Ceph crush运行图
Crush map介绍
ceph集群中由monitor负责维护的运行图包括:
- Monitor map:监视器运行图
- osd map:osd运行图
- PG map:PG运行图
- Crush map:crush运行图
- Mds map:mds运行图
crush map是ceph集群物理拓扑的抽象,CRUSH算法通过crush map中集群拓扑结构、副本策略以及故障域等信息,来选择存放数据的osd。
以我当前集群为例,crush map描述的集群物理拓扑结构层级如下图,包括3个层级,分别是root、host和osd:

导出当前集群的crush map
ceph osd getcrushmap -o crushmap.bin #导出之后是一个二进制文件
crushtool -d crushmap.bin -o crushmap.txt #使用crushtool将二进制文件解析为文本
当前集群的crush map内容如下:
# begin crush map
tunable choose_local_tries 0
tunable choose_local_fallback_tries 0
tunable choose_total_tries 50
tunable chooseleaf_descend_once 1
tunable chooseleaf_vary_r 1
tunable chooseleaf_stable 1
tunable straw_calc_version 1
tunable allowed_bucket_algs 54# devices
device 0 osd.0 class hdd
device 1 osd.1 class hdd
device 2 osd.2 class hdd
device 3 osd.3 class hdd
device 4 osd.4 class hdd
device 5 osd.5 class hdd
device 6 osd.6 class hdd
device 7 osd.7 class hdd
device 8 osd.8 class hdd
device 9 osd.9 class hdd
device 10 osd.10 class ssd
device 11 osd.11 class ssd
device 12 osd.12 class ssd
device 13 osd.13 class ssd
device 14 osd.14 class ssd
device 15 osd.15 class hdd
device 16 osd.16 class hdd
device 17 osd.17 class ssd# types
type 0 osd
type 1 host
type 2 chassis
type 3 rack
type 4 row
type 5 pdu
type 6 pod
type 7 room
type 8 datacenter
type 9 zone
type 10 region
type 11 root# buckets
host ceph-osd-05 {id -3 # do not change unnecessarilyid -4 class hdd # do not change unnecessarilyid -13 class ssd # do not change unnecessarily# weight 0.146alg straw2hash 0 # rjenkins1item osd.2 weight 0.049item osd.8 weight 0.049item osd.14 weight 0.049
}
host ceph-osd-04 {id -5 # do not change unnecessarilyid -6 class hdd # do not change unnecessarilyid -14 class ssd # do not change unnecessarily# weight 0.146alg straw2hash 0 # rjenkins1item osd.3 weight 0.049item osd.5 weight 0.049item osd.10 weight 0.049
}
host ceph-osd-01 {id -7 # do not change unnecessarilyid -8 class hdd # do not change unnecessarilyid -15 class ssd # do not change unnecessarily# weight 0.146alg straw2hash 0 # rjenkins1item osd.1 weight 0.049item osd.6 weight 0.049item osd.11 weight 0.049
}
host ceph-osd-03 {id -9 # do not change unnecessarilyid -10 class hdd # do not change unnecessarilyid -16 class ssd # do not change unnecessarily# weight 0.146alg straw2hash 0 # rjenkins1item osd.0 weight 0.049item osd.7 weight 0.049item osd.13 weight 0.049
}
host ceph-osd-02 {id -11 # do not change unnecessarilyid -12 class hdd # do not change unnecessarilyid -17 class ssd # do not change unnecessarily# weight 0.146alg straw2hash 0 # rjenkins1item osd.4 weight 0.049item osd.9 weight 0.049item osd.12 weight 0.049
}
host ceph-osd-06 {id -19 # do not change unnecessarilyid -20 class hdd # do not change unnecessarilyid -21 class ssd # do not change unnecessarily# weight 0.146alg straw2hash 0 # rjenkins1item osd.16 weight 0.049item osd.17 weight 0.049item osd.15 weight 0.049
}
