hadoop环境新手安装教程
1、资源准备:
(1)jdk安装包:我的是1.8.0_202
(2)hadoop安装包:我的是hadoop-3.3.1
 注意这里不要下载成下面这个安装包了,我就一开始下载错了
注意这里不要下载成下面这个安装包了,我就一开始下载错了
错误示例:![]()
2、主机网络相关参数准备
这里主要涉及hostname改写、hosts修改和ip地址改写
(1)修改hostname。这里我用了3台虚拟机,1台改为master,另外2台分别改为node1和node2
cd /etc/ // 进入配置目录vi hostname // 编程hostname 配置文件![]()
(2)修改hosts。这里根据每台虚机的ip选择相应的hostname就行
vi /etc/hosts (3)IP地址改写,这里需要修改虚机的配置,选择NAT模式,DHCP选择想要的网段就行。
(3)IP地址改写,这里需要修改虚机的配置,选择NAT模式,DHCP选择想要的网段就行。

注意:以上的操作需要在每台虚机上分别执行 !!!
3、配置ssh免密登陆
这一步在master主机上操作,一直按回车:
ssh-keygen 会生成以下4个文件:
![]()
之后使用以下命令将密钥分发到node1和node2:
ssh-copy-id root@node1
ssh-copy-id root@localhost
ssh-copy-id root@node2成功后就应该能免密登陆node1和node2了:
![]()
4、配置java环境
我将jdk安装包和hadoop安装包都放在master主机/opt目录下了,同时新建一个bigdata目录:

(1)首先需要解压jdk安装包,并将解压后的文件夹放进bigdata目录:
tar -zxvf jdk-8u202-linux-x64.tar.gz
mv jdk1.8.0_202/ bigdata/(2)然后配置java环境变量:
vi /etc/profile 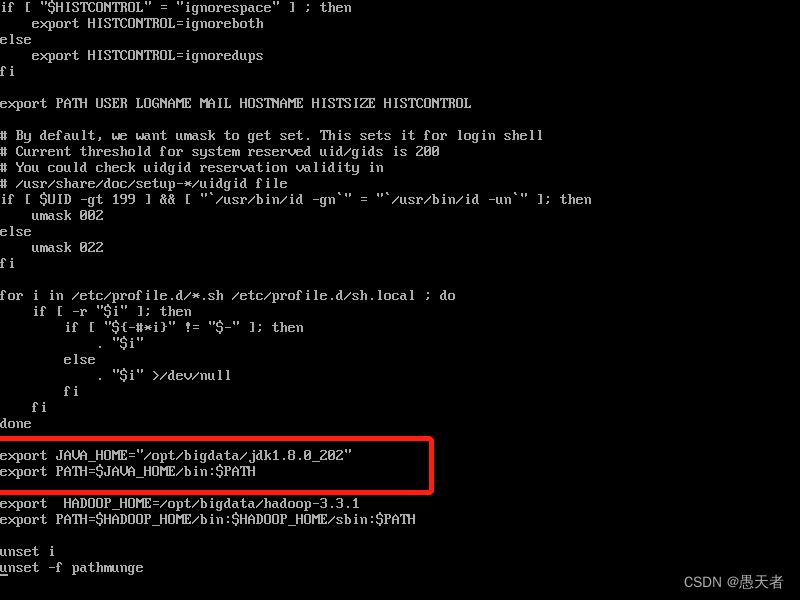
配置完生效并验证是否成功:
source /etc/profile
java -version #验证环境是否配置成功 
5、安装hadoop
同样是先解压然后移动到bigdata目录:
tar -zxvf hadoop-3.1.1.tar.gz
mv hadoop-3.1.1 bigdata/接着同样是配置环境变量:
vi /etc/profile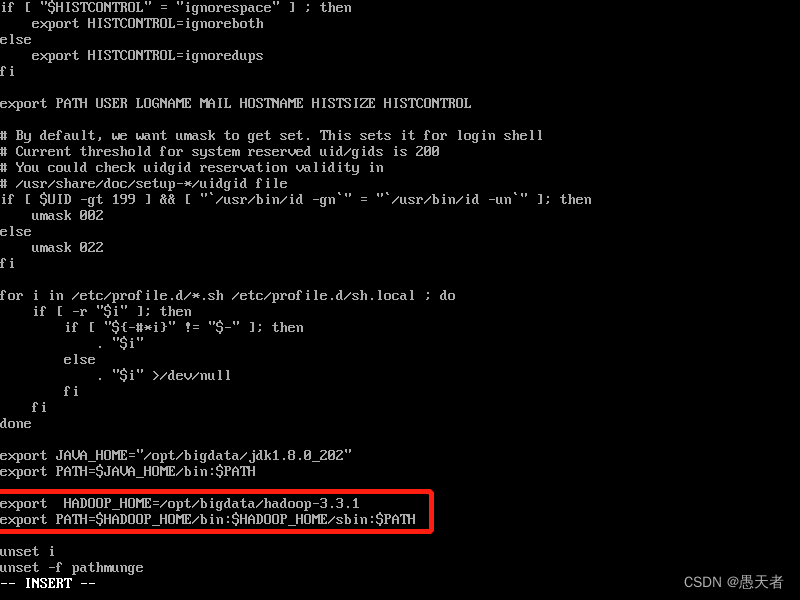
配置完生效并验证是否成功:
source profile
hadoop verison 
6、配置hadoop
这一步需要对hadoop下的 core-site.xml、hadoop-env.sh、hdfs-site.xml、mapred-site.xml、yarn-site.xml等文件进行配置。
首先进入存放文件的目录:
cd /opt/bigdata/hadoop-3.3.1/etc/hadoop/ 
(1)配置hadoop-env.sh
vi命令打开文件,输入 :/export JAVA_HOME 查找需要修改的地方并修改(注意将版本号换成自己的):
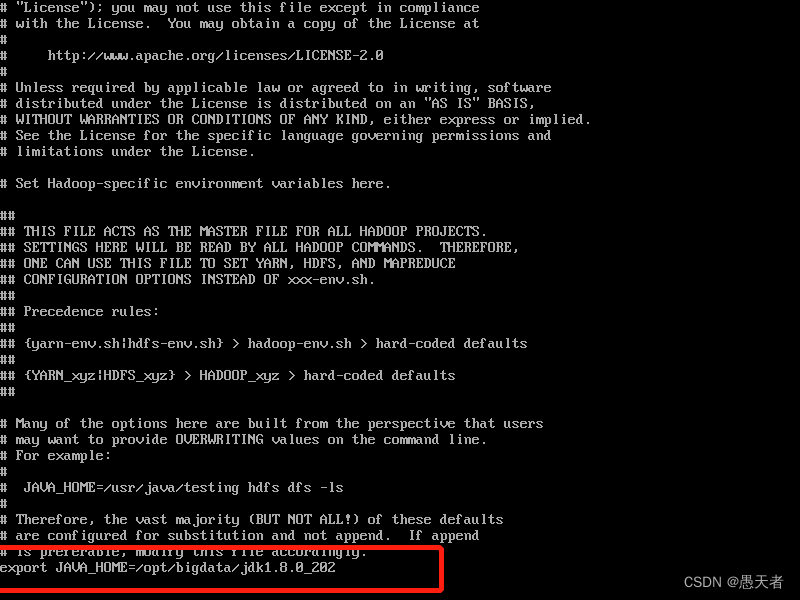
(2)配置 core-site.xml
vi命令打开文件,找到一对尖括号框起来的configuration位置,插入(注意将版本号换成自己的):
<configuration><property><name>fs.default.name</name><value>localhost:9000</value></property><property><name>hadoop.temp.dir</name><value>/opt/bigdata/hadoop-3.3.1/temp</value></property>
</configuration>修改成如下:

(3)配置hdfs-site.xml
vi打开文件同样在configuration处插入(注意将版本号换成自己的):
<configuration><property><name>dfs.replication</name><value>2</value></property><property><name>dfs.datanode.name.dir</name><value>/opt/bigdata/hadoop-3.3.1/hdfs/name</value></property><property><name>dfs.datanode.data.dir</name><value>/opt/bigdata/hadoop-3.3.1/hdfs/data</value></property><property><name>dfs.namenode.secondary.http-address</name><value>node1:9001</value></property><property><name>dfs.http.address</name><value>0.0.0.0:50070</value></property>
</configuration>(4)配置mapred-site.xml
同样的操作:
<configuration><property><name>mapred.job.tracker.http.address</name><value>0.0.0.0:50030</value></property><property><name>mapred.task.tracker.http.address</name><value>0.0.0.0:50060</value></property><property><name>mapreduce.framework.name</name><value>yarn</value></property>
<property><name>mapreduce.application.classpath</name><value>/opt/bigdata/hadoop-3.3.1/etc/hadoop,/opt/bigdata/hadoop-3.3.1/share/hadoop/common/*,/opt/bigdata/hadoop-3.3.1/share/hadoop/common/lib/*,/opt/bigdata/hadoop-3.3.1/share/hadoop/hdfs/*,/opt/bigdata/hadoop-3.3.1/share/hadoop/hdfs/lib/*,/opt/bigdata/hadoop-3.3.1/share/hadoop/mapreduce/*,/opt/bigdata/hadoop-3.3.1/share/hadoop/mapreduce/lib/*,/opt/bigdata/hadoop-3.3.1/share/hadoop/yarn/*,/opt/bigdata/hadoop-3.3.1/share/hadoop/yarn/lib/*
</value>
</property>
</configuration>
(5)配置下yarn-site.xml
<property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value>
</property>
<property><name>yarn.resourcemanager.webapp.address</name><value>master:8099</value>
</property>(6)配置workers
在当前目录修改workers文件:
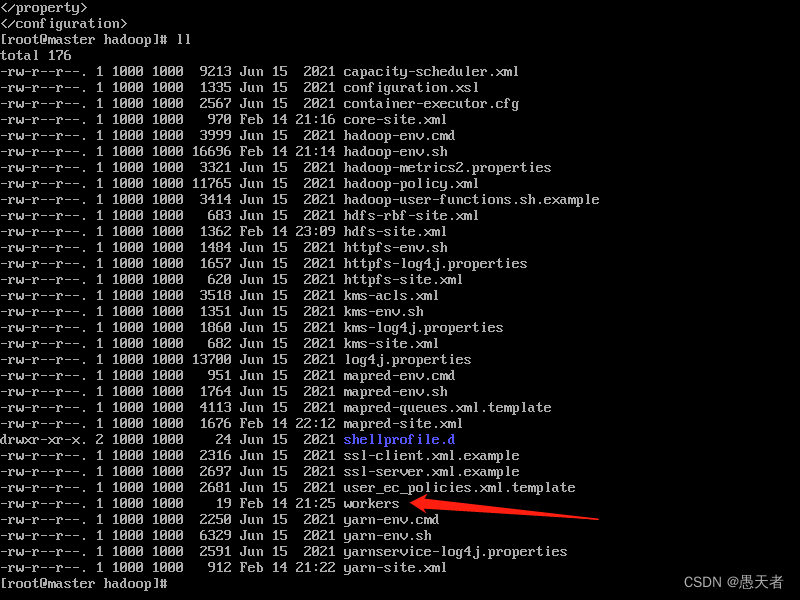
最后只有master、node1和node2:

7、环境的配置已经改完了。接着还需要修改一下启动脚本的参数:
进入到sbin目录:
cd /opt/bigdata/hadoop-3.3.1/sbin(1) 在start-dfs.sh,stop-dfs.sh两个文件顶部添加以下参数:
#!/usr/bin/env bash
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
(2)start-yarn.sh,stop-yarn.sh顶部也需添加以下参数:
#!/usr/bin/env bash
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
至此,所有的配置都已经做完了,现在需要将配置文件分发到两个子节点去(子节点没有bigdata文件夹需要新建一个):
scp -r /opt/bigdata/hadoop-3.3.1 node1:/opt/bigdata
scp -r /opt/bigdata/hadoop-3.3.1 node2:/opt/bigdata接着分别在两个子节点上执行下面命令生效配置:
source /etc/profile
source ~/.bashrc最后就可以开始准备启动hadoop集群了。
(1)第一次启动需要初始化hdfs,在 /opt/bigdata/hadoop-3.3.1/bin目录下执行:
./hdfs namenode -format出现如下语句表示初始化成功:
![]()
(2)进入/opt/bigdata/hadoop-3.3.1/sbin目录执行最后的集群启动命令:
./start-all.sh 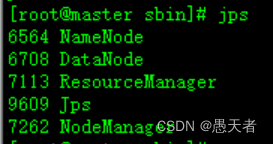

