18- Adaboost梯度提升树 (集成算法) (算法)
Adaboost 梯度提升树:
from sklearn.ensemble import AdaBoostClassifier
model = AdaBoostClassifier(n_estimators=500)
model.fit(X_train,y_train)1、Adaboost算法介绍
1.1、算法引出
AI 39年(公元1995年),扁鹊成立了一家专治某疑难杂症的医院,经过半年的精心筹备,硬件设施已全部到位,只缺经验丰富的医生前来坐诊。找几个猎头打听了一下,乖乖,请一个资深专家(总监头衔的),一年的工资就得256万。这恐怕还不够去知名搜索引擎投放广告!
穷则思变,扁鹊院长想来想去,找到了两个天才的顾问,名叫Freund和Schapire,想请他们出出主意,怎样用较低的成本解决医生的问题。这两位老兄想到了同一个点子:
三个臭皮匠,赛过诸葛亮
我们玩人海战术!不如去医学院招一批应届生,给他们训练一段时间然后上岗,组成一个会诊小组,一起来给病人看病,集体决策。扁鹊很快招来了8个年轻的新手:
赵大夫,钱大夫,孙大夫,李大夫,周大夫,吴大夫,郑大夫,王大夫
1.2、算法策略
怎么训练这些新人呢?两个顾问设计出了一套培训方案:
-
用大量的病例让这些新手依次学习,每个大夫自己琢磨怎样诊断,学习结束后统计一下每个人在这些病例上的诊断准确率
-
训练时,前面的大夫误诊的病例,后面的大夫要重点学习研究,所谓查缺补漏
-
训练结束之后,给每个大夫打分,如果一个大夫对病例学习的越好,也就是说在这些学习的病例集上诊断的准确率越高,他在后面诊断病人时的话语权就越大
1.3、训练流程
接下来培训过程开始了。首先接受培训的是赵大夫,经过学习总结,他摸索出了一套诊断规则,这套规则表现很不错,至少在学习用的病例集上,达到了70%的诊断准确率。学习完成之后,他给每一条病例调整了权重,被他误诊的病例,权重增大,诊断正确的病例,权重调小,以便于后面的医生有重点的学习。
接下来让钱大夫学习,他同样学习这些病例,但重点要关注被赵大夫误诊的那些病例,经过一番训练,钱大夫达到了75%的准确率。学习完之后,他也调整了这些病例的权重,被他误诊的病例,加大权重,否则减小权重。
后面的过程和前面类似,依次训练孙大夫,李大夫,周大夫,吴大夫,郑大夫,王大夫,每个大夫在学习的时候重点关注被前面的大夫误诊的病例,学习完之后调整每条病例的权重。这样到最后,王大夫对前面这些大夫都误诊的病例特别擅长,专攻这些情况的疑难杂症!
1.4、大夫话语权
当所有大夫都培训完成之后,就可以让他们一起坐堂问诊了。Freund和Schapire设计出了这样一套诊断规则:来一个病人之后,8个大夫一起诊断,然后投票。如果一个大夫之前在学习时的诊断准确率为p,他在投票时的话语权是:
按照这个计算规则,8个大夫的话语权为:
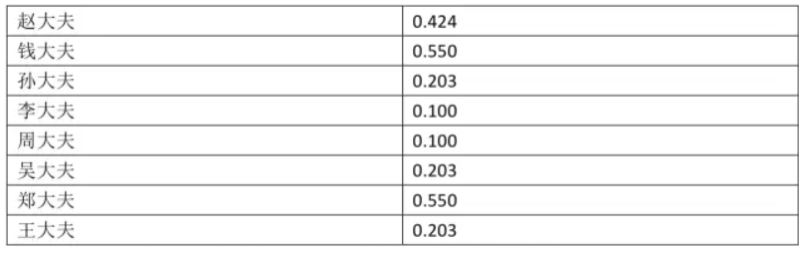
1.5、诊断结果
这样诊断结果的计算方法为,先汇总整合8个大夫的诊断结果:

在这里对病人的诊断结果有两种可能,阳性和阴性,我们量化表示,+1表示阳性,-1表示阴性。
最后的诊断结果是:如果上面计算出来的s值大于0,则认为是阳性,否则为阴性。
1.6、病人诊断
第一个病人来了,8个大夫一番诊断之后,各自给出了结果:
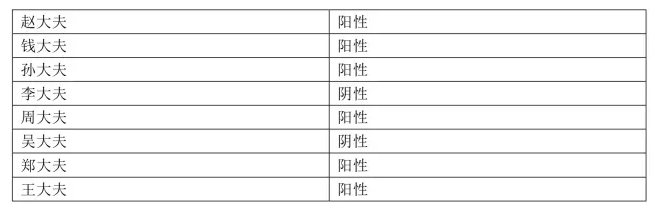
现在是投票集体决策的时候了。投票值为:
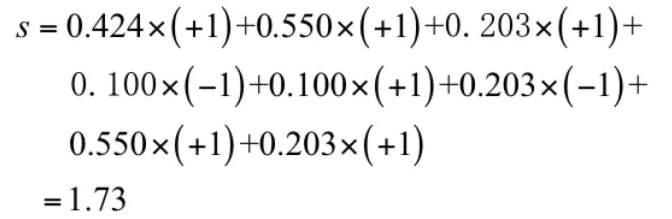
按照规则,这个病人被判定为阳性。
1.7、算法总结
医院运营了3个月,效果出奇的好,扁鹊院长统计了一下,诊断准确率居然高达95%,不比一个资深老专家差!每个医生一年的工资10万,8个医生总共才80万,这比请一个资深专家要便宜170万,太划算了!
这次成功之后,Freund和Schapire决定把这种方法推广到其他行业,用于解决一些实际问题。这些行业要解决的问题都有一个特点:要做出一个决策,这个决策有两种可能,例如银行要根据客户的收入、负债情况、信用记录等信息决定给客户贷款还是不贷款;人脸识别公司要判断一张图像是人脸还是不是人脸。这就是机器学习中的二分类问题,给定一个样本数据,判断这个样本的类别。对于上面的疾病诊断来说,样本数据就是病人的各项检查数据,类别是阴性和阳性。
两位天才给这种方法取了一个名字:AdaBoost算法。
Adaboosting中的Ada是adaptive的意思,所以AdaBoosting表示自适应增强算法!
2、Adaboost算法使用
2.1、乳腺癌案例
1、导包
import numpy as np
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import AdaBoostClassifier,RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn import datasets2、加载拆分数据
X,y = datasets.load_breast_cancer(return_X_y=True)
display(X.shape,y.shape,np.unique(y))
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2)3、使用决策树建模
model = DecisionTreeClassifier()
# 训练
model.fit(X_train,y_train)
# 预测值
y_pred = model.predict(X_test)
display(y_pred[:20],y_test[:20])
# 准确率
accuracy_score(y_test,y_pred) # 准确率大约是:0.89473684210526324、使用随机森林建模
%%time
model = RandomForestClassifier(n_estimators=500)
# 训练
model.fit(X_train,y_train)
# 预测
y_pred = model.predict(X_test)
display(y_pred[:20],y_test[:20])
# 准确率
accuracy_score(y_test,y_pred) # 准确率大约是:0.9561403508771935、使用Adaboost算法建模
%%time
model = AdaBoostClassifier(n_estimators=500)
# 训练
model.fit(X_train,y_train)
# 预测
y_pred = model.predict(X_test)
display(y_pred[:20],y_test[:20])
# 准确率
accuracy_score(y_test,y_pred) # 准确率大约是:0.9649122807017544结论:
-
课件,Adaboost对数据拟合更加深入,准确率高,效果好
-
果然是:三个臭皮匠,顶个诸葛亮!
2.2、手写数字案例
1、导包
import numpy as np
