【微服务】Elasticsearch数据聚合自动补全数据同步(四)
🚗Es学习·第四站~
🚩Es学习起始站:【微服务】Elasticsearch概述&环境搭建(一)
🚩本文已收录至专栏:微服务探索之旅
👍希望您能有所收获
在第二站的学习中,我们已经导入了大量数据到es中,实现了数据存储功能。接下来如需看自己实操效果请根据第二站的三.环境搭建部分导入初始数据。
一.数据聚合
(1) 聚合的作用
聚合(aggregations)可以让我们极其方便的实现对数据的统计、分析、运算。例如:
- 什么品牌的手机最受欢迎?
- 这些手机的平均价格、最高价格、最低价格?
- 这些手机每月的销售情况如何?
实现这些统计功能的比数据库的sql要方便的多,而且查询速度非常快,可以实现近实时搜索效果。
(2) 聚合的种类
聚合常见的有三类:
-
桶(Bucket)聚合:用来对文档做分组
- TermAggregation:按照文档字段值分组,例如按照品牌值分组、按照国家分组
- Date Histogram:按照日期阶梯分组,例如一周为一组,或者一月为一组
-
度量(Metric)聚合:用以计算一些值,比如:最大值、最小值、平均值等
- Avg:求平均值
- Max:求最大值
- Min:求最小值
- Stats:同时求max、min、avg、sum等
-
管道(pipeline)聚合:其它聚合的结果为基础做聚合

注意:参加聚合的字段必须是keyword、日期、数值、布尔类型
(3) Bucket聚合
如果我们要统计所有数据中的酒店品牌有几种,其实就是按照品牌对数据分组。此时可以根据酒店品牌的名称做聚合,也就是Bucket聚合。
(3.1) 基本使用
语法如下:
GET /hotel/_search
{"size": 0, // 设置size为0,设置结果中不包含文档,只包含聚合结果"aggs": { // 定义聚合"brandAgg": { //给聚合起个名字"terms": { // 聚合的类型,按照品牌值聚合,所以选择term"field": "brand", // 参与聚合的字段"size": 20 // 希望获取的聚合结果数量}}}
}
结果如图:

