MySQL 锁机制
1.概述
锁是计算机协调多个进程或线程并发访问某一种资源的机制。
在数据库中,除去计算机硬件资源(CPU、RAM、I/O等)的争用外,数据也是一种供许多用户共享的资源。如何保证并发访问数据的一致性、有效性是所有数据库必须解决的一个问题,锁冲突也是影响数据库并发访问性能的一个重要因素,因此锁对于数据库而言尤其重要,也更加复杂。
比如我们在淘宝抢购商品时,当两个客户同时抢购一个商品时,后台的数据库中必然用到事务和锁,通过对整个下单流程进行统一的事务交和数据库加锁机制,保证商品不会被超卖。
1.1 锁的分类
- 数据库操作类型分类(读/写)
- 读锁(共享锁):针对同一份数据,多个读操作可以同时进行而不会互相影响;
- 写锁(排他锁):当前操作没有完成前,会阻断其他的写锁和读锁;
- 对数据的操作粒度
- 表锁:对数据表上锁
- 行锁:对操作的数据行上锁
2.表锁(偏向读)
2.1.特点
偏向读操作,偏向 MYISAM 存储引擎,开销小,加锁快,无死锁,锁定粒度大,发生锁冲突的概率最高,并发最低
2.2.数据库锁的基本操作
- 手动添加表锁
lock table 表名1 read(write), 表名2 read(write), 其他; - 查看上锁的表
show open tabels; - 手动解锁
unlock tables;
2.3.示例
2.3.1.建立数据库
-- 创建数据库
CREATE DATABASE big_data;-- 使用数据库
use big_data;-- 创建数据表
create table mylock (id int not null primary key auto_increment,name varchar(20) default ''
) engine myisam;CREATE TABLE IF NOT EXISTS `book`(`bookid` INT(10) UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMENT,`card` INT (10) UNSIGNED NOT NULL
);-- 插入数据
insert into mylock(name) values('a');
insert into mylock(name) values('b');
insert into mylock(name) values('c');
insert into mylock(name) values('d');
insert into mylock(name) values('e');INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20)));
2.3.2.添加读锁
mylock 表添加读取锁,同时打开两个 session 窗口
session1窗口
-- # 1.为 mylock 表添加读锁
lock table mylock read;
-- > OK
-- > 时间: 0s-- # 2.查询 mylock 表
select * from mylock;
-- +----+------+
-- | id | name |
-- +----+------+
-- | 1 | a1 |
-- | 2 | b |
-- | 3 | c |
-- | 4 | d |
-- | 5 | e |
-- +----+------+
-- 5 rows in set (0.00 sec)-- # 3.更新 mylock 表
update mylock set name = 'a' where id = 1;
-- > 1099 - Table 'mylock' was locked with a READ lock and can't be updated
-- > 时间: 0.001s-- # 4.查询 book 表
select * from book;
-- > 1100 - Table 'book' was not locked with LOCK TABLES
-- > 时间: 0s-- # 5.更新 book 表
update book set card = 10 where bookid = 1;
-- > 1100 - Table 'book' was not locked with LOCK TABLES
-- > 时间: 0s-- # 6.释放锁
unlock table;
-- > OK
-- > 时间: 0s
session2窗口
-- # 1.查询 mylock 表
select * from mylock;
-- +----+------+
-- | id | name |
-- +----+------+
-- | 1 | a1 |
-- | 2 | b |
-- | 3 | c |
-- | 4 | d |
-- | 5 | e |
-- +----+------+
-- 5 rows in set (0.00 sec)-- # 2.查询 book 表
select * from book;
-- +--------+------+
-- | bookid | card |
-- +--------+------+
-- | 4 | 2 |
-- | 25 | 2 |
-- | 36 | 2 |
-- | 23 | 3 |
-- | 38 | 4 |
-- | 15 | 6 |
-- | 16 | 6 |
-- | 24 | 6 |
-- | 39 | 6 |
-- | 34 | 20 |
-- +--------+------+
-- 10 rows in set (0.00 sec)-- # 3.更新 book表
update book set card = 10 where bookid = 1;
-- > Affected rows: 1
-- > 时间: 0.003s-- # 4.更新 mylock 表
update mylock set name = 'a3' where id = 1;
-- 一直在更新等待中,阻塞掉了
由于session1 在 mylock 表加上读锁,导致队列阻塞,只有当session1 释放读锁时session2 才能对 mylock 表进行更新操作,因此更新操作等待时间很长。
加读锁后不同 session 对表操作总结
| 表操作 | 当前 session | 其他 session |
|---|---|---|
| 读取加了写锁的表 | YES | YES |
| 读取没有加写锁的表 | NO | YES |
| 更新/插入加了写锁的表 | NO | 阻塞等待 |
| 更新/插入没有加写锁的表 | NO | YES |
| 删除加了写锁的表 | NO | 阻塞等待 |
| 删除没有加写锁的表 | NO | YES |
2.2.3 添加写锁
mylock 表添加写入锁,同时打开两个 session 窗口
session1窗口
-- # 1.给 mylock 表添加写锁
lock table mylock write;
-- > OK
-- > 时间: 0s-- # 2.查询 mylock 表
select * from mylock;
