【python资料】pandas的条件查询
一、说明
在使用Pandas的DataFrame进行数据挖掘的时候,需要形形色色的条件查询,但是这些查询的基本语法是啥,查询的灵活性如何,本文将对他们进行详细列出,便于以后查阅。
二、Pandas条件查询方法
2.1 简单条件查询
1、使用“ [] ”符号进行简单条件查询
- 基本语法:
![]()
- 例如:
import pandas as pddf = pd.read_csv('data.csv')
df[df['col1'] > 10] # 查询col1列中大于10的行表达式特点:是将由>,==,<, 等比较运算符构成表达式。
2、用“&”连起来的多条件查询
- 基本语法
![]()
使用多个条件进行复合条件查询,是"[ ]"表达式用“&”连起来,
- 例如:
df[(df['col1'] > 5) & (df['col2'] < 10)] # 查询col1列中大于5且col2列中小于10的行
3、str.contains()字符串条件查询
- 语法

使用str.contains()方法进行字符串条件查询,是查出字符串的子串有“apple”的行。
- 例如:
df[df['col1'].str.contains('apple')] # 查询col1列中包含'apple'字符串的行
4、多个字符串内容用isin条件查询
- 语法
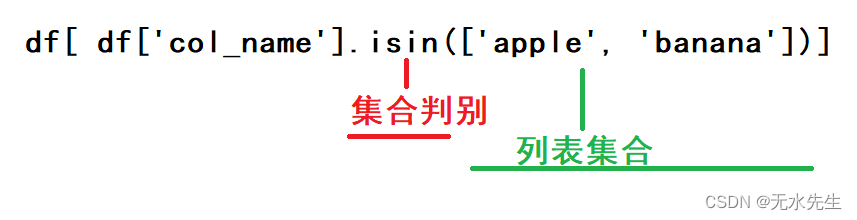
使用isin()方法进行包含查询,
- 例如:
df[df['col1'].isin(['apple', 'banana'])] # 查询col1列中包含'apple'或'banana'的行
5、between条件查询
使用between()方法进行范围查询,例如:
df[df['col1'].between(5, 10)] # 查询col1列中在5到10之间的行
6、查询空值
使用isna()或isnull()方法进行查询空值,例如:
df[df['col1'].isna()] # 查询col1列中为空值的行
2.2、高级查询
2.2.1 内嵌语句查询
- 例1: 比如我想找到所有姓张的人的信息:
df[[x.startswith('张') for x in df['姓名']]] 月份 姓名 性别 应发工资 实发工资 职位
0 1 张三 男 2000 1500 主犯
1 2 张三 男 2000 1000 主犯
2 3 张三 女 2000 15000 主犯
3 4 张三 女 2000 1500 主犯
4 5 张三 女 2000 1500 主犯
这里stratswith方法是Python自带的字符串方法,点这里查看详细说明。
- 还有一种方法:
criterion = df['姓名'].map(lambda x: x.startswith('张'))df[criterion]
月份 姓名 性别 应发工资 实发工资 职位
0 1 张三 男 2000 1500 主犯
1 2 张三 男 2000 1000 主犯
2 3 张三 女 2000 15000 主犯
3 4 张三 女 2000 1500 主犯
4 5 张三 女 2000 1500 主犯
- 速度比较:
# 第一种方法
%timeit df[[x.startswith('张') for x in df['姓名']]]
203 µs ± 8.92 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
# 第二种方法
%timeit criterion = df['姓名'].map(lambda x: x.startswith('张'))
93.2 µs ± 6.21 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each)
%timeit df[criterion]
201 µs ± 2.44 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
可以看到,第二种方法实际上并没有明显快多少。并且如果加上添加检索规则的时间反而更慢。
2.2.2 可用于修改内容的where方法
- 先看用法:
