Java的Atomic原子类
Java SDK 并发包里提供了丰富的原子类,我们可以将其分为五个类别,这五个类别提供的方法基本上是相似的,并且每个类别都有若干原子类。
- 对基本数据类型的变量值进行原子更新;
- 对对象变量的指向进行原子更新;
- 对数组里面的的元素进行原子更新;
- 原子化的对象属性更新器;
- 原子化的累加器。

基本数据类型
AtomicBoolean、AtomicLong、AtomicInteger 这三个类提供了一些对基本数据类型的变量值进行原子更新的方法。
这些类提供的方法是相似的,主要有(以 AtomicLong 为例):
// 原子化的 i++
long getAndIncrement()
// 原子化的 i--
long getAndDecrement()// 原子化的 ++i
long incrementAndGet()
// 原子化的 --i
long decrementAndGet()// 原子化的 i+=delta,返回值为+=前的i值
long getAndAdd(long delta)
// 原子化的 i+=delta,返回值为+=后的i值
long addAndGet(delta)// CAS操作。如果写回成功返回true,否则返回false
boolean compareAndSet(long expect, long update)// 以下四个方法新值可以通过传入函数式接口(func函数)来计算
long getAndUpdate(LongUnaryOperator updateFunction)
long updateAndGet(LongUnaryOperator updateFunction)
long getAndAccumulate(long x, LongBinaryOperator accumulatorFunction)
long accumulateAndGet(long x, LongBinaryOperator accumulatorFunction)
// 演示 getAndUpdate() 方法的使用
public static void main(String[] args) {AtomicLong atomicLong = new AtomicLong(0);long result = atomicLong.getAndUpdate(new LongUnaryOperator() {@Overridepublic long applyAsLong(long operand) {return operand + 1;}});
}
对象引用类型
AtomicReference、AtomicStampedReference、AtomicMarkableReference 这三个类提供了一些对对象变量的指向进行原子更新的方法。如果需要对对象的属性进行原子更像,那么可以使用原子化的对象属性更新器。
public class ClassName {AtomicReference<Employee> employeeAR = new AtomicReference<>(new Employee("小明"));public void methodName() {Employee oldVal = employeeAR.get();Employee newVal = new Employee(oldVal.getName());employeeAR.compareAndSet(oldVal, newVal);}
}
对象引用的原子化更新需要重点关注 ABA 问题。当一个线程在进行 CAS 操作时,另一个线程可能会在此期间修改了同一个共享变量的值,然后又将其改回原来的值。这种情况下,CAS 操作就无法检测到共享变量值的变化,从而导致 ABA 问题。如果我们仅仅在写回数据前判断数值是 A,可能导致不合理的写回操作。AtomicStampedReference 和 AtomicMarkableReference 这两个原子类可以解决 ABA 问题。
- AtomicStampedReference 通过为对象引用建立类似版本号(stamp)的方式,来解决 ABA 问题。AtomicStampedReference 实现的 CAS 方法增加了版本号参数
- AtomicMarkableReference 的实现机制则更简单,将版本号简化成了一个 Boolean 值
boolean compareAndSet(V expectedReference, V newReference, int expectedStamp, int newStamp)boolean compareAndSet(V expectedReference, V newReference,boolean expectedMark, boolean newMark)
数组
AtomicIntegerArray、AtomicLongArray、AtomicReferenceArray 这三个类提供了一些对数组里面的的元素进行原子更新的方法。
