FAT NTFS Ext3文件系统有什么区别
10 年前 FAT 文件系统还是常见的格式,而现在 Windows 上主要是 NTFS,Linux 上主要是Ext3、Ext4 文件系统。关于这块知识,一般资料只会从支持的磁盘大小、数据保护、文件名等各种维度帮你比较,但是最本质的内容却被一笔带过。它们最大的区别是文件系统的实现不同,具体怎么不同?文件系统又有哪些实现?
硬盘分块
在了解文件系统实现之前,我们先来了解下操作系统如何使用硬盘。使用硬盘和使用内存有一个很大的区别,内存可以支持到字节级别的随机存取,而这种情况在硬盘中通常是不支持的。过去的机械硬盘内部是一个柱状结构,有扇区、柱面等。读取硬盘数据要转动物理的磁头,每转动一次磁头时间开销都很大,因此一次只读取一两个字节的数据,
非常不划算。随着 SSD 的出现,机械硬盘开始逐渐消失(还没有完全结束),现在的固态硬盘内部是类似内存的随机存取结构。但是硬盘的读写速度还是远远不及内存。而连续读多个字节的速度,还远不如一次读一个硬盘块的速度。因此,为了提高性能,通常会将物理存储(硬盘)划分成一个个小块,比如每个 4KB。这样做也可以让硬盘的使用看起非常整齐,方便分配和回收空间。况且,数据从磁盘到内存,需要通过电子设备,比如 DMA、总线等,如果一个字节一个字节读取,速度较慢的硬盘就太耗费时间了。过去的机械硬盘的速度可以比内存慢百万倍,现在的固态硬盘,也会慢几十到几百倍。即便是最新的 NvMe 接口的硬盘,和内存相比速度仍然有很大的差距。因此,一次读/写一个块(Block)才是可行的方案。
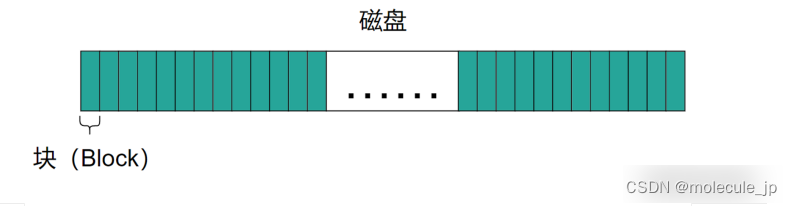
如上图所示,操作系统会将磁盘分成很多相等大小的块。这样做还有一个好处就是如果你知道块的序号,就可以准确地计算出块的物理位置。
文件的描述
我们将硬盘分块后,如何利用上面的硬盘存储文件,就是文件系统(File System)要负责的事情了。当然目录也是一种文件,因此我们先讨论文件如何读写。不同的文件系统利用方式不同,今天会重点讨论 3 种文件系统:
- 早期的 FAT 格式
- 基于 inode 的传统文件系统
- 日志文件系统(如 NTFS, EXT2、3、4)
-
FAT 表
- 早期人们找到了一种方案就是文件分配表(File Allocate Table,FAT)。如下图所示:

一个文件,最基本的就是要描述文件在硬盘中到底对应了哪些块。FAT 表通过一种类似链表的结构描述了文件对应的块。上图中:文件 1 从位置 5 开始,这就代表文件 1 在硬盘上的第 1 个块的序号是 5 的块 。然后位置 5 的值是 2,代表文件 1 的下一个块的是序号 2 的块。顺着这条链路,我们可以找到 5 → 2 → 9 → 14 → 15 → -1。-1 代表结束,所以文件 1 的块是:5,2,9,14,15。同理,文件 2 的块是 3,8,12。FAT 通过一个链表结构解决了文件和物理块映射的问题,算法简单实用,因此得到过广泛的应用,到今天的 Windows/Linux/MacOS 都还支持 FAT 格式的文件系统。FAT 的缺点就是非常占用内存,比如 1T 的硬盘,如果块的大小是 1K,那么就需要 1G 个 FAT 条目。通常一个FAT 条目还会存一些其他信息,需要 2~3 个字节,这就又要占用 2-3G 的内存空间才能用FAT 管理 1T 的硬盘空间。显然这样做是非常浪费的,问题就出在了 FAT 表需要全部维护在内存当中.
索引节点(inode)
为了改进 FAT 的容量限制问题,可以考虑为每个文件增加一个索引节点(inode)。这样,随着虚拟内存的使用,当文件导入内存的时候,先导入索引节点(inode),然后索引节点中有文件的全部信息,包括文件的属性和文件物理块的位置。

