kubernetes(k8s) 知识总结(第2期)
1. “控制器”思想
kube-controller-manager 是一系列控制器的集合,这些控制器被放在 Kubernetes 项目的 pkg/controller 目录,这些控制器都以独有的方式负责某种编排功能。它们都遵循一个通用的编排模式——控制循环。
以 Deployment 为例介绍它对控制器模型的实现:
(1)Deployment 控制器从 etcd 中获取所有携带了 app: nginx 标签的 Pod,然后统计它们的数量,这就是实际状态。
(2)Deployment 对象的 Replicas 字段的值就是期望状态。
(3)Deployment 控制器比较两个状态,然后根据结果确定是创建 Pod 还是删除已有的 Pod。
一个 Kubernetes 对象的主要编排逻辑是在对比阶段完成的,这个操作称为调谐(reconcile)。调谐的过程称作调谐循环或者同步循环。
Deployment 定义的 template 字段在 Kubernetes 中有一个专属的名字:PodTemplate。
2. Deployment & ReplicaSet
如果你更新了 Deployment 的 Pod 模板,那么 Deployment 就要遵循一种叫作滚动更新的方式,来升级现有容器。这个能力的实现依赖 Kubernetes 中的一个非常重要的概念:ReplicaSet。
例子:
apiVersion: apps/v1
kind: ReplicaSet
metadata:name: nginx-setlabels:app: nginx
spec:replicas: 3selector:matchLabels:app: nginxtemplate:metadata:labels:app: nginxspec:containers:- name: nginximage: nginx:1.7.9一个 ReplicaSet 对象是又副本数目的定义和一个 Pod 模板组成的。它的定义其实是一个 Deployment 的一个子集。更重要的是,Deployment 控制器实际上操纵的是 ReplicaSet 对象,而不是 Pod 对象。看下边的 Deployment 定义:
apiVersion: apps/v1
kind: Deployment
metadata:name: nginx-deploymentlabels:app: nginx
spec:replicas: 3selector:matchLabels:app: nginxtemplate:metadata:labels:app: nginxspec:containers:- name: nginximage: nginx:1.7.9ports:- containerPort: 80Deployment、ReplicaSet 和 Pod 的关系如下图所示:
ReplicaSet 负责通过控制器模式保证系统中 Pod 的个数永远等于指定个数。这也是 Deployment 只允许容器的 restartPolicy=Always 的原因:只有在容器保证自己始终处于 Running 状态的前提下,ReplicaSet 调整 Pod 的个数才有意义。在此基础上,Deployment 同样通过控制器模式来操作 ReplicaSet 的个数和属性,进而实现水平扩展/收缩和滚动更新。
水平扩展/收缩非常容易实现,Deployment Controller 只需要修改它所控制的 ReplicaSet 的 Pod 的副本数就可以了,这个指令是 kubectl scale:
kubectl scale deployment nginx-deployment --replicas=4滚动更新的过程如下:
首先创建 Deployment:
$ kubectl create -f nginx-deployment.yaml --record检查这个 Deployment 状态信息:
$ kubectl get deployments
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
nginx-deployment 3 0 0 0 1s这几个字段的含义如下所示:
(1)DESIRED:用户期望的 Pod 副本个数(spec.replicas 的值)。
(2)CURRENT:当前处于 Running 状态的 Pod 的个数。
(3)UP-TO-DATE:当前处于最新版本的 Pod 的个数。所谓最新版本,指的是 Pod 的 Spec 部分与 Deployment 里 Pod 模板里定义的完全一致。
(4)AVAILABLE:当前已经可用的 Pod 的个数,即既是 Running 状态,又是最新版本,并且已处于 Ready(健康检查显示正常)状态的 Pod 的个数。
这个 AVAILABLE 字段描述的才是用户所期望的最终状态。
可以使用以下指令,实时查看 Deployment 对象的状态变化:
kubectl rollout status deployment/nginx-deployment一段时间后,可以看到 Deployment 的 3 个 Pod 进入了 AVAILABLE 状态:
$ kubectl get deployments
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
nginx-deployment 3 3 3 3 20s此时可以查看这个 Deployment 所控制的 ReplicaSet:
$ kubectl get rs
NAME DESIRED CURRENT READY AGE
nginx-deployment-****** 3 3 3 20s在用户提交了一个 Deployment 对象后,Deployment Controller 会立即创建一个 Pod 副本数为 3 的 ReplicaSet。这个 ReplicaSet 的名字由 Deployment 的名字和一个随机字符串共同组成。这个随机字符串叫作 pod-template-hash。ReplicaSet 会把这个随机字符串加在它所控制的所有 Pod 的标签里,从而避免这些 Pod 与集群里其他 Pod 混淆。
ReplicaSet 的 DESIRED、CURRENT 和 READY 字段的含义和 Deployment 中是一致的。所以,Deployment 是在 ReplicaSet 的基础上添加了 UP-TO-DATE 这个跟版本有关的字段。
