复杂数据集,召回、精度等突破方法记录【以电科院过检识别模型为参考】
目录
一、数据分析与数据集构建
二、所有相关的脚本
三、模型效果
一、数据分析与数据集构建
由于电科院数据集有17w-18w张,标签错误的非常多,且漏标非常多,但是所有有效时间只有半个月左右,显卡是M60,训练速度特别慢,所以需要尽量留足训练时间,至少是1周左右,而且为了保证训练的轮数尽量多,还需要使得数据集尽量有效,减少冗余
数据复杂情况如下:
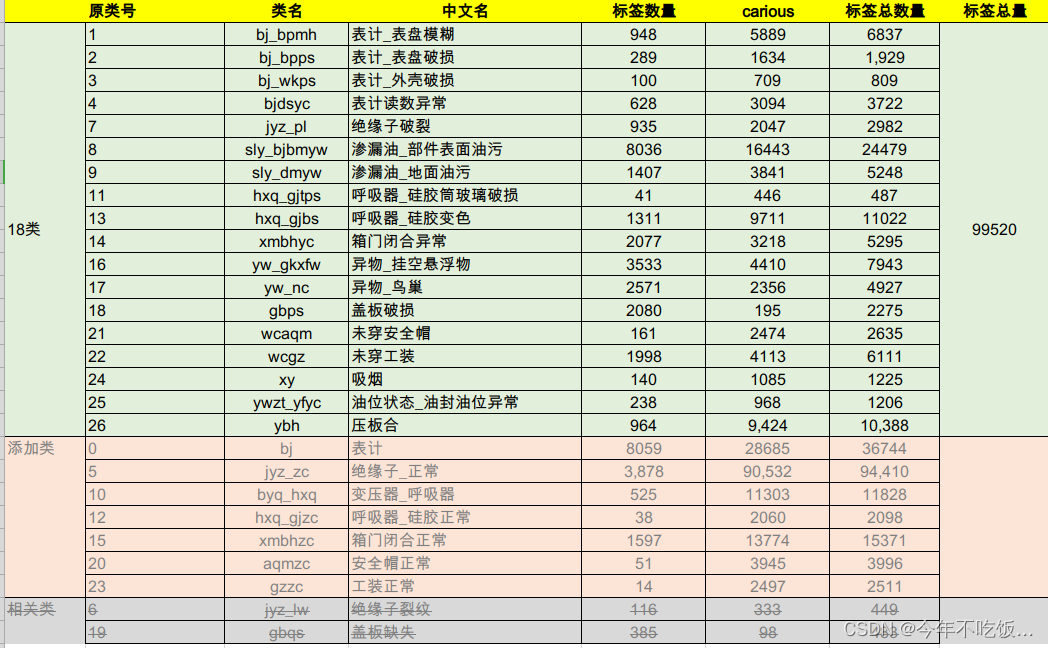
由于只训练缺陷类,效果难以达到较好的情况,所以这里考虑加入正常数据,作为辅助,做法流程是:
只筛选缺陷看看带出来多少正常——在里面剔除不需要的类(这里是6和19)——然后由于正常类不能和异常交叉存在,所以剔除和异常交叉的正常类的标,IOU阈值取0.5
得到数据情况如下:
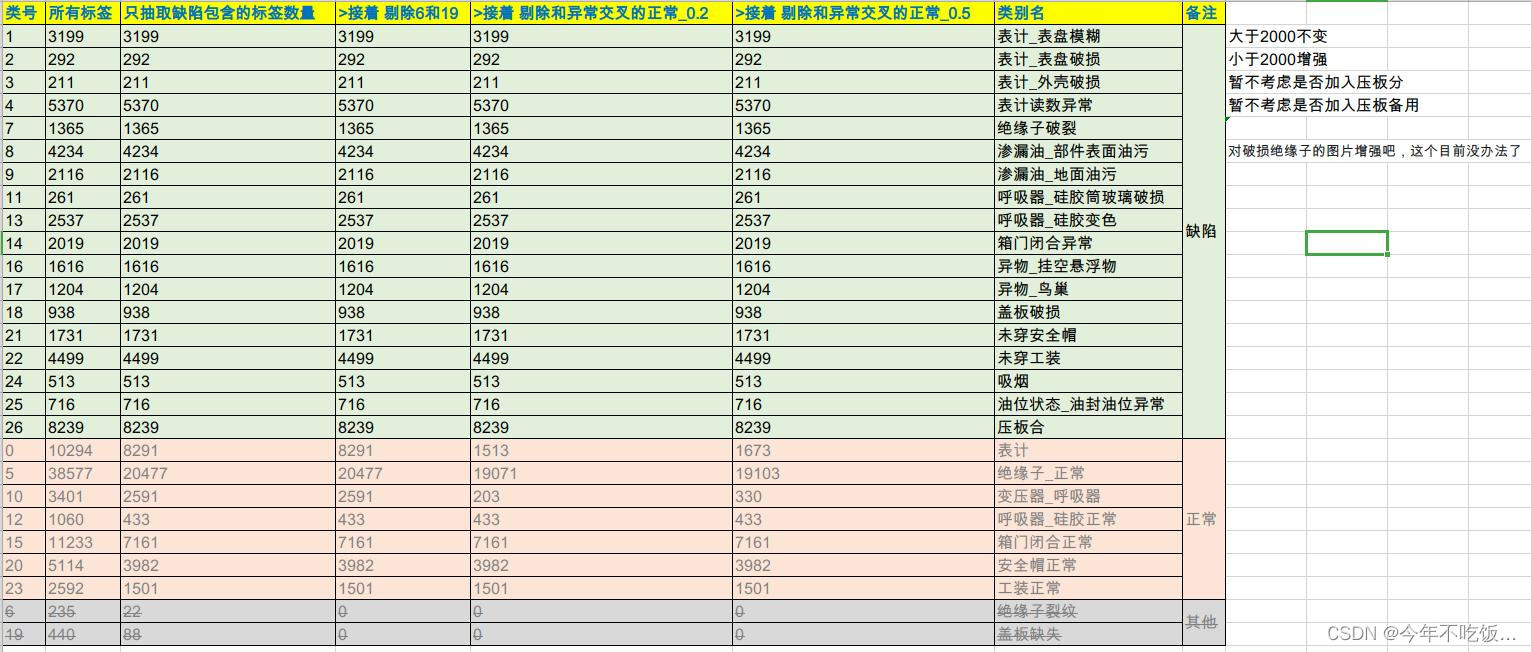
由于“绝缘子正常”太多,这里考虑删除一部分,使得绝缘子正常的数量也能在1000-2000,做法是先统计“5_class27_0518_接着剔除和异常交叉的正常_0.5_抽取绝缘子正常”,然后统计每个类和绝缘子共存的情况,看看哪些较多,能否剔除该类中共存的绝缘子达到目的,数据统计如下:
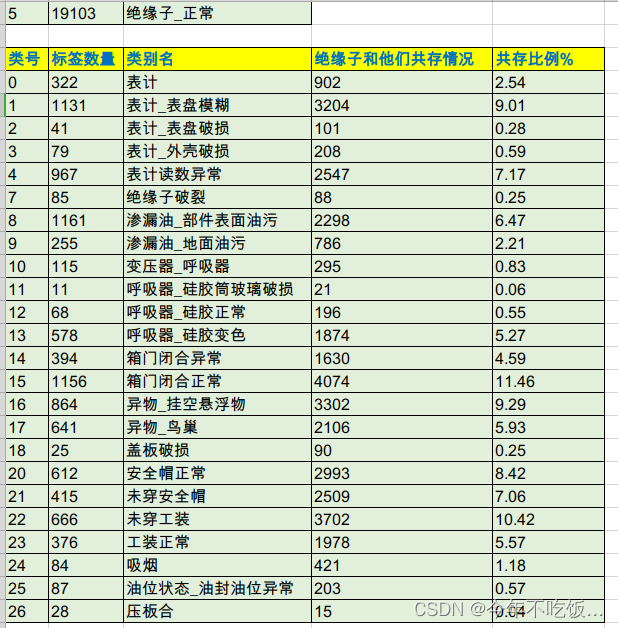
可见绝缘子并不是很大一部分分布在某一个或者几个类里面的,所以这里无法剔除,只是对“绝缘子破损”进行增强来弥补该类的数据不足
最终训练使用的数据是“6_2_class27_0518_接着剔除和异常交叉的正常_0.5_split”,然后将数据20-25%作为val,其余进行train,进行训练,寻找最佳的方法
数据集每类平衡的规则是:不足2000的增强到2000幅,补充的对照样本(绝缘子正常等)不足1000的增强到1000,尽量均衡的前提下正样本不能多
寻找到最佳方法后,所有是train,不留val,使得尽量多的数据参与训练,以得到最佳模型
二、所有相关的脚本
1_abcd当指定类和它相关类iou过大时剔除该指定类
import osdef calculate_iou(box1, box2):# 提取边界框的坐标和尺寸x1, y1, w1, h1 = box1[1:]x2, y2, w2, h2 = box2[1:]# 计算边界框的右下角坐标x1_right, y1_bottom = x1 + w1, y1 + h1x2_right, y2_bottom = x2 + w2, y2 + h2# 计算相交区域的坐标x_intersect = max(x1, x2)y_intersect = max(y1, y2)x_intersect_right = min(x1_right, x2_right)y_intersect_bottom = min(y1_bottom, y2_bottom)# 计算相交区域的宽度和高度intersect_width = max(0, x_intersect_right - x_intersect)intersect_height = max(0, y_intersect_bottom - y_intersect)# 计算相交区域的面积intersect_area = intersect_width * intersect_heightif intersect_area<0.000001:return 1# 计算两个边界框的面积box1_area = w1 * h1box2_area = w2 * h2# 计算最小并集whole_area = float(box1_area + box2_area - intersect_area)min_area = float(min(box1_area,min(box2_area,whole_area)))# 计算IOUiou = intersect_area /min_areareturn ioudef filter_annotations(queding_id,id_list,filename):list1 = []list2 = []filtered_annotations = []with open(filename, 'r') as file:lines = file.readlines()print('all:\n',lines)for line in lines:class_label, x, y, width, height = line.split(' ')x, y, width, height = float(x), float(y), float(width), float(height)class_id = int(class_label)if int(class_id) == queding_id:list1.append([class_id, x, y, width, height])elif int(class_id) in id_list:list2.append([class_id, x, y, width, height])else:filtered_annotations.append(line)for annotation1 in list1:iou_greater_than_0_2 = Falsefor annotation2 in list2:iou = calculate_iou(annotation1, annotation2)if iou > 0.2:print('iou,',iou)iou_greater_than_0_2 = Truebreakif not iou_greater_than_0_2:line_dst1 = str(annotation1[0])+" "+str(annotation1[1])+" "+str(annotation1[2])+" "+str(annotation1[3])+" "+str(annotation1[4])+"\n"filtered_annotations.append(line_dst1)for annotation2 in list2:line_dst2 = str(annotation2[0])+" "+str(annotation2[1])+" "+str(annotation2[2])+" "+str(annotation2[3])+" "+str(annotation2[4])+"\n"filtered_annotations.append(line_dst2)with