doc_count为聚合分组后其中文档的数量。
(3.2) 结果排序
默认情况下,Bucket聚合会统计Bucket内的文档数量,记为_count,并且按照_count降序排序。
我们可以通过指定order属性,自定义聚合的排序方式:
GET /hotel/_search
{"size": 0, "aggs": {"brandAgg": {"terms": {"field": "brand","order": {"_count": "asc" // 按照_count升序排列},"size": 20}}}
}
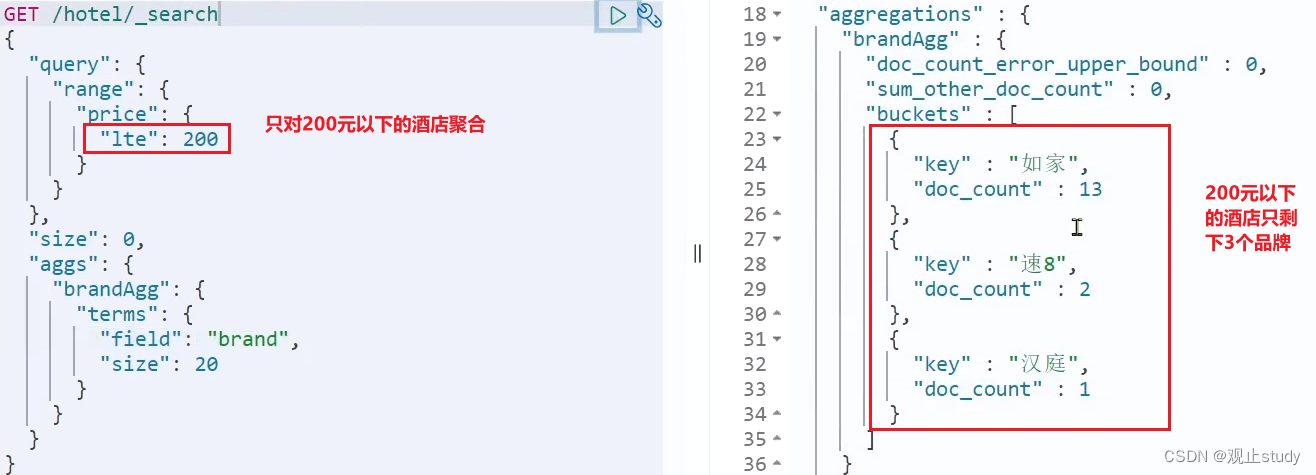
(3.3) 限定范围
默认情况下,Bucket聚合是对索引库的所有文档做聚合,但真实场景下,只会对用户搜索的结果聚合。因此上述聚合必须添加限定条件。
我们要限定聚合的文档范围,只需添加query条件即可:
GET /hotel/_search
{"query": {"range": {"price": {"lte": 200 // 只对200元以下的文档聚合}}}, "size": 0, "aggs": {"brandAgg": {"terms": {"field": "brand","size": 20}}}
}
这次,聚合得到的品牌明显变少了:
(4) Metric聚合
上述我们通过使用Bucket聚合对酒店按照品牌分组,形成了一个个桶。现在我们需要对桶内的酒店做运算,获取每个品牌的用户评分的min、max、avg等值。
这就要用到Metric聚合了,例如stat聚合:就可以获取min、max、avg等结果。
语法如下:
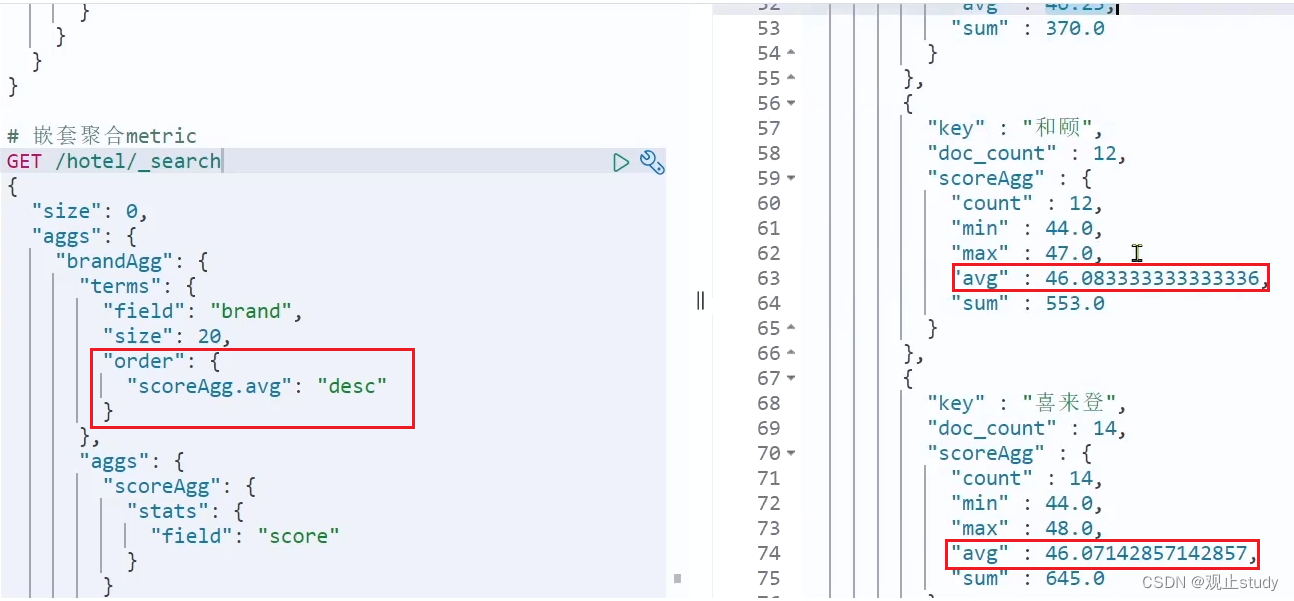
GET /hotel/_search
{"size": 0, "aggs": {"brandAgg": { "terms": { "field": "brand", "size": 20},"aggs": { // 是brands聚合的子聚合,也就是分组后对每组分别计算"score_stats": { // 聚合名称"stats": { // 聚合类型,这里stats可以计算min、max、avg等"field": "score" // Metric聚合字段,这里是score}}}}}
}
这里的score_stats聚合是在brandAgg的聚合内部嵌套的子聚合。因为我们需要在每个桶分别计算。
另外,我们还可以给聚合结果做个排序,例如按照每个桶的酒店平均分做排序:
(5) RestAPI实现聚合
(5.1) 基础语法
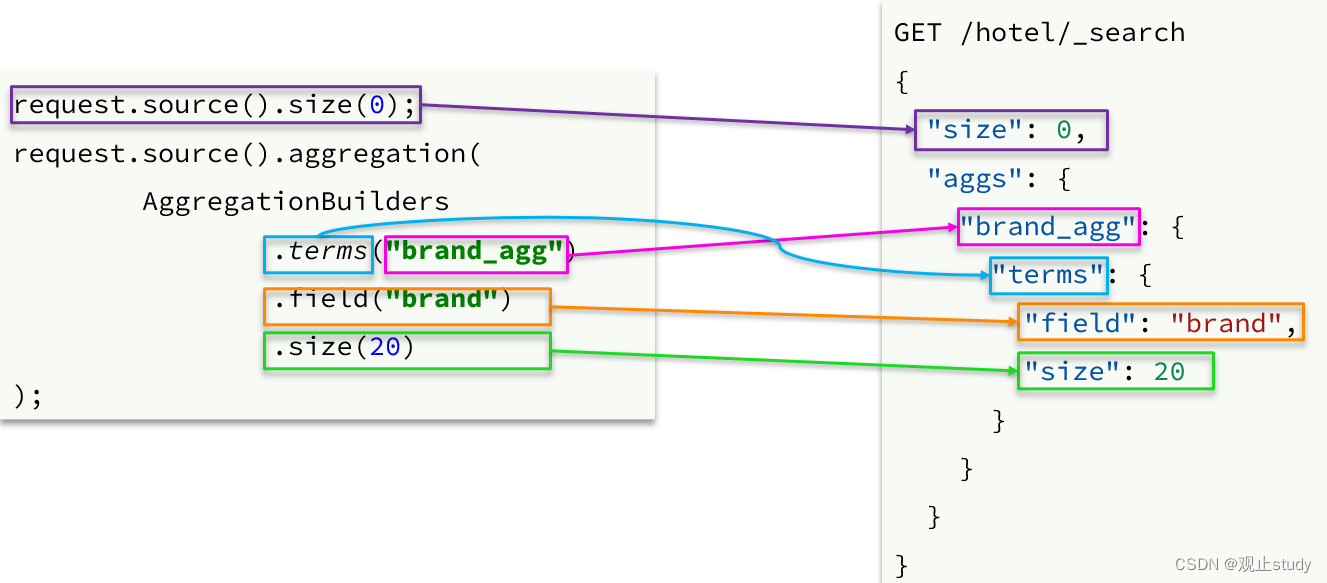
聚合条件与query条件同级别,因此需要使用request.source()来指定聚合条件。
聚合条件的语法:
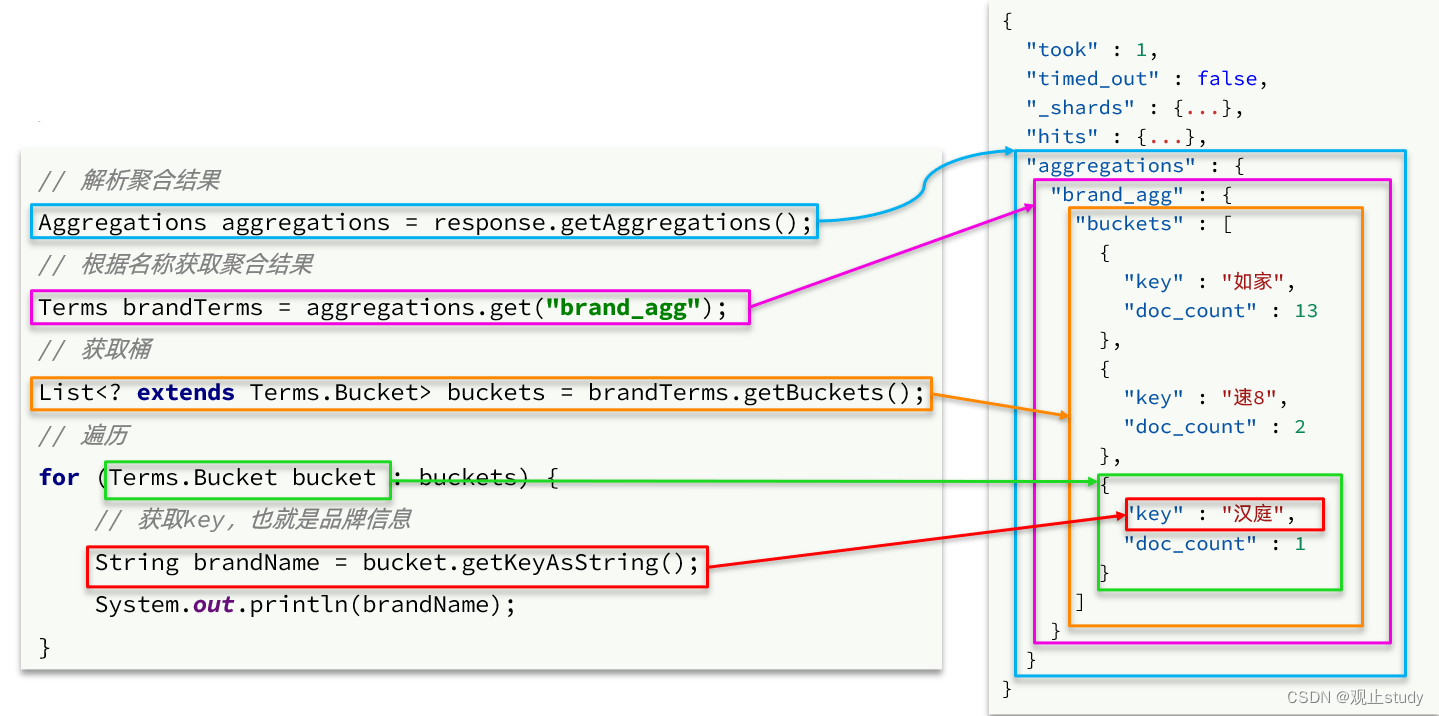
聚合的结果也与查询结果不同,API也比较特殊。不过同样是JSON逐层解析:
(5.2) 使用示例
需求:查询杭州的所有酒店分类数据。
@Test
void tesAggregationt( ) {// 1.准备RequestSearchRequest request = new SearchRequest("hotel");// 2.准备DSL// 2.1.queryrequest.source().query(QueryBuilders.termQuery("city","杭州"));// 2.2.设置sizerequest.source().size(0);// 2.3.聚合request.source().aggregation(AggregationBuilders.terms("brandAgg").field("brand").size(100));// 3.发出请求SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 4.解析结果Aggregations aggregations = response.getAggregations();// 4.1.根据聚合名称获取聚合结果Terms brandTerms = aggregations.get(aggName);// 4.2.获取bucketsList<? extends Terms.Bucket> buckets = brandTerms.getBuckets();// 4.3.遍历打印结果for (Terms.Bucket bucket : buckets) {// 4.4.获取keyString key = bucket.getKeyAsString();System.out.println(key);}
}运行可以看到我们成功查出了酒店数据

