Tensorflow2基础代码实战系列之双层RNN文本分类任务
深度学习框架Tensorflow2系列
注:大家觉得博客好的话,别忘了点赞收藏呀,本人每周都会更新关于人工智能和大数据相关的内容,内容多为原创,Python Java Scala SQL 代码,CV NLP 推荐系统等,Spark Flink Kafka Hbase Hive Flume等等~写的都是纯干货,各种顶会的论文解读,一起进步。
这个系列主要和大家分享深度学习框架Tensorflow2的各种api,从基础开始。
#博学谷IT学习技术支持#
文章目录
- 深度学习框架Tensorflow2系列
- 前言
- 一、文本分类任务实战
- 二、数据集介绍
- 三、RNN模型所需数据解读
- 四、实战代码
- 1.数据预处理
- 2.构建初始化embedding层
- 3.构建训练数据
- 4.自定义双层RNN网络模型
- 5.设置参数和训练策略
- 6.模型训练
- 总结
前言
通过代码案例实战,学习Tensorflow2的各种api。
一、文本分类任务实战
任务介绍:
数据集构建:影评数据集进行情感分析(分类任务)
词向量模型:加载训练好的词向量或者自己训练都可以
序列网络模型:训练RNN模型进行识别
二、数据集介绍
训练和测试集都是比较简单的电影评价数据集,标签为0和1的二分类,表示对电影的喜欢和不喜欢