open(filename,"w",encoding="utf-8") as f:for line in filtered_annotations:f.write(line)return filtered_annotationsif __name__=='__main__':"""queding_id = 0id_list = [1,2,3,4]--------------------------queding_id = 5id_list = [6,7]--------------------------queding_id = 10id_list = [11,12,13]"""queding_id = 10id_list = [11,12,13]folder_path='./1_class27'for root,_,files in os.walk(folder_path):if len(files)>0:for file in files:if file.endswith('.txt'):print('---------------')print(file)file_path=os.path.join(root,file)res = filter_annotations(queding_id,id_list,file_path)for l in res:print(l)2splitImgAndLabelByLabelid
# -*- encoding:utf-8 -*-
import os
import cv2
import sys
import shutil
from pathlib import Pathsuffixs = [".png"]if len(sys.argv) != 2:print("input as:\n python 1splitImgAndLabelByLabelid.py imgFolder")sys.exit()path = sys.argv[1]if not os.path.exists(path):print("sorry, you input empty floder ! ")sys.exit()file_type_list = ['txt']for name in os.listdir(path):print("-"*20)print("name,",name)file_path=os.path.join(path,name)file_type=file_path.split('.')[-1]for suffix in suffixs:file_name=file_path[0:file_path.rfind('.', 1)]+suffixif os.path.exists(file_name):image=cv2.imread(file_name)if image is None:continueelse:breakif(file_type in file_type_list):bef=open(file_path)ids=[]for line in bef.readlines():linenew = line.strip().split(" ")if len(linenew) == 5:ids.append(int(linenew[0]))ids_len=len(ids)if ids_len == 0:save_path = "empty"if not os.path.exists(save_path):os.mkdir(save_path)shutil.move(file_path,save_path)shutil.move(file_name,save_path)elif ids_len == 1:save_path = str(ids[0])if not os.path.exists(save_path):os.mkdir(save_path)shutil.move(file_path,save_path)shutil.move(file_name,save_path)else:ids.sort()if ids[0] == ids[-1]:save_path = str(ids[0])if not os.path.exists(save_path):os.mkdir(save_path)shutil.move(file_path,save_path)shutil.move(file_name,save_path)else:save_path = "various"if not os.path.exists(save_path):os.mkdir(save_path)shutil.move(file_path,save_path)shutil.move(file_name,save_path)print(ids)3_copyfilesbyclassid
# encoding:utf-8import os
import cv2
import shutilsuffixs = [".JPG",".PNG",".bmp",".jpeg",".jpg",".png"]def backup_txt_files(src_dir, dst_dir):for root,_,files in os.walk(src_dir):for file in files:if file.endswith('.txt'):# select labelsrc_path = os.path.join(root, file)rel_path = os.path.relpath(src_path,src_dir)dst_path = os.path.join(dst_dir, rel_path)new_label_data = []with open(src_path, "r", encoding="utf-8") as f:for line in f:line_tmp = line.strip().split(" ")if len(line_tmp) == 5:if int(line_tmp[0]) == 6 :continueline_dst = line_tmp[0]+" "+line_tmp[1]+" "+line_tmp[2]+" "+line_tmp[3]+" "+line_tmp[4]+"\n"new_label_data.append(line_dst)if