二.自动补全
当用户在搜索框输入字符时,我们应该提示出与该字符有关的搜索项,如图:
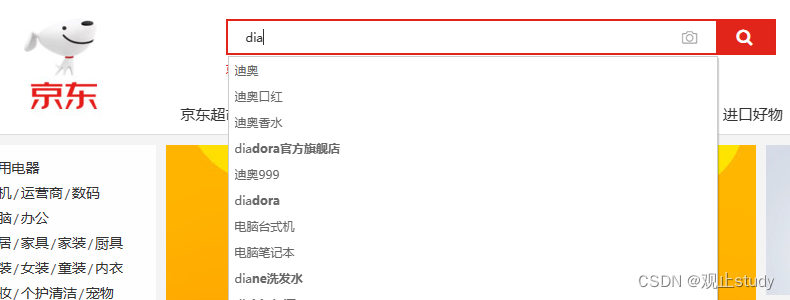
这种根据用户输入的字母,提示完整词条的功能,就是自动补全了。
(1) 拼音分词器
要实现根据字母做补全,就必须对文档按照拼音分词,这时就需要自己配置拼音分词功能,在GitHub上恰好有elasticsearch的拼音分词插件。
链接:https://pan.baidu.com/s/1eSlsQ6ypaDNkqXO75mC6IA
提取码:3yzw
资料中也提供了拼音分词器的安装包:
安装步骤:
- 连接服务器,切换到es绑定的插件数据卷中
cd /var/lib/docker/volumes/es-plugins/_data
2. 将压缩包上传至此目录并解压
unzip elasticsearch-analysis-pinyin-7.12.1.zip -d py
3. 重启elasticsearch
docker restart es
- 测试用法
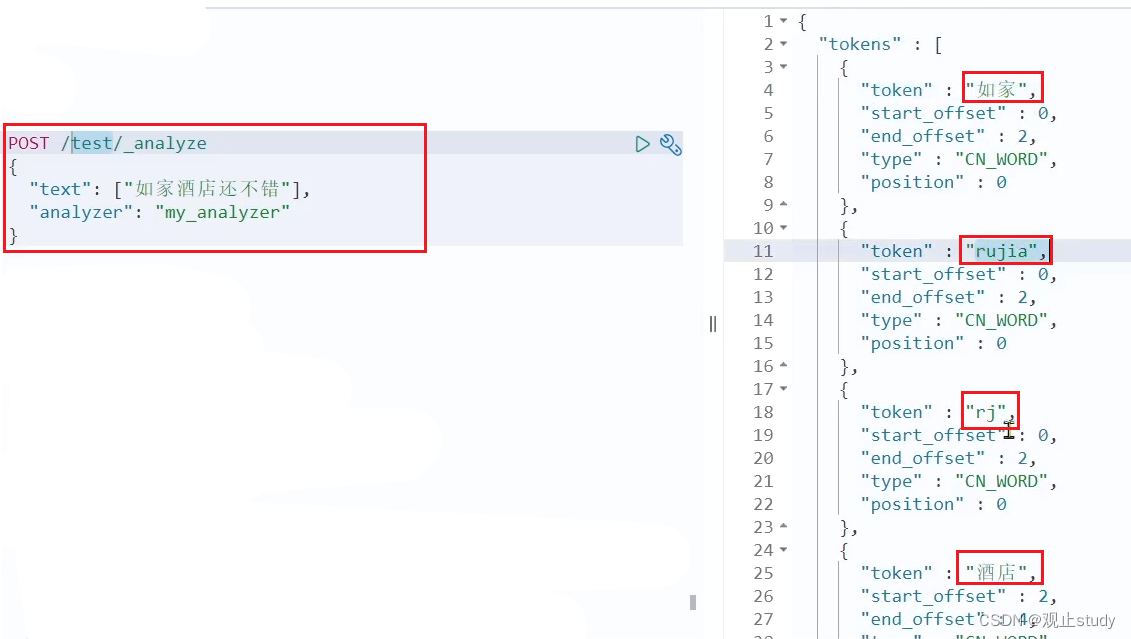
POST /_analyze
{"text": "如家酒店还不错","analyzer": "pinyin"
}
- 结果:

如上可以看到我们已经成功安装好了拼音分词器。但是它还存在一些问题,无法直接使用,接下来让我们一起解决吧。
(2) 自定义分词器
(2.1) 概述
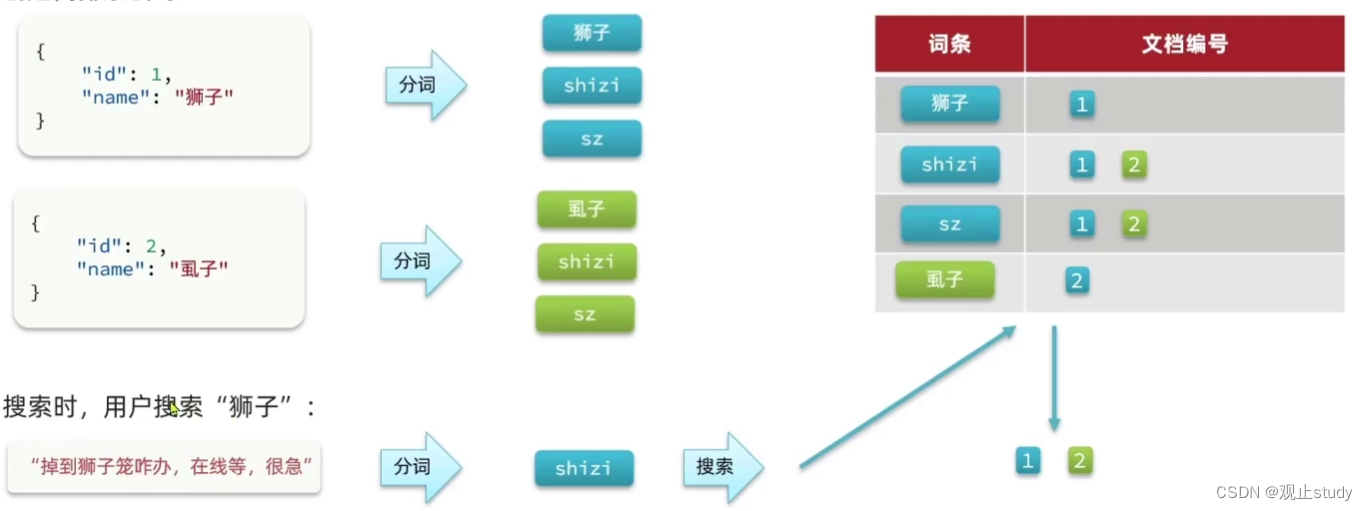
默认的拼音分词器会将每个汉字单独分为拼音,而我们所希望的是每个词条形成一组拼音,因此需要对拼音分词器做个性化定制,形成自定义分词器。
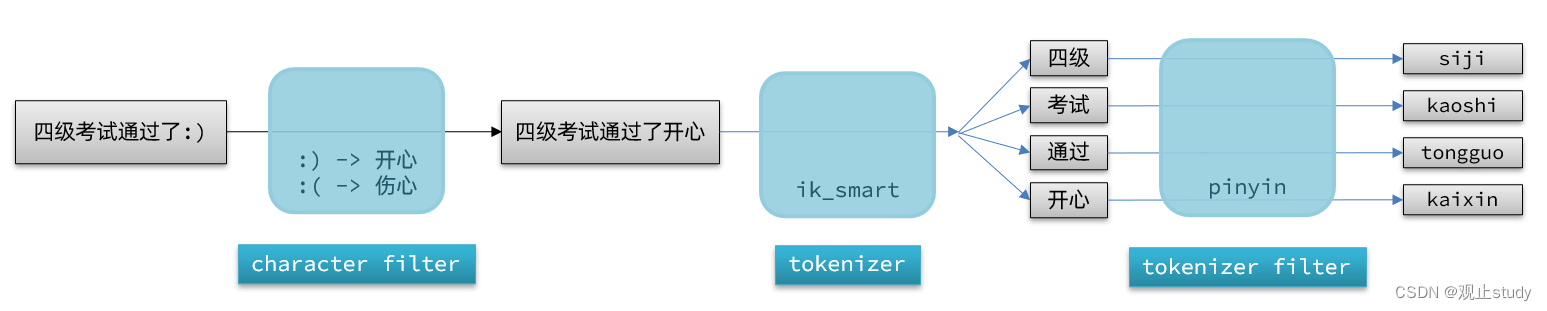
elasticsearch中分词器(analyzer)的组成包含三部分:
- character filters:在tokenizer之前对文本进行处理。例如删除字符、替换字符
- tokenizer:将文本按照一定的规则切割成词条(term)。例如keyword,就是不分词;还有ik_smart
- tokenizer filter:将tokenizer输出的词条做进一步处理。例如大小写转换、同义词处理、拼音处理等
文档分词时会依次由这三部分来处理文档:
(2.2) 使用
我们在可以在创建索引库时,通过settings来配置自定义的analyzer(分词器)。
声明自定义分词器的语法如下:
PUT /test // 创建索引库
{"settings": {"analysis": {"analyzer": { // 自定义分词器"my_analyzer": { // 自定义分词器名称"tokenizer": "ik_max_word", // 切割词条"filter": "py" // 自定义拼音处理方式}},"filter": { // 自定义tokenizer filter"py": { // 过滤器名称"type": "pinyin", // 过滤器类型,这里是pinyin"keep_full_pinyin": false,"keep_joined_full_pinyin": true,"keep_original": true,"limit_first_letter_length": 16,"remove_duplicated_term": true,"none_chinese_pinyin_tokenize": false}}}},"mappings": {"properties": {"name": { // 定义字段"type": "text", // 定义类型"analyzer": "my_analyzer", // 定义字段分词器"search_analyzer": "ik_smart" }}}
}
拼音分词器filter属性详细配置介绍可以看官方文档拼音分词插件。
测试:
(2.3) 补充
拼音分词器适合在创建倒排索引的时候使用,但不适合在搜索的时候使用,这是为了避免搜索时搜到到同音字。
改进使用:
PUT /test
{"settings": {"analysis": {"analyzer": { "my_analyzer": { "tokenizer": "ik_max_word", "filter": "py" }},"filter": { "py": {...}}}},"mappings": {"properties": {"name": { "type": "text", "analyzer": "my_analyzer", // 指定创建倒排索引分词器"search_analyzer": "ik_smart" // 指定搜索时分词器}}}
}
我们可以在配置中指定两个分词器,一个用于创建倒排索引,一个用于搜索。
(3) 自动补全查询
es提供了Completion Suggester查询来实现自动补全功能。这个查询会匹配以用户输入内容开头的词条并返回。为了提高补全查询的效率,对于文档中字段的类型有一些约束:
-
参与补全查询的字段必须是
completion类型。 -
字段的内容一般是用来补全的多个词条形成的数组。
比如,一个这样的索引库:
// 创建索引库
PUT test
{"mappings": {"properties": {"title":{"type": "completion"}}}
}
然后插入下面的数据:
// 示例数据
POST test/_doc
{"title": ["Sony", "WH-1000XM3"]
}
POST test/_doc
{"title": ["SK-II", "PITERA"]
}
POST test/_doc
{"title": ["Nintendo", "switch"]
}
查询的DSL语句如下:
// 自动补全查询
GET /test/_search
{"suggest": {"title_suggest": {"text": "s", // 查询时待补全关键字"completion": {"field": "title", // 补全查询的字段"skip_duplicates": true, // 跳过重复的"size": 10 // 获取前10条结果}}}
}
测试结果:
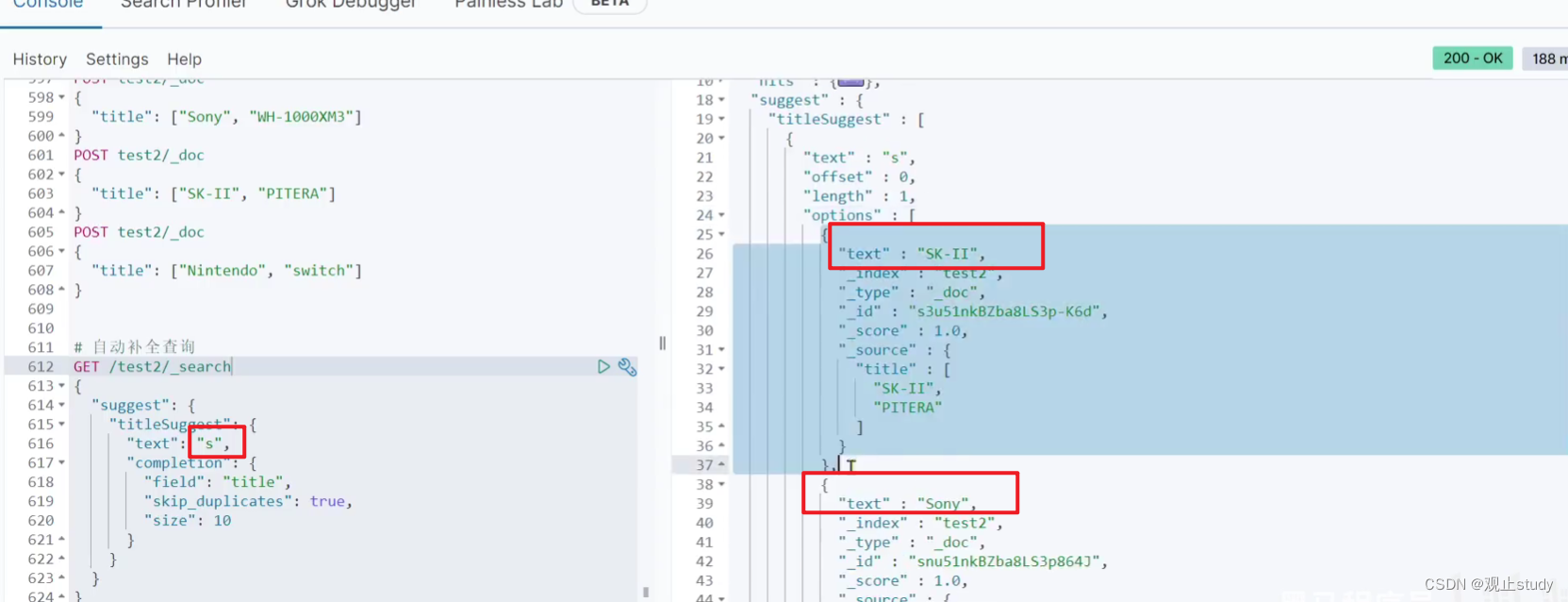
如上可以看到我们已经成功实现了自动补全功能,接下来让我们一起用Java代码来实现一下。
(4) RestAPI实现自动补全
(4.1) 基础语法
先让我们看看发送请求代码对比
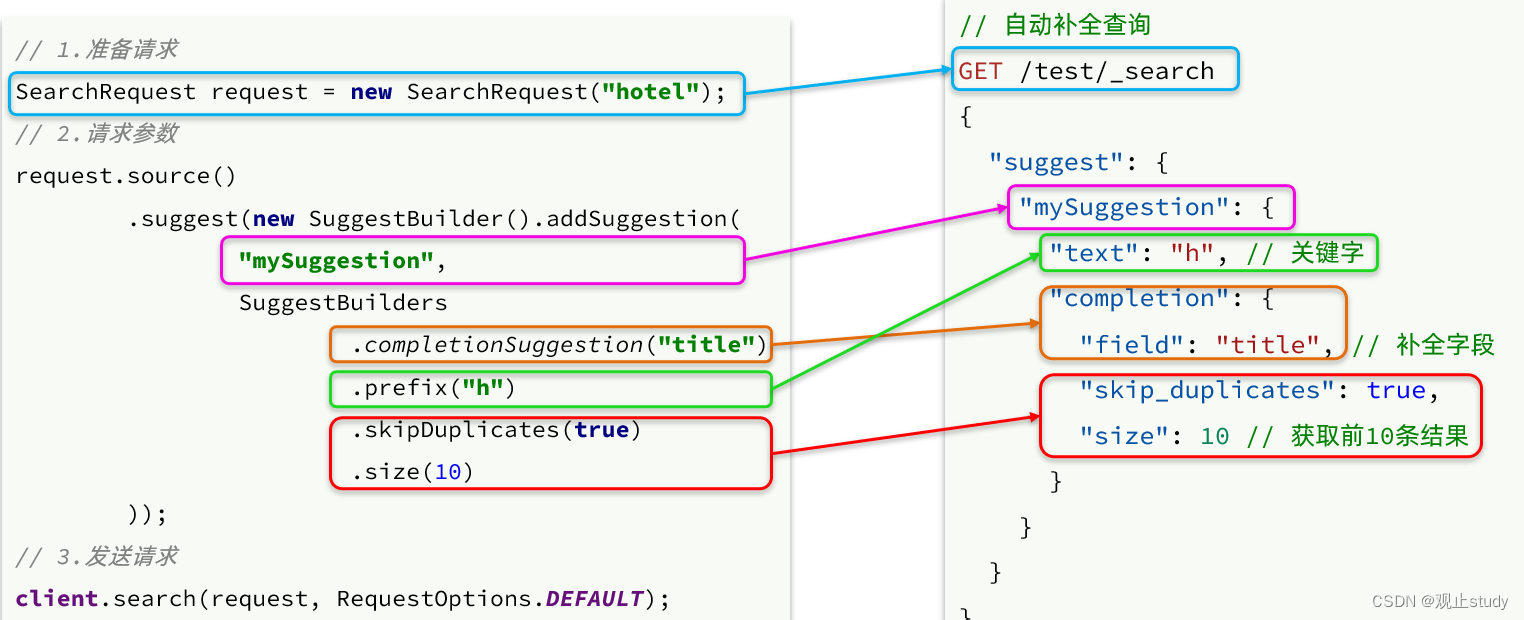
自动补全结果解析的代码如下:

(4.2) 使用示例
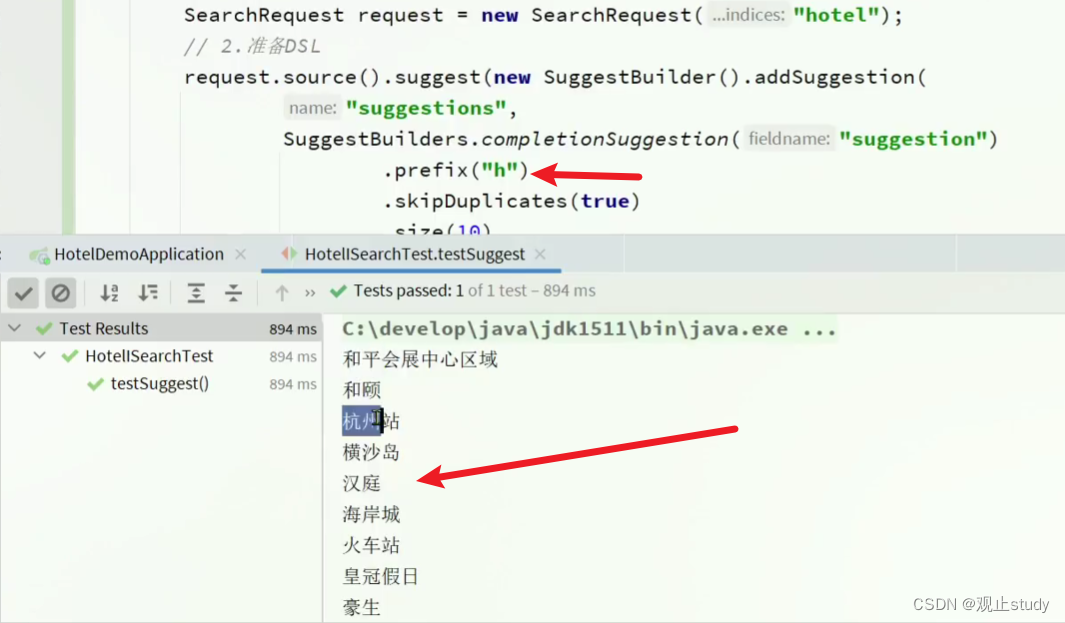
@Test
void testSuggester() {// 1.准备RequestSearchRequest request = new SearchRequest("hotel");// 2.准备DSLrequest.source().suggest(new SuggestBuilder().addSuggestion("suggestions",SuggestBuilders.completionSuggestion("suggestion").prefix("h").skipDuplicates(true).size(10)));// 3.发起请求SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 4.解析结果Suggest suggest = response.getSuggest();// 4.1.根据补全查询名称,获取补全结果CompletionSuggestion suggestions = suggest.getSuggestion("suggestions");// 4.2.获取optionsList<CompletionSuggestion.Entry.Option> options = suggestions.getOptions();// 4.3.遍历打印for (CompletionSuggestion.Entry.Option option : options) {String text = option.getText().toString();System.out.println(text)}
}
运行可以看到我们已经成功获取到补全结果
三.数据同步方案
本处不涉及代码,方案实现可以看项目实战篇
(1) 引入
es中的数据来自于mysql数据库,因此mysql数据发生改变时,es也必须跟着改变,这个就是elasticsearch与mysql之间的数据同步。

