elasticsearch 批量写入(Python版).md
1. 插入数据
现在我们如果有大量的文档(例如10000000万条文档)需要写入es 的某条索引中,该怎么办呢?
1.1 顺序插入
import time
from elasticsearch import Elasticsearches = Elasticsearch()def timer(func):def wrapper(*args, **kwargs):start = time.time()res = func(*args, **kwargs)print('共耗时约 {:.2f} 秒'.format(time.time() - start))return resreturn wrapper@timer
def create_data():""" 写入数据 """for line in range(100):es.index(index='s2', doc_type='doc', body={'title': line})if __name__ == '__main__':create_data() # 执行结果大约耗时 7.79 秒
1.2 批量插入
import time
from elasticsearch import Elasticsearch
from elasticsearch import helperses = Elasticsearch()def timer(func):def wrapper(*args, **kwargs):start = time.time()res = func(*args, **kwargs)print('共耗时约 {:.2f} 秒'.format(time.time() - start))return resreturn wrapper@timer
def create_data():""" 写入数据 """for line in range(100):es.index(index='s2', doc_type='doc', body={'title': line})@timer
def batch_data():""" 批量写入数据 """action = [{"_index": "s2","_type": "doc","_source": {"title": i}} for i in range(10000000)]helpers.bulk(es, action)if __name__ == '__main__':# create_data()batch_data() # MemoryError
我们通过elasticsearch模块导入helper,通过helper.bulk来批量处理大量的数据。首先我们将所有的数据定义成字典形式,各字段含义如下:
_index对应索引名称,并且该索引必须存在。_type对应类型名称。_source对应的字典内,每一篇文档的字段和值,可有有多个字段。
首先将每一篇文档(组成的字典)都整理成一个大的列表,然后,通过helper.bulk(es, action)将这个列表写入到es对象中。
然后,这个程序要执行的话——你就要考虑,这个一千万个元素的列表,是否会把你的内存撑爆(MemoryError)!很可能还没到没到写入es那一步,却因为列表过大导致内存错误而使写入程序崩溃!很不幸,我的程序报错了。下图是我在生成列表的时候,观察任务管理器的进程信息,可以发现此时Python消耗了大量的系统资源,而运行es实例的Java虚拟机却没什么变动。
解决办法是什么呢?我们可以分批写入,比如我们一次生成长度为一万的列表,再循环着去把一千万的任务完成。这样, Python和Java虚拟机达到负载均衡。
下面的示例测试10万条数据分批写入的速度
import time
from elasticsearch import Elasticsearch
from elasticsearch import helperses = Elasticsearch()def timer(func):def wrapper(*args, **kwargs):start = time.time()res = func(*args, **kwargs)print('共耗时约 {:.2f} 秒'.format(time.time() - start))return resreturn wrapper
@timer
def batch_data():""" 批量写入数据 """# 分批写# for i in range(1, 10000001, 10000):# action = [{# "_index": "s2",# "_type": "doc",# "_source": {# "title": k# }# } for k in range(i, i + 10000)]# helpers.bulk(es, action)# 使用生成器for i in range(1, 100001, 1000):action = ({"_index": "s2","_type": "doc","_source": {"title": k}} for k in range(i, i + 1000))helpers.bulk(es, action)if __name__ == '__main__':# create_data()batch_data() # 耗时 93.53 s
1.3 批量插入优化
采用 Python 生成器