import pandas as pd
from sklearn import tree
import graphviz
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import AdaBoostClassifier,RandomForestClassifier
from sklearn.linear_model import LogisticRegression
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score2、加载拆分数据
data = pd.read_csv('./digits.csv')
# 随机抽样
data = data.take(np.random.randint(0,42000,5000))
X = data.iloc[:,1:]
y = data['label']
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2,random_state=1024)
display(X_train.shape,X_test.shape,y_train.shape,y_test.shape)3、决策树
model = DecisionTreeClassifier()
# 训练
model.fit(X_train,y_train)
# 预测值
y_pred = model.predict(X_test)
display(y_pred[:20],y_test[:20].values)
# 准确率
accuracy_score(y_test,y_pred) # 准确率:0.7794、随机森林
%%time
model = RandomForestClassifier(n_estimators=100)
# 训练
model.fit(X_train,y_train)
# 预测
y_pred = model.predict(X_test)
display(y_pred[:20],y_test[:20].values)
# 准确率
accuracy_score(y_test,y_pred) # 准确率:0.9345、Adaboost提升算法
%%time
model = AdaBoostClassifier(n_estimators=100)
# 训练
model.fit(X_train,y_train)
# 预测
y_pred = model.predict(X_test)
display(y_pred[:20],y_test[:20].values)
# 准确率
accuracy_score(y_test,y_pred) # 准确率:0.5216、逻辑回归算法
%%time
model = LogisticRegression(max_iter=10000)
# 训练
model.fit(X_train,y_train)
# 预测
y_pred = model.predict(X_test)
display(y_pred[:20],y_test[:20].values)
# 准确率
accuracy_score(y_test,y_pred) # 准确率:0.8917、可视化
plt.figure(figsize=(5*2,10*2))
plt.rcParams['font.family'] = 'STKaiti'
for i in range(50):plt.subplot(10,5,i + 1)plt.imshow(X_test.iloc[i].values.reshape(28,28))plt.axis('off')plt.title('预测值是:%d' %(y_pred[i]))
结论:
-
手写数字的特征是像素值,特征值多大784个
-
而且像素中很多值都是0,没有特征区分度
-
Adaboost对这个效果就不好
-
逻辑回归,比决策树算法效果要好一些
3、Adaboost二分类算法原理
3.1、算法流程
算法流程详解:

3.2、手撕算法
3.2.1、创建模拟数据
from sklearn.ensemble import AdaBoostClassifier
import numpy as np
from sklearn import tree
import graphviz
X = np.arange(10).reshape(-1,1)
y = np.array([1,1,1,-1,-1,-1,1,1,1,-1])
display(X,y)3.2.2、Adaboost建模
# 使用SAMME表示在构建树时,每棵树都采用相同的分裂方式
ada = AdaBoostClassifier(algorithm='SAMME',n_estimators=3)
ada.fit(X,y)
y_ = ada.predict(X)
display(y,y_)3.2.3、查看每一棵树结构
第一棵树:
dot_data = tree.export_graphviz(ada[0],filled=True)
graph = graphviz.Source(dot_data)
y1_ = ada[0].predict(X) # 第一棵树的预测值,怎么预测呢?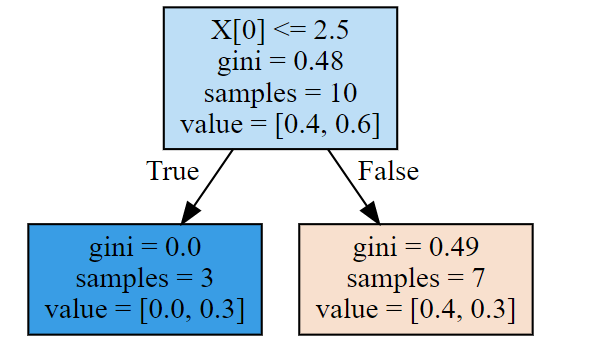
第二棵树:
dot_data = tree.export_graphviz(ada[1],filled=True)
print(ada[1].predict(X))
graphviz.Source(dot_data)#样本权重,发生变化了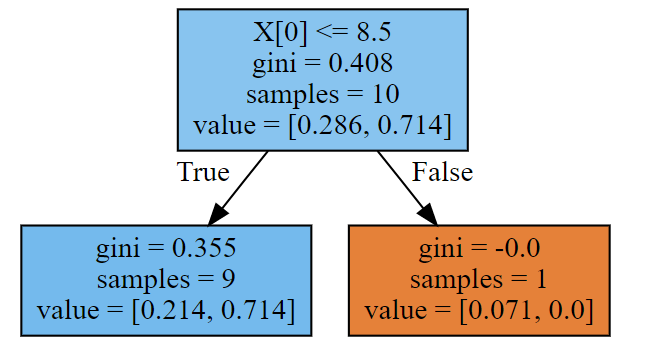
第三棵树:
dot_data = tree.export_graphviz(ada[2],filled=True)
print(ada[2].predict(X))
graphviz.Source(dot_data)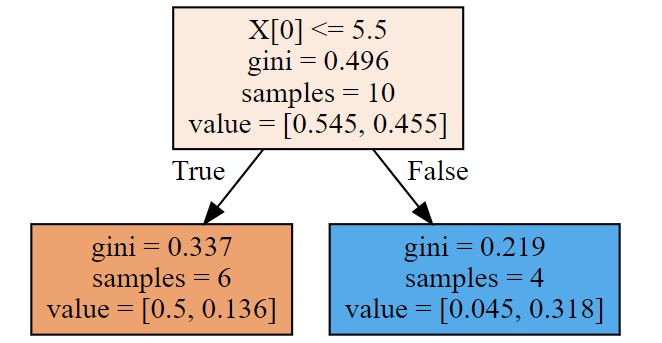
3.2.4、第一棵树代码构建
1、gini系数计算
w1 = np.full(shape = 10,fill_value=1/10)
cond = y == -1
p1 = w1[cond].sum()
cond = y == 1
p2 = w1[cond].sum()
# 计算方式一
gini = p1 * (1 - p1) + p2 * (1 - p2)
print('计算方式二:',gini)
# 计算方式二
gini = 1 - p1**2 - p2**2
print('计算方式二:',gini) # 输出:0.482、拆分条件
gini_result = []
best_split = {}
lower_gini = 1