(2) 思路分析
常见的数据同步方案有三种:
- 同步调用
- 异步通知
- 监听binlog
(2.1 ) 同步调用
方案一:同步调用
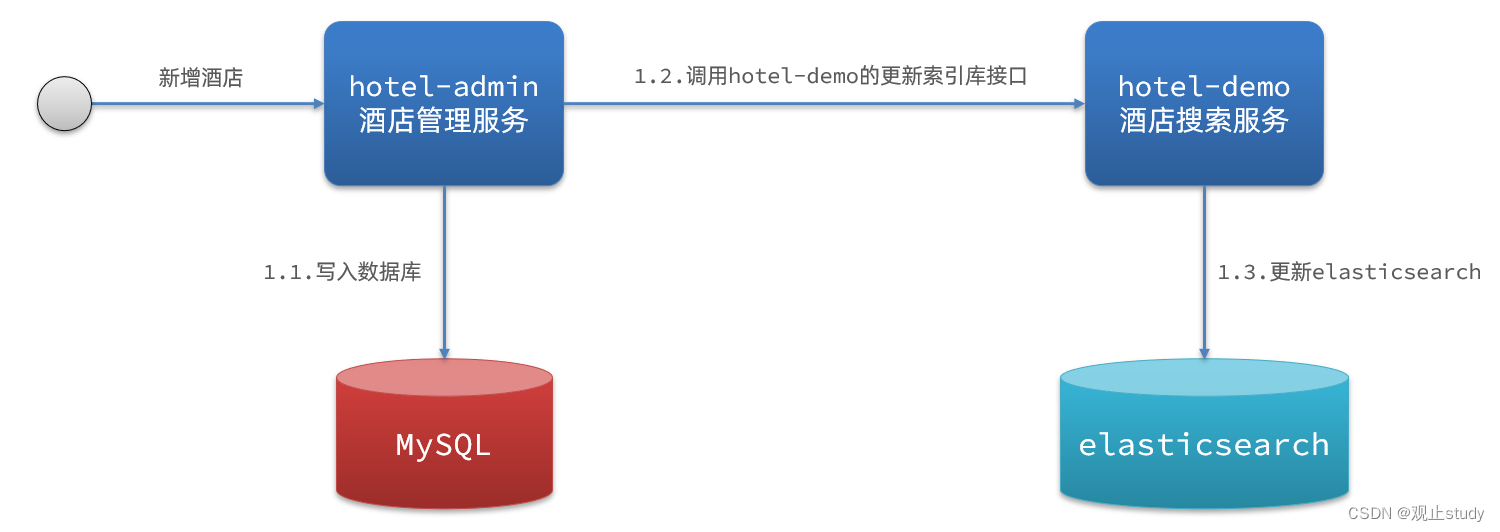
基本步骤如下:
- hotel-demo服务对外提供接口,用来修改elasticsearch中的数据
- 酒店管理服务在完成数据库操作后,直接调用hotel-demo服务提供的修改接口,
(2.2) 异步通知
方案二:异步通知
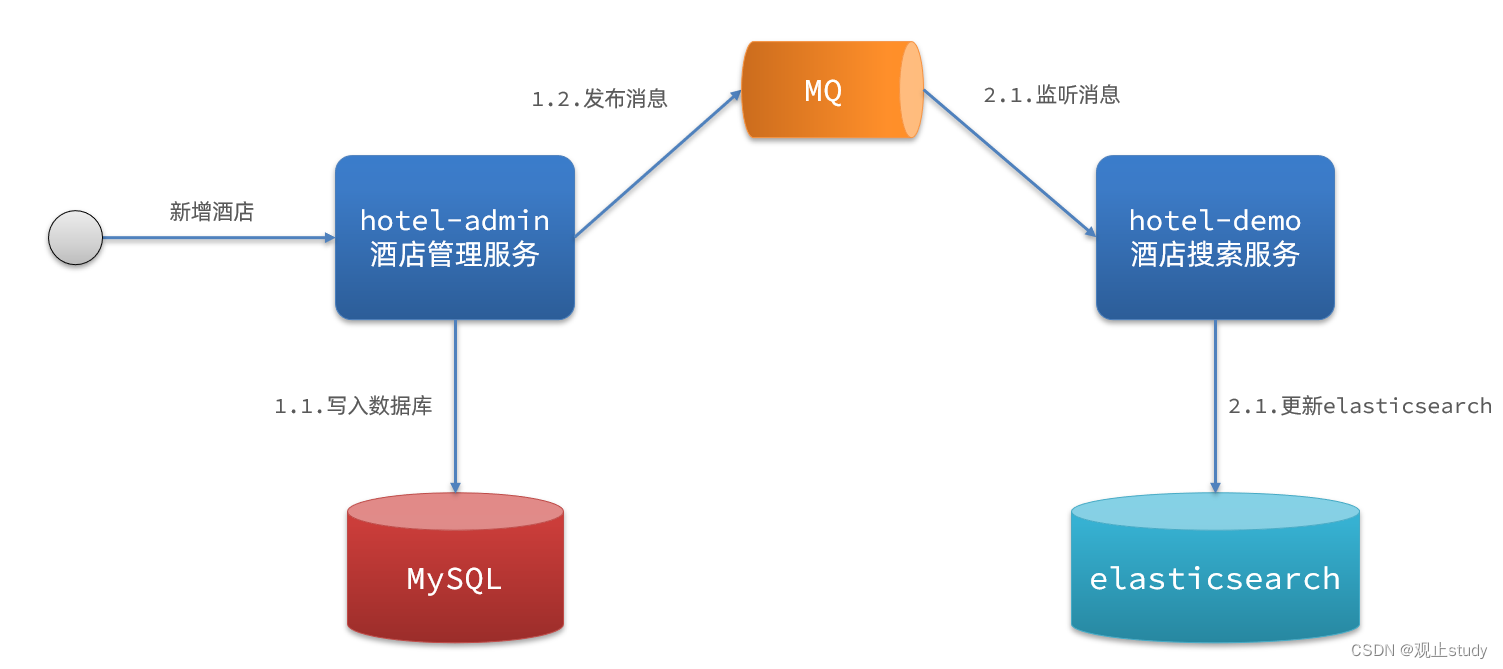
流程如下:
- hotel-admin服务对mysql数据库数据完成增、删、改后,发送MQ消息
- hotel-demo服务监听MQ,接收到消息后完成elasticsearch数据修改
(2.3) 监听binlog
方案三:监听binlog
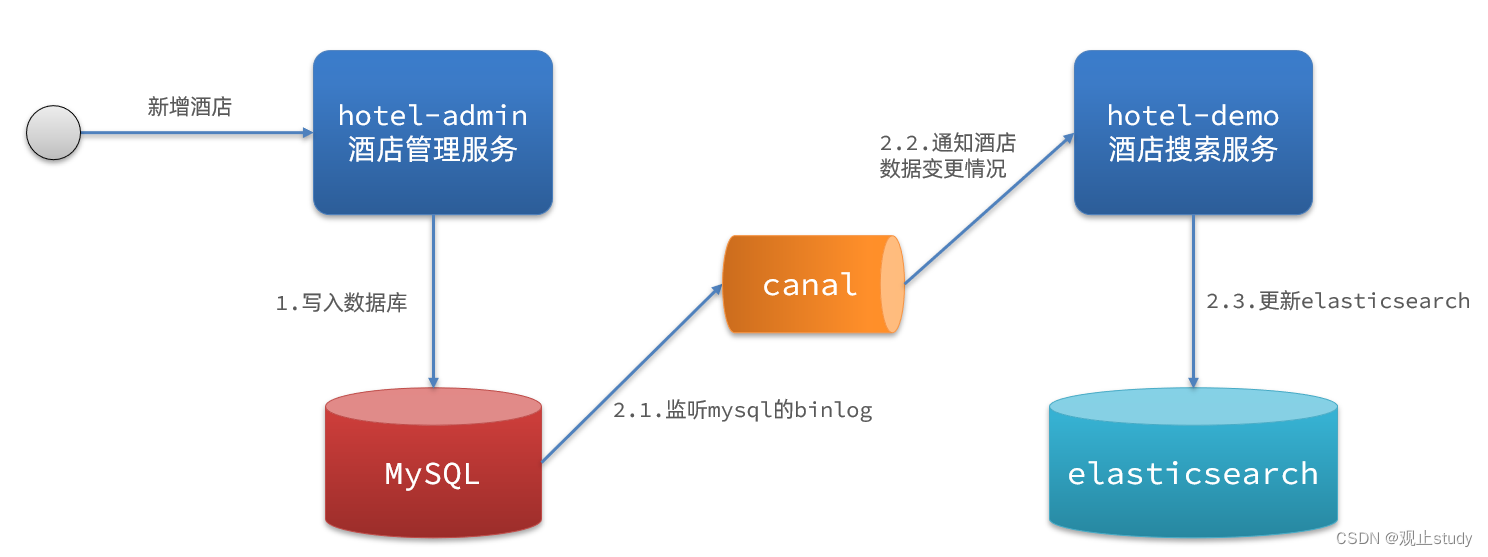
流程如下:
- 给mysql开启binlog功能
- mysql完成增、删、改操作都会记录在binlog中
- hotel-demo基于canal监听binlog变化,实时更新elasticsearch中的内容
(2.4) 优缺点对比
方式一:同步调用
- 优点:实现简单,粗暴
- 缺点:业务耦合度高
方式二:异步通知
- 优点:低耦合,实现难度一般
- 缺点:依赖mq的可靠性
方式三:监听binlog
- 优点:完全解除服务间耦合
- 缺点:开启binlog增加数据库负担、实现复杂度高
相关文章:
【微服务】Elasticsearch数据聚合自动补全数据同步(四)
🚗Es学习第四站~ 🚩Es学习起始站:【微服务】Elasticsearch概述&环境搭建(一) 🚩本文已收录至专栏:微服务探索之旅 👍希望您能有所收获 在第二站的学习中,我们已经导入了大量数据到es中&…...
java面试题(十七)spring
2.1 请你说说Spring的核心是什么 参考答案 Spring框架包含众多模块,如Core、Testing、Data Access、Web Servlet等,其中Core是整个Spring框架的核心模块。Core模块提供了IoC容器、AOP功能、数据绑定、类型转换等一系列的基础功能,而这些功能…...

