层的文件中;
-
分区字段值的确定来自于用户价值数据手动指定(静态分区)或者根据查询结果位置自动推断(动态分区)
-
Hive支持多重分区,也就是说在分区的基础上继续分区,划分更加细粒度
1.2 分区表物理存储结构
分区表表在hdfs上作为一个文件夹存在,添加分区之后就可以在hdfs文件系统当中看到表下面多了一个文件夹
0: jdbc:hive2://node03:10000> dfs -ls /user/hive/warehouse/myhive1.db/score;
+----------------------------------------------------+--+
| DFS Output |
+----------------------------------------------------+--+
| Found 4 items |
| drwxr-xr-x - hadoop supergroup 0 2020-06-07 15:57 /user/hive/warehouse/myhive1.db/score/month=201803 |
| drwxr-xr-x - hadoop supergroup 0 2020-06-07 15:57 /user/hive/warehouse/myhive1.db/score/month=201804 |
| drwxr-xr-x - hadoop supergroup 0 2020-06-07 15:57 /user/hive/warehouse/myhive1.db/score/month=201805 |
| drwxr-xr-x - hadoop supergroup 0 2020-06-07 15:53 /user/hive/warehouse/myhive1.db/score/month=201806 |
1.3 分区表使用场景
实际工作中分区表常常被运用于按照某一维度进行统计分析的场景下,数据被按照某一个日期、年月日等等,将一个大的文件切分成一个个小文件,分而治之,这样处理起来性能就会有显著提升。
分区表建表语法:
CREATE TABLE table_name (column1 data_type, column2 data_type) PARTITIONED BY (partition1 data_type, partition2 data_type,….);
需要注意:分区字段不能是表中已经存在的字段,因为分区字段最终也会以虚拟字段的形式显示在表结构上。
1.4 静态分区表是什么?
静态分区表:所谓的静态分区表指的就是,我们在创建表的时候,就已经给该表中的数据定义好了数据类型,在进行加载数据的时候,我们已经知道该数据属于什么类型,并且直接加载到该分区内就可以了。
语法如下:
load data [local] inpath ' ' into table tablename partition(分区字段='分区值'...);
Local表示数据是位于本地文件系统还是HDFS文件系统。
1.4.1 静态分区表案例
-- 创建分区表
hive (myhive)> create table score(s_id string, c_id string, s_score int) partitioned by (month string) row format delimited fields terminated by '\t';
-- 创建一个表带多个分区
hive (myhive)> create table score2 (s_id string,c_id string, s_score int) partitioned by (year string, month string, day string) row format delimited fields terminated by '\t';
-- 加载数据到静态分区表当中去
hive (myhive)>load data local inpath '/kkb/install/hivedatas/score.csv' into table score partition (month='201806');
-- 加载数据到多分区静态分区表当中去
hive (myhive)>load data local inpath '/kkb/install/hivedatas/score.csv' into table score partition (month='201806');
-- 加载数据到多分区静态分区表当中去
hive (myhive)> load data local inpath '/kkb/install/hivedatas/score.csv' into table score2 partition(year='2018', month='06', day='01');
-- 查看分区
show partitions score;
+---------------+--+
| partition |
+---------------+--+
| month=201803 |
| month=201804 |
| month=201805 |
| month=201806 |
+---------------+--+
-- 创建分区(怎么添加hive分区)
alter table score add partition(month='201805');
alter table score add partition(month='201804') partition(month = '201803');
-- 删除分区(怎么删除hive分区)
alter table score drop partition(month = '201806');
特殊说明:同内部表和外部表一致,如果该分区表为外部表,则分区对应的HDFS目录数据不会被删除。
1.4.2 分区表练习一
需求描述
- 现在有一个文件score.csv文件,里面有三个字段,分别是s_id string, c_id string, s_score int
- 字段都是使用 \t进行分割
- 存放在集群的这个目录下/scoredatas/day=20180607,这个文件每天都会生成,存放到对应的日期文件夹下面去
- 文件别人也需要公用,不能移动
- 请创建hive对应的表,并将数据加载到表中,进行数据统计分析,且删除表之后,数据不能删除
-- 本地上传数据到hdfs
cd /opt/module/hive-1.1.0-cdh5.14.2/data/test
hdfs dfs -mkdir -p /scoredatas/day=20180607
hdfs dfs -put score.csv /scoredatas/day=20180607/
-- 创建外部分区表,并指定文件数据存放目录
create external table score4(s_id string, c_id string, s_score int) partitioned by (day string) row format delimited fields terminated by '\t' location '/scoredatas';