# 如何划分呢,分成两部分
for i in range(len(X) - 1):split = X[i:i+2].mean()cond = (X <= split).ravel()part1 = y[cond]part2 = y[~cond]gini1 = 0gini2 = 0for i in np.unique(y):p1 = (part1 == i).sum()/part1.sizegini1 += p1 * (1 - p1)p2 = (part2 == i).sum()/part2.sizegini2 += p2 * (1 - p2)part1_p = cond.sum()/cond.sizepart2_p = 1 - part1_pgini = part1_p * gini1 + part2_p* gini2gini_result.append(gini)if gini < lower_gini:lower_gini = ginibest_split.clear()best_split['X[0]'] = split
print(gini_result)
print(best_split)3、计算误差率
# 计算误差率
print(y)
y1_ = ada[0].predict(X) #预测结果
print(y1_)
y1_ = np.array([1 if X[i] < 2.5 else -1 for i in range(10)])
print(y1_)
e1 = ((y != y1_)).mean()#误差
print('第一棵树误差率是:',e1)4、计算第一个分类器权重
# 计算第一个弱学习器的权重,相当于大夫的话语权
alpha_1 = 1/2*np.log((1 -e1)/e1 )
print('计算第一个弱学习器的权重:',alpha_1)
# 输出:计算第一个弱学习器的权重: 0.423648930193601845、更新样本权重
# 在w1的基础上,进行更新 w1 = [0.1,0.1,0.1……]
w2 = w1 * np.exp(-alpha_1 * y * y1_)
w2 = w2/w2.sum() # 归一化
print('第一棵树学习结束更新权重:\n',w2)
# 输出
'''
第一棵树学习结束更新权重:[0.07142857 0.07142857 0.07142857 0.07142857 0.07142857 0.071428570.16666667 0.16666667 0.16666667 0.07142857]
'''3.2.5、第二棵树代码构建 (后面继续)
相关文章:
18- Adaboost梯度提升树 (集成算法) (算法)
Adaboost 梯度提升树: from sklearn.ensemble import AdaBoostClassifier model AdaBoostClassifier(n_estimators500) model.fit(X_train,y_train) 1、Adaboost算法介绍 1.1、算法引出 AI 39年(公元1995年),扁鹊成立了一家专治某疑难杂症…...
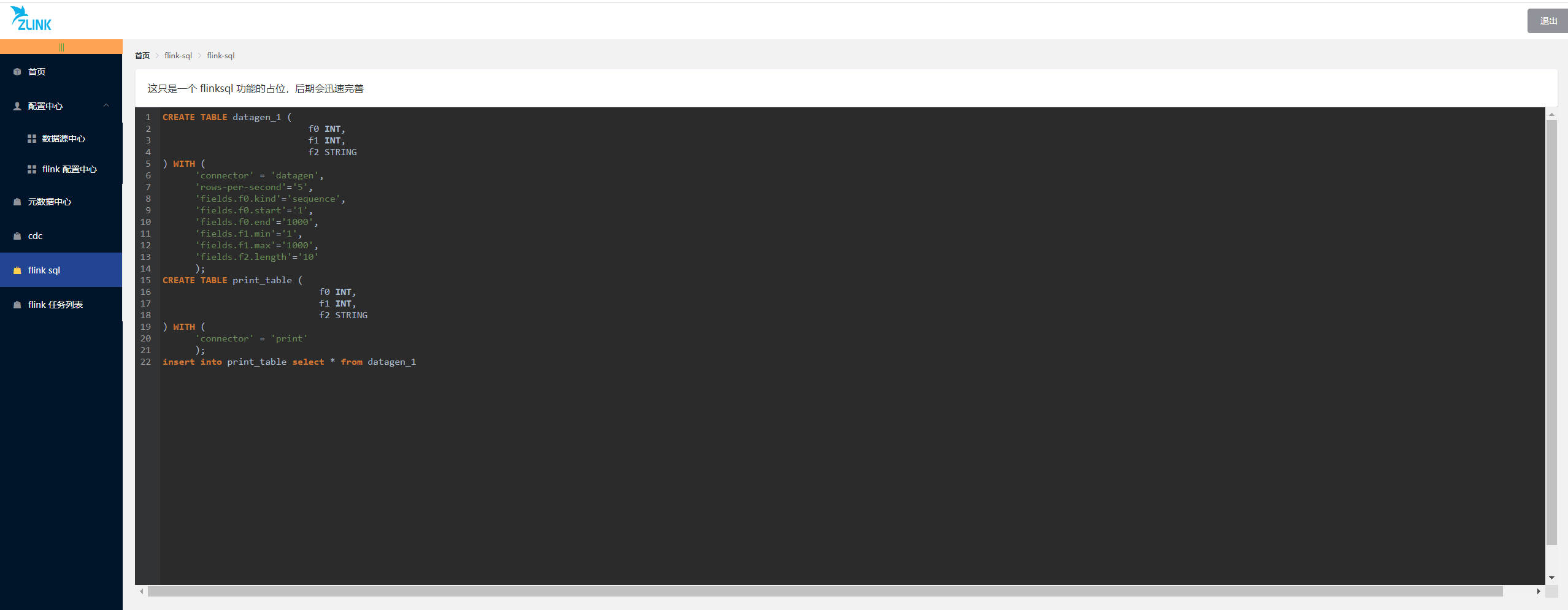
zlink 介绍
zlink 是一个基于 flink 开发的分布式数据开发工具,提供简单的易用的操作界面,降低用户学习 flink 的成本,缩短任务配置时间,避免配置过程中出现错误。用户可以通过拖拉拽的方式实现数据的实时同步,支持多数据源之间的…...

