OpenAI目前所有模型介绍
目录
概述
GPT-4 (limted beta)
GPT-3.5
GPT-3
各类模型介绍
DALL·E Beta
Whisper Beta
Embeddings
Moderation
Codex (deprecated)
概述
| 模型 | 描述 |
|---|---|
| GPT-4 Limited beta | 一组在 GPT-3.5 上改进的模型,可以理解并生成自然语言或代码 |
| GPT-3.5 | 一组在 GPT-3 上改进的模型,可以理解并生成自然语言或代码 |
| DALL·E Beta | 可以在给定自然语言提示的情况下生成和编辑图像的模型 |
| Whisper Beta | 一种可以将音频转换为文本的模型 |
| Embeddings | 一组可以将文本转换为数字形式的模型 |
| Moderation | 可以检测文本是否敏感或不安全的微调模型 |
| GPT-3 | 一组可以理解和生成自然语言的模型 |
| Codex Deprecated | 一组可以理解和生成代码的模型,包括将自然语言翻译成代码 |
GPT-4 (limted beta)
GPT-4 是一个大型多模态模型(今天接受文本输入并发出文本输出,将来会出现图像输入),由于其更广泛的常识和高级推理,它可以比我们以前的任何模型更准确地解决难题能力。 与 gpt-3.5-turbo 一样,GPT-4 针对聊天进行了优化,但也适用于使用 Chat Completions API 的传统完成任务。
| 最新的模型 | 描述 | 最大的 TOKENS | 训练数据日期 |
|---|---|---|---|
| gpt-4 | 比任何 GPT-3.5 模型都更强大,能够执行更复杂的任务,并针对聊天进行了优化。 将使用我们最新的模型迭代进行更新。 | 8,192 tokens | Up to Sep 2021 |
| gpt-4-0314 | 2023 年 3 月 14 日的 gpt-4 快照。与 gpt-4 不同,此模型不会收到更新,并且会在新版本发布 3 个月后弃用。 | 8,192 tokens | Up to Sep 2021 |
| gpt-4-32k | 与基本 gpt-4 模式相同的功能,但上下文长度是其 4 倍。 将使用我们最新的模型迭代进行更新。 | 32,768 tokens | Up to Sep 2021 |
| gpt-4-32k-0314 | 2023 年 3 月 14 日的 gpt-4-32 快照。与 gpt-4-32k 不同,此模型不会收到更新,并将在新版本发布 3 个月后弃用。 | 32,768 tokens | Up to Sep 2021 |
对于许多基本任务,GPT-4 和 GPT-3.5 模型之间的差异并不显着。 然而,在更复杂的推理情况下,GPT-4 比我们之前的任何模型都更有能力。
GPT-3.5
GPT-3.5 模型可以理解并生成自然语言或代码。 我们在 GPT-3.5 系列中功能最强大且最具成本效益的模型是 gpt-3.5-turbo,它已针对聊天进行了优化,但也适用于传统的完成任务。
| 最新的模型 | 描述 | 最大的 TOKENS | 训练数据日期 |
|---|---|---|---|
| gpt-3.5-turbo | 功能最强大的 GPT-3.5 模型并针对聊天进行了优化,成本仅为 text-davinci-003 的 1/10。 将使用我们最新的模型迭代进行更新。 | 4,096 tokens | Up to Sep 2021 |
| gpt-3.5-turbo-0301 | 2023 年 3 月 1 日的 gpt-3.5-turbo 快照。与 gpt-3.5-turbo 不同,此模型不会收到更新,并将在新版本发布 3 个月后弃用。 | 4,096 tokens | Up to Sep 2021 |
| text-davinci-003 | 可以以比居里、巴贝奇或 ada 模型更好的质量、更长的输出和一致的指令遵循来完成任何语言任务。 还支持在文本中插入补全。 的 | 4,097 tokens | Up to Jun 2021 |
| text-davinci-002 | 与 text-davinci-003 类似的功能,但使用监督微调而不是强化学习进行训练 | 4,097 tokens | Up to Jun 2021 |
| code-davinci-002 | 针对代码完成任务进行了优化 | 8,001 tokens | Up to Jun 2021 |
我们建议使用 gpt-3.5-turbo 而不是其他 GPT-3.5 模型,因为它的成本更低。