三、RNN模型所需数据解读
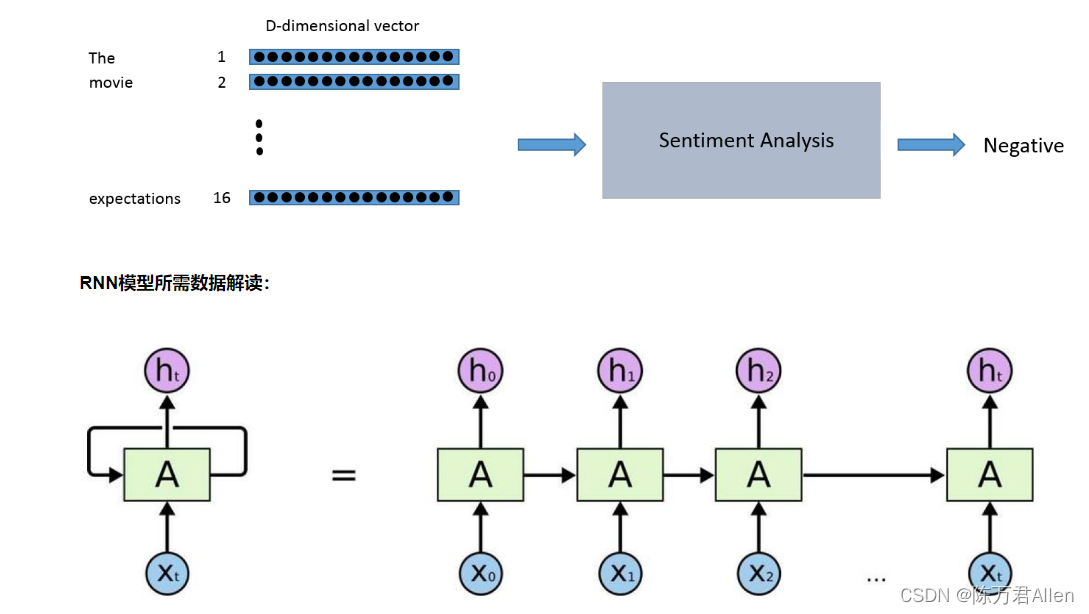
RNN是一个比较基础的序列化模型,其中输入的数据为[batch_size,max_len,feature_dim]
四、实战代码
1.数据预处理
import os
import warnings
warnings.filterwarnings("ignore")
import tensorflow as tf
import numpy as np
import pprint
import logging
import time
from collections import Counter
from pathlib import Path
from tqdm import tqdm# 构建语料表,基于词频来进行统计
counter = Counter()
with open('./data/train.txt',encoding='utf-8') as f:for line in f:line = line.rstrip()label, words = line.split('\t')words = words.split(' ')counter.update(words)words = ['<pad>'] + [w for w, freq in counter.most_common() if freq >= 10]
print('Vocab Size:', len(words))Path('./vocab').mkdir(exist_ok=True)with open('./vocab/word.txt', 'w',encoding='utf-8') as f:for w in words:f.write(w+'\n')# 得到word2id映射表
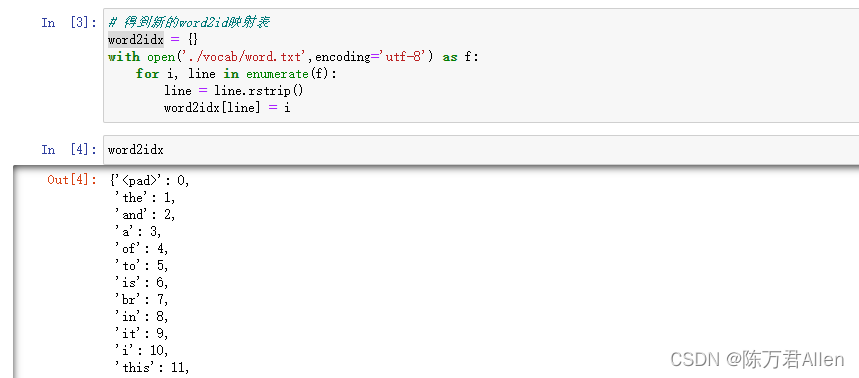
word2idx = {}
with open('./vocab/word.txt',encoding='utf-8') as f:for i, line in enumerate(f):line = line.rstrip()word2idx[line] = i
得到的结果如下
2.构建初始化embedding层
# 做了一个大表,里面有20598个不同的词,【20599*50】
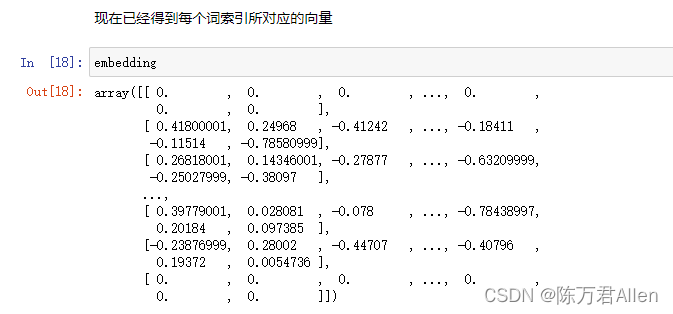
embedding = np.zeros((len(word2idx)+1, 50)) # + 1 表示如果不在语料表中,就都是unknowwith open('./data/glove.6B.50d.txt',encoding='utf-8') as f: #下载好的count = 0for i, line in enumerate(f):if i % 100000 == 0:print('- At line {}'.format(i)) #打印处理了多少数据line = line.rstrip()sp = line.split(' ')word, vec = sp[0], sp[1:]if word in word2idx:count += 1embedding[word2idx[word]] = np.asarray(vec, dtype='float32') #将词转换成对应的向量# 保存结果
print("[%d / %d] words have found pre-trained values"%(count, len(word2idx)))
np.save('./vocab/word.npy', embedding)
print('Saved ./vocab/word.npy')
得到的结果如下:word.txt中的每个单词转换成对应的向量
3.构建训练数据
def data_generator(f_path, params):with open(f_path,encoding='utf-8') as f:print('Reading', f_path)for line in f:line = line.rstrip()label, text = line.split('\t')text = text.split(' ')x = [params['word2idx'].get(w, len(word2idx)) for w in text]#得到当前词所对应的IDif len(x) >= params['max_len']:#截断操作x = x[:params['max_len']]else:x += [0] * (params['max_len'] - len(x))#补齐操作y = int(label)yield x, ydef dataset(is_training, params):_shapes = ([params['max_len']], ())_types = (tf.int32, tf.int32)if is_training:ds = tf.data.Dataset.from_generator(lambda: data_generator(params['train_path'], params),output_shapes = _shapes,output_types = _types,)ds = ds.shuffle(params['num_samples'])ds = ds.batch(params['batch_size'])ds = ds.prefetch(tf.data.experimental.AUTOTUNE)#设置缓存序列,目的加速else:ds = tf.data.Dataset.from_generator(lambda: data_generator(params['test_path'], params),output_shapes = _shapes,output_types = _types,)ds = ds.batch(params['batch_size'])ds = ds.prefetch(tf.data.experimental.AUTOTUNE)return ds
4.自定义双层RNN网络模型
class Model(tf.keras.Model):def __init__(self, params):super().__init__()self.embedding = tf.Variable(np.load('./vocab/word.npy'),dtype=tf.float32,name='pretrained_embedding',trainable=False,)self.drop1 = tf.keras.layers.Dropout(params['dropout_rate'])self.drop2 = tf.keras.layers.Dropout(params['dropout_rate'])self.drop3 = tf.keras.layers.Dropout(params['dropout_rate'])self.rnn1 = tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(params['rnn_units'], return_sequences=True))self.rnn2 = tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(params['rnn_units'], return_sequences=True))self.rnn3 = tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(params['rnn_units'], return_sequences=False))self.drop_fc = tf.keras.layers.Dropout(params['dropout_rate'])self.fc = tf.keras.layers.Dense(2*params['rnn_units'], tf.nn.elu)self.out_linear = tf.keras.layers.Dense(2)def call(self, inputs, training=False):if inputs.dtype != tf.int32:inputs = tf.cast(inputs, tf.int32)batch_sz = tf.shape(inputs)[0]rnn_units = 2*params['rnn_units']x = tf.nn.embedding_lookup(self.embedding, inputs)x = self.drop1(x, training=training)x = self.rnn1(x)x = self.drop2(x, training=training)x = self.rnn2(x)x = self.drop3(x, training=training)x = self.rnn3(x)x = self.drop_fc(x, training=training)x = self.fc(x)x = self.out_linear(x)return x
5.设置参数和训练策略
params = {'vocab_path': './vocab/word.txt','train_path': './data/train.txt','test_path': './data/test.txt','num_samples': 25000,'num_labels': 2,'batch_size': 32,'max_len': 1000,'rnn_units': 200,'dropout_rate': 0.2,'clip_norm': 10.,'num_patience': 3,'lr': 3e-4,
}
def is_descending(history: list):history = history[-(params['num_patience']+1):]for i in range(1, len(history)):if history[i-1] <= history[i]:return Falsereturn True
word2idx = {}
with open(params['vocab_path'],encoding='utf-8') as f:for i, line in enumerate(f):line = line.rstrip()word2idx[line] = i
params['word2idx'] = word2idx
params['vocab_size'] = len(word2idx) + 1model = Model(params)
model.build(input_shape=(None, None))#设置输入的大小,或者fit时候也能自动找到decay_lr = tf.optimizers.schedules.ExponentialDecay(params['lr'], 1000, 0.95)#相当于加了一个指数衰减函数
optim = tf.optimizers.Adam(params['lr'])
global_step = 0history_acc = []
best_acc = .0t0 = time.time()
logger = logging.getLogger('tensorflow')
logger.setLevel(logging.INFO)
6.模型训练
while True:# 训练模型for texts, labels in dataset(is_training=True, params=params):with tf.GradientTape() as tape:#梯度带,记录所有在上下文中的操作,并且通过调用.gradient()获得任何上下文中计算得出的张量的梯度logits = model(texts, training=True)loss = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=labels, logits=logits)loss = tf.reduce_mean(loss)optim.lr.assign(decay_lr(global_step))grads = tape.gradient(loss, model.trainable_variables)grads, _ = tf.clip_by_global_norm(grads, params['clip_norm']) #将梯度限制一下,有的时候回更新太猛,防止过拟合optim.apply_gradients(zip(grads, model.trainable_variables))#更新梯度if global_step % 50 == 0:logger.info("Step {} | Loss: {:.4f} | Spent: {:.1f} secs | LR: {:.6f}".format(global_step, loss.numpy().item(), time.time()-t0, optim.lr.numpy().item()))t0 = time.time()global_step += 1# 验证集效果m = tf.keras.metrics.Accuracy()for texts, labels in dataset(is_training=False, params=params):logits = model(texts, training=False)y_pred = tf.argmax(logits, axis=-1)m.update_state(y_true=labels, y_pred=y_pred)acc = m.result().numpy()logger.info("Evaluation: Testing Accuracy: {:.3f}".format(acc))history_acc.append(acc)if acc > best_acc:best_acc = acclogger.info("Best Accuracy: {:.3f}".format(best_acc))if len(history_acc) > params['num_patience'] and is_descending(history_acc):logger.info("Testing Accuracy not improved over {} epochs, Early Stop".format(params['num_patience']))break
总结
通过RNN文本分类任务代码案例实战,学习Tensorflow2的各种api。
相关文章:
Tensorflow2基础代码实战系列之双层RNN文本分类任务
深度学习框架Tensorflow2系列 注:大家觉得博客好的话,别忘了点赞收藏呀,本人每周都会更新关于人工智能和大数据相关的内容,内容多为原创,Python Java Scala SQL 代码,CV NLP 推荐系统等,Spark …...