这时,修改 Deployment 中的 Pod 模板,就会自动触发“滚动更新”。Deployment Controller 会使用修改后的 Pod 模板创建一个新的 ReplicaSet,这个新的 ReplicaSet 初始 Pod 副本数为 0。随后,Deployment Controller 逐步将旧 ReplicaSet 管理的 Pod 的副本数从 3 变成 0,将新的 ReplicaSet 管理的 Pod 的副本数从 0 变成 3。为了保证服务的连续性,Deployment Controller 会确保在任何时间窗口内,只有指定比例的 Pod 处于离线状态,只有指定比例的新 Pod 被创建出来,这两个值默认都是 DESIRED 值的 25%。这个字段叫 RollingUpdateStrategy,其中 maxSurge 指定的是除 DESIRED 数量外,在一次滚动更新中 Deployment Controller 还能创建多少新的 Pod,而 maxUnavailable 指的是在一次滚动更新中 Deployment Controller 可以删除多少旧的 Pod。这两个配置还可以用百分比表示,表示的是 DESIRED 数量乘以百分比的值。
如图所示,Deployment Controller 实际控制的是 ReplicaSet 的数目,以及每个 ReplicaSet 的属性。一个应用的版本对应的正是一个 ReplicaSet,这个版本应用的 Pod 数量由 ReplicaSet 通过它自己的控制器(ReplicaSet Controller)来保证。通过多个这样的 ReplicaSet 对象,Kubernetes 项目就实现了对多个应用版本的描述。
在升级过程中,如果镜像出现错误,新版本的 ReplicaSet 的水平扩展将会停止,其中的 Pod 状态非 READY。旧版本的 ReplicaSet 的水平收缩也停止。这时,使用以下命令就可以回滚到上一个版本:
kubectl rollout undo deployment/nginx-deployment如果想回滚到更早之前的版本,可以先查看历史版本:
kubectl rollout history deployment/nginx-deployment查看具体版本的细节:
kubectl rollout history deployment/nginx-deployment --revision=2回滚:
kubectl rollout undo deployment/nginx-deployment --to-revision=2如果担心每次更新系统都会产生新的 ReplicaSet,导致资源浪费,可以使用一种方法让我们的多次操作只产生一个 ReplicaSet,先执行以下指令:
kubectl rollout pause deployment/nginx-deployment之后就可以随意使用 kubectl edit 或 kubectl set image 修改 Deployment 了,修改之后执行:
kubectl rollout resume deployment/nginx-deploymentDeployment 有一个 spec.revisionHistoryLimit 字段,可以控制历史版本个数。
3. StatefulSet
分布式应用的多个实例之间往往有依赖关系,比如主从关系、主备关系;还有数据存储类应用的多个实例往往会在本地磁盘保存一份数据。这种实例之间有不对等关系,以及实力对外部数据有依赖关系的应用,就是有状态应用。
apiVersion: apps/v1
kind: StatefulSet
metadata:name: web
spec:serviceName: "nginx"replicas: 2selector:matchLabels:app: nginxtemplate:metadata:labels:app: nginxspec:containers:- name: nginximage: nginx:1.9.1ports:- containerPort: 80name: web这个 YAML 文件和 Deployment 的唯一区别就是多了一个 serviceName=nginx 字段,这个字段的作用就是告诉 StatefulSet 控制器,在执行控制循环时请使用 nginx 这个 Headless Service 来保证 Pod 可解析。
StatefulSet 给它所管理的所有 Pod 的名字进行了编号,这些编号是从 0 开始累加的,不重复。每个 Pod 对应不同的 Headless Service,也就意味着每个 Pod 拥有独一无二的 IP 地址。
StatefulSet 这个控制器的主要作用之一,就是使用 Pod 模板创建 Pod 时对它们进行编号,并且按照编号顺序逐一完成创建工作。而当 StatefulSet 的“控制循环”发现 Pod 的实际状态与期望状态不一致,需要新建或者删除 Pod 以进行“调谐”时,它会严格按照这些 Pod 编号的顺序逐一完成这些操作。通过 Headless Service 的方式,StatefulSet 为每一个 Pod 创建了一个固定并且稳定的 DNS 记录,来作为它的访问入口。
想使用一个 Volume,只需要以下两步:
第一步,定义一个 PVC,声明想要的 Volume 属性:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:name: pv-claim
spec:accessModes:- ReadWriteOnceresources:requests:storage: 1Gi第二步,在应用的 Pod 中声明使用这个 PVC:
apiVersion: v1
kind: Pod
metadata:name: pv-pod
spec:containers:- name: pv-containerimage: nginxports:- containerPort: 80name: "http-server"volumeMounts:- mountPath: "/usr/share/nginx/html"name: pv-storagevolumes:- name: pv-storagepersistentVolumeClaim:claimName: pv-claim在这个 Pod 的 Volumes 定义中,只需要声明它的类型是 persistentVolumeClaim,然后指定 PVC 的名字,完全不必关心 Volume 本身的定义。
此时,只要创建这个 PVC 对象,Kubernetes 就会自动为它绑定一个符合条件的 Volume。这些符合条件的 PV 来自运维人员维护的 PV 对象:
apiVersion: v1
kind: PersistentVolume
metadata:name: pv-volumelabels:type: local
