PostgreSQL 源码部署
文章目录
- 说明
- 1. 准备工作
- 1.1 源码包下载
- 1.2 解压安装目录
- 1.3 安装依赖包
- 1.4 添加用户
- 1.5 创建数据目录
- 2. 编译安装
- 2.1 源码编译
- 2.2 配置环境变量
- 2.3 初始化数据库
- 2.4 启动数据库
- 2.5 连接数据库
- 3. 参数调整
- 3.1 配置 pg_hba
- 3.2 监听相关
- 2.4 日志文件
- 2.5 内存参数
说明
本篇文章介绍 PostgreSQL 单机源码编译部署的详细步骤。
1. 准备工作
1.1 源码包下载
进入 PostgreSQL 官网下载页面 选择 Source 栏目:
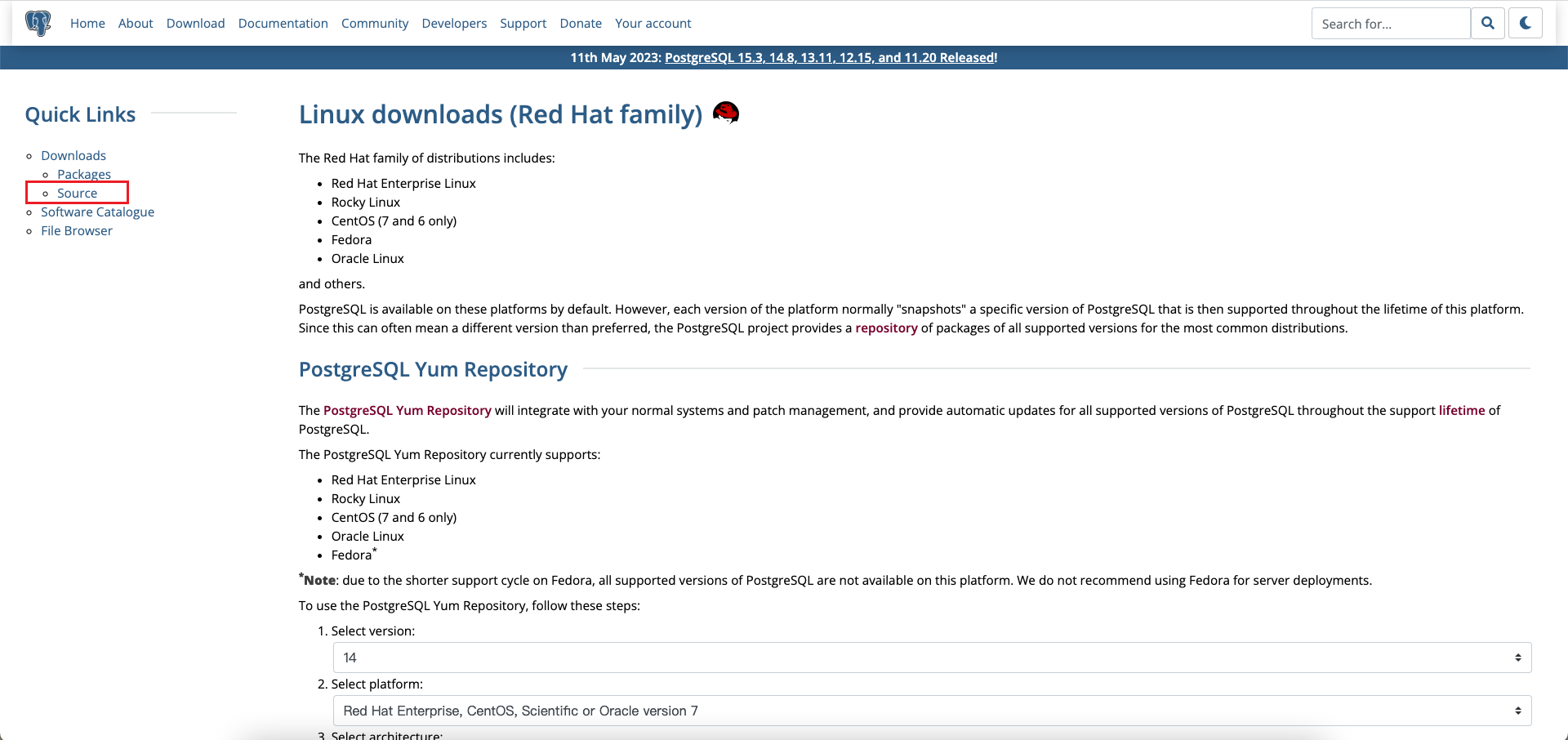
接着就进入源码版本目录,选择需要安装的版本下载即可。
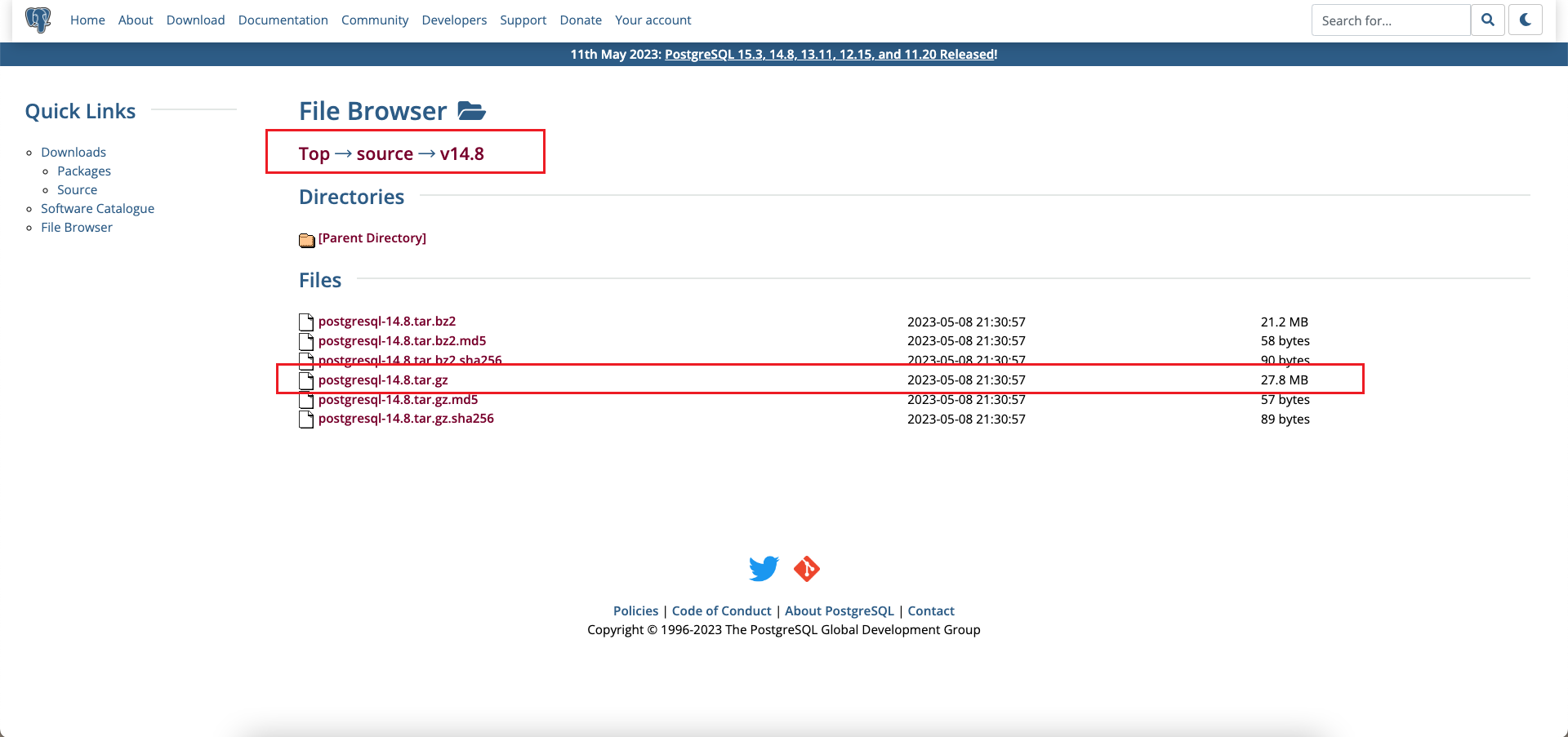
1.2 解压安装目录
源码包下载完成后,上传到服务器,进行解压缩:
tar -xf postgresql-14.8.tar.gz
1.3 安装依赖包
yum install gcc gcc-c++ readline-devel readline readline-dev zlib-devel
1.4 添加用户
groupadd postgres
useradd -g postgres postgres
1.5 创建数据目录
为 PostgreSQL 创建存储数据的目录:
mkdir -p /data/pgsql/{data,logs}
chown -R postgres:postgres /data/pgsql/
2. 编译安装
2.1 源码编译
cd 到源码目录下:
cd /opt/postgresql-14.8
执行 configure:
./configure --prefix=/usr/local/pgsql
| 参数名 | 含义 |
|---|---|
| prefix | 软件目录也就是安装目录 |
| with-perl | 编译时添加该参数才能够使用 perl 语法的 PL/Perl 过程语言写自定义函数,需要提前安装好相关的 perl 开发包:libperl-dev |
| with-python | 编译时添加该参数才能够使用 python 语法的 PL/Perl 过程语言写自定义函数,需要提前安装好相关的 python 开发包:python-dev |
| with-blocksize & with-wal-blocksize | 默认情况下 PG 数据库的数据页大小为 8KB,若数据库用来做数仓业务,可在编译时将数据页进行调整,以提高磁盘 IO |
编译安装:
make && make install
编译完成后,会在 prefix 参数指定的目录下生成 PostgreSQL 程序文件。
2.2 配置环境变量
根据自己实际环境,修改安装目录和数据目录:
vi /etc/profile
export PGHOME=/usr/local/pgsql
export PGDATA=/data/pgsql/data
export PATH=$PGHOME/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/pgsql/lib
source /etc/profile
2.3 初始化数据库
切换到 postgres 用户:
su postgres
执行数据库初始化 -D 选项后面是数据目录:
initdb -D /data/pgsql/data/
The files belonging to this database system will be owned by user "postgres".
This user must also own the server process.The database cluster will be initialized with locale "zh_CN.UTF-8".
The default database encoding has accordingly been set to "UTF8".
initdb: could not find suitable text search configuration for locale "zh_CN.UTF-8"
The default text search configuration will be set to "simple".Data page checksums are disabled.fixing permissions on existing directory /data/pgsql/data ... ok
creating subdirectories ... ok
selecting dynamic shared memory implementation ... posix