如上图,索引节点除了属性和块的位置,还包括了一个指针块的地址。这是为了应对文件非常大的情况。一个大文件,一个索引节点存不下,需要通过指针链接到其他的块去描述文件。这种文件索引节点(inode)的方式,完美地解决了 FAT 的缺陷,一直被沿用至今。FAT 要把所有的块信息都存在内存中,索引节点只需要把用到的文件形成数据结构,而且可以使用虚拟内存分配空间,随着页表置换,这就解决了 FAT 的容量限制问题。
目录的实现
有了文件的描述,接下来我们来思考如何实现目录(Directory)。目录是特殊的文件,所以每个目录都有自己的 inode。目录是文件的集合,所以目录的内容中必须有所有其下文件的inode 指针。
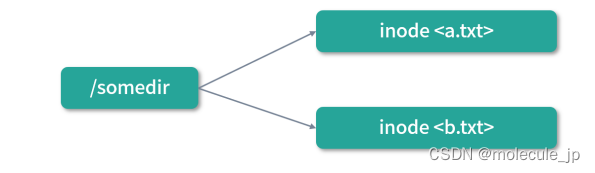
文件名也最好不要放到 inode 中,而是放到文件夹中。这样就可以灵活设置文件的别名,及实现一个文件同时在多个目录下。

如上图,/foo 和 /bar 两个目录中的 b.txt 和 c.txt 其实是一个文件,但是拥有不同的名称。这种形式我们称作“硬链接”,就是多个文件共享 inode。
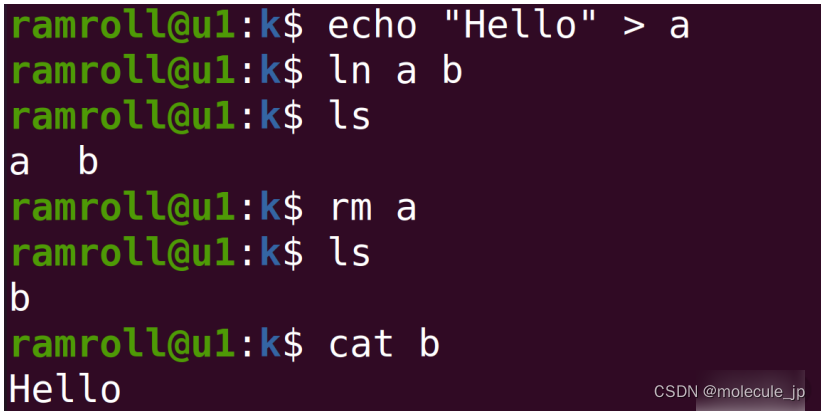
硬链接有一个非常显著的特点,硬链接的双方是平等的。上面的程序我们用ln指令为文件 a 创造了一个硬链接b。如果我们创造完删除了 a,那么 b 也是可以正常工作的。如果要删除掉这个文件的 inode,必须 a,b 同时删除。这里你可以看出 a,b 是平等的。和硬链接相对的是软链接,软链接的原理如下图:
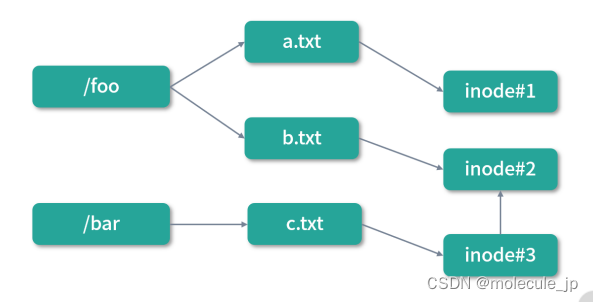
图中c.txt是b.txt的一个软链接,软链接拥有自己的inode,但是文件内容就是一个快捷方式。因此,如果我们删除了b.txt,那么b.txt对应的 inode 也就被删除了。但是c.txt依然存在,只不过指向了一个空地址(访问不到)。如果删除了c.txt,那么不会对b.txt造成任何影响。在 Linux 中可以通过ln -s创造软链接。
ln -s a b # 将b设置为a的软链接(b是a的快捷方式)
以上,我们对文件系统的实现有了一个初步的了解。从整体设计上,本质还是将空间切块,然后划分成目录和文件管理这些分块。读、写文件需要通过 inode 操作磁盘。操作系统提供的是最底层读写分块的操作,抽象成文件就交给文件系统。比如想写入第 10001 个字节,那么会分成这样几个步骤:
1.
修改内存中的数据
2.
计算要写入第几个块
3.
查询 inode 找到真实块的序号
4.
将这个块的数据完整的写入一次磁盘
你可以思考一个问题,如果频繁读写磁盘,上面这个模型会有什么问题?可以把你的思考和想法写在留言区,我们在本讲后面会详细讨论。解决性能和故障:日志文件系统在传统的文件系统实现中,inode 解决了 FAT 容量限制问题,但是随着 CPU、内存、传输线路的速度越来越快,对磁盘读写性能的要求也越来越高。传统的设计,每次写入操作都需要进行一次持久化,所谓“持久化”就是将数据写入到磁盘,这种设计会成为整个应用的瓶颈。因为磁盘速度较慢,内存和 CPU 缓存的速度非常快,如果 CPU 进行高速计算并且频繁写入磁盘,那么就会有大量线程阻塞在等待磁盘 I/O 上。磁盘的瓶颈通常在写入上,因为通常读取数据的时候,会从缓存中读取,不存在太大的瓶颈。加速写入的一种方式,就是利用缓冲区。