root default {id -1 # do not change unnecessarilyid -2 class hdd # do not change unnecessarilyid -18 class ssd # do not change unnecessarily# weight 0.878alg straw2hash 0 # rjenkins1item ceph-osd-05 weight 0.146item ceph-osd-04 weight 0.146item ceph-osd-01 weight 0.146item ceph-osd-03 weight 0.146item ceph-osd-02 weight 0.146item ceph-osd-06 weight 0.146
}# rules
rule replicated_rule {id 0type replicatedmin_size 1max_size 10step take defaultstep chooseleaf firstn 0 type hoststep emit
}
rule erasure-code {id 1type erasuremin_size 3max_size 4step set_chooseleaf_tries 5step set_choose_tries 100step take defaultstep chooseleaf indep 0 type hoststep emit
}# end crush map
crush map主要由5部分组成:
- tunables:tunables参数主要用来修正一些旧BUG、优化算法以及向后兼容老版本
- devices:代表各个osd。是CRUSH树状结构的叶子节点
- types:bucket的类型,可以自定义,编号为正整数
- buckets:CRUSH树状结构的所有中间节点就叫bucket,bucket可以是一些device的集合,也可以是诸如(host、rack、room等)的集合
- rules:定义数据在集群中的分布策略,即pg选择osd的策略
tunables参数
各tunable参数含义如下:
#为了向后兼容应保持为0
tunable choose_local_tries 0
#为了向后兼容应保持为0
tunable choose_local_fallback_tries 0
#选择bucket的最大重试次数,如果重试50次crush算法还未选择出合适的bucket就失败,可以调整此参数
tunable choose_total_tries 50
#为了向后兼容应保持为1
tunable chooseleaf_descend_once 1
#修复旧bug,为了向后兼容应该保持为1
tunable chooseleaf_vary_r 1
#避免不必要的pg迁移,为做向后兼容应保持为1
tunable chooseleaf_stable 1
#straw算法版本,为了向后兼容应保持为1
tunable straw_calc_version 1
#允许使用的bucket选择算法,通过位运算计算得出的值
tunable allowed_bucket_algs 54
bucke选择算法包括:uniform、list、straw和straw2
devices
devices定义了集群中的每个osd,每个device都有一个id和name,例如osd.1中的1就是device的id
device也可以设置对应的类别,比如hdd、ssd,这样方便crush规则根据磁盘类型来选择osd
#device定格式
device {num} {osd.name} class {disk-type}例如:
device 0 osd.0 class hdd
device 1 osd.1 class hdd
device 13 osd.13 class ssd
types
types表示bucket的类型,crush树状结构中除了osd外,其余层级的节点都是bucket,osd一般作为叶子节点。每个bucket对应ceph集群的每个物理拓扑位置,每个bucket可以是低一层级bucket的集合或者是一些叶子节点的集合
可以自定义新的type,但按照惯例,叶子节点必须为osd,其type为0
ceph默认定义的11种type如下:
type 0 osd #osd
type 1 host #主机
type 2 chassis #刀片服务器的机箱
type 3 rack #机架/机柜
type 4 row #一排机柜
type 5 pdu #机柜的接入电源
type 6 pod #一个机房种的若干个小房间
type 7 room #机房
type 8 datacenter #数据中心
type 9 zone
type 10 region #区域
type 11 root #根节点
bucketes
所有的中间节点就叫bucket,bucket可以是一些devices的集合,也可以是低一级的buckets的集合,根节点root是整个集群的入口。
定义一个bucket时需要遵循以下语法:
<bucket-type> <bucket-name> {#全局唯一的负整数idid <-num>#所有item的存储容量,1代表1TB,0.5代表0.5TB,依次类推weight <num>#选择下一级bucket使用的算法,uniform、list、straw或straw2alg <value>#bucket使用的hash算法,默认为0hash <value>#低一层级的bucket名称,以及其对应的weightitem <item-name> weight <weight-value>
}
例如当前集群中有6个节点,每个节点上有两块50G HDD和一块50G SSD,其定义如下:
host ceph-osd-05 {id -3 # do not change unnecessarilyid -4 class hdd # do not change unnecessarilyid -13 class ssd # do not change unnecessarily# weight 0.146alg straw2hash 0 # rjenkins1item osd.2 weight 0.049item osd.8 weight 0.049item osd.14 weight 0.049
}
host ceph-osd-04 {id -5 # do not change unnecessarilyid -6 class hdd # do not change unnecessarilyid -14 class ssd # do not change unnecessarily# weight 0.146alg straw2hash 0 # rjenkins1item osd.3 weight 0.049item osd.5 weight 0.049item osd.10 weight 0.049