len(new_label_data)>0:# process labeldst_folder=os.path.dirname(dst_path)os.makedirs(dst_folder, exist_ok=True)with open(dst_path,"w",encoding="utf-8") as f:for line in new_label_data:f.write(line)# process imagefor suffix in suffixs:file_name=src_path[0:src_path.rfind('.', 1)]+suffixif os.path.exists(file_name):image=cv2.imread(file_name)if image is not None:shutil.copy(file_name, dst_folder)break# 指定源路径和备份路径(最好使用绝对路径)
src_dir = 'various'
dst_dir = 'various_6'# 执行备份操作
backup_txt_files(src_dir, dst_dir)4_ccccc补充various到单类中
# encoding:utf-8import os
import shutil
from termios import PARODD
import cv2
import randomdef backup_txt_files(src_dir, sample_dir,class_id,num_thresh):src_num_files = len([f for f in os.listdir(src_dir) if os.path.isfile(os.path.join(src_dir, f))])//2if src_num_files > num_thresh:exit()# search_res=[]for root,_,files in os.walk(sample_dir):for file in files:if file.endswith('.txt'):flag = Falselabel_path = os.path.join(root, file)with open(label_path, "r", encoding="utf-8") as f:for line in f:line_tmp = line.strip().split(" ")if len(line_tmp) == 5:if int(line_tmp[0]) == class_id :flag = Trueif flag == False:continuefile_name=label_path[0:label_path.rfind('.', 1)]+".jpg"if os.path.exists(file_name):image=cv2.imread(file_name)if image is not None:search_res.append((file_name,label_path))# shufrandom.shuffle(search_res)sample_num_files = len(search_res)//2# save_path=src_dir+"_various"os.makedirs(save_path,exist_ok=True)# add_num = num_thresh - src_num_filesprint(src_dir,' ',src_num_files,' ',add_num)if sample_num_files < add_num:for file,label in search_res:shutil.move(file,save_path)shutil.move(label,save_path)else:for i in range(add_num):shutil.move(search_res[i][0],save_path)shutil.move(search_res[i][1],save_path)# 指定源路径和备份路径(最好使用绝对路径)
src_dir = 'single'
sample_dir = 'various'
num_thresh = 3000# 执行备份操作
for folder in os.listdir(src_dir):print('-'*40)backup_txt_files(os.path.join(src_dir,folder),sample_dir,int(folder),num_thresh)5_dedadada当指定类标过多时删去标抹去标签区域
import os
import random
import cv2def process(label_path,class_id):if label_path.endswith('.txt'):# select label# print('-'*40)# print('label_path,',label_path)new_label_data = []with open(label_path, "r", encoding="utf-8") as f:for line in f:line_tmp = line.strip().split(" ")if len(line_tmp) == 5:if int(line_tmp[0]) == class_id :# print(class_id)# process imagefile_name=label_path[0:label_path.rfind('.', 1)]+'.jpg'if os.path.exists(file_name):# print('draw&ignore ',class_id,' ',file_name)image=cv2.imread(file_name)if image is not None:# class_label = line_tmp[0]x, y, width, height = map(float, line_tmp[1:])x_min = int((x - width/2) * image.shape[1])y_min = int((y - height/2) * image.shape[0])x_max = int((x + width/2) * image.shape[1])y_max = int((y + height/2) * image.shape[0])cv2.rectangle(image, (x_min, y_min), (x_max, y_max), (125, 125, 125), -1)cv2.imwrite(file_name,image)# ignore labelcontinueline_dst = line_tmp[0]+" "+line_tmp[1]+" "+line_tmp[2]+" "+line_tmp[3]+" "+line_tmp[4]+"\n"# print('~~~~liuxia,',int(line_tmp[0]),class_id,line_dst)new_label_data.append(line_dst)# print('new_label_data,',new_label_data)with open(label_path,"w",encoding="utf-8") as f:for line in new_label_data:f.write(line)def getfilelistbyclassid(path,class_id,ignoreid):file_list=[]for folder in os.listdir(path):if ignoreid==1:if str(class_id) in folder:continueelif ignoreid==2:if str(class_id)+"_various" != folder:continuefolder_path=os.path.join(path,folder)for file in os.listdir(folder_path):if file.endswith('.txt'):label_path=os.path.join(folder_path,file)with open(label_path, "r", encoding="utf-8") as f:for line in f:line_tmp = line.strip().split(" ")if len(line_tmp) == 5:if int(line_tmp[0]) == class_id :file_list.append(label_path)breakreturn file_listif __name__=='__main__':id_list = [0,1]path='./images'for class_id in id_list:# print('-'*40)# print('dddd,',class_id)id_path=os.path.join(path,str(class_id))file_num=len([f for f in os.listdir(id_path) if os.path.isfile(os.path.join(id_path, f))])//2if file_num > 1000:# 当前超出限制,把当前之外的抹去(注意当前的还未处理,需要加,2023年05月20日11:44:58)for folder in os.listdir(path):if folder == str(class_id):continuefor file in os.listdir(os.path.join(path,folder)):if file.endswith('.txt'):label_path = os.path.join(os.path.join(path,folder), file)process(label_path,class_id)else:various_id_path=os.path.join(path,str(class_id)+"_various")various_file_num=len([f for f in os.listdir(id_path) if os.path.isfile(os.path.join(id_path, f))])//2file_various_num=various_file_num+file_numif file_various_num < 1000:# 另外的超出的标抹去file_list=getfilelistbyclassid(path,class_id,ignoreid=1)if len(file_list)+file_various_num>1000:random.shuffle(file_list)for i in range(len(file_list)+file_various_num-1000):process(file_list[i],class_id)else:# various超出的标抹去various_file_list=getfilelistbyclassid(path,class_id,ignoreid=2)random.shuffle(various_file_list)for i in range(len(various_file_list)+file_num-1000):process(various_file_list[i],class_id) # 另外的需要全部抹去other_file_list=getfilelistbyclassid(path,class_id,ignoreid=1)random.shuffle(other_file_list)for i in range(len(other_file_list)):process(other_file_list[i],class_id) # 抹去数据过多类的标:# 0,5,10,12,15,20,23# 1、如单类大于1000# 则删除various及其他中的标,同时抹去图像上的区域# 2、如单类小于1000,但是结合various大于1000# 则删除其他中的标,同时抹去图像上的区域# 3、单类+various还是小于1000# 则在其他中找到满足1000,则删除剩余的标,同时抹去图像上的区域
三、模型效果
待补充
相关文章:
复杂数据集,召回、精度等突破方法记录【以电科院过检识别模型为参考】
目录 一、数据分析与数据集构建 二、所有相关的脚本 三、模型效果 一、数据分析与数据集构建 由于电科院数据集有17w-18w张,标签错误的非常多,且漏标非常多,但是所有有效时间只有半个月左右,显卡是M60,训练速度特别…...