selecting default max_connections ... 100
selecting default shared_buffers ... 128MB
selecting default time zone ... Asia/Shanghai
creating configuration files ... ok
running bootstrap script ... ok
performing post-bootstrap initialization ... ok
syncing data to disk ... okinitdb: warning: enabling "trust" authentication for local connections
You can change this by editing pg_hba.conf or using the option -A, or
--auth-local and --auth-host, the next time you run initdb.Success. You can now start the database server using:pg_ctl -D /data/pgsql/data/ -l logfile start
2.4 启动数据库
进入 logs 目录下,创建启动日志文件,将启动时的日志输出到该文件:
touch /data/pgsql/logs/start.log
启动 PostgreSQL:
pg_ctl -D /data/pgsql/data/ -l /data/pgsql/logs/start.log start
关闭数据库可以使用下方命令:
# 关闭数据库
pg_ctl -D /data/pgsql/data/ -l /data/pgsql/logs/start.log stop
# 重启数据库
pg_ctl -D /data/pgsql/data/ -l /data/pgsql/logs/start.log restart
2.5 连接数据库
启动成功使用 psql 即可进入数据库:
>>>>$ psql
psql (14.8)
Type "help" for help.postgres=# select version();version
---------------------------------------------------------------------------------------------------------PostgreSQL 14.8 on x86_64-pc-linux-gnu, compiled by gcc (GCC) 4.8.5 20150623 (Red Hat 4.8.5-44), 64-bit
3. 参数调整
3.1 配置 pg_hba
PostgreSQL 数据目录中,会自动生成 pg_hba.conf 文件,该文件是一个黑名单访问控制文件,可以控制允许哪些 IP 地址的机器访问数据库。默认,不允许远程访问数据,所以安装完成后需要配置下。
# TYPE DATABASE USER ADDRESS METHOD# "local" is for Unix domain socket connections only
# Type 表示访问方式,local 表示本地套接字访问,DATABASE、USER 分别表示数据库和用户
# 参数 all 表示所有的数据库或用户,ADDRESS 表示一个地址或者网段,METHOD 表示验证的方式
# 默认的 trust 表示完全信任,password 表示发送明文密码,不建议使用,建议使用 md5 模式
local all all trust
# IPv4 local connections:
host all all 127.0.0.1/32 trust
# IPv6 local connections:
host all all ::1/128 trust
# Allow replication connections from localhost, by a user with the
# replication privilege.
local replication all trust
host replication all 127.0.0.1/32 trust
host replication all ::1/128 trust
可以在 pg_hba 文件中加入下面一行,表示允许任何用户远程连接数据库,连接时需要提供密码:
host all all 0/0 md5
详细可参考文档:pg_hba 文件说明
3.2 监听相关
在数据目录中的 postgresql.cnf 中,可以找到如下内容:
listen_addresses = 'localhoset' # what IP address(es) to listen on;# comma-separated list of addresses;# defaults to 'localhost'; use '*' for all# (change requires restart)
