【闲聊杂谈】高并发下基于LVS的负载均衡
1、使用http协议进行网络请求
在前几年公布的用户入网数据中,移动入网的数量已经达到六七亿的规模,固网用户数也达到三至五个亿。想要解决这么大并发访问的场景,有多种的解决方案,常规有基于4层的,也有基于7层的。这个4层和7层描述的就是OSI网络分层模型。

分层的目的主要还是为了方便解耦:
1、应用层就是直接面对用户(比如浏览器),这些软件都是直接和用户进行交互,对外提供服务的应用程序;
2、表示层同来指定协议、语义,字符串的加解密、显示等等;
3、会话层用来进行session相关的管理;
4、传输控制层用来建立连接,表示连接的建立成功或失败;
5、网络层负责设备间如何去路由、如何通信、数据包怎么发送等等;
6、链路层落实通信协议,具体到如何发送;
7、物理层中有很多具体的硬件设备,每种不同的设备设施最终的协议可能不一样;
分层的好处就是每一层都有专门的人员进行完善,每一层对其中的变更、升级、替换等,只要对外的接口不变,里面具体的实现可以随便改。在win系统下,有成品的浏览器,直接输入网址就可以对网站进行请求。如果放在Linux系统下, 没有浏览器的情况,改如何将一个网站的页面请求回来?
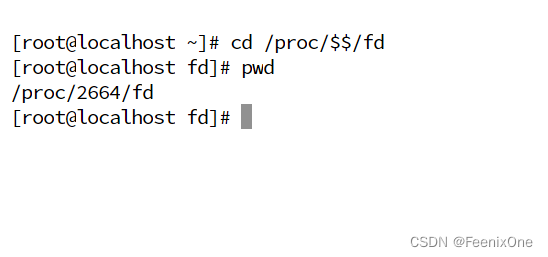
cd /proc/$$/fd($$ 代表当前进程的进程ID,fd 是文件描述符)
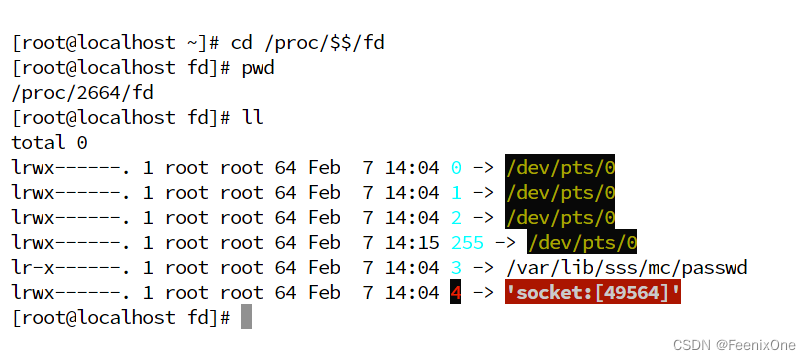
exec 8<> /dev/tcp/www.baidu.com/80(和百度进行握手,创建通信 )

echo -e 'GET / HTTP/1.0\n' >& 8(echo的意思是打印,-e是识别后面字符串中的\n作为换行符,>是输出,&是指后面的8是文件描述符,也就是/proc/$$/fd中的8),字符串'GET / HTTP/1.0\n'其实就是http协议规定的快速请求头的最小写法:GET是请求方法,/是请求资源,HTTP/1.0是协议版本,后面也必须跟上\n换行符,没有这个换行符会报错。
然后通过echo将这些重定向到8号文件描述符指向的socket中,也就是会发送给www.baidu.com,不过这个命令在回车会后,好像没啥反映
 不过只要连接建立成功,请求发送完成,就一定会接受到返回的数据,通过cat命令去读取
不过只要连接建立成功,请求发送完成,就一定会接受到返回的数据,通过cat命令去读取
cat 0<& 8

而刚刚这些操作,就是基于http协议进行的一个网络请求的演示,http协议只是应用层众多协议中的一个常见的规范。echo 和 cat 也都是在模拟浏览器的工作
2、网络基础知识
网络层与下一跳
一般说到网络配置,应该包含这4个维度:
1、IPADDR(IP地址);
2、NETMASK(子网掩码);
3、GATEWAY(网关);
4、DNS(域名解析);
IP地址好理解,用来标识每一个通讯的节点,简单点说就是网络坐标。子网掩码,用来和IP地址做按位与运算可以得出网络号。假设IP地址为192.168.150.14,子网掩码一般是255.255.255.0,按位与运算之后得到192.168.150.0,也就是这台机器所在网络的网络号是192.168.150.0,这台机器就是192.168.150.0这个网络中的第14号机器。
知道了IP地址和子网掩码的作用自后,来看网络层的路由表:

想要搞明白这张表是干什么使的,就得先搞明白TCP/IP在通信的时候怎么寻找目标呢?
第一种方式就是:在互联网中的每一个设备,都把除自身之外的其它设备的连接方式都记录下来。可如果每一台设备都有全局拓扑图的话,只需要进行一个图计算,寻找一个最短路劲即可。但是全局的设备何止千千万,先不说全记录下来现不现实,就算全部记录下来之后,计算通信的效率也会变得非常慢。只要数据量一上来,计算起来必然会有延迟,这是硬伤,没得洗。
第二种方式,也就是目前TCP/IP主流的计算方式,使用下一跳来进行通信路径的选择。在每个节点中不必存储完整的通信链路,只需要存储其周边一步之内的数据(也就是其所在的路由器局域网内的数据)。然后通过路由器中路由表的计算跳转,跳到下个路由器,经过节节跳动,最终到达终点路由器的网络中的具体某一个设备进行通信。
然而,“下一跳”这个概念提出之后,受到学术界的抨击,说这样子 通信不完整会造成数据丢包。于是做了一个轰动世界的实验:从美国的一台计算机打开一个比较大的文件,切分成很多的数据包向外发送。发送的数据包通过长途电缆、卫星到宇宙,再通过卫星返回地球,在通过海底电缆达到欧洲,再走蜂窝网络传输到某台具体的计算机。所有的数据包都没有丢失,按照发送的顺序拼接还原了这个文件,证明了下一跳机制通过TCP这种可靠的传输方式,并不会造成所谓的数据丢失问题。
那么这个下一跳是如何跳的呢?这时候路由表就派上用场了。ping一下www.baidu.com
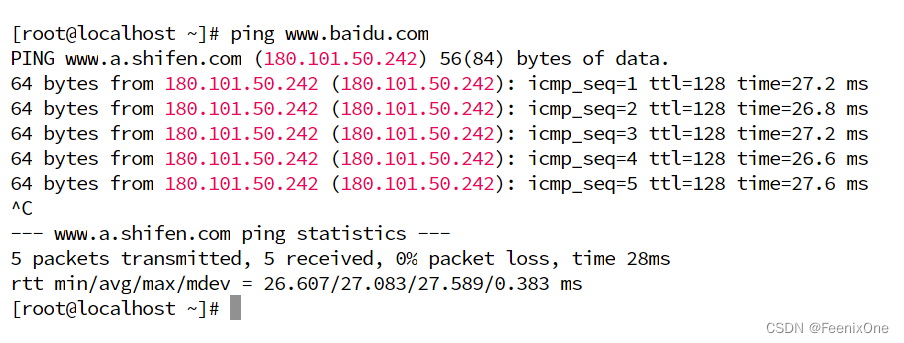
ping的是www.baidu.com是个域名,实际上需要连接的是180.101.50.242这个地址。而本身这台机器的IP是192.168.160.129,要怎么找到180.101.50.242这个地址呢?首先,在路由表中会有3条记录,对于后面两条记录来说,用180.101.50.242这个地址和255.255.255.0做按位与运算之后,得出的结果是180.101.50.0,既和192.168.122.0不匹配,也和192.168.160.0不匹配。于是,只能用180.101.50.242和0.0.0.0做按位与运算之后得到0.0.0.0,和0.0.0.0匹配,那么192.168.160.2就是下一跳的地址,也就是这个局域网网关的地址。这个数据包想走出这个局域网,就必须通过网关这个口出去。
这就是路由器存在的意义,如果说局域网是一个监狱,局域网中的每一台机器都是这个监狱中的犯人,而路由器就是这个监狱中的监狱长。犯人想要和外界通信,就必须经过监狱长的转达,所以在一个局域网中,任何一台电脑想要和局域网外的机器通信,就必须先将数据交给路由器来处理。在路由器的内部,也维护了这么一张路由表,收到了数据包之后,一样也会做转发路径的判定,也就是找寻它自己的下一跳地址。
链路层与MAC地址
上面说了,在网络层算出了下一跳的地址192.168.160.2之后,要把数据经过网关统一向外发送。那么现在问题来了,访问的目标地址是180.101.50.242,那现在要怎么把数据给到这个网关呢?这就是链路层该干的事了。在数据外面再套一层网卡地址,也就是常说的MAC地址,链路层也有自己的表来维护这些数据:arp -a

