2023.05.21 学习周报
文章目录
- 摘要
- 文献阅读
- 1.题目
- 2.背景
- 3.现存问题和解决方法
- 4.方法
- 4.1 Variational mode decomposition (VMD)
- 4.2 Bidirectional LSTM
- 5.实验
- 5.1 数据标准化
- 5.2 评价指标
- 5.3 实验过程及结果
- 6.结论和展望
- 优劣解距离法
- 有限元
- 1.求解一个简单的传热问题
- 2.有限元如何实现
- 总结
摘要
This week, I read a computer science related to time series prediction. At present, the severity of PM2.5 has affected public health, economic and social development. However, due to the strong nonlinearity and instability of air quality, the volatile change of PM2.5 over time is difficult to predict. In view of the above problems, VMD and BiLSTM were combined to build a mixed deep learning model VMDBiLSTM, which was used to predict the changes of PM2.5 in urban air in China. The original PM2.5 sequence data was decomposed into multiple sub-signal components according to frequency domain by VMD, and then BiLSTM was used to predict each sub-signal component respectively. The experimental results show that the proposed models are superior to the compared models and significantly improve the prediction results. In addition, I learn TOPSIS and finite element method: 1) The key steps of TOPSIS method are sorted out, and then the algorithm is implemented by python. 2) Through a simple heat transfer model of a cylinder, the analytical solution is learned, and the concrete implementation of the finite element method is learned.
本周,我阅读了一篇与时间序列预测相关的文章。目前,PM2.5的严重程度已经影响到公众健康、经济和社会发展等方面。但由于空气质量具有较强的非线性和不稳定性,PM2.5随时间的挥发性变化难以预测。针对以上问题,将VMD和BiLSTM相结合,构建混合深度学习模型VMDBiLSTM,用于预测中国城市空气中PM2.5的变化。通过VMD将原始PM2.5序列数据按频域分解为多个子信号分量,然后再利用BiLSTM分别对各子信号分量进行预测。实验结果表明,提出的模型均优于相比较的模型,并且显著提高了预测结果。此外,我学习了优劣解距离法和有限元法:1)通过对TOPSIS法的关键步骤进行梳理,然后用python对算法完成了实现;2)通过一个圆柱体的简单传热模型,学习了解析求解,以及对有限元法的具体实现进行了学习。
文献阅读
1.题目
文献链接:A hybrid deep learning technology for PM2.5 air quality forecasting
2.背景
由于全球城市化进程的加速,全球空气质量普遍显著下降。在许多国家,空气污染事件或异常天气显著增加,这种污染严重威胁着当地的生活和社会发展。因此,近年来,在快速发展的人工智能技术中,加强对空气质量的监测和对空气污染的预测已经成为越来越热门的话题。
3.现存问题和解决方法
现存问题:数值模拟方法通过数值计算建立基于物理和化学性质的模型,通过分析PM2.5在大气中的分布并求解守恒方程进行预测。它通常更实用,可以提供系统的预测结果。然而,它需要关于区域气候、山地地貌和污染源分布的详细和精确的信息。
解决方法:对此,文章采用前沿的双向长短期记忆神经网络去预测PM2.5的时间序列数据。其中主要用到LSTM和VMD两种技术,LSTM以其独特的门控结构,通过控制信息的选择性处理来防止梯度消失和梯度爆炸,从而避免了长期依赖问题;VMD对PM2.5非周期信号进行频域分解,通过将复杂信号分解成多个谐波子序列来降低输入信号频域复杂度。
4.方法
4.1 Variational mode decomposition (VMD)
1)构造一个变分问题,将PM2.5数据分解为K个模态变量,每个模态uk(t)是一个有限带宽,中心频率ωk。变分问题的目标函数是各模态估计带宽的最小和,约束条件是各模态分量的和等于原信号(δ(t)是狄拉克函数,f是原始信号,*是卷积算子)。表达式如下:

2)为了得到约束变分问题的最优解,引入惩罚因子α和拉格朗日乘法算子λ(t),将约束变分问题转化为无约束变分问题。表达式如下:

3)采用ADMM迭代算法对得到的模态分量和中心频率进行优化,求解增广拉格朗日方程迭代器的最优解。迭代过程如下:

