论文阅读 | Video Super-Resolution Transformer
引言:2021年用Transformer实现视频超分VSR的文章,改进了SA并在FFN中加入了光流引导
论文:【here】
代码:【here】
Video Super-Resolution Transformer
引言
视频超分中有一组待超分的图片,因此视频超分也经常被看做是一个序列问题。这种序列问题的解决方法通常有RNN,SLTM,和transformer。由于transformer并不需要递归也更适合,并备受关注
注意力机制
目前用transformer处理图片的思路是全连接注意力机制,the fully connected self-attention(FCSA)
(这里的这个FCSA的概念是作者提出来的,作者举例VIT和PIT都是FCSA,因此我把它当做对整个图像的分成的块做自注意力)
然而,作者认为这样的FCSA的机制并不能很好的提取空间局部信息,但是局部信息对于VSR来说又是很关键的。
此外,除了空间局部信息,时域信息也是很重要的,视频中的图片中的信息可以通过相邻的图片进行补充。现在,该如何用transformer来处理时域信息也是没有被探索过的(这个领域还没有人做)
前馈网络
现有的前馈网络token-wise feed-forward layer不能实现图像之间的对齐,这里强调token,即是指全连接都是在每一个token中实现的,token和token之间没有关联。token 之间的特征关联在FCSA模块中实现的,但是在FFN中没有特征传播。因此,在这个模块中,作者实现了以像元为单位(而不是token),实现了特征传播和特征对齐
问题定义
第一个定义是映射函数的loss
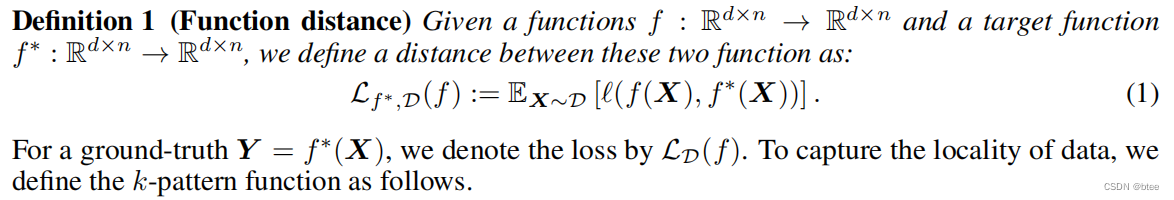
第二个定义是神经元组成/参数传播的定义,同时这个连接了不同神经元的映射与真实映射之间的loss应该小于一个epsilon

第三个定义为视频超分的定义和目标

第四个定义为transformer的架构

(这一块有点枯燥,主要是作者的第二个定义,神经元的参数传播为后面的公式推导奠定基础)
视频超分 Transformer
作者介绍了这样一个公式,来证明FCSA不太适合视频超分tranformer(公式没有看懂,我这里就跳过了)

总之,作者通过这个公式论证了全连接注意力机制FCSA会导致梯度消失的问题
When q is not sufficiently large, the fully connected attention layer may result in the gradient vanishing issue. It implies that the gradient descent will be “stuck” upon the initialization, and thus will fail to learn the k-pattern function. Therefore, the fully connected self-attention layer cannot use the spatial information of each frame since the local information is not encoded in the embeddings of all tokens. Moreover, this issue may become more serious when directly using such layers in video super-resolution.
而如果用作者提出的,则时空卷积自注意力机制STCSA很好的解决了这个问题