-- +----+------+
-- | id | name |
-- +----+------+
-- | 1 | a3 |
-- | 2 | b1 |
-- | 3 | c3 |
-- | 4 | d |
-- | 5 | e |
-- +----+------+
-- 5 rows in set (12.18 sec)-- # 3.查询 book 表
select * from book;
-- > 1100 - Table 'book' was not locked with LOCK TABLES
-- > 时间: 0s-- # 4.更新 mylock 表
update mylock set name = 'b1' where id = 2;
-- > Affected rows: 1
-- > 时间: 0s-- # 5.更新后查询 mylock 表
select * from mylock;-- # 6.查询 book 表
select * from book;
-- > 1100 - Table 'book' was not locked with LOCK TABLES
-- > 时间: 0s-- # 7.更新 book 表
update book set card = 22 where bookid = 1;
> 1100 - Table 'book' was not locked with LOCK TABLES
> 时间: 0s-- # 8.释放写锁
unlock table;
session2
-- 1.查询 mylock 表
select * from mylock;
-- 阻塞等待-- 2.查询 book 表
select * from book;
-- +--------+------+
-- | bookid | card |
-- +--------+------+
-- | 4 | 2 |
-- | 25 | 2 |
-- | 36 | 2 |
-- | 23 | 3 |
-- | 38 | 4 |
-- | 15 | 6 |
-- | 16 | 6 |
-- | 24 | 6 |
-- | 39 | 6 |
-- | 34 | 20 |
-- +--------+------+
-- 10 rows in set (0.00 sec)-- 3.更新 mylock 表
update mylock set name = 'c3' where id = 3;
-- 阻塞等待-- 4.更新 book 表
update book set card = 2222 where bookid = 4;
-- > Affected rows: 1
-- > 时间: 0.001s
由于session1 在 mylock 表加上写锁,导致队列阻塞,只有当session1 释放读锁时session2 才能对 mylock 表进行查询、更新、插入、删除操作,阻塞等待时间很长。
| 表操作 | 当前 session | 其他 session |
|---|---|---|
| 读取加了写锁的表 | YES | 阻塞等待 |
| 读取没有加写锁的表 | NO | YES |
| 更新/插入加了写锁的表 | YES | 阻塞等待 |
| 更新/插入没有加写锁的表 | NO | YES |
| 删除加了写锁的表 | YES | 阻塞等待 |
| 删除没有加写锁的表 | NO | YES |
2.3.4.总结
MYISAM 在执行查询语句 SELECT 前,会自动给涉及到的所有表加读锁;在执行增删改操作前,会自动给涉及到的所有表加写锁。
MySQL 的表级锁有两种模式:
- 表共享读锁(Table Read Lock)
- 表独占写锁(Table Write Lock)
对使用 MyISAM 文件存储引擎的表进行操作会出现以下情况:
- 对 MyISAM 表的读操作(加读锁)不会阻塞其他进程对同一表的读请求,但会阻塞同一表的写请求。当读锁释放后才会执行其他进程的写操作;
- 对 MyISAM 表的写操作(加写锁)会阻塞其他进程对同一表的读和写操作,只有写锁释放后,才能执行其他进程的读写操作;
- 简而言之,就是读锁会阻塞写操作,但是不会阻塞读操作。而写锁则会把读操作和写操作都阻塞;
2.4.表锁分析
查看数据库中那些表加锁
show open tables;
分析表锁定,使用命令:
show status like 'table%';
参数说明:
- Table_locks_immediate:产生表级锁定的次数,表示可以立即获取锁查询的次数,每立即获取锁值加 1;
- Table_locks_waited:出现表级锁定争用而发生等待的次数(不能立即获取锁的次数,每等待一次锁值加 1)数值高说明存在严重的表级锁争用情况;
MyISAM 的读写锁调度是写优先,因此不适合做写为主表的引擎。因为加锁后,其他线程不能做任何操作,大量的更新会使得查询很难获得锁,进而造成查询阻塞。
3.行锁(偏向写)
3.1.特点
偏向 **InnoDB **存储引擎,开销大,加锁慢;会出现死锁问题,锁的粒度小,发生锁冲突的概率最低,并发度是最高的。
InnoDB 引擎和 MyISAM 引擎最大的不同:InnoDB 支持事务(transaction)和行级锁。
3.2.事务相关
3.2.1.事务及其 ACID 属性
事务是由一组 **SQL **语句组成的逻辑处理单元,事物具有以下四个属性,通常简称为事务的 ACID 属性
原子性(Atomicity):事务是一个原子操作,对数据的修改,要么全都执行,要么全都不执行;
一致性(Consistent):在事务开始和完成时,数据必须保持一致状态。这也就意味着所有相关的数据规则都必须应用于事务的修改,以保持数据的完整性;事务结束时,所有内部数据结构(如:B 树索引或双向链表)也都必须是正确的;
隔离性(Isolation):数据库系统提供一定的隔离机制,保证事务不受外部并发操作影响的**“独立环境”**执行。这意味着事务处理的中间状态对外部是不可见的,反之亦然;
持久性(Durable):事务完成后,对于数据的修改是永久性的,即使出现系统故障也能够保持;
3.2.2.并发带来的事务问题
更新丢失(Lost Update)
当两个或多个事务选择同一行,并基于最初选定的值更行当前行是,由于每个事务不知道其他事务的存在,最后的更新覆盖了由其他事务所作的更新,产生丢失更新的问题。
| 时间片 | 事务 A | 事务 B |
|---|---|---|
| T1 | 开始事务 | |
| T2 | 开始事务 | |
| T3 | 查询账户余额 300 元 | |
| T4 | 查询账户余额 300 元 | |
| T5 | 账户充值 200 元,余额 500 元 | |
| T6 | 提交事务 | |
| T7 | 消费 100 元,余额 200 元 | |
| T8 | 撤销事务 | |
| T9 | 余额 300 元 |
事务 A 最后提交事务,导致事务 B 的事务提交被覆盖,造成事务 B 更新的数据丢失
脏读(Dirty Reads)
事务 A 正在对一条记录做修改,这个事务完成提交前,这条记录的数据就处于待定状态(可能提交也可能回滚);此时,事务 B 也来读取这条待定状态的数据,并对数据做进一步的处理,就会产生数据依赖关系,这种现象叫做**“脏读”**。
