kafka的log存储解析
kafka的log存储解析——topic的分区partition分段segment以及索引等
引言Kafka中的Message是以topic为基本单位组织的,不同的topic之间是相互独立的。每个topic又可以分成几个不同的partition(每个topic有几个partition是在创建topic时指定
的),每个partition存储一部分Message。借用官方的一张图,可以直观地看到topic和partition的关系。
partition是以文件的形式存储在文件系统中,比如,创建了一个名为page_visits的topic,其有5个partition,那么在Kafka的数据目录中(由配置文件中的log.dirs指定的)中就有这
样5个目录: page_visits-0, page_visits-1,page_visits-2,page_visits-3,page_visits-4,其命名规则为<topic_name>-<partition_id>,里面存储的分别就是这5个partition的
数据。
接下来,本文将分析partition目录中的文件的存储格式和相关的代码所在的位置。
Partition中的每条Message由offset来表示它在这个partition中的偏移量,这个offset不是该Message在partition数据文件中的实际存储位置,而是逻辑上一个值,它唯一确定了
partition中的一条Message。因此,可以认为offset是partition中Message的id。partition中的每条Message包含了以下三个属性:
其中offset为long型,MessageSize为int32,表示data有多大,data为message的具体内容。它的格式和Kafka通讯协议中介绍的MessageSet格式是一致。
Partition的数据文件则包含了若干条上述格式的Message,按offset由小到大排列在一起。它的实现类为FileMessageSet,类图如下:
它的主要方法如下:
我们来思考一下,如果一个partition只有一个数据文件会怎么样?
那Kafka是如何解决查找效率的的问题呢?有两大法宝:1) 分段 2) 索引。
Kafka解决查询效率的手段之一是将数据文件分段,比如有100条Message,它们的offset是从0到99。假设将数据文件分成5段,第一段为0-19,第二段为20-39,以此类推,每
段放在一个单独的数据文件里面,数据文件以该段中最小的offset命名。这样在查找指定offset的Message的时候,用二分查找就可以定位到该Message在哪个段中。
数据文件分段使得可以在一个较小的数据文件中查找对应offset的Message了,但是这依然需要顺序扫描才能找到对应offset的Message。为了进一步提高查找的效率,Kafka为
每个分段后的数据文件建立了索引文件,文件名与数据文件的名字是一样的,只是文件扩展名为.index。
索引文件中包含若干个索引条目,每个条目表示数据文件中一条Message的索引。索引包含两个部分(均为4个字节的数字),分别为相对offset和position。
index文件中并没有为数据文件中的每条Message建立索引,而是采用了稀疏存储的方式,每隔一定字节的数据建立一条索引。这样避免了索引文件占用过多的空间,从而可以将
索引文件保留在内存中。但缺点是没有建立索引的Message也不能一次定位到其在数据文件的位置,从而需要做一次顺序扫描,但是这次顺序扫描的范围就很小了。
Partition的数据文件
offset
MessageSize
data
append: 把给定的ByteBufferMessageSet中的Message写入到这个数据文件中。
searchFor: 从指定的startingPosition开始搜索找到第一个Message其offset是大于或者等于指定的offset,并返回其在文件中的位置Position。它的实现方式是从
startingPosition开始读取12个字节,分别是当前MessageSet的offset和size。如果当前offset小于指定的offset,那么将position向后移动LogOverHead+MessageSize(其
中LogOverHead为offset+messagesize,为12个字节)。
read:准确名字应该是slice,它截取其中一部分返回一个新的FileMessageSet。它不保证截取的位置数据的完整性。
sizeInBytes: 表示这个FileMessageSet占有了多少字节的空间。
truncateTo: 把这个文件截断,这个方法不保证截断位置的Message的完整性。
readInto: 从指定的相对位置开始把文件的内容读取到对应的ByteBuffer中。
1. 新数据是添加在文件末尾(调用FileMessageSet的append方法),不论文件数据文件有多大,这个操作永远都是O(1)的。
2. 查找某个offset的Message(调用FileMessageSet的searchFor方法)是顺序查找的。因此,如果数据文件很大的话,查找的效率就低。
数据文件的分段
为数据文件建索引
相对offset:因为数据文件分段以后,每个数据文件的起始offset不为0,相对offset表示这条Message相对于其所属数据文件中最小的offset的大小。举例,分段后的一个数
据文件的offset是从20开始,那么offset为25的Message在index文件中的相对offset就是25-20 = 5。存储相对offset可以减小索引文件占用的空间。
position,表示该条Message在数据文件中的绝对位置。只要打开文件并移动文件指针到这个position就可以读取对应的Message了。在Kafka中,索引文件的实现类为OffsetIndex,它的类图如下:
主要的方法有:
我们以几张图来总结一下Message是如何在Kafka中存储的,以及如何查找指定offset的Message的。