那些你不得不会的提高工作效率的软件神器
那些你不得不会的提高工作效率的软件神器 文本编辑器 vscode 跨平台,插件丰富。 code-server vscode服务器版本,可以在浏览器中开发调试代码,尤其适用于windows端开发linux服务器程序。 vim linux/unix/mac终端最强大的文本编辑器。 note…...

【VMware】Ubunt 20.04时间设置
文章目录 设置本地时间 UTC8设置24小时制同步网络时间参考 Talk is cheap, show me the code. 设置本地时间 UTC8 查看当前时区状态 rootnode1:~/k8s# timedatectlLocal time: Sun 2023-05-21 15:24:02 CSTUniversal time: Sun 2023-05-21 07:24:02 UTCRTC time: Sun 2023-05-2…...
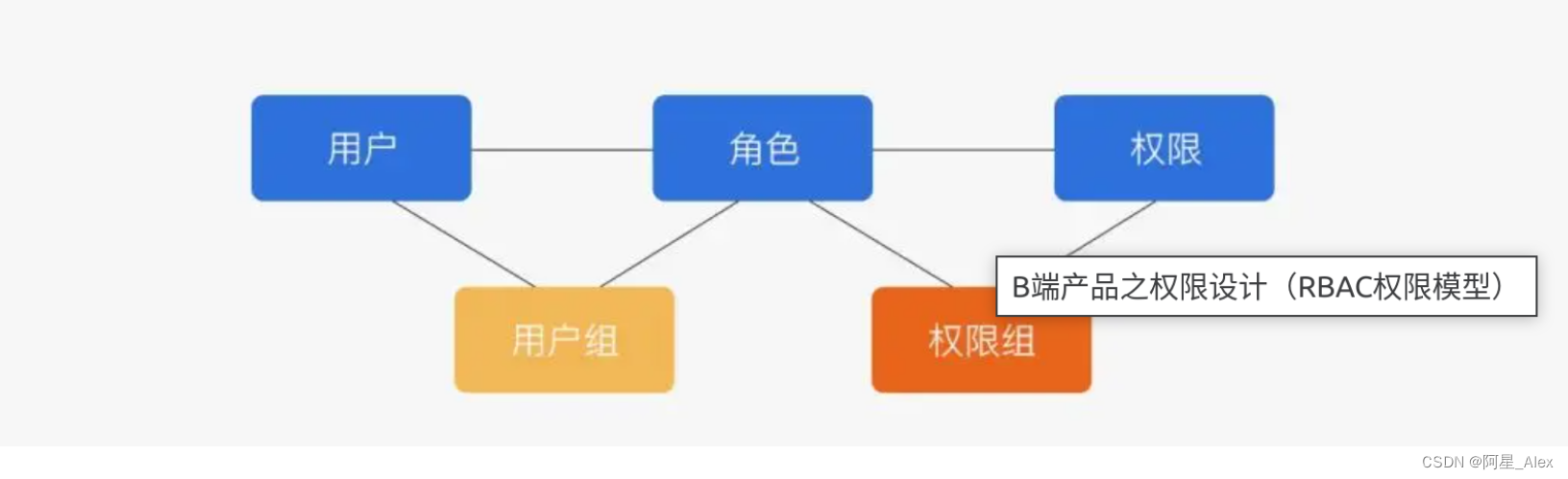
单点登录三:添加RBAC权限校验模型功能理解及实现demo
1、RBAC权限模型 RBAC(Role-Based Access Control)是一种基于角色的访问控制模型,用于管理系统中用户的权限和访问控制。它将用户、角色和权限之间的关系进行了明确的定义,以实现灵活的权限管理和控制。 1.1、RBAC模型主要包括以…...
)
基于用户认证数据构建评估模型预测认证行为风险系统(附源码)
文件说明 datasets // 数据集(训练集、测试集) feature engineering // 特征工程 models // 评估模型 测试环境 Python3.8 任务描述 项目来自系统认证风险预测https://www.datafountain.cn/competitions/537 项目完整源码下载:https://download.csdn.net/download/liu…...