STCSA的实现
即将图片划成8 * 8 * 5的小块(这里的5是指连续的图片数),在8 * 8 * 5的3D块中实现块中的像元单位的特征自注意力
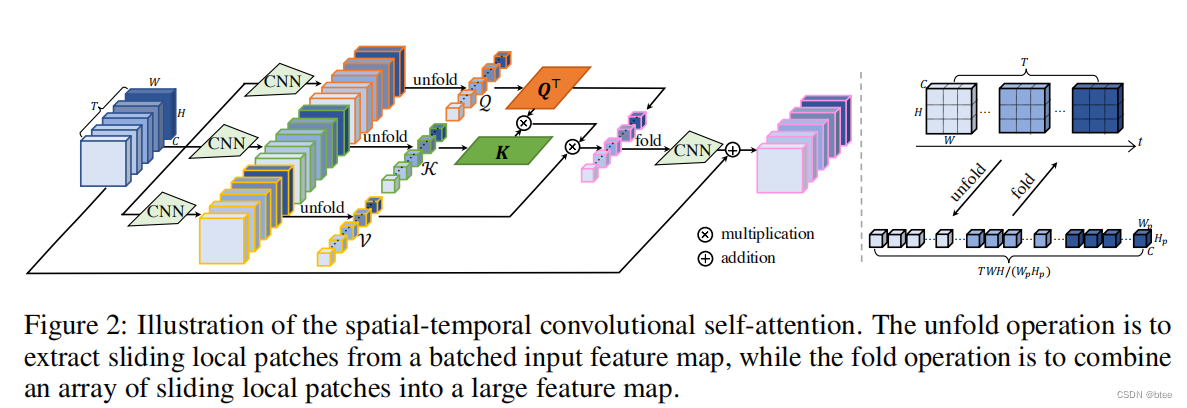
同时,作者还加入了一个3D位置编码信息,编码规则如下

