一篇解决Linux 中的负载高低和 CPU 开销并不完全对应
负载是查看 Linux 服务器运行状态时很常用的一个性能指标。在观察线上服务器运行状况的时候,我们也是经常把负载找出来看一看。在线上请求压力过大的时候,经常是也伴随着负载的飙高。
但是负载的原理你真的理解了吗?我来列举几个问题,看看你对负载的理解是否足够的深刻。
- 负载是如何计算出来的?
- 负载高低和 CPU 消耗正相关吗?
- 内核是如何暴露负载数据给应用层的?
如果你对以上问题的理解还拿捏不是很准,那么今天就带你来深入地了解一下 Linux 中的负载 !
一、理解负载查看过程
我们经常用 top 命令查看 Linux 系统的负载情况。一个典型的 top 命令输出的负载如下所示。
# top
Load Avg: 1.25, 1.30, 1.95 .....
......输出中的 Load Avg 就是我们常说的负载,也叫系统平均负载。因为单纯某一个瞬时的负载值并没有太大意义。所以 Linux 是计算了过去一段时间内的平均值,这三个数分别代表的是过去 1 分钟、过去 5 分钟和过去 15 分钟的平均负载值。
那么 top 命令展示的数据数是如何来的呢?事实上,top 命令里的负载值是从 /proc/loadavg 这个伪文件里来的。通过 strace 命令跟踪 top 命令的系统调用可以看的到这个过程。
# strace top
...
openat(AT_FDCWD, "/proc/loadavg", O_RDONLY) = 7内核中定义了 loadavg 这个伪文件的 open 函数。当用户态访问 /proc/loadavg 会触发内核定义的函数,在这里会读取内核中的平均负载变量,简单计算后便可展示出来。整体流程如下图所示。

我们根据上述流程图再展开了看下。伪文件 /proc/loadavg 在 kernel 中定义是在 /fs/proc/loadavg.c 中。在该文件中会创建 /proc/loadavg,并为其指定操作方法 loadavg_proc_fops。
//file: fs/proc/loadavg.c
static int __init proc_loadavg_init(void)
{proc_create("loadavg", 0, NULL, &loadavg_proc_fops);return 0;
}在 loadavg_proc_fops 中包含了打开该文件时对应的操作方法。
//file: fs/proc/loadavg.c
static const struct file_operations loadavg_proc_fops = {.open = loadavg_proc_open,......
};当在用户态打开 /proc/loadavg 文件时,都会调用 loadavg_proc_fops 中的 open 函数指针 - loadavg_proc_open。loadavg_proc_open 接下来会调用 loadavg_proc_show 进行处理,核心的计算是在这里完成的。
//file: fs/proc/loadavg.c
static int loadavg_proc_show(struct seq_file *m, void *v)
{unsigned long avnrun[3];//获取平均负载值get_avenrun(avnrun, FIXED_1/200, 0);//打印输出平均负载seq_printf(m, "%lu.%02lu %lu.%02lu %lu.%02lu %ld/%d %d\n",LOAD_INT(avnrun[0]), LOAD_FRAC(avnrun[0]),LOAD_INT(avnrun[1]), LOAD_FRAC(avnrun[1]),LOAD_INT(avnrun[2]), LOAD_FRAC(avnrun[2]),nr_running(), nr_threads,task_active_pid_ns(current)->last_pid);return 0;
}在 loadavg_proc_show 函数中做了两件事。
- 调用 get_avenrun 读取当前负载值
- 将平均负载值按照一定的格式打印输出
在上面的源码中,大家看到了 FIXED_1/200、LOAD_INT、LOAD_FRAC 等奇奇怪怪的定义,代码写的这么猥琐是因为内核中并没有 float、double 等浮点数类型,而是用整数来模拟的。这些代码都是为了在整数和小数之间转化使的。知道这个背景就行了,不用过度展开剖析。
这样用户通过访问 /proc/loadavg 文件就可以读取到内核计算的负载数据了。其中获取 get_avenrun 只是在访问 avenrun 这个全局数组而已。
//file:kernel/sched/core.c
void get_avenrun(unsigned long *loads, unsigned long offset, int shift)
{loads[0] = (avenrun[0] + offset) << shift;loads[1] = (avenrun[1] + offset) << shift;loads[2] = (avenrun[2] + offset) << shift;
}现在可以总结一下我们开篇中的一个问题: 内核是如何暴露负载数据给应用层的 ?
内核定义了一个伪文件 /proc/loadavg,每当用户打开这个文件的时候,内核中的 loadavg_proc_show 函数就会被调用到,接着访问 avenrun 全局数组变量 并将平均负载从整数转化为小数,并打印出来。
好了,另外一个新问题又来了,avenrun 全局数组变量中存储的数据是何时,又是被如何计算出来的呢?
资料直通车:Linux内核源码技术学习路线+视频教程内核源码
学习直通车:Linux内核源码内存调优文件系统进程管理设备驱动/网络协议栈
二、内核中负载的计算过程
接上小节,我们继续查看 avenrun 全局数组变量的数据来源。这个数组的计算过程分为如下两步:
1.PerCPU 定期汇总瞬时负载 :定时刷新每个 CPU 当前任务数到 calc_load_tasks,将每个 CPU 的负载数据汇总起来,得到系统当前的瞬时负载。
2.定时计算系统平均负载 :定时器根据当前系统整体瞬时负载,使用指数加权移动平均法(一种高效计算平均数的算法)计算过去 1 分钟、过去 5 分钟、过去 15 分钟的平均负载。
接下来我们分成两个小节来分别介绍。
2.1 PerCPU 定期汇总负载
在 Linux 内核中,有一个子系统叫做时间子系统。在时间子系统里,初始化了一个叫高分辨率的定时器。在该定时器中会定时将每个 CPU 上的负载数据(running 进程数 + uninterruptible 进程数)汇总到系统全局的瞬时负载变量 calc_load_tasks 中。整体流程如下图所示。