其中,参数 listen_addresses 表示监听的 IP 地址,默认是在 localhost/127.0.0.1 处监听,这样会导致远程主机无法访问数据库,如果需要远程访问,需要将其设置为实际网络地址,设置为 * 表示监听所有地址,该参数修改重启生效。
PS:配置完 3.1 和 3.2 两个步骤,PostgreSQL 就可以支持远程连接。
下表是其它常见监听相关的参数,按需设置:
| 参数 | 含义 |
|---|---|
| port | 服务器监听TCP端口,默认 5432 |
| max_connections | Server 端允许最大连接数,默认 100 |
| superuser_reserved_connections | Server 端为超级账号保留的连接数,默认3 |
| unix_socket_directory | Server 监听客户端 Unix 嵌套字目录,默认 /tmp |
2.4 日志文件
下面是 PostgreSQL 日志相关的参数,一般都是需要配置:
| 参数 | 含义 |
|---|---|
| logging_collector | 是否打开日志 |
| log_rotation_age | 超过多少天生产一个新的日志文件 |
| log_rotation_size | 超过多少大小生成一个新的日志文件 |
| log_directory | 日志目录,可以是绝对路径或相对 PGDATA 的相对路径 |
| log_destination | 日志记录类型,默认是 stderr,只记录错误输出 |
| log_filename | 日志文件名,默认是 postgresql-%Y-%m-%d_%H%M%S.log |
| log_truncate_on_rotation | 当日志名已存在时,是否覆盖原文件 |
以下是几个常用的配置模版,每天生成一个新的日志文件:
logging_collector = on
log_directory = '/data/pgsql/logs'
log_filename = 'postgresql-%Y-%m-%d_%H%M%S.log'
log_truncate_on_rotation = off
log_rotation_age = 1d
log_rotation_size = 0
每当一个日志写满时(如 100MB)切换一个日志:
logging_collector = on
log_directory = '/data/pgsql/logs'
log_filename = 'postgresql-%Y-%m-%d_%H%M%S.log'
log_truncate_on_rotation = off
log_rotation_age = 0
log_rotation_size = 100MB
只保留最近 7 天的日志,进行循环覆盖:
logging_collector = on
log_directory = '/data/pgsql/logs'
log_filename = 'error_log.log'
log_truncate_on_rotation = on
log_rotation_age = 7d
log_rotation_size = 0
2.5 内存参数
熟悉 MySQL 的同学都知道它有一个参数 innodb_buffer_pool 限制 innodb 引擎缓冲池的大小,buffer pool 越大可以缓存的页就越多,可以减少很多磁盘 IO 消耗,提升数据库的性能。shared_buffer 在 PostgreSQL 中与 MySQL 的 buffer pool 是异曲同工。
| 参数 | 含义 |
|---|---|
| shared_buffer | 共享内存缓存区大小,默认 128MB |
| temp_buffers | 每个会话使用的临时缓存区大小,默认 8MB |
| work_mem | 内存临时表排序操作或者 hash join 需要使用到的内存缓存大小,默认 4MB |
| maintenance_work_mem | 对于维护性操作(vacuum、create index)最大使用内存,默认 64M,最小 1M |
| max_stack_depth | Server 端执行堆栈最大安全深度,默认 2M,若发现无法执行复杂函数时可适当调整该参数 |
相关文章:
PostgreSQL 源码部署
文章目录 说明1. 准备工作1.1 源码包下载1.2 解压安装目录1.3 安装依赖包1.4 添加用户1.5 创建数据目录 2. 编译安装2.1 源码编译2.2 配置环境变量2.3 初始化数据库2.4 启动数据库2.5 连接数据库 3. 参数调整3.1 配置 pg_hba3.2 监听相关2.4 日志文件2.5 内存参数 说明 本篇文…...