import time
from elasticsearch import Elasticsearch
from elasticsearch import helperses = Elasticsearch()def timer(func):def wrapper(*args, **kwargs):start = time.time()res = func(*args, **kwargs)print('共耗时约 {:.2f} 秒'.format(time.time() - start))return resreturn wrapper
@timer
def gen():""" 使用生成器批量写入数据 """action = ({"_index": "s2","_type": "doc","_source": {"title": i}} for i in range(100000))helpers.bulk(es, action)if __name__ == '__main__':# create_data()# batch_data()gen() # 约90s
参考文章:
https://www.cnblogs.com/Neeo/articles/10788573.html
相关文章:
.md)
elasticsearch 批量写入(Python版).md
1. 插入数据 现在我们如果有大量的文档(例如10000000万条文档)需要写入es 的某条索引中,该怎么办呢? 1.1 顺序插入 import time from elasticsearch import Elasticsearches Elasticsearch()def timer(func):def wrapper(*arg…...
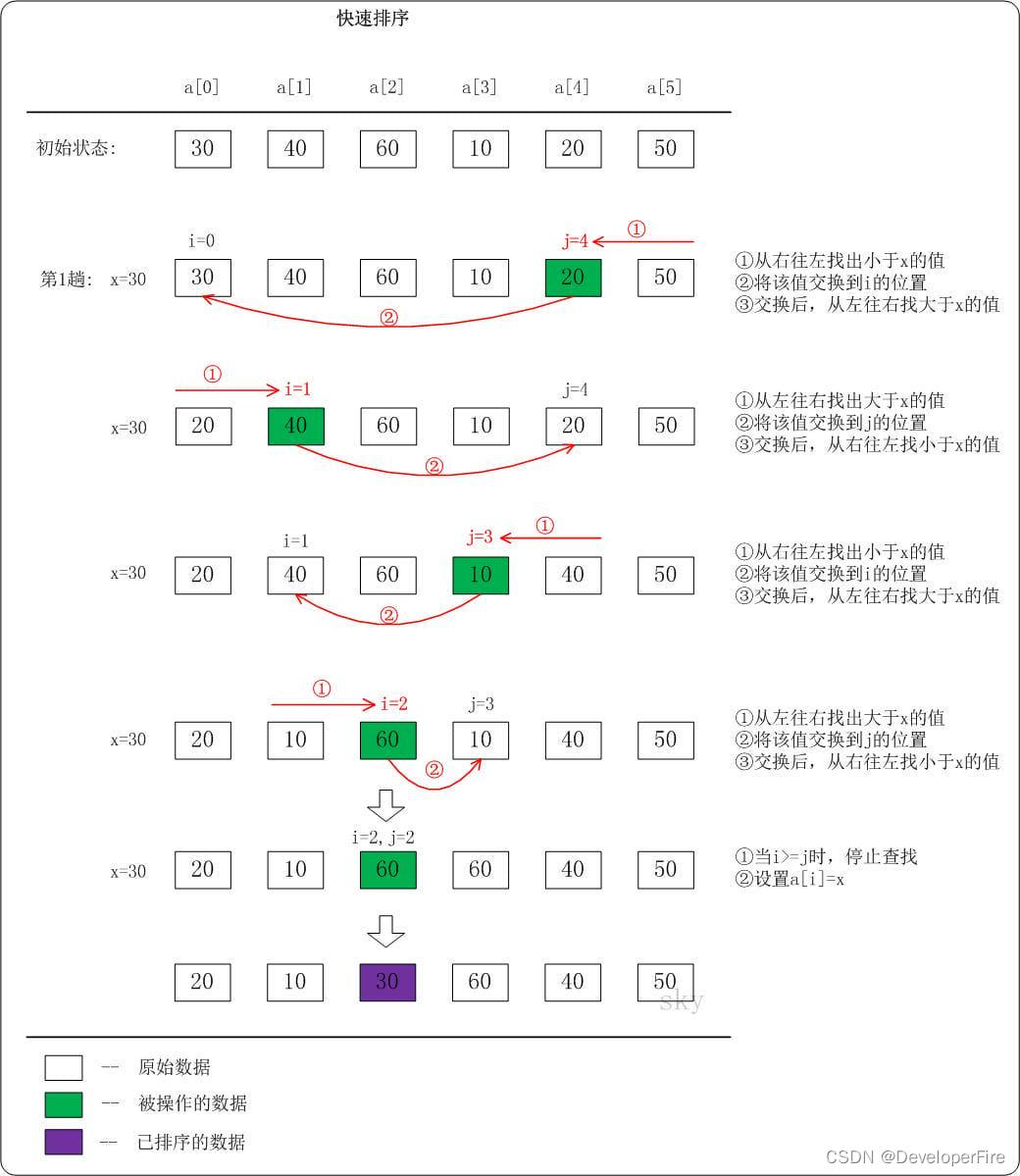
【排序算法】快速排序(Quick Sort)
快速排序(Quick Sort)使用分治法算法思想。快速排序介绍它的基本思想是: 选择一个基准数,通过一趟排序将要排序的数据分割成独立的两部分;其中一部分的所有数据都比另外一部分的所有数据都要小。然后,再按此方法对这两部分数据分别进行快速排…...
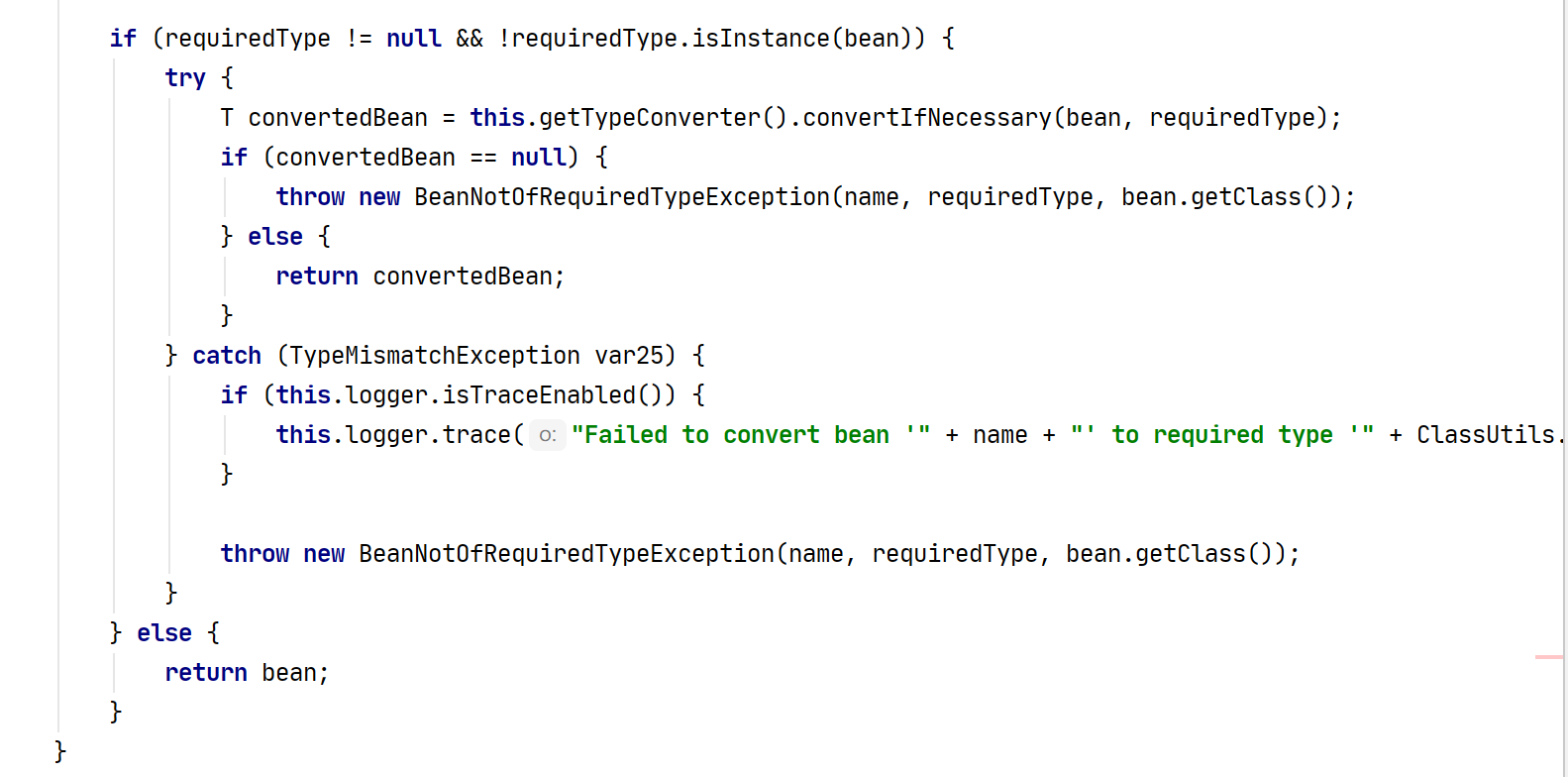
SpringIOC之创建Bean的核心方法doGetBean
概述面向资源(XML、Properties)、面向注解定义的 Bean 是如何被解析成 BeanDefinition(Bean 的“前身”),并保存至 BeanDefinitionRegistry 注册中心里面,实际也是通过 ConcurrentHashMap 进行保存。Spring…...