-- 进行hive的数据表修复,说白了就是建立我们表与我们数据文件之间的一个关系映射(),修复成功之后即可看到数据已经全部加载到表当中去了
msck repair table score4;
1.4.3 分区操作
- 一次添加多个分区
ALTER TABLE page_view ADD PARTITION (dt='2008-08-08', country='us') location '/path/to/us/part080808' PARTITION (dt='2008-08-09', country='us') location '/path/to/us/part080809';
- 删除分区
ALTER TABLE login DROP IF EXISTS PARTITION (dt='2008-08-08');ALTER TABLE page_view DROP IF EXISTS PARTITION (dt='2008-08-08', country='us');
- 修改分区
ALTER TABLE table_name PARTITION (dt='2008-08-08') SET LOCATION "new location";
ALTER TABLE table_name PARTITION (dt='2008-08-08') RENAME TO PARTITION (dt='20080808');
- 表的重命名
ALTER TABLE table_name RENAME TO new_table_name
1.5 动态分区表是什么?
动态分区表:所谓的动态分区表,其实建表方式跟静态分区表没有区别,最主要的区别是在载入数据的时候,静态分区表我们载入数据之前必须保证该分区存在,并且已经明确知道载入的数据的类型,知道要将数据加载到那个分区当中去,而动态分区表,在载入的时候,我们事先并不知道该条数据属于哪一类,而是需要hive自己去判断该数据属于哪一类,并将该条数据加载到对应的目录中去。
建表语句跟静态分区表的建表语句相同,这里不再赘述,主要来看看数据的加载:
对于动态分区表数据的加载,我们需要先开启hive的非严格模式,并且通过insert的方式进行加载数据。
所谓动态分区指的是分区的字段值是基于查询结果自动推断出来的。核心语法就是insert+select。
启用hive动态分区,需要在hive会话中设置两个参数:
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
第一个参数表示开启动态分区功能,第二个参数指定动态分区的模式。分为nonstick非严格模式和strict严格模式。strict严格模式要求至少有一个分区为静态分区。
1.5.1 动态态分区表案例(如何实现动态分区)
这里针对hive动态分区的实现进行说明,实例内容是在一个普通表里面存在订单时间的字段,将普通数据表的数据按照订单时间作为分区字段,动态分区到分区表中。
-- 创建分区表,分别创建普通表,和分区表
-- 创建普通表
create table t_order(order_number string,order_price double,order_time string
)row format delimited fields terminated by '\t';
-- 创建目标分区表
create table order_dynamic_partition(order_number string,order_price double
)partitioned BY(order_time string)
row format delimited fields terminated by '\t';
-- 导入准备好的数据
cd /opt/module/hive-1.1.0-cdh5.14.2/data/test
vim order_partition.txt
10001 100 2019-03-02
10002 200 2019-03-02
10003 300 2019-03-02
10004 400 2019-03-03
10005 500 2019-03-03
10006 600 2019-03-03
10007 700 2019-03-04
10008 800 2019-03-04
10009 900 2019-03-04
-- 普通表t_order load加载数据
load data local inpath '/opt/module/hive-1.1.0-cdh5.14.2/data/test/order_partition.txt' overwrite into table t_order;
-- 动态分区的实现, 将普通表的数据按照order_time字段作为分区字段,动态加载数据到分区表中
hive> set hive.exec.dynamic.partition=true; -- 开启动态分区功能
hive> set hive.exec.dynamic.partition.mode=nonstrict; -- 设置hive为非严格模式
hive> insert into table order_dynamic_partition partition(order_time) select order_number, order_price, order_time from t_order;
-- 查看分区
show partitions order_dynamic_partition;
+------------------------+--+
| partition |
+------------------------+--+
| order_time=2019-03-02 |
| order_time=2019-03-03 |
| order_time=2019-03-04 |
+------------------------+--+
开启开启动态分区的条件和注意事项:
1、必须先开启动态分区模式为非严格模式
2、在指定分区的时候,并没有指定具体分区的值,而只是指定的分区的字段
3、partition中的字段其实是作为插入目标表中的一个字段,所以在从另外一张表select的时候必须查询字段中包含索要分区的这个字段。
2 Hive分桶表
2.1 Hive分桶表概念?
Hive分桶是相对分区进行更细粒度的划分。是将整个数据内容按照某列取hash值,对桶的个数取模的方式决定该条记录存放在哪个桶当中;具有相同hash值的数据进入到同一个文件中。 如要安装name属性分为3个桶,就是对name属性值的hash值对3取摸,按照取模结果对数据分桶。如取模结果为0的数据记录存放到一个文件,取模为1的数据存放到一个文件,取模为2的数据存放到一个文件。
2.2 创建分桶表
在创建分桶表之前要执以下的命令,开启对分桶表的支持以及reduce个数
set hive.enforce.bucketing=true;
# 设置与桶相同的reduce个数(默认只有一个reduce)
set mapreduce.job.reduces=4;COPY