df.where(df['性别'] == '男')
月份 姓名 性别 应发工资 实发工资 职位
0 1.0 张三 男 2000.0 1500.0 主犯
1 2.0 张三 男 2000.0 1000.0 主犯
2 NaN NaN NaN NaN NaN NaN
3 NaN NaN NaN NaN NaN NaN
4 NaN NaN NaN NaN NaN NaN
5 2.0 李四 男 1800.0 1300.0 从犯
6 3.0 李四 男 1800.0 1300.0 从犯
7 4.0 李四 男 1800.0 1300.0 从犯
8 5.0 李四 男 1800.0 1300.0 从犯
9 NaN NaN NaN NaN NaN NaN
10 NaN NaN NaN NaN NaN NaN
11 NaN NaN NaN NaN NaN NaN
12 NaN NaN NaN NaN NaN NaN
这里where的使用和直接访问标签的方式就有所不同了,这是将所有满足条件的项保持原状,而其它项全部设为NaN。如果要替换数据的话,需要比较复杂的表达式,这里只看一个简单的例子:
dates = pd.date_range('1/1/2000', periods=8)
df = pd.DataFrame(np.random.randn(8, 4),index=dates, columns=['A', 'B', 'C', 'D'])
df.where(df < 0, -df)
A B C D
2000-01-01 -2.843891 -0.140803 -1.816075 -0.248443
2000-01-02 -0.195239 -1.014760 -0.621017 -0.308201
2000-01-03 -0.773316 -0.411646 -1.091336 -0.486160
2000-01-04 -1.753884 -0.596536 -0.273482 -0.685287
2000-01-05 -1.125159 -0.549449 -0.275434 -0.861960
2000-01-06 -1.059645 -1.600819 -0.085352 -0.406073
2000-01-07 -1.692449 -1.767384 -0.266578 -0.593165
2000-01-08 -0.163517 -1.645777 -1.509307 -0.637490
这里插一句:实际上numpy也有where方法,用法类似,可参考:Python Numpy中返回下标操作函数-节约时间的利器
2.2.3 快速的查询方法query
df.query('姓名>性别')
月份 姓名 性别 应发工资 实发工资 职位
2 3 张三 女 2000 15000 主犯
3 4 张三 女 2000 1500 主犯
4 5 张三 女 2000 1500 主犯
9 1 王五 女 1800 1300 龙套
10 2 王五 女 1800 1300 龙套
11 3 王五 女 1800 1300 龙套
12 4 王五 女 1800 1300 龙套
这里,字符串的比较可以查看Python的字符串比较。当然,这里可以看到,query方法主要还是用于列的比较。
2.3 pandas中的shift()函数
- 语法:
shift(periods, freq, axis)- 参数注释:
| 参数 | 参数意义 | |
|---|---|---|
| period | 表示移动的幅度,可以是正数,也可以是负数,默认值是1,1就表示移动一次,注意这里移动的都是数据,而索引是不移动的,移动之后没有对应值的,就赋值为NaN。 | |
| freq | DateOffset, timedelta, or time rule string,可选参数,默认值为None,只适用于时间序列,如果这个参数存在,那么会按照参数值移动时间索引,而数据值没有发生变化。 | |
| axis | 0为垂,1为水平 |
- 实例代码
# 表格数据生成
import pandas as pd
import numpy as np
import datetime