上图中所有写操作先存入缓冲区,然后每过一定的秒数,才进行一次持久化。 这种设计,是一个很好的思路,但最大的问题在于容错。 比如上图的步骤 1 或者步骤 2 只执行了一半,如何恢复?如果步骤 2 只写入了一半,那么数据就写坏了。如果步骤 1 只写入了一半,那么数据就丢失了。无论出现哪种问题,都不太好处理。更何况写操作和写操作之间还有一致性问题,比如说一次删除 inode 的操作后又发生了写入……解决上述问题的一个非常好的方案就是利用日志。假设 A 是文件中某个位置的数据,比起传统的方案我们反复擦写 A,日志会帮助我们把 A 的所有变更记录下来,比如:
A=1
A=2
A=3
上面 A 写入了 3 次,因此有 3 条日志。日志文件系统文件中存储的就是像上面那样的日志,而不是文件真实的内容。当用户读取文件的时候,文件内容会在内存中还原,所以内存中 A 的值是 3,但实际磁盘上有 3 条记录。从性能上分析,如果日志造成了 3 倍的数据冗余,那么读取的速度并不会真的慢三倍。因为我们多数时候是从内存和 CPU 缓存中读取数据。而写入的时候,因为采用日志的形式,可以考虑下图这种方式,在内存缓冲区中积累一批日志才写入一次磁盘。

上图这种设计可以让写入变得非常快速,多数时间都是写内存,最后写一次磁盘。而上图这样的设计成不成立,核心在能不能解决容灾问题。你可以思考一下这个问题——丢失一批日志和丢失一批数据的差别大不大。其实它们之间最大的差别在于,如果丢失一批日志,只不过丢失了近期的变更;但如果丢失一批数据,那么就可能造成永久伤害。举个例子,比如说你把最近一天的订单数据弄乱了,你可以通过第三方支付平台的交易流水、系统的支付记录等帮助用户恢复数据,还可以通过订单关联的用户信息查询具体是哪些用户的订单出了问题。但是如果你随机删了一部分订单, 那问题就麻烦了。你要去第三发支付平台调出所有流水,用大数据引擎进行分析和计算。为了进一步避免损失,一种可行的方案就是创建还原点(Checkpoint),比如说系统把最近30s 的日志都写入一个区域中。下一个 30s 的日志,写入下一个区域中。每个区域,我们称作一个还原点。创建还原点的时候,我们将还原点涂成红色,写入完成将还原点涂成绿色。
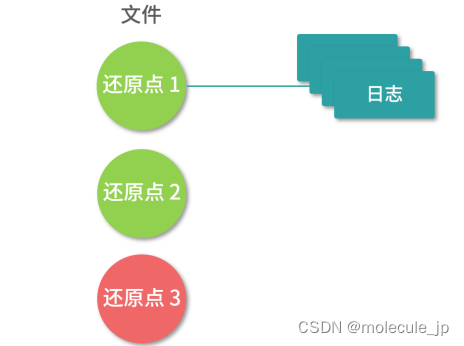
如上图,当日志文件系统写入磁盘的时候,每隔一段时间就会把这段时间内的所有日志写入一个或几个连续的磁盘块,我们称为还原点(Checkpoint)。操作系统读入文件的时候,依次读入还原点的数据,如果是绿色,那么就应用这些日志,如果是红色,就丢弃。所以上图中还原点 3 的数据是不完整的,这个时候会丢失不到 30s 的数据。如果将还原点的间隔变小,就可以控制风险的粒度。另外,我们还可以对还原点 3 的数据进行深度恢复,这里可以有人工分析,也可以通过一些更加复杂的算法去恢复。
总结
3 种文件系统的实现。FAT 的设计简单高效,如果你要自己管理一定的空间,可以优先考虑这种设计。inode 的设计在内存中创造了一棵树状结构,对文件、目录进行管理,并且索引到磁盘中的数据。这是一种经典的数据结构,这种思路会被数据库设计、网络资源管理、缓存设计反复利用。日志文件系统——日志结构简单、容易存储、按时间容易分块,这样的设计非常适合缓冲、批量写入和故障恢复。现在我们很多分布式系统的设计也是基于日志,比如 MySQL 同步数据用 binlog,Redis 的AOF,著名的分布式一致性算法 Paxos ,因此 Zookeeper 内部也在通过实现日志的一致性来实现分布式一致性。
FAT、NTFS 和 Ext3有什么区别?
FAT 通过内存中一个类似链表的结构,实现对文件的管理。NTFS 和 Ext3 是日志文件系统,它们和 FAT 最大的区别在于写入到磁盘中的是日志,而不是数据。日志文件系统会先把日志写入到内存中一个高速缓冲区,定期写入到磁盘。日志写入是追加式的,不用考虑数据的覆盖。一段时间内的日志内容,会形成还原点。这种设计大大提高了性能,当然也会有一定的数据冗余。
相关文章:
FAT NTFS Ext3文件系统有什么区别
10 年前 FAT 文件系统还是常见的格式,而现在 Windows 上主要是 NTFS,Linux 上主要是Ext3、Ext4 文件系统。关于这块知识,一般资料只会从支持的磁盘大小、数据保护、文件名等各种维度帮你比较,但是最本质的内容却被一笔带过。它们最…...