spec:capacity:storage: 10Girbd:monitors:- '10.16.154.78:6789'- '10.16.154.82:6789'- '10.16.154.83:6789'pool: kubeimage: foofsType: ext4readOnly: trueuser: adminkeyring: /etc/ceph/keyringimageformat: "2"imagefeatures: "layering"Kubernetes 就会为我们创建的 PVC 对象绑定这个 PV。
以上边的 StatefulSet 为例,添加一个 volumeClaimTemplates 字段:
apiVersion: apps/v1
kind: StatefulSet
metadata:name: web
spec:serviceName: "nginx"replicas: 2selector:matchLabels:app: nginxtemplate:metadata:labels:app: nginxspec:containers:- name: nginximage: nginx:1.9.1ports:- containerPort: 80name: webvolumeMounts:- name: wwwmountPath: /usr/share/nginx/htmlvolumeClaimTemplates:- metadata:name: wwwspec:accessModes:- ReadWriteOnceresources:requests:storage: 1Gi凡是被这个 StatefulSet 管理的 Pod,都会声明一个对应的 PVC,这个 PVC 的定义就来自 volumeClaimTemplates 字段。这个 PVC 的名字会被分配一个与这个 Pod 完全一致的编号。这个自动创建的 PVC 与 PV 绑定成功后就会进入 Bound 状态,这就意味着这个 Pod 可以挂在并使用这个 PV 了。
在创建了 StatefulSet 之后,集群里出现两个 PVC,命名格式都是<PVC 名字>-<StatefulSet 名字>-<编号>,且处于 Bound 状态。
梳理一下 StatefulSet 的工作原理:
首先,StatefulSet 的控制器直接管理的是 Pod。其次,Kubernetes 通过 Headless Service 为这些有编号的 Pod 在 DNS 服务器中生成带有相同编号的 DNS 记录。最后,StatefulSet 还为每个 Pod 分配并创建一个相同编号的 PVC。
4. DaemonSet
DaemonSet 的主要作用是在 Kubernetes 集群中运行一个 Daemon Pod。这个 Pod 有三个特征:
① 这个 Pod 在集群里的每一个节点上运行
② 每个节点上只有一个这样的 Pod 实例
③ 当有新节点加入 Kubernetes 集群后,该 Pod 会自动地在新节点上被创建出来;而当旧节点被删除后,它上面的 Pod 也会相应地被回收。
常用的例子有:
各种网络插件的 Agent 组件、各种存储插件的 Agent 组件、各种监控组件和日志组件必须在每一个节点上运行。
apiVersion: apps/v1
kind: DaemonSet
metadata:name: fluentd-elasticsearchnamespace: kube-systemlabels:k8s-app: fluentd-logging
spec:selector:matchLabels:name: fluentd-elasticsearchtemplate:metadata:labels:name: fluentd-elasticsearchspec:tolerations:- key: node-role.kubernetes.io/mastereffect: NoSchedulecontainers:- name: fluentd-elasticsearchimage: quay.io/fluentd_elasticsearch/fluentd:v3.0.0resources:limits:memory: 200Mirequests:cpu: 100mmemory: 200MivolumeMounts:- name: varlogmountPath: /var/log- name: varlibdockercontainersmountPath: /var/lib/docker/containersreadOnly: trueterminationGracePeriodSeconds: 30volumes:- name: varloghostPath:path: /var/log- name: varlibdockercontainershostPath:path: /var/lib/docker/containers这个 DaemonSet 管理的是一个 fluentd-elasticsearch 镜像的 Pod,功能是通过 fluentd 将 Docker 中的日志转发到 Elasticsearch 中。
可以看到,DaemonSet 跟 Deployment 非常相似,只不过没有 replicas 字段;他也使用 selector 选择管理所有携带了 name: fluentd-elasticsearch 标签的 Pod。这些 Pod 的模板也是用 template 字段定义的。在该字段中,定义了一个使用 fluentd-elasticsearch:1.20 镜像的容器,而且该容器挂载了两个 hostPath 类型的 Volume,分别对应宿主机的 /var/log 目录和 /var/lib/docker/containers 目录。
DaemonSet 如何保证每个节点上有且只有一个被管理的 Pod 呢?DaemonSet Controller 首先从 etcd 里获取所有的节点列表,然后遍历所有节点,这时,就很容易检查当前节点是否有一个携带了 name: fluentd-elasticsearch 标签的 Pod 在运行。
检查的结果可能有3种情况:
(1)没有这种 Pod,这就意味着要在该节点上创建这样一个 Pod
(2)有这种 Pod,但是数量大于1,说明要删除该节点上多余的 Pod
(3)正好只有一个这种 Pod,说明该节点是正常的
如何在指定节点上新建 Pod ?可以使用 nodeSelector。不过,nodeSelector 已经是一个将要被废除的字段了,最好使用 nodeAffinity 代替它:
apiVersion: v1
kind: Pod