ARP是一种协议,通过这个协议来解释IP地址和网卡硬件地址的映射。类似于DNS会解析域名和IP地址间的映射这样。不过DNS是全网的域名→IP地址,ARP是局域网的网卡地址→IP地址。
那么最终链路层完事儿之后,数据包中会封装三个地址:
1、最外层的MAC地址决定下一跳点给谁;
2、次外层的IP地址决定这个数据最终给谁;
3、最里层的端口号是给服务器中目标端口号对应的进程;
那么,如果有多个下一跳的时候,怎么判断走哪个呢?这个是由网络工程师来决定,运营商搭建整体的网络。无论是全国的骨干网,还是城域网,都是由公司外包去搭建这个网络,交给网络工程师去规划,所以会人为的在路由表中固定几条路由条目。
说到这,现在这几层基本上就通了。应用层里基本就是http协议,上层应用比如浏览器想要建立通信,先到内核(传输控制层、网络层、链路层、物理层都是在内核中)中,调传输控制层。传输控制层根TCP/IP协议,制造数据包(开始准备三次握手),数据准备好之后调网络层。到了网络层开始触发路由条目的判定,拿着IP地址去路由表中计算查找,找到下一跳之后调链路层。在链路层中根据下一跳的IP地址,通过ARP协议获取MAC地址,封装好数据。到这一步,现在的数据包就封装好了通信的基础数据(源端口号、目标端口号、源IP地址、目标IP地址、源MAC地址、目标MAC地址),这些数据已经完成了点与点间通信的定位。
解决高并发的核心思想就是,一台服务器架不住,就上两台;两台机器架不住,就上四台.....直到能架住这些流量为止。那问题来了,用户访问的是同一个域名,一个域名要配给哪台机器呢?好像给谁也不对。那就不直接给到具体的某一台服务器,在服务器前面放一个代理的服务器,让所有的请求先去访问这个代理,然后通过代理将一个个的请求分发到不同的服务器上,就解决了IP不同的问题。
3、基于网络层提出解决高并发的思路
为什么Tomcat的并发量低
那现在问题来了,代理服务器也是服务器,凭什么后面的那些具体干活的服务器扛不住的流量,代理服务器就可以扛得住呢?首先要明白为什么Tomcat的并发连数高不起来,因为它是一个应用层的软件,处于OSI模型中的最上层,同样的Nginx也是应用层的一个软件。从前面介绍的7层模型角度来说,每次通信都要从自身的应用层→.....→物理层→对方的物理层→.....→对方的应用层,这么多层的穿插,效率怎么高的起来;而且,应用层是处于用户态,其它几层都是在内核态中,还要在用户态和内核态中频繁切换,进一步拖垮效率;最后,数据想要到达应用层,就必须先经过传输控制层的三次握手,也就是说光是确认连接的数据包就得来回跑3次,又是对资源的一大消耗;而Tomcat本身也是用Java开发的一个软件,它还是跑在JVM中,还不是直接和操作系统交互,相当于中间又套了一个虚拟机出来,所以Tomcat性能就更低。
如何提高负载设备的并发量
好,现在知道了慢的原因,那要怎么给它变快呢?想一下家里的路由器,只需要一台路由器就可以带动家里那么多设备上网,也没卡顿也没延迟啥的,为什么路由器能做到这么快的效率呢?因为它本身并不是实现功能的目标服务器,它只是做了数据包级别的转发。换句话说,就是路由器的转发甚至还没达到传输控制层,只是在物理层、链路层、网络层之间进行数据交互,没走到传输控制层也就意味着都没有经过3次握手,自然效率极高。
同样的思路,前面提到的代理服务器,如果这台服务器接受到的一个个数据包到它身上的时候,停留的时间足够短,不走4层,甚至都不走3层,自然这个效率就提高上去了,效率一块自然并发量也就可以承受得更多。