参考:Hadoop 平台搭建完整步骤
相关文章:
hadoop环境新手安装教程
1、资源准备: (1)jdk安装包:我的是1.8.0_202 (2)hadoop安装包:我的是hadoop-3.3.1 注意这里不要下载成下面这个安装包了,我就一开始下载错了 错误示例: 2、主机网络相…...
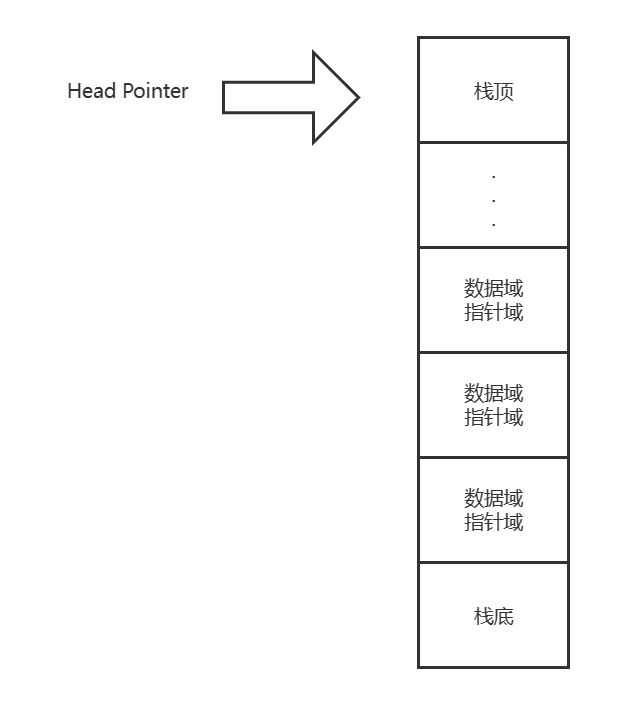
数据结构与算法基础-学习-11-线性表之链栈的初始化、判断非空、压栈、获取栈长度、弹栈、获取栈顶元素
一、个人理解链栈相较于顺序栈不存在上溢(数据满)的情况,除非内存不足,但存储密度会低于顺序栈,因为会多存一个指针域,其他逻辑和顺序表一致。总结如下:头指针指向栈顶。链栈没有头节点直接就是…...