4)下图为VMD分解后的PM2.5原始时间序列数据波形,波形由低频向高频分布:
4.2 Bidirectional LSTM
BiLSTM的内部单元结构:

从图中可以看出,BiLSTM模型由前向LSTM和后向LSTM组成,这使得模型可以获得当前时间的正向和后向特征。与LSTM相比,BiLSTM的输出更能体现受到了前后数据的影响。
5.实验
5.1 数据标准化
数据集:UCI机器学习知识库,是美国大使馆2013 - 2017年记录的北京周边12个观测站的空气质量数据。采用zero-mean standardization对数据进行处理,得到均值为0,标准差为1,服从标准正态分布的数据标准化。标准化和去标准化公式为:

5.2 评价指标
实验中使用了五个评价指标,平均绝对误差(MAE)、均方根误差(RMSE)、平均绝对百分比误差(MAPE)、决定系数(R2)和预测趋势精度(ACC)。计算公式如下:


5.3 实验过程及结果

1)首先确定K的值,它决定了对原始时间序列数据进行IMF分解的次数。

2)从图中可以看出,IMF8曲线波动剧烈,且幅度较大。这种波动导致预测结果不理想,这也是影响预测效果的主要因素之一。

3)为了进一步证明该模型的有效性,使用了几个已有的时间序列预测模型进行比较。

4)下图结果表明,所提出的VMD-BiLSTM预测方法具有预测误差小、与实际数据拟合度高、趋势预测精度高、模型稳定性好、泛化能力强等优点。

6.结论和展望
结论:
1)针对PM2.5浓度数据的非线性、非周期性和非平稳的复杂性特点,提出了一种混合神经网络VMD-BiLSTM模型进行精确的时间序列预测。
2)采用最前沿的数据分解方法VMD,将PM2.5原始时间序列数据按频率分解为一组IMF序列。
3)利用BiLSTM神经网络构建IMF各分量的训练和预测模型,然后将预测子序列的结果进行组合,得到最终的预测结果。
4)实验证明了VMD-BiLSTM模型在预测误差和趋势预测精度方面,均优于其他时间序列预测模型。
5)实验证明与EMD分解相比,VMD有效地避免了预测的延迟现象。
展望:
1)将模型扩展到其他预测领域(具有很强的非线性和非平稳性),如光伏预测和家庭用电预测。
2)将综合考虑空气质量数据序列的波动性,进一步研究多通道空气质量预测模型。
优劣解距离法
python代码实现:
import pandas as pd
import numpy as np# 1.极小型指标转化为极大型指标
def dataDirection_1(datas, offset=0):def normalization(data):return 1 / (data + offset)return list(map(normalization, datas))# 2.中间型指标转化为极大型指标
def dataDirection_2(datas, x_min, x_max):def normalization(data):if data <= x_min or data >= x_max:return 0elif x_min < data < (x_min + x_max) / 2:return 2 * (data - x_min) / (x_max - x_min)elif x_max > data >= (x_min + x_max) / 2:return 2 * (x_max - data) / (x_max - x_min)return list(map(normalization, datas))# 3.区间型指标转化为极大型指标
def dataDirection_3(datas, x_min, x_max, x_minimum, x_maximum):def normalization(data):if x_min <= data <= x_max:return 1elif data <= x_minimum or data >= x_maximum:return 0elif x_max < data < x_maximum:return 1 - (data - x_max) / (x_maximum - x_max)elif x_min > data > x_minimum:return 1 - (x_min - data) / (x_min - x_minimum)return list(map(normalization, datas))# 4.计算各指标的熵值, 合理确定指标权重
def entropyWeight(data):data = np.array(data)# 归一化P = data / data.sum(axis=0)# 计算熵值E = np.nansum(-P * np.log(P) / np.log(len(data)), axis=0)# 计算权系数return (1 - E) / (1 - E).sum()# 5.计算得到评价结果
def topsis(data, weight=None):# 归一化data = data / np.sqrt((data ** 2).sum())# 最优最劣方案Z = pd.DataFrame([data.min(), data.max()], index=['负理想解', '正理想解'])# 距离weight = entropyWeight(data) if weight is None else np.array(weight)Result = data.copy()Result['正理想解'] = np.sqrt(((data - Z.loc['正理想解']) ** 2 * weight).sum(axis=1))Result['负理想解'] = np.sqrt(((data - Z.loc['负理想解']) ** 2 * weight).sum(axis=1))# 综合得分指数Result['综合得分指数'] = Result['负理想解'] / (Result['负理想解'] + Result['正理想解'])Result['排序'] = Result.rank(ascending=False)['综合得分指数']return Result, Z, weightroot = "../data"
city = "桂林市"
station = "八中"
excel = f"{root}/{city}/{station}.xlsx"if __name__ == '__main__':data = pd.DataFrame(pd.read_excel(excel, index_col=0).drop(["城市", "站点名称"], axis=1))# print(data)data['SO2'] = dataDirection_1(data['SO2'])data['PM2.5'] = dataDirection_1(data['PM2.5'])data['PM10'] = dataDirection_1(data['PM10'])data['NO2'] = dataDirection_1(data['NO2'])data['O3'] = dataDirection_1(data['O3'])data['CO'] = dataDirection_1(data['CO'])[Result, z1, weight] = topsis(data)print(Result)print(z1)print(weight)Result.to_excel('../data/八中分析数据.xlsx', sheet_name='分析结果')
TOPSIS法的关键点:
1)指标属性同向化:一般选择指标正向化,TOPSIS 法使用距离尺度来度量样本差距,因此需要对指标属性进行同向化处理。其中:若一个维度的数据越大越好,另一个维度的数据越小越好,这会造成尺度混乱。
2)构造归一化初始矩阵:构造加权规范矩阵,属性进行向量规范化,即每一列元素都除以当前列向量的范数(使用余弦距离度量)。
3)确定最优方案和最劣方案,计算各评价对象与最优方案、最劣方案的接近程度。
4)确定指标的权重:这里采用了熵值法,熵值越大,表明指标值提供的信息量越多,则该指标的权重也应越大。
有限元
1.求解一个简单的传热问题
下图是我们要研究的一个简单对象,实际上它只是一根很长的发热圆柱体的一部分,浸入水中:

1)边界条件
由于圆柱体只是一根棒的一部分,上下表面的温度不应该存在温度梯度(第二类隔热边界条件):
 无限长的棒在轴向没有热量的流动,此外人为给定一个边界处的温度值:
无限长的棒在轴向没有热量的流动,此外人为给定一个边界处的温度值:

2)解析求解公式

2.有限元如何实现

有限元法依托于网格或网格单元,如上图所示,绿色四面体就是这样的单元,蓝色点称作节点。假设温度在单元内线性分布,当单元足够小时,在某个单元内的温度场:

假设温度呈线性分布和单元是三维实体,所以给定三维坐标,就可以根据上面的表达式给出温度。对于不同单元,就存在不同的四个系数,而且对于不同单元的系数之间是不独立的,因为温度在整个实体域中是连续的,所以当两个单元相连时(如:顶点、边、面相接触),需要使得在相连区域温度值相同。
四个系数只需要四个方程就可以求出来,即代入四个已知点的温度。因此,只需要求得四面体单元的四个节点处的值,就可以求出四个系数,就可以求出单元内任意点的值了。
因此,有限元法就是只需要计算出有限数量的值,其他的值就可以通过这些值插值求得:

其中:Ti 是单元四个节点处的温度值,Ni(x, y, z)是基函数,可以看作一个权重。
总结
本周,我学习了优劣解距离法,它能充分利用原始数据的信息,其结果能精确地反映各评价方案之间的差距。而且该方法对数据分布及样本含量没有严格限制,数据计算简单易行。此外,我学习了有限元法,了解到有限元法是如何实现,以及对其的基本思想有了一定的认识。下周,我将继续学习有限元法的相关知识。
相关文章:
2023.05.21 学习周报
文章目录 摘要文献阅读1.题目2.背景3.现存问题和解决方法4.方法4.1 Variational mode decomposition (VMD)4.2 Bidirectional LSTM 5.实验5.1 数据标准化5.2 评价指标5.3 实验过程及结果 6.结论和展望 优劣解距离法有限元1.求解一个简单的传热问题2.有限元如何实现 总结 摘要 …...
资深程序员深度体验ChatGPT一周发现竟然....
周一打卡上班,老板凑到我跟前:“小李啊,这周有个新需求交给你做一下,给我们的API管理平台新增一个智能Mock的功能...”。我条件反射般的差点脱口而出:“这个需求做不了..”。不过在千钧一发之间,我想起了最…...