创建分桶表
create table myhive1.user_buckets_demo(id int, name string)
clustered by(id)
into 4 buckets
row format delimited fields terminated by '\t';COPY
如何向分桶表中导入数据
向分桶表中导入数据,不可以直接加载,需要先导入普通表,再导入分桶表中,这种和动态分区类似。
# 创建普通表
create table user_demo(id int, name string)
row format delimited fields terminated by '\t';
# 准备数据文件 buckets.txt
cd /opt/module/hive-1.1.0-cdh5.14.2/data/test
vim user_bucket.txt
1 anzhulababy1
2 anzhulababy2
3 anzhulababy3
4 anzhulababy4
5 anzhulababy5
6 anzhulababy6
7 anzhulababy7
8 anzhulababy8
9 anzhulababy9
10 anzhulababy10
# 向普通标中导入数据
load data local inpath '/opt/module/hive-1.1.0-cdh5.14.2/data/test/user_bucket.txt' overwrite into table user_demo;
# 查看数据
select * from user_demo;
+---------------+-----------------+--+
| user_demo.id | user_demo.name |
+---------------+-----------------+--+
| 1 | anzhulababy1 |
| 2 | anzhulababy2 |
| 3 | anzhulababy3 |
| 4 | anzhulababy4 |
| 5 | anzhulababy5 |
| 6 | anzhulababy6 |
| 7 | anzhulababy7 |
| 8 | anzhulababy8 |
| 9 | anzhulababy9 |
| 10 | anzhulababy10 |
+---------------+-----------------+--+
# 加载数据到桶表user_buckets_demo中
insert into table user_buckets_demo select * from user_demo;COPY
2.3 分桶表物理存储结构
分桶表表在hdfs上作为一个文件存在。
0: jdbc:hive2://node03:10000> dfs -ls /user/hive/warehouse/myhive1.db/user_buckets_demo;
+----------------------------------------------------+--+
| DFS Output |
+----------------------------------------------------+--+
| Found 4 items |
| -rwxr-xr-x 3 hadoop supergroup 30 2020-06-08 13:30 /user/hive/warehouse/myhive1.db/user_buckets_demo/000000_0 |
| -rwxr-xr-x 3 hadoop supergroup 45 2020-06-08 13:30 /user/hive/warehouse/myhive1.db/user_buckets_demo/000001_0 |
| -rwxr-xr-x 3 hadoop supergroup 47 2020-06-08 13:30 /user/hive/warehouse/myhive1.db/user_buckets_demo/000002_0 |
| -rwxr-xr-x 3 hadoop supergroup 30 2020-06-08 13:30 /user/hive/warehouse/myhive1.db/user_buckets_demo/000003_0 |
+----------------------------------------------------+--+
2.4 分桶表使用场景
- 取样sampling更高效。没有分桶的话需要扫描整个数据集。
- 提升某些查询操作效率,例如map side join
2.5 如何抽样查询桶表的数据
tablesample抽样语句语法:tablesample(bucket x out of y)
- x表示从第几个桶开始取数据
- y与进行采样的桶数的个数、每个采样桶的采样比例有关
select * from user_buckets_demo tablesample(bucket 1 out of 2);
-- 需要采样的总桶数=4/2=2个
-- 先从第1个桶中取出数据
-- 1+2=3,再从第3个桶中取出数据
3 内部表
- Hive 内部表与外部表
- 六、Hive中的内部表、外部表、分区表和分桶表
托管表(Managed TABLE)也称为内部表(Internal TABLE)。这是Hive中的默认表。当我们在Hive中创建一个表,没有指定为外部表时,默认情况下我们创建的是一个内部表。如果我们创建一个内部表,那么表将在HDFS中的特定位置创建。默认情况下,表数据将在HDFS的/usr/hive/warehouse目录中创建。如果我们删除了一个内部表,那么这个表的表数据和元数据都将从HDFS中删除。
3.1 创建表
我们可以用下面的语句在Hive里面创建一个内部表:
CREATE TABLE IF NOT EXISTS tb_station_coordinate(station string,lon string,lat string
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ',';
我们已经成功创建了表并使用如下命令检查表的详细信息:
hive> describe formatted tb_station_coordinate;
OK
# col_name data_type comment station string
lon string
lat string # Detailed Table Information
Database: default
Owner: xiaosi
CreateTime: Tue Dec 12 17:42:09 CST 2017
LastAccessTime: UNKNOWN
Retention: 0
Location: hdfs://localhost:9000/user/hive/warehouse/tb_station_coordinate