你知道 BI 是什么吗?关于 BI 系统的概述
BI 作为信息化建设中的关键一环,在企业中通常起到承上启下的作用,下能连接打通企业业务系统数据库,将各部门数据分类分级统一储存到数据仓库,简化存储取数流程,减少人力、时间成本;上能提供数据可视化报表…...
git:详解git rebase命令
背景 今天无意中打开 git 官网,发现 git 命令还是很多的,然而我们常用的就那几个,今天来学习一个也不怎么常用的命令 rebase 官网链接 都说学一个东西最好的方式就是读他的 官方文档,这里我读了一遍,把一些核心的地…...

第四章——随机变量的数字特征
文章目录1、数字特征的定义2、数学期望(均值)2.1、数学期望的定义及性质2.1.1、定义2.1.2、性质2.2、数学期望相关例题2.3、Yg(X)的数学期望2.4、Zg(X,Y)的数学期望2.5、随机变量函数的数学期望例题3、方差3.1、方差的定义与性质3.2、相关例题3.3、切比雪…...

vue2源码阅读理解-响应式数据原理
首先明确,vue2是如何实现响应式的? 通过object.defineProperty观察者模式实现,在创建vue实例的过程中,也就是介于beforecomputed~computed的过程中,会执行如下函数initState export function initState (vm: Componen…...
服务调用分布式session
目录一、nginx动静分离二、服务调用1、创建配置zmall-cart购物车模块2、创建配置zmall-order订单模块3、服务调用三、spring session实战1、什么是Spring Session2、为什么要使用Spring Session3、错误案例展示4、配置spring-session四、二级域名问题五、用户登录一、nginx动静…...

Maven知识点-插件-maven-surefire-plugin简介
Maven本身并不是一个单元测试框架,Java 世界中主流的单元测试框架为JUnit 和TestNG。 Maven 所做的只是在构建执行到特定生命周期阶段的时候,通过插件来执行JUnit或者TestNG的测试用例。 这一插件就是maven-surefire-plugin,可以称之为测试…...

如何借力Alluxio推动大数据产品性能提升与成本优化?
内容简介 随着数字化不断发展,各行各业数据呈现海量增长的趋势。存算分离将存储系统和计算框架拆分为独立的模块,Alluxio作为如今主流云数据编排软件之一,为计算型应用(如 Apache Spark、Presto)和存储系统࿰…...
(脚本包含,父子脚本))
linux shell脚本被包含是什么意思?.命令和source命令(在脚本中运行脚本,脚本中调用脚本)(脚本包含,父子脚本)
在 shell 编程中,当一个 shell 脚本被另一个 shell 脚本包含,即用 . 或 source 命令包含,则被包含的脚本在当前 shell 进程内执行,并且可以访问当前 shell 进程的环境变量和函数。 此时,$0 代表的是主脚本的名称&#…...

MySQL进阶篇之锁(lock)
05、锁 5.1、概述 1、介绍 锁是计算机协调多个进程或线程并发访问某一资源的机制。在数据库中,除传统的计算资源(CPU、RAM、I/O)的争用以外,数据也是一种供许多用户共享的资源。如何保证数据并发访问的一致性、有效性是所有数据…...

TMDSEVM6657LS评估板恢复出厂默认状态
TMDSEVM6657LS评估板恢复出厂默认状态 前言 TMDSEVM6657LS评估板特别适用于DSP开发的初学者,但有时候拿到手的开发板几经流转,被别人修改过,也可能自己烧录过程出错,导致开发板的状态未知等原因,需要恢复到出厂默认状…...

聊一聊,我对DDD的关键理解
作者:闵大为 阿里业务平台解决方案团队 当我们在学习DDD的过程中,感觉学而不得的时候,可能会问:我们还要学么?这的确引人深思。本文基于工作经验,尝试谈谈对DDD的一些理解。 一、序 《阿甘正传》中…...
—— 认识复杂度和简单排序算法)
算法笔记(一)—— 认识复杂度和简单排序算法
时间复杂度是在一个算法流程中,常数操作的数量级指标。(最差情况下的算法表现) 比较两个算法的优劣,在足够的空间下,看时间复杂度指标,若相同,需要在大数据运行下来判断两个算法的“常数项指标…...
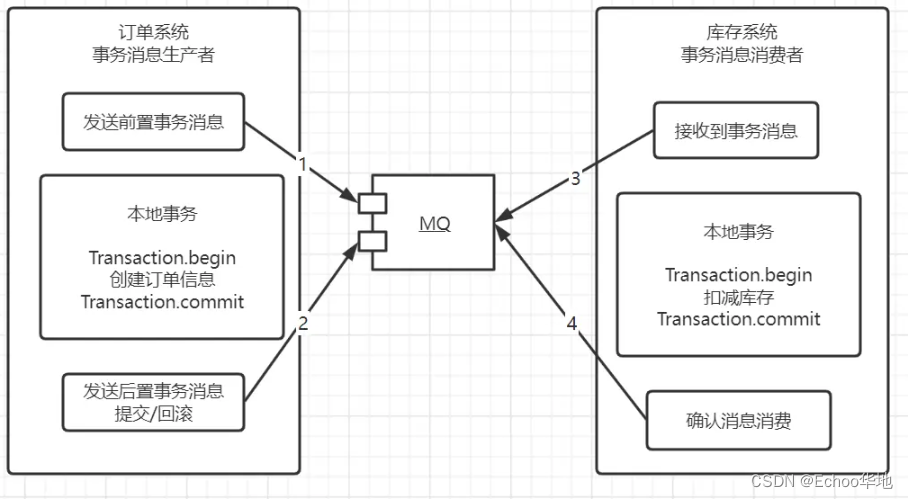
MQ消息中间件常见题及解决办法
目录儿常见MQRocketMQ2、RocketMQ测试可用MQ常见问题1、幂等性问题2、如何保证消息不丢失3、消息积压问题4、事务消息设计分析常见MQ RocketMQ RocketMQ又四部分组成 NameServer 同步Broker服务信息,给消费者和生产者提供可用Broker的服务信息。Broker 消息存储业…...
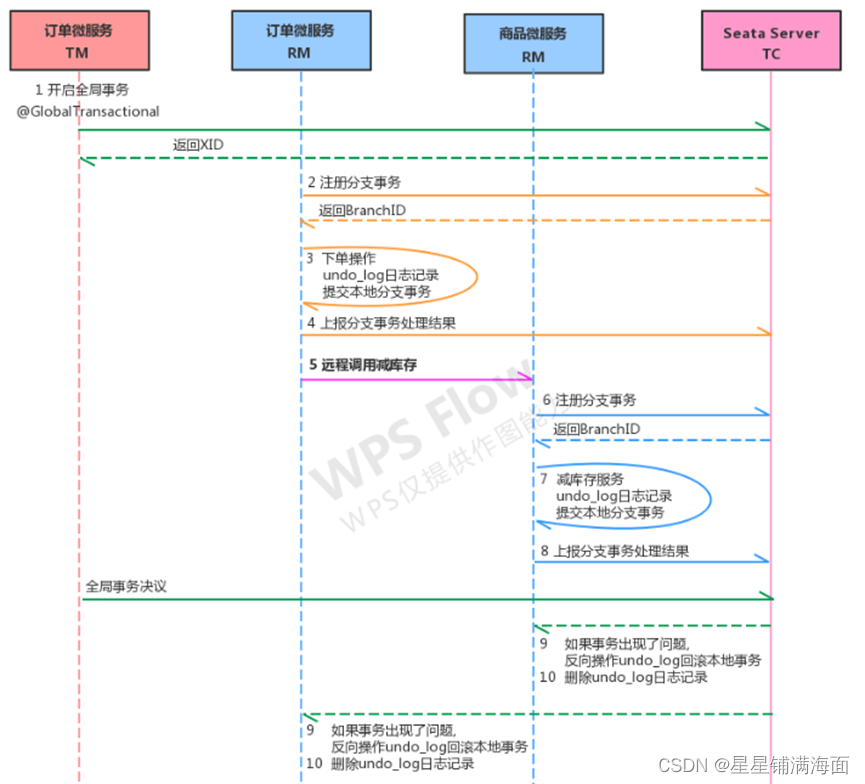
网关服务限流熔断降级分布式事务
目录一、网关服务限流熔断降级二、Seata--分布式事务1、分布式事务基础①事务②本地事物③分布式事务④分布式事务的场景2、分布式事务解决方案①全局事务②最大努力通知③TCC事务3、Seata介绍4、Seata实现分布式事务控制①案例基本代码(异常模拟)②启动…...
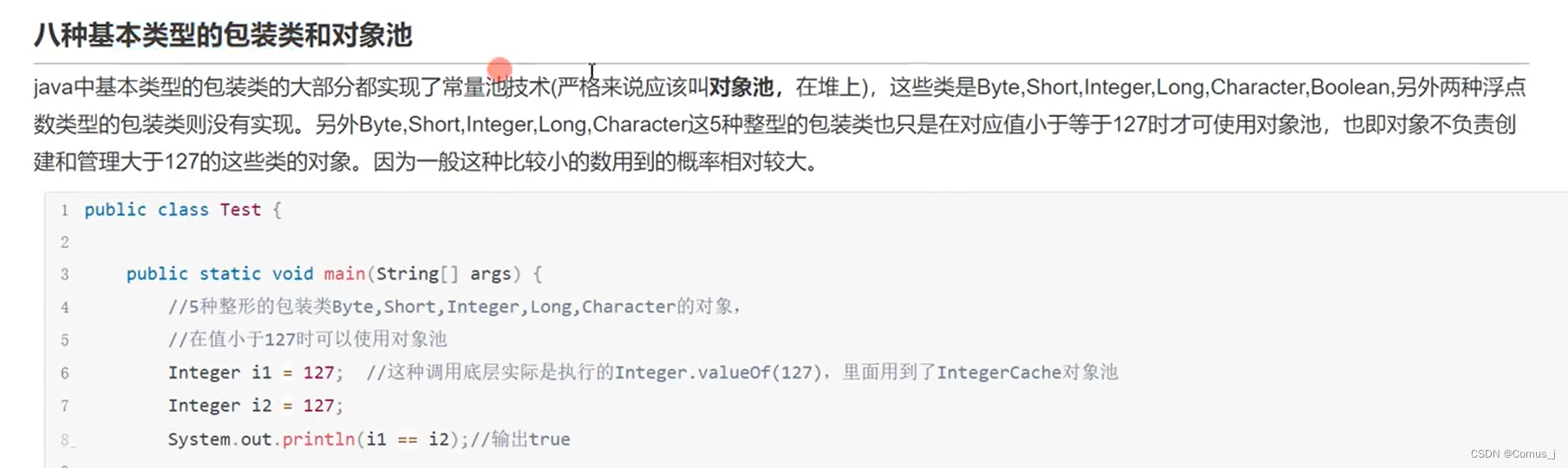
JVM——7JVM调优实战及常量池详解
Arthas工具的使用 阿里巴巴开源的java诊断工具 下载插件 上传至linux环境 在linux跑起来的java项目,可以用Arthas进行查看 项目上线前的时候没问题,上线了就出问题 ,用来查看线上代码 jad 项目名 :反编译线上正在运行的代码 用…...