C++之std::string的resize与reverse
std::string的resize与reverse前言1.resize2.reserve前言 在C中我们经常用std::string 来保存字符串,其中有两个比较常用但是却平时容易被搞混的两个函数,分别是resize和reserve,模糊意识里,这两个方法都是对std::string的容量或元…...

在.net中运用ffmpeg 操作视频
using System;using System.Collections.Generic;using System.Diagnostics;using System.IO;using System.Text;namespace learun.util{/// <summary>/// ffmpeg视频相关处理的类/// </summary>public class FFmpegUtil{public static int Run(string cmd){try{//…...
05- 线性回归算法 (LinearRegression) (算法)
线性回归算法(LinearRegression)就是假定一个数据集合预测值与实际值存在一定的误差, 然后假定所有的这些误差值符合正太分布, 通过方程求这个正太分布的最小均值和方差来还原原数据集合的斜率和截距。当误差值无限接近于0时, 预测值与实际值一致, 就变成了求误差的极小值。 fr…...

JAVA补充知识01之枚举enum
目录 1. 枚举类的使用 1.1 枚举类的理解 1.2 举例 1.3 开发中的建议: 1.4 Enum中的常用方法 1.5 熟悉Enum类中常用的方法 1.6 枚举类实现接口的操作 1.7 jdk5.0之前定义枚举类的方式 (了解即可) 1.8 jdk5.0之后定义枚举类的方式 1…...
jenkins下配置maven
1. 先在jenkins服务器上安装maven 下载-解压-重命名-启动 [rootVM-0-12-centos local]# wget https://mirrors.aliyun.com/apache/maven/maven-3/3.9.0/binaries/apache-maven-3.9.0-bin.tar.gz [rootVM-0-12-centos local]# tar xf apache-maven-3.9.0-bin.tar.gz [rootVM-0…...

春季开学即将到来!大学生活必备数码清单奉上
马上就要开学了,你的返校装备是否已经准备齐全了呢?对于高校学生来说,很多数码产品都属于必备装备,比如下面这几款产品就受到了大量年轻消费者的喜爱,在它们的帮助下能够让大家的学习时光变得更快乐。1、不入耳黑科技骨…...
ubuntu18.04 天选2 R95900hx 3060显卡驱动安装
天选2 R95900hx 3060显卡驱动安装需求问题解决内核集显显卡驱动需求 外接显示器,安装nvidia驱动 问题 由于一开始直接在软件和更新中附加读懂安装了nvidia-470,导致系统黑屏。 解决 grub页面系统选择进入ubuntu recovery模式,选择root&a…...
Harbor安装部署实战详细手册
文章目录前言一、安装docker二、安装docker-compose1.下载2.赋权3.测试三、安装harbor1.下载2.解压3.修改配置文件4.部署5.配置开机自启动6.登录验证7.补充说明四、harbor使用问题1.docker login问题:Error response from daemon: Get https://: http: server gave …...
)
华为OD机试真题JAVA实现【箱子之形摆放】真题+解题思路+代码(20222023)
🔥系列专栏 华为OD机试(JAVA)真题目录汇总华为OD机试(Python)真题目录汇总华为OD机试(C++)真题目录汇总华为OD机试(JavaScript)真题目录汇总文章目录 🔥系列专栏题目输入输出描述示例一输入输出说明备注解题思路Code运行结果版权说明...
| 真题+思路+考点+代码+岗位)
华为OD机试 - 事件推送(Python)| 真题+思路+考点+代码+岗位
事件推送 题目 同一个数轴 X 上有两个点的集合 A={A1, A2, …, Am} 和 B={B1, B2, …, Bn}, Ai 和 Bj 均为正整数,A、B 已经按照从小到大排好序,A、B 均不为空, 给定一个距离 R (正整数), 列出同时满足如下条件的所有(Ai, Bj)数对: Ai <= BjAi, Bj 之间的距离小于…...