我们把上述流程图展开看一下,我们找到了高分辨率定时器的源码如下:
//file:kernel/time/tick-sched.c
void tick_setup_sched_timer(void)
{//初始化高分辨率定时器 sched_timerhrtimer_init(&ts->sched_timer, CLOCK_MONOTONIC, HRTIMER_MODE_ABS);//将定时器的到期函数设置成 tick_sched_timerts->sched_timer.function = tick_sched_timer;...
}在高分辨率初始化的时候,将到期函数设置成了 tick_sched_timer。通过这个函数让每个 CPU 都会周期性地执行一些任务。其中刷新当前系统负载就是在这个时机进行的。这里有一点要注意一个前提是每个 CPU 都有自己独立的运行队列,。
我们根据 tick_sched_timer 的源码进行追踪,它依次通过调用 tick_sched_handle => update_process_times => scheduler_tick。最终在 scheduler_tick 中会刷新当前 CPU 上的负载值到 calc_load_tasks 上。因为每个 CPU 都在定时刷,所以 calc_load_tasks 上记录的就是整个系统的瞬时负载值。
我们来看下负责刷新的 scheduler_tick 这个核心函数:
//file:kernel/sched/core.c
void scheduler_tick(void)
{int cpu = smp_processor_id();struct rq *rq = cpu_rq(cpu);update_cpu_load_active(rq);...
}在这个函数中,获取当前 cpu 以及其对应的运行队列 rq(run queue),调用 update_cpu_load_active 刷新当前 CPU 的负载数据到全局数组中。
//file:kernel/sched/core.c
static void update_cpu_load_active(struct rq *this_rq)
{...calc_load_account_active(this_rq);
}//file:kernel/sched/core.c
static void calc_load_account_active(struct rq *this_rq)
{//获取当前运行队列的负载相对值delta = calc_load_fold_active(this_rq);if (delta)//添加到全局瞬时负载值atomic_long_add(delta, &calc_load_tasks);...
}在 calc_load_account_active 中看到,通过 calc_load_fold_active 获取当前运行队列的负载相对值,并把它加到全局瞬时负载值 calc_load_tasks 上。至此,calc_load_tasks 上就有了当前系统当前时间下的整体瞬时负载总数了 。
我们再展开看看是如何根据运行队列计算负载值的:
//file:kernel/sched/core.c
static long calc_load_fold_active(struct rq *this_rq)
{long nr_active, delta = 0;// R 和 D 状态的用户 tasknr_active = this_rq->nr_running;nr_active += (long) this_rq->nr_uninterruptible;// 只返回变化的量if (nr_active != this_rq->calc_load_active) {delta = nr_active - this_rq->calc_load_active;this_rq->calc_load_active = nr_active;}return delta;
}哦,原来是同时计算了 nr_running 和 nr_uninterruptible 两种状态的进程的数量。对应于用户空间中的 R 和 D 两种状态的 task 数(进程 OR 线程)。
由于 calc_load_tasks 是一个长期存在的数据。所以在刷新 rq 里的进程数到其上的时候,只需要刷变化的量就行,不用全部重算。因此上述函数返回的是一个 delta。
2.2 定时计算系统平均负载
上一小节中我们找到了系统当前瞬时负载 calc_load_tasks 变量的更新过程。现在我们还缺一个计算过去 1 分钟、过去 5 分钟、过去 15 分钟平均负载的机制。
传统意义上,我们在计算平均数的时候采取的方法都是把过去一段时间的数字都加起来然后平均一下。把过去 N 个时间点的所有瞬时负载都加起来取一个平均数不完事了。这其实是我们传统意义上理解的平均数,假如有 n 个数字,分别是 x1, x2, ..., xn。那么这个数据集合的平均数就是 (x1 + x2 + ... + xn) / N。
但是如果用这种简单的算法来计算平均负载的话,存在以下几个问题:
1.需要存储过去每一个采样周期的数据
假设我们每 10 毫秒都采集一次,那么就需要使用一个比较大的数组将每一次采样的数据全部都存起来,那么统计过去 15 分钟的平均数就得存 1500 个数据(15 分钟 * 每分钟 100 次) 。而且每出现一个新的观察值,就要从移动平均中减去一个最早的观察值,再加上一个最新的观察值,内存数组会频繁地修改和更新。
2.计算过程较为复杂
计算的时候再把整个数组全加起来,再除以样本总数。虽然加法很简单,但是成百上千个数字的累加仍然很是繁琐。
3.不能准确表示当前变化趋势 传统的平均数计算过程中,所有数字的权重是一样的。但对于平均负载这种实时应用来说,其实越靠近当前时刻的数值权重应该越要大一些才好。因为这样能更好反应近期变化的趋势。
所以,在 Linux 里使用的并不是我们所以为的传统的平均数的计算方法,而是采用的一种指数加权移动平均(Exponential Weighted Moving Average,EMWA) 的平均数计算法。
这种指数加权移动平均数计算法在深度学习中有很广泛的应用。另外股票市场里的 EMA 均线也是使用的是类似的方法求均值的方法。该算法的数学表达式是:a1 = a0 * factor + a * (1 - factor)。这个算法想理解起来有点小复杂,感兴趣的同学可以 Google 自行搜索。
我们只需要知道这种方法在实际计算的时候只需要上一个时间的平均数即可,不需要保存所有瞬时负载值。另外就是越靠近现在的时间点权重越高,能够很好地表示近期变化趋势。
这其实也是在时间子系统中定时完成的,通过一种叫做指数加权移动平均计算的方法,计算这三个平均数。