df = pd.DataFrame(np.arange(16).reshape(4,4),columns=['A','B','C','D'],index=pd.date_range('20130101', periods=4))>>>dfA B C D
2013-01-01 0 1 2 3
2013-01-02 4 5 6 7
2013-01-03 8 9 10 11
2013-01-04 12 13 14 15
#默认是axis = 0轴的设定,当period为正时向下移动
# 表示表格从原始数据第二行开始有效
df.shift(2)
A B C D
2013-01-01 NaN NaN NaN NaN
2013-01-02 NaN NaN NaN NaN
2013-01-03 0.0 1.0 2.0 3.0
2013-01-04 4.0 5.0 6.0 7.0
#默认是axis = 0轴的设定,当period为负时向下移动
df.shift(-2)
A B C D
2013-01-01 8.0 9.0 10.0 11.0
2013-01-02 12.0 13.0 14.0 15.0
2013-01-03 NaN NaN NaN NaN
2013-01-04 NaN NaN NaN NaN
#axis = 1,当period为正向右,为负向左移动
df.shift(2,axis=1)
A B C D
2013-01-01 NaN NaN 0.0 1.0
2013-01-02 NaN NaN 4.0 5.0
2013-01-03 NaN NaN 8.0 9.0
2013-01-04 NaN NaN 12.0 13.0
# frep参数决定索引为日期,正加负减
df.shift(freq=datetime.timedelta(1))
A B C D
2013-01-02 0 1 2 3
2013-01-03 4 5 6 7
2013-01-04 8 9 10 11
2013-01-05 12 13 14 15
df.shift(freq=datetime.timedelta(-1))
A B C D
2012-12-31 0 1 2 3
2013-01-01 4 5 6 7
2013-01-02 8 9 10 11
2013-01-03 12 13 14 15除了上述方法之外,还有:query方法的条件处理、MultiIndex情况下的处理、get方法、lookup方法等等
三、更多内容
(更新中..)
相关文章:
【python资料】pandas的条件查询
一、说明 在使用Pandas的DataFrame进行数据挖掘的时候,需要形形色色的条件查询,但是这些查询的基本语法是啥,查询的灵活性如何,本文将对他们进行详细列出,便于以后查阅。 二、Pandas条件查询方法 2.1 简单条件查询 1、…...
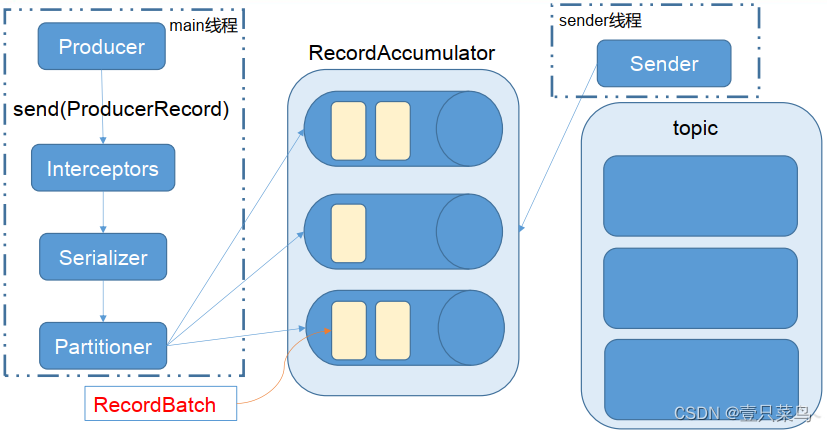
中间件(三)- Kafka(二)
Kafka 6. 高效读写&Zookeeper作用6.1 Kafka的高效读写6.2 Kafka中zookeeper的作用 7. 事务7.1 Producer事务7.2 Consumer事务 8. API生产者流程9. 通过python调用kafka9.1 安装插件9.2 生产者(Producer)与消费者(Consumer)9.3…...
DAY01_MySQL基础数据类型navicat使用DDL\DML\DQL语句练习
目录 1 数据库相关概念1.1 数据库1.2 数据库管理系统1.3 常见的数据库管理系统1.4 SQL 2 MySQL2.1 MySQL安装2.1.1 安装步骤 2.2 MySQL配置2.2.1 添加环境变量2.2.2 MySQL登录2.2.3 退出MySQL 2.3 MySQL数据模型2.4 MySQL目录结构2.5 MySQL一些命令2.5.1 修改默认账户密码2.5.2…...
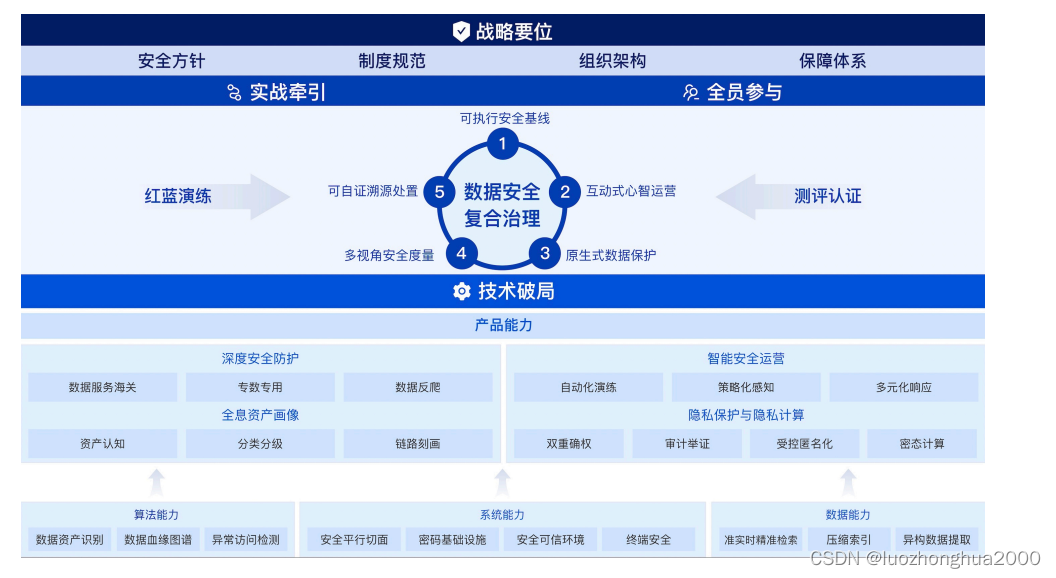
数据安全复合治理框架和模型解读(0)
数据治理,数据安全治理行业在发展,在实践,所以很多东西是实践出来的,哪有什么神仙理论指导,即使有也是一家之说,但为了提高企业投产比,必要的认知是必须的,当前和未来更需要专业和创新。数据安全治理要充分考虑现实数据场景,强化业务安全与数据安全治理,统一来治理,…...