信息收集思路
1、开发者注释 在网站前端代码中遗留的开发者注释 其中可能包含某些关键信息 💡 使用F12 、CtrlU 、view-source: 查看前端源码 3、Robots文件 爬虫协议,网站根目录存在的robots.txt文件,用于告知搜索引擎或爬虫哪些路径和页面不…...

Tauri应用开发(二):创建第一个Tauri应用
创建tauri应用 推荐参考官方文档:https://tauri.app/v1/guides/ 创建命令: npm create tauri-applatest💡注意:请确保Node.js和Rust已经正确安装 在创建过程中,需要根据提示选择配置项。 主要配置有: 项目…...

自信裸辞:一晃 ,失业都3个月了.....
最近,找了很多软测行业的朋友聊天、吃饭 ,了解了一些很意外的现状 。 我一直觉得他们技术非常不错,也走的测开/管理的路径;二三月份裸辞的,然后一直在找工作,现在还没找到工作 。 经过我的分析࿰…...

Python3 输入和输出
在Python 3中,你可以使用内置的函数来进行输入和输出操作。 输入(Input): 要从用户那里获取输入,可以使用input()函数。input()函数会等待用户输入,并返回一个字符串。你可以将输入存储在一个变量中&#…...
Mybatis Plus 使用@TableLogic实现逻辑删除
文章目录 步骤1:修改数据库表添加deleted列步骤2:实体类添加属性步骤3:运行删除方法知识点1:TableLogic 接下来要讲解是删除中比较重要的一个操作,逻辑删除,先来分析下问题: 这是一个员工和其所签的合同表,关系是一个员工可以签多…...

2023/5/23总结
super关键字 super关键字的用法和this 关键字的用法相似 this:代表本类对象的引用(this关键字指向调用该方法的对象一般我们是在当前类中使用this关键字,所以我们常说this代表本类对象的引用)super:代表父类存储空间的标识(可以理解为父类对象…...
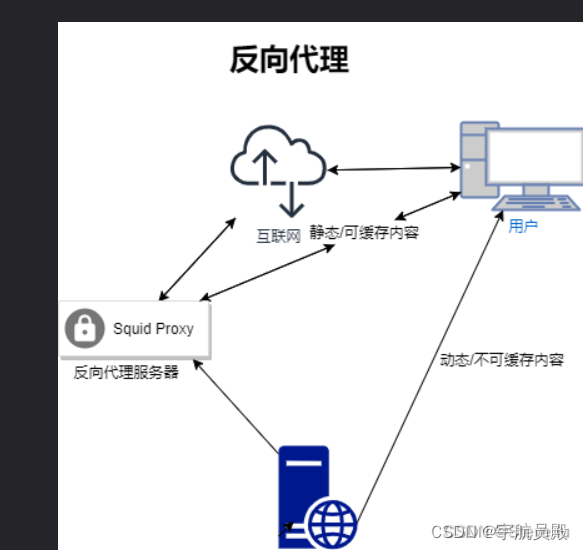
Squid代理服务器应用
在web架构中,用户一般进入负载均衡层,通过调度来访问web应用层,但是如果访问量太大,并发量较高,web应用层会吃不消,我们把静态资源、经常要访问的资源放入缓存,用户直接访问缓存层,加…...