}
rules
rules定义了pool中数据在集群中的存储规则,crush算法的每一步都按照规则来执行
默认情况下,crush map中定义了两个rule:replicated_rule和erasure-code,分别对应副本池和纠删码池。用户可以根据自己的需求添加不同的rule,并为pool指定不同的rule。比如,对于性能要求较高的业务,将其数据存储在ssd pool中,其余业务的数据存放在hdd pool中。
rule的定义规范如下:
rule <rule-name> {#全局唯一的idid <num>#副本类型,副本或纠删码type <replicated|erasure>#如果副本数小于该值,不会采用此ruleminsize <num>#如果副本数大于该值,不会采用该rulemaxsize <num>#crush规则选择bucket的入口,如果指定了device-class,则必须选择匹配类型的osdstep take <bucket-name> [class <device-calss>]#crush规则选择bucket的方式,分为choose和chooseleaf两种,N代表选择的数量,<bucket-type>是预期的bucket类型,代表故障域step <choose|chooseleaf> <firstn|indep> <N> type <bucket-type>#代表规则执行结束,返回选择结果给客户端step emit
}
关于step <choose|chooseleaf> <firstn|indep> type 的含义如下:
-
choose:表示选择到预期数量和类型的的bucket即可结束
-
chooseleaf:表示选择到预期数量和类型的bucket,并从这些bucket中选出osd。chooseleaf可以看做是choose的封装,如果只使用choose,需要定义多条choose规则最终选择出osd
例如,下面的chooselaef规则和choose规则的作用是一致的:
step chooseleaf firstn 0 type hoststep choose firstn 0 type host
step choose firstn 1 type osd
-
firstn和indep:当出现osd down的情况时,用于控制CRUSH的副本策略。副本池使用firstn,纠删码池选择indep,纠删码池要求选择结果是有序的
例如:一个PG分布在osd 1、2、3、4、5上,然后3 down了
在firstn模式下,crush算法会选择1、2,选择3时发现down掉了,然后接着选择4、5,最后选择一个新的未down掉的6,最终结果会变迁为[1、2、3、4、5] -> [1、2、4、5、6]
在indep模式下,crush算法会选择1、2,选择3时发现其down掉了,接着会尝试选择一个未down掉的6,然后选择4、5,最终的结果会变迁为[1、2、3、4、5] -> [1、2、6、4、5]
-
N:如果N=0,选择的数量等于副本数;如果0<N<副本数,选择的数量等于N;如果N<0,选择的数量等于副本数-N
crush map默认的副本池规则和纠删码池规则如下:
rule replicated_rule {id 0type replicatedmin_size 1max_size 10step take default #从default根节点开始选择bucketstep chooseleaf firstn 0 type host #以host为故障域,选择3个host,并从这3个host上分别选择一个osdstep emit
}
rule erasure-code {id 1type erasuremin_size 3max_size 4step set_chooseleaf_tries 5step set_choose_tries 100step take defaultstep chooseleaf indep 0 type host #选择step emit
}
Crush map调整案例
osd权重调整
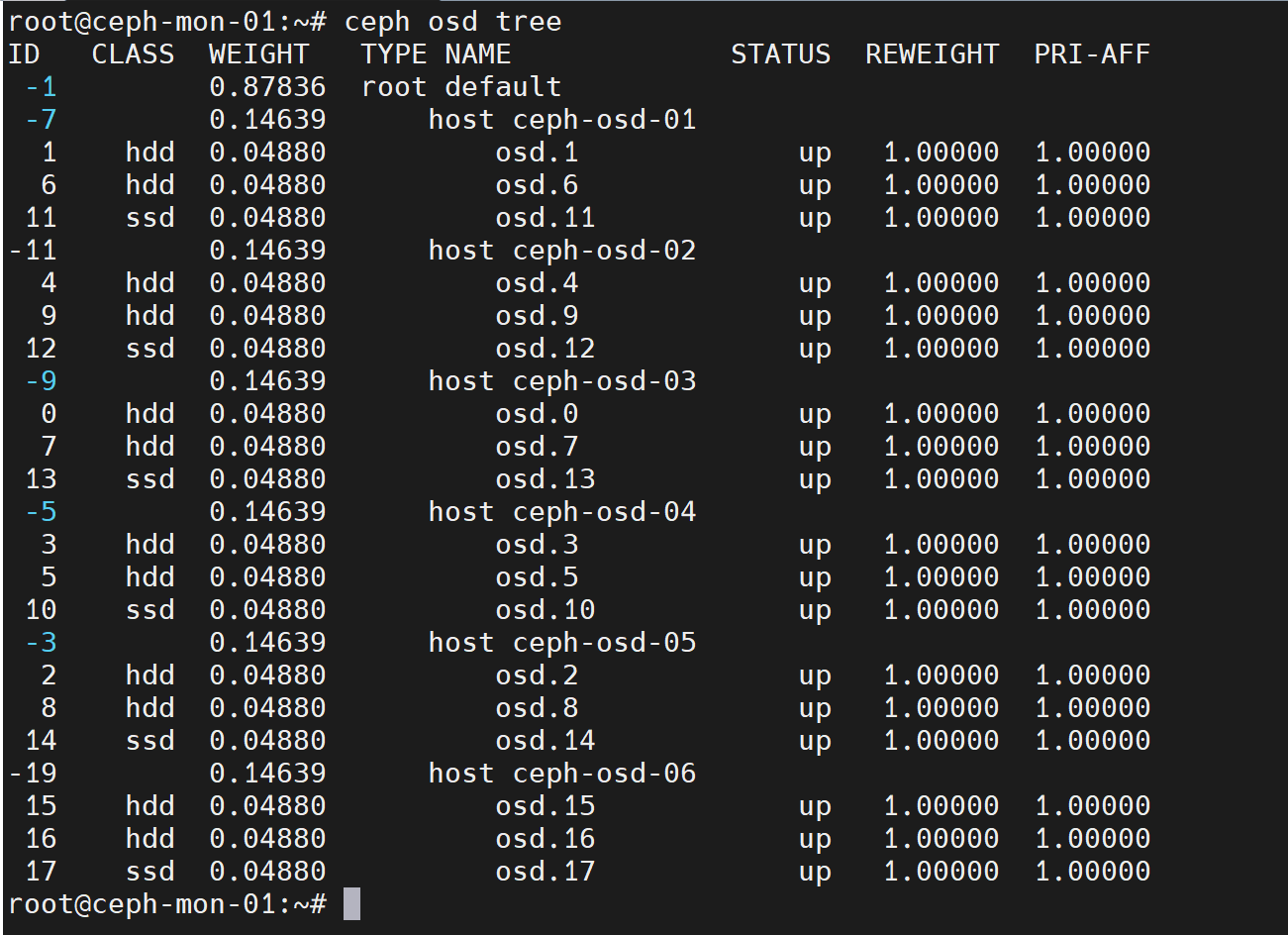
每个osd设备有weight属性和reweight属性:
- weight表示该osd的容量相对值,1TB对应1.00,500G对应0.5,依此类推。通过weight属性可以实现基于磁盘空间分配PG数量,让crush算法尽可能往磁盘空间大的osd多分配PG,往磁盘空间小的osd少分配PG
- reweight属性的目的是重新平衡crush算法随机分配的PG,默认的分配是概率上的均衡,即使所有osd都是一样的容量也会产生一些PG分布不均匀的情况,此时可以通过调整reweight参数,让ceph集群立即重新平衡当前磁盘的PG,以达到数据重新平衡的目的。reweight的值只能在0到1之间。
修改osd的weight值
ceph osd crush reweight osd.1 0.1 #修改osd.1的权重为0.1
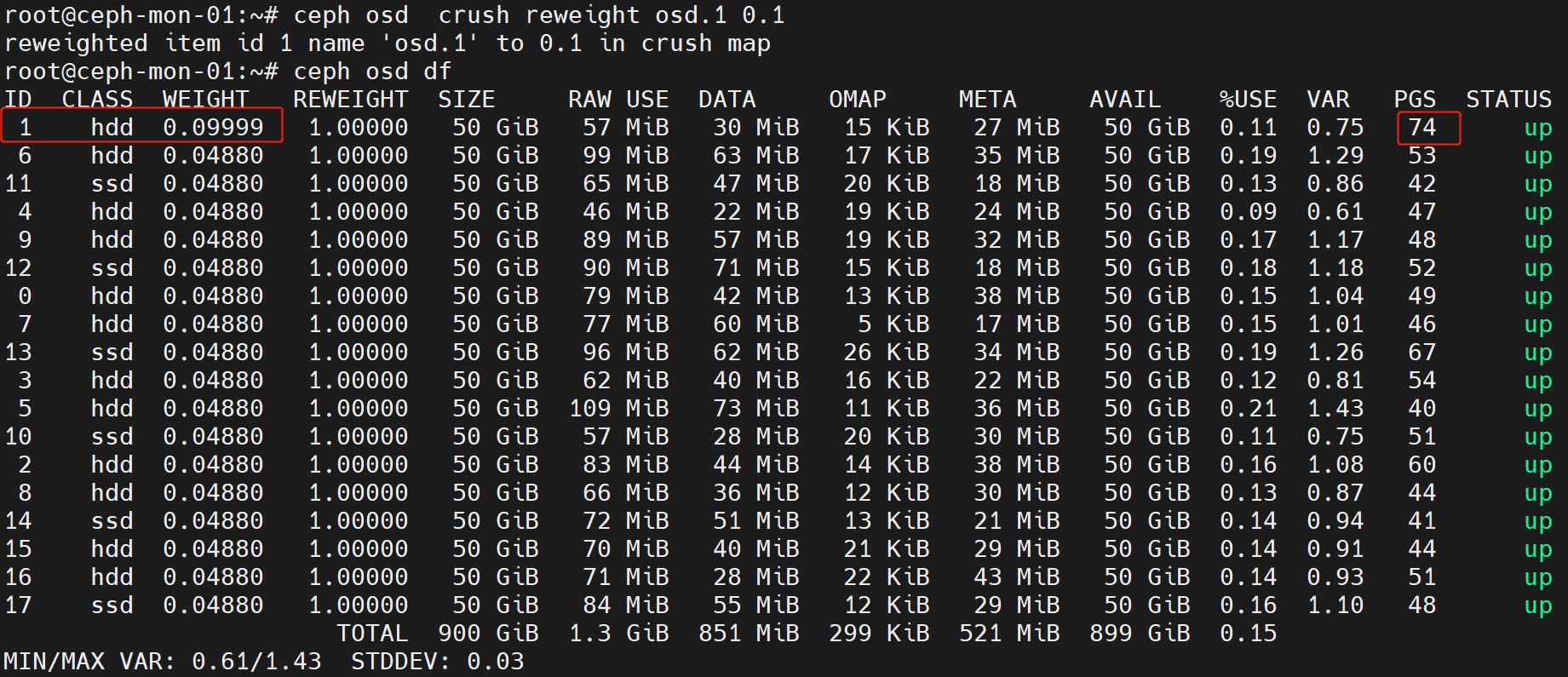
修改osd的reweight值
ceph osd reweight osd.5 0.8 #修改osd.5的reweight的值为0.8
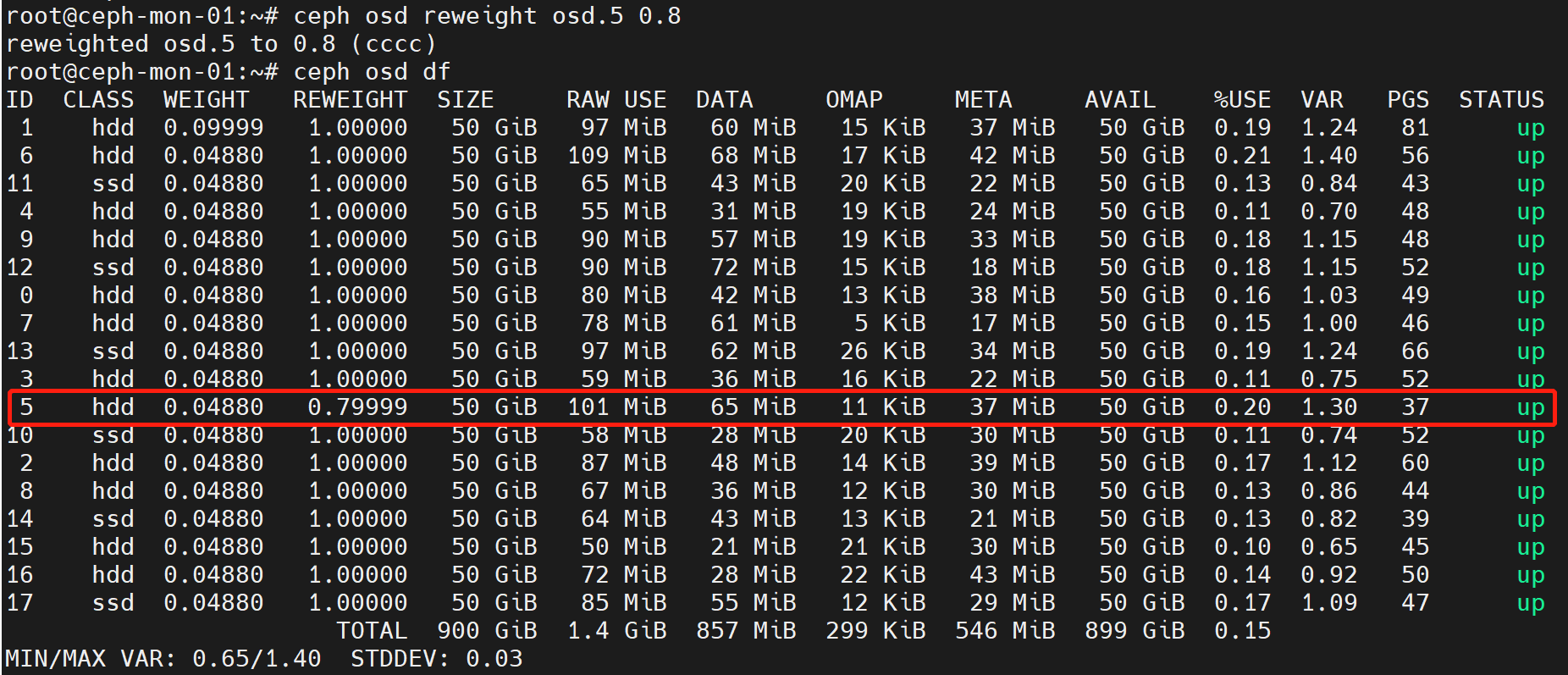
在osd使用率不均匀的时候,可以通过调低使用率较高的osd的reweight值来触发pg数据迁移,降低osd利用率。
不过要注意,修改osd的weight和reweight值都会立即触发pg数据迁移,在数据量较大时可能会集群性能。
数据分类存放(ssd pool和hdd pool)
集群中ssd和hdd磁盘共存时,可以创建ssd存储池和hdd存储池,将对存储性能要求较高的业务的数据存放在ssd存储池中,以提升业务性能
创建两条针对副本池的crush rule
#语法格式
#ceph osd crush rule create-replicated <rule-name> <root-name> <bucket-type> <device-class>#创建名为rule-ssd的规则,从根default开始选择host类型bucket,并最终从host中选择ssd类型的osd
ceph osd crush rule create-replicated rule-ssd default host ssd #创建名为rule-hdd的规则,从根default开始选择host类型bucket,并最终从host中选择hdd类型的osd
ceph osd crush rule create-replicated rule-ssd default host hddceph osd crush rule list #查看crush rule规则