Message是按照topic来组织,每个topic可以分成多个的partition,比如:有5个partition的名为为page_visits的topic的目录结构为:
partition是分段的,每个段叫LogSegment,包括了一个数据文件和一个索引文件,下图是某个partition目录下的文件:
可以看到,这个partition有4个LogSegment。
借用博主@lizhitao博客上的一张图来展示是如何查找Message的。
比如:要查找绝对offset为7的Message:
这套机制是建立在offset是有序的。索引文件被映射到内存中,所以查找的速度还是很快的。
append方法,添加一对offset和position到index文件中,这里的offset将会被转成相对的offset。
lookup, 用二分查找的方式去查找小于或等于给定offset的最大的那个offset
小结
1. 首先是用二分查找确定它是在哪个LogSegment中,自然是在第一个Segment中。
2. 打开这个Segment的index文件,也是用二分查找找到offset小于或者等于指定offset的索引条目中最大的那个offset。自然offset为6的那个索引是我们要找的,通过索引文
件我们知道offset为6的Message在数据文件中的位置为9807。
3. 打开数据文件,从位置为9807的那个地方开始顺序扫描直到找到offset为7的那条Message。一句话,Kafka的Message存储采用了分区(partition),分段(LogSegment)和稀疏索引这几个手段来达到了高效性。
Kafka 将消息以 topic 为单位进行归纳
将向 Kafka topic 发布消息的程序成为 producers.
将预订 topics 并消费消息的程序成为 consumer.
Kafka 以集群的方式运行,可以由一个或多个服务组成,每个服务叫做一个 broker.
producers 通过网络将消息发送到 Kafka 集群,集群向消费者提供消息
数据传输的事务定义通常有以下三种级别:
(
1)最多一次: 消息不会被重复发送,最多被传输一次,但也有可能一次不传输
(
2)最少一次: 消息不会被漏发送,最少被传输一次,但也有可能被重复传输.
(
3)精确的一次(Exactly once):不会漏传输也不会重复传输,每个消息都传输被一次而且仅仅被传输一次,这是大家所期望的
(
1)节点必须可以维护和 ZooKeeper 的连接,Zookeeper 通过心跳机制检查每个节点的连接
(
2)如果节点是个 follower,他必须能及时的同步 leader 的写操作,延时不能太久
producer 直接将数据发送到 broker 的 leader(主节点),不需要在多个节点进行分发,为了帮助 producer 做到这点,所有的 Kafka 节点都可以及时的告知:哪些节点是活动的,
目标topic 目标分区的 leader 在哪。这样 producer 就可以直接将消息发送到目的地了
Kafaconsumer 消费消息时,向 broker 发出"fetch"请求去消费特定分区的消息,consumer 指定消息在日志中的偏移量(offset),就可以消费从这个位置开始的消息,
customer 拥有了 offset 的控制权,可以向后回滚去重新消费之前的消息,这是很有意义的
Kafka 最初考虑的问题是,customer 应该从 brokes 拉取消息还是 brokers 将消息推送到
consumer,也就是 pull 还 push。在这方面,Kafka 遵循了一种大部分消息系统共同的传统的设计:producer 将消息推送到 broker,consumer 从 broker 拉取消息
一些消息系统比如 Scribe 和 ApacheFlume 采用了 push 模式,将消息推送到下游的 consumer。这样做有好处也有坏处:由 broker 决定消息推送的速率,对于不同消费速率的
consumer 就不太好处理了。消息系统都致力于让 consumer 以最大的速率最快速的消费消息,但不幸的是,push 模式下,当 broker 推送的速率远大于 consumer 消费的速率
时, consumer 恐怕就要崩溃了。最终 Kafka 还是选取了传统的 pull 模式
Pull 模式的另外一个好处是 consumer 可以自主决定是否批量的从 broker 拉取数据。Push 模式必须在不知道下游 consumer 消费能力和消费策略的情况下决定是立即推送每条
消息还是缓存之后批量推送。如果为了避免 consumer 崩溃而采用较低的推送速率,将可能导致一次只推送较少的消息而造成浪费。Pull 模式下,consumer 就可以根据自己的
消费能力去决定这些策略
Pull 有个缺点是,如果 broker 没有可供消费的消息,将导致 consumer 不断在循环中轮询,
直到新消息到 t 达。为了避免这点,Kafka 有个参数可以让 consumer 阻塞知道新消息到达
(当然也可以阻塞知道消息的数量达到某个特定的量这样就可以批量发
消息由一个固定长度的头部和可变长度的字节数组组成。头部包含了一个版本号和 CRC32
校验码。
·消息长度: 4 bytes (value: 1+4+n)
·版本号: 1 byte
·CRC 校验码: 4 bytes
·具体的消息: n bytes
(1).Kafka 把 topic 中一个 parition 大文件分成多个小文件段,通过多个小文件段,就容易定期清除或删除已经消费完文件,减少磁盘占用。
(2).通过索引信息可以快速定位 message 和确定 response 的最大大小。
(3).通过 index 元数据全部映射到 memory,可以避免 segment file 的 IO 磁盘操作。(4).通过索引文件稀疏存储,可以大幅降低 index 文件元数据占用空间大小。
(1).Kafka 持久化日志,这些日志可以被重复读取和无限期保留
(2).Kafka 是一个分布式系统:它以集群的方式运行,可以灵活伸缩,在内部通过复制数据提升容错能力和高可用性
(3).Kafka 支持实时的流式处理
相关文章:

kafka的log存储解析
kafka的log存储解析——topic的分区partition分段segment以及索引等 引言Kafka中的Message是以topic为基本单位组织的,不同的topic之间是相互独立的。每个topic又可以分成几个不同的partition(每个topic有几个partition是在创建topic时指定 的),每个…...
4.文件系统
组成 Linux:一切皆文件 索引节点(I-node) I-node(Index Node):文件系统的内部数据结构,用于管理文件的元数据和数据块。 文件的元数据:包括文件的权限、拥有者、大小、时间戳、索引…...

Shell脚本case in esac分支语句应用
记录:434 场景:Shell脚本case in esac分支语句应用。 版本:CentOS Linux release 7.9.2009。 1.case in esac格式 格式: case 值 in 模式1)expression;; 模式2)expression;; 模式n)expression;; esac 解析:case…...
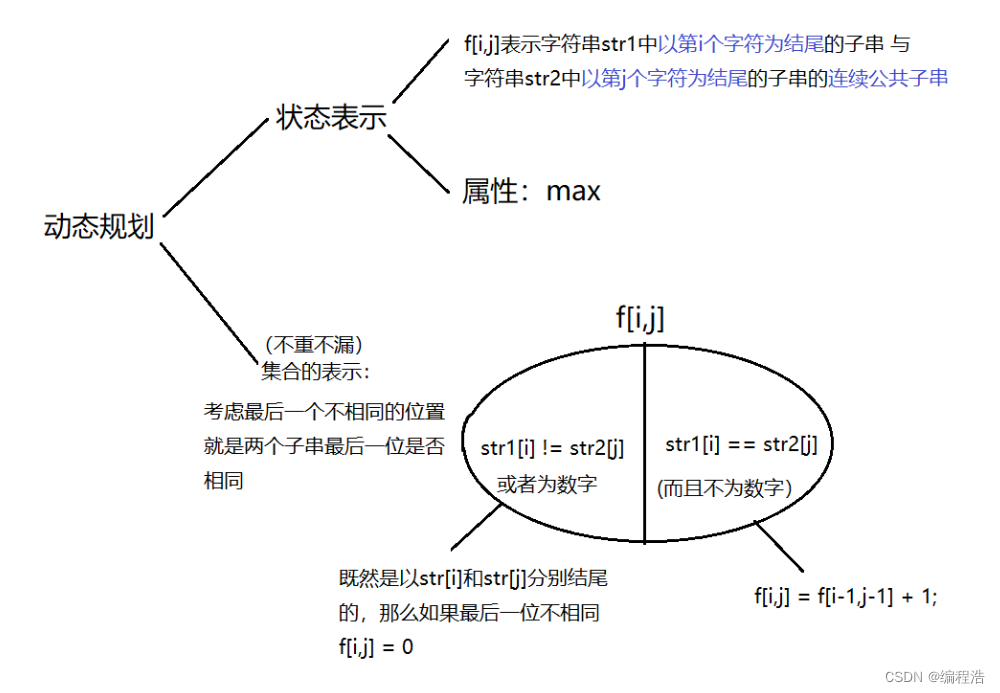
【线性dp必学四道题】线性dp四道经典例题【最长上升子序列】、【最长公共子序列】、【最长公共上升子序列(maxv的由来)】【最长公共子串】
【最长上升子序列】、【最长公共子序列】、【最长公共上升子序列】 最长上升子序列f[i] 表示以i结尾的最长子序列 最长公共子序列f[i][j] 表示 a前i 和 b前j个 最长公共长度 最长公共上升子序列f[i][j]代表所有a[1 ~ i]和b[1 ~ j]中以b[j]结尾的公共上升子序列的集合 最长公共子…...