网络编程中的sockfd是什么?
2023年5月22日,周一早上: 今天早上学习网络编程时遇到了sockfd这个变量,于是学习了一下,顺便写篇博客来记录自己的学习成功。 sockfd是什么意思? "sock"是socket的缩写。"fd"则是file descripto…...
如何利用Citespace和vosviewer既快又好地写出高质量的论文及快速锁定热点和重点文献进行可视化分析?
基于Citespace和vosviewer文献计量学可视化SCI论文高效写作方法 CiteSpace是什么? 简单来说,它一款通过将国内外文献进行可视化分析来帮助你了解一门学科前世今生的软件。 面对成千上万篇的文献,怎样才能快速锁定自己最感兴趣的主题及科学…...
(学习日记)AD学习 #1
写在前面: 由于时间的不足与学习的碎片化,写博客变得有些奢侈。 但是对于记录学习(忘了以后能快速复习)的渴望一天天变得强烈。 既然如此 不如以天为单位,以时间为顺序,仅仅将博客当做一个知识学习的目录&a…...
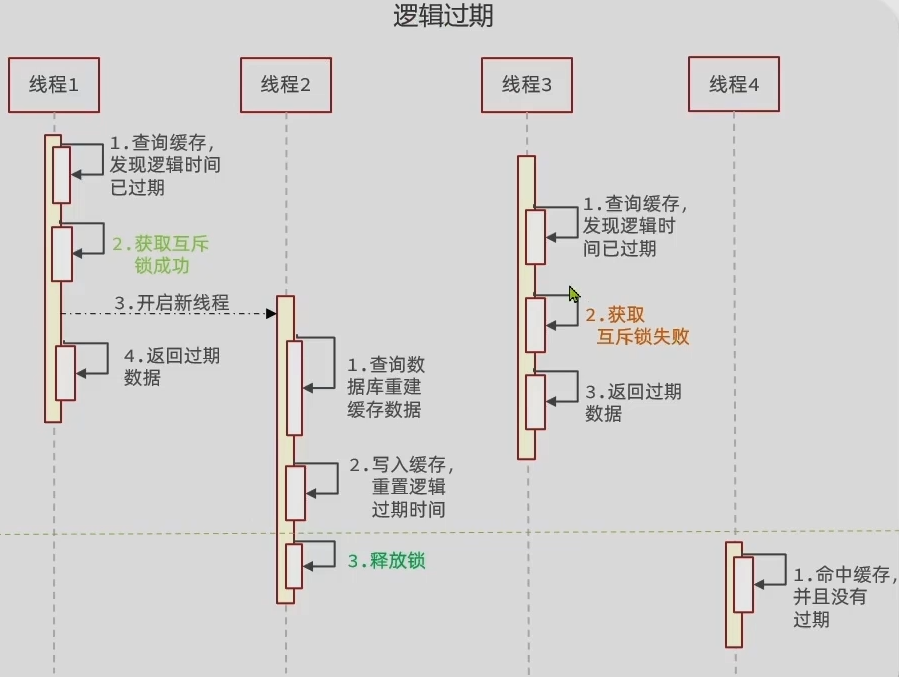
缓存存在的问题
文章目录 缓存问题缓存穿透引入解决方案 缓存雪崩缓存击穿 缓存问题 使用缓存时常见的问题主要分为三个:缓存穿透 、缓存雪崩、缓存击穿。 下面对其进行一一学习 缓存穿透 引入 定义:缓存穿透是指客户端请求的数据在缓存中和数据库中都不存在&#…...