代码(作者非常贴心的加上了尺寸的注释)
class globalAttention(nn.Module):def __init__(self, num_feat=64, patch_size=8, heads=1):super(globalAttention, self).__init__()self.heads = headsself.dim = patch_size ** 2 * num_featself.hidden_dim = self.dim // headsself.num_patch = (64 // patch_size) ** 2self.to_q = nn.Conv2d(in_channels=num_feat, out_channels=num_feat, kernel_size=3, padding=1, groups=num_feat) self.to_k = nn.Conv2d(in_channels=num_feat, out_channels=num_feat, kernel_size=3, padding=1, groups=num_feat)self.to_v = nn.Conv2d(in_channels=num_feat, out_channels=num_feat, kernel_size=3, padding=1)self.conv = nn.Conv2d(in_channels=num_feat, out_channels=num_feat, kernel_size=3, padding=1)self.feat2patch = torch.nn.Unfold(kernel_size=patch_size, padding=0, stride=patch_size)self.patch2feat = torch.nn.Fold(output_size=(64, 64), kernel_size=patch_size, padding=0, stride=patch_size)def forward(self, x):b, t, c, h, w = x.shape # B, 5, 64, 64, 64H, D = self.heads, self.dimn, d = self.num_patch, self.hidden_dimq = self.to_q(x.view(-1, c, h, w)) # [B*5, 64, 64, 64] k = self.to_k(x.view(-1, c, h, w)) # [B*5, 64, 64, 64] v = self.to_v(x.view(-1, c, h, w)) # [B*5, 64, 64, 64]unfold_q = self.feat2patch(q) # [B*5, 8*8*64, 8*8]unfold_k = self.feat2patch(k) # [B*5, 8*8*64, 8*8] unfold_v = self.feat2patch(v) # [B*5, 8*8*64, 8*8] unfold_q = unfold_q.view(b, t, H, d, n) # [B, 5, H, 8*8*64/H, 8*8]unfold_k = unfold_k.view(b, t, H, d, n) # [B, 5, H, 8*8*64/H, 8*8]unfold_v = unfold_v.view(b, t, H, d, n) # [B, 5, H, 8*8*64/H, 8*8]unfold_q = unfold_q.permute(0,2,3,1,4).contiguous() # [B, H, 8*8*64/H, 5, 8*8]unfold_k = unfold_k.permute(0,2,3,1,4).contiguous() # [B, H, 8*8*64/H, 5, 8*8]unfold_v = unfold_v.permute(0,2,3,1,4).contiguous() # [B, H, 8*8*64/H, 5, 8*8]unfold_q = unfold_q.view(b, H, d, t*n) # [B, H, 8*8*64/H, 5*8*8]unfold_k = unfold_k.view(b, H, d, t*n) # [B, H, 8*8*64/H, 5*8*8]unfold_v = unfold_v.view(b, H, d, t*n) # [B, H, 8*8*64/H, 5*8*8]attn = torch.matmul(unfold_q.transpose(2,3), unfold_k) # [B, H, 5*8*8, 5*8*8]attn = attn * (d ** (-0.5)) # [B, H, 5*8*8, 5*8*8]attn = F.softmax(attn, dim=-1) # [B, H, 5*8*8, 5*8*8]attn_x = torch.matmul(attn, unfold_v.transpose(2,3)) # [B, H, 5*8*8, 8*8*64/H]attn_x = attn_x.view(b, H, t, n, d) # [B, H, 5, 8*8, 8*8*64/H]attn_x = attn_x.permute(0, 2, 1, 4, 3).contiguous() # [B, 5, H, 8*8*64/H, 8*8]attn_x = attn_x.view(b*t, D, n) # [B*5, 8*8*64, 8*8]feat = self.patch2feat(attn_x) # [B*5, 64, 64, 64]out = self.conv(feat).view(x.shape) # [B, 5, 64, 64, 64]out += x # [B, 5, 64, 64, 64]return out