Table Type: MANAGED_TABLE
Table Parameters: COLUMN_STATS_ACCURATE {\"BASIC_STATS\":\"true\"}numFiles 0 numRows 0 rawDataSize 0 totalSize 0 transient_lastDdlTime 1513071729 # Storage Information
SerDe Library: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
InputFormat: org.apache.hadoop.mapred.TextInputFormat
OutputFormat: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
Compressed: No
Num Buckets: -1
Bucket Columns: []
Sort Columns: []
Storage Desc Params: field.delim , serialization.format ,
Time taken: 0.16 seconds, Fetched: 33 row(s)
从上面我们可以看到表的类型Table Type为MANAGED_TABLE,即我们创建了一个托管表(内部表)。
3.2 导入数据
我们使用如下命令将一个样本数据集导入到表中:
hive> load data local inpath '/home/xiaosi/station_coordinate.txt' overwrite into table tb_station_coordinate;
Loading data to table default.tb_station_coordinate
OK
Time taken: 2.418 seconds
如果我们在HDFS的目录/user/hive/warehouse/tb_station_coordinate查看,我们可以得到表中的内容:
xiaosi@yoona:~$ hadoop fs -ls /user/hive/warehouse/tb_station_coordinate
Found 1 items
-rwxr-xr-x 1 xiaosi supergroup 374 2017-12-12 17:50 /user/hive/warehouse/tb_station_coordinate/station_coordinate.txt
xiaosi@yoona:~$
xiaosi@yoona:~$
xiaosi@yoona:~$ hadoop fs -text /user/hive/warehouse/tb_station_coordinate/station_coordinate.txt
桂林北站,110.302159,25.329024
杭州东站,120.213116,30.290998
山海关站,119.767555,40.000793
武昌站,114.317576,30.528401
北京南站,116.378875,39.865052
...
> /home/xiaosi/station_coordinate.txt是本地文件系统路径。从上面的输出我们可以看到数据是从本地的这个路径复制到HDFS上的/user/hive/warehouse/tb_station_coordinate/目录下。 为什么会自动复制到HDFS这个目录下呢?这个是由Hive的配置文件设置的。在Hive的${HIVE_HOME}/conf/hive-site.xml配置文件中指定,hive.metastore.warehouse.dir属性指向的就是Hive表数据存放的路径(在这配置的是/user/hive/warehouse/)。Hive每创建一个表都会在hive.metastore.warehouse.dir指向的目录下以表名创建一个文件夹,所有属于这个表的数据都存放在这个文件夹里面/user/hive/warehouse/tb_station_coordinate。
3.3 删除表
现在让我们使用如下命令删除上面创建的表:
hive> drop table tb_station_coordinate;
Moved: 'hdfs://localhost:9000/user/hive/warehouse/tb_station_coordinate' to trash at: hdfs://localhost:9000/user/xiaosi/.Trash/Current
OK
Time taken: 1.327 seconds
从上面的输出我们可以得知,原来属于tb_station_coordinate表的数据被移到hdfs://localhost:9000/user/xiaosi/.Trash/Current文件夹中(如果你的Hadoop没有采用回收站机制,那么删除操作将会把属于该表的所有数据全部删除)(回收站机制请参阅:[Hadoop Trash回收站使用指南](http://smartying.club/2017/12/07/Hadoop/Hadoop Trash回收站使用指南/))。
如果我们在HDFS的目录/user/hive/warehouse/tb_station_coordinate查看:
xiaosi@yoona:~$ hadoop fs -ls /user/hive/warehouse/tb_station_coordinate
ls: `/user/hive/warehouse/tb_station_coordinate': No such file or directory
你可以看到输出为No such file or directory,因为表及其内容都从HDFS从删除了。
4 外部表
当数据在Hive之外使用时,创建外部表(EXTERNAL TABLE)来在外部使用。无论何时我们想要删除表的元数据,并且想保留表中的数据,我们使用外部表。外部表只删除表的schema。
4.1 外部普通表
我们使用如下命令创建一个外部表:
CREATE EXTERNAL TABLE IF NOT EXISTS tb_station_coordinate(station string,lon string,lat string
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ',';
我们现在已经成功创建了外部表。我们使用如下命令检查关于表的细节:
hive> describe formatted tb_station_coordinate;
OK
# col_name data_type comment station string
lon string
lat string # Detailed Table Information
Database: default
Owner: xiaosi
CreateTime: Tue Dec 12 18:16:13 CST 2017
LastAccessTime: UNKNOWN
Retention: 0