子串分值【第十一届】【省赛】【A组】
问题描述 对于一个字符串 s,我们定义 s 的分值 f(s) 为 s 中恰好出现一次的字符个数。例如 f("aba")1,f("abc")3, f("aaa")0。 现在给定一个字符串 s[0..n−1](长度为 n),请你计算对于…...
SpringCloud 中 Config、Bus、Stream、Sleuth
文章目录🚏 第十三章 分布式配置中心🚬 一、Config 概述🚬 二、Config 快速入门🚭 config-server:🛹 1、使用gitee创建远程仓库,上传配置文件🛹 2、导入 config-server 依赖…...

Quantum 构建工具使用新的 TTP 投递 Agent Tesla
Zscaler 的研究人员发现暗网上正在出售名为 Quantum Builder 的构建工具,该工具可以投递 .NET 远控木马 Agent Tesla。与过去的攻击行动相比,本次攻击转向使用 LNK 文件。 Quantum Builder 能够创建恶意文件,如 LNK、HTA 与 PowerShell&…...

Casbin Talent 2026:高校开发者开源进阶与工业级项目实战指南
1. 项目概述:Casbin Talent 2026,一个为高校开发者量身定制的开源进阶通道如果你是一名在校大学生,对开源世界充满好奇,渴望在真实的工业级项目中打磨技术,但又觉得像Google Summer of Code(GSoC࿰…...

基于 HM-TM32 红外摄像头:棉花燃烧+起火自动录制 30 秒视频
在棉花仓储、纺织原料监测等实际场景中,利用 HM-TM32 微型红外测温机芯实现非接触式火情监测具备极高的实用价值,本文基于 Windows 笔记本环境,实现红外摄像头实时画面显示,并在检测到棉花起火或高温异常时自动录制 30 秒视频留存…...

Arm CoreLink GFC-200 Flash控制器架构与优化实践
1. Arm CoreLink GFC-200 Flash控制器架构解析在嵌入式系统设计中,非易失性存储管理是核心挑战之一。作为Arm CoreLink系列的重要成员,GFC-200通用Flash控制器通过创新的总线架构和分区管理机制,为SoC设计提供了高效的Flash存储解决方案。这款…...

别再手动调阈值了!OpenCV实战:用Otsu和自适应阈值搞定光照不均的图片分割
智能图像分割实战:Otsu与自适应阈值技术解决光照不均难题 在工业质检、医疗影像分析、自动驾驶等场景中,图像分割的准确性直接影响最终结果。但现实世界的光照条件往往复杂多变——同一张图片可能同时存在过曝和欠曝区域,传统全局阈值方法在…...

别再只玩开发板了!用吃灰的STM32核心板DIY一个专属游戏手柄,实战HID协议
从零构建STM32游戏手柄:深入解析HID协议与实战开发 你是否曾盯着抽屉里积灰的STM32核心板思考它能做什么?与其重复点亮LED的基础实验,不如挑战一个既实用又有趣的项目——打造专属游戏手柄。这不仅能让硬件资源重获新生,更是深入理…...

Cursor-Learner:基于编辑器历史数据,自动生成个性化AI编程助手Prompt
1. 项目概述:一个帮你“诊断”编程习惯的智能助手 如果你和我一样,每天都在和 Cursor 或 WindSurf 这类 AI 驱动的代码编辑器打交道,那你肯定也遇到过这样的困惑:为什么有时候 AI 助手能精准地理解你的意图,写出漂亮的…...

New-API数据导出功能:轻松管理AI模型使用记录与账单数据
New-API数据导出功能:轻松管理AI模型使用记录与账单数据 【免费下载链接】new-api A unified AI model hub for aggregation & distribution. It supports cross-converting various LLMs into OpenAI-compatible, Claude-compatible, or Gemini-compatible for…...

芯片测试中的扫描压缩技术解析与应用
1. 扫描压缩技术概述在当今纳米级芯片设计中,扫描压缩技术已成为降低测试成本、保证测试质量的必备手段。随着芯片复杂度呈指数级增长,传统扫描测试方法面临两大核心挑战:测试数据量(Test Data Volume)爆炸式增长导致测…...

LangGraph大模型脚手架实战:揭秘6种爆款智能体设计模式,玩转生产级Agent开发!
最近Herness大火,我就在反思,我们在日常进行智能体开发的过程中,是否也在做类似的事,我们用过claude code sdk、codex sdk、copilot cli等通用agent做封装,也用过dify或者coze搭工作流,也用过langchain做过…...

Gemini实时字幕在Google Meet中延迟超800ms?揭秘谷歌内部SRE监控数据与3步毫秒级调优法
更多请点击: https://intelliparadigm.com 第一章:Gemini实时字幕在Google Meet中延迟超800ms?揭秘谷歌内部SRE监控数据与3步毫秒级调优法 谷歌内部SRE团队近期公开的一组匿名化监控数据显示:在高并发(>500人&…...