Hive内置函数
文章目录Hive内置函数字符串函数时间类型函数数学函数集合函数条件函数类型转换函数数据脱敏函数其他函数用户自定义函数Hive内置函数 查询内置函数用法: DESCRIBE FUNCTION EXTENDED 函数名;字符串函数 字符串连接函数:concat带分隔符字符串连接函数…...
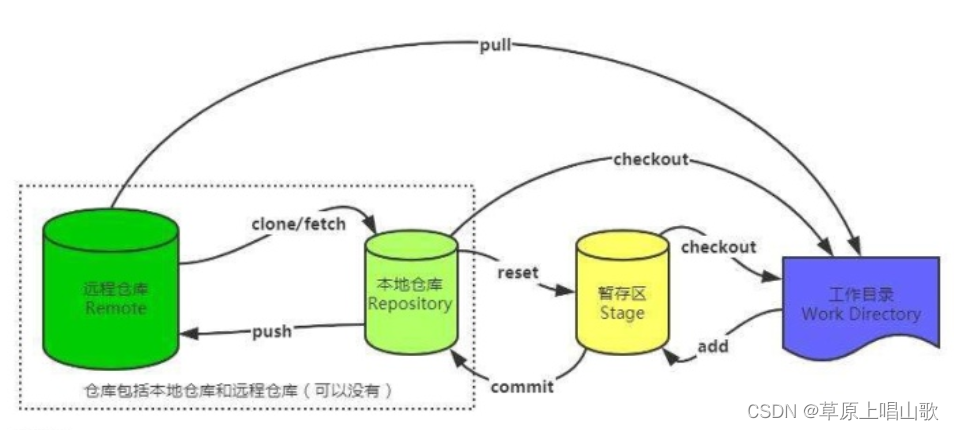
Git如何快速入门
什么是Git?我们开发的项目,也需要一个合适的版本控制系统来协助我们更好地管理版本迭代,而Git正是因此而诞生的(有关Git的历史,这里就不多做阐述了,感兴趣的小伙伴可以自行了解,是一位顶级大佬在…...
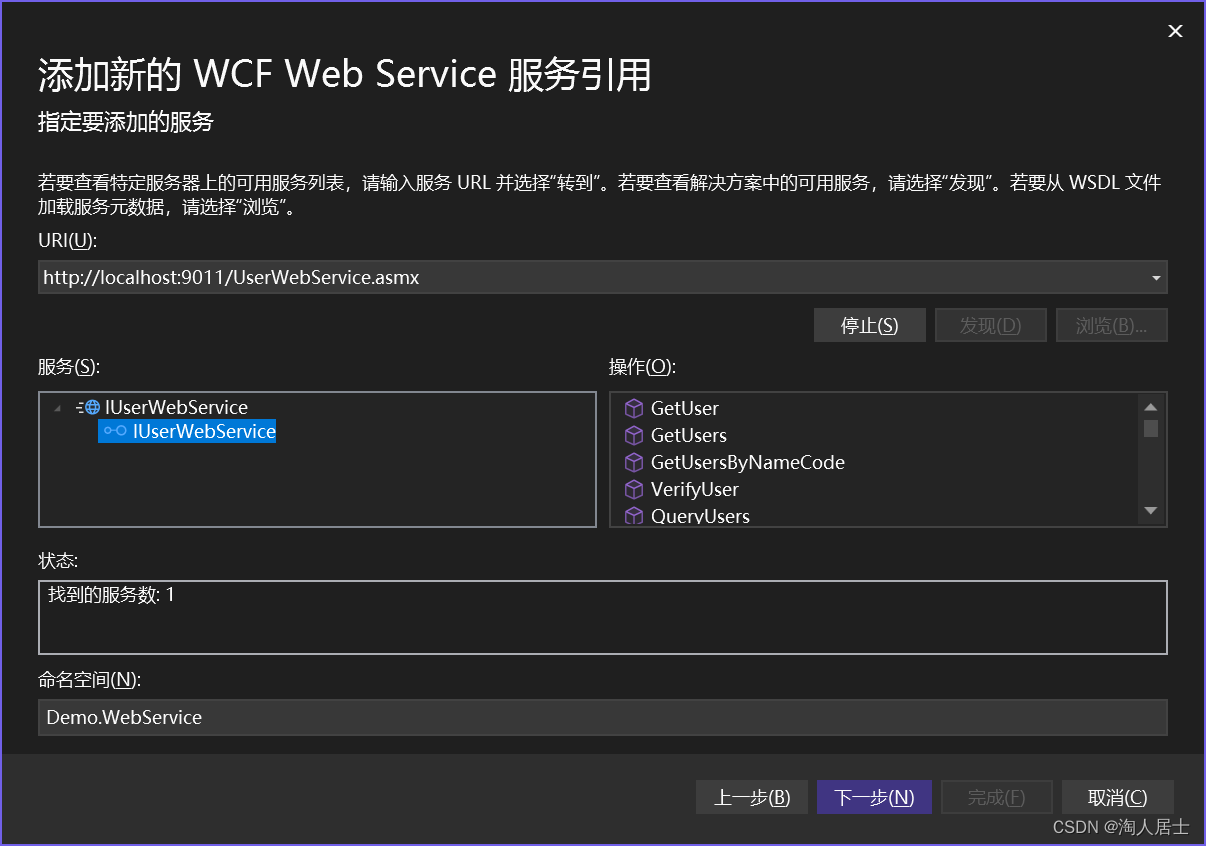
netcore构建webservice以及调用的完整流程
目录构建前置准备编写服务挂载服务处理SoapHeader调用添加服务调用服务补充内容构建 前置准备 框架版本要求:netcore3.1以上 引入nuget包 SoapCore 编写服务 1.编写服务接口 示例 using System.ServiceModel;namespace Services;[ServiceContract(Namespace &…...
)
Mysql事务基础(解析)
并发事务带来的问题A和B是并发事务脏写(A被B覆盖)两个事务。B事务覆盖了A事务。解决:应该事务并行脏读(B读到了A的执行中间结果)A修改了东西。B看到了他的中间状态。解决:读写冲突。加锁,改完再…...

2023 年首轮土地销售活动来了 与 The Sandbox 一起体验「体素狂热」!
2 月 14 日晚上 11 点,开始你的体素冒险。 The Sandbox 很高兴推出 2023 年的第一次土地销售活动。欢迎来到「体素狂热 (Voxel Madness)」! 简要概括 土地销售抽奖活动将于北京时间 2 月 14 日星期二晚上 11 点开始 「体素狂热」 土地销售活动将于 2 月…...