public class ClassName {AtomicLongArray atomicLongArray = new AtomicLongArray(new long[]{0, 1});public void methodName() {int index = 0;long oldVal = atomicLongArray.get(index);long newVal = oldVal + 1;atomicLongArray.compareAndSet(index, oldVal, newVal);}
}
原子化的对象属性更新器
原子化的对象属性更新器有:AtomicIntegerFieldUpdater、AtomicLongFieldUpdater、AtomicReferenceFieldUpdater。
这三个类提供了一些对对象的属性进行原子更新的方法。这些方法是利用反射机制实现的。
public class ClassName {AtomicIntegerFieldUpdater<Employee> fieldUpdater =AtomicIntegerFieldUpdater.newUpdater(Employee.class, "salary");Employee employee = new Employee("小明", 1000);public void methodName() {int oldVal = employee.getSalary();int newVal = oldVal + 1000;fieldUpdater.compareAndSet(employee, oldVal, newVal);}
}
需要注意的是:
- 对象属性的类型必须是基本数据类型,不能是基本数据类型对应的包装类。如果对象属性的类型不是基本数据类型,newUpdater() 方法会抛出 IllegalArgumentException 运行时异常。
- 对象的属性必须是 volatile 类型的,只有这样才能保证可见性。如果对象的属性不是 volatile 类型的,newUpdater() 方法会抛出 IllegalArgumentException 运行时异常。
// AtomicIntegerFieldUpdater 类中的代码
if (field.getType() != int.class) {throw new IllegalArgumentException("Must be integer type");
}if (!Modifier.isVolatile(modifiers)) {throw new IllegalArgumentException("Must be volatile type");
}
原子化的累加器
原子化的累加器有:LongAdder、DoubleAdder、LongAccumulator、DoubleAccumulator。这四个类仅仅用来在多线程环境下,执行累加操作。
相比原子化的基本数据类型,原子化的累加器的速度更快,但是它(原子化的累加器)不支持 compareAndSet() 方法。如果仅仅需要累加操作,使用原子化的累加器性能会更好。
原子化的累加器的本质是空间换时间。
LongAdder 的使用示例如下所示:
public static void main(String[] args) {LongAdder adder = new LongAdder();// 初始化adder.add(1);// 累加for (int i = 0; i < 100; i++) {adder.increment();}long sum = adder.sum();
}
LongAccumulator 与 LongAdder 类似,但 LongAccumulator 提供了更加灵活的累加操作,可以自定义累加函数。
使用示例如下所示。在使用示例中,我们创建了一个 LongAccumulator 对象,初始值为1,累加函数为 (x, y) -> x * y,即每次累加都将之前的结果与新的值相乘。然后,我们累加了三个数值,最后输出累加结果。由于累加函数是(x, y) -> x * y,所以最终的累加结果为1 * 5 * 10 * 20 = 1000。
public static void main(String[] args) {LongAccumulator accumulator = new LongAccumulator(new LongBinaryOperator() {@Overridepublic long applyAsLong(long left, long right) {return left * right;}}, 1);// 初始值为1,累加函数为(x, y) -> x * yaccumulator.accumulate(5);accumulator.accumulate(10);accumulator.accumulate(20);// 累加结果为 1 * 5 * 10 * 20 = 1000long result = accumulator.get();
}
参考资料
21 | 原子类:无锁工具类的典范 (geekbang.org)
相关文章:
Java的Atomic原子类
Java SDK 并发包里提供了丰富的原子类,我们可以将其分为五个类别,这五个类别提供的方法基本上是相似的,并且每个类别都有若干原子类。 对基本数据类型的变量值进行原子更新;对对象变量的指向进行原子更新;对数组里面的…...