这样就完全考虑8 * 8感受野内的局部特征了,但是块与块之间的边缘只能朝一个方向进行特征传播
于是作者提出了一种新型的FFN
feed-forward Network实现
作者首先将5张图片中的相邻光流求出来,如果边缘图像的另一边没有图了,则跟自己作光流
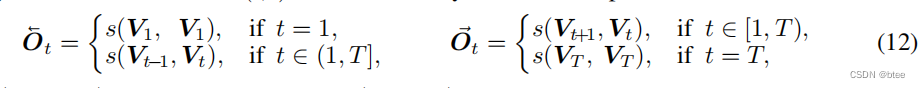
这样可以得到5 * 2张光流图(这里的5指视频图片数),每张图片都有它的前向流图和后向流图,然后前向warp和后向warp后,原有的每张图的时间位置上都可以多加两张图,分别来自前一时刻图片前向warp得到,和后一时刻的图片后向warp得到
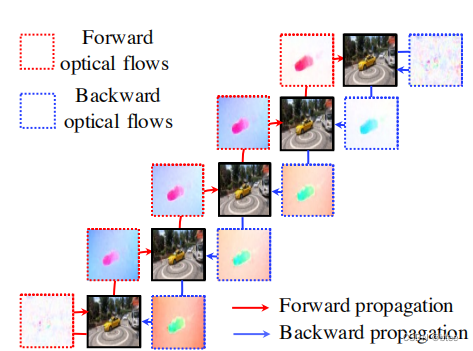
然后通过两组图片的融合,即生成了最终结果
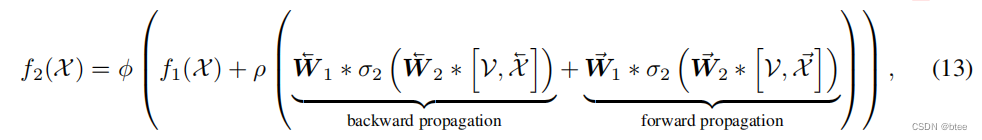
值得一提的是,这里的FFN和传统FFN不同,由于前面的SA部分保留的图片的原有尺寸,这里的FFN直接用3*3卷积实现
class FeedForward(nn.Module):def __init__(self, num_feat):super().__init__()self.backward_resblocks = ResidualBlocksWithInputConv(num_feat+3, num_feat, num_blocks=30)self.forward_resblocks = ResidualBlocksWithInputConv(num_feat+3, num_feat, num_blocks=30)self.fusion = nn.Conv2d(num_feat*2, num_feat, 1, 1, 0, bias=True)self.lrelu = nn.LeakyReLU(negative_slope=0.1, inplace=True)def forward(self, x, lrs=None, flows=None):b, t, c, h, w = x.shapex1 = torch.cat([x[:, 1:, :, :, :], x[:, -1, :, :, :].unsqueeze(1)], dim=1) # [B, 5, 64, 64, 64]flow1 = flows[1].contiguous().view(-1, 2, h, w).permute(0, 2, 3, 1) # [B*5, 64, 64, 2]x1 = flow_warp(x1.view(-1, c, h, w), flow1) # [B*5, 64, 64, 64]x1 = torch.cat([lrs.view(b*t, -1, h, w), x1], dim=1) # [B*5, 67, 64, 64]x1 = self.backward_resblocks(x1) # [B*5, 64, 64, 64]x2 = torch.cat([x[:, 0, :, :, :].unsqueeze(1), x[:, :-1, :, :, :]], dim=1) # [B, 5, 64, 64, 64]flow2 = flows[0].contiguous().view(-1, 2, h, w).permute(0, 2, 3, 1) # [B*5, 64, 64, 2]x2 = flow_warp(x2.view(-1, c, h, w), flow2) # [B*5, 64, 64, 64]x2 = torch.cat([lrs.view(b*t, -1, h, w), x2], dim=1) # [B*5, 67, 64, 64]x2 = self.forward_resblocks(x2) # [B*5, 64, 64, 64]# fusion the backward and forward featuresout = torch.cat([x1, x2], dim=1) # [B*5, 128, 64, 64]out = self.lrelu(self.fusion(out)) # [B*5, 64, 64, 64]out = out.view(x.shape) # [B, 5, 64, 64, 64] return out
实验
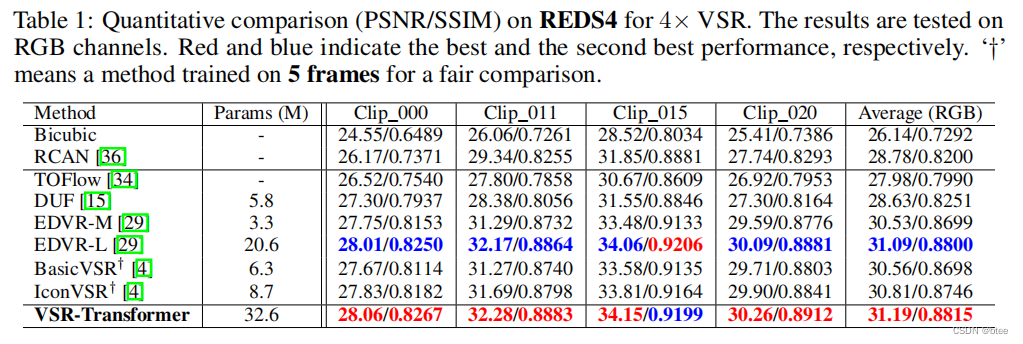