docker快速部署xxjob2.3.0-SpringBoot快速集成示例
xxjob 2.3.0 部署 参考资料 docker安装xxl-job-admin步骤_JEECG低代码平台的技术博客_51CTO博客 run前准备 1 新建数据库 xxl_job 2 建表sql(可以直接使) https://github.com/xuxueli/xxl-job/blob/master/doc/db/tables_xxl_job.sql建库sql # # XXL-JOB v2.4.0-SNAPSHOT…...
项目管理的前路,前辈能给一些意见吗?
什么是项目管理?关于项目管理的解释主要是基于国际项目管理三大体系不同的解释及本领域权威专家的解释!!!! 项目管理就是以项目为对象的系统管理方法,通过一个临时性的、专门的柔性组织,对项目进行高效率的计划、组织、指导和控制,…...

省钱的年轻人,钱包被折扣店钻了空子
【潮汐商业评论/原创】过年期间,除了商场超市,小区附近的折扣店成了Amy经常光顾的对象。用Amy的话来说,“跟附近超市比价格,跟大卖场比距离,综合下来折扣店就是我随时购物的不二选择。”从Amy的话里,我们可…...

【华为OD机试真题 js、python】优选核酸检测点、寻找核酸检测点【2022 Q4 100分】
代码请进行一定修改后使用,提供有js、python两种语言 题目描述 张三要去外地出差,需要做核酸,需要在指定时间点前做完核酸,请帮他找到满足条件的 核酸检测只点。 给出一组核酸检测点的距离和每个核酸检测点当前的人数给出张三要去做核酸的出发时间 出发时间是10分钟的倍数…...
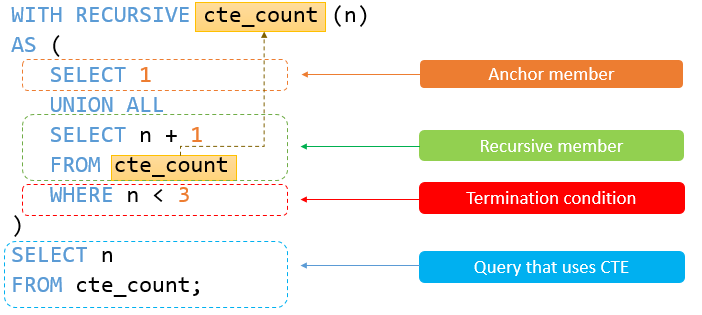
【MySQL】MySQL 8.0 新特性之 - 公用表表达式(CTE)
MySQL 8.0 新特性之 - 公用表表达式(CTE)1. 公用表表达式(CTE) - WITH 介绍1.1 公用表表表达式1.1.1 什么是公用表表达式1.1.2 CTE 语法1.1.3 CTE示例1.3 递归 CTE1.3.1 递归 CTE 简介1.3.2 递归成员限制1.3.3 递归 CTE 示例1.3.4…...

基础面试题:C++中如何理解const修饰符
面试题目:1、题 int i10; const int*p &i; int *const* p &i; const在不同位置有什么不 同 2、const 修饰类成员变量是有什么特殊要求 3、const 修饰类成员函数会发什么 4、const 对象有什么意义 目录 前言 一、const的意义 二、const使用规则 1.初始化…...
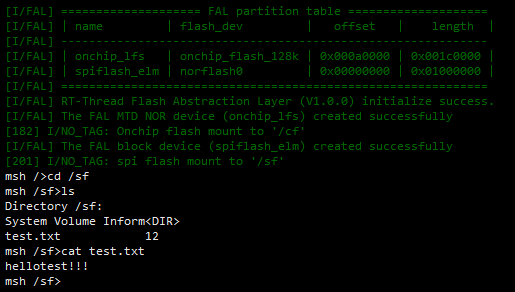
在RT-Thread STM32F407平台下配置SPI flash为U盘
记录下SPI Flash U盘实现过程中踩过的坑,与您分享。前提条件是,需要先将SPI Flash 配置到elm fal文件系统,并挂载成功。如下图然后开始配置USB1,在CubeMX,选择SUB_OTG_FS2 选择USB Device3,确认USB时钟为48…...

数据存储技术复习(二)未完
module3存储是数据中心内的核心元素。请说明常用的存储选项及其特点。磁盘驱动器:具有很大的存储容量,随机读/写访问闪存驱动器:使用半导体介质,提供高性能,低功耗2.若某磁盘驱动器显示每个磁道有八个扇区&…...