简而言之,就是事务 B 读取到了事务 A 已修改但没有提交的数据,还在这个数据的基础上做了操作。此时事务 A 回滚,事务 B 读取到的数据无效,不符合一致性要求。
不可重复读(Non-Repeatable Reads)
一个事务先后读取同一条记录,但在事务的两次读取之间该数据被其他事务所修改或删除,两次读取到的数据不一致或不能读取,这种现象叫做**“不可重复读”**。
简而言之,就是事务 A 读取到了事务 B 已经提交的修改数据,不符合隔离性。
幻读(Phantom Reads)
一个事务按相同的查询条件重新读取以前检索过的数据,却发现其他事务插入了满足其查询条件的新数据,这种现象称为**“幻读”**
简而言之,事务A读取到了事务B提交的新增数据,不符合隔离性。
幻读和脏读比较:
- 脏读是事务B里面修改了数据;
- 幻读是事务B里面新增了数据;
幻读和不可重复读比较:
- 不可重复读的重点是修改:同样的条件,两次读发现值不一样;
- 幻读的重点在于新增或者删除:同样的条件,两次读发现得到的记录数不一样;
3.2.3.事务的隔离级别
-
DEFAULT:
默认级别,由 DBA 默认的设置来决定隔离级别,归属下列某一种:
-
READ_UNCOMMITTED:
就是一个事务可以读取另一个未提交事务的数据。
会出现脏读、不可重复读、幻读(隔离级别最低,但并发性高)
最低级别,只能保证不读取物理上损坏的数据;
-
READ_COMMITTED:
就是一个事务要等另一个事务提交后才能读取数据,解决脏读问题。
会出现不可重复读、幻读问题(锁定正在读取的行,适用于大多数系统,Oracle默认级别)
语句级别;
-
REPEATABLE_READ:
就是在开始读取数据(事务开启)时,不再允许修改操作,解决不可重复读问题。
会出现幻读问题(锁定所读的所有行,MYSQL默认级别)
事务级别;
-
SERALZABLE:
是最高的事务隔离级别,在该级别下,事务串行化顺序执行,可以避免脏读、不可重复读与幻读。
但是这种事务隔离级别效率低下,比较耗数据库性能,一般不使用。(锁整表)
最高级别,事务级别;
事务隔离级别由上到下依次提升,隔离级别越高,越能保证数据的完整性和一致性。但对数据库性能的消耗依次增加,并发执行效率依次下降。
事务隔离实质上就是使得事务在一定程度上**“串行”,实际上是与并发相矛盾的。同时,不同的应用对读一致性和事务的隔离级别是不同的,有些应用可能对“不可重复读”和“幻读”**不敏感,更关心数据的并发处理能力。
查看当前数据库的事务隔离级别:
show variables like 'tx_isolation';大多数的数据库默认隔离级别为 Read Commited,比如 SqlServer、Oracle
少数数据库默认隔离级别为:Repeatable Read 比如:MySQL InnoDB
| Dirty reads | non-repeatable reads | phantom reads | |
|---|---|---|---|
| READ_UNCOMMITTED | Y | Y | Y |
| READ_COMMITTED | N | Y | Y |
| REPEATABLE_READ | N | N | Y |
| SERALZABLE | N | N | N |
3.3.示例
-- 创建数据库
-- CREATE DATABASE big_data;-- 使用数据库
-- use big_data;-- 创建数据表
CREATE TABLE test_innodb_lock (a INT(11),b VARCHAR(16))ENGINE=INNODB;
INSERT INTO test_innodb_lock VALUES(1,'b2');
INSERT INTO test_innodb_lock VALUES(3,'3');
INSERT INTO test_innodb_lock VALUES(4, '4000');
INSERT INTO test_innodb_lock VALUES(5,'5000');
INSERT INTO test_innodb_lock VALUES(6, '6000');
INSERT INTO test_innodb_lock VALUES(7,'7000');
INSERT INTO test_innodb_lock VALUES(8, '8000');
INSERT INTO test_innodb_lock VALUES(9,'9000');
INSERT INTO test_innodb_lock VALUES(1,'b1');-- 创建索引
CREATE INDEX test_innodb_a_ind ON test_innodb_lock(a);
CREATE INDEX test_innodb_lock_b_ind ON test_innodb_lock(b);-- 关闭自动提交
SET autocommit=0;-- 查询数据
select * from test_innodb_lock;
-- +------+------+
-- | a | b |
-- +------+------+
-- | 1 | b2 |
-- | 3 | 3 |
-- | 4 | 4000 |
-- | 5 | 5000 |
-- | 6 | 6000 |
-- | 7 | 7000 |
-- | 8 | 8000 |
-- | 9 | 9000 |
-- | 1 | b1 |
-- +------+------+
-- 9 rows in set (0.00 sec)
3.3.1.行锁示例
session 1 窗口
-- 1.1.更新数据
update test_innodb_lock set b = 'b3' where a = 3;
-- > Affected rows: 1
-- > 时间: 0s-- 1.2.查询数据
select * from test_innodb_lock;
-- +------+------+
-- | a | b |
-- +------+------+
-- | 1 | b2 |
-- | 3 | b3 |
-- | 4 | 4000 |
-- | 5 | 5000 |
-- | 6 | 6000 |
-- | 7 | 7000 |
-- | 8 | 8000 |
-- | 9 | 9000 |
-- | 1 | b1 |
-- +------+------+
-- 9 rows in set (0.00 sec)-- 1.3.提交查询
commit;
-- > OK
-- > 时间: 0.003s-- 2.1.更新行数据
update test_innodb_lock set b = '3000' where a = 4;
-- > Affected rows: 1
-- > 时间: 0s-- 2.2.更新后查询
select * from test_innodb_lock;
-- +------+------+
-- | a | b |
-- +------+------+
-- | 1 | b2 |