Java程序设计入门教程--逻辑运算符和位运算符
目录 逻辑运算符 位运算符 逻辑运算符 逻辑运算符就是表示逻辑关系的运算符。下表列出了逻辑运算符的基本运算,假设布尔变量A为真,变量B为假。 逻辑运算符表 操作符 描述 例子 && 当且仅当两个操作数都为真,条件才为真。 &…...
接口测试简介以及接口测试用例设计思路
接口测试简介 1.什么是接口 接口就是内部模块对模块,外部系统对其他服务提供的一种可调用或者连接的能力的标准,就好比usb接口,他是系统向外接提供的一种用于物理数据传输的一个接口,当然仅仅是一个接口是不能进行传输的&#x…...

C++ Qt项目实战:构建高效的代码管理器
C Qt项目实战:构建高效的代码管理器 一、项目概述(Introduction)1.1 项目背景(Project Background)1.2 项目目标(Project Goals)1.3 项目应用场景(Project Application Scenarios&am…...

【JavaScript 递归】判断两个对象的键值是否完全一致,支持深层次查询,教你玩转JavaScript脚本语言
博主:東方幻想郷 Or _LJaXi 专栏分类:JavaScript | 脚本语言 JavaScript 递归 - 判断两个对象的键值 🌕 起因🌓 代码流程⭐ 第一步 判断两个对象的长度是否一致⭐ 第二步 循环 obj 进行判断两个对象⭐ 第三步 递归条件判断两个对象…...