metadata:name: with-node-affinity
spec:affinity:nodeAffinity:requiredDuringSchedulingIgnoredDuringExecution:nodeSelectorTerms:- matchExpressions:- key: metadata.nameoperator: Invalues:- node-ituringrequiredDuringSchedulingIgnoredDuringExecution 的意思是这个 nodeAffinity 必须在每次调度时予以考虑,也意味着可以设置在某些情况下不考虑这个 nodeAffinity。这个 Pod 将来只允许在 metadata.name 是 node-ituring 的节点上运行。
此外,DaemonSet 还会给这个 Pod 自动加上另外一个与调度有关的字段:tolerations。这意味着这个 Pod 会“容忍”某些节点上的“污点”(Taint)。
apiVersion: v1
kind: Pod
metadata:name: with-toleration
spec:tolerations:- key: node.kubernetes.io/unschedulableoperator: Existseffect: NoSchedule这个 Toleration 的含义是:“容忍”所有被标记为 unschedulable “污点”的节点,“容忍”的效果是允许调度。在正常情况下,被加上 unschedulable “污点”的节点是不会有任何 Pod 被调度上去的。但是,DaemonSet 自动地给被管理的 Pod 加上了这个特殊的 Toleration, 就使得这些 Pod 可以忽略这项限制,继而保证每个节点上都会被调度一个 Pod。
5. Job 与 CronJob
有一类作业属于“离线业务”,也叫 Batch Job(计算业务)。这种业务在计算完成后就直接退出了。
Job API 对象的定义非常简单,示例如下:
apiVersion: batch/v1
kind: Job
metadata:name: pi
spec:template:spec:containers:- name: piimage: resouer/ubuntu-bccommand: ["sh", "-c", "echo 'scale=10000; 4*a(1)' | bc -l "]restartPolicy: NeverbackoffLimit: 4在这个 Job 的 YAML 文件中,可以看到 Pod 模板:spec.template。在这个模板中,定义了一个 Ubuntu 镜像的容器,它运行的程序是:echo 'scale=10000; 4*a(1)' | bc -l 。
在一个 Job 对象创建后,它的 Pod 模板被自动加上了一个 controller-uid=<随机字符串> 这样的 Label。而这个 Job 对象本身被自动加上了这个 Label 对应的 Selector,从而保证了 Job 与它所管理的 Pod 之间的匹配关系。
在 Pod 模板中定义 restartPolicy=Never 的原因是离线计算的 Pod 永远不应该被重启。事实上,restartPolicy 在 Job 对象里只允许设置为 Never 和 OnFailure;而在 Deployment 对象里,restartPolicy 只允许设置为 Always。
如果一个离线作业失败了,Job Controller 就会不断尝试创建一个新 Pod。当然,这个尝试肯定不能无限进行下去。所以,就在 Job 对象的 spec.backoffLimit 字段里定义了重试次数为4,这个字段的默认值为6。
需要注意的是,Job Controller 重新创建 Pod 的间隔是呈指数级增加的,即下一次重新创建 Pod 的动作会分别发生在 10s、20s、40s... 后。
在 Job 的 API 对象里,有一个 spec.activeDeadlineSeconds 字段可以限制运行时长。一旦超过这个时间,这个 Job 的所有 Pod 都会被终止。并且,你可以在 Pod 的状态里看到终止的原因: reason: DeadlineExceeded。
在 Job 对象中,负责并行控制的参数有两个:
(1)spec.parallelism 定义的是一个 Job 在任意时间最多可以启动多少个 Pod 同时运行。
(2)spec.completions 定义的是 Job 至少要完成的 Pod 的数目。
下面,介绍一个非常有用的 Job 对象:CronJob:
apiVersion: batch/v1beta1
kind: CronJob
metadata:name: hello
spec:schedule: "* * * * *"jobTemplate:spec:template:spec:containers:- name: helloimage: busyboxargs:- /bin/sh- -c- date; echo Hello from the Kubernetes clusterrestartPolicy: OnFailure最重要的关键词是 jobTemplate,这就意味着,CronJob 是一个 Job 对象的控制器。它创建和删除 Job 的依据是 schedule 字段定义的、一个标准的 Unix Cron 格式的表达式。
由于定时任务的特殊性,很可能某个 Job 还没有执行完,另一个新的 Job 就产生了。可以通过 spec.concurrencyPolicy 字段来定义具体的处理策略:
(1)concurrencyPolicy=Allow,这是默认情况,意味着这些 Job 可以同时存在。
(2)concurrencyPolicy=Forbid,这意味着不会创建新的 Pod。
(3)concurrencyPolicy=Replace,这意味着新产生的 Job 会替换旧的、未执行完的 Job。
如果某一次 Job 创建失败,这次创建就会被标记为“miss”。在指定时间窗口内 miss 的数目达到 100 时,CronJob 会停止再创建这个 Job。这个时间窗口可以由 spec.startingDeadlineSeconds 字段指定。
相关文章:
kubernetes(k8s) 知识总结(第2期)
1. “控制器”思想 kube-controller-manager 是一系列控制器的集合,这些控制器被放在 Kubernetes 项目的 pkg/controller 目录,这些控制器都以独有的方式负责某种编排功能。它们都遵循一个通用的编排模式——控制循环。 以 Deployment 为例介绍它对控…...