使用 QuTrunk+Amazon Deep Learning AMI(TensorFlow2)构建量子神经网络
量子神经网络是基于量子力学原理的计算神经网络模型。1995年,Subhash Kak 和 Ron Chrisley 独立发表了关于量子神经计算的第一个想法,他们致力于量子思维理论,认为量子效应在认知功能中起作用。然而,量子神经网络的典型研究涉及将…...
python selenium浏览器复用技术
使用selenium 做web自动化的时候,经常会遇到这样一种需求,是否可以在已经打开的浏览器基础上继续运行自动化脚本? 这样前面的验证码登录可以手工点过去,后面页面使用脚本继续执行,这样可以解决很大的一个痛点。 命令行…...

第二章:创建虚拟机
创建Windows server:首先第一步就是打开我们的vm,然后找到上一章讲的主页图标创建新的虚拟机。点击这上面类似的,然后转站。博文地址:https://blog.csdn.net/ryduijftgvhj/article/details/127934939?spm1001.2014.3001.5502视频…...

码上【call,apply,bind】的手写
一、call (1)官方用法 call() 方法使用一个指定的 this 值和单独给出的一个或多个参数来调用一个函数。 语法:function.call(要绑定的this值,参数,参数,…)。不一定这些参数都需要,这些参数都…...
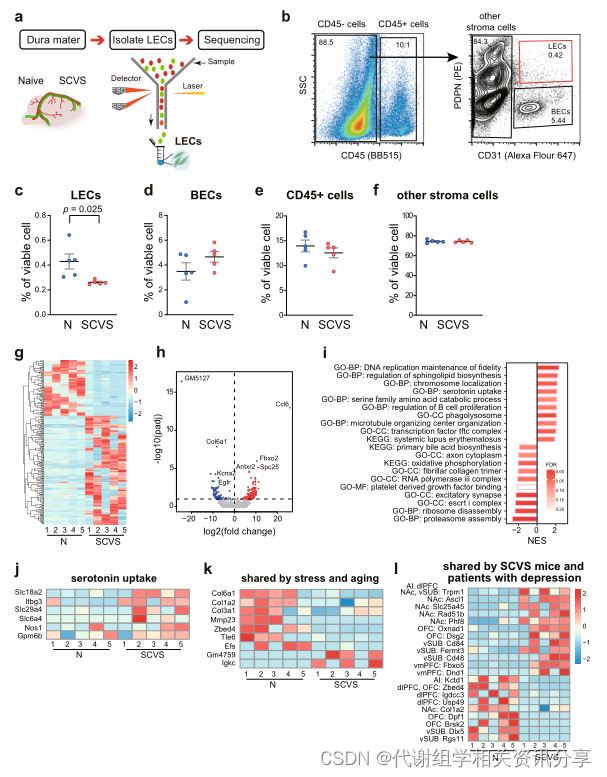
代谢组学Nature子刊!抑郁症居然“男女有别”,脑膜淋巴管起关键作用!