在别的文章里有看到块与块之间会出现伪影,然而文章的结果挺完美的
总结
用transformer解决VSR的问题,虽然在空间小范围内进行attention是可行的,也不会造成太大的计算量,但是总觉得对于transformer的优势没有发挥出来,大的感受野和全局信息的利用才是transformer的优势所在
相关文章:
论文阅读 | Video Super-Resolution Transformer
引言:2021年用Transformer实现视频超分VSR的文章,改进了SA并在FFN中加入了光流引导 论文:【here】 代码:【here】 Video Super-Resolution Transformer 引言 视频超分中有一组待超分的图片,因此视频超分也经常被看做…...

7-6 带头节点的双向循环链表操作
本题目要求读入一系列整数,依次插入到双向循环链表的头部和尾部,然后顺序和逆序输出链表。 链表节点类型可以定义为 typedef int DataType; typedef struct LinkedNode{DataType data;struct LinkedNode *prev;struct LinkedNode *next; }LinkedNode;链…...

npm publish 、 npm adduser 提示 403 的问题
0. 查看使用的源:npm config get registry1. 如果使用的不是官方的源,切换:npm config set registry https://registry.npmjs.org/2. 登录:npm adduser3. 查看是否登录成功:npm whoami4. 执行发布命令:npm …...

Java 8的函数式接口使用示例
什么是函数式接口 有且只有一个抽象方法的接口被称为函数式接口,函数式接口适用于函数式编程的场景,Lambda就是Java中函数式编程的体现,可以使用Lambda表达式创建一个函数式接口的对象,一定要确保接口中有且只有一个抽象方法&…...

2023年企业如何改善员工体验?为什么员工体验很重要?
什么是员工体验?大约 96% 的企业领导者表示,专注于员工体验可以更轻松地留住顶尖人才。[1] 这还不是全部。令人震惊的是,87%的企业领导者还表示,优先考虑员工的幸福感将给他们带来竞争优势。尽管有这些发现,但只有19%的…...
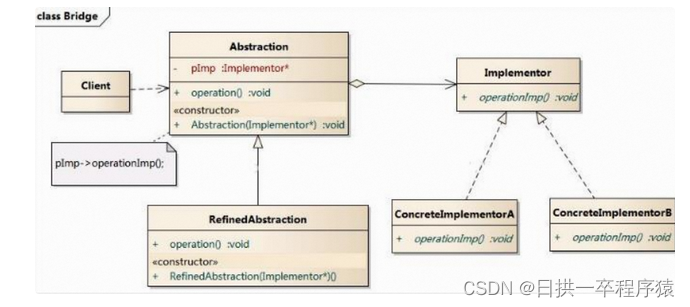
设计模式:桥接模式让抽象和实现解耦,各自独立变化
一、问题场景 现在对”不同手机类型“的 “不同品牌”实现操作编程(比如: 开机、关机、上网,打电话等) 二、传统解决方案 传统方案解决手机使用问题类图: 三、传统方案分析 传统方案解决手机操作问题分析 1、扩展性问题(类爆炸),如果我们…...