追寻幸福:探索幸福的关键特征和行为
目录 1. 积极的心态 2. 良好的人际关系 3. 自我接纳和自尊 4. 追求意义和目标 5. 健康的身心状态 6. 感知和实现个人价值 幸福是一个主观的感受,因此不同的人对于幸福的定义和追求方式可能会有所不同。然而,有一些共同的特点和行为模式,…...

Redis-02-集群
一、redis5搭建集群 1.1、案例:搭建6台redis主机,配置如下 redis并发量:https://www.gxlcms.com/redis-350423.html主机IP:192.168.168.60~65修改redis配置文件hash槽移动,槽内的数据也随之移动 [root60 ~]# vim /e…...
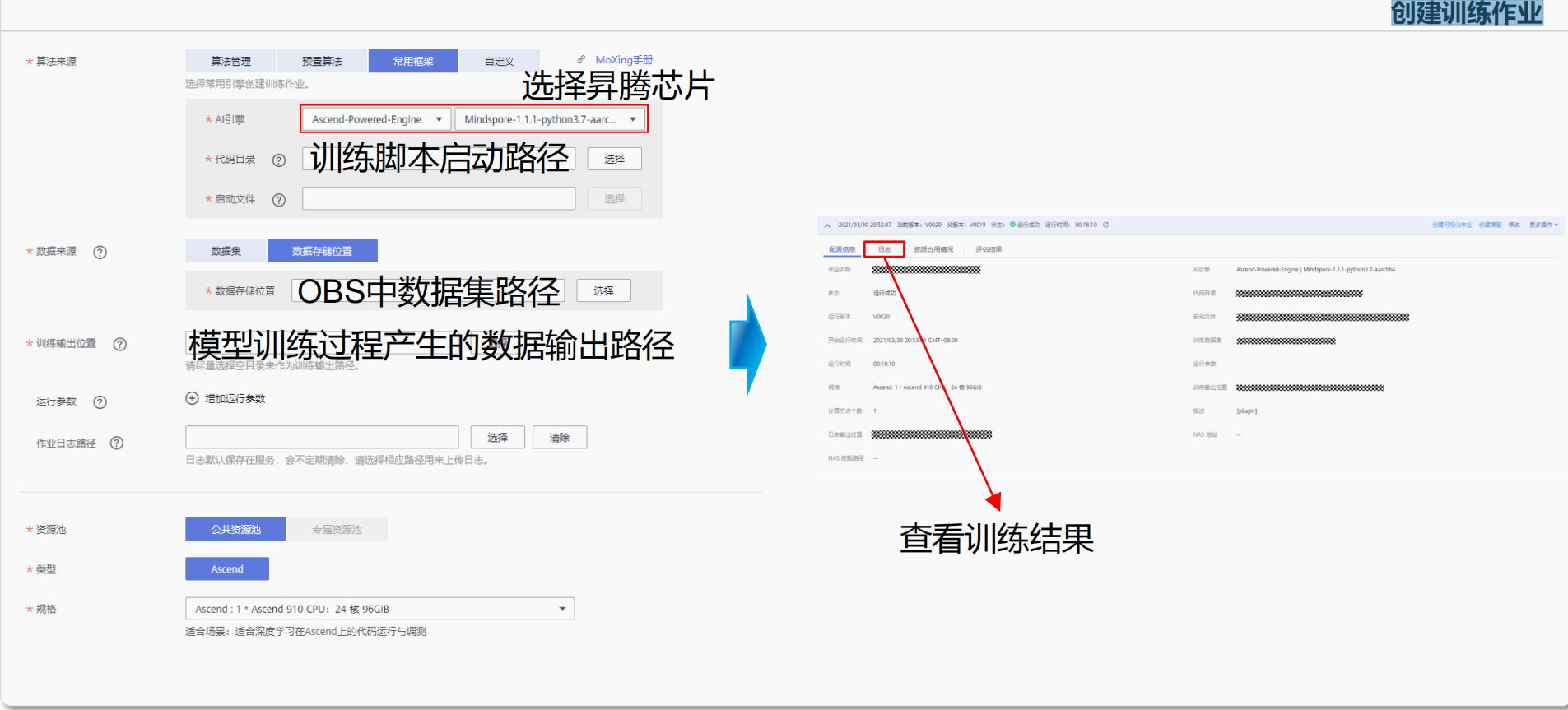
【2023 · CANN训练营第一季】MindSpore模型快速调优攻略 第三章——MindSpore云上调试调优
1.ModelArts云上调试调优 ModelArts密钥初始化 详细教程: 初始化OBS服务 创建训练作业 2.MindSpore IDE插件效率提升 通过智能代码块推荐、代码自动补全等特性,提升MindSpore脚本开发效率,对接ModelArts云服务,实现模型训…...
python笔记17_实例演练_二手车折旧分析p2
…… 书接上文 4.车辆等级维度 探查车龄为5年的车辆,折旧价值与车辆等级的关系。 # 筛选出车龄为5的数据创建新表 data_age5 data[data[age] 5] data_age5 # 分组聚合计算均值 data_car_level data_age5.groupby(car_level_name)[lowest_price].mean().reset…...