本地训练中文LLaMA模型实战教程,民间羊驼模型,24G显存盘它!
羊驼实战系列索引 博文1:本地部署中文LLaMA模型实战教程,民间羊驼模型 博文2:本地训练中文LLaMA模型实战教程,民间羊驼模型(本博客) 博文3:精调训练中文LLaMA模型实战教程,民间羊驼模型(马上发布) 简介 在学习完上篇【1本地部署中文LLaMA模型实战教程,民间羊驼模…...

快速学Go依赖注入工具wire
Go相对java和C是较新的语言,但也有诸多优秀特性及生态库。本文介绍大多数软件工程中常用的功能:依赖注入。首先介绍什么是依赖注入,go实现库wire与其他语言的差异。然后通过简单示例实现依赖注入,简化代码、提升可读性。 依赖注入…...
流程控制语句)
python入门(4)流程控制语句
1. 条件判断语句 条件控制语句用于根据条件来决定程序的执行路径。在Python中,常见的条件控制语句有以下几种: (1)if语句:用于执行满足条件的代码块。示例代码: age 20 if age > 18:print("成年…...

【进阶】C 语言表驱动法编程原理与实践
数据压倒一切。如果选择了正确的数据结构并把一切组织的井井有条,正确的算法就不言自明。编程的核心是数据结构,而不是算法。——Rob Pike 目录 说明 概念提出 查表方式 直接查找 索引查找 分段查找 实战示例 字符统计 月天校验 名称构造 值名…...
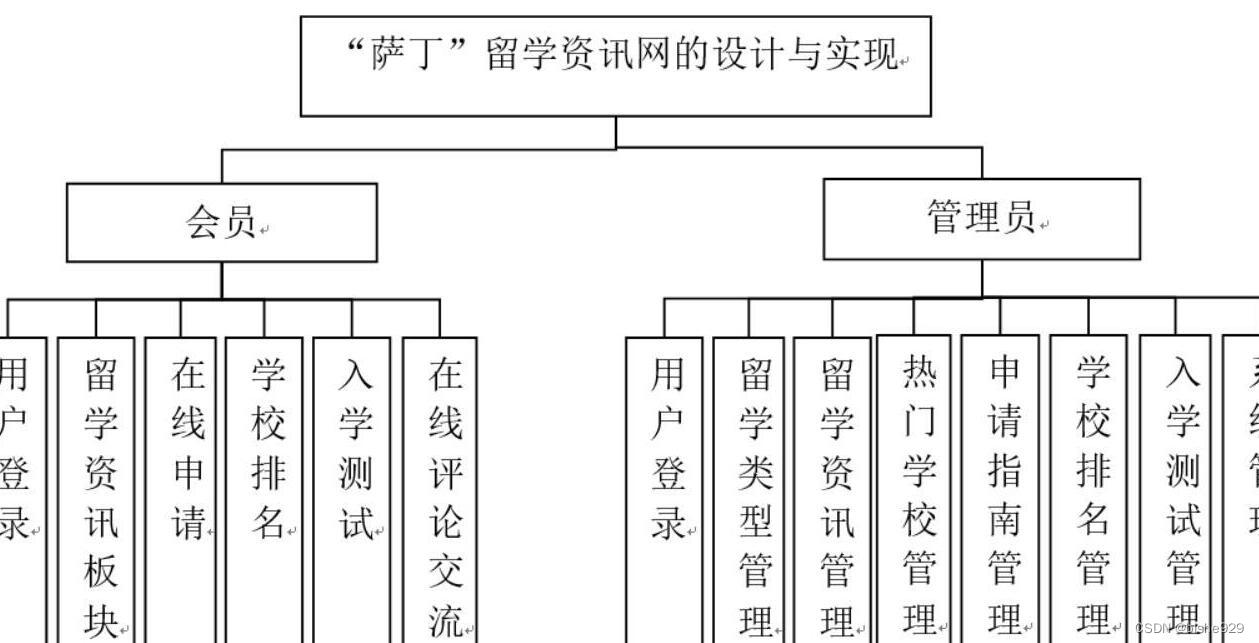
java+springboot留学生新闻资讯网的设计与实现
Spring框架是Java平台的一个开放源代码的Full-stack(全栈)应用程序框架,和控制翻转容器的实现。Spring框架的一些核心功能理论,可以用于所有Java应用,Spring还为Java EE构建的Web应用提供大量的扩展支持。Spring框架没有实现任何的编程模型&a…...

分布式事务与分布式锁区别及概念学习
一、 分布式事务 1.1 背景 传统事务ACID是基于单数据库的本地事务,仅支持单机事务,并不支持跨库事务。但随着微服务架构的普及,业务的分库分表导致一个大型业务系统往往由若干个子系统构成,这些子系统又拥有各自独立的数据库。往往一个业务流程需要由多个子系统共同完成,…...

windows先的conda环境复制到linux环境
如果是迁移的环境一致:同是windows或同是linux直接用这个命令即可: conda create -n new_env_name --clone old_env_path 如果是window的环境迁移到linux这种跨环境就不能用上面的方法,网上这方面的资料也很多,记录一下我的…...