C++学习记录——십 STL初级认识、标准库string类
文章目录1、什么是STL2、STL简介3、什么是string类4、string类的常用接口说明1、常见构造函数2、容量操作3、迭代器4、其他的标准库的string类关于string类的内容,可以在cplusplus.com查看到。 1、什么是STL STL是C标准库的重要组成部分,不仅是一个可复…...
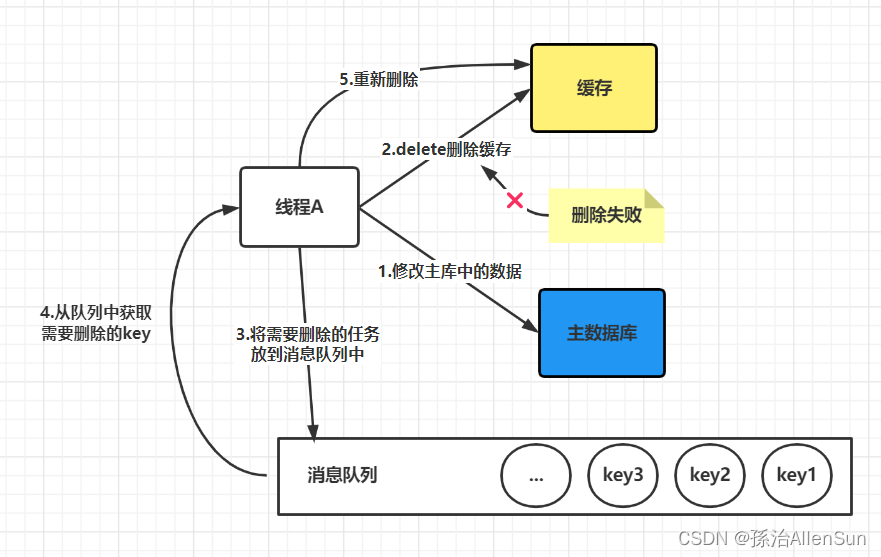
【redis】redis缓存与数据库的一致性
【redis】redis缓存与数据库的一致性【1】四种同步策略【2】更新缓存还是删除缓存(1)更新缓存(2)删除缓存【3】先更新数据库还是先删除缓存(1)出现失败时候的情况1-先删除缓存,再更新数据库&…...
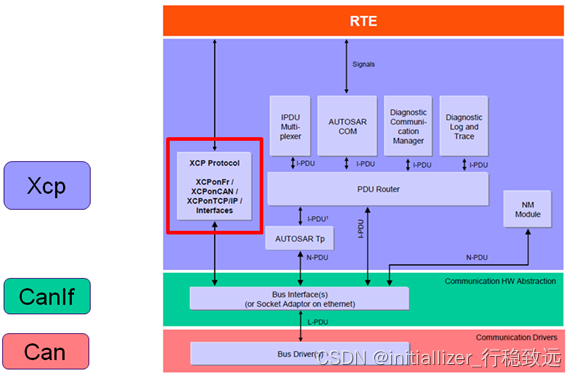
XCP实战系列介绍12-基于Vector_Davinci工具的XCP配置介绍(一)
本文框架 1.概述2. EcuC配置2.1 Pdu添加步骤2.2 配置项说明3. Can 模块配置4. CanIf 模块配置4.1 接收帧的Hardware Receive Object配置4.2 接收帧和发送帧的Pdu配置1.概述 在文章《看了就会的XCP协议介绍》中详细介绍了XCP的协议,在《XCP实战系列介绍01-测量与标定底层逻辑》…...
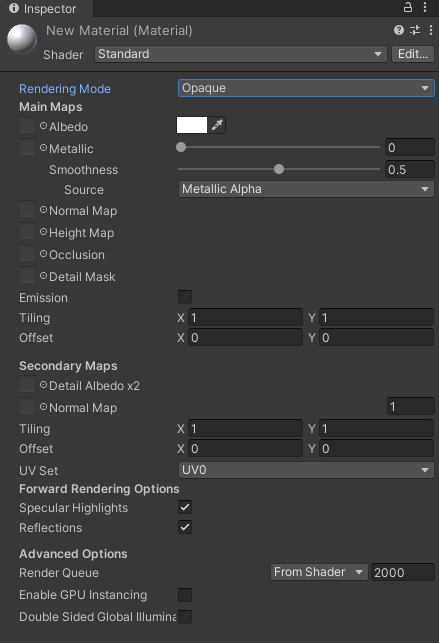
Unity Material详解
一、创建 二、属性 1.Shader:Unity内置了一些shader,用户自定义的shader也在这里出现. Edit: 可以编辑一些shader可编辑的内容,如一些属性. 2.Rendering Mode:渲染模式 Opaque-不透明-石头适用于所有的不透明的物体Cutout-镂空-破布透明度只有0%和100…...

碰撞检测算法分类
包围形法粗糙检测, 包含以下两种类检测外接圆法轴对齐包围矩形, AABB 碰撞检测算法之包围形法分离轴精细检测 BOX vs PolygonOBBseparating Axis Theorem碰撞检测算法之分离轴定理GJKGJK(Gilbert–Johnson–Keerthi), 相比 SAT 算法ÿ…...

代码随想录第十二天(
文章目录232. 用栈实现队列补充知识——Deque232. 用栈实现队列 答案思路: 在push数据的时候,只要数据放进输入栈就好,但在pop的时候,操作就复杂一些,输出栈如果为空,就把进栈数据全部导入进来࿰…...