文章标题:A functional role of meningeal lymphatics in sex difference of stress susceptibility in mice 发表期刊:Nature Communications 影响因子:17.694 发表时间:2022年8月 作者单位:中山大学中山医学院 …...
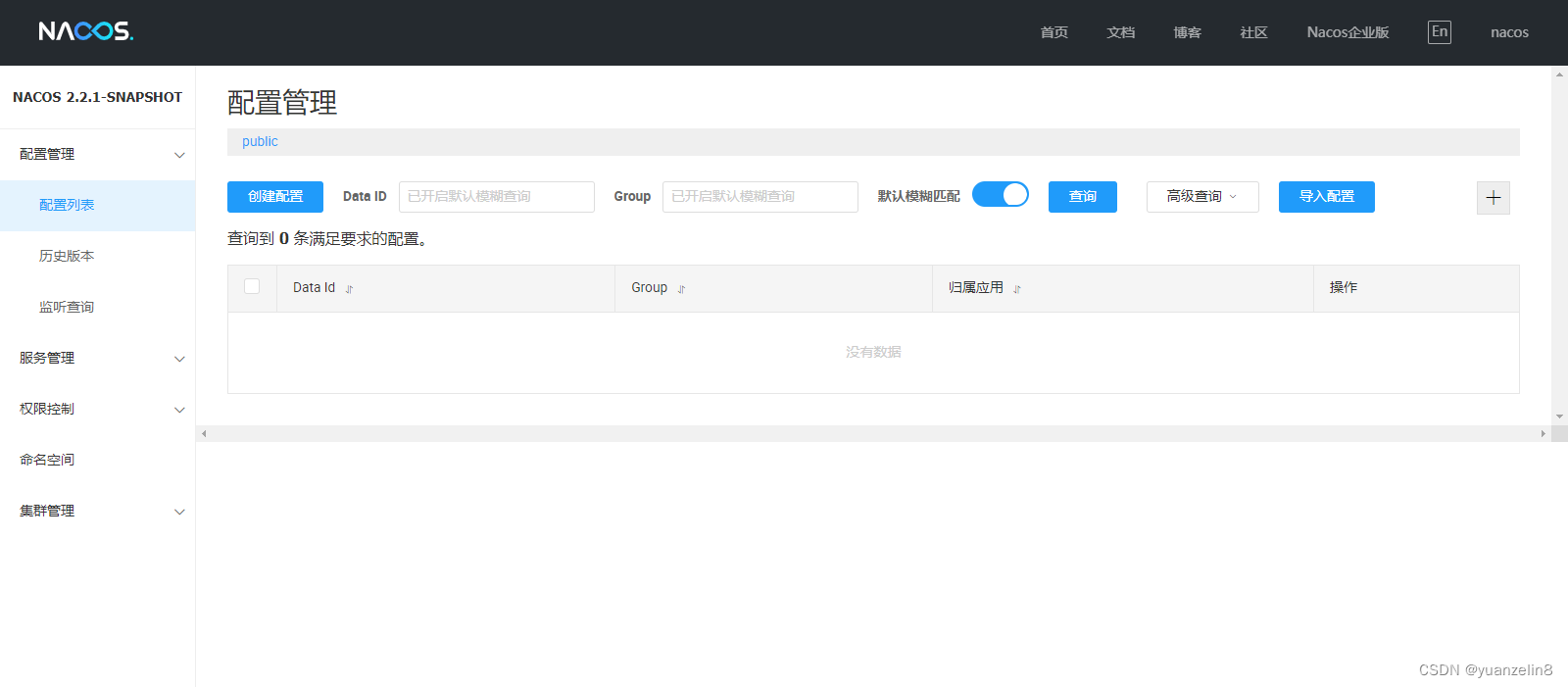
nacos配置中心搭建
网站每次更新版本都有短暂暂停,影响用户使用,返回经常不可用,需要改进 需要实现高可用,搭建负载均衡,实现jenkinsnacos不停机部署 nacos搭建预备环境准备 64 bit OS,支持 Linux/Unix/Mac/Windows&#x…...
uni-app低成本封装一个取色器组件
在uni-ui中找不到对应的工具 后面想想也是 移动端取色干什么? 没办法 也挂不住特殊需求 因为去应用市场下载 这总东西 又不是很有必要 那么 下面这个组件或许能解决您的烦恼 <template><view class"content"><view class"dialog&…...
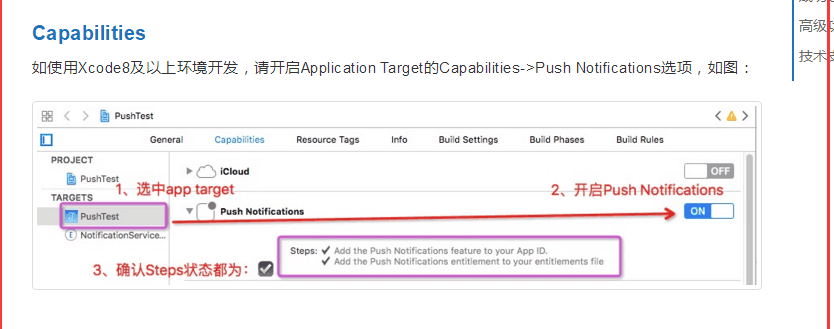
APP 怎么免费接入 MobPush
1、获取 AppKey 申请 Appkey 的流程,请点击 http://bbs.mob.com/thread-8212-1-1.html?fromuid70819 2、下载 SDK 下载解压后,如下图: 目录结构 (1)Sample:演示Demo。(2)SDK&am…...