Python爬虫-快手photoId
前言 本文是该专栏的第49篇,后面会持续分享python爬虫干货知识,记得关注。 笔者在本专栏的上一篇,有详细介绍平台视频播放量的爬取方法。与该平台相关联的文章,笔者已整理在下方,感兴趣的同学可查看翻阅。 1. Python如何解决“快手滑块验证码”(4) 2. 快手pcursor 3. …...
软件测试人员如何为项目的质量保障兜底?看完你就明白了...
上线前层层保障 01文档管理 关键词:需求文档、设计文档、测试文档 1.需求和设计产出方为产品、开发,测试需要做好流程监督,这里重点说下测试文档。 2.测试文档,从业务领域来说,一般有测试计划、测试用例、业务总结文…...
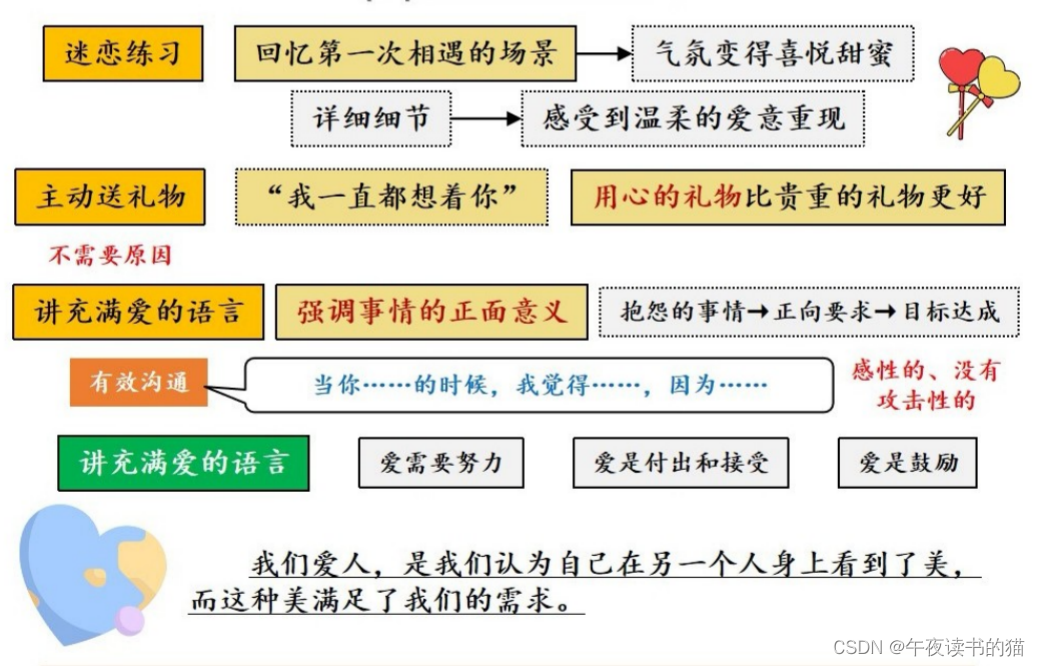
《幸福关系的7段旅程》
关于作者 本书作者安德鲁∙马歇尔,英国顶尖婚姻咨询机构RELATE的资深专家,拥有 30年丰富的咨询经验,并为《泰晤士报》《观察家》和《星期日快报》撰写专栏文章。已出版19部作品,并被翻译成20种语言。 关于本书 《幸福关系的7段…...