医疗IT系统安科瑞隔离电源装置在医院的应用
【摘要】介绍该三级综合医院采用安科瑞隔离电源系统5件套,使用落地式配电柜安装方式,从而实现将TN系统转化为IT系统,以及系统绝缘情况监测。 【关键词】医用隔离电源系统;IT系统;绝缘情况监测;三级综合医院…...

高压放大器在3D打印中的应用
随着3D打印技术的快速发展,高压放大器在3D打印中的应用越来越受到人们的关注。高压放大器在3D打印中扮演着非常重要的角色,可以提高3D打印的效率和精度,从而实现更高的打印质量。本文将详细介绍高压放大器在3D打印中的应用及其原理。 高压放…...

chatgpt赋能python:Python中的三角函数介绍
Python中的三角函数介绍 Python作为一种高级编程语言,可以处理基础算术运算、三角函数等高等数学的操作。其中,三角函数是常用的数学函数之一,Pyhon中的三角函数包括正弦函数、余弦函数、正切函数等。 正弦函数 正弦函数在三角学中是最基本…...
异常检测论文1
本文仅作为个人阅读文献,做笔记记录。 <> \usepackage[dvipsnames]{xcolor} 一、摘要部分: 我们发现,现有的数据集偏向于局部结构异常,如划痕、凹痕或污染。特别是,它们缺乏违反逻辑约束形式的异常࿰…...