我们来详细看下上图中的执行过程。时间子系统将在时钟中断中会注册时钟中断的处理函数为 timer_interrupt 。
//file:arch/ia64/kernel/time.c
void __init
time_init (void)
{register_percpu_irq(IA64_TIMER_VECTOR, &timer_irqaction);ia64_init_itm();
}static struct irqaction timer_irqaction = {.handler = timer_interrupt,.flags = IRQF_DISABLED | IRQF_IRQPOLL,.name = "timer"
};当每次时钟节拍到来时会调用到 timer_interrupt,依次会调用到 do_timer 函数。
//file:kernel/time/timekeeping.c
void do_timer(unsigned long ticks)
{ ...calc_global_load(ticks);
}其中 calc_global_load 是平均负载计算的核心 。它会获取系统当前瞬时负载值 calc_load_tasks,然后来计算过去 1 分钟、过去 5 分钟、过去 15 分钟的平均负载,并保存到 avenrun 中,供用户进程读取。
//file:kernel/sched/core.c
void calc_global_load(unsigned long ticks)
{...// 1.获取当前瞬时负载值active = atomic_long_read(&calc_load_tasks);// 2.平均负载的计算avenrun[0] = calc_load(avenrun[0], EXP_1, active);avenrun[1] = calc_load(avenrun[1], EXP_5, active);avenrun[2] = calc_load(avenrun[2], EXP_15, active);...
}获取瞬时负载比较简单,就是读取一个内存变量而已。在 calc_load 中就是采用了我们前面说的指数加权移动平均法 来计算过去 1 分钟、过去 5 分钟、过去 15 分钟的平均负载的。具体实现的代码如下:
//file:kernel/sched/core.c
/** a1 = a0 * e + a * (1 - e)*/
static unsigned long
calc_load(unsigned long load, unsigned long exp, unsigned long active)
{load *= exp;load += active * (FIXED_1 - exp);load += 1UL << (FSHIFT - 1);return load >> FSHIFT;
}虽然这个算法理解起来挺复杂,但是代码看起来确实要简单不少,计算量看起来很少。而且看不懂也没有关系,只需要知道内核并不是采用的原始的平均数计算方法,而是采用了一种计算快,且能更好表达变化趋势的算法就行。
至此,我们开篇提到的**“负载是如何计算出来的?”** 这个问题也有结论了。
Linux 定时将每个 CPU 上的运行队列中 running 和 uninterruptible 的状态的进程数量汇总到一个全局系统瞬时负载值中,然后再定时使用指数加权移动平均法来统计过去 1 分钟、过去 5 分钟、过去 15 分钟的平均负载。
三、平均负载和 CPU 消耗的关系
现在很多同学都将平均负载和 CPU 给联系到了一起。认为负载高、CPU 消耗就会高,负载低,CPU 消耗就会低。
在很老的 Linux 的版本里,统计负载的时候确实是只计算了 runnable 的任务数量,这些进程只对 CPU 有需求。在那个年代里,负载和 CPU 消耗量确实是正相关的。负载越高就表示正在 CPU 上运行,或等待 CPU 执行的进程越多,CPU 消耗量也会越高。
但是前面我们看到了,本文使用的 3.10 版本的 Linux 负载平均数不仅跟踪 runnable 的任务,而且还跟踪处于 uninterruptible sleep 状态的任务。而 uninterruptible 状态的进程其实是不占 CPU 的。