vue AntD中栅格布局的四种大小xs,sm,md,lg
cssBootstrap栅格布局的四种大小xs,sm,md,lg前端为了页面在不同大小的设备上也能够正常显示,通常会使用栅格布局的方式来实现。使用bootStrap的网格系统时,常见到一下格式的类名col-*-*visible-*-*hidden_*_* 中间可为xs,xsm,md,lg等表示大小的单词的缩写…...
打开窗口全屏)
window.open()打开窗口全屏
window.open (page.html, page, height100, width400, top0, left0, toolbarno, menubarno, scrollbarsno, resizableno,locationn o, statusno, fullscreenyes); 参数解释: window.open() 弹出新窗口的命令; ‘page.html’ 弹出窗口的文件名ÿ…...
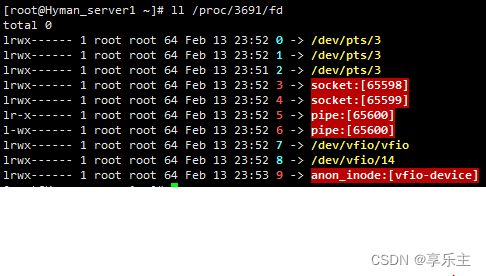
VFIO软件依赖——VFIO协议
文章目录背景PCI设备模拟PCI设备抽象VFIO协议实验Q&A背景 在虚拟化应用场景中,虚拟机想要在访问PCI设备时达到IO性能最优,最直接的方法就是将物理设备暴露给虚拟机,虚拟机对设备的访问不经过任何中间层的转换,没有虚拟化的损…...

C/C++【内存管理】
✨个人主页: Yohifo 🎉所属专栏: C修行之路 🎊每篇一句: 图片来源 Love is a choice. It is a conscious commitment. It is something you choose to make work every day with a person who has chosen the same thi…...

第8篇:Java编程语言的8大优势
目录 1、简单性 2、面向对象 3、编译解释性 4、稳健性 5、安全性 6、跨平台性...

STM32定时器实现红外接收与解码
1.NEC协议 红外遥控是一种比较常用的通讯方式,目前红外遥控的编码方式中,应用比较广泛的是NEC协议。NEC协议的特点如下: 载波频率为 38KHz8位地址和 8位指令长度地址和命令2次传输(确保可靠性)PWM 脉冲位置调制&#…...
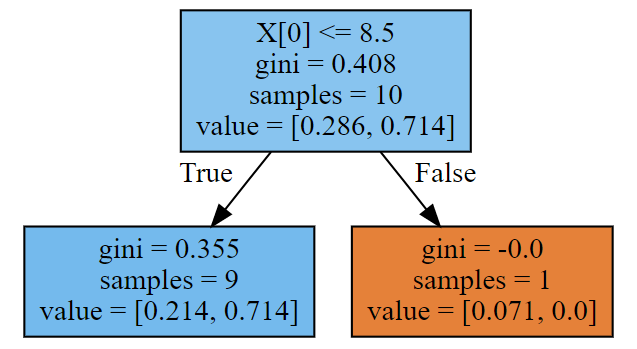
18- Adaboost梯度提升树 (集成算法) (算法)
Adaboost 梯度提升树: from sklearn.ensemble import AdaBoostClassifier model AdaBoostClassifier(n_estimators500) model.fit(X_train,y_train) 1、Adaboost算法介绍 1.1、算法引出 AI 39年(公元1995年),扁鹊成立了一家专治某疑难杂症…...
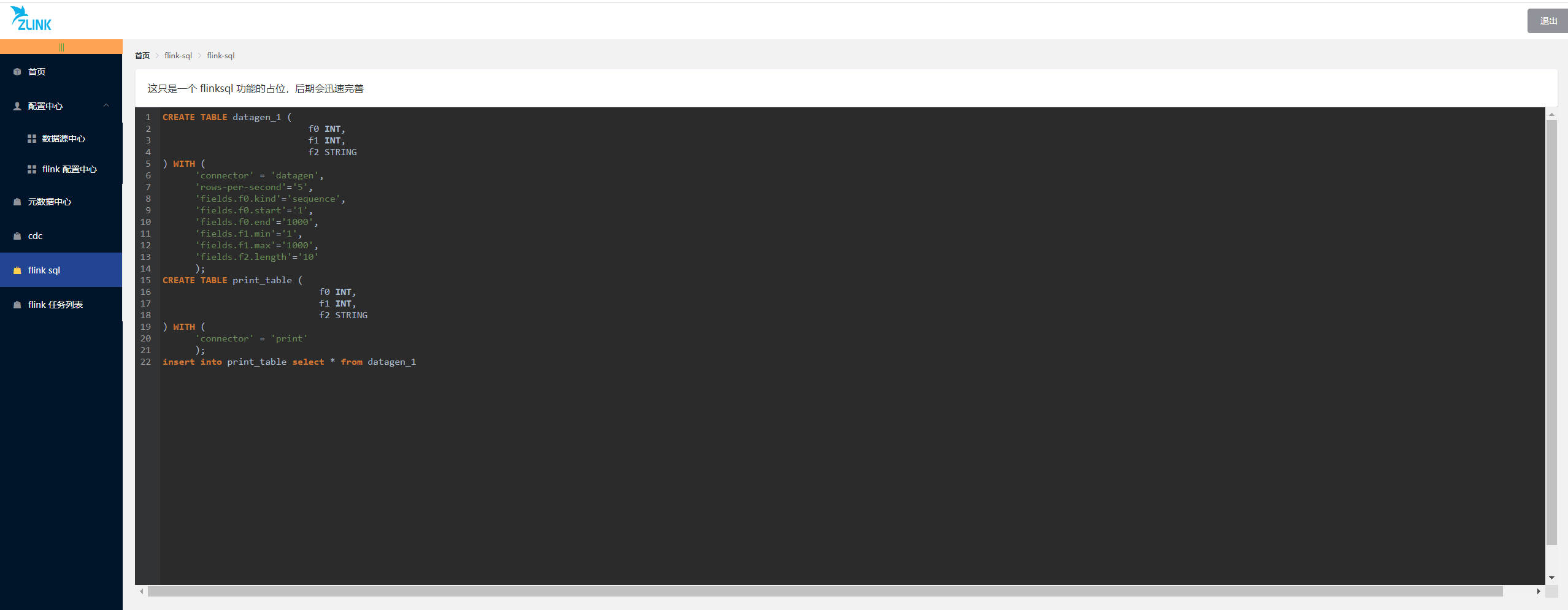
zlink 介绍
zlink 是一个基于 flink 开发的分布式数据开发工具,提供简单的易用的操作界面,降低用户学习 flink 的成本,缩短任务配置时间,避免配置过程中出现错误。用户可以通过拖拉拽的方式实现数据的实时同步,支持多数据源之间的…...