离线语音控制新方案,NRK3303语音识别芯片在智能风扇的应用
随着科技的不断发展,智能家居已经成为人们日常生活中不可或缺的一部分,涌现出越来越多的智能设备,如智能门锁、智能灯泡、智能冰箱等,这些设备为人们的生活带来了更多的便利和创新。其中作为常见的风扇通过添加智能语音控制功能&a…...
在树莓派3B+上安装Pytorch1.7
在树莓派3B上安装Pytorch1.7(应该是最简单的方法了)_package libopenblas-dev has no installation cand_Chauncey_Wang的博客-CSDN博客由于项目要求,我需要在树莓派上安装pytorch这就有几个问题,首先吧,咱们和外面之间有一道长城,…...

Java性能权威指南-总结4
Java性能权威指南-总结4 Java性能调优工具箱操作系统的工具和分析CPU运行队列磁盘使用率网络使用率 Java监控工具基本的VM信息 Java性能调优工具箱 操作系统的工具和分析 CPU运行队列 快速小结 检查应用性能时,首先应该审查CPU时间。优化代码的目的是提升而不是…...

c语言全局变量和局部变量问题汇总
✅作者简介:嵌入式领域优质创作者,博客专家 ✨个人主页:咸鱼弟 🔥系列专栏:单片机设计专栏 📃推荐一款求职面试、刷题神器👉注册免费刷题 1、关键字static的作用是什么? 定义静态变…...

14.3:给定一个由字符串组成的数组strs,必须把所有的字符串拼接起来,返回所有可能的拼接结果中字典序最小的结果
给定一个由字符串组成的数组strs,必须把所有的字符串拼接起来,返回所有可能的拼接结果中字典序最小的结果 贪心写法 首先注意的一点是:如果两个字符串的长度相同,“abc”,“abd”,肯定是“abc”的字典序最…...

C++ 项目实战:跨平台的文件与视频压缩解压工具的设计与实现
C实战:跨平台文件与视频压缩解压工具的设计与实现 一、引言(Introduction)1.1 项目背景与目标1.2 技术选型:C、FFmpeg、libarchive、libzip、QtCFFmpeglibarchivelibzipQt 二、设计思路与框架(Design Philosophy and F…...
数据)
C和指针(二)数据
数据类型 1,C语言中仅有四种基本数据类型——整型、浮点型、指针、聚合类型(数组、结构等)。 2,整型包括字符、短整型、整型、长整型,且可以分为有符号和无符号两种版本。 1)长整型至少和整型一样长&#…...
)
PyTorch基础学习(一)
一.简介 PyTorch是一个基于Python的开源机器学习框架,它提供了丰富的工具和接口,用于构建和训练深度学习模型。PyTorch的主要特点包括: 动态计算图: PyTorch使用动态计算图,这意味着在模型构建过程中可以实时地进行计…...

chatgpt赋能python:Python代做:让您的网站更友好的SEO利器
Python代做:让您的网站更友好的SEO利器 如果您是一位网站管理员或者SEO工程师,您一定知道SEO对于网站的重要性。那么在SEO中,Python代做可以为您提供什么?在本文中,我们将通过介绍Python代做的技术和方法,…...

2022年都快结束了,还有人不会安卓录屏?在安卓上录制屏幕的的实现方式
前言 在我之前的文章 《以不同的形式在安卓中创建GIF动图》 中,我挖了一个坑,可以通过录制屏幕后转为 GIF 的方式来创建 GIF。只是当时我只是提了这么一个思路,并没有给出录屏的方式,所以本文的内容就是教大家如何通过调用系统 A…...

px rem em rpx 区别 用法
任意浏览器的默认字体高都是16px。所有未经调整的浏览器都符合: 1em16px。那么12px0.75em,10px0.625em。为了简化font-size的换算,需要在css中的body选择器中声明Font-size62.5%,这就使em值变为 16px*62.5%10px, 这样12px1.2em, 10px1em, 也就是说只需要…...

忆享聚焦|ChatGPT、AI、网络数字、游戏……近期热点资讯一览
“忆享聚焦”栏目第十四期来啦!本栏目汇集近期互联网最新资讯,聚焦前沿科技,关注行业发展动态,筛选高质量讯息,拓宽用户视野,让您以最低的时间成本获取最有价值的行业资讯。 目录 行业资讯 1.科技部部长王志…...
)
[Daimayuan] 树(C++,动态规划,01背包方案数)
有一棵 n n n 个节点的以 1 1 1 号点为根的有根树。现在可以对这棵树进行若干次操作,每一次操作可以选择树上的一个点然后删掉连接这个点和它的儿子的所有边。 现在我们想知道对于每一个 k k k ( 1 ≤ k ≤ n 1≤k≤n 1≤k≤n),最少需要多少次操作能…...