所以说,负载高并一定是 CPU 处理不过来,也有可能会是因为磁盘等其他资源调度不过来而使得进程进入 uninterruptible 状态的进程导致的!
为什么要这么修改。我从网上搜到了远在 1993 年的一封邮件里找到了原因,以下是邮件原文。
From: Matthias Urlichs <[email]urlichs@smurf.sub.org[/email]>
Subject: Load average broken ?
Date: Fri, 29 Oct 1993 11:37:23 +0200The kernel only counts "runnable" processes when computing the load average.
I don't like that; the problem is that processes which are swapping or
waiting on "fast", i.e. noninterruptible, I/O, also consume resources.It seems somewhat nonintuitive that the load average goes down when you
replace your fast swap disk with a slow swap disk...Anyway, the following patch seems to make the load average much more
consistent WRT the subjective speed of the system. And, most important, the
load is still zero when nobody is doing anything. ;-)--- kernel/sched.c.orig Fri Oct 29 10:31:11 1993
+++ kernel/sched.c Fri Oct 29 10:32:51 1993
@@ -414,7 +414,9 @@unsigned long nr = 0;for(p = &LAST_TASK; p > &FIRST_TASK; --p)
- if (*p && (*p)->state == TASK_RUNNING)
+ if (*p && ((*p)->state == TASK_RUNNING) ||
+ (*p)->state == TASK_UNINTERRUPTIBLE) ||
+ (*p)->state == TASK_SWAPPING))nr += FIXED_1;return nr;}可见这个修改是在 1993 年就引入了。在这封邮件所示的 Linux 源码变化中可以看到,负载正式把 TASK_UNINTERRUPTIBLE 和 TASK_SWAPPING 状态(交换状态后来从 Linux 中删除)的进程也给添加了进来。在这封邮件中的正文中,作者也清楚地表达了为什么要把 TASK_UNINTERRUPTIBLE 状态的进程添加进来的原因。我把他的说明翻译一下,如下:
“内核在计算平均负载时只计算“可运行”进程。我不喜欢那样;问题是正在“快速”交换或等待的进程,即不可中断的 I/O,也会消耗资源。当您用慢速交换磁盘替换快速交换磁盘时,平均负载下降似乎有点不直观...... 无论如何,下面的补丁似乎使负载平均值更加一致 WRT 系统的主观速度。而且,最重要的是,当没有人做任何事情时,负载仍然为零。;-)”
这一补丁提交者的主要思想是平均负载应该表现对系统所有资源的需求情况,而不应该只表现对 CPU 资源的需求 。
假设某个 TASK_UNINTERRUPTIBLE 状态的进程因为等待磁盘 IO 而排队的话,此时它并不消耗 CPU,但是正在等磁盘等硬件资源。那么它是应该体现在平均负载的计算里的。所以作者把 TASK_UNINTERRUPTIBLE 状态的进程都表现到平均负载里了。
所以,负载高低表明的是当前系统上对系统资源整体需求更情况。如果负载变高,可能是 CPU 资源不够了,也可能是磁盘 IO 资源不够了,所以还需要配合其它观测命令具体分情况分析。
四、总结
今天我带大家深入地学习了一下 Linux 中的负载。我们根据一幅图来总结一下今天学到的内容。