C++之std::string的resize与reverse
std::string的resize与reverse前言1.resize2.reserve前言 在C中我们经常用std::string 来保存字符串,其中有两个比较常用但是却平时容易被搞混的两个函数,分别是resize和reserve,模糊意识里,这两个方法都是对std::string的容量或元…...

在.net中运用ffmpeg 操作视频
using System;using System.Collections.Generic;using System.Diagnostics;using System.IO;using System.Text;namespace learun.util{/// <summary>/// ffmpeg视频相关处理的类/// </summary>public class FFmpegUtil{public static int Run(string cmd){try{//…...
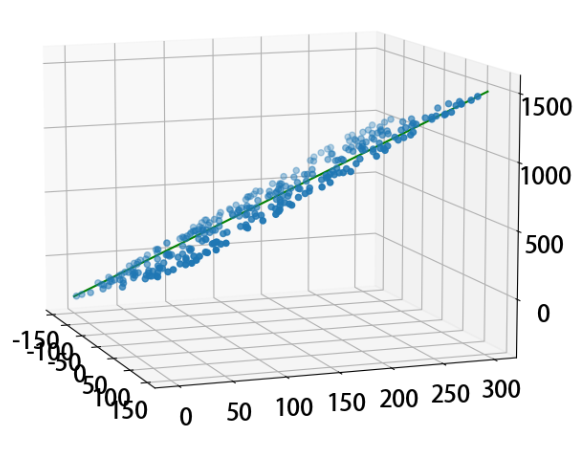
05- 线性回归算法 (LinearRegression) (算法)
线性回归算法(LinearRegression)就是假定一个数据集合预测值与实际值存在一定的误差, 然后假定所有的这些误差值符合正太分布, 通过方程求这个正太分布的最小均值和方差来还原原数据集合的斜率和截距。当误差值无限接近于0时, 预测值与实际值一致, 就变成了求误差的极小值。 fr…...