-- | 3 | b3 |
-- | 4 | 3000 |
-- | 5 | 5000 |
-- | 6 | 6000 |
-- | 7 | 7000 |
-- | 8 | 8000 |
-- | 9 | 9000 |
-- | 1 | b1 |
-- +------+------+
-- 9 rows in set (0.00 sec)-- 2.3.更新后提交
commit;
-- > OK
-- > 时间: 0.001s-- 2.4.提交后查询
select * from test_innodb_lock;
-- +------+------+
-- | a | b |
-- +------+------+
-- | 1 | b2 |
-- | 3 | b3 |
-- | 4 | 4000 |
-- | 5 | 5000 |
-- | 6 | 6000 |
-- | 7 | 7000 |
-- | 8 | 8000 |
-- | 9 | 9000 |
-- | 1 | b1 |
-- +------+------+
-- 9 rows in set (0.00 sec)-- 2.5.session 2提交后提交
commit;
-- > OK
-- > 时间: 0.001s-- 2.6.提交后查询
select * from test_innodb_lock;
-- +------+------+
-- | a | b |
-- +------+------+
-- | 1 | b2 |
-- | 3 | b3 |
-- | 4 | b4 |
-- | 5 | 5000 |
-- | 6 | 6000 |
-- | 7 | 7000 |
-- | 8 | 8000 |
-- | 9 | 9000 |
-- | 1 | b1 |
-- +------+------+
-- 9 rows in set (0.00 sec)-- 3.1.更新a=5
update test_innodb_lock set b = '5005' where a = 5;
-- > Affected rows: 1
-- > 时间: 0s-- 3.2.提交事务
commit;
-- > OK
-- > 时间: 0.001s-- 3.3.提交后查询
select * from test_innodb_lock;
-- +------+------+
-- | a | b |
-- +------+------+
-- | 1 | b2 |
-- | 3 | b3 |
-- | 4 | b4 |
-- | 5 | 5005 |
-- | 6 | 6000 |
-- | 7 | 7000 |
-- | 8 | 8000 |
-- | 9 | 9009 |
-- | 1 | b1 |
-- +------+------+
-- 9 rows in set (0.00 sec)
session 2 窗口
-- 1.1.session 1 未提交 session 2 查询
select * from test_innodb_lock;
-- +------+------+
-- | a | b |
-- +------+------+
-- | 1 | b2 |
-- | 3 | 3 |
-- | 4 | 4000 |
-- | 5 | 5000 |
-- | 6 | 6000 |
-- | 7 | 7000 |
-- | 8 | 8000 |
-- | 9 | 9000 |
-- | 1 | b1 |
-- +------+------+
-- 9 rows in set (0.00 sec)-- 1.2.session 1提交后session 2提交
commit;
-- > OK
-- > 时间: 0.001s-- 1.3.session 1和 session 2都提交后查询
select * from test_innodb_lock;
-- +------+------+
-- | a | b |
-- +------+------+
-- | 1 | b2 |
-- | 3 | b3 |
-- | 4 | 4000 |
-- | 5 | 5000 |
-- | 6 | 6000 |
-- | 7 | 7000 |
-- | 8 | 8000 |
-- | 9 | 9000 |
-- | 1 | b1 |
-- +------+------+
-- 9 rows in set (0.00 sec)-- 2.1.更新行数据,session 1尚未提交,此时会出现阻塞当session 1提交后session 2才能更新
update test_innodb_lock set b = 'b4' where a = 4;
-- > Affected rows: 1
-- > 时间: 0s-- 2.2.session 1提交事务后提交
commit;
-- > OK
-- > 时间: 0.001s-- 2.3.查询数据
select * from test_innodb_lock;
-- +------+------+
-- | a | b |
-- +------+------+
-- | 1 | b2 |
-- | 3 | b3 |
-- | 4 | b4 |
-- | 5 | 5000 |
-- | 6 | 6000 |
-- | 7 | 7000 |
-- | 8 | 8000 |
-- | 9 | 9000 |
-- | 1 | b1 |
-- +------+------+
-- 9 rows in set (0.00 sec)-- 3.1.更新a=9
update test_innodb_lock set b = '9009' where a = 9;
-- > Affected rows: 1
-- > 时间: 0s-- 3.2.提交事务
commit;
-- > OK
-- > 时间: 0.001s-- 3.3.提交后查询
select * from test_innodb_lock;
-- +------+------+
-- | a | b |
-- +------+------+
-- | 1 | b2 |
-- | 3 | b3 |
-- | 4 | b4 |
-- | 5 | 5005 |
-- | 6 | 6000 |
-- | 7 | 7000 |
-- | 8 | 8000 |
-- | 9 | 9009 |
-- | 1 | b1 |
-- +------+------+
-- 9 rows in set (0.00 sec)
3.3.2.索引失效行锁升级为表锁
session 1 窗口
-- 1.1 查询当前数据
select * from test_innodb_lock;
-- +------+-------+
-- | a | b |
-- +------+-------+
-- | 1 | 10010 |
-- | 3 | b3 |
-- | 4 | b4 |
-- | 5 | 5005 |
-- | 6 | 6000 |
-- | 7 | 7007 |
-- | 8 | 8008 |
-- | 9 | 10010 |
-- | 1 | 10010 |
-- +------+-------+