我把负载工作原理分成了如下三步。
- 1.内核定时汇总每 CPU 负载到系统瞬时负载
- 2.内核使用指数加权移动平均快速计算过去1、5、15分钟的平均数
- 3.用户进程通过打开 loadavg 读取内核中的平均负载
我们再回头来总结一下开篇提到的几个问题。
1.负载是如何计算出来的?
是定时将每个 CPU 上的运行队列中 running 和 uninterruptible 的状态的进程数量汇总到一个全局系统瞬时负载值中,然后再定时使用指数加权移动平均法来统计过去 1 分钟、过去 5 分钟、过去 15 分钟的平均负载。
2.负载高低和 CPU 消耗正相关吗?
负载高低表明的是当前系统上对系统资源整体需求更情况。如果负载变高,可能是 CPU 资源不够了,也可能是磁盘 IO 资源不够了。所以不能说看着负载变高,就觉得是 CPU 资源不够用了。
3.内核是如何暴露负载数据给应用层的?
内核定义了一个伪文件 /proc/loadavg,每当用户打开这个文件的时候,内核中的 loadavg_proc_show 函数就会被调用到,该函数中访问 avenrun 全局数组变量,并将平均负载从整数转化为小数,然后打印出来。

相关文章:
一篇解决Linux 中的负载高低和 CPU 开销并不完全对应
负载是查看 Linux 服务器运行状态时很常用的一个性能指标。在观察线上服务器运行状况的时候,我们也是经常把负载找出来看一看。在线上请求压力过大的时候,经常是也伴随着负载的飙高。 但是负载的原理你真的理解了吗?我来列举几个问题&#x…...
关于IDM下载器,提示:一个假冒的序列号被用来注册……idea项目文件路径报红
关于IDM下载器,提示:一个假冒的序列号被用来注册……到C:\Windows\System32\drivers\etc 修改目录下面的hosts文件(如果没有修改的权限就右键属性hosts文件修改user的权限为完全控制),在hosts里面增加以下内容…...
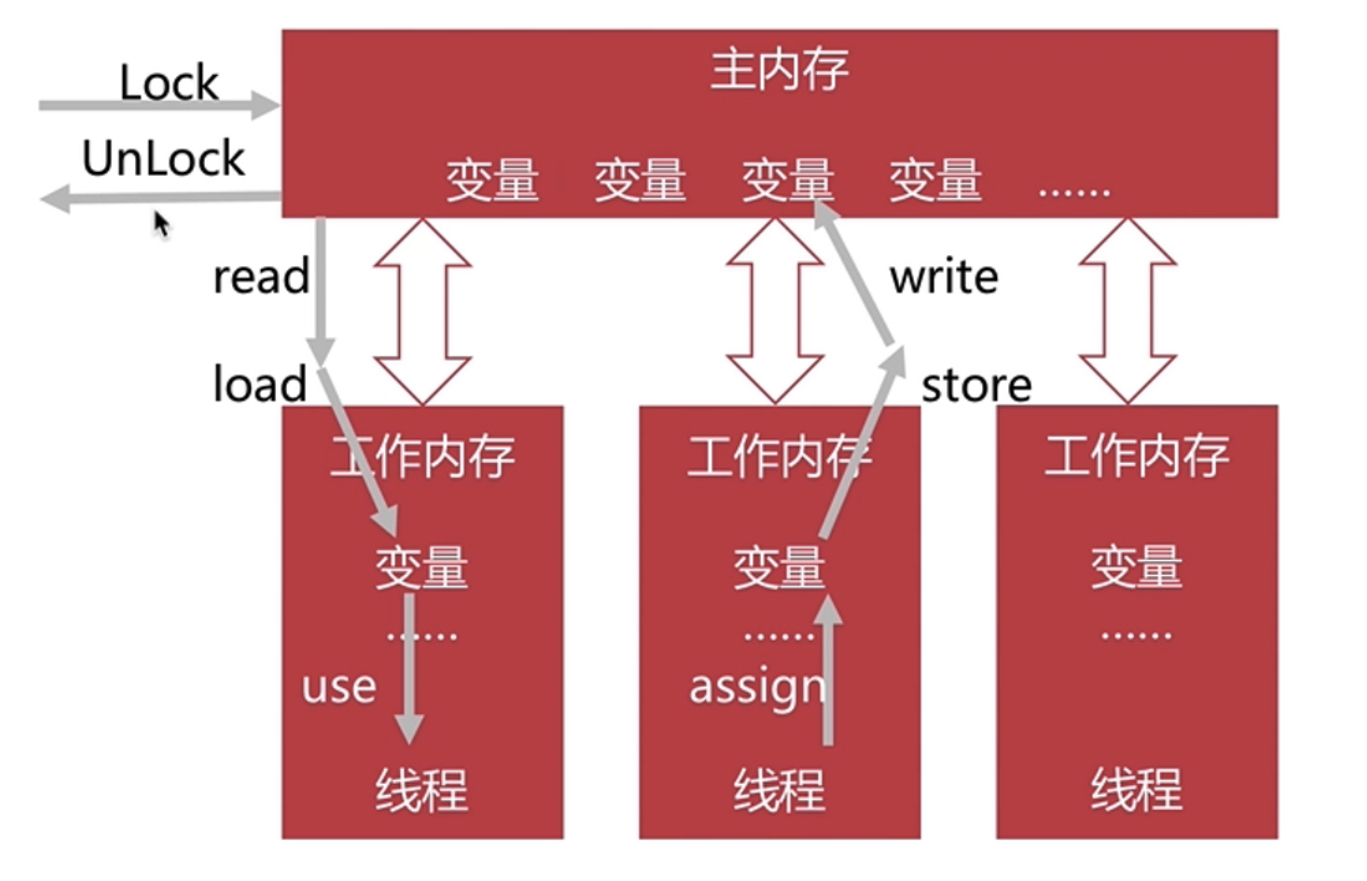
JVM - 高效并发
目录 Java内存模型和内存间的交互操作 Java内存模型 内存间的交互操作 内存间交互操作的规则 volatile特性 多线程中的可见性 volatile 指令重排原理和规则 指令重排 指令重排的基本规则 多线程中的有序性 线程安全处理 锁优化 锁优化之自旋锁与自适应自旋 锁优…...