Location: hdfs://localhost:9000/user/hive/warehouse/tb_station_coordinate
Table Type: EXTERNAL_TABLE
Table Parameters: COLUMN_STATS_ACCURATE {\"BASIC_STATS\":\"true\"}EXTERNAL TRUE numFiles 0 numRows 0 rawDataSize 0 totalSize 0 transient_lastDdlTime 1513073773 # Storage Information
SerDe Library: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
InputFormat: org.apache.hadoop.mapred.TextInputFormat
OutputFormat: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
Compressed: No
Num Buckets: -1
Bucket Columns: []
Sort Columns: []
Storage Desc Params: field.delim , serialization.format ,
Time taken: 0.132 seconds, Fetched: 34 row(s)
从上面我们可以看到表的类型Table Type为EXTERNAL_TABLE,即我们创建了一个外部表。
4.2 导入数据
我们使用如下命令将一个样本数据集导入到表中:
hive> load data local inpath '/home/xiaosi/station_coordinate.txt' overwrite into table tb_station_coordinate;
Loading data to table default.tb_station_coordinate
OK
Time taken: 2.418 seconds
如果我们在HDFS的目录/user/hive/warehouse/tb_station_coordinate查看,我们可以得到表中的内容:
xiaosi@yoona:~$ hadoop fs -ls /user/hive/warehouse/tb_station_coordinate
Found 1 items
-rwxr-xr-x 1 xiaosi supergroup 374 2017-12-12 18:19 /user/hive/warehouse/tb_station_coordinate/station_coordinate.txt
xiaosi@yoona:~$
xiaosi@yoona:~$
xiaosi@yoona:~$ hadoop fs -text /user/hive/warehouse/tb_station_coordinate/station_coordinate.txt
桂林北站,110.302159,25.329024
杭州东站,120.213116,30.290998
山海关站,119.767555,40.000793
武昌站,114.317576,30.528401
...
4.3 删除表
现在让我们使用如下命令删除上面创建的表:
hive> drop table tb_station_coordinate;
OK
Time taken: 0.174 seconds
hive>
我们的Hadoop已经开启了回收站机制,但是删除操作并没有将数据进行删除,不像删除内部表一样,输出Moved: 'hdfs://localhost:9000/user/hive/warehouse/tb_station_coordinate' to trash at: hdfs://localhost:9000/user/xiaosi/.Trash/Current(回收站机制请参阅:[Hadoop Trash回收站使用指南](http://smartying.club/2017/12/07/Hadoop/Hadoop Trash回收站使用指南/))。为了验证我们真的没有删除数据,我们在HDFS目录下查看数据:
xiaosi@yoona:~$ hadoop fs -ls /user/hive/warehouse/tb_station_coordinate
Found 1 items
-rwxr-xr-x 1 xiaosi supergroup 374 2017-12-12 18:19 /user/hive/warehouse/tb_station_coordinate/station_coordinate.txt
xiaosi@yoona:~$
xiaosi@yoona:~$ hadoop fs -text /user/hive/warehouse/tb_station_coordinate/station_coordinate.txt
桂林北站,110.302159,25.329024
杭州东站,120.213116,30.290998
山海关站,119.767555,40.000793
武昌站,114.317576,30.528401
北京南站,116.378875,39.865052
...
你可以看到表中的数据仍然在HDFS中。所以我们得知如果我们创建一个外部表,在删除表之后,只有与表相关的元数据被删除,而不会删除表的内容。
4.4 创建表指定外部目录
只有当你的数据在/user/hive/warehouse目录中时,上述方法才能有效。但是,如果你的数据在另一个位置,如果你删除该表,数据也将被删除。所以在这种情况下,你需要在创建表时设置数据的外部位置,如下所示:
CREATE EXTERNAL TABLE IF NOT EXISTS tb_station_coordinate(station string,lon string,lat string
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
LOCATION '/user/xiaosi/test/coordinate/';
备注: 你也可以通过在创建表时设置数据存储位置来创建一个内部表。但是,如果删除表,数据将被删除。 如果你想要创建外部表,需要在创建表的时候加上 EXTERNAL 关键字,同时指定外部表存放数据的路径(例如2.4所示),也可以不指定外部表的存放路径(例如2.3所示),这样Hive将在HDFS上的/user/hive/warehouse/目录下以外部表的表名创建一个文件夹,并将属于这个表的数据存放在这里。
5 内部表和外部表使用场景
5.1 内部表
- 数据是临时的
- 希望使用
Hive来管理表和数据的生命周期 - 删除后不想要数据
5.2 外部表
- 这些数据也在
Hive之外使用。 Hive不管理数据和权限设置以及目录等,需要你有另一个程序或过程来做这些事情- 不是基于现有表(AS SELECT)来创建的表
- 可以创建表并使用相同的模式并指向数据的位置
相关文章:

Hive的分区表与分桶表内部表外部表
文章目录1 Hive分区表1.1 Hive分区表的概念?1.1.1 分区表注意事项1.2 分区表物理存储结构1.3 分区表使用场景1.4 静态分区表是什么?1.4.1 静态分区表案例1.4.2 分区表练习一1.4.3 分区操作1.5 动态分区表是什么?1.5.1 动态态分区表案例&#…...

和数集团打造《神念无界:源起山海》,诠释链游领域创新与责任
首先,根据网上资料显示,一部《传奇》,二十年热血依旧。 《传奇》所缔造的成绩,承载的是多少人的青春回忆,《传奇》无疑已经在游戏史上写下了浓墨重彩的一笔。 相比《传奇》及背后的研发运营公司娱美德名声大噪&#x…...

小白入门模拟IC设计,如何快速学习?
众所周知,模拟电路很难学。以最普遍的晶体管来说,我们分析它的时候必须首先分析直流偏置,其次在分析交流输出电压。可以说,确定工作点就是一项相当麻烦的工作(实际中来说),晶体管的参数多、参数…...
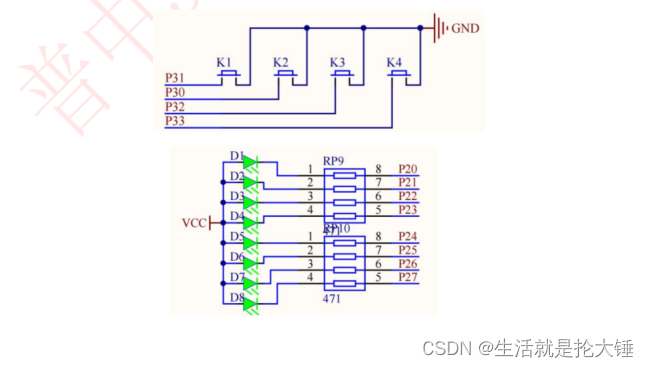
51单片机——中断系统之外部中断实验,小白讲解,相互学习
中断介绍 中断是为使单片机具有对外部或内部随机发生的事件实时处理而设置的,中断功能的存在,很大程度上提高了单片机处理外部或内部事件的能力。它也是单片机最重要的功能之一,是我们学些单片机必须要掌握的。 为了更容易的理解中断概念&…...
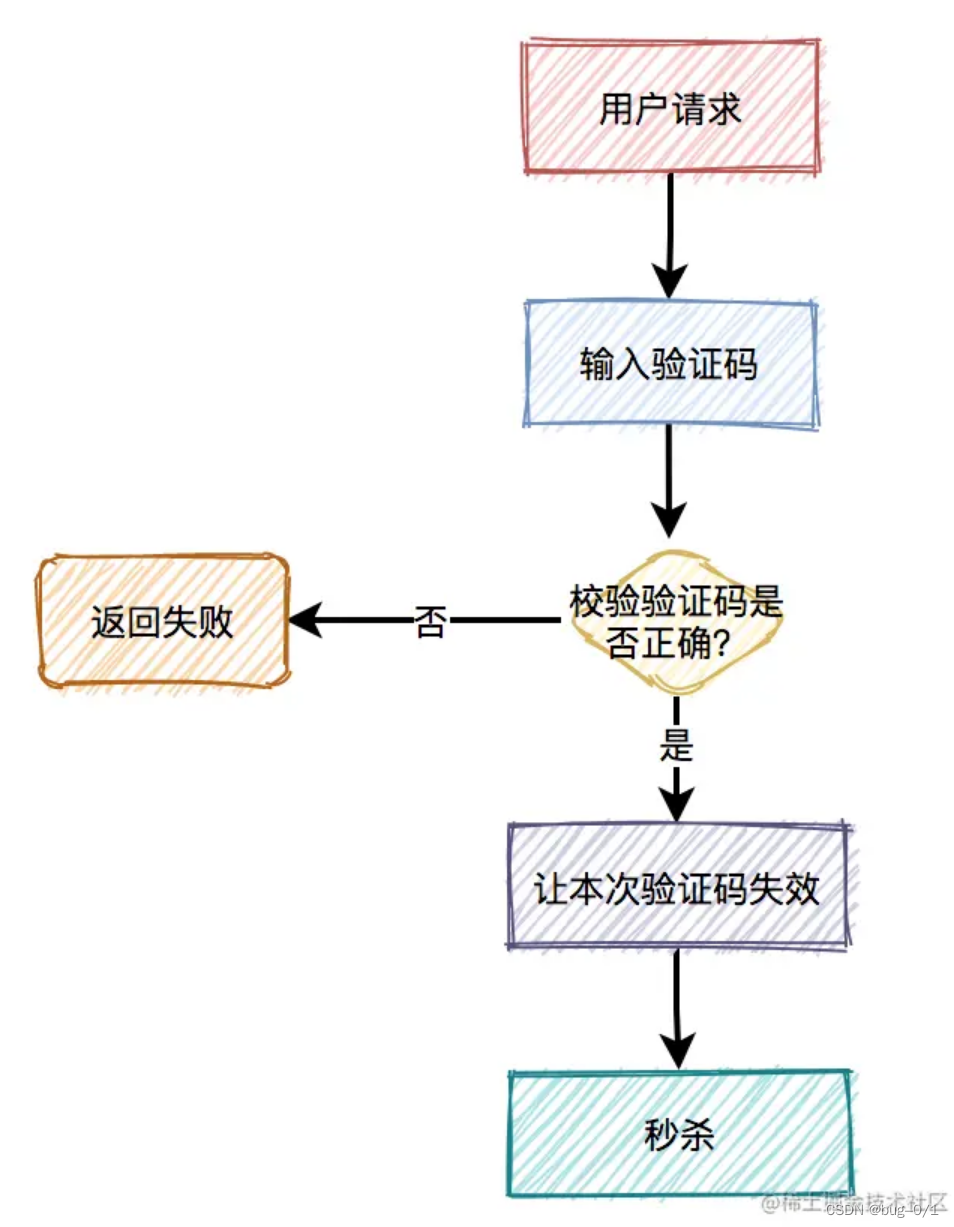
如何设计一个秒杀系统
秒杀系统要如何设计? 前言 高并发下如何设计秒杀系统?这是一个高频面试题。这个问题看似简单,但是里面的水很深,它考查的是高并发场景下,从前端到后端多方面的知识。 秒杀一般出现在商城的促销活动中,指定…...