linux搭建hadoop环境
1、安装JDK (1)下载安装JDK:确保计算机联网之后命令行输入下面命令安装JDK sudo apt-get install sun-java8-jdk (2)配置计算机Java环境:打开/etc/profile,在文件最后输入下面…...
02 Maven创建及使用
maven作用 主要用作基于java平台的项目 maven能提供一种项目配置 maven能自动从maven的中央仓库帮我们自动下载并管路项目依赖的jar包 提供了标准的目录结构 中央仓库两种类型:共有的中央仓库:私有中央仓库 使用mvn -v查看是否安装成功 修改本地仓库的的位置 在setting…...

如何在 Rocky Linux 上检查磁盘空间?
在 Rocky Linux 上检查磁盘空间是系统管理和维护的重要任务之一。磁盘空间的监控和管理可以帮助我们及时发现和解决存储空间不足的问题,以确保系统的正常运行。本文将详细介绍在 Rocky Linux 上检查磁盘空间的方法。 方法 1:使用 df 命令 df 命令是 Li…...
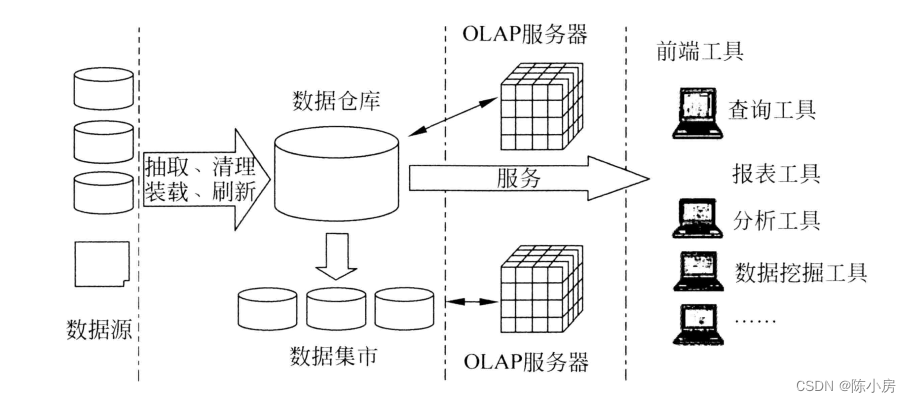
【软考系统规划与管理师笔记】第2篇 信息技术知识1
目录 1 软件工程 1.1 软件需求分析与定义 1.2 软件设计、测试与维护 1.3 软件质量保证及质量评价 1.4 软件配置管理 1.5 软件过程管理 1.6 软件复用 2 面向对象系统分析与设计 2.1 面向对象设计的基本概念 2.2统一建模语言与可视化建模 3. 应用集成技术 3.1 数据库与…...