ChatGPT 的 AskYourPDF 插件所需链接如何获取?
一、背景 目前 ChatGPT 主要有两款 PDF 对话插件,一个是 AskYourPDF 一个是 ChatWithPDF(需 ChatGPT Plus),他们都可以实现给一个公共的PDF 链接,然后进行持续对话,对读论文,阅读 PDF 格式的文…...
基于自营配送模式的车辆路径规划设计与实现_kaic
摘要 近年来,随着我国消费水平逐渐提升,消费者在网上购物的频率也越来越高,电商发展速度迅猛,加大了物流配送的压力,促使物流企业以更大的运力,更短的时间将货物送达。在货品的运输过程中,成本居…...
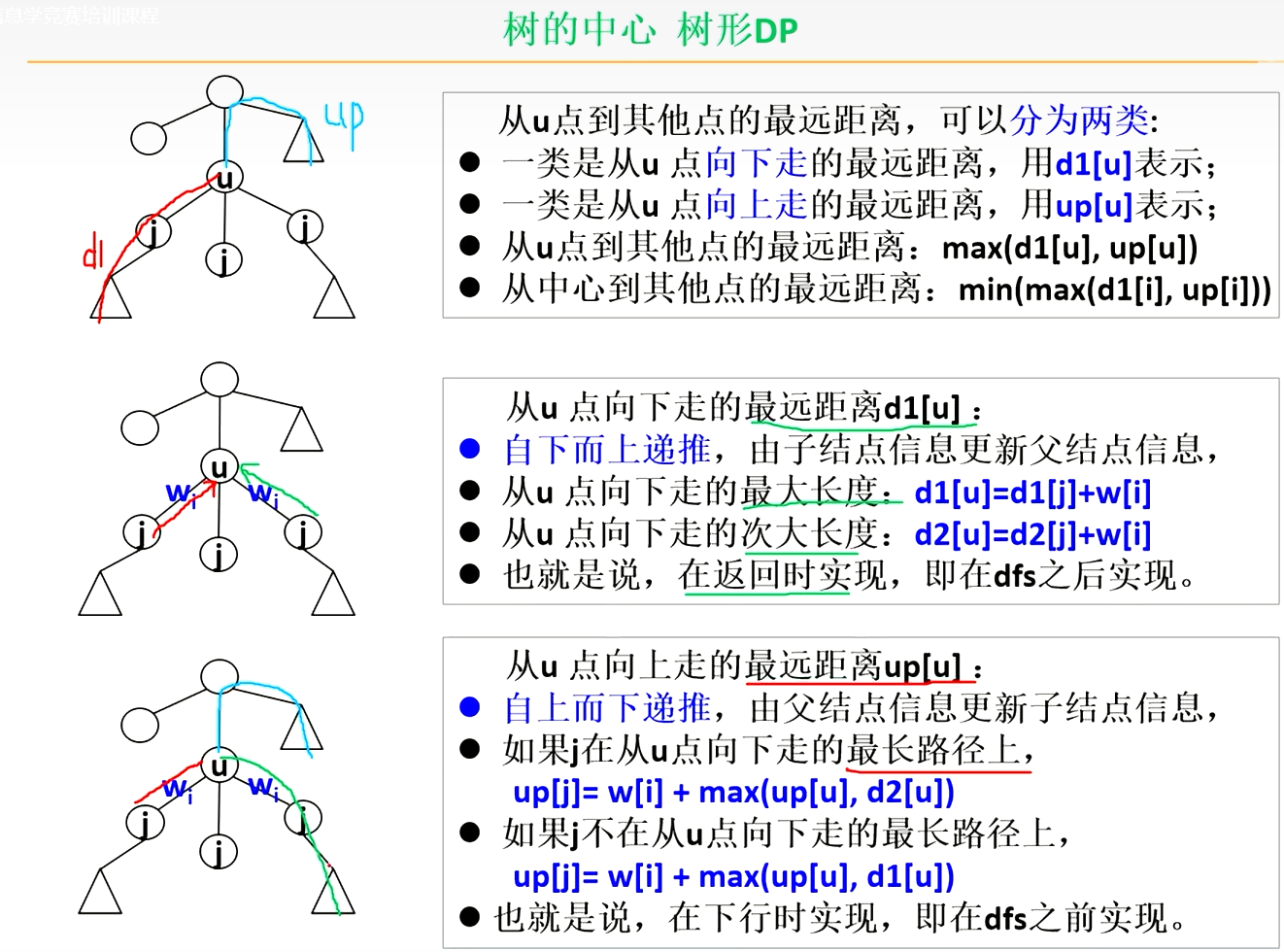
动态规划-树形DP
树的重心 题目 链接:https://www.acwing.com/problem/content/848/ 给定一颗树,树中包含 n n n 个结点(编号 1 ∼ n 1 \sim n 1∼n)和 n − 1 n-1 n−1 条无向边。 请你找到树的重心,并输出将重心删除后&#x…...
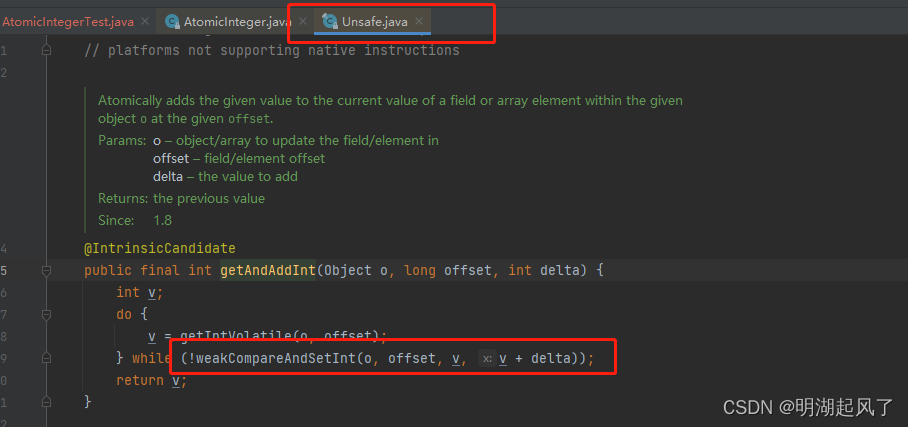
多线程基础(二)CAS无锁优化/自旋锁/乐观锁、ABA问题
CAS (Compare And Set)比较并替换 上篇文章的锁问题解决,可以使用更高效的方法,使用AtomXXX类,AtomXXX类本身方法都是原子性的,但不能保证多个方法连续调用是原于性的。 import java.util.ArrayList; imp…...