【Linux】信号量
🎇Linux: 博客主页:一起去看日落吗分享博主的在Linux中学习到的知识和遇到的问题博主的能力有限,出现错误希望大家不吝赐教分享给大家一句我很喜欢的话: 看似不起波澜的日复一日,一定会在某一天让你看见坚持…...

android-java同步方法和异步方法
接口 Java接口是一系列方法的声明,是一些方法特征的集合,一个接口只有方法的特征没有方法的实现,因此这些方法可以在不同的地方被不同的类实现,而这些实现可以具有不同的行为(功能)。 两种含义:…...
:请求和响应)
Flask入门(5):请求和响应
目录5.请求和响应5.1 请求5.2 响应5.请求和响应 5.1 请求 request对象封装解析了请求报文中的数据,其大部分功能是由依赖包werkzeug完成的,并且每个request对象都是线程隔离的,保证了数据的安全性。 request对象的属性 1.request.method …...
记进组后第五次组会汇报
2023年2月14日 日记一、小组组会二、实验室组会1、汇报内容(1)参考文献(2)CQF机制a.研究现状b.相关思考(3)研究计划2、汇报反馈一、小组组会 上午十点整,小组组会开始,有两个同学我…...
)
nil Foundation的Placeholder证明系统(2)
前序博客: nil Foundation的Placeholder证明系统(1) nil; Foundation团队2022年11月论文《Placeholder证明系统》。[2022年11月29日版本] 8. 优化 8.1 Batched FRI 不同于单独检查每个commitment,可对其进行FRI聚合。如对多项…...
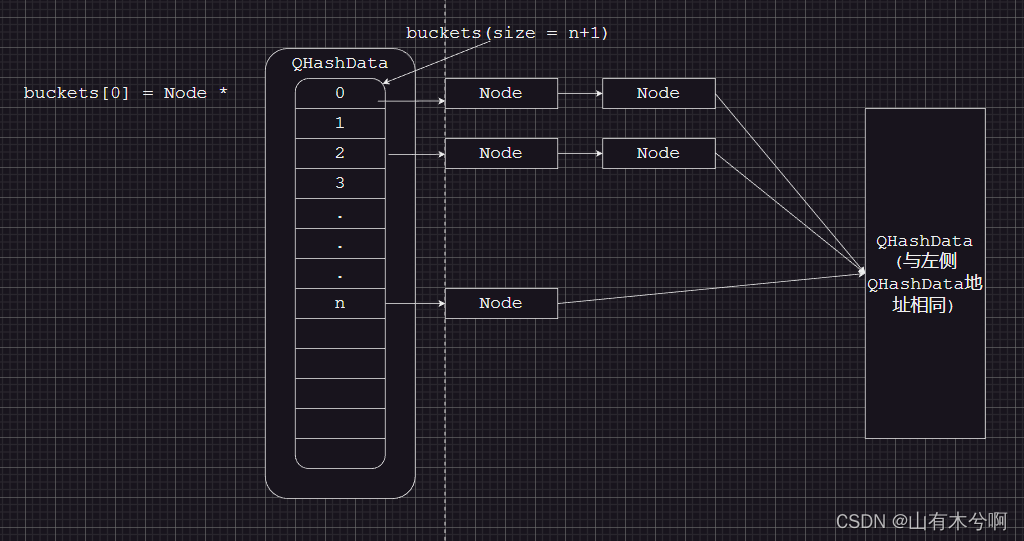
QHash源码解读
QT版本 v5.12.10 元素 // 重点说明QHashData的函数,QHashData是QHash的基础 struct QHashData {struct Node {Node *next;uint h;};Node *fakeNext; // 永为nullNode **buckets; // Node *数组QtPrivate::RefCount ref;int size; // node个数int nodeSize; /…...

【Unity细节】RigidBody中Dynamic和Kinematic的区别
👨💻个人主页:元宇宙-秩沅 hallo 欢迎 点赞👍 收藏⭐ 留言📝 加关注✅! 本文由 秩沅 原创 收录于专栏:unity细节和bug ⭐Dynamic和Kinematic的区别⭐ 文章目录⭐Dynamic和Kinematic的区别⭐dz…...

【C++、数据结构】哈希 — 闭散列与哈希桶的模拟实现
文章目录📖 前言1. STL中哈希表的两个应用⚡1.1 🌟unordered_set1.2 🌟unordered_map2. 常见查找的性能对比💥3. 哈希表模拟实现🏁3.1 哈希的概念:3.2 哈希函数:3.3 哈希冲突:3.4 闭…...