【无标题】ELISA-3(加装跟踪装置)—让群体协作更智能!
群体智能是近年来发展迅速的一个人工智能学科领域,通过对蚂蚁、蜜蜂等为代表的社会性昆虫群体行为的研究,实现分布式等智能行为。作为新一代人工智能的重要方向,群体智能通常用于无人机、机器人集群的协同作业。目前,群体智能在基…...
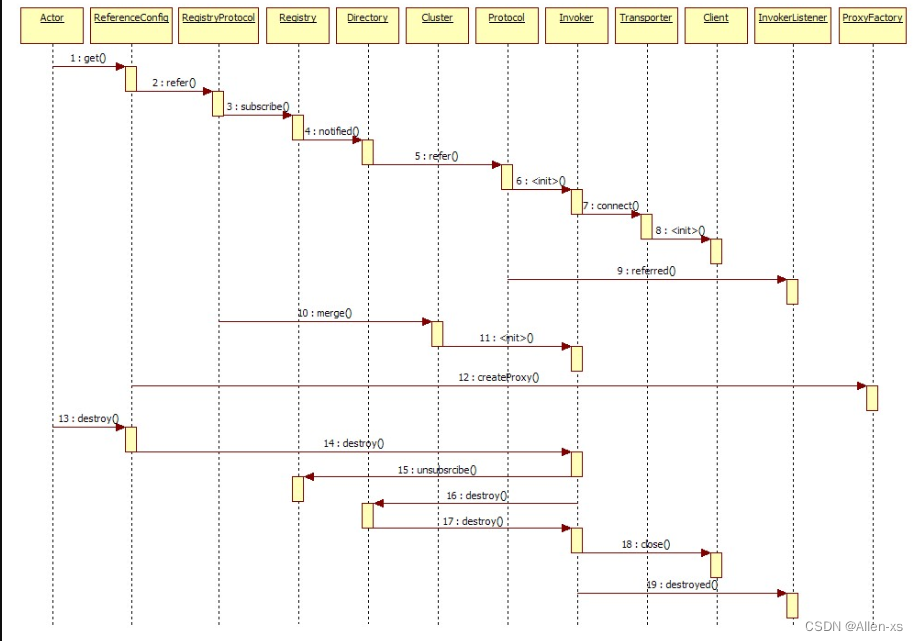
Dubbo源码解析一服务暴露与发现
Dubbo 服务暴露与发现 1. Spring中自定义Schema1.1 案例使用1.2 dubbo中的相关对象 2. 服务暴露机制2.1 术语解释2.2 流程机制2.3 源码分析2.3.1 导出入口2.3.2 导出服务到本地2.3.3 导出服务到远程(重点)2.3.4 开启Netty服务2.3.5 服务注册2.3.6 总结 3. 服务发现3.1 服务发现…...
有哪些工具软件一旦用了就离不开?
💖前言 目前,随着科技的快速发展,电脑已经进入了许许多多人的生活 ,在平日的学习、工作和生活里,我们会用的各种各样的强大软件。市面上除了某些大公司开发在强大软件,还有各路大神开发具有某些功能的强大…...

ObjectARX如何判断点和多段线的关系
目录 1 基本思路2 相关知识点2.1 ECS坐标系概述2.2 其他点坐标转换接口2.3 如何获取多段线的顶点ECS坐标 3 实现例程3.1 接口实现3.2 测试代码 4 实现效果 在CAD的二次开发中,点和多段线的关系是一个非常重要且常见的问题,本文实现例程以张帆所著《Objec…...

四、DRF序列化器create方法与update方法
上一章: 二、Django REST Framework (DRF)序列化&反序列化&数据校验_做测试的喵酱的博客-CSDN博客 下一章: 五、DRF 模型序列化器ModelSerializer_做测试的喵酱的博客-CSDN博客 一、背景 1、创建请求,post,用户输入…...