厄瓜多尔公司注册方案
简介: 经济概况与商机 厄瓜多尔是世界上第74大国家,是南美西部国家,与哥伦比亚,秘鲁和太平洋接壤。厄瓜多尔地处世界中心,地理位置优越,地理位置优越-赤道线零纬度,使其成为通往太平洋的理想枢…...
安全渗透环境准备(工具下载)
数据来源 01 一些VM虚拟机的安装 攻击机kali: kali官网 渗透测试工具Kali Linux安装与使用 kali汉化 虚拟机网络建议设置成NAT模式,桥接有时不稳定。 靶机OWASP_Broken_Web_Apps: 迅雷下载 网盘下载 安装教程 开机之后需要登录&am…...

118.(leaflet篇)leaflet空间判断-点与geojson面图层的空间关系(turf实现)
听老人家说:多看美女会长寿 地图之家总目录(订阅之前建议先查看该博客) 文章末尾处提供保证可运行完整代码包,运行如有问题,可“私信”博主。 效果如下所示: 下面献上完整代码,代码重要位置会做相应解释 <!DOCTYPE html> <html>...

目标检测与目标跟踪算法技术汇总
现如今chatgpt的爆火,我也使用了一段时间,问了许多关于人工智能技术的问题,基本是它能够回答了大部分的原理的,至于其人工智能涉及到的算法以及网络,考虑到也没有图,可能在给出这类回答上,是不太…...

Linux 系统启动过程
过去几十年,公用事业行业发生了重大变化。能源需求的转变导致企业利润率的波动,但不是运营成本的波动。 许多公用事业公司通过后勤部门流程自动化来削减成本,比如招采流程自动化。 在招采活动中,人工招采会产生盲点。由于公共事业…...

【每日一题Day118】LC1124表现良好的最长时间段 | 前缀和+单调栈/哈希表
表现良好的最长时间段【LC1124】 给你一份工作时间表 hours,上面记录着某一位员工每天的工作小时数。 我们认为当员工一天中的工作小时数大于 8 小时的时候,那么这一天就是「劳累的一天」。 所谓「表现良好的时间段」,意味在这段时间内&#…...
)
vue使用nprogress(进度条)
目录 1.安装 2.引入 3.配置 4.使用 5.使用场景 6.改变颜色 1.安装 npm install --save nprogress2.引入 import NProgress from nprogress import nprogress/nprogress.css3.配置 NProgress.configure({easing: ease, // 动画方式,和css动画属性一样&#…...
@NotNull 、@NotBlank、@NotEmpty区别和使用
引言 今天在使用validation校验的时候,发现了使用校验不起作用,一时间有点摸不到头绪,就看了一下同事提交的代码,发现了问题在用NotNull用法,用的有些错误,所以在这里讲一下NotNull、NotBlank、NotEmpty区…...
Nacos——Nacos简介以及Nacos Server安装
资料来源:02-Nacos配置管理-什么是配置中心_哔哩哔哩_bilibili nacos记得下载2.x版本的,负责以后新建配置的时候会出现“发布错误,请检查参数是否正确”错误!!!! 目录 一、Nacos简介 1.1 四…...

Presto 文档和笔记
1. Presto Presto 官网 Presto 文档 2. 配置 3.1 node 配置 cat etc/node.properties # Generated by Apache Ambari. Fri Feb 10 14:52:10 2023node.data-dir/mnt/bmr/presto/data node.environmentproduction node.idbmr-master-4b7cbaa3.2 jvm 配置 cat etc/jvm.confi…...
大尺度衰落与小尺度衰落
一. 大尺度衰落 无线电磁波信号在收发天线长距离(远大于传输波长)或长时间范围发生的功率变化,称为大尺度衰落,一般可以用路径损耗模型来描述,路径损耗是由发射功率在空间中的辐射扩散造成的,根据功率传输…...
完美解决:重新安装VMware Tools灰色。以及共享文件夹的创建(centos8)
解决:重新安装VMware Tools灰色问题:重新安装VMware Tools灰色解决方案-挂载VMware中的linux.iso1. vmtools的linux.iso挂载及安装2. 共享文件夹的创建及配置问题:重新安装VMware Tools灰色 发现一个小问题,我的vm虚拟机安装后发…...