中小学智慧校园电子班牌系统源码 Saas云平台模式
智慧电子班牌区别于传统电子班牌,智慧校园电子班牌系统更加注重老师和学生的沟通交流和及时数据交互。学校为每个教室配置一台智能电子班牌,一般安装于教室门口,用来实时显示学校通知、班级通知,可设置集中分布式管理,…...

记录一次服务器被攻击的经历
突然收到阿里云发过来的异常登陆的信息: 于是,急忙打开电脑查看对应的ECS服务器的记录: 发现服务器的cpu占用率异常飙升,所以可以大概断定服务器已经被非法入侵了。 通过自己的账号登陆后,发现sshd服务有异常的链接存…...
Python解题 - CSDN周赛第29期 - 争抢糖豆
本期问哥是志在必得,这本算法书我已经觊觎许久,而之前两次因为种种原因未能如愿。因此,问哥这几天花了不少时间,把所有之前在每日一练做过的题目重新梳理了一遍。苦心人,天不负,感谢官方大大! 第…...

C代码中访问链接脚本中的符号
一、目的在之前的《GNU LD脚本命令语言(一)》、《GNU LD脚本命令语言(二)》我们介绍了GNU链接脚本的知识点,基本上对链接脚本中的SECTION、REGION、以及加载地址与执行地址的关系等内容有了一定的了解。本篇主要讲解链…...
MySQL 8:MySQL索引
索引就是通过一定的算法建立数据模型,用于快速查找某一列中具有特定值的行。如果没有索引,MySQL 必须从第一条记录开始读取整个表,直到找到相关的表。表越大,查询数据所花费的时间就越多。如果表中查询的列有索引,MySQ…...
JVM详解
一,JVM 1,JVM区域划分 类装载器,运行时数据区,字节码执行引擎 2,JVM内存模型(运行时数据区) 由本地方法栈,虚拟机栈,堆,方法区,和程序计数器组成。…...
MySQL数据库调优————索引数据结构
B-TREE B-TREE数据结构 B-TREE特性 根节点的子结点个数2 < X < m,m是树的阶 假设m 3,则根节点可有2-3个孩子 中间节点的子节点个数m/2 < y < m 假设m 3,中间节点至少有2个孩子,最多3个孩子 每个中间节点包含n个关…...