GPT-3
GPT-3 模型可以理解和生成自然语言。 这些模型被更强大的 GPT-3.5 代模型所取代。 然而,最初的 GPT-3 基础模型(davinci、curie、ada 和 babbage)是目前唯一可用于微调的模型。
| 最新的模型 | 描述 | 最大的 TOKENS | 训练数据日期 |
|---|---|---|---|
| text-curie-001 | 非常有能力,比Davinci更快,成本更低。 | 2,049 tokens | Up to Oct 2019 |
| text-babbage-001 | 能够执行简单的任务,速度非常快,成本更低。 | 2,049 tokens | Up to Oct 2019 |
| text-ada-001 | 能够执行非常简单的任务,通常是 GPT-3 系列中最快的型号,而且成本最低。 | 2,049 tokens | Up to Oct 2019 |
| davinci | 功能最强大的 GPT-3 模型。 可以完成其他模型可以完成的任何任务,而且通常质量更高。 | 2,049 tokens | Up to Oct 2019 |
| curie | 非常有能力,但比Davinci更快,成本更低。 | 2,049 tokens | Up to Oct 2019 |
| babbage | 能够执行简单的任务,速度非常快,成本更低。 | 2,049 tokens | Up to Oct 2019 |
| ada | 能够执行非常简单的任务,通常是 GPT-3 系列中最快的型号,而且成本最低。 | 2,049 tokens | Up to Oct 2019 |
各类模型介绍
DALL·E Beta
DALL·E 是一个人工智能系统,可以根据自然语言的描述创建逼真的图像和艺术作品。 目前支持在提示的情况下创建具有特定大小的新图像、编辑现有图像或创建用户提供的图像的变体的能力。
通过Open API 提供的当前 DALL·E 模型是 DALL·E 的第 2 次迭代,具有比原始模型更逼真、更准确且分辨率高 4 倍的图像。 您可以通过我们的实验室界面或 API 进行试用。
产生图片的一些官网提供例子

编辑图片的例子

Whisper Beta
Whisper 是一种通用的语音识别模型。 它在不同音频的大型数据集上进行训练,也是一个多任务模型,可以执行多语言语音识别以及语音翻译和语言识别。 Whisper v2-large 模型目前可通过我们的 API 使用 whisper-1 模型名称获得。
目前,Whisper 的开源版本与通过我们的 API 提供的版本之间没有区别。 然而,通过Open API,我们提供了一个优化的推理过程,这使得通过我们的 API 运行 Whisper 比通过其他方式运行要快得多。
Embeddings
嵌入是文本的数字表示,可用于衡量两段文本之间的相关性。 我们的第二代嵌入模型 text-embedding-ada-002 旨在以一小部分成本取代之前的 16 种第一代嵌入模型。 嵌入可用于搜索、聚类、推荐、异常检测和分类任务。
Moderation
审核模型旨在检查内容是否符合 OpenAI 的使用政策。 这些模型提供了查找以下类别内容的分类功能:仇恨、仇恨/威胁、自残、性、性/未成年人、暴力和暴力/图片。
审核模型接受任意大小的输入,该输入会自动分解以修复模型特定的上下文窗口。
| MODEL | DESCRIPTION |
|---|---|
| text-moderation-latest | 最有能力的审核模型。 精度会略高于稳定模型 |
| text-moderation-stable |
Codex (deprecated)
Codex 模型现已弃用。 他们是我们 GPT-3 模型的后代,可以理解和生成代码 他们的训练数据包含自然语言和来自 GitHub 的数十亿行公共代码。 了解更多。
他们最擅长 Python,精通 JavaScript、Go、Perl、PHP、Ruby、Swift、TypeScript、SQL,甚至 Shell 等十几种语言。
以下 Codex 模型现已弃用:
| 最新的模型 | 描述 | 最大的 TOKENS | 训练数据日期 |
|---|---|---|---|
| code-davinci-002 | 功能最强大的 Codex 型号。 特别擅长将自然语言翻译成代码。 除了补全代码,还支持在代码中插入补全。 的 | 8,001 tokens | Up to Jun 2021 |
| code-davinci-001 | ode-davinci-002的早期版本 | 8,001 tokens | Up to Jun 2021 |
| code-cushman-002 | 几乎与 Davinci Codex 一样强大,但速度稍快。 这种速度优势可能使其成为实时应用程序的首选。 | Up to 2,048 tokens | |
| code-cushman-001 | code-cushman-002 的早期版本 | Up to 2,048 tokens |
以上所有的内容来自https://platform.openai.com/docs/models
相关文章:
OpenAI目前所有模型介绍
目录 概述 GPT-4 (limted beta) GPT-3.5 GPT-3 各类模型介绍 DALLE Beta Whisper Beta Embeddings Moderation Codex (deprecated) 概述 模型描述GPT-4 Limited beta 一组在 GPT-3.5 上改进的模型,可以理解并生成自然语言或代码GPT-3.5一组在 GPT-3 上改…...