如果要保障数据传输足够的快,这台负载均衡服务器就不会和客户端握手,但是如此一来也会带来一个问题,只是数据包级别的传递,连7层都没有到,根本就不知道发的是什么协议,什么字符串怎么定义的,URL什么的都根本看不到。所以就要求后端服务器是镜像的,因为客户端可能每次访问的请求都会被负载到不同的服务器上,这就要求每个服务器上的资源必须是完全一致的才不会出错。
这也是和Nginx的反向代理做负载均衡不一样的地方,Nginx作为应用层的软件,每次交互的数据都已经达到7层,那么就可以对这些数据进行一些判断之后,根据业务需要进行处理分发。这样就无需所有后端的服务器都是镜像组成,可以指定某些请求固定分发到某些服务器上。但也正是由于到达了7层,通信的处理比较繁琐,效率上必然大打折扣。
Nginx是7层的,LVS是4层的。对于Nginx来说基本上能撑到五六万的并发已经很不错了,但是如果使用LVS,只要硬件配置高,带宽足够高,配置合适的组网模式,它能应付的并发流量远大于Nginx。所以一般在企业中,一般会在Nginx前先搭建一套LVS来撑住流量,LVS后面才是Nginx撑住握手级别的并发,将请求再转给后面的Tomcat进行具体的处理。
4、LVS实现负载均衡
LVS全称是Linux Virtual Server,也就是Linux虚拟服务器,是由章文嵩博士于1998年主导的开源负载均衡项目,目前LVS已经被集成到Linux内核模块中。该项目在Linux内核中实现了基于IP的数据请求负载均衡调度方案,终端互联网用户从外部访问公司的外部负载均衡服务器,终端用户的Web请求会发送给LVS调度器,调度器根据自己预设的算法决定将该请求发送给后端的某台Web服务器,比如,轮询算法可以将外部的请求平均分发给后端的所有服务器,终端用户访问LVS调度器虽然会被转发到后端真实的服务器,但如果真实服务器连接的是相同的存储,提供的服务也是相同的服务,最终用户不管是访问哪台真实服务器,得到的服务内容都是一样的,整个集群对用户而言都是透明的。最后根据LVS工作模式的不同,真实服务器会选择不同的方式将用户需要的数据发送到终端用户,LVS工作模式分为NAT模式、TUN模式、以及DR模式。
动手前需要知道的辅助知识
隐藏VIP和通告
隐藏VIP(虚拟IP,对外隐藏,对内可见),需要动到kernel协议,因为从4层往下,都是内核中的事。Linux系统的/proc目录是个虚拟目录,只有开机之后这个目录下才会有数据出现。这目录里放的就是内核以及进程,将它们的参数变量抽象成文件,给一个path路径可以去访问修改。修改文件中的值,等于是修改这个变量参数的值。文件里的数值一遍,内核立刻产生效果。假设程序中有一个变量a,Linux的机制是一切皆文件,会把这个变量a映射成一个文件。a的值是3,这个文件打开看就一定也是3。把3改成8,也就是将变量a的值改为8。
而且这个目录既然映射的是程序内存中的变量,所以这个目录下的文件修改的时候不能用vim命令去打开修改。vim这个命令有点类似于win中的office工具,使用office打开一个word文本文件,会产生一个隐藏的临时文件。既然这个路径文件代表的是kernel中的一个内存地址空间,用vim打开之后成的临时文件,就会在进程的地址空间中产生一个额外的变量。但是对于操作系统来说,可以修改,但是不能乱创建,所以这个文件中值的修改只能使用echo去重定向覆盖。
/proc/sys/net/ipv4/conf/,来到这个目录下,选择具体的某一块网卡进行修改,在网卡的文件夹中,会有两个文件:arp_ignore和arp_announce,也就是上面提到的arp协议的两个参数。
arp_ignore:定义接受到的ARP请求时的响应级别。
0:只要本地配置的有相应地址,就给予响应;
1:仅在请求的目标MAC地址配置请求到达的接口上的时候,才给予响应;
一台计算上可以有多块网卡,每块网卡可以配置不同的地址。假设网卡A和网卡B都在同一台计算机上,那么可以通过请求网卡A来询问是否有网卡B,也就是说可以通过请求网卡A来请求网卡B。当设置成0的时候,就是允许通过网卡A来请求网卡B;当设置成1的时候,就是不允许通过网卡A来请求网卡B。这就是所谓的对外隐藏,对内响应。
arp_announce:定义将自己的地址向外通告时的通告级别。
0:将本地任何接口上的任何地址向外通告;
1:试图仅向目标网络通告与其网络匹配的地址;
2:仅向与本地接口上地址匹配的网络进行通告;
首先,要知道在任何操作系统上,一块物理网卡可以配多个不同的IP地址。设置0,就是将所有网卡上所有的IP地址都对外通告;设置1,就是每块网卡只通告自己的所有地址;设置2,就是将不同的IP地址通告给不同的网络,IP地址之间相互独立。
lo网卡
使用ifconfig命令,查看网卡的信息。除了ens33之外,下面还有一块lo网卡,这块网卡的地址是127.0.0.1,这地址熟吧,一天到晚经常看。这块lo和ens33都是网卡,只不过ens33是物理网卡,这块lo是虚拟出来的网卡,其实就是一个软件,一段代码模拟的一块网卡。自己跟自己玩的时候,比如本机的浏览器访问本机的服务器,域名写localhost,或者IP写127.0.0.1。当数据进入内核之后,一看目标地址就是本机的地址,就会走到这块lo网卡,直接掉头发回本地,按照端口号该找谁找谁。
网卡上的任何接口都可以配子接口,配子IP。将VIP配成lo网卡的子IP,也就是将VIP配在操作系统内核的虚拟网卡上而不配在虚拟网卡上,这样外界就请求不到,这样也就实现了对外隐藏,对内可见。
IPVS模块
LVS这个东西一开始是作为独立的项目进行研发,完成之后这东西太有用了,太厉害了,以至于Linux的作者就将它封装成了一个小模块,包裹进了Linux内核中。基本上现在的Linux系统都是自带LVS模块,这个模块的名称就是IPVS。所以在使用Linux系统进行LVS的搭建,无需安装任何的应用啥的,除非某些特定的发型版本将这个模块剔除。
但是内核会暴露系统调用,系统调用最终被C语言封装成API,普通人不会开发语言,只能使用外壳程序。所以虽然系统自带LVS这个模块,但还是要装一个和内核模块交互的接口。也就是要装一个ipvsdm软件(yum install ipvsdm -y),通过这个软件会去调用底层内核,这样才能生效。
搭建LVS负载均衡服务
先准备3台Linux系统的虚拟机,我这边使用的是CentOS8,IP地址分别为:
LVS-1 → 192.168.160.134
LVS-2 → 192.168.160.135
LVS-3 → 192.168.160.136
配置子接口
在LVS-1上配置子接口:ifconfig ens33:2 192.168.160.100/24
24的意思就是添加子网掩码为255.255.255.0,因为IPv4是用二进制位来标识,以点分字节,一个字节占8位。255就是8个位上都为1,三个字节都为1就是24。同理,如果子网掩码是255.255.0.0,那就是192.168.160.100/16。这种是偷懒的写法,等同于ifconfig ens33:2 192.168.160.100 netmask 255.255.255.0
再使用ifconfig来查看网卡信息
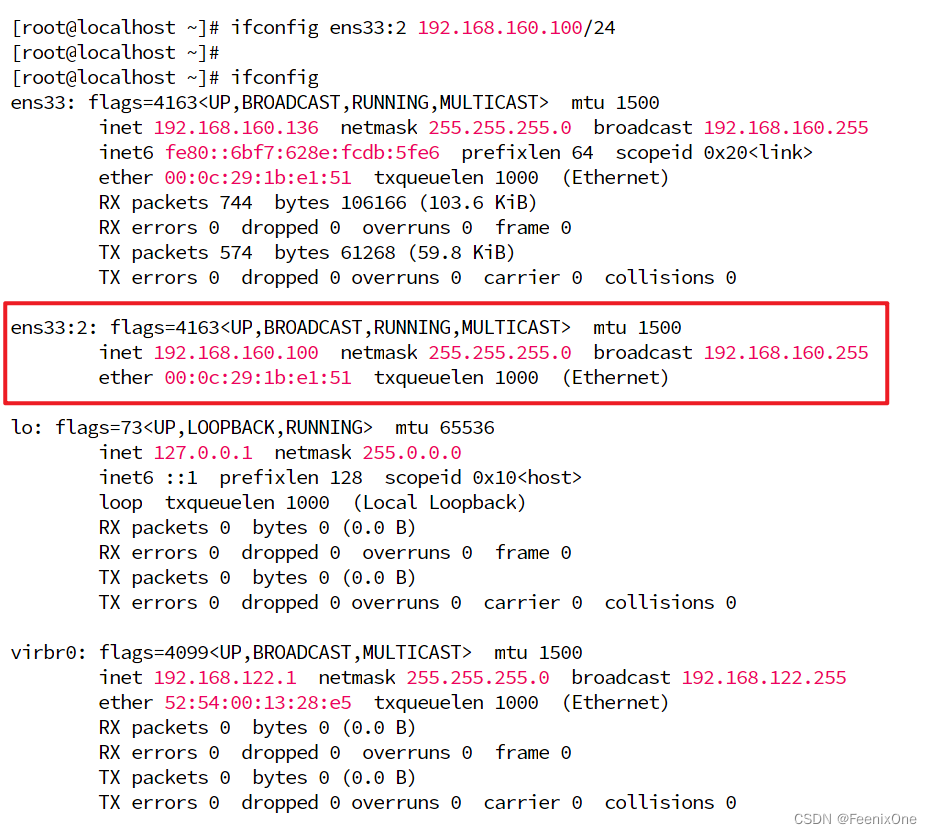
除了曾经的ens33之外,就会多了一个子接口ens33:2,IP地址为192.168.160.100,子网掩码为255.255.255.0。如果想要禁用这个子接口,可以通过ifconfig ens33:2 down来禁用。
设置ARP协议
在LVS-1上设置了子接口之后,接下来就需要在LVS-2和LVS3上设置ARP协议,也就是修改arp_ignore和arp_annaounce的值。
进入到网卡的配置目录下,选择需要修改的网卡:cd /proc/sys/net/ipv4/conf/ens33/
确认此时arp_ignore的值:cat arp_ignore
默认arp_ignore的值为0,修改为1:echo 1 > arp_ignore
再次确认arp_ignore的值已经修改成功:cat arp_ignore
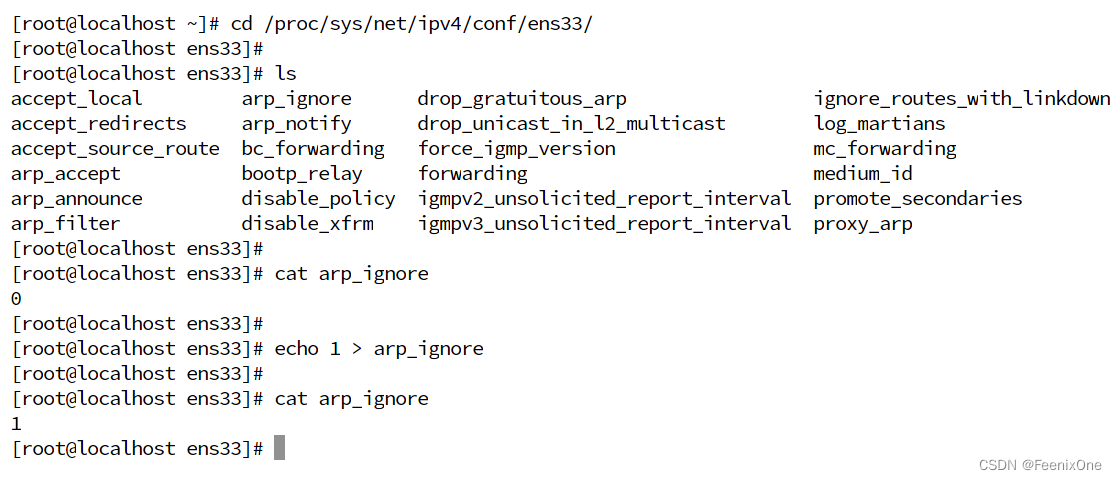
修改完arp_ignore的值之后,再来修改arp_announce的值,
确认此时arp_announce的值:cat arp_announce
默认arp_announce的值为0,修改为2:echo 2 > arp_announce
再次确认arp_announce的值已经修改成功:cat arp_announce

现在改的是其中一个接口,为了保证所有的接口都生效,来到当前目录的上一级,进入all里面继续修改arp_ignore和arp_announce的值
cd ../all
echo 1 > arp_ignore
echo 2 > arp_announce

配置lo网卡的子接口
在LVS-2上配置lo网卡的子接口,和LVS-1上的ens33网卡的子接口可不一样,lo子接口的子网掩码是全255,也就是:ifconfig lo:2 192.168.160.100 netmask 255.255.255.255