visual studio 改变界面语言
在使用visual studio 2019 时,开始是英文界面,后面变成了中文界面。但是看视频教学时有的是英文界面,我就想回到英文界面,所以有切换界面语言的需要。其实操作很简单:工具-> 选项 打开界面在界面里选择环境…...

2023.2.16每日一题——1250. 检查「好数组」
每日一题题目描述解题核心解法一:数论题目描述 题目链接:1250. 检查「好数组」 给你一个正整数数组 nums,你需要从中任选一些子集,然后将子集中每一个数乘以一个 任意整数,并求出他们的和。 假如该和结果为 1&#x…...

亿级高并发电商项目-- 实战篇 --万达商城项目 八(安装FastDFS、安装Nginx、文件服务模块、文件上传功能、商品功能与秒杀商品等功能)
专栏:高并发---分布式项目 👏作者简介:大家好,我是小童,Java开发工程师,CSDN博客博主,Java领域新星创作者 📕系列专栏:前端、Java、Java中间件大全、微信小程序、微信支…...

Viper捐款7000万韩元,合计人民币是多少钱?
Viper捐款7000万韩元,合计人民币是多少钱? #2023LCK春季赛##英雄联盟# #Viper捐款7000万韩元# Viper向大田东区捐款 7000 万,成为大田荣誉协会 105 号会员。Viper选手从 2019 年开始一直向大田东区捐款,但是他不希望这件事被公开…...
前端vue实现系统拦截跳转外链并进入跳转询问界面
跳转询问界面如下图所示: 给自己挖坑的实现方式,最终解决方案请看最底下 思路:正常情况下我们有2种方式跳转外链 第一种非a标签,我们手动添加事件进行跳转 <div class"dingdan public-padding p-item" click&quo…...
单引号、双引号、不加引号和反引号用法和区别详解)
【Linux】Shell(Bash)单引号、双引号、不加引号和反引号用法和区别详解
简要总结 不加引号:不会将含有空格的字符串视为一个整体输出, 如果内容中有变量等,会先把变量解析出结果,然后在输出最终内容来,如果字符串中带有空格等特殊字符,则不能完整的输出,需要改加双引号ÿ…...

本人使用的idea插件
文章目录🚏 本人使用的idea插件🚬 pojo to Json🚬 GsonFormatPlus🚬 EasyYapi🚬 Chinese (Simplified) Language Pack / 中文语言包🚬 MyBatis Log Free🚬 MyBatisPlusX🚬 Statistic…...

站在行业C位,谷医堂打开健康管理服务新思路
对于农村及贫困地区老百姓来说,由于交通因素和家庭经济条件制约,看病难致身体调理情况一直不太乐观,这也导致心理压力很大。然而,随着近年中医药产业崛起与快速发展,这种局面很快就会得到改观,以湖南谷医堂…...
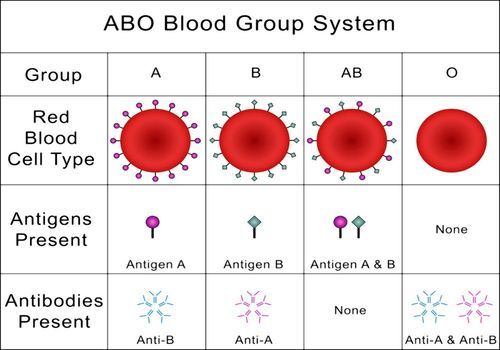
ABO溶血症概率
[简介]ABO溶血是由于母亲和胎儿ABO血型不合引起的新生儿溶血,概率不是很大,一般出现在准妈妈是O血,准爸爸是非O血,这次容易发生血型不合,但新生儿ABO溶血概率不高,大多数症状相对较轻。ABO溶血的概率是什么…...