【P43】JMeter 吞吐量控制器(Throughput Controller)
文章目录 一、吞吐量控制器(Throughput Controller)参数说明二、测试计划设计2.1、Total Executions2.2、Percent Executions2.3、Per User 一、吞吐量控制器(Throughput Controller)参数说明 允许用户控制后代元素的执行的次数。…...

方正书版命令详解
方正书版常用的排版符包括: 空格:表示文字之间的间距,不同字号的文字需要适当调整空格大小。 省略号:用于省略一段文字,通常用三个点表示(…)。 破折号:用于表示强调或者断句&…...
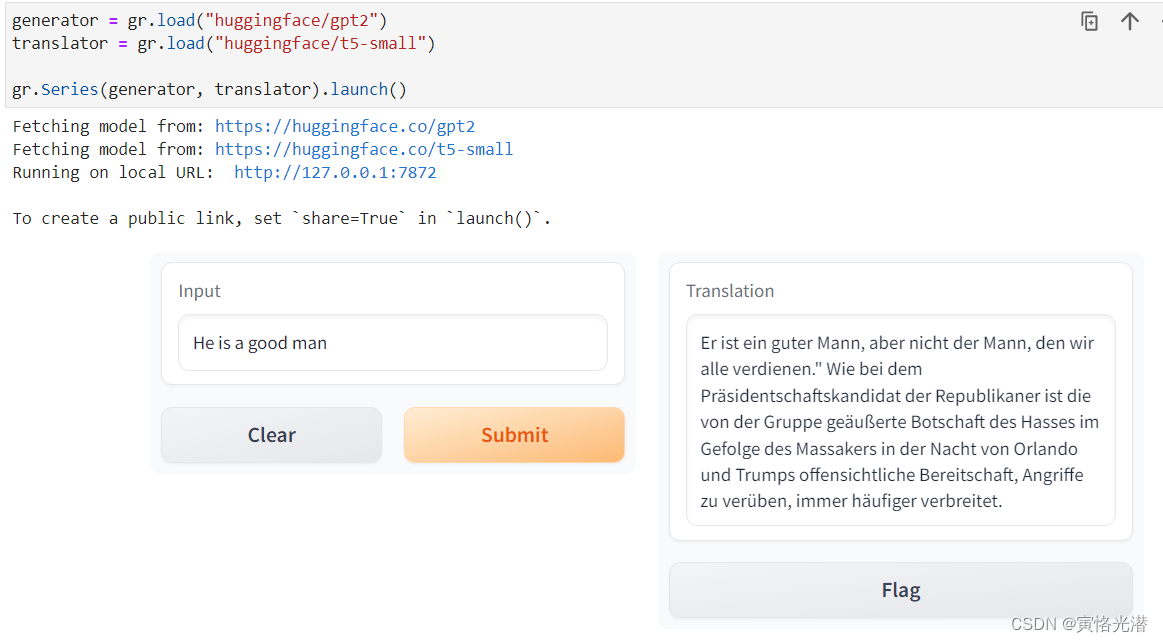
Gradio的web界面演示与交互机器学习模型,高级接口特征《6》
大多数模型都是黑盒,其内部逻辑对最终用户是隐藏的。为了鼓励透明度,我们通过简单地将Interface类中的interpretation关键字设置为default,使得向模型添加解释变得非常容易。这允许您的用户了解输入的哪些部分负责输出。 1、Interpret解释 …...
本地项目上传到Git(Gitee)仓库
一、步骤解答(详细图解步骤见第二大点) 1、打开我们的项目所在文件夹,我们发现是不存在.git文件 2、在你的项目文件夹外层【鼠标右击】弹出菜单,在【鼠标右击】弹出的菜单中,点击【Git Bash Here】,弹出运…...