windows-Mysql的主从数据库同步设置
复制原有的mysql修改my.ini配置文件 修改端口号修改从数据的地址和从数据库的数据存放地址安装从数据库进入从数据库的bin目录,打开命令窗口输入命令:mysqld.exe install mysql-back --defaults-file "C:\ProgramData\MySQL\MySQL Server 5.7-back\…...

Docker逃逸
文章目录原理环境搭建Docker 环境判断Docker 容器逃逸特权模式逃逸如何判断是否为特权模式逃逸docker.sock挂载逃逸逃逸Remote API未授权访问未授权访问逃逸容器服务缺陷逃逸影响版本环境搭建逃逸脏牛漏洞逃逸参考原理 docker其实就是一个linux下的进程,它通过Name…...

k8s项目部署
k8s命令k8s项目部署部署流程实现导出相应的yaml文件 kubectl create deployment 名字--image镜像-o yaml --dry-runclient > 文件名 例: kubectl create deployment nginx --imagenginx -o yaml --dry-runclient > m1.yaml导出已经部署后的yaml文件 kubectl g…...

Modbus通信协议学习笔记
Modbus主从设备 主控设备(Modbus Master):工控机、PLC、触摸屏等等 从设备(Modbus Slave):PLC、Modbus采集模块、带485通讯的传感器、仪器仪表等等 Modbus物理接口:串口(RS232、RS4…...

ubuntu重启、关机命令
// // // //之前用linux系统, 一键解决也是可以的,反正我每次用命令(泪目…),中间崩了好几次,换回win,此篇也做记录 // // // 重启命令 以下所有命令在root根目录下输入(普通用户&…...

Xshell 7 连接云服务器的步骤和出现的错误
一、工具准备云服务器Xshell 7二、使用 Xshell 7 连接数据库三、新建会话属性后,没有自动弹出 SSH 用户名要求输入四、SSH 用户身份验证不能输入 Password五、Xshell 连接 centos 7 服务器 报错提示 “ssh服务拒绝了密码,请再试一次“,但是密…...
Python多进程同步——文件锁
多个进程共享同一份资源(共享内存、文件等)时,会涉及到资源竞争问题。为了解决这种问题,一般采取的措施是进程在访问资源前加锁保护,避免多个进程同时读写。本文介绍的Python文件锁可以用来解决多进程的同步问题。 目录…...