为什么lo网卡子接口的子网掩码和LVS-1网卡的子网掩码不一样呢?掩码存在的意义就是去和IP进行按位与运算,从而生成路由条目。如果lo网卡子接口的子网掩码也写成255.255.255.0,那么也就意味着走lo网卡也可以抵达192.168.160.0这个网络里面,而ens33也可以抵达192.168.160.0这个网络里面。如果这两张网卡都可以抵达192.168.160.0这个网络里面,现在ping 192.168.160.1这个目标地址,既可以走ens33物理网卡,也可以走lo:2虚拟网卡,对于kernel来说,虚拟网卡肯定比物理网卡更近,也就是会走到lo网卡,然后lo网卡本身就是自己跟自己玩的网卡,那么这个数据就会永远发不出去。
而将lo子接口的子网掩码配成255.255.255.255,和IP地址做完按位与运算,整个网络号就是192.168.160.100,和ens33得出的不一样,规避死循环的风险。那么同样的,LVS-2上的操作同步到LVS-3上再重复一遍配置:先调内核,再改IP。

安装httpd软件,并创建主页面
在LVS-2和LVS-3中安装httpd软件:yum install httpd -y
httpd是Apache开源的一个软件,和Tomcat一样是一个WebServer,Tomcat是动态的,这个是静态的。装完之后,使用 service httpd start 将启动httpd服务,默认占用80端口。
启动完服务之后,在/var/www/html下创建一个index.html页面,写上本机IP
vim /var/www/html/index.html → from lvs-* 192.168.160.***
有了这个主页之后,就可以对LVS-2和LVS-3通过浏览器进行访问:

安装ipvsadm软件,并配置负载均衡规则
在LVS-1中安装ipvsadm工具,从而才能调用kernel中自带的lvs模块:yum install ipvsadm -y
配置负载数据入口规则:ipvsadm -A -t 192.168.160.100:80 -s rr
-A 指的是这是接受数据的规则
-t 指的是tcp数据传输使用tcp协议
192.168.160.100:80 指的是访问的目标地址端口号
-s rr 指的是轮询
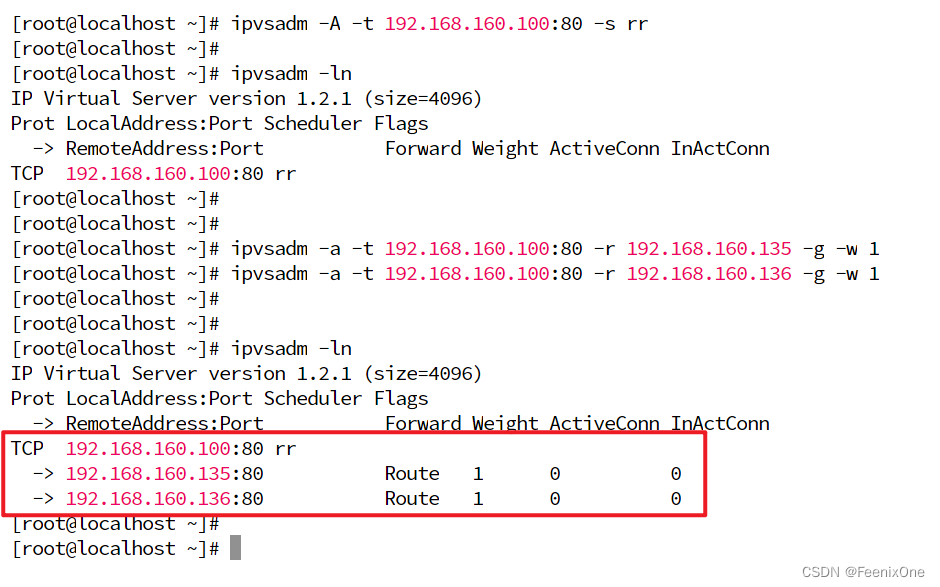
使用 ipvsadm -ln 可以查看当前已经配置的规则
 配置负载数据负载规则:ipvsadm -a -t 192.168.160.100:80 -r 192.168.160.135 -g -w 1
配置负载数据负载规则:ipvsadm -a -t 192.168.160.100:80 -r 192.168.160.135 -g -w 1
-a 指的是这是接受到数据后负载出去的规则
-t 指的是tcp数据传输使用tcp协议
192.168.160.100:80 指的是访问的目标地址端口号
-r 指的是需要将数据负载出去
192.168.160.135 指的是负载目标地址
-g 指的是轮询
-w 指的是加权重
1 指的是权重为1
同样的负载规则也得给LVS-3(192.168.160.136)来一套:ipvsadm -a -t 192.168.160.100:80 -r 192.168.160.136 -g -w 1
当这些配置好之后,在通过 ipvsadm -ln 这个命令来查当前lvs的负载均衡规则,就可以很清晰的看到,当接受到访问 192.168.160.100 的数据后,会负载给 192.168.160.135和192.168.160.136
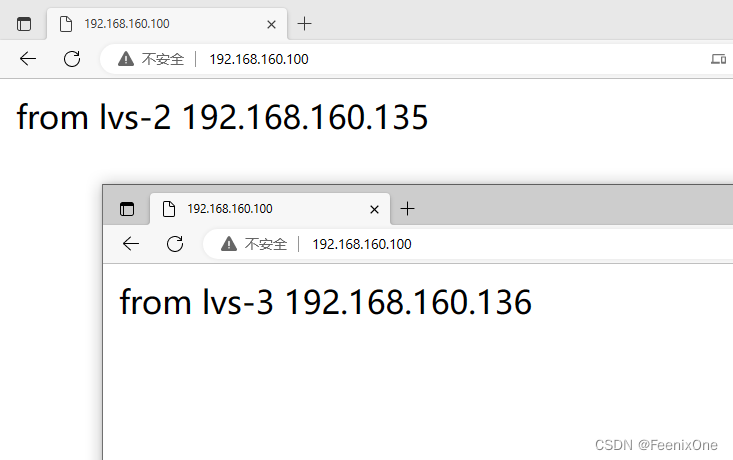
这套负载的规则配置完之后,即时生效。此刻再去访问192.168.160.100,就会转发到192.168.160.135或192.168.160.136
疯狂的按F5对页面刷新,攒一波连接,然后在LVS-1中通过 ipvsadm -lnc 查看
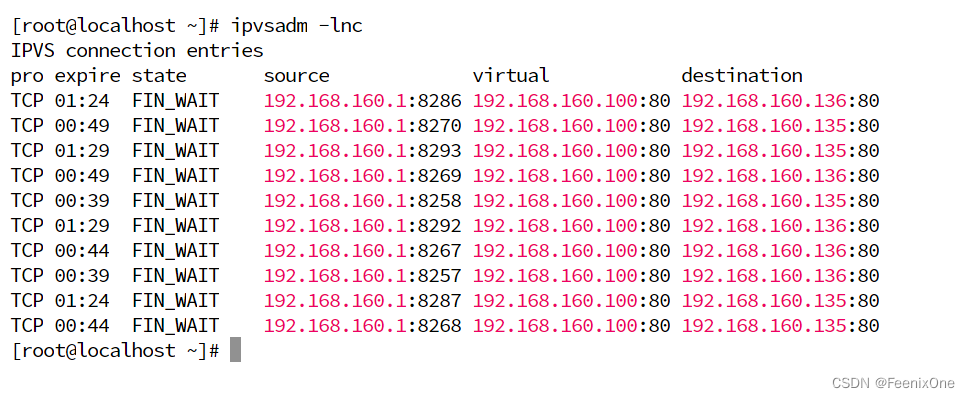
值得一提的是这个 state 列,FIN_WAIT代表连接过;SYN_RECV代表LVS自身正常,后面负载的网络有问题,已经负载出去的数据没有回来确认。
5、高并发下的高可用保障
前面已经成功搭建起了基于4层网络、无需三次握手的LVS负载均衡。所有的流量都先进来LVS服务器之后,再进行分发给后面的若干真是服务器。在这个架构之中,也存在不少隐患。这台用于负载均衡的机器是单台的,一旦它宕机,那么所有的数据都无法负载到后面真实干活的服务器,这就是所谓的单点故障问题。除此之外,被负载的那些服务器自身也会存在宕机问题,一旦宕机之后,LVS中还存有跟这个机器的负载记录,但无法真正的接受访问,所以转到这台机器上的那部分用户就会请求异常。
通常单点故障问题的解决方案,就是解决这个单点问题:只有一台机器,机器坏了就无法使用;那就准备多台,一台坏了可以继续使用另一台。有多台机器的情况下,一般有两种形式:主备模式和主主模式。主备模式就是只有主机上有被访问的IP,备机只有在主机宕机之后,迅速的接管主机的工作,对于客户端来说,主机的宕机和切换是透明的,完全不知道后面发生啥;而在主主模式下, 所有的LVS都是主机,全都对外提供服务,所以这里要借用其它的技术,比如动态DNS等。主主模式非常复杂,而且实际中企业用的也不多,这里详细介绍下主备模式。
主备模式
在主备模式下,备机是怎么知道主机挂没挂,怎么知道什么时候要去接管主机?要么由备机来主动轮询,询问主机:你死没死~你死没死~如果有好几台备机,每个固定时间来询问一下主机,每一个备机主机都要去响应一遍,这样在主机的网卡上,既要接收很多外界请求的数据包,又要接收这些备机询问的数据包,这样主机就要承受比较大的压力。
为了缓解这种没必要的压力,可以由主机固定向外界发出广播,备机收到这个广播就知道主机还活着。什么时候收不到这个广播了,就知道主机已经没了,可以上位了。但是只要是牵涉到网络,一般就没有说能一次性确认的。网络中存在太多不确定因素,所以一般都会设置一些重试机制:当这些备机好几次都没有接收到主机的广播,才会确认主机没了。
那么又该怎么确认负载的真实服务器宕机了呢?绝大多数人在确定一个服务是否正常,就是去访问它,它能返给你数据那就是正常运行着。这里需要说明一点,很多人喜欢用 ping 去检验一个服务是否正常,其实这是不对的。就拿 ping www.baidu.com 来说,baidu的服务运行在应用层,访问www.baidu.com是可以走到第7层应用层。但是ping却只到达第3层网络层,再往上的传输控制层压根就不会走到,也就是说ping只是从一方的网络层到另一方的网络层,连握手都没握。所以,使用ping去检验服务是否正常运行是不对的。所以最简单的方法就是去访问一下,访问的本质就是验证第7层应用层底层的http协议:发送请求,返回200,起码被访问的目标服务器本身是正常运行的。
使用keepalived解决单点故障,保证主备切换
为了解决单点故障,主备切换的问题,keepalived诞生了,这个程序可以:
1、监控自身的服务;
2、主机通告自己还活着,备机监听主机的状态。当主机宕机之后,一堆备机推举出新的主机;
3、可以将原来手动做的那些lvs的配置,全部自动化完成。上面写的那些命令,都是直接将参数拼接在命令中一次性自行,不过keepalived是有配置文件的,这些东西可以写在keepalived的配置文件中;
4、对后端服务做健康检查,把宕机的后端服务剔除;
在搭建lvs主备模式之前,需要再准备一台Linux服务器,姑且称之为LVS-4。在LVS-4上也需要重复LVS-1的步骤安装lvs服务,让LVS-1和LVS-4这两台机器形成相互主备。而ens33:2这个子接口的IP地址,只在主机上配置,备机上不需要配置。只有当主机宕机之后,备机才能配置上ens33:2这个子接口。而这件事就正是由keepalived来做,所以需要在LVS-1和LVS-4上安装keepalived。注意:上面的实验已经在LVS-1上手动进行了lvs的配置,要把LVS-1上的配置都清掉,keepalived启动完成后会自动去做这些事情。
清除LVS-1上的ipvs负载记录:ipvsadm -C
清除LVS-1上的子接口:ifconfig ens33:2 down
清除完这些配置之后,LVS-1恢复到裸机状态