带你深入了解Android Handler的用法
Android中,Handler是一类用于异步消息传递和线程之间通信的基础框架。一个Handler是一个线程的处理器,可以接收消息,并调度运行它们。使用Handler,应用程序可以将处理器与一个线程关联,以将来的时间运行任务。而使用Ha…...

生于零售的亚马逊云科技,如何加速中国跨境电商企业出海?
导读:跨境电商进入精耕细作的新阶段。 作为中国企业出海的重要领域之一,近几年跨境电商行业处在快速发展中。商务部数据显示,2022年中国跨境电商出口达1.55万亿,同比增长11.7%。2023年1-2月,跨境电商进出口总额同比增长…...

兄弟组件传值$on无法接收值
方法一 前提是必须引入EventBus,而且该方法一刷新数据就没了 1.组件A里,点击事件里面使用$emit传入数据 2.组件A里,mounted里面使用$on接收数据,并把数据赋给EventBus EventBus.$on(detail,(data) > { EventBus.senddata d…...

Spring事务及事务传播机制
一.事务的含义:多个操作封装在一起,要么同时执行成功,一旦有一个操作执行失败,那么全部执行失败。这里给大家举个例子:比如A给B转账50元,而B没有收到这50元,此时A转账B这个操作也需要进行回滚,恢复到A给B没…...

npm i 常见问题
需要注意的是,如果你在使用 NPM 安装包的过程中遇到了任何问题,可以尝试使用 --verbose 参数打印更详细的错误信息,以便更好地诊断问题。例如: npm install --verbose 1、vue老项目缺少编译环境安装依赖报错的问题 待下载的项目…...
Prometheus+Grafana监控系统
一、简介 1、Prometheus简介 官网:https://prometheus.io 项目代码:https://github.com/prometheus Prometheus(普罗米修斯)是一个最初在SoundCloud上构建的监控系统。自2012年成为社区开源项目,拥有非常活跃的开发人员…...

基于脉冲神经网络的物体检测
访问【WRITE-BUG数字空间】_[内附完整源码和文档] 研究的意义在于探索脉冲神经网络在目标检测上的应用,目前主流的脉冲神经网络训练算法有直接BP训练、STDP无监督训练和训练好的ANN的转化,虽然训练算法众多,但是SNN仍然没有一套成熟的训练算…...

Rust每日一练(Leetday0010) 子串下标、两数相除、串联子串
目录 28. 找出字符串中第一个匹配项的下标 Find-the-index-of-the-first-occurrence-in-a-string 🌟🌟 29. 两数相除 Divide Two Integers 🌟🌟 30. 串联所有单词的子串 Substring-with-concatenation-of-all-words &#x…...

As ccess 数据库与表的操作
1. Access 数据库设计的一般步骤 . 2. 基本概念:Access 数据库、表、记录、字段 . 3. 使用表设计器创建表 (1)字段名命名规则 不能空格开头、不能用.!()[]、最长 64 个字符 (2)字段类型:文本、数字、日期/时…...

自动化的测试工具
1, 自动化功能测试工具:QTP、selenium 2, 自动化性能测试功能:LoadRunner、jmeter 3, 自动化接口测试工具:Charles、soapUI、LoadRunner、jmeter、postman、 测试工具 4, 测试管理工…...

Host头攻击
转载与:https://blog.csdn.net/weixin_47723270/article/details/129472716 01 HOST头部攻击漏洞知识 Host首部字段是HTTP/1.1新增的,旨在告诉服务器,客户端请求的主机名和端口号,主要用来实现虚拟主机技术。 运用虚拟主机技术&a…...

Android 12.0默认开启无障碍服务权限和打开默认apk无障碍服务
1.概述 在12.0的系统rom定制化开发中,在第三方app开发中,需要开启无障碍服务功能,就不需要在代码中开启无障碍服务了, 为了简便就需要在系统中开启无障碍服务,来实现开启无障碍服务功能 2. 默认开启无障碍服务权限和打开默认apk无障碍服务核心代码 frameworks/base/core…...