【算法数据结构体系篇class03】:数组、链表、栈、队列、递归时间复杂度、哈希表、有序表问题
一、反转链表package class03;import java.util.ArrayList; import java.util.List;/*** 链表反转*/ public class ReverseLinkedList {public static class Node {public int value;public Node next;public Node(int data) {value data;}}public static class DoubleNode {p…...

【SITS2026权威前瞻】:AI研发自动化测试的5大范式跃迁与2024落地避坑指南
更多请点击: https://intelliparadigm.com 第一章:AI研发自动化测试:SITS2026专题 随着大模型驱动的研发范式演进,AI系统本身的可测试性面临全新挑战——模型行为非确定、输入空间高维、验证标准模糊。SITS2026(Softw…...

PCI、PCIe与InfiniBand接口技术对比与应用解析
1. 计算机接口技术演进背景在服务器和PC硬件架构中,I/O接口技术始终是决定系统性能的关键因素之一。作为从业15年的系统架构师,我见证了从传统PCI总线到现代高速互连技术的完整演进历程。这种演进并非简单的替代关系,而是针对不同应用场景的技…...

GoAmzAI:开源本地化部署,AI赋能亚马逊卖家高效生成运营文案
1. 项目概述:一个面向亚马逊卖家的AI助手最近在和一些做跨境电商的朋友聊天,发现他们每天花在亚马逊店铺运营上的时间,很大一部分都耗在了重复性的文案工作上。从产品标题、五点描述、A页面,到广告文案、客户邮件回复,…...

大量全新惠普AM4准系统迷你主机涌入咸鱼,支持桌面端5700G处理器,双M2+SATA三盘位,还可选配GTX 1660 Ti 6GB显卡!
众所周知英特尔12代处理器以及AMD锐龙 5000系处理器都是如今极为坚挺的一代平台,两者注定是未来很长一段时间的传家宝平台。而且你敢信,如今依旧还是主流,横跨多年还没有过时和淘汰的迹象,令无数垃圾佬们蠢蠢欲动。其实咸鱼上早就…...

Oracle诉Google案:API版权与合理使用对软件互操作性的深远影响
1. 一场定义软件未来的世纪诉讼:Oracle诉Google案深度解析2012年5月,科技界和法律界都将目光聚焦在了美国加州北区联邦地方法院。一场被业界称为“世纪诉讼”的官司——Oracle America Inc. 诉 Google Inc. 案——进入了关键的第一阶段庭审。表面上看&am…...

Void Memory:为AI智能体构建持久记忆的轻量级解决方案
1. 项目概述:为AI智能体构建持久记忆的“记忆锚”如果你和我一样,长期与Claude Code、Cursor这类AI编程助手并肩作战,一定对那个令人沮丧的瞬间不陌生:你花了半小时向它详细解释了一个复杂项目的架构、你的编码偏好、刚刚踩过的坑…...

OpenClaw工作空间管理工具:自动化文件治理与优化实践
1. 项目概述:一个专为OpenClaw设计的本地化工作空间管理工具如果你和我一样,深度使用过OpenClaw这套开源AI智能体框架,那你一定对那几个核心的Markdown配置文件又爱又恨。AGENTS.md里定义着你的数字员工,SOUL.md是它们的“灵魂”与…...

AI伦理编程实战:从公平性算法到可解释性模型的工程实践
1. 项目概述:当代码开始思考,我们该教它什么? “AI伦理编程”这个词,听起来像是一个技术乌托邦,一个我们只要遵循几条规则就能让机器变得善良的简单任务。但当你真正坐下来,试图将“公平”、“透明”、“无…...

MediaCreationTool.bat:5分钟解决Windows安装的所有痛点
MediaCreationTool.bat:5分钟解决Windows安装的所有痛点 【免费下载链接】MediaCreationTool.bat Universal MCT wrapper script for all Windows 10/11 versions from 1507 to 21H2! 项目地址: https://gitcode.com/gh_mirrors/me/MediaCreationTool.bat 还…...

AI不是功能叠加,而是范式重铸:揭秘奇点大会首次披露的“AI原生产品熵减评估矩阵”及4类高危反模式
更多请点击: https://intelliparadigm.com 第一章:AI不是功能叠加,而是范式重铸:从工具思维到原生心智的跃迁 当开发者仍在用“给CMS加个AI摘要按钮”的方式理解大模型时,真正的变革早已发生在架构底层——AI正从可插…...