LVS-2、LVS-3依然保留lo子接口
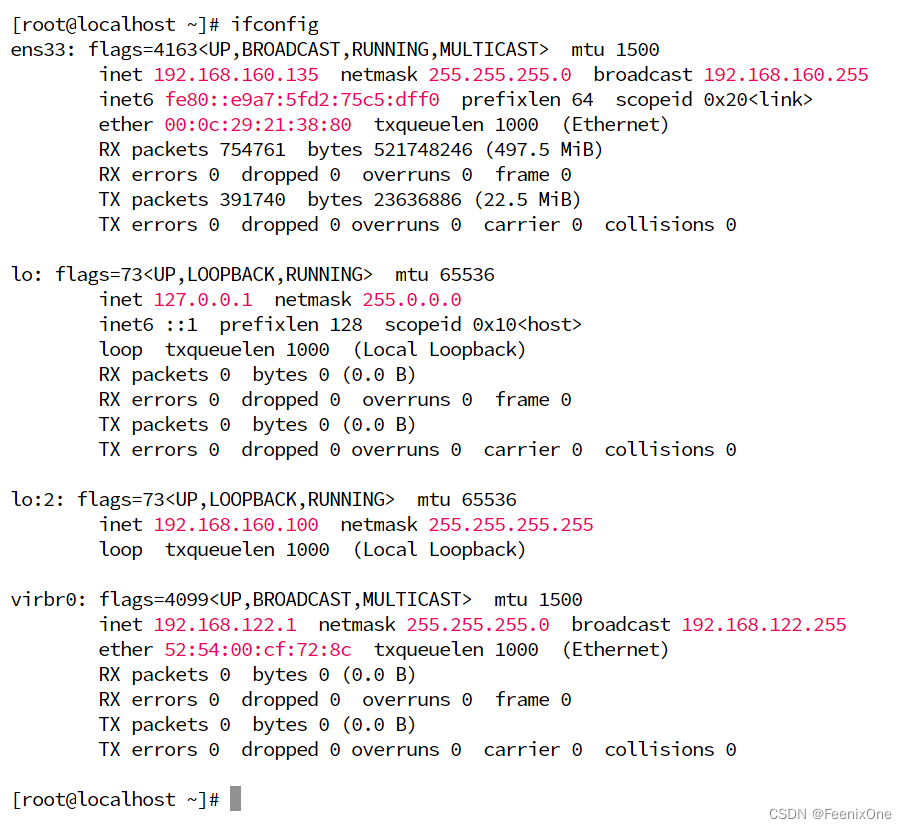
LVS-4本身就是台裸机,连ipvsadm都没有安装
使用LVS-1和LVS-4搭建主备模式
在LVS-1和LVS-4上安装keepalived
keepalived安装命令:yum install keepalived -y
安装完keepalived之后,可以通过读取配置文件去内核的ipvs模块自动配置负载规则,换言之,它是有能力替代ipvsadm这个软件,不过一会儿还需要在使用一下这个命令,所以LVS-4上也将ipvsadm一并安装。
修改keepalived配置文件
来到配置文件的目录 /etc/keepalived/,先将原版的配置文件备份,然后使用vim打开
vrrp_instance VI_1 { ## vrrp:虚拟路由冗余协议state MASTER ## MASTER指的是在集群主备模式中作为主机(BACKUP就是备机)interface ens33 ## 集群中广播自己还活着的数据,走的哪块网卡virtual_router_id 51 ## 这个id用来标识归属哪个集群中,别跑去别的集群给别人当主机或备机了priority 100 ## 权重值,选举新主机的时候,权重值高的优先advert_int 1authentication { ## 权限认证,可以用来防止别的机器乱入我这个网络集群auth_type PASSauth_pass 1111}virtual_ipaddress { ## 虚拟IP地址,客户端访问这个地址,然后被负载出去真实的服务器192.168.160.100/24 dev ens33 label ens33:2}
}virtual_server 192.168.160.100 80 { ## 配置负载规则delay_loop 6lb_algo rrlb_kind DR ## LVS的模式,有NAT、DR、隧道persistence_timeout 0 ## 设定一个时间(单位:秒),在这个时间内用户的每次请求视为同一个批次,同一批次的请求尽量负载到同一台服务器protocol TCPreal_server 192.168.160.135 80 { ## 被负载的真实服务器地址weight 1 ## 负载权重HTTP_GET { ## 对real_server(被负载的真实服务器)做健康检查,使用http协议以get请求去访问url {path /status_code 200}connect_timeout 3 ## 连接超时时间retry 3 ## 重试次数delay_before_retry 3 ## 重试间隔时间}}real_server 192.168.160.136 80 { ## 被负载的真实服务器地址weight 1 ## 负载权重HTTP_GET { ## 对real_server(被负载的真实服务器)做健康检查,使用http协议以get请求去访问url {path /status_code 200}connect_timeout 3 ## 连接超时时间retry 3 ## 重试次数delay_before_retry 3 ## 重试间隔时间}}
}保存LVS-1上修改后的文件,使用scp复制到LVS-4同目录下,将MASTER改为BACKUP、权重由MASTER的100改为50即可:scp ./keepalived.conf root@192.168.160.137:`pwd`

启动keepalived服务
在LVS-1上启动keepalived服务命令:service keepalived start
启动之后,再次查看LVS-1的网卡信息,会发现keepalived已经自动添加了子网卡