android 12.0长按Power弹出关机对话框去掉屏幕截图和紧急呼救功能
1.概述 在12.0的系统长按关机键,会弹出关机的对话框,关机对话框里面由关机重启截图和紧急呼叫等功能,而由于开发功能需求要求去掉屏幕截图和紧急呼叫等功能,所以就要先找到关机对框的代码 然后实现功能 功能分析: 长按电源键弹出关机对话框,通过adb shell命令发现 就是f…...

2023年下半年软考高级需要报班吗?
首先,对于软考高级考试报班与否的问题,需要根据自身的情况来做出决定。如果你有较强的自学能力,且具备丰富的实际工作经验和技术知识,那么不报班也完全可以自学备考。但如果你对软件工程的知识掌握程度较低,或者时间紧…...

使用WordPress提高企业敏捷性
喜欢WordPress的原因有很多:该平台非常适合内容管理以及控制预算。此外, 在 提高开发效率和简化项目管理方面,WordPress可以通过多种方式提供帮助。 对于任何企业业务,目标始终是在不影响质量的情况下更快地启动项目、发布修复和…...

SSM编程---Day 07
目录 SpringMVC 一、概念 二、springMVC的请求处理流程 三、mvc:annotation-driven 标签的作用 四、HandlerMapping、Handler和HandlerAdapter的介绍 五、SpringMVC 体系结构 六、SpringMVC的常用注解 七、view和controller之间的传值 SpringMVC 一、概念 1、 Spring…...
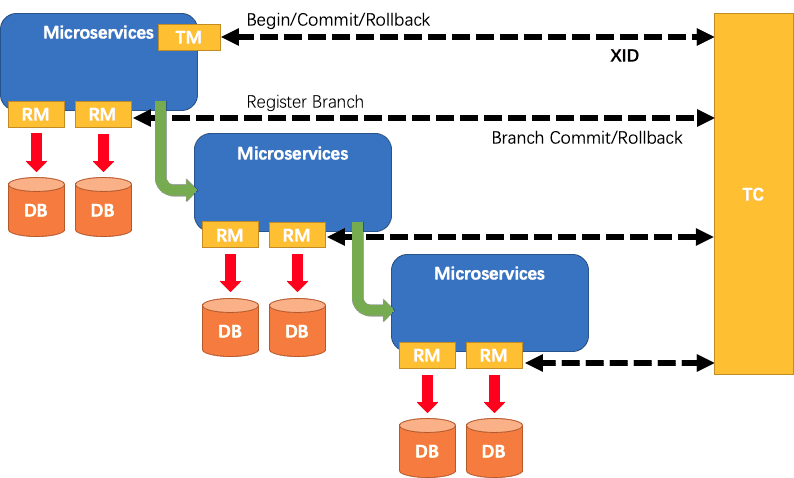
Seata术语
1.什么是Seata Seata是一款开源的分布式事务解决方案,致力于在微服务架构下提供高性能和简单易用的分布式事务服务。 官网 2.Seata能干嘛 一个典型的分布式事务过程 分布式事务处理过程的一ID三组件模型: Transaction ID XID 全局唯一的事务ID三组…...

【Axure教程】通过文本框维护下拉列表选项
下拉列表(Dropdown List)是一种常见的用户界面元素,用于提供一组选项供用户选择。它通常以一个展开的列表形式出现,用户可以点击或选择列表中的一个选项。一般来说,他的选项值是由系统代码组成的,所以一般是…...