如何选择源代码加密软件
(SDC沙盒)和DLP、文档加密、云桌面等,其优缺点做客观比较如下: 比较内容安全容器(SDC沙盒)DLP文档加密云桌面代表厂家*信达卖咖啡、赛门贴科亿*通、IP噶德、*盾、*途四杰、深*服设计理念以隔离容器加准入技术为基础,构…...

TO-B类软件产品差异化
产品差异化,是在市场众多同质化产品中,突出自身产品亮点的重要方式。对于客户来讲其选择是多种多样的,与其花费大量的时间研究每一家产品的特点,还不如直接选择品牌更大、价格更低的产品来的直接,因此显而易见的突出产…...
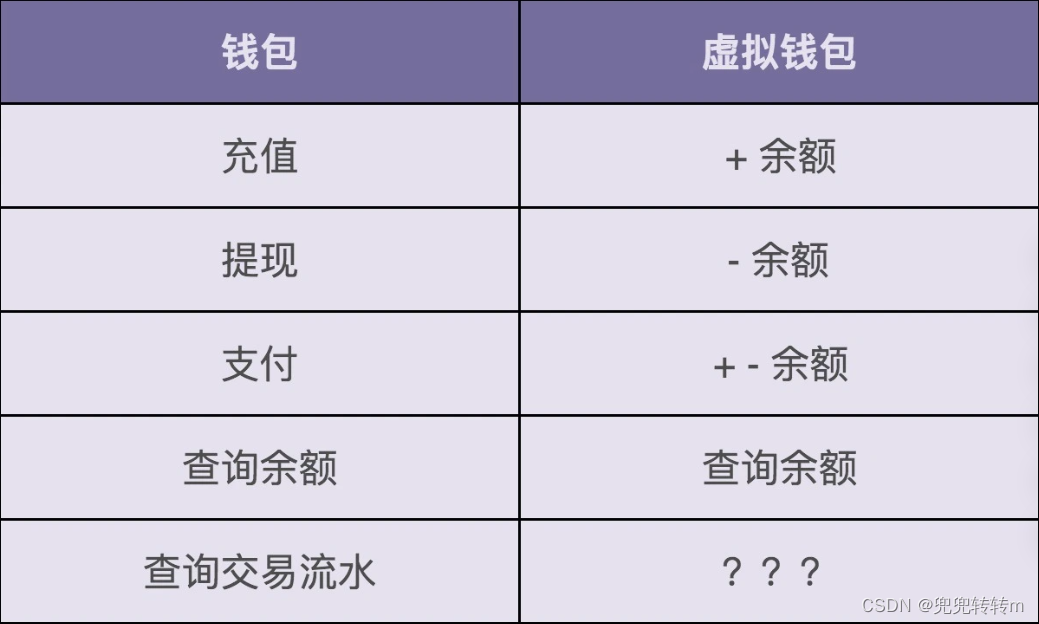
设计模式之美-实战一(上):业务开发常用的基于贫血模型的MVC架构违背OOP吗?
领域驱动设计(Domain Driven Design,简称DDD)盛行之后,这种基于贫血模型的传统的开发模式就更加被人诟病。而基于充血模型的DDD开发模式越来越被人提倡。所以,我打算用两节课的时间,结合一个虚拟钱包系统的…...

ChatGPT如何训练自己的模型
ChatGPT是一种自然语言处理模型,它的任务是生成自然流畅的对话。如果想要训练自己的ChatGPT模型,需要进行大量的数据收集、预处理、配置训练环境、模型训练、模型评估等过程。本文将详细介绍这些过程,帮助读者了解如何训练一个高品质的ChatGP…...
)
springboot使用线程池的实际应用(一)
在实际Spring Boot项目中,我们可以使用Java的原生多线程或者使用Spring自带的线程池进行多线程编程。多线程的好处在于能够提高应用程序的运行效率,特别是在某些计算密集型场景下。以下是一些使用多线程的典型场景: 并发处理请求:…...