3大核心模块构建戴森球计划模块化生产体系:从混乱到有序的进阶指南
3大核心模块构建戴森球计划模块化生产体系:从混乱到有序的进阶指南 【免费下载链接】FactoryBluePrints 游戏戴森球计划的**工厂**蓝图仓库 项目地址: https://gitcode.com/GitHub_Trending/fa/FactoryBluePrints 概念解析:模块化生产的本质与价值…...

Qwen3-4B快速上手:无需深度学习基础,轻松玩转AI对话
Qwen3-4B快速上手:无需深度学习基础,轻松玩转AI对话 想体验一个反应迅速、对话流畅的AI助手吗?阿里通义千问的Qwen3-4B模型或许就是你需要的。这个专门优化过的版本去掉了所有视觉处理功能,专注于文本对话,响应速度大…...

Tessent Shell双Pass插入策略深度解读:为什么MemoryBIST要先于EDT/OCC插入?
Tessent Shell双Pass插入策略:MemoryBIST优先于EDT/OCC的技术本质解析 在芯片测试领域,Tessent Shell的双Pass插入流程(Two-Pass Insertion Process)是一个被广泛采用却鲜少深入探讨的核心方法论。当工程师首次接触"先Memory…...

低代码拖拽逻辑执行慢10倍?:用3个内存布局优化+1个opcode精简表,让RuleEngine吞吐量突破23,000 TPS
第一章:低代码拖拽逻辑执行慢10倍?:用3个内存布局优化1个opcode精简表,让RuleEngine吞吐量突破23,000 TPS低代码规则引擎在拖拽式策略编排场景下,常因对象频繁分配、字段间接寻址与冗余指令解析导致执行路径膨胀。我们…...

3大维度重构投资决策:用TradingAgents-CN打造智能交易系统
3大维度重构投资决策:用TradingAgents-CN打造智能交易系统 【免费下载链接】TradingAgents-CN 基于多智能体LLM的中文金融交易框架 - TradingAgents中文增强版 项目地址: https://gitcode.com/GitHub_Trending/tr/TradingAgents-CN 在数字化投资时代…...

SenseVoice-small-onnx语音识别效果:不同信噪比下识别鲁棒性测试
SenseVoice-small-onnx语音识别效果:不同信噪比下识别鲁棒性测试 1. 测试背景与意义 语音识别技术在日常生活中的应用越来越广泛,从智能助手到会议转录,从客服系统到语音输入,无处不在。但在真实环境中,音频质量往往…...

解码像素,探寻隐匿——CTF-03图片隐写学习心得
CTF-03聚焦图片隐写专项学习,是从基础安全知识迈向数据隐藏与取证实战的重要进阶。通过本次学习,我系统掌握了图片隐写的核心原理、常见工具与实操技巧,不仅深化了对“数据隐匿”攻防思维的理解,更提升了对图片文件的深度分析与信…...

OpenClaw智能剪贴板:GLM-4.7-Flash增强复制粘贴功能
OpenClaw智能剪贴板:GLM-4.7-Flash增强复制粘贴功能 1. 为什么我们需要更聪明的剪贴板 作为一个每天要和大量文本打交道的技术写作者,我经常陷入这样的困境:从网页复制的内容带着乱七八糟的格式,从PDF摘录的段落夹杂着换行符和乱…...

利用ADS实现多频段阻抗自动优化的实战指南
1. 从零开始理解多频段阻抗匹配 刚入行那会儿,我对阻抗匹配的理解还停留在"把50欧姆搞对就行"的层面。直到某次调试一个同时工作在900MHz和2.4GHz的双频天线时,才发现单频段匹配的思路完全不够用——调好了低频段,高频段性能就崩了…...

AnotherRedisDesktopManager:让Redis管理变得简单高效的5个理由
AnotherRedisDesktopManager:让Redis管理变得简单高效的5个理由 【免费下载链接】AnotherRedisDesktopManager qishibo/AnotherRedisDesktopManager: Another Redis Desktop Manager 是一款跨平台的Redis桌面管理工具,提供图形用户界面,支持连…...