创建两个pool,分别使用上面的rule-ssd和rule-hdd
ceph osd pool create ssd-pool 16 16 replicated rule-ssd
ceph osd pool create hdd-pool 16 16 replicated rule-hdd
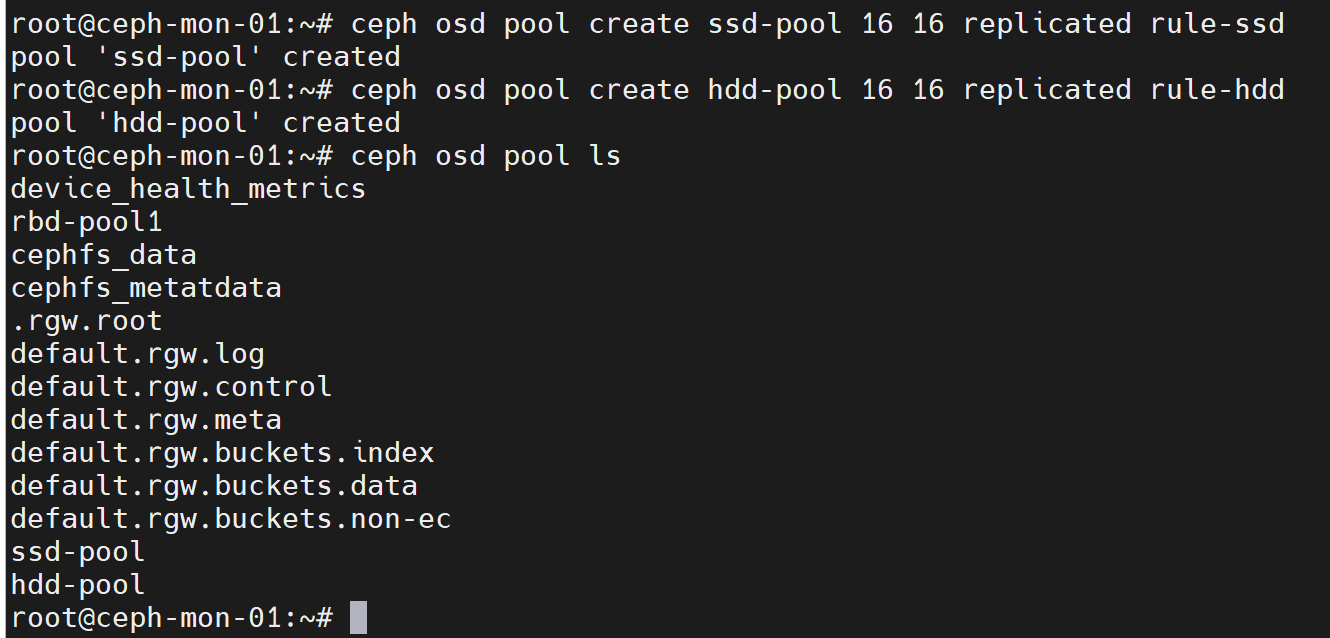
查看两个pool中pg对应的osd组合
ceph osd crush class ls-osd ssd #列出所有ssd类型的osd
ceph osd crush class ls-osd hdd #列出所有hdd类型的osd
ceph pg ls-by-pool ssd-pool |awk '{print $1,$2,$15}'
ceph pg ls-by-pool hdd-pool |awk '{print $1,$2,$15}'
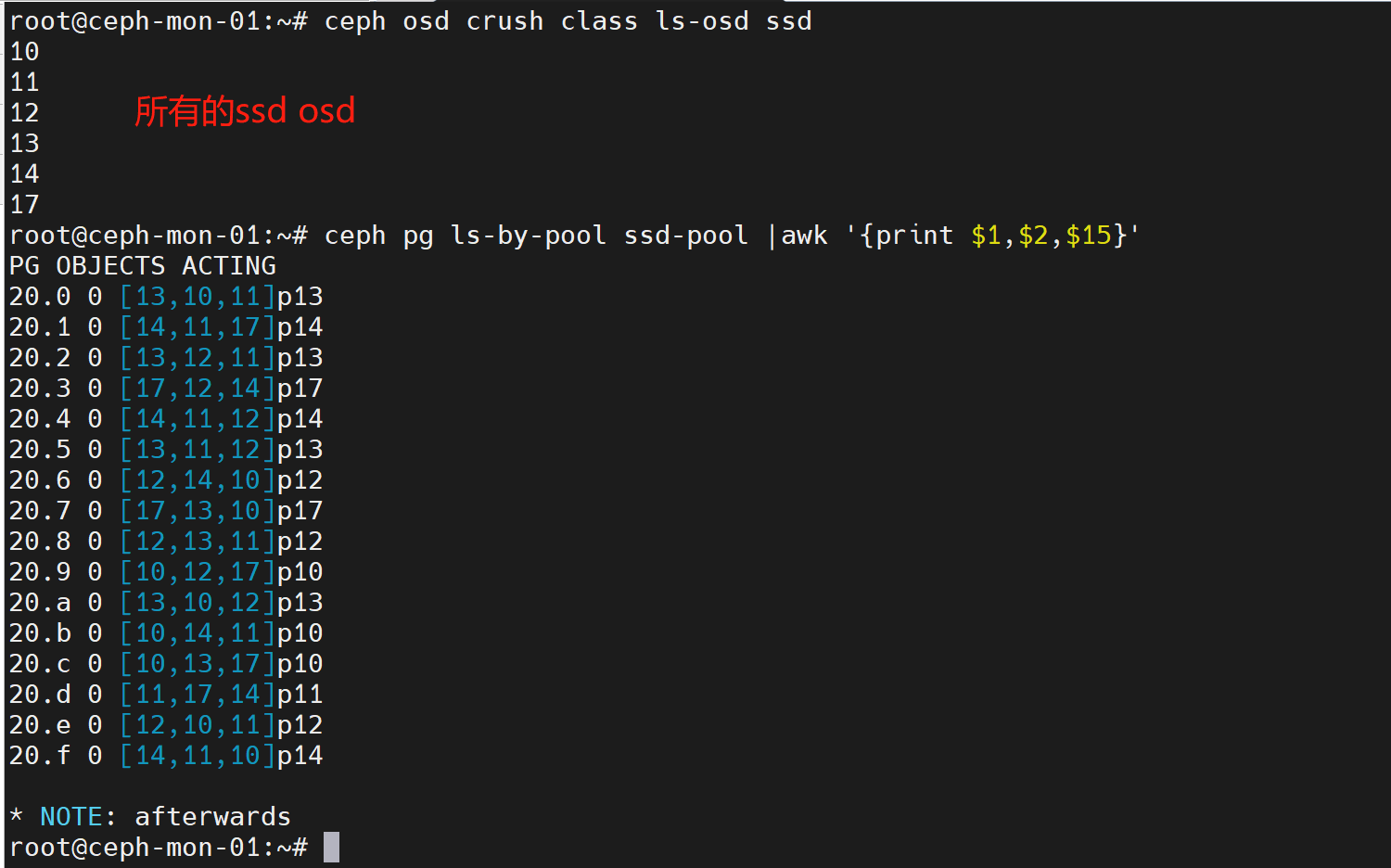
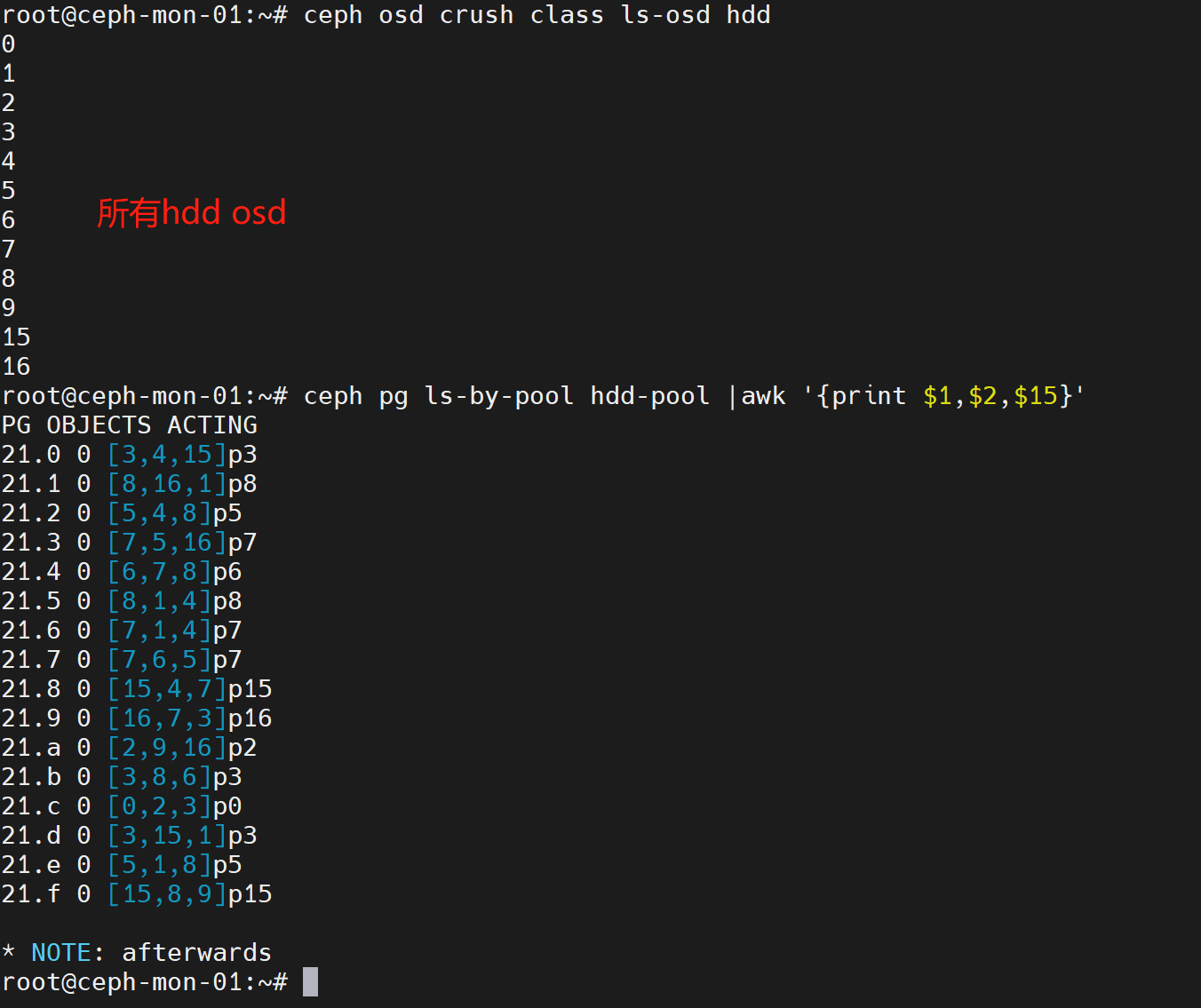
如上图,所有ssd-pool中的pg都分布在ssd osd上,hdd-pool中的pg都分布在hdd osd上。
以rack为故障域
将集群的物理拓扑修改为以下结构:
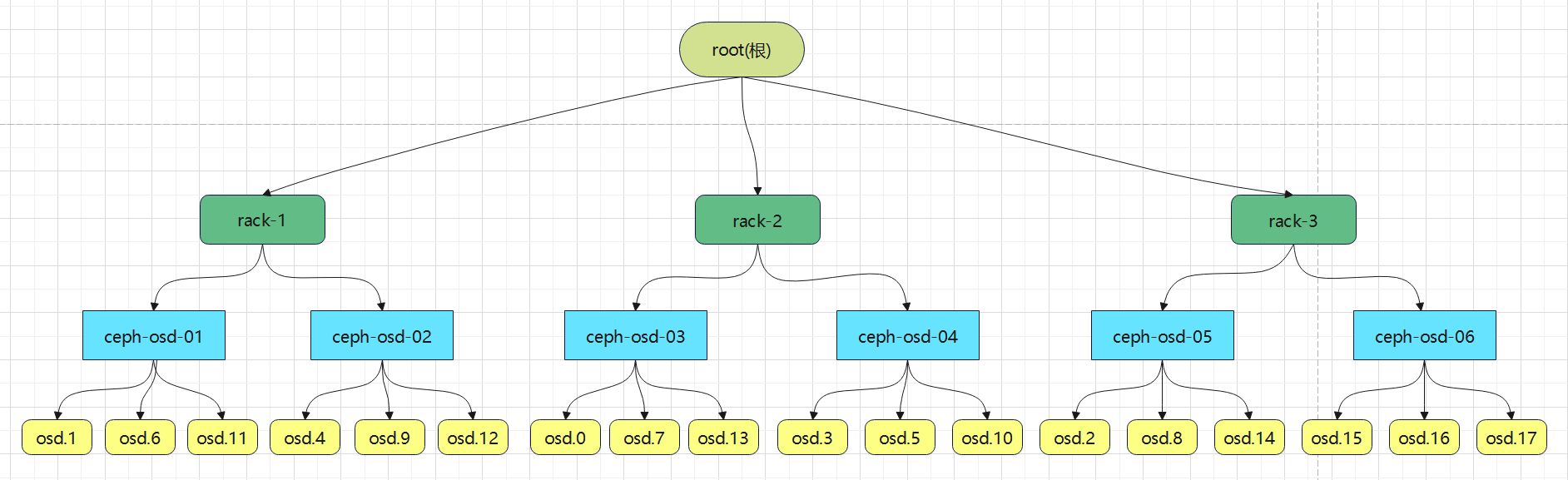
导出集群当前的crush map
ceph osd getcrushmap -o crushmap.bin
crushtool -d crushmap.bin -o crushmap-v1.txt
cp crushmap-v1.txt crushmap-v2.txt
修改crush map,添加rack bucket和crush rule
vim crushmap-v2.txt
###############################################
#添加3个rack类型的bucket,每个rack包含两个host
rack rack-1 {id -25id -26 class hddid -27 class ssd# weight 0.294alg straw2hash 0item ceph-osd-01 weight 0.148item ceph-osd-02 weight 0.146
}rack rack-2 {id -28id -29 class hddid -30 class ssd# weight 0.292alg straw2hash 0item ceph-osd-03 weight 0.146item ceph-osd-04 weight 0.146