ESP-8266学习笔记
1、学习地址 【XMF09F系列资源】基于MicroPython的ESP8266物联网应用开发-赛教资源目录汇总-小蜜蜂笔记 Quick reference for the ESP8266 — MicroPython latest documentation 2、MicroPython及相关开发资源 3、固件烧录与uPyLoader的使用 烧录教程参考: https://www.…...

告别昂贵定位器!用Python和PyTorch复现DCL-Net,实现无传感器3D超声重建
告别昂贵定位器!用Python和PyTorch复现DCL-Net实现无传感器3D超声重建在医学影像领域,3D超声重建技术正逐步改变传统诊断方式。想象一下,医生只需手持普通超声探头自由扫描,AI系统就能自动将二维切片合成为三维立体图像——这正是…...

【STM32 C 语言入门】什么是强制类型转换?小白也能秒懂!
一、什么是强制类型转换?一句话讲透 强制类型转换,就是“强行把一种数据类型,变成另一种数据类型”。 打个比方: 你手里拿着一个苹果(int类型)但函数只收橙子(枚举类型)强制类型转换…...
torchvision transforms 报错怎么办?教你一招避坑
💓 博客主页:瑕疵的CSDN主页 📝 Gitee主页:瑕疵的gitee主页 ⏩ 文章专栏:《热点资讯》 torchvision.transforms报错大揭秘:一招解决90%的坑目录torchvision.transforms报错大揭秘:一招解决90%的…...

Taotoken用量看板如何帮助团队分析并优化大模型API支出
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken用量看板如何帮助团队分析并优化大模型API支出 对于团队技术负责人或项目经理而言,管理大模型API支出并非易事…...

Agent协议标准化:互操作性的未来
Agent协议标准化:互操作性的未来 一、引言 钩子:你是否遇到过这些Agent协作的痛点? 你花了3天时间基于OpenAI GPT-4开发了一个客户需求分析Agent,能自动解析用户对话生成需求文档,但当你想把生成的需求文档同步给公司内部基于Llama 3部署的产品排期Agent时,却发现两个A…...
下载与使用指南)
Cobalt Strike(CS)下载与使用指南
⚠️ 免责声明:本文内容仅用于合法授权的网络安全测试、实验室学习与企业安全防护研究。禁止将相关工具用于任何未授权攻击、非法入侵、数据窃取或破坏行为,否则可能违反当地法律法规。 一、什么是 Cobalt Strike(CS) 1.1 简介 …...

暗黑破坏神2现代重生:D2DX如何让经典游戏在4K宽屏时代焕发新生?
暗黑破坏神2现代重生:D2DX如何让经典游戏在4K宽屏时代焕发新生? 【免费下载链接】d2dx D2DX is a complete solution to make Diablo II run well on modern PCs, with high fps and better resolutions. 项目地址: https://gitcode.com/gh_mirrors/d2…...

3分钟定位:Windows热键冲突终极排查工具
3分钟定位:Windows热键冲突终极排查工具 【免费下载链接】hotkey-detective A small program for investigating stolen key combinations under Windows 7 and later. 项目地址: https://gitcode.com/gh_mirrors/ho/hotkey-detective Hotkey Detective是一款…...

微信小程序数据可视化:为什么ECharts组件是你的最佳选择?
微信小程序数据可视化:为什么ECharts组件是你的最佳选择? 【免费下载链接】echarts-for-weixin 基于 Apache ECharts 的微信小程序图表库 项目地址: https://gitcode.com/gh_mirrors/ec/echarts-for-weixin 当我们开发微信小程序时,数…...

多路召回RAG系统
项目采用 多路召回 Rerank的RAG架构,核心入口是 RagSpecialistAgent.java,当用户与问答助手进行语言交流时,输入查询,首先先进行意图识别,判断是单任务还是多任务,并且判断是否需要RAG检索,因为…...