Android 12.0屏蔽掉SystemUI的某些通知提示音
1.概述 在12.0的系统开发中,在系统SystemUI中会发一些通知的声音,但是同时也会在开机的时候,会有一些通知的声音,特别是不想要的一些通知的声音, 这些对于产品还是有一些影响的,所以为了产品体验,就需要屏蔽掉一些开机的通知的声音 2.屏蔽某些通知的提示音的核心代码 …...

测试计划模板二
XXX测试计划 文档作者: 编写日期: 项目经理: 批准日期: 文档模板修改纪录表 日期 修改人 修改内容描述...

华为OD机试真题B卷 Java 实现【分奖金】,附详细解题思路
一、题目描述 公司老板做了一笔大生意,想要给每位员工分配一些奖金,想通过游戏的方式来决定每个人分多少钱。按照员工的工号顺序,每个人随机抽取一个数字。按照工号的顺序往后排列,遇到第一个数字比自己数字大的,那么…...
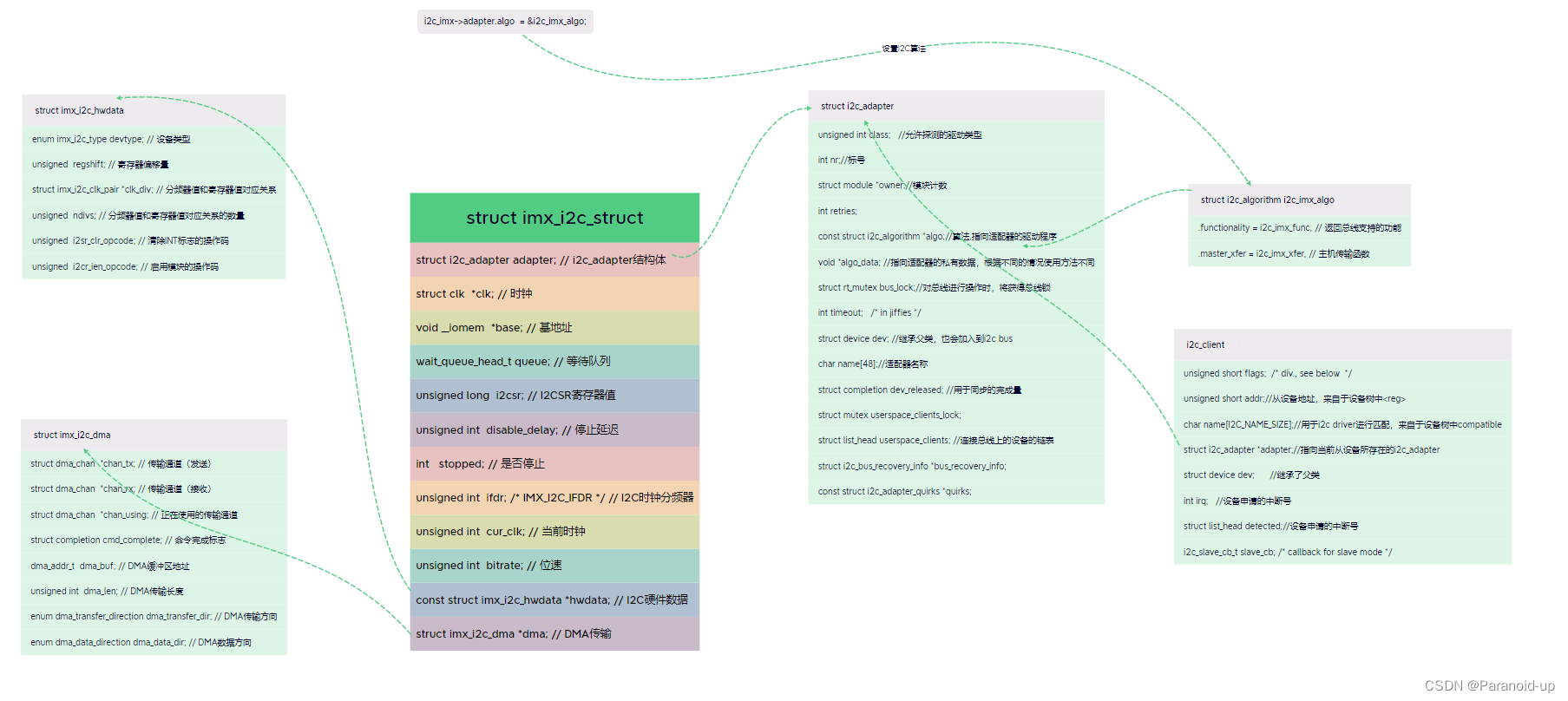
IMX6ULL平台I2C数据结构分析
IMX6ULL平台I2C数据结构分析 文章目录 IMX6ULL平台I2C数据结构分析i2c_clienti2c_adapterimx_i2c_structimx_i2c_hwdataimx_i2c_dma 在 i.MX 平台的 I2C 驱动中,存在多个相关的结构体,它们之间的联系和在内核中的作用如下: struct i2c_client…...