}rack rack-3 {id -31id -32 class hddid -33 class ssd# weight 0.292alg straw2hash 0item ceph-osd-05 weight 0.146item ceph-osd-06 weight 0.146
}#添加一个根节点,包含3个rack
root rep-rack {id -34id -35 class hddid -36 class ssd# weight 0.880alg straw2hash 0item rack-1 weight 0.294item rack-2 weight 0.292item rack-3 weight 0.292
}#添加一个副本型rule,以rack为故障域
rule rule-cross-rack {id 4type replicatedmin_size 1max_size 10step take rep-rackstep chooseleaf firstn 0 type rackstep emit
}
###############################################
导入修改后的crush map
crushtool -c crushmap-v2.txt -o crushmap-v2.bin
ceph osd setcrushmap -i crushmap-v2.bin
可以通过ceph osd tree验证新的物理拓扑结构是否生效,如下图
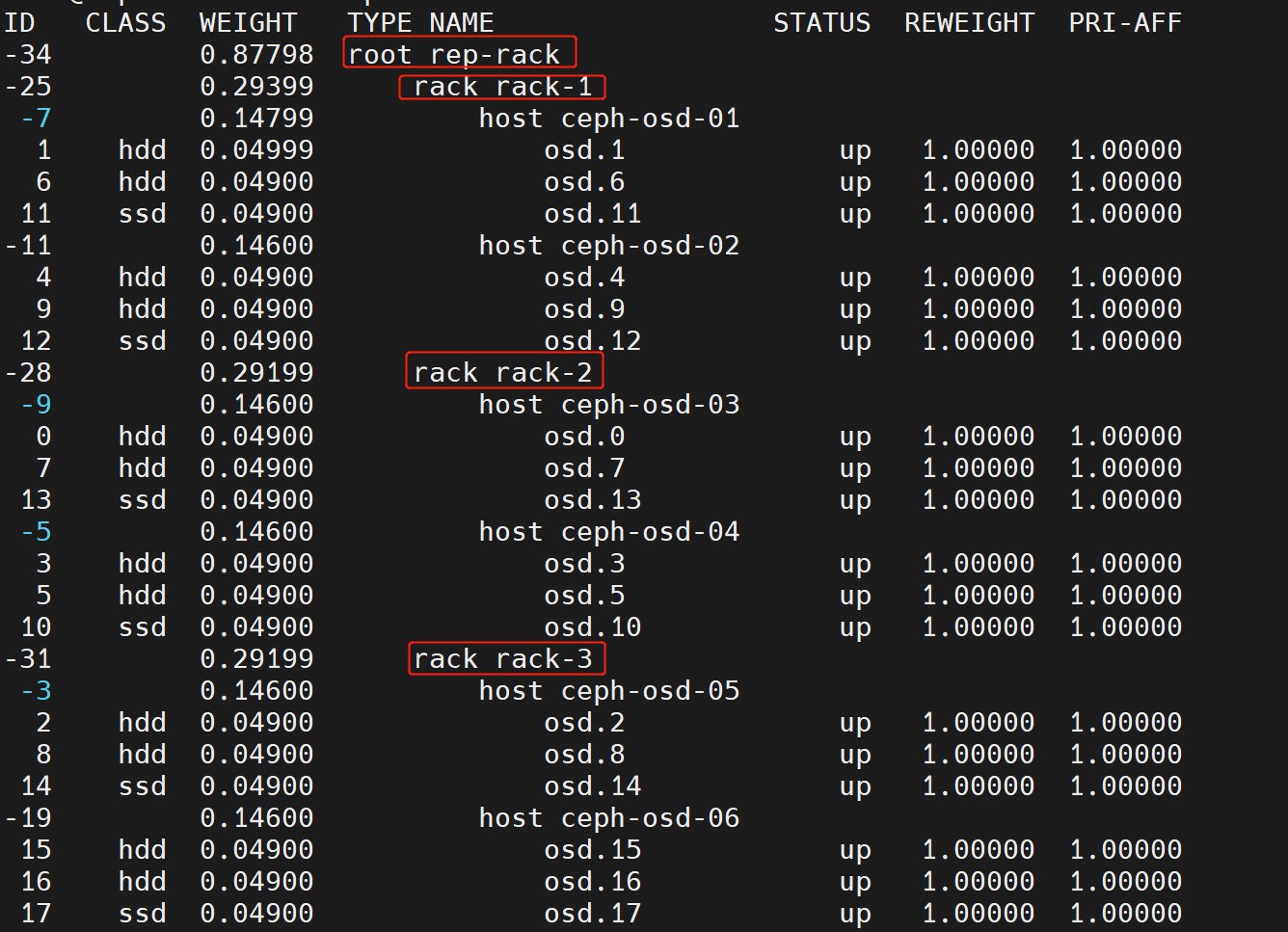
创建pool验证
ceph osd pool create cross-rack-pool 16 16 replicated rule-cross-rack
ceph pg ls-by-pool cross-rack-pool | awk '{print $1,$2,$15}' #查看pg对应osd
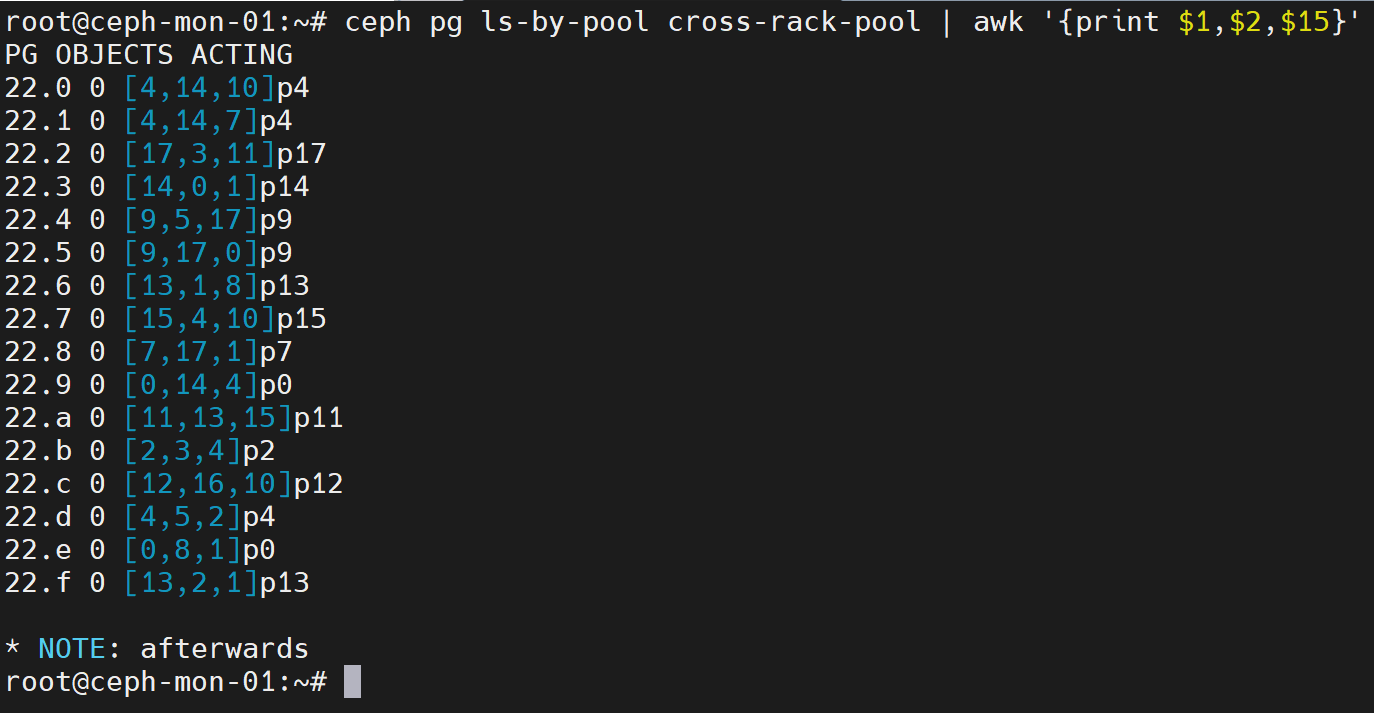
如上图,pg对应的osd都分布在不同的rack
相关文章:
Ceph crush运行图
Crush map介绍 ceph集群中由monitor负责维护的运行图包括: Monitor map:监视器运行图osd map:osd运行图PG map:PG运行图Crush map:crush运行图Mds map:mds运行图 crush map是ceph集群物理拓扑的抽象&…...