-- 9 rows in set (0.00 sec)-- 1.2 更新b=10010 所在行数据
update test_innodb_lock set a=20 where b=10010;
-- Query OK, 3 rows affected (0.00 sec)
-- Rows matched: 3 Changed: 3 Warnings: 0-- 1.3 提交事务
commit;
-- Query OK, 0 rows affected (0.02 sec)-- 1.4 提交后查询
select * from test_innodb_lock;
-- +------+-------+
-- | a | b |
-- +------+-------+
-- | 20 | 10010 |
-- | 3 | 3000 |
-- | 4 | b4 |
-- | 5 | 5005 |
-- | 6 | 6000 |
-- | 7 | 7007 |
-- | 8 | 8008 |
-- | 20 | 10010 |
-- | 20 | 10010 |
-- +------+-------+
-- 9 rows in set (0.00 sec)
session 2 窗口
-- 1.1 查询当前数据
select * from test_innodb_lock;
-- +------+-------+
-- | a | b |
-- +------+-------+
-- | 1 | 10010 |
-- | 3 | b3 |
-- | 4 | b4 |
-- | 5 | 5005 |
-- | 6 | 6000 |
-- | 7 | 7007 |
-- | 8 | 8008 |
-- | 9 | 10010 |
-- | 1 | 10010 |
-- +------+-------+
-- 9 rows in set (0.00 sec)-- 1.2 session 1更新后未提交,由于session 1索引失效导致行锁失效变成表锁,session 2更新不同行时被阻塞
update test_innodb_lock set b='3000' where a=3;
-- Query OK, 1 row affected (9.93 sec)
-- Rows matched: 1 Changed: 1 Warnings: 0-- session 1提交后提交
commit;
-- Query OK, 0 rows affected (0.01 sec)-- 提交后查询
select * from test_innodb_lock;
-- +------+-------+
-- | a | b |
-- +------+-------+
-- | 20 | 10010 |
-- | 3 | 3000 |
-- | 4 | b4 |
-- | 5 | 5005 |
-- | 6 | 6000 |
-- | 7 | 7007 |
-- | 8 | 8008 |
-- | 20 | 10010 |
-- | 20 | 10010 |
-- +------+-------+
-- 9 rows in set (0.00 sec)
行锁示例总结:
- 当前session 更新数据后不提交,其他session 不能看到更新后的数据;
- 当前session 更新一行数据未提交,其他 session 更新同一行数据时会阻塞;
- 当前 session 和其他 session 更新不同的数据行时,不会发生阻塞;
- 索引失效会导致行锁变成表锁;
3.3.3.间隙锁
当我们用范围查询而不是相等条件检索数据,并请求共享锁或排他锁时,InnoDB 会给符合条件的已有数据的索引项加锁;对于键值在条件范围内但并不存在的记录,叫做**“间隙(GAP)”,InnoDB 也会对“间隙”加锁,这种锁机制就叫做"间隙锁(Next-Key 锁)"**。
间隙锁的危害:
Query 执行过程中通过范围查找的话,会锁住整个范围内所有的索引键值,即使这个值不存在。
间隙锁的一个致命弱点,就是当锁定一个范围值后,即使某些不存在的键值也会被锁定,会造成在锁定的时候无法插入锁定键值范围内的任何数据。在某些场景下可能会对性能造成很大影响。
session 1窗口
-- 1.1 更新 1 < a < 6 的行 b 为 test
update test_innodb_lock set b='test' where a > 1 and a < 6;
-- Query OK, 3 rows affected (0.00 sec)
-- Rows matched: 3 Changed: 3 Warnings: 0-- 1.2 提交事务
commit;
-- Query OK, 0 rows affected (0.00 sec)-- 1.3 提交后查询
select * from test_innodb_lock;
-- +------+------+
-- | a | b |
-- +------+------+
-- | 1 | b2 |
-- | 3 | test |
-- | 4 | test |
-- | 5 | test |
-- | 6 | 6000 |
-- | 7 | 7000 |
-- | 8 | 8000 |
-- | 9 | 9000 |
-- | 1 | b1 |
-- +------+------+
-- 9 rows in set (0.00 sec)-- 2.1 session 2提交后提交
commit;
-- Query OK, 0 rows affected (0.00 sec)-- 2.2 提交后查询
select * from test_innodb_lock;
-- +------+------+
-- | a | b |
-- +------+------+
-- | 1 | b2 |
-- | 3 | test |
-- | 4 | test |
-- | 5 | test |
-- | 6 | 6000 |
-- | 7 | 7000 |
-- | 8 | 8000 |
-- | 9 | 9000 |
-- | 1 | b1 |
-- | 2 | 2000 |
-- +------+------+
-- 10 rows in set (0.00 sec)-- 3.锁定一行
-- 3.1 打上起始点
begin;
-- Query OK, 0 rows affected (0.00 sec)-- 3.2 查询锁定
select * from test_innodb_lock where a=8 for update;
-- +------+------+
-- | a | b |
-- +------+------+
-- | 8 | 8000 |
-- +------+------+
-- 1 row in set (0.00 sec)-- 3.3 提交事务
commit;
-- Query OK, 0 rows affected (0.00 sec)-- 3.4 session 2提交后提交
commit;
-- Query OK, 0 rows affected (0.00 sec)-- 3.5 提交后查询