使用Python中PDB模块中的命令来调试Python代码的教程
这篇文章主要介绍了使用Python中PDB模块中的命令来调试Python代码的教程,包括设置断点来修改代码等、对于Python团队项目工作有一定帮助,需要的朋友可以参考下 你有多少次陷入不得不更改别人代码的境地?如果你是一个开发团队的一员,那么你遇…...

Codeforces Round 764 (Div. 3)
比赛链接 Codeforces Round 764 A. Plus One on the SubsetB. Make APC. Division by Two and PermutationD. Palindromes ColoringE. Masha-forgetful A. Plus One on the Subset Example input 3 6 3 4 2 4 1 2 3 1000 1002 998 2 12 11output 3 4 1题意: 你可…...
四月,收割12家offer,面试也太容易了吧....
前言 下面是我根据工作这几年来的面试经验,加上之前收集的资料,整理出来350道软件测试工程师 常考的面试题。字节跳动、阿里、腾讯、百度、快手、美团等大厂常考的面试题,在文章里面都有 提到。 虽然这篇文章很长,但是绝对值得你…...

Xubuntu22.04之自动调节亮度护眼redshift(一百七十四)
简介: CSDN博客专家,专注Android/Linux系统,分享多mic语音方案、音视频、编解码等技术,与大家一起成长! 优质专栏:Audio工程师进阶系列【原创干货持续更新中……】🚀 人生格言: 人生…...
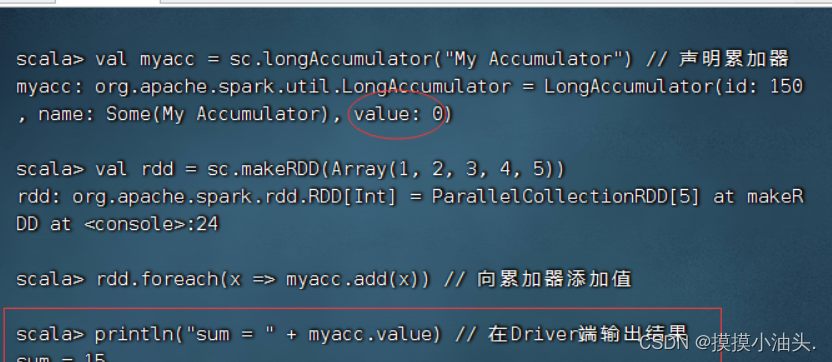
Spark基础学习笔记----RDD检查点与共享变量
零、本讲学习目标 了解RDD容错机制理解RDD检查点机制的特点与用处理解共享变量的类别、特点与使用 一、RDD容错机制 当Spark集群中的某一个节点由于宕机导致数据丢失,则可以通过Spark中的RDD进行容错恢复已经丢失的数据。RDD提供了两种故障恢复的方式,…...
)
ES6(对象,数组,类型化数组)
对象 1,Object.is 用于判断两个值是否相等, 其内部实现类SameValue算法, 其行为类似于“” 但与“”不同的是 它认为两个NaN是相等的 而0,-0是不相等的 2,Object.assign 表示此方法可以将对象合并成一个 他的第一个…...
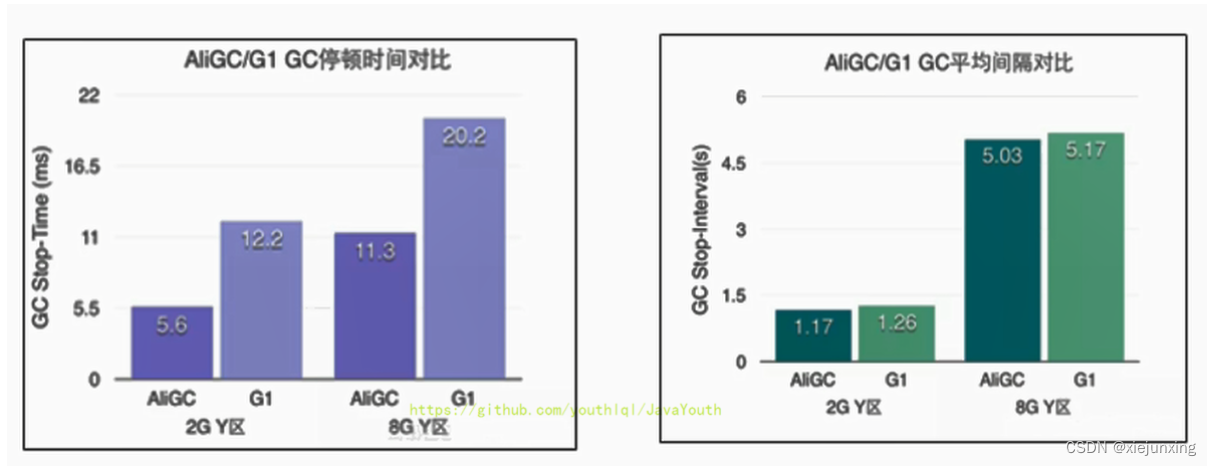
JVM系列-第12章-垃圾回收器
垃圾回收器 GC 分类与性能指标 垃圾回收器概述 垃圾收集器没有在规范中进行过多的规定,可以由不同的厂商、不同版本的JVM来实现。 由于JDK的版本处于高速迭代过程中,因此Java发展至今已经衍生了众多的GC版本。 从不同角度分析垃圾收集器,…...