庄懂的TA笔记(十七)<特效:屏幕UV + 屏幕扰动>
庄懂的TA笔记(十七)<特效:屏幕UV 屏幕扰动> 大纲: 目录 庄懂的TA笔记(十七)<特效:屏幕UV 屏幕扰动> 大纲: 正文: 一…...
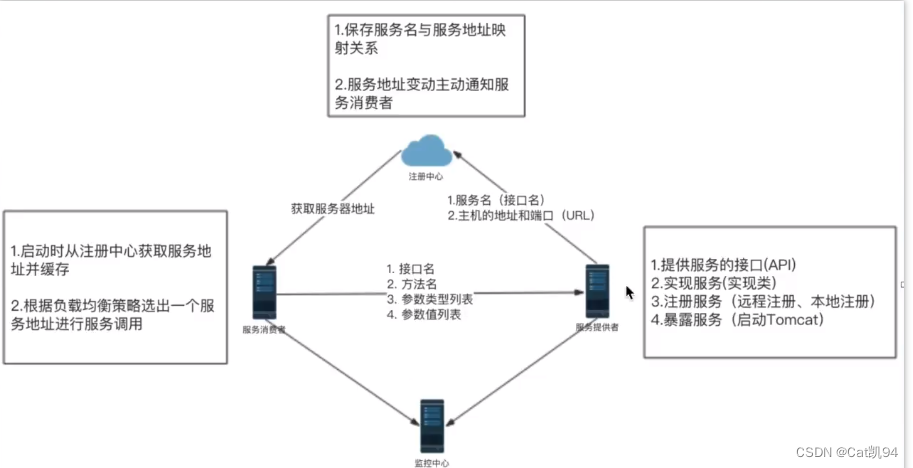
手写简易RPC框架
目录 简介 服务提供者 服务注册:注册中心 HttpServerHandler处理远程调用请求 consumer服务消费端 简介 RPC(Remote Procedure Call)——远程过程调用,它是一种通过网络从远程计算机程序上请求服务, 而不需要了解…...
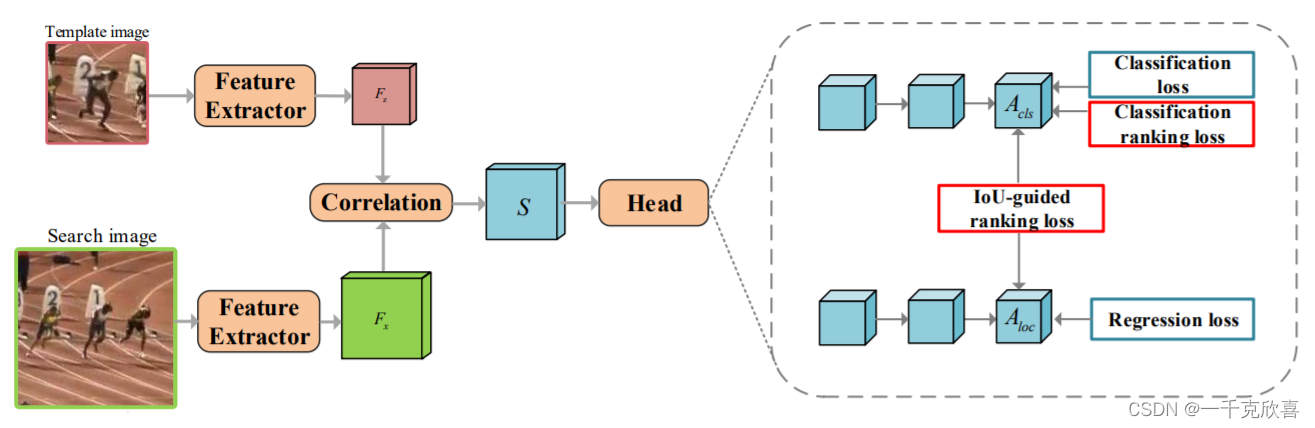
基于孪生网络的目标跟踪
一、目标跟踪 目标跟踪是计算机视觉领域研究的一个热点问题,其利用视频或图像序列的上下文信息,对目标的外观和运动信息进行建模,从而对目标运动状态进行预测并标定目标的位置。具体而言,视觉目标(单目标)…...
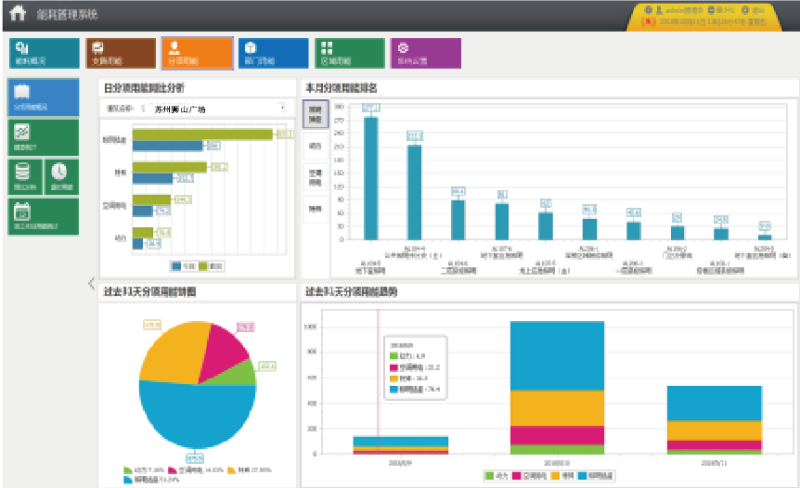
苏州狮山广场能耗管理系统
摘要:随着社会生活水平的提高,经济的繁荣发展,人们对能源的需求逐渐增长,由此带来的能源危机日益严重。商场如何实时的了解、分析和控制商场的能源消耗已成为需要解决的迫在眉睫的难题。传统的能源消耗智能以月/季度/年为周期进行…...
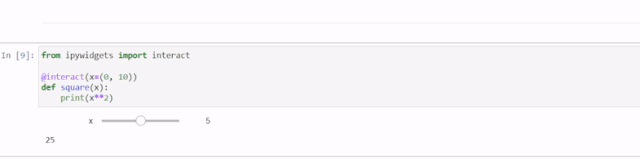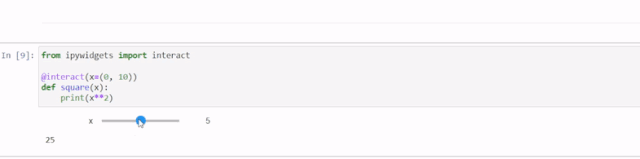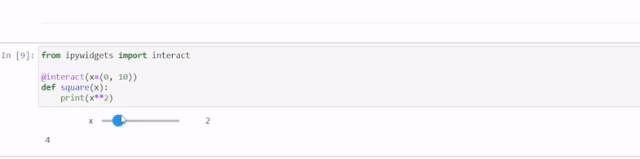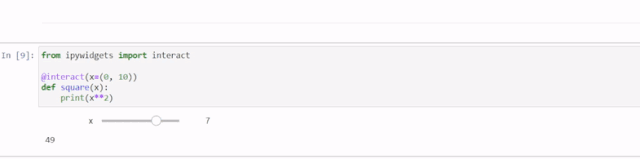
Jupyter Notebook 10个提升体验的高级技巧
Jupyter 笔记本是数据科学家和分析师用于交互式计算、数据可视化和协作的工具。Jupyter 笔记本的基本功能大家都已经很熟悉了,但还有一些鲜为人知的技巧可以大大提高生产力和效率。在这篇文章中,我将介绍10个可以提升体验的高级技巧。 改变注释的颜色 颜…...