记ABAC的落地实践
为什么使用ABAC 一般提到授权,我们就会想到角色(role)。什么样的用户拥有什么样的角色可以怎么操作什么样的资源,这是我们普遍使用的权限系统的模型。这里的角色实质上是包含了一组用户操作资源的规则集合。一旦角色被创建&#…...

【C++】C++11线程库 和 C++IO流
春风若有怜花意,可否许我再少年。 文章目录 一、C11线程库1.thread类介绍2.mutex互斥锁 和 CAS原子操作(compare and set)3.lock_guard和unique_lock4.两个线程交替打印,一个打印奇数,一个打印偶数(线程同步…...

cpp11实现线程池(六)——线程池任务返回值类型Result实现
介绍 提交任务函数submitTask中返回的Result类型应该是用Result类包装当前的task,因为出函数之后task即如下形式:return Result(task); Result和Task都要互相持有对方的指针,Task要将任务执行结果通过Result::setVal(run()) 调用传给其对应…...
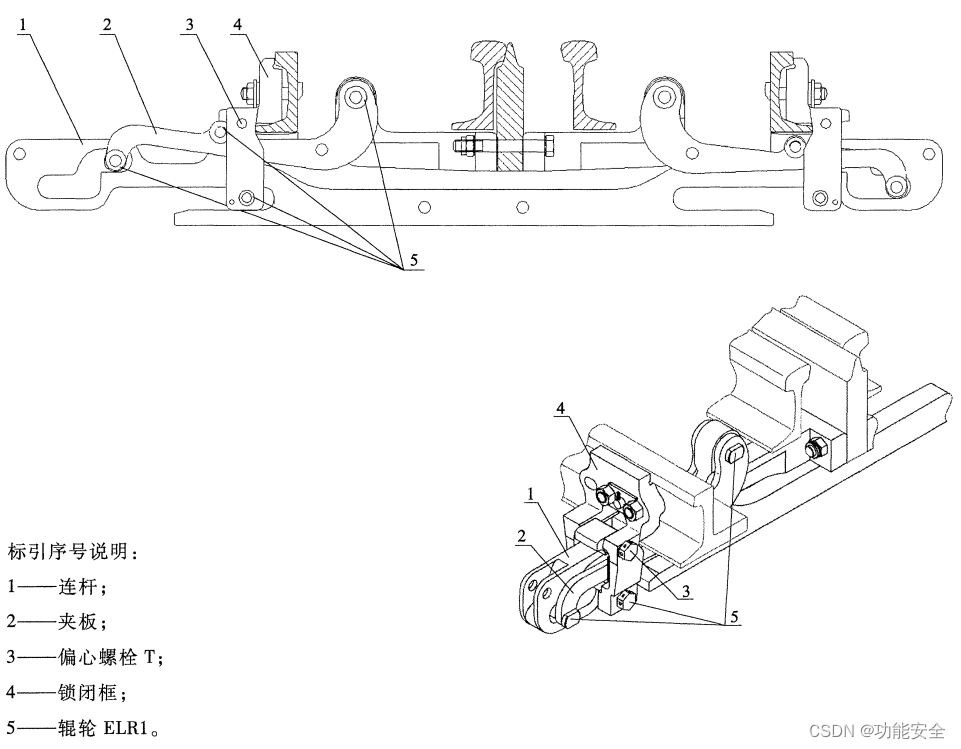
道岔外锁闭装置介绍
简述 道岔外锁闭装置是一种能可靠地锁闭尖轨和基本轨的器械。它能有效地克服尖轨在密贴时的转换阻力,即使连接杆折断,外锁闭装置仍在起着锁闭作用。外锁闭能够隔离列车通过时对转换设备的振动和冲击,提高转换设备寿命和可靠性。 产品分类 …...