零操作难度,轻松进行应用测试,App专项测试之Monkey测试完全指南!
目录 前言: 一、 Monkey测试的基础参数 1.1 事件类型参数: 1.2 覆盖包 1.3 事件数量 二、 Monkey测试的高级参数 2.1 稳定性级别 2.2 策略参数 2.3 包含选项参数 三、 附加代码 四、 总结 前言: 在移动应用的开发过程中࿰…...

Linux安装Docker(这应该是你看过的最简洁的安装教程)
Docker是一种开源的容器化平台,可以将应用程序及其依赖项打包成一个可移植的容器,以便在不同的环境中运行。Docker的核心是Docker引擎,它可以自动化应用程序的部署、扩展和管理,同时还提供了一个开放的API,可以与其他工…...

使用AES算法加密技术集成Java和Vue保护您的数据,代码示例和算法原理
1 算法的原理: AES是一种对称加密算法,也就是说加密和解密使用的是同一个密钥。其基本原理是将明文分成固定大小的块(128位),然后使用密钥对每个块进行加密操作,最后生成密文。在加密过程中,还需要使用一个向量(IV)来增加安全性,避免相同的明文块生成相同的密文块。…...
vcruntime140_1.dll丢失怎样修复,推荐4个vcruntime140_1.dll丢失的修复方法
vcruntime140_1.dll文件是Microsoft Visual C Redistributable for Visual Studio 2015运行库的一部分,它是一个用于支持Visual C构建的应用程序的系统文件。这个文件包含了在运行C程序时所需要的函数和类库,主要负责向应用程序提供运行时环境。如果电脑…...
快来试试这几个简单好用的手机技巧吧
技巧一:相机功能 苹果手机的相机功能确实非常出色,除了出色的像素之外,还有许多其他实用功能可以提升拍摄体验。 这些相机功能提供了更多的选择和便利性,使用户能够更好地适应不同的拍摄需求。 自拍功能:通过选择自…...
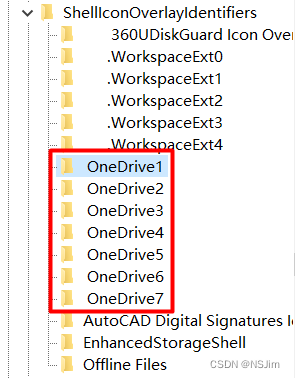
OneDrive同步角标消失 - 解决方案
问题 在电脑端使用OneDrive时,文件管理器OneDrive文件夹内的文件会在左下角显示同步状态,如下图。若没有显示同步角标,则此功能出现异常,下文介绍如何显示同步角标。 值得一提的是,同步角标只起到显示作用࿰…...
自学网络安全【黑客】,一般人我劝你还是算了吧
前言:我是劝一般人算了,看你是一般人还是。。。 一、网络安全学习的误区 1.不要试图以编程为基础去学习网络安全2.不要刚开始就深度学习网络安全3.收集适当的学习资料4.适当的报班学习二、学习网络安全的些许准备 1.硬件选择2.软件选择3.外语能力三、网…...