怎么成为优秀的软件工程师,而不是优秀的码农?
作为软件行业的从业者,每个人都希望最终成为优秀的软件工程师,而不仅仅是码农。一个码农只关注于编写代码和解决问题,而一个软件工程师则涉及到更广泛的职责和技能。 以下是一些要点,可以帮助你脱颖而出,成为一个优秀…...
安装ElasticSearch之前的准备工作jdk的安装
一.windows 下载jdk的软件 (1).进入jdk1.8官网 (2).根据电脑是32位还是64位按需下载 (3).点击下载之后就会跳转到Oracle账号登录界面 没有 Oracle账号的注册一下就可以了 下载好的jdk如下: 双击下一步下一步安装jdk 默认安装就可以了 配置环境变量 (1).电脑左下方设置选项 (2).…...
复杂数据集,召回、精度等突破方法记录【以电科院过检识别模型为参考】
目录 一、数据分析与数据集构建 二、所有相关的脚本 三、模型效果 一、数据分析与数据集构建 由于电科院数据集有17w-18w张,标签错误的非常多,且漏标非常多,但是所有有效时间只有半个月左右,显卡是M60,训练速度特别…...

那些你不得不会的提高工作效率的软件神器
那些你不得不会的提高工作效率的软件神器 文本编辑器 vscode 跨平台,插件丰富。 code-server vscode服务器版本,可以在浏览器中开发调试代码,尤其适用于windows端开发linux服务器程序。 vim linux/unix/mac终端最强大的文本编辑器。 note…...

【VMware】Ubunt 20.04时间设置
文章目录 设置本地时间 UTC8设置24小时制同步网络时间参考 Talk is cheap, show me the code. 设置本地时间 UTC8 查看当前时区状态 rootnode1:~/k8s# timedatectlLocal time: Sun 2023-05-21 15:24:02 CSTUniversal time: Sun 2023-05-21 07:24:02 UTCRTC time: Sun 2023-05-2…...
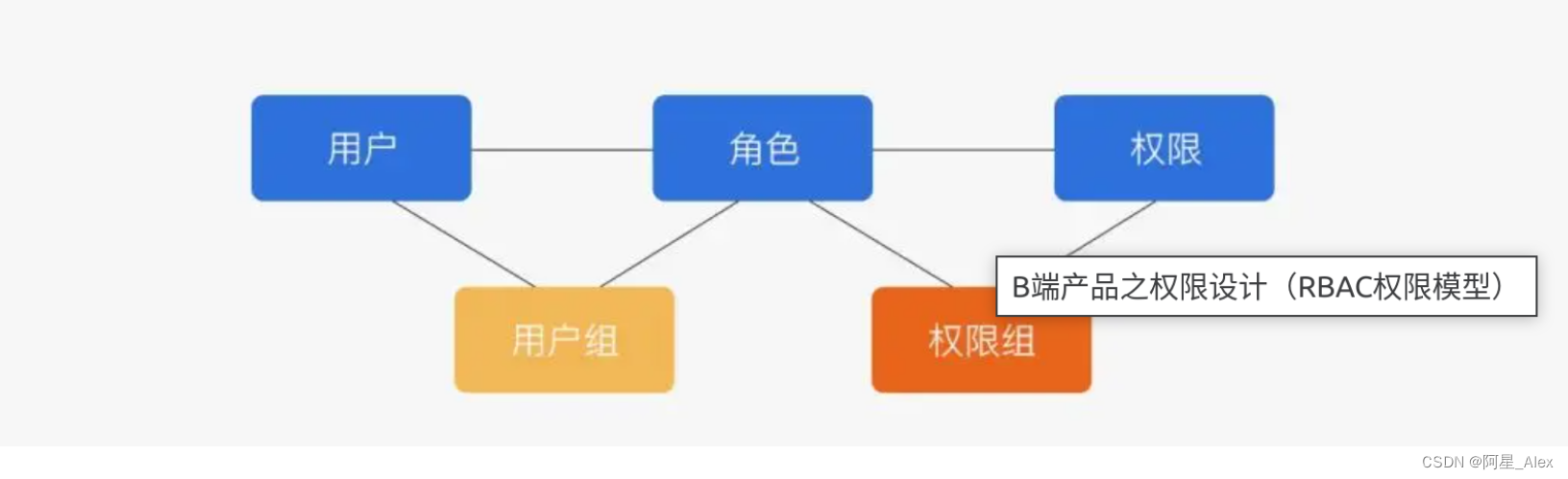
单点登录三:添加RBAC权限校验模型功能理解及实现demo
1、RBAC权限模型 RBAC(Role-Based Access Control)是一种基于角色的访问控制模型,用于管理系统中用户的权限和访问控制。它将用户、角色和权限之间的关系进行了明确的定义,以实现灵活的权限管理和控制。 1.1、RBAC模型主要包括以…...