select * from test_innodb_lock;
-- +------+------+
-- | a | b |
-- +------+------+
-- | 1 | b2 |
-- | 3 | test |
-- | 4 | test |
-- | 5 | test |
-- | 6 | 6000 |
-- | 7 | 7000 |
-- | 8 | xxxx |
-- | 9 | 9000 |
-- | 1 | b1 |
-- | 2 | 2000 |
-- +------+------+
-- 10 rows in set (0.00 sec)
session 2窗口
-- 1.1 session1 更新范围数据,产生间隙锁造成阻塞,session1 提交后执行
insert into test_innodb_lock values(2,'2000');
-- Query OK, 1 row affected (7.61 sec)-- 1.2 session 1提交后提交
commit;
-- Query OK, 0 rows affected (0.01 sec)-- 1.3 提交后查询
select * from test_innodb_lock;
-- +------+------+
-- | a | b |
-- +------+------+
-- | 1 | b2 |
-- | 3 | test |
-- | 4 | test |
-- | 5 | test |
-- | 6 | 6000 |
-- | 7 | 7000 |
-- | 8 | 8000 |
-- | 9 | 9000 |
-- | 1 | b1 |
-- | 2 | 2000 |
-- +------+------+
-- 10 rows in set (0.00 sec)-- 3.锁定一行
-- 3.1 更新一行,由于session 1查询时锁定行,导致执行阻塞。session 1提交后才能执行
update test_innodb_lock set b='xxxx' where a=8;
-- Query OK, 1 row affected (7.90 sec)
-- Rows matched: 1 Changed: 1 Warnings: 0-- 3.2 提交事务
commit;
-- Query OK, 0 rows affected (0.00 sec)-- 3.3 提交后查询
select * from test_innodb_lock;
-- +------+------+
-- | a | b |
-- +------+------+
-- | 1 | b2 |
-- | 3 | test |
-- | 4 | test |
-- | 5 | test |
-- | 6 | 6000 |
-- | 7 | 7000 |
-- | 8 | xxxx |
-- | 9 | 9000 |
-- | 1 | b1 |
-- | 2 | 2000 |
-- +------+------+
-- 10 rows in set (0.00 sec)
面试问题:如何锁定行?
select xxxx… for update 锁定某一行后,其他的操作会被阻塞,直到锁定行的会话提交。
3.3.4 总结
**InnoDB **存储引擎由于实现了行级锁定,虽然在锁定机制实现方面所带来的性能损耗比表级锁更多,但是在整体并发处理能力方面要远优于 **MyISAM **的表级锁定的。当系统并发量比较高的时候,InnoDB 的整体性能和 **MyISAM **相比会有比较明显的优势。
**InnoDB **的行级锁同样也存在问题,当我们不当使用时,可能会使 **InnoDB **的整体性能表现比 MyISAM 更差。
3.4.行锁分析
通过检查 **InnoDB_row_lock **状态变量来分析系统上的行锁争夺情况
查看命令 ** show status like ‘%innodb_row_lock%’**
show status like 'innodb_row_lock%';-- +-------------------------------+-------+
-- | Variable_name | Value |
-- +-------------------------------+-------+
-- | Innodb_row_lock_current_waits | 0 |
-- | Innodb_row_lock_time | 91944 |
-- | Innodb_row_lock_time_avg | 18388 |
-- | Innodb_row_lock_time_max | 51296 |
-- | Innodb_row_lock_waits | 5 |
-- +-------------------------------+-------+
-- 5 rows in set (0.00 sec)
状态变量说明:
Innodb_row_lock_current_waits:当前正在等待锁定的数量;Innodb_row_lock_time:从系统启动到现在锁定总时间;
Innodb_row_lock_time_avg:每次平均等待时间;
Innodb_row_lock_time_max:从系统启动到现在等待最长的一次所花的时间;
Innodb_row_lock_waits:系统启动后到现在总共等待的次数;
五个状态变量中比较重要的:
Innodb_row_lock_time_avg:每次平均等待时间;
Innodb_row_lock_waits:系统启动后到现在总共等待的次数;
Innodb_row_lock_time:从系统启动到现在锁定总时间;
尤其 是当前等待次数很高,而且每次等待时长也很长的时候,需要分析系统中出现多次等待的原因,并根据分析结果指定优化计划。
3.5.优化建议
- 尽可能让所有数据检索都通过索引完成,避免无索引行锁升级为表锁;
- 合理设计索引,尽量缩小锁的范围;
- 尽可能减少检索条件,避免间隙锁;
- 尽量控制事务大小,减少锁定资源量和时间长度;
- 尽可能使用低级别的事务隔离;
4.页锁
页级锁是MySQL中锁定粒度介于行级锁和表级锁中间的一种锁。表级锁速度快,但冲突多,行级冲突少,但速度慢。所以取了折衷的页级,一次锁定相邻的一组记录。BDB支持页级锁。
相关文章:

MySQL 锁机制
1.概述 锁是计算机协调多个进程或线程并发访问某一种资源的机制。 在数据库中,除去计算机硬件资源(CPU、RAM、I/O等)的争用外,数据也是一种供许多用户共享的资源。如何保证并发访问数据的一致性、有效性是所有数据库必须解决的一…...

HACKER KID: 1.0.1实战演练
文章目录 HACKER KID: 1.0.1实战演练一、前期准备1、相关信息 二、信息收集1、端口扫描2、访问网站3、扫描目录4、查看源码5、请求参数6、burpsuite批量请求7、编辑hosts文件8、DNS区域传输9、编辑hosts10、访问网站11、注册账号12、burpsuite抓包13、XML注入14、解密15、登录网…...