插卡ipvs信息,通过lvs负载的规则也都配置完成
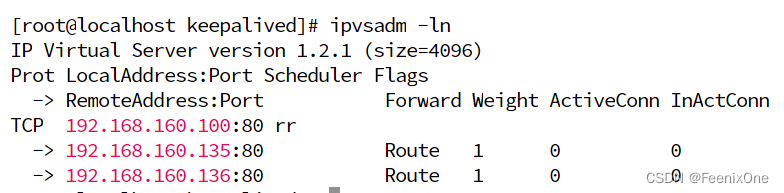
此时访问192.168.160.100已经可以成功负载到192.168.160.135和192.168.160.136两台机子。
此时再去启动LVS-4上的keepalived服务,启动成功之后,并不会马上出现子网卡的信息(但是lvs的负载规则已经配置完成),因为LVS-1还没挂,LVS-4只是备机,还不是主机。只有当LVS-1挂掉之后,LVS-4会里面接替LVS-1,在本机上瞬间配置好子网卡,完成主机的负载转发工作。
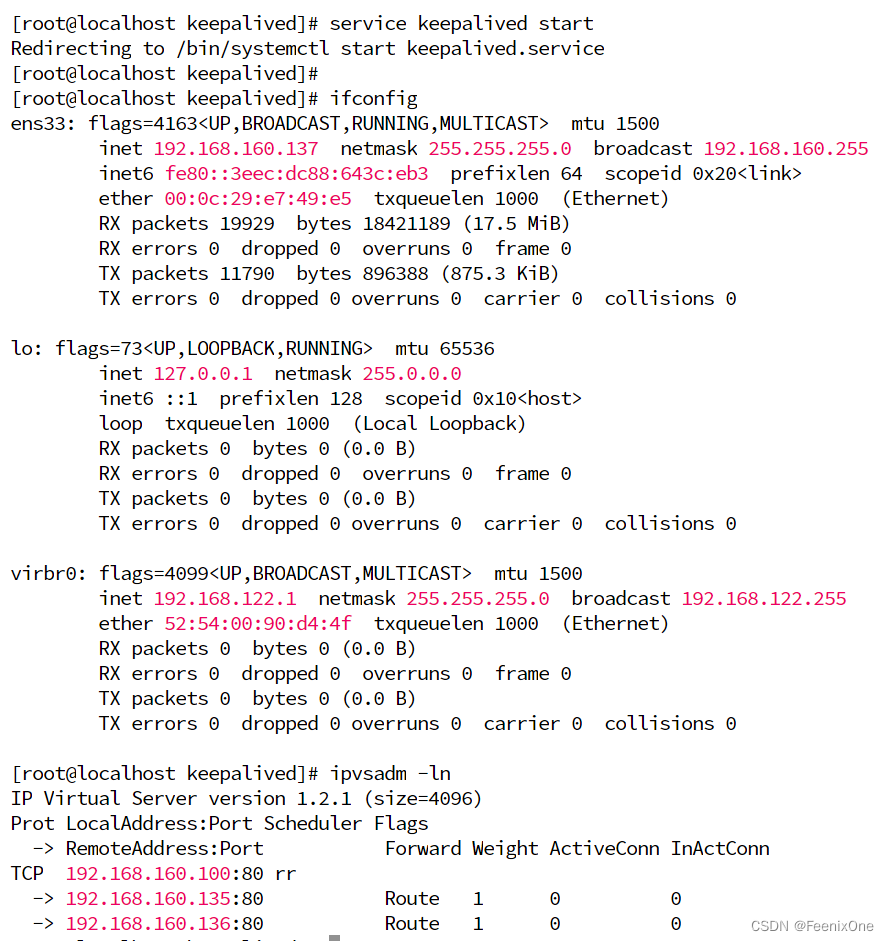
验证keepalived保证主备模式的高可用
现在两台机器的keepalived都已经启动成功,疯狂的刷新页面,分别查看两台机器的ipvsadm -lnc

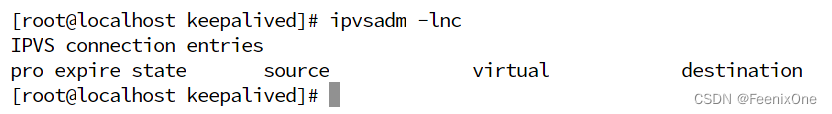
可以看到都是走的LVS-1主机,没有经过LVS-4备机。然后在LVS-1上执行 ifconfig ens33 down 将LVS-1的物理网卡禁用,再去查看LVS-4的网卡信息,可以看到keepalived瞬间将主机接管过来,并自动配置好子网卡信息,进行数据转发工作。
需要注意的是,当LVS-1的网卡正常之后,在这个集群中是会将主机再次抢回到自己身上。本身这个集群主备一共就俩机子,而且LVS-1的权重比LVS-4的要高很多,并且断开的时间很短,没有产生很多的访问数据,但是并不是在所有的主备模型中,重回集群的机子就一定能够抢回主机的位置。
zookeeper的引入
试验到这里就算告一段落了,但这里面有个很有意思的问题:LVS-1和LVS-4的主备模式是通过keepalived来进行主备切换。而keepalived自身也是个程序,程序本身就是最不靠谱的东西,它也会像LVS-1一样挂掉,LVS-1挂掉了还有LVS-4给替补,keepalived自身挂掉了怎么办?
LVS-1中的keepalived一旦挂了,不能和LVS-4中的keepalived通信,告诉LVS-1这个主机还活着,这样LVS-4就会认为LVS-1已经死亡,立马给自己机器就配置了子网卡,这样机器上就都会有ens33:2这个网卡,客户端来访问的时候就会造成混乱,三次握手和四次分手会负载给不同的真实服务器,造成连接建立不起来或者直接丢弃数据包。
这样就形成了一个死循环:因为一台LVS会存在单点故障,所以引入了keepalived技术保证高可用。但是这个技术自身也存在不可靠的问题,这就变成了因为要解决一个单点问题而引入了另一个不可靠的问题。要是再搞一个守护进程去守护keepalived,守护进程自身也会挂.....所以,应该要通过一个高可用集群的方式来解决这个问题 - zookeeper。keepalived自己是单兵作战,自身就存在可靠性问题,但是如果将其替换成一个zookeeper集群,这就可靠了。
相关文章:
【闲聊杂谈】高并发下基于LVS的负载均衡
1、使用http协议进行网络请求 在前几年公布的用户入网数据中,移动入网的数量已经达到六七亿的规模,固网用户数也达到三至五个亿。想要解决这么大并发访问的场景,有多种的解决方案,常规有基于4层的,也有基于7层的。这个…...

Redis新数据类型
目录 Bitmaps 简介 命令 Bitmaps和set对比 HyperLogLog 介绍 命令 Geospatial 简介 命令 Bitmaps 简介 现代计算机用二进制(位)作为信息的基本单位,1个字节等于8位。合理的使用和操作位可以有效的提高内存的使用率和开发效率。 redis提供了Bitmaps这个"数据类…...