)
【C++】基础知识--输入/输出(5)
前面部分的示例程序几乎没有提供与用户的交互(如果有的话)。他们只是在屏幕上打印简单的值,但标准库提供了许多其他方式通过其输入/输出功能与用户交互。本节将简要介绍一些最有用的方法。 cin标准输入cout标准输出cerr标准错误(输…...
经典文献阅读之--PIBT(基于可见树的实时规划方案)
0. 简介 作为路径规划而言,不单单有单个机器人自主路径规划,近年来随着机器人行业的兴起,多机器人自主路径规划也越来越受到关注,对于多智能体寻路(MAPF)。一般的操作会给定一个地图、机器人集群、以及它们的初始位置和目的地&am…...

SAP-MM-计算方案字段解析
01、 “步骤”:标识此条件类型在计算方案中的顺序编号,此编号会影响到后续业务中条件类型的排序,不同条件类型之间的编号最好间隔大一些,这样设置便于以后对计算方案进行扩展; 02、 “计数器”࿱…...

go-gf框架两个表以事务方式写入示例
下面是对每一行代码的中文解释: // 创建数据库连接对象 var tx gdb.TX这行代码声明了一个名为tx的变量,类型为gdb.TX,表示数据库事务对象。 // 开启事务 if tx, err g.DB().Ctx(ctx).Begin(ctx); err nil {这行代码通过在数据库连接&…...

2023-5-31第三十一天
conform顺从,遵从,一致 squeeze挤压 proprietary专卖权,专利的,所有的 endeavor努力,尽力 comprise由...组成,包含 compose组成,写作 compact小型的 consult咨询,查阅 expan…...
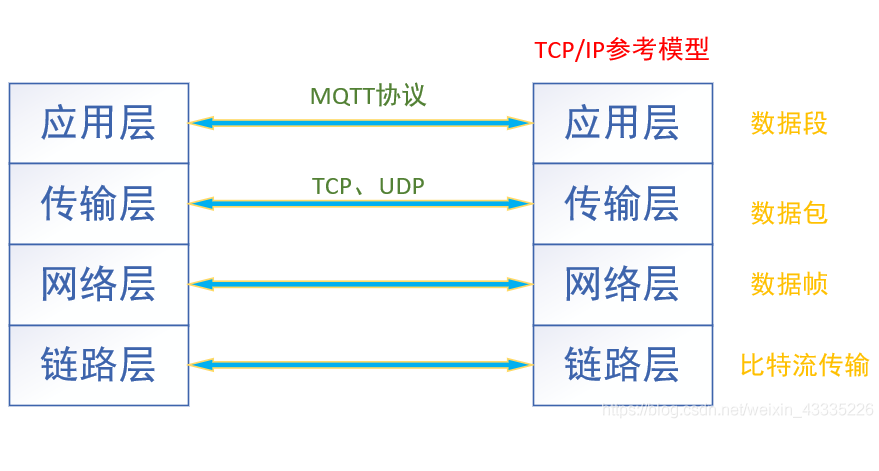
什么是MQTT?mqtt协议和http协议区别
摘要: 什么是MQTT?MQTT(Message Queuing Telemetry Transport)译为:消息队列遥测传输,是一种轻量级的通讯协议,用于在网络上传输消息。MQTT 最初由 IBM 发布,后来成为 OASIS…...