LSLib:游戏资源逆向工程的架构级解决方案
LSLib:游戏资源逆向工程的架构级解决方案 【免费下载链接】lslib Tools for manipulating Divinity Original Sin and Baldurs Gate 3 files 项目地址: https://gitcode.com/gh_mirrors/ls/lslib 面对《神界:原罪》和《博德之门3》等CRPG游戏复杂…...
)
DeepSeek安全认证落地实战手册(含ISO 27001+AI治理双认证模板)
更多请点击: https://codechina.net 第一章:DeepSeek安全合规认证全景概览 DeepSeek系列大模型在企业级落地过程中,安全与合规能力是核心信任基石。其认证体系覆盖全球主流监管框架与行业标准,形成多维度、全生命周期的保障网络。…...

如何快速释放微信空间:CleanMyWechat终极清理指南
如何快速释放微信空间:CleanMyWechat终极清理指南 【免费下载链接】CleanMyWechat 自动删除 PC 端微信缓存数据,包括从所有聊天中自动下载的大量文件、视频、图片等数据内容,解放你的空间。 项目地址: https://gitcode.com/gh_mirrors/cl/C…...

如何快速解决Windows依赖问题:终极系统优化指南
如何快速解决Windows依赖问题:终极系统优化指南 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 你是否曾经遇到过打开心爱的游戏时突然弹出"缺少…...
)
DeepSeek日志异常检测实战:基于时序大模型的动态基线算法(已通过金融级等保三级日志审计验证)
更多请点击: https://intelliparadigm.com 第一章:DeepSeek日志分析方案概述 DeepSeek系列大模型在推理与训练过程中会产生海量结构化与半结构化日志,涵盖请求元数据、token级耗时、KV缓存命中率、显存占用、错误堆栈等关键维度。本方案聚焦…...

Windows HEIC缩略图终极指南:5分钟解决iPhone照片预览难题
Windows HEIC缩略图终极指南:5分钟解决iPhone照片预览难题 【免费下载链接】windows-heic-thumbnails Enable Windows Explorer to display thumbnails for HEIC/HEIF files 项目地址: https://gitcode.com/gh_mirrors/wi/windows-heic-thumbnails 你是否经常…...
)
macOS上VirtualBox虚拟机卡顿?试试这个‘丝滑’增强包(含CentOS 7依赖安装避坑)
macOS上VirtualBox虚拟机卡顿终极优化指南:从依赖安装到性能调优刚在Mac上装好VirtualBox虚拟机,满心欢喜准备大展拳脚,却发现鼠标移动像在糖浆里游泳?窗口拖拽时仿佛在跟系统拔河?这种体验简直让人想摔键盘。别急着放…...

GoldenCheetah:从数据迷雾到训练洞察的专业运动分析平台
GoldenCheetah:从数据迷雾到训练洞察的专业运动分析平台 【免费下载链接】GoldenCheetah Performance Software for Cyclists, Runners, Triathletes and Coaches 项目地址: https://gitcode.com/gh_mirrors/go/GoldenCheetah 你是否曾面对一堆运动数据却不知…...

韭菜盒子:在VSCode中打造你的专属投资工作台,让代码与行情无缝融合
韭菜盒子:在VSCode中打造你的专属投资工作台,让代码与行情无缝融合 【免费下载链接】leek-fund :chart_with_upwards_trend: 韭菜盒子VSCode插件,可以看股票、基金、期货等实时数据。 LeekFund turns your VS Code and Cursor into a real-ti…...

告别卡顿与黑边:D2DX让你的《暗黑破坏神2》在现代PC上完美重生
告别卡顿与黑边:D2DX让你的《暗黑破坏神2》在现代PC上完美重生 【免费下载链接】d2dx D2DX is a complete solution to make Diablo II run well on modern PCs, with high fps and better resolutions. 项目地址: https://gitcode.com/gh_mirrors/d2/d2dx 你…...