实现 element-plus 表格多选时按 shift 进行连选的功能
前言 element-plus表格提供了多选功能,可单击勾选一条数据,可全选。 现在有个很合理的需求,希望实现类似于文件系统中shift连续选择功能,并且在表格排序后,依照排序后的顺序连选。 一、el-table 多选表格基本使用 1、…...
)
华为OD机试真题JAVA实现【考古学家】真题+解题思路+代码(20222023)
🔥系列专栏 华为OD机试(JAVA)真题目录汇总华为OD机试(Python)真题目录汇总华为OD机试(C++)真题目录汇总华为OD机试(JavaScript)真题目录汇总文章目录 🔥系列专栏题目输入输出示例一输入输出说明示例二输入输出说明...
Spring3之基于Aspect实现AOP
简介 使用 Aspect 搭配 Spring 可轻松实现 AOP;本章将通过一个完整示例演示如何实现这一功能 实现步骤 修改 beans.xml 配置文件的 schema 部分;可以在 spring-framework-reference.html 文件通过搜索关键字 “/aop” 找到配置 schema,然后…...
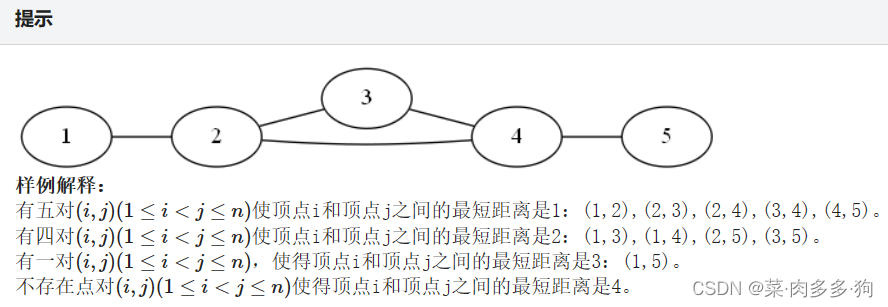
buctoj-寒假集训进阶训练赛(二十二)
问题 A: Stones 题目描述 由于自行车状态错误,森普尔开始每天早上从东到西走,每天晚上走回去。走路可能会有点累,所以森普这次总是玩一些游戏。 路上有很多石头,当他遇到一块石头时,如果是他遇到的奇数石头࿰…...
)
华为OD机试真题JAVA实现【静态扫描最优成本】真题+解题思路+代码(20222023)
🔥系列专栏 华为OD机试(JAVA)真题目录汇总华为OD机试(Python)真题目录汇总华为OD机试(C++)真题目录汇总华为OD机试(JavaScript)真题目录汇总文章目录 🔥系列专栏题目输入输出描述示例一输入输出说明示例二输入输出说明...
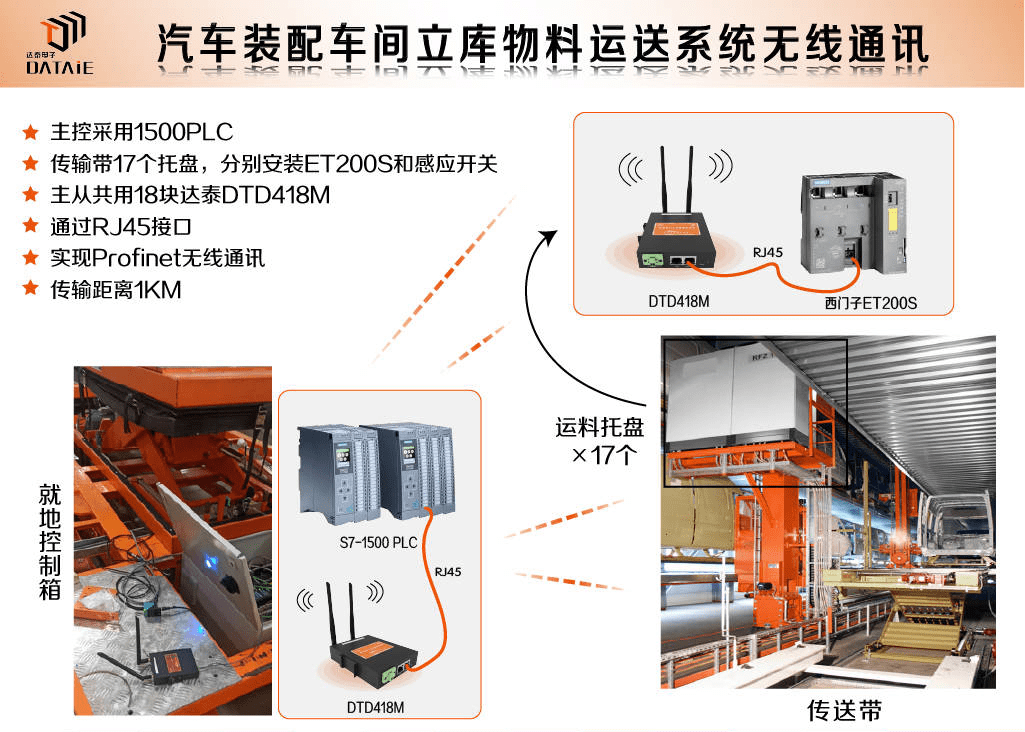
汽车装配工厂立库物料运送线PLC无线应用
一、应用背景此次项目地在比亚迪的西安工厂,需要实现PLC无线通讯的地方是汽车厂的立体仓库物料运输线。生产物流担负运输、存储、装卸物料等任务。汽车制造业是典型的多工种、多工艺、多物料的大规模生产过程,因此原材料与零部件必需及时准确送至工位&am…...

Python雪花代码
前言 用python画个雪花玩玩,源码在文末公众号哈。 雪花类 class Snow(): #雪花类 def __init__(self): self.r 6 #雪花的半径 self.x ra.randint(-1000,1000) #雪花的横坐标 self.y ra.randint(-500,5…...
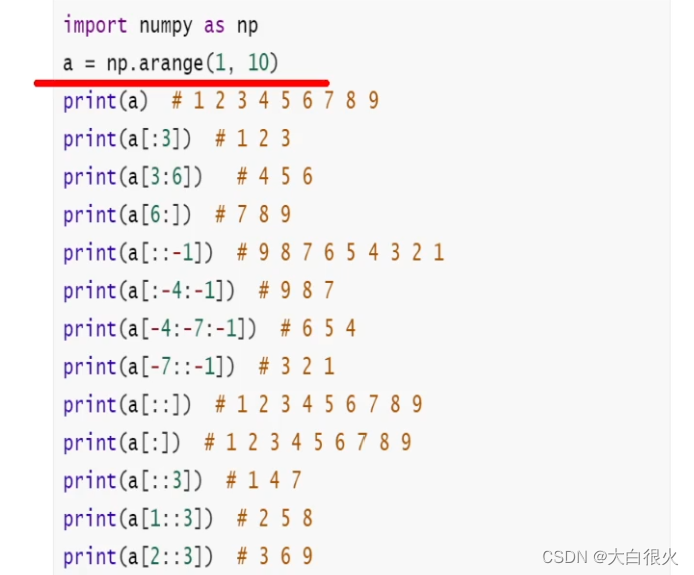
Numpy基础与实例——人工智能基础
文章目录一、Numpy概述1. 优势2. numpy历史3. Numpy的核心:多维数组4. 内存中的ndarray对象4.1 元数据(metadata)4.2 实际数据二、numpy基础1. ndarray数组2. arange、zeros、ones、zeros_like3. ndarray对象属性的基本操作3.1 修改数组维度3…...