达梦数据库作业管理
一、基本功能 作业系统大致包含作业,警报,操作员三部分。 作业可运行DMPL/SQL脚本,定期备份数据库,检查等。可定时执行,也可通过警报触发执行,可产生警报通知用户状态。一个作业由多个步骤组成,…...

数据结构-考研难点代码突破(C++实现树型查找-二叉搜索树(二叉排序树))
文章目录1.二叉搜索树基本操作二叉搜索树的效率分析2. C实现1.二叉搜索树基本操作 二叉排序树是具有下列特性的二叉树: 若左子树非空,则左子树上所有结点的值均小于根结点的值。若右子树非空,则右子树上所有结点的值均大于根结点的值。左、…...

emqx异常处理
启动异常 通过解压tar压缩包安装后通过 ./bin/emqx start 启动报错 WARNING: Default (insecure) Erlang cookie is in use. WARNING: Configure node.cookie in /opt/emqx/etc/emqx.conf or override from environment variable EMQX_NODE__COOKIE NOTE: Use the same config…...

ai llm训练数据合成说明
一、推理服务 使用llamacpp做本地推理服务,使用gguf加gpu加速。 模型使用Jackrong/Qwen3.5-9B-Claude-4.6-Opus-Reasoning-Distilled-GGUF llama-server.exe -m .\Qwen3.5-9B.Q4_K_M.gguf -ngl 99 -c 4096 --host 0.0.0.0 --port 8080 --parallel 4 -np …...

ARM PB11MPCore USB与DVI接口设计与信号完整性分析
1. ARM PB11MPCore接口架构解析PB11MPCore作为ARM经典的嵌入式开发平台,其外设接口设计体现了工业级嵌入式系统的典型特征。我们先从整体架构入手,理解USB和DVI接口在系统中的位置。1.1 系统级接口布局开发板采用前后面板分离设计,关键接口分…...

ADAS环视系统与视频解码器关键技术解析
1. ADAS环视系统技术解析1.1 汽车安全技术演进路径从ABS防抱死系统到安全气囊,再到如今的ADAS(高级驾驶辅助系统),汽车安全技术在过去二十年经历了三次重大迭代。德国车企在这个领域始终保持着技术领先,最早实现了车道…...

mlc-llm:大语言模型跨平台高效部署的机器学习编译框架
1. 项目概述:当大语言模型遇见“通用编译” 如果你在过去一年里折腾过大语言模型(LLM)的本地部署,大概率经历过这样的场景:兴冲冲地从Hugging Face下载了一个7B参数的模型,却发现自己的消费级显卡…...

ARM9EJ-S核心调试技术与系统速度访问机制解析
1. ARM9EJ-S核心调试技术概述 在嵌入式系统开发领域,调试技术的重要性不亚于代码编写本身。ARM9EJ-S作为经典的嵌入式处理器核心,其调试子系统设计体现了ARM架构对开发效率的深度考量。这套调试系统不仅仅是简单的"暂停-查看"工具,…...

大模型多格式量化训练技术解析与应用实践
1. 多格式量化训练技术解析在大语言模型部署实践中,量化技术已经成为平衡计算效率和模型性能的关键手段。传统量化方案通常需要为每种目标精度单独训练和存储模型,这在资源受限的边缘设备上会带来显著的存储和管理开销。多格式量化训练(Multi-format QAT…...

CANN/ops-nn动态量化RMS归一化融合算子
aclnnAddRmsNormDynamicQuantV2 【免费下载链接】ops-nn 本项目是CANN提供的神经网络类计算算子库,实现网络在NPU上加速计算。 项目地址: https://gitcode.com/cann/ops-nn 📄 查看源码 产品支持情况 产品是否支持Ascend 950PR/Ascend 950DT√A…...
的基本原理与特性分析)
深入了解场效应管(FET)的基本原理与特性分析
场效应管(FET)基础概念场效应管(Field Effect Transistor, FET)是一种通过电场效应控制电流的半导体器件,属于电压控制型器件。其核心特点包括高输入阻抗、低驱动功耗和单极型载流子传导(仅多数载流子参与导…...

无实景不建模 孪生自生成:无改造无感追踪技术路径,重构数字孪生与视频孪生交付逻辑
数字孪生长期深陷建模依赖的行业困局,传统技术路径均以人工建模、激光点云扫描、第三方测绘为前置核心环节,不仅带来高昂的资金投入、漫长的实施周期,更存在模型更新滞后、实景适配性差、运维成本高企等难以破解的行业顽疾。同时,…...

Verdi 2017.12实战:一步步教你用UVM Debug Mode追踪寄存器模型与Sequence事务
Verdi 2017.12实战:UVM Debug Mode全流程调试指南 在芯片验证领域,高效的调试能力直接决定项目进度。当测试平台遇到寄存器读写异常或sequence事务不符合预期时,如何快速定位问题根源?Verdi 2017.12提供的UVM Debug Mode正是为解决…...