卷积、相关、匹配滤波、脉冲压缩以及模糊函数
文章目录 【 1. 卷积 】1.1 连续卷积1.2 离散卷积【 2.相关 】2.1 自相关2.2 互相关【 3.匹配滤波 】3.1 滤波器模型3.2 有色噪声-匹配滤波器3.3 白噪声-匹配滤波器3.3.1 原始-白噪声-匹配滤波器3.3.2 简化-白噪声-匹配滤波器3.4 动目标的匹配滤波【 4.脉冲压缩】4.1 时域脉冲压…...
C# 栈(Stack)
目录 一、概述 二、基本的用法 1.入栈 2.出栈 Pop 方法 Peek 方法 3.判断元素是否存在 4.获取 Stack 的长度 5.遍历 Stack 6.清空容器 7.Stack 泛型类 三、结束 一、概述 栈表示对象的简单后进先出 (LIFO) 非泛型集合。 Stack 和 List 一样是一种储存容器&#x…...

网络流量监控及流量异常检测
当今的企业面临着许多挑战,尤其是在监控其网络基础设施方面,需要确保随着网络规模和复杂性的增长,能够全面了解网络的运行状况和安全性。为了消除对网络性能的任何压力,组织应该采取的一项重要行动是使用随组织一起扩展的工具监控…...

六.热修复
文章目录 前言什么是热修复?如何进行热修复?热修复需要解决的问题 1.Android常用的热修复解决方案2.ClassLoader类加载机制2.1 Android类加载器2.2 双亲委托机制2.3 类查找流程 3.插桩式热修复运行期修复落地3.1 什么是字节码插桩?3.2 ASM3.3…...

2000万的行数在2023年仍然是 MySQL 表的有效软限制吗?
谣言 互联网上有传言说我们应该避免在单个 MySQL 表中有超过 2000 万行。否则,表的性能会下降,当它超过软限制时,你会发现 SQL 查询比平时慢得多。这些判断是在多年前使用HDD硬盘存储时做出的。我想知道在2023年对于基于SSD的MySQL数据库来说…...

jvm问题排查
常用工具 命令查询资源信息 top:显示系统整体资源使用情况 vmstat:监控内存和 CPU iostat:监控 IO 使用 netstat:监控网络使用 查看java进程 jps 查看运行时信息 jinfo pid gc工具 jstat: 查看jvm内存信息 GCViewer — 离线分析G…...