Java集合工具:first和last
在平常开发过程中,我们经常会遇到截取列表片段的需求,比如取列表中前4个元素、取后四个元素。Java的List提供了subList方法,可以用来完成这些工作,但是使用起来并没有那么便利,比如取前四个元素: list.sub…...

leetcode 905. 按奇偶排序数组
题目描述解题思路执行结果 leetcode 905. 按奇偶排序数组 题目描述 按奇偶排序数组 给你一个整数数组 nums,将 nums 中的的所有偶数元素移动到数组的前面,后跟所有奇数元素。 返回满足此条件的 任一数组 作为答案。 示例 1: 输入:…...

r2frida:打通静态分析与动态调试的逆向工作流
1. 这不是“又一个插件”,而是动态分析工作流的物理层重构你有没有过这样的经历:在逆向一个加固App时,刚用r2 -A扫完符号,发现关键函数全被混淆成sub_401a2c;切到Frida写个Java.perform脚本hook住目标方法,…...
)
避坑指南:用SARIMA做时间序列预测时,这5个参数调优错误千万别犯(Python实战)
SARIMA模型调优实战:避开时间序列预测中的五大陷阱引言在数据分析领域,时间序列预测一直是个既迷人又充满挑战的课题。每当我看到那些起伏的曲线,总能感受到数据背后隐藏的故事和规律。SARIMA模型作为时间序列分析的重要工具,因其…...

保险领域AutoML实战:从数据不平衡到模型部署的端到端解决方案
1. 项目概述:当AutoML遇上保险数据在保险行业摸爬滚打了十几年,从最初用Excel做简单的赔付率分析,到后来引入逻辑回归、决策树,再到如今面对动辄上百个特征、千万级样本的复杂数据集,我深刻体会到一件事:构…...
:工厂模式——对象创建的解耦艺术)
设计模式实战解读(二):工厂模式——对象创建的解耦艺术
本文是「设计模式实战解读」系列第二篇。系列文章统一按照 定义 → 痛点场景 → 模式结构 → 核心实现 → 真实应用 → 常见变种 → 优缺点 → 避坑指南 → FAQ 的结构展开,每篇聚焦一个模式讲透。 一句话定义 工厂模式(Factory):…...
:输入你的GPU型号/任务类型/预算,3步锁定最优解)
DeepSeek模型版本选择终极决策树(2024Q3权威更新):输入你的GPU型号/任务类型/预算,3步锁定最优解
更多请点击: https://codechina.net 第一章:DeepSeek模型版本选择终极决策树(2024Q3权威更新):输入你的GPU型号/任务类型/预算,3步锁定最优解 选择适配的 DeepSeek 模型版本是高效落地大模型应用的关键前提…...

文房四宝-徽墨
文房四宝,除了你已经熟悉的墨(以徽墨为代表),还包括笔、纸、砚。这套书写工具共同构成了中国传统文化中文房雅器的核心,每一宝都有其最具代表性的产地与传奇故事。简单来说就是:湖笔、徽墨、宣纸、端砚。&a…...

【Sora 2视频后期处理黄金法则】:20年AI影像专家亲授5大不可绕过的帧级调优技巧
更多请点击: https://codechina.net 第一章:Sora 2视频后期处理的底层逻辑与帧级思维重构 Sora 2并非传统时间轴驱动的剪辑工具,其视频后期处理建立在扩散模型与隐空间帧序列联合优化的基础之上。每一帧不再作为孤立图像存在,而是…...

新手教程使用curl命令快速测试Taotoken的OpenAI兼容接口
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 新手教程:使用curl命令快速测试Taotoken的OpenAI兼容接口 基础教程类,面向刚注册Taotoken的开发者…...

QrazyBox终极指南:专业二维码修复工具拯救你的损坏二维码
QrazyBox终极指南:专业二维码修复工具拯救你的损坏二维码 【免费下载链接】qrazybox QR Code Analysis and Recovery Toolkit 项目地址: https://gitcode.com/gh_mirrors/qr/qrazybox 你是否曾因打印模糊、水渍污染或屏幕划痕导致的重要二维码无法扫描而焦急…...

Google 广告场景下 Uniswap 钓鱼攻击机理与 Web3 防御体系研究
摘要 2026 年 5 月 22 日,GoPlus 安全团队发布预警,针对 Web3 领域头部去中心化交易平台 Uniswap 的搜索引擎钓鱼攻击呈规模化爆发态势。攻击者通过购买 Google Ads 关键词广告,将高仿钓鱼网站置顶于搜索结果前列,结合视觉相似域名…...