洛谷P8792 最大公约数
[蓝桥杯 2022 国 A] 最大公约数 题目描述 给定一个数组,每次操作可以选择数组中任意两个相邻的元素 x , y x, y x,y 并将其中的一个元素替换为 gcd ( x , y ) \gcd(x, y) gcd(x,y),其中 gcd ( x , y ) \gcd(x, y) gcd(x,y) 表示 x x x 和 y…...
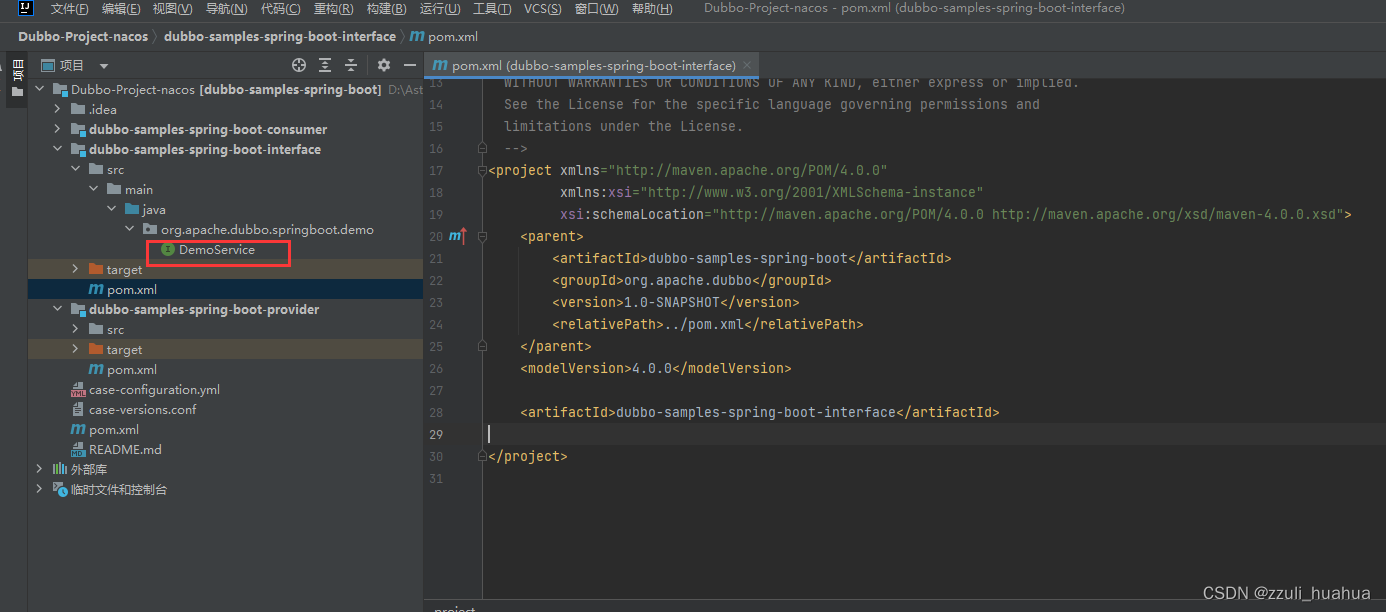
【SpringBoot集成Nacos+Dubbo】企业级项目集成微服务组件,实现RPC远程调用
文章目录 一、需求环境/版本 二、须知2.1、什么是RPC?2.2、什么是Dubbo?2.3、什么是Nacos? 三、普通的SpringBoot项目集成微服务组件方案(笔者给出两种)方案一(推荐)1、导入maven依赖࿰…...

MySQL主从同步(开GTID)
目录 一、搭建简单的主从同步 二、mysql删除主从(若没有配置过可以不用进行这一步) 1、停止slave服务器的主从同步 2、重置master服务 三、开启GTID 1、Master配置 2、Slave配置 一、搭建简单的主从同步 GTID原理:http://t.csdn.cn/g…...

打造精细化调研,这些产品榜上有名,你用了吗?
调查问卷是一种流行的数据收集工具,研究人员、营销人员和企业使用它来征求目标受众的反馈意见。调查问卷工具使创建、分发和分析调查问卷的过程变得更加简单和高效。想要做好一份调查问卷,选择一款好用的工具是少不了的。不过,在众多的问卷工…...
[golang gin框架] 37.ElasticSearch 全文搜索引擎的使用
一.全文搜索引擎 ElasticSearch 的介绍,以及安装配置前的准备工作 介绍 ElasticSearch 是一个基于 Lucene 的 搜索服务器,它提供了一个 分布式多用户能力的 全文搜索引擎,基于 RESTful web 接口,Elasticsearch 是用 Java 开发的,并作为 Apach…...