【Redis】浅谈Redis-集群(Cluster)
文章目录 前言1、集群实现1.1 创建cluster目录,并将redis.conf复制到该文件夹1.2 复制redis.conf,并进行配置1.3 启动redis,查看启动状态1.4 合成集群1.5 查看集群1.6 集群读写操作 2、SpringBoot整合redis集群2.1 引入包2.2 设置配置2.3 使用…...
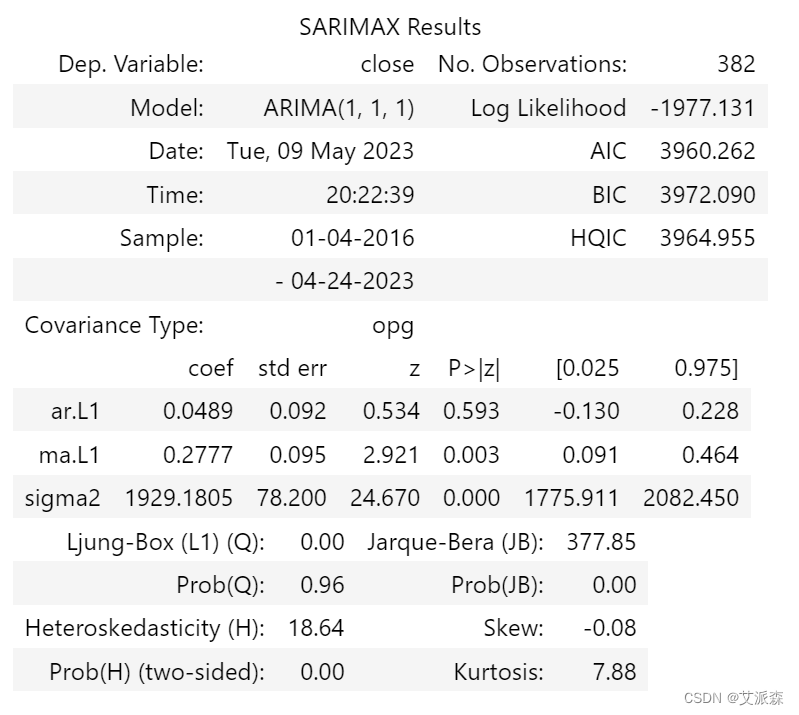
Python3实现基于ARIMA模型来预测茅台股票价格趋势
🤵♂️ 个人主页:艾派森的个人主页 ✍🏻作者简介:Python学习者 🐋 希望大家多多支持,我们一起进步!😄 如果文章对你有帮助的话, 欢迎评论 💬点赞Ǵ…...
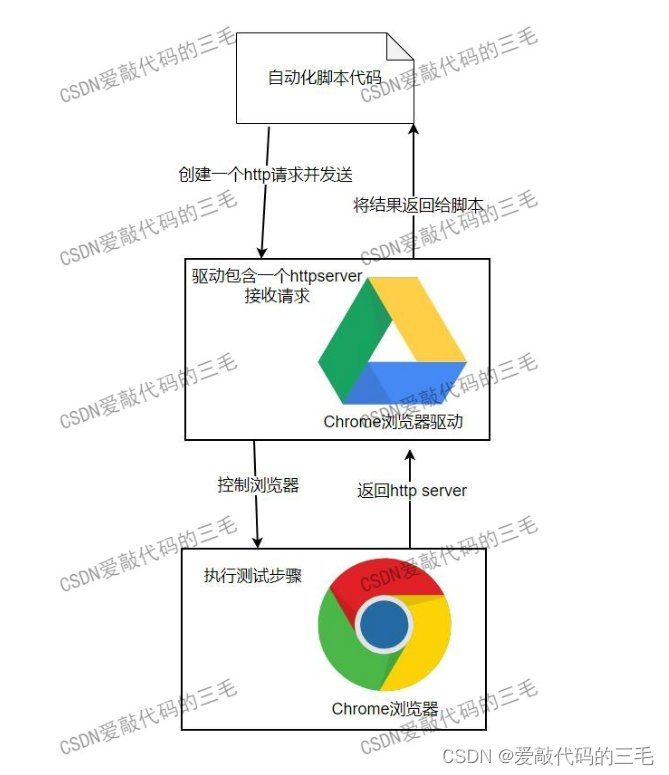
自动化测试selenium环境搭建
自动化测试工具selenium搭建 1. 自动化和selenium基本概念 1) 什么是自动化?为什么要做自动化? 自动化测试能够代替一部分的手工测试,自动化测试能够提高测试的效率。随着项目功能的增加,版本越来越多,版本的回归测试的压力也…...
SaaS系统平台,如何兼顾客户的个性化需求?
在当今数字化的商业环境中,SaaS系统已经成为企业运营的重要组成部分之一。 SaaS系统平台的好处是显而易见的,可以将业务流程数字化,从而帮助企业提高效率并节省成本。 但是,由于每个企业的业务都不尽相同,所以在选择Sa…...

QDir拼接路径解决各种斜杠问题
一般在项目中经常需要组合路径,与其他程序进行相互调用传递消息通信。 经常可能因为多加斜杠、少加斜杠等问题导致很多问题。 为了解决这些问题,我们可以使用QDir来完成路径的拼接,不直接拼接字符串。 QDir的静态方法QDir::cleanPath() 是为了规范化路径名的,在使用QDir组…...
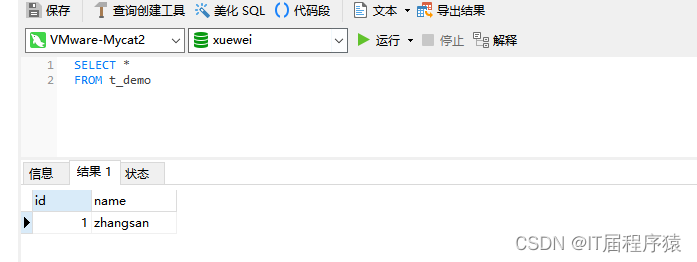
mycat2主从配置实现读写分离
mycat2主从配置实现读写分离 在https://blog.csdn.net/zhangxue_wei/article/details/130840504基础上继续搭建 1.创建mycat数据源,可以在navcat里直接执行 1.1读数据源m1 /* mycat:createDataSource{"dbType":"mysql","idleTimeout&qu…...