【分布族谱】泊松分布和二项分布、正态分布的关系
文章目录 泊松分布和二项分布的关系和正态分布的关系 泊松分布 如果在有限时间 ( 0 , 1 ) (0,1) (0,1)内进行 n n n次伯努利实验,那么每次伯努利实验所占用的时间为 1 n \frac{1}{n} n1,按照自然规律,一件事情肯定是时间越长越容易发生&am…...

关于QTreeWidget的setData函数
当使用 Q T r e e W i d g e t I t e m QTreeWidgetItem QTreeWidgetItem 的 s e t D a t a setData setData 方法时,需要传递三个参数,分别是列索引、角色和数据。 列索引:表示要设置数据的列的索引。 Q T r e e W i d g e t I t e m QTre…...
Microsoft Office 2003的安装
哈喽,大家好。今天一起学习的是office2003的安装,这个老版本的office可是XP操作系统的老搭档了,有兴趣的小伙伴也可以来一起试试手。 一、测试演示参数 演示操作系统:Windows XP 不建议win7及以上操作系统使用 系统类型ÿ…...

使用Spring Boot和Spring Cloud实现多租户架构:支持应用多租户部署和管理
使用Spring Boot和Spring Cloud实现多租户架构:支持应用多租户部署和管理 一、概述1 什么是多租户架构?2 多租户架构的优势3 实现多租户架构的技术选择 二、设计思路1 架构选型1.1 Spring Boot1.2 Spring Cloud 2 数据库设计3 应用多租户部署3.1 应用隔离…...