电源模块 DC-DC直流升压正负高压输出12v24v转±110V±150V±220V±250V±300V±600V
特点效率高达80%以上1*2英寸标准封装电源正负双输出稳压输出工作温度: -40℃~85℃阻燃封装,满足UL94-V0 要求温度特性好可直接焊在PCB 上应用HRA 1~40W系列模块电源是一种DC-DC升压变换器。该模块电源的输入电压分为:4.5~9V、9~18V、及18~36VDC标准&…...
【动画图解】这个值取对了,ViewPager2才能纵享丝滑
前言 在前两篇文章中,我们通过一张张清晰明了的「示意图」,详细地复盘了RecyclerView「缓存复用机制」与「预拉取机制」的工作流程,这种「图解」创作形式也得到了来自不同平台读者们的一致认可。 而从本文开始,我们将正式进入Vi…...
CSDN每日一练:小豚鼠搬家
题目名称:小豚鼠搬家 时间限制:1000ms内存限制:256M 题目描述 小豚鼠排排坐。 小艺酱买了一排排格子的小房子n*m,她想让k只小豚鼠每只小豚鼠都有自己的房子。 但是为了不浪费空间,她想要小房子的最外圈尽量每行每列都有…...

Dockerfile命令及实践构建一个网站
dockerfile用于构建docker镜像的,部署一个用于运行你所需的容器环境。相当一个脚本,通过dockerfile自己的指令,来构建软件依赖、文件依赖、存储、定制docker镜像的方式有两种:手动修改容器内容,导出新的镜像基于Docker…...
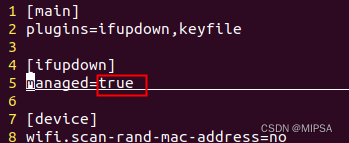
[VMware]Ubuntu18.04 网络图标消失
Ubuntu 18.04 网络图标消失运行环境问题解决NO.1 执行 sudo systemctl stop network-managerNO.2 执行 sudo rm /var/lib/NetworkManager/NetworkManager.stateNO.3 执行 sudo systemctl start network-managerNO.4 vi /etc/NetworkManager/NetworkManager.confNO.5 执行 sudo …...

国产C2000,P2P替代TMS320F280049C,独立双核32位CPU,主频高达400MHz
一、特性参数 1、独立双核,32位CPU,单核主频400MHz 2、IEEE 754 单精度浮点单元 (FPU) 3、三角函数单元 (TMU) 4、1MB 的 FLASH (ECC保护) 5、1MB 的 SRAM (ECC保护&…...

二十五、Gtk4-多线程分析
1 回顾 1.1 Gnome相关 首先回顾一下GLib,GObject,GIO,Gtk的不同,因为下面会涉及到这些概念里面的函数。 所有这些都是由Gnome项目开发的库,一般都用于Gnome环境相关的应用程序。 Gtk:GUI界面库。GLib&a…...
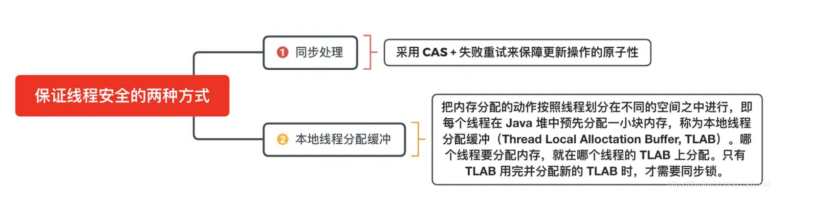
JVM基础学习
JVM分为两个子系统,两个组件一个子系统是Class loader类装载系统,另一个子系统是Execution Engine执行引擎一个组件是Runtime data area 运行时数据区,Native Interface 本地接口Class loader:根据给定的全限定类名来装载class文件到运行时数…...