JAVA补充知识01之枚举enum
目录 1. 枚举类的使用 1.1 枚举类的理解 1.2 举例 1.3 开发中的建议: 1.4 Enum中的常用方法 1.5 熟悉Enum类中常用的方法 1.6 枚举类实现接口的操作 1.7 jdk5.0之前定义枚举类的方式 (了解即可) 1.8 jdk5.0之后定义枚举类的方式 1…...
jenkins下配置maven
1. 先在jenkins服务器上安装maven 下载-解压-重命名-启动 [rootVM-0-12-centos local]# wget https://mirrors.aliyun.com/apache/maven/maven-3/3.9.0/binaries/apache-maven-3.9.0-bin.tar.gz [rootVM-0-12-centos local]# tar xf apache-maven-3.9.0-bin.tar.gz [rootVM-0…...

VideoAgentTrek-ScreenFilter项目依赖管理:.NET生态下的客户端封装库开发
VideoAgentTrek-ScreenFilter项目依赖管理:.NET生态下的客户端封装库开发 最近在做一个视频处理相关的项目,需要频繁调用VideoAgentTrek-ScreenFilter的HTTP API。每次调用都得手动拼装HTTP请求、处理序列化、解析响应,代码里到处都是重复的…...

终极指南:如何用Continue AI代码助手提升10倍开发效率
终极指南:如何用Continue AI代码助手提升10倍开发效率 【免费下载链接】continue ⏩ Continue is an open-source autopilot for VS Code and JetBrains—the easiest way to code with any LLM 项目地址: https://gitcode.com/GitHub_Trending/co/continue …...

Kotaemon在教育培训中的应用:如何构建可信赖的学科答疑助手?
Kotaemon在教育培训中的应用:如何构建可信赖的学科答疑助手? 1. 教育场景中的AI答疑痛点 想象这样一个场景:晚自习教室里,一个学生正为生物作业发愁。他在手机上输入:"光合作用的暗反应发生在叶绿体的哪个部位&…...

往期精彩|阿尔茨海默病合集 | 以往高分文献分析,揭示阿尔茨海默病研究热点
阿尔茨海默病(AD)是在老年人群中最为普遍的神经退行性疾病,也是痴呆症的最常见原因,全球大约有2660万人受到影响。1、Neurology:新的血液生物标志物可以在阿尔茨海默病的早期阶段预测其进展2025年,巴塞罗那…...

Java突变测试终极指南:Pitest如何提升你的代码质量
Java突变测试终极指南:Pitest如何提升你的代码质量 【免费下载链接】pitest State of the art mutation testing system for the JVM 项目地址: https://gitcode.com/gh_mirrors/pi/pitest 突变测试是Java开发中革命性的质量保障技术,而Pitest&am…...

DeepSeek-OCR-2惊艳效果展示:多栏/斜拍/模糊PDF精准识别对比图集
DeepSeek-OCR-2惊艳效果展示:多栏/斜拍/模糊PDF精准识别对比图集 1. 从机械扫描到智能理解:OCR技术的革命性突破 如果你曾经尝试过从PDF文档中提取文字,特别是那些排版复杂、图片模糊或者拍摄角度倾斜的文档,你一定会理解那种挫…...

实测Qwen3-VL-30B:上传图片就能问,智能识别效果惊艳
实测Qwen3-VL-30B:上传图片就能问,智能识别效果惊艳 你有没有想过,给电脑看一张照片,它不仅能告诉你照片里有什么,还能像朋友一样跟你讨论照片里的故事?比如,你拍了一张晚餐的照片,…...

OpenClaw+ollama-QwQ-32B自动化写作:从指令到公众号草稿全流程
OpenClawollama-QwQ-32B自动化写作:从指令到公众号草稿全流程 1. 为什么需要自动化写作助手 作为一个技术博主,我每周都要产出2-3篇原创文章。最痛苦的环节不是写作本身,而是那些重复性的准备工作:收集资料、整理格式、调整排版…...

3大技巧:如何让旧Mac免费升级到最新macOS系统的完整方案
3大技巧:如何让旧Mac免费升级到最新macOS系统的完整方案 【免费下载链接】OpenCore-Legacy-Patcher 体验与之前一样的macOS 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 你是否有一台2012-2015年的旧款Mac,看着朋…...
)
甲方安全测试逼出来的实战:手把手教你用SM2国密算法加密前端敏感查询条件(附完整Java/JS代码)
从安全测试到生产落地:SM2国密算法在前端敏感数据加密中的实战指南 去年的一次安全审计中,我们的系统因为用户身份证号在查询接口中明文传输被标记为中危漏洞。安全团队给出的报告截图至今让我记忆犹新——那些本应被保护的敏感数据,在抓包工…...