CF 751 --B. Divine Array
Black is gifted with a Divine array a consisting of n (1≤n≤2000) integers. Each position in a has an initial value. After shouting a curse over the array, it becomes angry and starts an unstoppable transformation. The transformation consists of infinite…...

Springcloud1--->Eureka注册中心
目录 Eureka原理Eureka入门案例编写EurekaServer将user-service注册到Eureka消费者从Eureka获取服务 Eureka详解基础架构高可用的Eureka Server失效剔除和自我保护 Eureka原理 Eureka:就是服务注册中心(可以是一个集群),对外暴露自…...
面试阿里、字节全都一面挂,被面试官说我的水平还不如应届生
测试员可以先在大厂镀金,以后去中小厂毫无压力,基本不会被卡,事实果真如此吗?但是在我身上却是给了我很大一巴掌... 所谓大厂镀金只是不卡简历而已,如果面试答得稀烂,人家根本不会要你。况且要不是大厂出来…...

Taotoken用量看板如何帮助团队分析并优化大模型API支出
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken用量看板如何帮助团队分析并优化大模型API支出 对于团队技术负责人或项目经理而言,管理大模型API支出并非易事…...

使用taotoken聚合api为智能客服场景提供稳定大模型支持
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用Taotoken聚合API为智能客服场景提供稳定大模型支持 智能客服系统是许多企业服务用户的核心环节,其回答的准确性、及…...

量子机器学习在金融领域的应用:从核心算法到图神经网络实践
1. 量子机器学习在金融领域的应用全景与核心逻辑量子机器学习(QML)这个领域,听起来像是科幻小说里的概念,但过去几年,它已经从理论物理的殿堂,逐步走进了金融工程、风险建模这些非常“接地气”的领域。我接…...
:3个隐藏技能断层导致输出质量长期停滞)
AI视频生成“假熟练”陷阱(83%用户未察觉):3个隐藏技能断层导致输出质量长期停滞
更多请点击: https://kaifayun.com 第一章:AI视频生成工具学习曲线分析 AI视频生成工具的学习曲线呈现出显著的非线性特征:初学者可在数小时内完成基础视频合成,但要稳定产出符合商业标准的高质量内容,通常需跨越模型…...

多保真度机器学习加速卟啉-粘土体系激子动力学模拟
1. 项目概述:当机器学习遇见量子化学,破解卟啉-粘土体系能量转移之谜在人工光合作用和下一代太阳能电池材料的研发前沿,科学家们一直致力于模仿自然界的高效光捕获系统。想象一下,植物和某些细菌中的叶绿素分子,能够近…...

为什么93%的Gemini集成应用在48小时内必须升级?权威发布:3个高危CVE编号+官方回滚方案
更多请点击: https://intelliparadigm.com 第一章:Gemini Bug修复公告 近日,我们在 Gemini 模型推理服务的 v2.4.1 版本中发现一个影响高并发场景下响应一致性的关键缺陷:当连续提交含嵌套 JSON Schema 的结构化请求时࿰…...

漫画阅读新体验:JHenTai如何让你在五大平台无缝畅读E-Hentai内容?
漫画阅读新体验:JHenTai如何让你在五大平台无缝畅读E-Hentai内容? 【免费下载链接】JHenTai A cross-platform manga app made for e-hentai & exhentai by Flutter 项目地址: https://gitcode.com/gh_mirrors/jh/JHenTai 还在为在不同设备上…...

trae之mcp服务初体验 完美实现某视频请求头参数x-ca-sign值逆向
问题提问: 请通过 MCP 服务分析 https://m.yichengwlkj.com/pc?channel=CHANNEL_USK 网站中的 https://api.rrmj.plus/m-station/app/page?position=CHANNEL_USK&pageNum=1&personalRecommend=0 请求链接。该请求的请求头中包含一个名为 x-ca-sign 的参数,该参数的…...

TestDisk PhotoRec:免费开源数据恢复工具的终极完整指南
TestDisk & PhotoRec:免费开源数据恢复工具的终极完整指南 【免费下载链接】testdisk TestDisk & PhotoRec 项目地址: https://gitcode.com/gh_mirrors/te/testdisk 当您不小心删除了重要文件,或者硬盘分区突然消失时,那种恐慌…...

如何用AD8232构建你的第一个专业级心电监测系统:从零到一的完整指南
如何用AD8232构建你的第一个专业级心电监测系统:从零到一的完整指南 【免费下载链接】AD8232_Heart_Rate_Monitor AD8232 Heart Rate Monitor 项目地址: https://gitcode.com/gh_mirrors/ad/AD8232_Heart_Rate_Monitor 想要亲手打造一个专业级的心电监测设备…...