如何快速掌握Unitree Go2机器人ROS2开发:面向初学者的完整教程
如何快速掌握Unitree Go2机器人ROS2开发:面向初学者的完整教程 【免费下载链接】go2_ros2_sdk Unofficial ROS2 SDK support for Unitree GO2 AIR/PRO/EDU 项目地址: https://gitcode.com/gh_mirrors/go/go2_ros2_sdk Unitree Go2 ROS2 SDK是一个强大的开源项…...
)
Claude长文档推理能力跃迁全记录(2024–2026技术演进图谱)
更多请点击: https://intelliparadigm.com 第一章:Claude 2026长文档推理能力的定义与边界 Claude 2026 的长文档推理能力指其在单次上下文窗口内(最大支持 2,000,000 tokens)对跨章节、多模态混合结构化文本(含嵌入表…...

XUnity.AutoTranslator终极指南:5分钟破解Unity游戏语言障碍
XUnity.AutoTranslator终极指南:5分钟破解Unity游戏语言障碍 【免费下载链接】XUnity.AutoTranslator 项目地址: https://gitcode.com/gh_mirrors/xu/XUnity.AutoTranslator 当你打开心爱的日系RPG游戏,却因为语言不通而无法理解剧情时ÿ…...

从SolidWorks到Simulink:手把手教你用Simscape Multibody Link搭建你的第一个虚拟样机
从SolidWorks到Simulink:手把手教你用Simscape Multibody Link搭建你的第一个虚拟样机 虚拟样机技术正在彻底改变传统机电系统的开发流程。想象一下,你刚刚在SolidWorks中完成了一个精巧的自动门闭锁装置的设计,现在不需要花费数周时间加工金…...

内容创作团队如何通过多模型选型提升文案生成质量与效率
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 内容创作团队如何通过多模型选型提升文案生成质量与效率 对于新媒体运营和内容营销团队而言,持续产出高质量、风格多样…...

解锁PS4游戏存档的终极掌控:Apollo Save Tool深度技术解析
解锁PS4游戏存档的终极掌控:Apollo Save Tool深度技术解析 【免费下载链接】apollo-ps4 Apollo Save Tool (PS4) 项目地址: https://gitcode.com/gh_mirrors/ap/apollo-ps4 在PlayStation 4的游戏生态中,PS4存档管理和游戏数据修改一直是玩家和开…...

如何彻底解决Minecraft离线启动限制:PrismLauncher-Cracked完全指南
如何彻底解决Minecraft离线启动限制:PrismLauncher-Cracked完全指南 【免费下载链接】PrismLauncher-Cracked This project is a Fork of Prism Launcher, which aims to unblock the use of Offline Accounts, disabling the restriction of having a functional O…...

免费开源!3分钟让Mac鼠标滚动告别卡顿的终极平滑方案
免费开源!3分钟让Mac鼠标滚动告别卡顿的终极平滑方案 【免费下载链接】Mos 一个用于在 macOS 上平滑你的鼠标滚动效果或单独设置滚动方向的小工具, 让你的滚轮爽如触控板 | A lightweight tool used to smooth scrolling and set scroll direction independently fo…...

AI编程助手色彩科学技能库:从OKLCH到APCA的现代色彩实践
1. 项目概述:一个为AI编程助手打造的“色彩科学专家”技能库如果你和我一样,经常在开发与色彩相关的工具、设计系统,或者需要向团队解释为什么某个颜色方案行不通时,总得反复查阅同一堆资料——那个讲解OKLAB色彩空间的视频、那篇…...

OpencvSharp 算子学习教案之 - Cv2.Sobel
OpencvSharp 算子学习教案之 - Cv2.Sobel 大家好,Opencv在很多工程项目中都会用到,而OpencvSharp则是以C#开发与实现的Opencv操作库,对.NET开发人员友好,但很多API的中文资料、应用场景及常见坑点等缺乏系统性归纳,因此…...