Android车载学习笔记1——车载整体系统简介
一、汽车操作系统 汽车操作系统包括安全车载操作系统、智能驾驶操作系统和智能座舱操作系统。 1. 安全车载操作系统 安全车载操作系统主要面向经典车辆控制领域,如动力系统、底盘系统和车身系统等,该类操作系统对实时性和安全性要求极高,生态…...
Apache Doris
Apache Doris教程 1.Doris 简介 1.1 Doris 概述 Apache Doris 由百度大数据部研发(之前叫百度 Palo,2018 年贡献到 Apache 社区后, 更名为 Doris ),在百度内部,有超过 200 个产品线在使用,…...

GB28181 对接海康平台,解决音视频卡顿问题
GB28181 对接海康平台,解决音视频卡顿问题 一、概述二、问题分析1、设备对比分析2、抓包对比分析3、验证分析结果三、总结四、讨论一、概述 设备使用GB28181协议对接海康平台时,发现音频和视频存在卡顿现象,不是一直卡顿,有时候卡有时候不卡,但是卡顿的时候音视频一起卡顿…...

Linux系统编程面试题
1. 什么是系统调用?它与普通函数调用有什么不同? 系统调用和普通函数调用的区别在于它们执行的上下文和权限不同。系统调用是操作系统内核提供的一组接口,允许用户程序请求操作系统执行特权操作,例如打开或关闭文件、创建新进程等…...
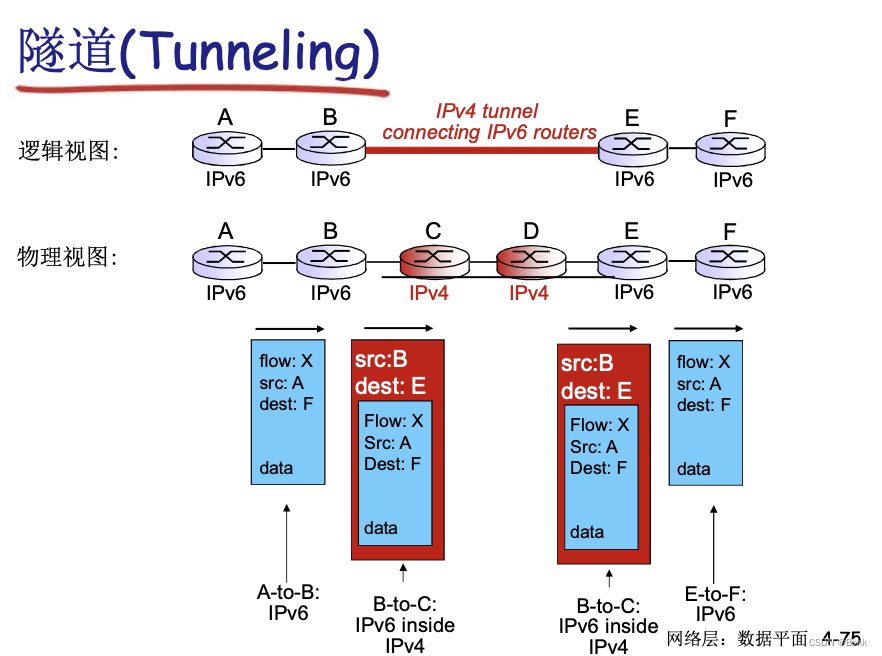
计算机网络 - 网络层的数据平面
Overview 首先Network Layer负责的是host to host的传输, 然后可以分为两个平面, 控制平面以及数据平面. 数据平面: 负责forward datagrams from input to output links 决定路由器从input到output 转发功能: 基于目标地址 转发表 SDN方式基于多个字段流表 控制平面: 调…...
《Spring Guides系列学习》guide41 - guide45
要想全面快速学习Spring的内容,最好的方法肯定是先去Spring官网去查阅文档,在Spring官网中找到了适合新手了解的官网Guides,一共68篇,打算全部过一遍,能尽量全面的了解Spring框架的每个特性和功能。 接着上篇看过的gu…...
数据库基础——1.数据库概述
从这篇文章我们开始学习数据库的相关知识 目录 1.为什么要使用数据库 2.数据库与数据库管理系统 2.1相关概念 2.2数据库与数据库管理系统的关系 编辑2.3常见的数据库管理系统 2.4常见的数据库介绍 3.MySQL介绍 3.1概述 3.2关于MySQL8.0 3.3 Oracle vs MySQL 4.RD…...

2023 光亚展|乐鑫将携 AI、Wi-Fi 6、私有云和 Matter 方案精彩亮相
2023 广州国际照明展览会(光亚展)将于 6 月 9 至 12 日在广州琶洲展馆启幕。本届展会以“光未来”为主题,畅想未来生活方式的无限可能。乐鑫科技 (688018.SH) 将在 B 区 9.2 号厅 D55 展位,带来具有前瞻性的智能照明解决方案和实体…...

用反射设计通用的实例化对象方案
需求 对象的相关信息存储在javabean.properties文件中,通过读取properties文件中的信息,实例化对象,要求程序不能硬编码,即程序可以通用,针对不同的对象,都可以实例化。仅需修改配置文件,不需要…...
破坏单例模式--存在的问题---问题的解决
目录 破坏单例模式--存在的问题---问题的解决 问题演示 破坏单例模式: 序列化 反射 序列化反序列化: 代码: 运行结果: 反射 代码: 运行结果: 问题的解决 序列化、反序列方式破坏单例模式的解…...