赋的几个发展阶段
赋,起源于战国,形成于汉代,是由楚辞衍化出来的,也继承了《诗经》讽刺的传统。关于诗和赋的区别,晋代文学家陆机在《文赋》里曾说: 诗缘情而绮靡,赋体物而浏亮。 也就是说,诗是用来抒发主观感情…...
:支持Anthropic API兼容、流式响应、模型热切换与RBAC权限隔离)
Claude本地化部署终极方案(企业级容器化全栈手册):支持Anthropic API兼容、流式响应、模型热切换与RBAC权限隔离
更多请点击: https://codechina.net 第一章:Claude本地化部署的架构全景与企业级价值定位 Claude本地化部署并非简单地将模型权重下载后运行,而是一套融合推理引擎优化、安全沙箱隔离、API网关治理与可观测性集成的端到端架构体系。其核心目…...
)
保姆级避坑指南:在Ubuntu 22.04上搞定ROS2 Humble、PX4与Gazebo的联合仿真(附Empy版本降级)
保姆级避坑指南:Ubuntu 22.04下ROS2 Humble与PX4联合仿真的21个关键陷阱当你在Ubuntu 22.04上第一次尝试搭建ROS2 Humble、PX4与Gazebo的联合仿真环境时,可能会遇到比预期更多的挑战。这不是一个简单的"复制粘贴命令就能完成"的任务——版本冲…...

别急着扔!12年老ThinkPad X230升级SSD和内存后,Win10流畅得像新电脑
12年老ThinkPad X230重生指南:极简升级打造流畅办公利器每次打开抽屉看到那台积灰的ThinkPad X230,总有种说不出的情感。这款2012年问世的经典商务本,曾陪伴无数人度过加班到凌晨的夜晚。如今性能确实有些力不从心,但直接丢弃又觉…...

基于USB ACA模式实现安卓手机边玩边充的游戏手柄设计
1. 项目缘起:当手机性能过剩,却败给了触摸屏几年前,我清理手机游戏时,发现一个挺无奈的现象:性能足以媲美掌机的智能手机里,只剩下一些慢节奏的平台解谜或者数独。那些曾经让我在掌机上废寝忘食的赛车、动作…...

树莓派Zero离线语音交互实战:TTS与STT引擎部署与优化
1. 项目概述:为什么选择树莓派 Zero 来实现语音功能?如果你玩过 Arduino、ESP32 这类微控制器,也接触过树莓派 4B 这样的单板电脑,那你大概能理解那种“选择困难症”:微控制器实时性强、功耗低,但算力有限&…...

观察Taotoken在多模型聚合调用下的路由与失败重试效果
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察Taotoken在多模型聚合调用下的路由与失败重试效果 在构建依赖大模型能力的应用时,服务的稳定性是开发者关注的核心…...

WarcraftHelper:让经典魔兽争霸3完美适配现代电脑的终极解决方案
WarcraftHelper:让经典魔兽争霸3完美适配现代电脑的终极解决方案 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为魔兽争霸3在现代操…...

每日一书㉗ | 刻意练习:为什么有些人努力一辈子还是平庸?
“本文来自「乐想屋」公众号,系列更新[每日一书],每次5分钟,帮你把书读薄,把知识用活”先问你一个问题。你身边有没有这样的人:入行时间比你短,但能力已经甩你好几条街。他们好像没有特别刻苦,但…...

无声输入革命:如何用Chaplin在5分钟内构建本地唇语识别系统
无声输入革命:如何用Chaplin在5分钟内构建本地唇语识别系统 【免费下载链接】chaplin A real-time silent speech recognition tool. 项目地址: https://gitcode.com/gh_mirrors/chapl/chaplin 在嘈杂的办公室、安静的图书馆,或是需要绝对隐私的医…...

HiveWE地图编辑器:告别卡顿,开启魔兽争霸III地图制作新纪元
HiveWE地图编辑器:告别卡顿,开启魔兽争霸III地图制作新纪元 【免费下载链接】HiveWE A Warcraft III world editor. 项目地址: https://gitcode.com/gh_mirrors/hi/HiveWE 还在为魔兽争霸III原版编辑器的缓慢加载和频繁卡顿而烦恼吗?你…...