XGBoost
目录 1.XGBoost推导示意图 2.分裂节点算法 Weighted Quantile Sketch 3.对缺失值得处理 1.XGBoost推导示意图 XGBoost有两个很不错得典型算法,分别是用来进行分裂节点选择和缺失值处理 2.分裂节点算法 Weighted Quantile Sketch 对于特征切点点得选择ÿ…...

Arm嵌入式编译器C/C++库架构与优化实践
1. Arm嵌入式编译器C/C库架构解析 1.1 运行时库体系结构 Arm Compiler for Embedded提供完整的C/C标准库实现,其架构设计遵循分层原则: 基础层 :ISO C99标准库(libc)提供字符串处理、内存管理、数学运算等基础功能 …...

3分钟拯救你的B站缓存视频:m4s-converter让珍贵回忆永不消失
3分钟拯救你的B站缓存视频:m4s-converter让珍贵回忆永不消失 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 你是否遇到过这样的困扰…...

避开BUUCTF《Life on Mars》的思维陷阱:当information_schema查询结果‘不对劲’时,你的排查清单应该有哪些?
破解BUUCTF《Life on Mars》的数据库迷局:当information_schema说谎时的七种侦查策略 在CTF赛场上,SQL注入类题目往往不会按教科书上的剧本发展。当你在BUUCTF《Life on Mars》这道题中执行group_concat(database()) from information_schema.schemata却…...

C语言核心知识体系总结
C语言核心知识体系总结本文旨在系统梳理C语言的基础与进阶知识点,帮助读者建立清晰的知识框架。内容涵盖:程序编译过程、数据类型与变量、运算符与表达式、控制结构、函数、指针、结构体与共用体、动态内存分配、文件操作等。适合复习巩固或查漏补缺。第…...

电力系统网络安全:从风险认知到威胁建模的实战指南
1. 从日常运维到风险认知:重新审视大容量电力系统的安全基线在能源行业干了十几年,我见过太多同行把大容量电力系统(Bulk Energy System, BES)的运维简化为“确保别停电”。日常的告警处理、设备巡检、工单流转构成了工作的全部叙…...

NVIDIA aicr:AI容器运行时核心原理与生产部署指南
1. 项目概述:当AI遇见容器运行时如果你在AI开发或者高性能计算领域摸爬滚打过一段时间,大概率会遇到一个让人头疼的问题:如何高效、稳定地管理那些“胃口”巨大、依赖复杂的AI工作负载?从训练一个大型语言模型到运行一个实时的计算…...

Git 入门教程:从命令行到 IDE 集成
文章目录Git 入门教程:从命令行到 IDE 集成一、环境准备与初始配置1.1 安装 Git1.2 配置用户身份2.2 查看仓库状态2.3 添加文件到暂存区2.4 提交文件到本地仓库2.5 查看历史版本2.6 版本回退2.7 删除文件三、Git 分支操作(多人协作核心)3.1 分…...

从零到一:手把手教你搭建MinGW-w64开发环境
1. 为什么需要MinGW-w64开发环境 第一次在Windows上写C代码时,我踩了个大坑:好不容易写完的代码,发现根本没法编译运行。这才意识到Windows不像Linux自带GCC编译器,需要额外搭建开发环境。MinGW-w64就是解决这个问题的神器&#x…...
用C++实现信奥题 P8563 Magenta Potion)
打卡信奥刷题(3245)用C++实现信奥题 P8563 Magenta Potion
P8563 Magenta Potion 题目描述 给定一个长为 nnn 的整数序列 aaa,其中所有数的绝对值均大于等于 222。有 qqq 次操作,格式如下: 1 i k\texttt{1 i k}1 i k,表示将 aia_iai 修改为 kkk。保证 $k $ 的绝对值大于等于 222。 2 l r…...

告别龟速!实测字节跳动Rust镜像源rsproxy.cn,安装rust和cargo快到飞起
Rust开发者福音:字节跳动镜像源rsproxy.cn全实测与避坑指南 上周深夜两点,我盯着终端里以KB/s为单位缓慢爬升的Rust安装进度条,第5次按下了CtrlC。作为一门以"零成本抽象"著称的语言,Rust的安装体验却让国内开发者付出了…...