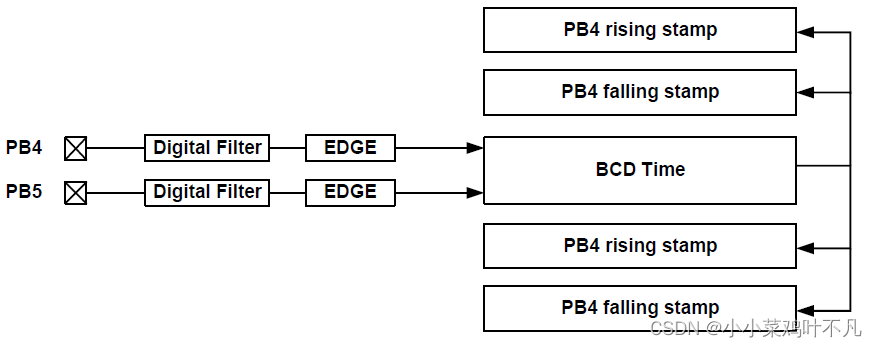
实时时钟 RTC(2)
RTC 使能与停止 RTC 上电后立即启动,不可关闭,软件应在32K 晶体振荡器完全起振后再设置当前时间;在晶体振荡器起振之前芯片使用内部环振计时,偏差较大。 RTC 时间设置 软件可以在任意时刻直接设置RTC 时间寄存器;由于…...
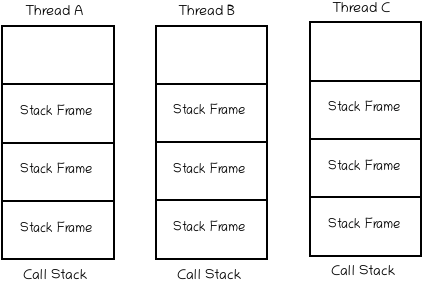
弄懂局部变量
成员变量和局部变量的区别 多个线程调用同一个对象的同一个方法时: 如果方法里无成员变量,那么不受任何影响 如果方法里有成员变量,只有读操作,不受影响 存在写操作,考虑多线程影响值 多线程调用…...
倾斜摄影三维模型数据的高程偏差修正的几何纠正技术方法探讨
倾斜摄影三维模型数据的高程偏差修正的几何纠正技术方法探讨 倾斜摄影是一种先进的数字摄影技术,可以生成高分辨率、高精度的三维模型数据。然而,在倾斜摄影中,由于相机的倾斜角度和地形的高程差异,可能会出现高程偏差问题。为了…...