AI算法工程师必学的Python库:这10个库,AI开发必备
对于软件测试从业者来说,随着人工智能技术在测试领域的渗透越来越深——从自动化测试用例生成到缺陷智能预测,从测试结果分析到测试环境智能化调度,掌握AI开发的核心工具链已经成为从功能测试向AI测试开发、智能化测试转型的核心竞争力。Pyth…...

为内部知识库问答系统集成多模型后备路由以提升服务韧性
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为内部知识库问答系统集成多模型后备路由以提升服务韧性 对于依赖大模型提供智能问答服务的企业内部知识库而言,服务的…...

Linux 软链接和硬链接详解:ln 命令背后的 inode 原理
Linux 软链接和硬链接详解:ln 命令背后的 inode 原理 1. 前言 Linux 中经常会看到链接文件,例如: /bin -> /usr/bin python -> python3 current -> /opt/app/releases/v2Linux 链接主要有两种: 软链接:symbol…...

RISC-V模拟器终极指南:如何快速掌握处理器可视化调试
RISC-V模拟器终极指南:如何快速掌握处理器可视化调试 【免费下载链接】Ripes A graphical processor simulator and assembly editor for the RISC-V ISA 项目地址: https://gitcode.com/gh_mirrors/ri/Ripes RISC-V模拟器Ripes是一款强大的图形化处理器仿真…...
的使用场景)
Python运算符:成员运算符(in/not in)的使用场景
Python运算符:成员运算符(in/not in)的使用场景📚 本章学习目标:深入理解成员运算符(in/not in)的使用场景的核心概念与实践方法,掌握关键技术要点,了解实际应用场景与最…...

5个理由告诉你为什么Mermaid Live Editor是图表创作的效率神器
5个理由告诉你为什么Mermaid Live Editor是图表创作的效率神器 【免费下载链接】mermaid-live-editor Edit, preview and share mermaid charts/diagrams. New implementation of the live editor. 项目地址: https://gitcode.com/GitHub_Trending/me/mermaid-live-editor …...

XUnity.AutoTranslator:如何免费实现Unity游戏实时翻译的完整指南
XUnity.AutoTranslator:如何免费实现Unity游戏实时翻译的完整指南 【免费下载链接】XUnity.AutoTranslator 项目地址: https://gitcode.com/gh_mirrors/xu/XUnity.AutoTranslator 在游戏的世界里,语言障碍常常成为玩家体验全球优秀作品的绊脚石。…...

以书香润心,借坚韧前行
一书一山海,一心一乾坤。身处车马喧嚣的世间,我们时常被生活的压力裹挟,被前路的未知困扰,在重复的日常里消磨热忱,在跌宕的波折中心生怯懦。而书籍,是治愈心灵、滋养成长的最好良方,于无声处给…...

BepInEx 6.0技术揭秘:如何构建跨平台Unity插件框架的5大核心机制
BepInEx 6.0技术揭秘:如何构建跨平台Unity插件框架的5大核心机制 【免费下载链接】BepInEx Unity / XNA game patcher and plugin framework 项目地址: https://gitcode.com/GitHub_Trending/be/BepInEx 在Unity游戏开发领域,插件框架的技术实现一…...

图神经网络与神经算子:革新颗粒系统仿真的AI降阶建模
1. 项目概述:当图神经网络遇上颗粒世界在计算物理和工程仿真领域,颗粒系统(如沙土、粉末、谷物)的模拟一直是个“硬骨头”。传统的离散元法(DEM)虽然能精确刻画每个颗粒的牛顿运动方程和接触力学࿰…...