智聚北京!相约全球人力资源数智化峰会
人力资源是推动经济社会发展的第一资源。作为我国经济压舱石的中央企业在对标世界一流企业和管理提升方面的持续创新,各行业领军企业围绕组织变革、管理升级、全球化发展走深走实。人力资源管理正从传统职能管理与管控,向紧贴业务战略实现、组织边界和人…...

工业缺陷检测数据及代码(附代码)
介绍 目前,基于机器视觉的表面缺陷检测设备已广泛取代人工视觉检测,在包括3C、汽车、家电、机械制造、半导体与电子、化工、制药、航空航天、轻工等多个行业领域得到应用。传统的基于机器视觉的表面缺陷检测方法通常采用常规图像处理算法或人工设计的特征加分类器。一般而言…...
CentOS 安装MongoDB 6.0
一、安装依赖 yum install libcurl openssl xz-libs 二、下载安装包 安装包下载地址https://www.mongodb.com/try/download/community这里我选择的是 选择RedHat / CentOS 7.0平台的原因是我的操作系统使用的是CentOS 7.0的,需要下载与操作系统匹配的安装包 三、…...
美团面试,被拷打了一小时....
刚从美团走出来,被拷打了一小时…越想越觉得可惜,回想面试经过,好好总结了几个点,发现面试没过的主要原因是在几个关键的问题没有给到面试官想要的答案。从而失去了这次宝贵的机会。 根据你的工作经历,说说你对质量保证…...

017+C语言中函数栈帧的创建与销毁(VS2022环境)
0.前言 您好,这里是limou3434的一篇个人博文,感兴趣的话您也可以看看我的其他文章。本次我将和您一起学习在C语言中函数栈帧的概念。 1.学习函数栈帧的意义 局部变量是怎么穿创建的?为什么局部变量的值是随机的函数是怎么传参的࿱…...

马斯克们叫停 GPT-5,更像是场行为艺术
目录 01 联名信说了什么? 02 发起方是谁? 03 谁签署了联名信? 04 联名信有哪些问题?三巨头的另外两位 Sam Altman 的表态 其他值得关注的署名者 比如马斯克。 另一个位于前列的署名者是 Stability AI 的创始人 Emad Most…...

事务基础知识
第13章 事务基础知识 1. 数据库事务概述 1.1 基本概念 **事务:**一组逻辑操作单元,使数据从一种状态变换到另一种状态。 **事务处理的原则:**保证所有事务都作为一个工作单元来执行,即使出现了故障,都不能改变这种…...

国产高性能DSP音频处理芯片的工作原理以及应用领域
DSP芯片是数字信号处理器的简称,它是一种专门用于数字信号处理的微处理器,它可以对数字信号进行高速运算和处理。DSP是一类嵌入式通用可编程微处理器,主要用于实现对信号的采集、识别、变换、增强、控制等算法处理,是各类嵌入式系…...