怎么发表CCF期刊?CCF期刊有什么不同之处? - 易智编译EaseEditing
发表CCF期刊,可以参考一下步骤: 选择目标期刊: 首先选择一个适合自己的目标期刊,可以是CCF推荐的高水平期刊,也可以是其他被广泛认可的期刊。 撰写论文: 根据目标期刊的要求,撰写论文。确保论…...

feat:使用企业微信JS-SDK的onMenuShareAppMessage()实现点击转发自定义分享内容(TypeScript)
背景:企业微信应用使用企业微信JS-SDK的分享接口实现分享样式自定义 原生: 需要实现成: 企业微信JS-SDK 是企业微信面向网页开发者提供的 基于企业微信内 的网页开发工具包。 通过使用企业微信JS-SDK,网页开发者 可借助企业微信…...

Java键盘事件处理及监听机制解析
文章目录 概念KeyEventKeyListener代码演示总结 概念 Java事件处理采用了委派事件模型。在这个模型中,当事件发生时,产生事件的对象将事件信息传递给事件的监听者进行处理。在Java中,事件源是产生事件的对象,比如窗口、按钮等&am…...

Git详解——安装、使用、搭建、IDEA集成
Git 看目录,篇幅挺长,越往后面越重要 目录一、git是什么?二、为什么要使用Git?三、版本控制工具四、git下载安装以及环境配置五、git基本命令六、git项目搭建七、远程仓库怎么搞?git,gitlab,github,gitee区别八、ide…...

【JavaSE】Java基础语法(二十一):内部类
文章目录 1. 内部类的基本使用2. 成员内部类3. 局部内部类4. 匿名内部类5. 匿名内部类在开发中的使用(应用) 1. 内部类的基本使用 内部类概念 在一个类中定义一个类。举例:在一个类A的内部定义一个类B,类B就被称为内部类 内部类定…...

Ceph应用
//存储类型 块存储 一对一,只能被一个主机挂载使用,数据以块为单位进行存储,典型代表: 硬盘 文件存储 一对多,能被多个主机同时挂载使用,数据以文件的形式存储的(元数据和实际数据是分开存储的),并且有…...

Oxford online English-Chair a Meeting 05/29
Part1-Welcoming attendees and starting the meeting Getting people’s attention If I could have your attention, please. Could I have your attention, please? Good afternoon, everyone. -> Good afternoon, everyone, could I have your attention, please?…...
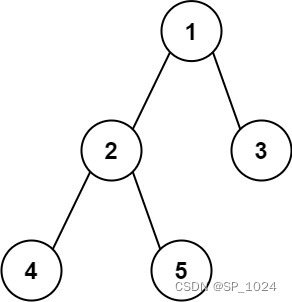
LeetCode: 二叉树的直径(java)
二叉树的直径 leetcode 543题。原题链接题目描述解题代码二叉树专题 leetcode 543题。原题链接 543题:二叉树的直径 题目描述 给你一棵二叉树的根节点,返回该树的 直径 。 二叉树的 直径 是指树中任意两个节点之间最长路径的 长度 。这条路径可能经过也…...