使用Python绘制股票CCI指标曲线
本文使用Python语言绘制一只股票的CCI(Commodity channel index)曲线,论文参考《Commodity channel index: Tool for trading cyclic trends》,该指标可以用来测量股价、外汇或者贵金属交易是否已超出常态分布范围, …...
【C语言技能树】浮点数在内存中的存储
Halo,这里是Ppeua。平时主要更新C语言,C,数据结构算法......感兴趣就关注我吧!你定不会失望。 🌈个人主页:主页链接 🌈算法专栏:专栏链接 我会一直往里填充内容哒! &…...
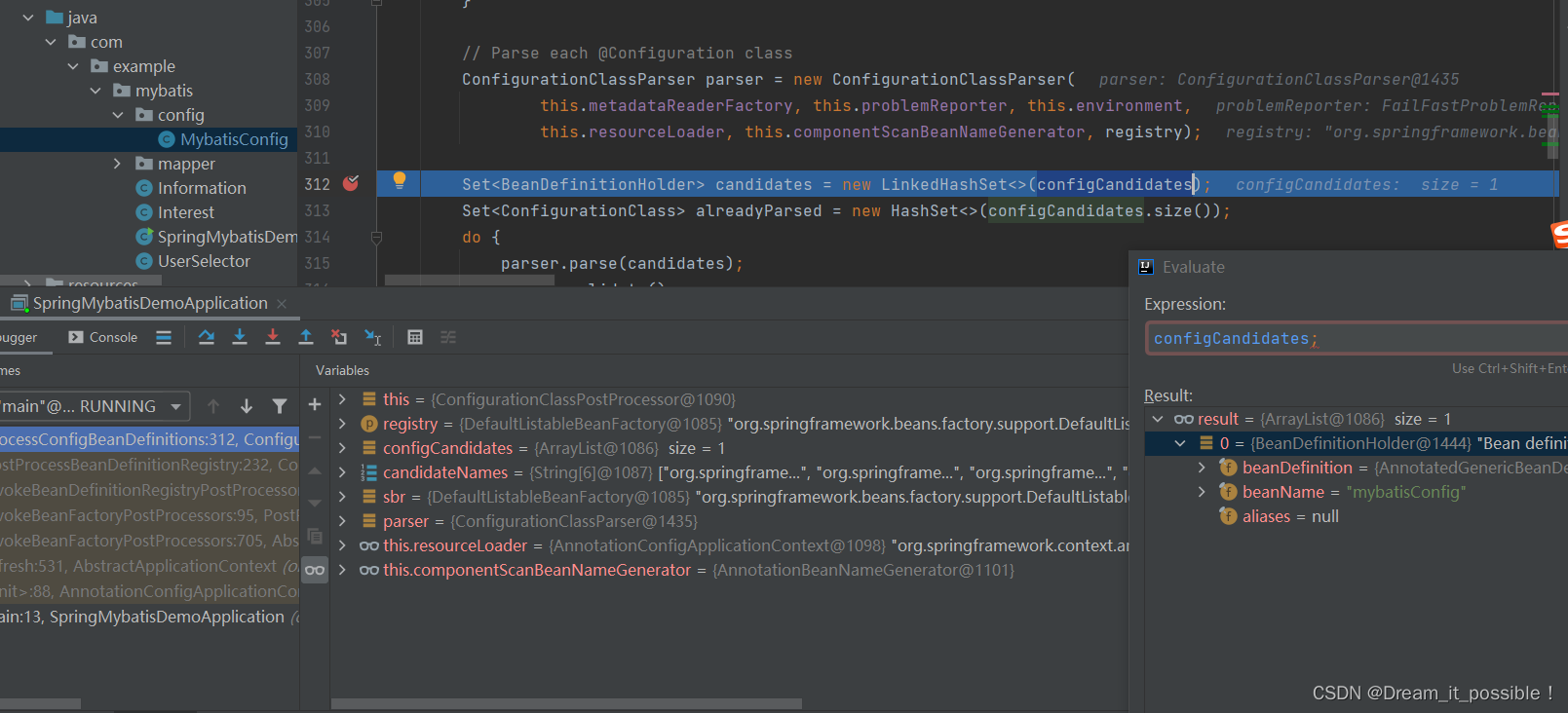
Spring框架源码(五) @configuration源码深度解析
Configuration 注解是spring-context模块提供的一个给开发者使用的配置类注解,开发者可以通过Configuration注解来定义配置类,也可以使用xml形式注入。 例如配置数据库配置,定义一个配置类,注入数据源DataSource, 事务管理器Trans…...
gcc头文件、库搜索路径方式全面盘点)
gcc/g++从入门到精通(3)gcc头文件、库搜索路径方式全面盘点
🎀 关于博主👇🏻👇🏻👇🏻 🥇 作者简介: 热衷于知识探索和分享的技术博主。 💂 csdn主页::【奇妙之二进制】 ✍️ 微信公众号:【Linux 世界】 🎉精彩专栏: 🎓 【面向工作git基础教程】 🧡 【C++11新特性深入剖析】 📚【shell脚本编程基础与...
Android Studio多渠道打包及自动化构建
Android 有不同的应用市场,也就是不同的渠道,需要为每个应用市场打一个安装包,但主要的代码是一样的,可能部分资源不一样,部分代码不一样,如果每个渠道都需要修改,然后打包,非常耗时…...
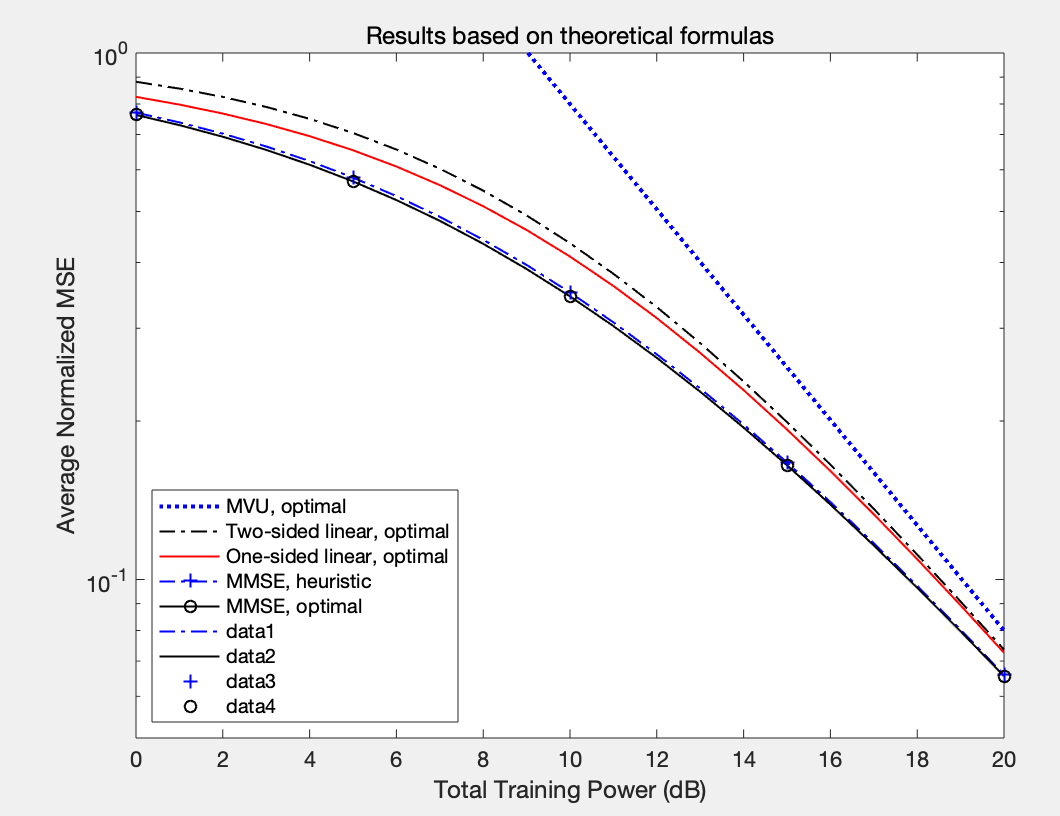
基于MATLAB的MIMO信道估计(附完整代码与分析)
目录 一. 介绍 二. MATLAB代码 三. 运行结果与分析 一. 介绍 本篇将在MATLAB的仿真环境中对比MIMO几种常见的信道估计方法的性能。 有关MIMO的介绍可看转至此篇博客: MIMO系统模型构建_唠嗑!的博客-CSDN博客 在所有无线通信中,信号通过…...

Python代码游戏————星球大战
♥️作者:小刘在C站 ♥️个人主页:小刘主页 ♥️每天分享云计算网络运维课堂笔记,努力不一定有收获,但一定会有收获加油!一起努力,共赴美好人生! ♥️夕阳下,是最美的绽放,树高千尺,落叶归根人生不易,人间真情 目录 一.Python介绍 二.游戏效果呈现 三.主代码 四....