Keil MDK优化级别设置与嵌入式开发性能调优
1. UVISION项目优化级别设置全解析在嵌入式开发领域,代码优化是提升性能、减少体积的关键环节。Keil MDK作为ARM架构的主流开发环境,提供了从项目全局到单个函数的多层级优化控制能力。本文将深入剖析如何在Vision环境中精细控制优化级别,帮助…...

告别打包焦虑:UE5 Windows与安卓打包速度优化与稳定性提升全攻略
告别打包焦虑:UE5 Windows与安卓打包速度优化与稳定性提升全攻略在虚幻引擎5(UE5)开发流程中,打包环节往往是开发者体验的分水岭——顺畅的打包过程能保持创作心流,而频繁的报错和漫长等待则会严重消耗开发热情。本文将…...
)
不止是选择器:用Unity Dropdown组件打造一个可交互的游戏设置菜单(附完整C#脚本)
不止是选择器:用Unity Dropdown组件打造一个可交互的游戏设置菜单在游戏开发中,设置菜单是玩家与游戏交互的重要桥梁。一个设计精良的设置菜单不仅能提升用户体验,还能让玩家根据个人偏好调整游戏参数。Unity的Dropdown组件常被简单用作选择器…...

如何利用AI工具变现:一个老程序员的真实观察
凌晨两点,你又刷到一个"AI月入5万"的短视频。 关了手机,睡不着了。 明天还要上班。 这种焦虑感,我太熟悉了。 作为一个写了12年代码的老程序员,这两年被问到最多的问题就是:"有什么真正能用的AI变现方法?" 今天不画饼,说点真话。 先说结论 AI…...

Kubernetes性能优化指南:提升集群运行效率
Kubernetes性能优化指南:提升集群运行效率 引言 在生产环境中,Kubernetes集群的性能优化是一个持续的过程。通过优化,可以提高资源利用率、减少响应时间、提升用户体验。 今天就来分享一下Kubernetes性能优化的经验和方法。 资源优化 Pod资源…...

栈以及队列的详细讲解
1.栈的定义以及实现栈:一种特殊的线性表,其只允许在固定的一端进行插入和删除元素操作。进行数据插入和删除操作的一端称为栈顶,另一端称为栈底。栈中的数据元素遵守后进先出LIFO(Last In First Out)的原则。压栈&…...

3步构建物联网数字孪生:Eclipse Ditto实战指南
3步构建物联网数字孪生:Eclipse Ditto实战指南 【免费下载链接】ditto Eclipse Ditto™: Digital Twin framework of Eclipse IoT - main repository 项目地址: https://gitcode.com/gh_mirrors/ditto6/ditto 在物联网(IoT)时代,如何高效管理成千…...
)
ChatGPT演讲稿写作避坑指南:17个高频失效场景+对应Prompt修正代码(含GitHub可执行验证库)
更多请点击: https://intelliparadigm.com 第一章:ChatGPT演讲稿写作的核心范式与认知跃迁 传统演讲稿创作依赖线性构思、反复修改与经验沉淀,而ChatGPT的介入并非简单替代人力,而是触发一场从“作者中心”到“提示—反馈—协同演…...

CatServer深度解析:构建高性能Minecraft模组与插件一体化服务端实战指南
CatServer深度解析:构建高性能Minecraft模组与插件一体化服务端实战指南 【免费下载链接】CatServer 高性能和高兼容性的1.12.2/1.16.5/1.18.2版本ForgeBukkitSpigot服务端 (A high performance and high compatibility 1.12.2/1.16.5/1.18.2 version ForgeBukkitSp…...

英雄联盟智能助手:League Akari 的5大核心功能深度解析
英雄联盟智能助手:League Akari 的5大核心功能深度解析 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit League Akari 是一款基于英…...