2026亲测:专业降AI率平台选这款就对了
2026 年降 AIGC 工具已从“基础语义改写”进化为多维度智能优化系统,核心评测指标涵盖 AI 生成痕迹识别精准度、专业领域术语匹配度、文本格式完整性、长篇内容逻辑一致性、降重效果稳定性以及高校检测平台兼容性。本次测评涵盖 8 款主流工具,测试场景覆…...
:为什么你的YOLO项目越用越废?对比TVA智能体四大核心差距)
TVA视觉智能体专栏(二):为什么你的YOLO项目越用越废?对比TVA智能体四大核心差距
摘要:常规YOLO模型只能完成目标识别,无推理、无决策、无迭代能力,面对光照波动、工件偏移、杂点干扰极易误漏检。本文从环境适配、缺陷推理、迭代能力、工程落地四个维度,精准对比传统深度学习与TVA智能体的本质差距,破…...

如何用NightX Client打造终极Minecraft 1.8.9体验?完整功能解析+新手教程 [特殊字符]
如何用NightX Client打造终极Minecraft 1.8.9体验?完整功能解析新手教程 🚀 【免费下载链接】NightX-Client Minecraft Forge 1.8.9 hacked client, Based on LiquidBounce 项目地址: https://gitcode.com/gh_mirrors/ni/NightX-Client NightX Cl…...

零基础玩转AI斗地主:DouZero_For_HappyDouDiZhu快速上手实战指南
零基础玩转AI斗地主:DouZero_For_HappyDouDiZhu快速上手实战指南 【免费下载链接】DouZero_For_HappyDouDiZhu 基于DouZero定制AI实战欢乐斗地主 项目地址: https://gitcode.com/gh_mirrors/do/DouZero_For_HappyDouDiZhu 想要在欢乐斗地主中体验AI智能辅助的…...

轻量神经网络在量子比特实时控制中的嵌入式部署实践
1. 项目概述:当机器学习遇见量子控制在量子计算这个前沿领域,我们每天都在与微观世界的“幽灵”打交道。一个量子比特的状态,就像地球仪上的一个点,可以用布洛赫球面上的经度和纬度来描述。要让这个点精确地旋转到我们指定的位置&…...
信道解码算法对比:OSD为何在短中长码中优于神经网络与Transformer解码器
1. 项目概述在通信系统的信道编码领域,前向纠错(FEC)技术是保障数据传输可靠性的核心。其基本原理是通过在发送端添加冗余信息,使接收端能够在存在噪声的信道中检测并纠正错误。随着机器学习技术的发展,基于神经网络的…...

终极鸣潮优化指南:3分钟解锁120FPS与专业抽卡分析
终极鸣潮优化指南:3分钟解锁120FPS与专业抽卡分析 【免费下载链接】WaveTools 🧰鸣潮工具箱 项目地址: https://gitcode.com/gh_mirrors/wa/WaveTools 你是否还在为《鸣潮》的60FPS帧率限制而烦恼?是否想科学分析自己的抽卡概率&#…...

3步精通League Akari:英雄联盟自动化辅助的终极配置方案
3步精通League Akari:英雄联盟自动化辅助的终极配置方案 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit League Akari是一款基于LC…...

Taotoken控制台用量看板提供的洞察与规划价值
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken控制台用量看板提供的洞察与规划价值 对于依赖大模型API进行开发的项目团队而言,成本与用量的不透明常常是管理…...

如何用3个步骤建立完全私有的点对点文件同步网络?
如何用3个步骤建立完全私有的点对点文件同步网络? 【免费下载链接】syncthing-android Wrapper of syncthing for Android. 项目地址: https://gitcode.com/gh_mirrors/sy/syncthing-android 你是否曾因云端服务的隐私隐患而犹豫不决?是否厌倦了每…...