java向Word模板中替换书签数据,插入图片,插入复选框,插入Word中表格的行数据,删除表格行数据
java向Word模板中替换书签数据,插入图片,插入复选框,插入Word中表格的行数据,删除表格行数据 使用插件:spire.doc 创建工具类,上代码: import com.spire.doc.Document; import com.spire.doc.…...
)
Java基础知识快速盘点(二)
一,类型转换 隐式转换 将一个类型转换为另一个类型时,系统默认转换常量优化机制算术运算时类型的隐式转换(byte,short在算术运算时都会转换为int)char类型在进行运算时会根据其编码值进行运算 显式转换 二࿰…...
企业降本增效的催化剂:敏捷迭代
伴随着开源技术的大爆发,新一代的软件技术如雨后春笋般层出不穷。每家企业在硬件及软件开发上都有许多开源技术可选,目的还是在于提高效率,降低开发成本。 本篇文章,带大家了解下促进企业降本增效的重要理念:敏捷迭代…...
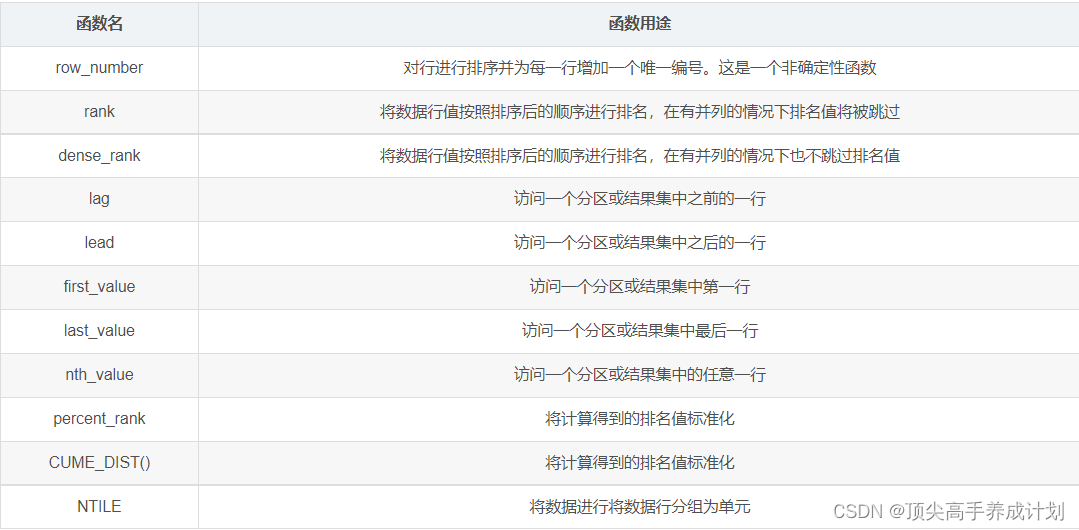
MySQL入门篇-MySQL高级窗口函数简介
备注:测试数据库版本为MySQL 8.0 这个blog我们来聊聊MySQL高级窗口函数 窗口函数在复杂查询以及数据仓库中应用得比较频繁 与sql打交道比较多的技术人员都需要掌握 如需要scott用户下建表及录入数据语句,可参考:scott建表及录入数据sql脚本 分析函数有3个基本组成…...
?)
什么是 API(应用程序接口)?
API(应用程序接口)是一种软件中介,它允许两个不相关的应用程序相互通信。它就像一座桥梁,从一个程序接收请求或消息,然后将其传递给另一个程序,翻译消息并根据 API 的程序设计执行协议。API 几乎存在于我们…...
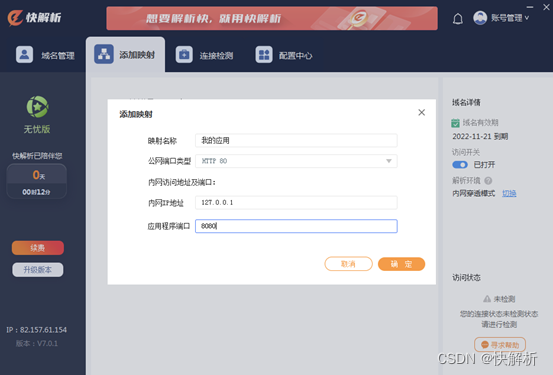
如何在外网访问内网的 Nginx 服务?
计算机业内人士对Nginx 并不陌生,它是一款轻量级的 Web 服务器/反向代理服务器及电子邮件(IMAP/POP3)代理服务器,除了nginx外,类似的apache、tomcat、IIS这几种都是主流的中间件。 Nginx 是在 BSD-like 协议下发行的&…...

vue2中defineProperty和vue3中proxy区别
区别一:defineProperty 是对属性劫持,proxy 是对代理对象 下面我们针对一个对象使用不同的方式进行监听,看写法上有什么不同。 // 原始对象 const data {name: Jane,age: 21 }defineProperty defineProperty 只能劫持对象的某一个属性&…...

将bean注入Spring容器的五种方式
前言 我们在项目开发中都用到Spring,知道对象是交由Spring去管理。那么将一个对象加入到Spring容器中,有几种方法呢,我们来总结一下。 ComponentScan Component ComponentScan可以放在启动类上,指定要扫描的包路径;…...

C生万物 | 常量指针和指针常量的感性理解
文章目录📚引言✒常量指针🔍介绍与分析📰小结与记忆口诀✒指针常量🔍介绍与分析📰小结与记忆口诀👉一份凉皮所引发的故事👈总结与提炼📚引言 本文我们来说说大家很困惑的两个东西&am…...

python 打包工具 pyinstaller和Nuitka区别
1.1 使用需求 这次也是由于项目需要,要将python的代码转成exe的程序,在找了许久后,发现了2个都能对python项目打包的工具——pyintaller和nuitka。 这2个工具同时都能满足项目的需要: 隐藏源码。这里的pyinstaller是通过设置key来…...
Python解题 - CSDN周赛第28期
上一期周赛问哥因为在路上,无法参加,但还是抽空登上来看了一下题目。4道题都挺简单的,有点遗憾未能参加。不过即使参加了,手速也未必能挤进前十。 本期也是一样,感觉新增的题目都偏数学类,基本用不到所谓的…...

MCP协议实战:用mcp-custom-dev构建AI助手专属工具链
1. 项目概述:一个为开发者赋能的MCP自定义开发工具最近在和一些做AI应用开发的朋友聊天,发现大家普遍遇到一个痛点:虽然现在大语言模型(LLM)的API调用很方便,但想把它们真正“嵌入”到自己的业务流程里&…...

JPlag代码抄袭检测:你的学术诚信守护神
JPlag代码抄袭检测:你的学术诚信守护神 【免费下载链接】JPlag State-of-the-Art Source Code Plagiarism & Collusion Detection. Check for plagiarism in a set of programs. 项目地址: https://gitcode.com/gh_mirrors/jp/JPlag 你是否曾为学生的代码…...

硅谷创新精神:从车库、真空管到一美元年薪的启示
1. 硅谷创新精神的物理原点:从车库到孤寂的一美元在科技圈待久了,总会听到一些传奇故事,比如乔布斯在车库里组装第一台苹果电脑,或者惠普的两位创始人在车库里捣鼓出第一个音频振荡器。这些故事被反复传颂,几乎成了硅谷…...

FinFET与FD-SOI工艺下的IC可靠性验证关键技术
1. 集成电路可靠性验证的挑战与演进在28nm工艺节点之前,芯片设计工程师面临的选择相对简单——只需沿着摩尔定律的轨迹向下一个工艺节点迁移。但随着FinFET和FD-SOI等新型晶体管结构的出现,以及台积电、三星等代工厂推出的多样化工艺节点选项,…...

Sora 2正式版突然开放API灰度权限?我们逆向解析了127行响应头与rate limit策略,发现3个隐藏调用阈值
更多请点击: https://intelliparadigm.com 第一章:Sora 2正式版核心能力与架构演进 Sora 2正式版标志着视频生成大模型从研究原型迈向工业级部署的关键跃迁。其底层架构采用分层时空联合建模(Hierarchical Spatio-Temporal Transformer&…...

BBDown终极指南:5分钟掌握B站视频本地化完整解决方案
BBDown终极指南:5分钟掌握B站视频本地化完整解决方案 【免费下载链接】BBDown Bilibili Downloader. 一个命令行式哔哩哔哩下载器. 项目地址: https://gitcode.com/gh_mirrors/bb/BBDown 在数字内容爆炸的时代,你是否曾为无法离线观看B站优质视频…...

收藏!小白程序员必备:2026年AI大模型就业新机遇与学习路线指南
根据世界经济论坛报告,到2030年科技、数据、AI等领域将创造1.7亿工作机会,同时淘汰9200万个岗位。AI市场规模预计到2034年达36804.7亿美元,年复合增长率19.20%。中国AI人才需求将远超供应。文章介绍了AI运营/AIGC内容创作者、算法工程师、大模…...

数据分析实习面试准备全攻略:专业知识+项目深挖+行为面试,职卓科技的面试辅导体系
摘要数据分析实习面试通常包含三大模块:专业知识考察(SQL、Python、统计学基础)、项目深挖(业务理解、技术选择、问题解决)、行为面试(团队协作、学习能力、职业规划)。很多学员在面试中表现不佳…...

终极大脑训练指南:5个简单步骤用BrainWorkshop提升你的认知能力
终极大脑训练指南:5个简单步骤用BrainWorkshop提升你的认知能力 【免费下载链接】brainworkshop Continued development of the popular brainworkshop game 项目地址: https://gitcode.com/gh_mirrors/br/brainworkshop BrainWorkshop是一款专业的免费开源大…...

Guitar Pro 8.1.5作为吉他爱好者的练琴神器,其跨平台支持与强大功能值得重点关注。本评测聚焦其核心优势与操作要点,为吉他学习者与原创音乐人提供高效解决方案。跨系统兼容性Guit
Guitar Pro 8.1.5作为吉他爱好者的练琴神器,其跨平台支持与强大功能值得重点关注。本评测聚焦其核心优势与操作要点,为吉他学习者与原创音乐人提供高效解决方案。跨系统兼容性 Guitar Pro 8.1.5同时支持macOS与Windows系统,mac用户无需转战Wi…...