MQTT的工作原理
介绍MQTT协议的消息模型,消息传输过程,消息发布和订阅。 一、介绍MQTT协议的消息模型 MQTT协议的消息模型被称为“主题”模型。在这种模型中,服务器接收到的消息将通过主题进行分类。客户端可以通过订阅一个或多个主题来接收所需的消息。 1.1 消息主题 1.2 消息内容 1.…...

iOS开发:UINavigationController自定义返回按钮,系统导航支持侧滑返回
当你使用系统导航想拦截用户返回事件时,无法拦截侧滑返回 当你自定义导航或者隐藏导航后,iOS系统导航的侧滑返回就失效了,那么用户体验将大打折扣 网上大部分自定义导航的解决方案是:给页面添加全局的轻扫手势,那么又区别于原生系统,改变了用户的操作习惯 在开发过程中,…...
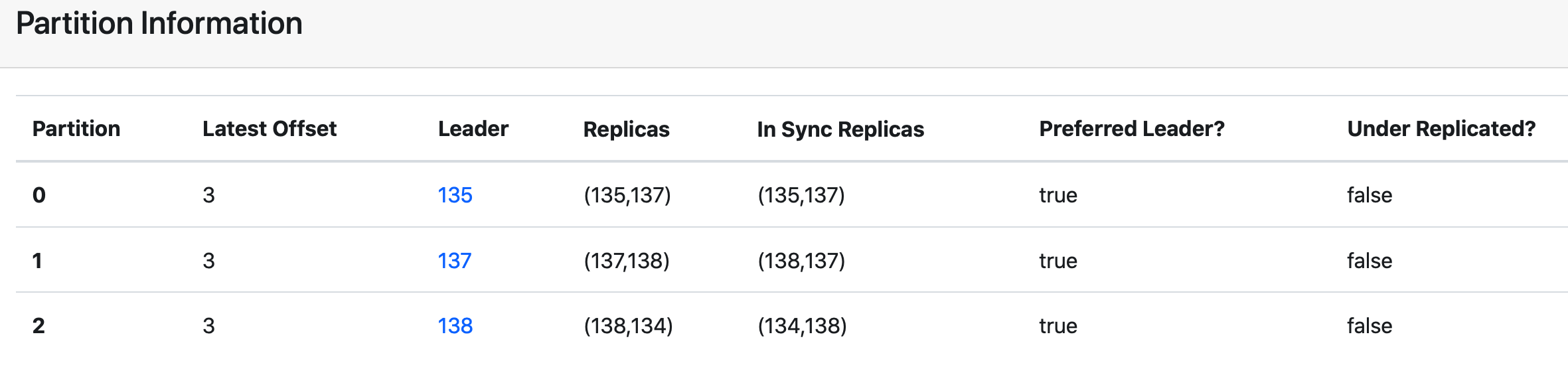
【Kafka进阶】-- unclean.leader.election.enable参数的内涵
一、背景近期,我们的kafka 消息队列集群(1.x版本)经过了一次事故。某节点意外宕机,导致 log 文件损坏,重启 kafka 失败,最后导致某个 topic 的分区不可用,本文对此做了简单的分析、解决和复现参考,以此为记…...
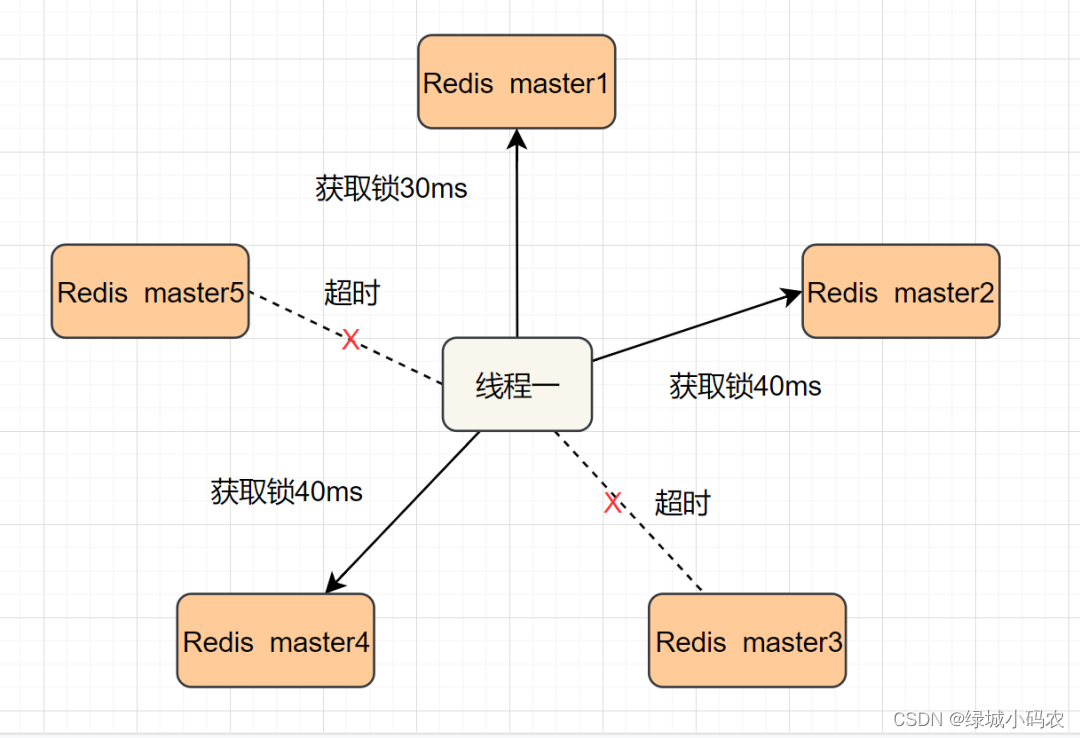
基于redis实现分布式锁
前言 我们的系统都是分布式部署的,日常开发中,秒杀下单、抢购商品等等业务场景,为了防⽌库存超卖,都需要用到分布式锁。 分布式锁其实就是,控制分布式系统不同进程共同访问共享资源的一种锁的实现。如果不同的系统或…...