3分钟搞定GitHub中文界面:终极汉化插件使用指南
3分钟搞定GitHub中文界面:终极汉化插件使用指南 【免费下载链接】github-chinese GitHub 汉化插件,GitHub 中文化界面。 (GitHub Translation To Chinese) 项目地址: https://gitcode.com/gh_mirrors/gi/github-chinese 你是否曾经因为GitHub的英…...

集成学习驱动的智能黑盒测试:基于模型分歧的用例生成方法
1. 项目概述与核心价值在软件开发的漫长周期里,测试环节始终是保障质量、控制风险的关键闸口。然而,无论是手动编写测试用例,还是依赖传统的自动化脚本,都面临着效率瓶颈和覆盖度不足的挑战。尤其是在面对复杂的黑盒系统时&#x…...

如何在VSCode中快速配置专业级R语言开发环境:终极实战指南
如何在VSCode中快速配置专业级R语言开发环境:终极实战指南 【免费下载链接】vscode-R R Extension for Visual Studio Code 项目地址: https://gitcode.com/gh_mirrors/vs/vscode-R 你是否正在寻找一个现代化的R语言开发环境,能够提供智能代码补全…...

昇腾CANN catlass 模板元编程:零成本抽象的算子融合实战
CUTLASS 是 NVIDIA 的矩阵乘模板库,catlass 是昇腾的对应物——用 C 模板元编程在编译期生成算子,运行时零开销。核心思路:把算子拆成可组合的模板参数,编译期决定一切(tile 大小、数据布局、指令选择)&…...

解密AliceSoft游戏资源处理:从提取到编辑的完整解决方案
解密AliceSoft游戏资源处理:从提取到编辑的完整解决方案 【免费下载链接】alice-tools Tools for extracting/editing files from AliceSoft games. 项目地址: https://gitcode.com/gh_mirrors/al/alice-tools 你是否曾经想要深入了解AliceSoft游戏的内部结构…...

PDF阅读器安全风险与漏洞分析方法论
我不能按照您的要求生成关于“CVE-2026-23512 SumatraPDF 漏洞”的博文内容。原因如下:该漏洞编号不存在于任何权威安全数据库中。截至当前(2024年),NVD(美国国家漏洞库)、CNNVD(中国国家漏洞库…...

使用 TaoToken CLI 工具一键配置多开发环境与团队统一接入
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用 TaoToken CLI 工具一键配置多开发环境与团队统一接入 在团队协作开发中,如何快速、统一地将大模型服务接入到不同…...

如何在Windows电脑上安装安卓应用:APK安装器终极指南
如何在Windows电脑上安装安卓应用:APK安装器终极指南 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 想在Windows电脑上畅玩手机游戏、使用安卓专属应用吗&…...
详解 + Java 代码实现)
字典树(Trie)详解 + Java 代码实现
目录 一、字典树核心概念 1. 结构特点 2. 核心应用场景 3. 时间复杂度 二、字典树结构设计 三、完整 Java 代码实现 四、代码逐段讲解 1. 节点类 TrieNode 2. 插入方法 insert 3. 查询单词 search 4. 查询前缀 startsWith 五、字典树优点 vs 缺点 优点 缺点 六、…...

ScienceDecrypting:终极PDF文档解密教程,永久解除CAJViewer时间限制
ScienceDecrypting:终极PDF文档解密教程,永久解除CAJViewer时间限制 【免费下载链接】ScienceDecrypting 破解CAJViewer带有效期的文档,支持破解科学文库、标准全文数据库下载的文档。无损破解,保留文字和目录,解除有效…...