BEVDet4D 论文学习
1. 解决了什么问题? 单帧数据包含的信息很有限,制约了目前基于视觉的多相机 3D 目标检测方法的性能,尤其是关于速度预测任务,要远落后于基于 LiDAR 和 radar 的方法。 2. 提出了什么方法? BEVDet4D 将 BEVDet 方法从…...
:如何设计实现一个集群环境下的分布式单例模式?)
【设计模式与范式:创建型】43 | 单例模式(下):如何设计实现一个集群环境下的分布式单例模式?
上两节课中,我们针对单例模式,讲解了单例的应用场景、几种常见的代码实现和存在的问题,并粗略给出了替换单例模式的方法,比如工厂模式、IOC 容器。今天,我们再进一步扩展延伸一下,一块讨论一下下面这几个问…...
Metal入门学习:绘制渲染三角形
一、编程指南PDF下载链接(中英文档) 1、Metal编程指南PDF链接 https://github.com/dennie-lee/ios_tech_record/raw/main/Metal学习PDF/Metal 编程指南.pdf 2、Metal着色语言(Metal Shader Language:简称MSL)编程指南PDF链接 https://github.com/dennie-lee/ios_te…...
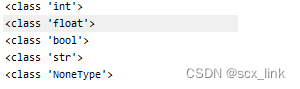
python 中常见变量类型
数值 a 10 b 123 … 字符串 在python中 用单引号’‘和双引号""括起来的都是字符串,不使用引号括起来的不是字符串,字符串是使用最多的数据类型,用来表示一段文本信息。 比如: a ‘123’ b “123” 字符串之间可以用加法运算…...
SVN使用教程(一)
文章目录 前言一、SVN是什么?二、SVN和Git对比,有什么优势?三、SVN主要应用四、SVN仓库五、安装SVN客户端 前言 提示:这里可以添加本文要记录的大概内容: 在制作系统或者写文档,都需要用于管理和跟踪开发…...

【5.19】四、性能测试—指标、种类
目录 4.1 性能测试概述 4.2 性能测试的指标 4.3 性能测试的种类 为了追求高质量、高效率的生活与工作,人们对软件产品的性能要求越来越高,例如软件产品要足够稳定、响应速度足够快,在用户量、工作量较大时也不会出现崩溃或卡顿等现象。人们…...
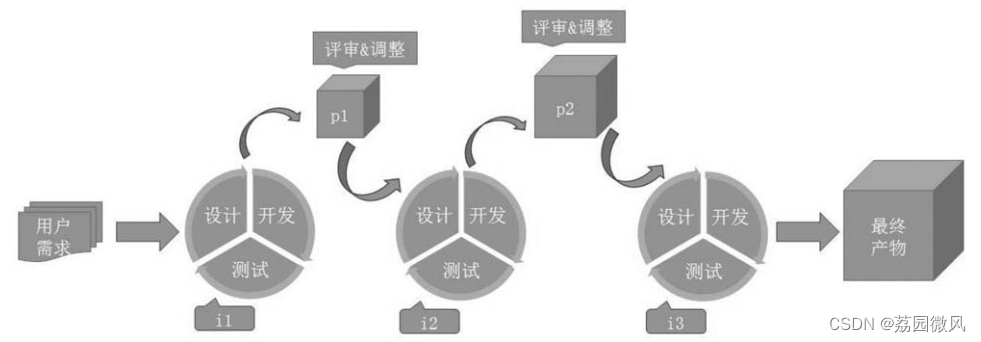
Windows平台上的5种敏捷软件开发(过程)模型
我是荔园微风,作为一名在IT界整整25年的老兵,今天总结一下Windows平台上的5种敏捷软件开发(过程)模型。 说到这个问题,你必须先知道除了敏捷模型还有没有其他什么模型?同时要比较模型的区别,首先还要看看什么叫软件开…...

保姆级教程:用iSYSTEM winIDEA和iC5000给S32K148烧录程序,附完整配置流程
从零掌握iSYSTEM工具链:S32K148开发板烧录与调试全流程实战第一次接触iSYSTEM的winIDEA和iC5000仿真器时,很多嵌入式开发者都会感到无从下手。不同于常见的开源工具链,这套专业级开发环境在汽车电子和工业控制领域有着广泛应用,尤…...
)
保姆级教程:在CentOS 7上用达梦8搭建DCA练习环境(附ulimit、VNC、ODBC全配置)
达梦8 DCA认证实战:CentOS 7环境搭建与调优全指南 在国产数据库技术快速发展的今天,达梦数据库作为核心产品之一,其DCA认证已成为众多从业者提升竞争力的重要选择。与理论为主的认证不同,DCA更注重实际操作能力,而一个…...

量子计算中Loschmidt回声相位测量的创新方法
1. 量子计算中的Loschmidt回声相位测量方法概述Loschmidt回声是量子动力学中一个重要的概念,它描述了量子系统在时间反演演化后与初始状态的相似程度。在量子计算领域,精确测量Loschmidt回声的相位信息对于理解量子系统的非平衡态行为、计算能量本征值以…...

从Office功能区的“局外人“到“掌控者“:Office RibbonX Editor深度指南
从Office功能区的"局外人"到"掌控者":Office RibbonX Editor深度指南 【免费下载链接】office-ribbonx-editor An overhauled fork of the original Custom UI Editor for Microsoft Office, built with WPF 项目地址: https://gitcode.com/g…...

搞定这 5 个全栈电商项目,面试别再用 Todo-List 凑数了
找独立开发练手项目或者写简历项目时,最忌讳两件事:一是太简单(纯前端 Mock 数据,点两下就没了),二是太假(一上来就硬套微服务、消息队列、高并发,结果自己根本Hold不住)…...

第三卷第4章:原型模式设计思想
第三卷第4章:原型模式设计思想 目录介绍 01.案例引入与思考 1.1 痛点场景 1.2 它哪里不舒服 1.3 引出本篇主角 02.原型模式介绍 2.1 原型模式由来 2.2 原型模式定义...

双稳健机器学习:用正交性与交叉拟合解决因果推断中的ML偏差
1. 项目概述:当机器学习遇见因果推断的“干扰”难题在实证研究的日常工作中,我们常常面临一个核心矛盾:我们真正关心的,往往只是一个或几个关键参数——比如一项政策对就业率的平均影响(平均处理效应,ATE&a…...

<背包问题>
背包问题是一类组合优化问题,其基本形式是给定一组物品,每个物品都有一个重量和一个价值,以及一个有限的背包容量,目标是在不超过背包容量的前提下,选择物品使得背包中的物品价值最大化。动态规划是解决背包问题的常用…...

对比自行维护多个 API 源,使用 Taotoken 聚合服务在运维复杂度上的降低
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比自行维护多个 API 源,使用 Taotoken 聚合服务在运维复杂度上的降低 在构建依赖多个大语言模型的应用时,…...

工业云脑:06 现在就能干:树莓派边缘盒子+PLC,10分钟缺陷检测小案例
06 现在就能干:树莓派边缘盒子+PLC,10分钟缺陷检测小案例 今天第九篇06小节——现在就能干:树莓派边缘盒子+PLC,10分钟缺陷检测小案例。新手照着做10分钟就能跑起来,老手一看就知道这玩意儿省了多少钱。以前想上AI检测,得花几万块买专业边缘盒子;现在?树莓派5(RPi 5)…...