降AI率软件数据安全测评:嘎嘎降不留存vs拿你论文训练AI!
降AI率软件数据安全测评:嘎嘎降不留存vs拿你论文训练AI! 一个月后导师消息:「你论文跟去年某高校论文相似度异常」 我硕士毕业季预算紧,搜降 AI 工具时格外注意「免费」「不限字数」这种关键词。找到一家工具——免费额度大、价…...

5分钟掌握暗黑2存档编辑:免费开源工具d2s-editor完全指南
5分钟掌握暗黑2存档编辑:免费开源工具d2s-editor完全指南 【免费下载链接】d2s-editor 项目地址: https://gitcode.com/gh_mirrors/d2/d2s-editor 还在为暗黑破坏神2重复刷装备而烦恼?想快速体验不同职业Build却不想从头练级?今天我要…...

AI与地缘政治双重冲击下,内存市场产能大迁移与供应链危机
1. 风暴之眼:当AI狂潮撞上地缘断供如果你最近想给电脑加条内存或者换个固态硬盘,大概率会被价格吓一跳。这不仅仅是简单的“涨价”,而是整个存储市场的底层逻辑正在被两股巨力彻底重塑。一边是AI数据中心对高性能内存近乎贪婪的吞噬ÿ…...

高频信号测量中的去嵌入技术原理与应用
1. 高频测量中的去嵌入技术本质在毫米波频段进行信号完整性测试时,我们常遇到一个棘手问题:测试夹具的电气特性会严重干扰被测器件(DUT)的真实性能表现。这就好比用一副劣质耳机试听高端音响系统——你永远无法分辨到底是音响本身…...

从人工到有机:数字健康AI的范式转变与工程实践
1. 从“人工”到“有机”:一次关于智能本质的范式转变在数字健康领域,我们每天都在与“人工智能”打交道。从辅助医生阅片的影像分析系统,到预测患者风险的算法模型,AI似乎已经成为推动医疗革新的核心引擎。然而,当我们…...

D3KeyHelper终极指南:5分钟上手暗黑3智能宏,轻松提升游戏体验
D3KeyHelper终极指南:5分钟上手暗黑3智能宏,轻松提升游戏体验 【免费下载链接】D3keyHelper D3KeyHelper是一个有图形界面,可自定义配置的暗黑3鼠标宏工具。 项目地址: https://gitcode.com/gh_mirrors/d3/D3keyHelper 还在为暗黑破坏…...

Latte文本到视频生成实战:打造个性化AI视频的终极指南
Latte文本到视频生成实战:打造个性化AI视频的终极指南 【免费下载链接】Latte [TMLR 2025] Latte: Latent Diffusion Transformer for Video Generation. 项目地址: https://gitcode.com/gh_mirrors/la/Latte Latte是一款基于TMLR 2025研究成果的文本到视频…...

Apache Arrow图像数据处理终极指南:如何构建高性能计算机视觉应用
Apache Arrow图像数据处理终极指南:如何构建高性能计算机视觉应用 【免费下载链接】arrow Apache Arrow is a multi-language toolbox for accelerated data interchange and in-memory processing 项目地址: https://gitcode.com/gh_mirrors/arrow13/arrow …...
)
手把手教你:在无外网环境下搞定VSCode插件离线安装(附下载地址拼接技巧)
企业内网开发环境高效配置指南:VSCode插件离线部署实战 在高度安全管控的企业研发环境中,外网隔离是常见的安全策略。当新入职的工程师第一次打开内网电脑上的VSCode时,面对空空如也的插件市场,那种无从下手的焦虑感我深有体会。三…...

VNote批量操作终极指南:如何一次处理百篇笔记提升效率 [特殊字符]
VNote批量操作终极指南:如何一次处理百篇笔记提升效率 🚀 【免费下载链接】vnote A pleasant note-taking platform in native C. 项目地址: https://gitcode.com/gh_mirrors/vn/vnote VNote批量操作是每个高效笔记用户必须掌握的技能!…...