SpringCloud微服务踩坑系列-java.lang.IllegalStateException
异常如下: 2023-05-24 08:47:10.764 ERROR 118400 --- [nio-8084-exec-1] o.a.c.c.C.[.[.[/].[dispatcherServlet] : Servlet.service() for servlet [dispatcherServlet] in context with path [] threw exception [Request processing failed; nested exceptio…...
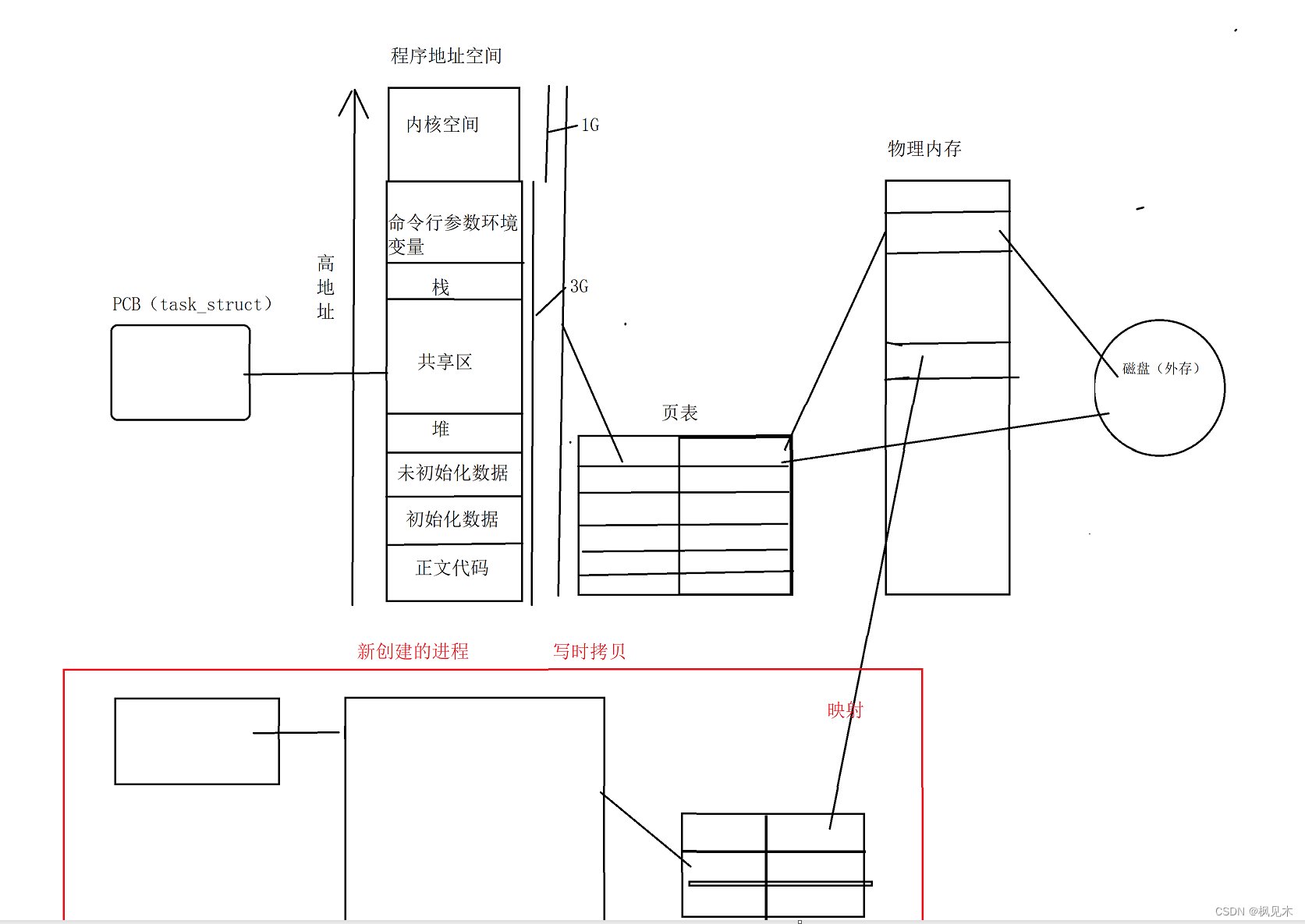
Linux-地址空间
文章目录 问题引入操作系统宏观认识操作系统与进程程序地址空间进程地址空间问题解释 问题引入 在Linux操作系统中、vim编译器下,出现了变量同地址但不同值的现象。 下面以解释该现象产生的原因为主线,在过程中学习Linux操作系统的知识。 运行代码展示…...

【EKS】基于Amazon EKS搭建kubernetes集群
文章目录 前言 | 亚马逊云科技 re:Invent前沿资讯一、介绍篇🎨什么是AWS 云计算什么是Amazon EKS 二、部署篇🔨1、创建集群VPC2、创建集群子网3、创建IGW网关4、创建路由表与子网绑定5、EKS集群创建6、创建kubeconfig配置文件7、添加计算节点组8、查看EK…...
Tomcat安装与启动和配置
目录 Tomcat 简介 Tomcat 安装 Tomcat 启动和配置 文件夹作用 启动,关闭Tomcat; 常见问题 配置 环境变量 IDEA中配置Tomcat Tomcat 简介 Tomcat 服务器是一个免费的开放源代码的Web 应用服务器,属于轻量级应用服务器,在…...
ruoyi-vue版本(十八)创建自己的项目,使用若依里面的技术,多数据源的实现
目录 1 创建自己的项目2 连接MySQL数据库(多数据源)2.1 若依实现多数据源2.1.1 主要思想2.2 第三方的依赖的实现1 创建自己的项目 1 创建一个空文件夹 2 idea 里面创建项目...
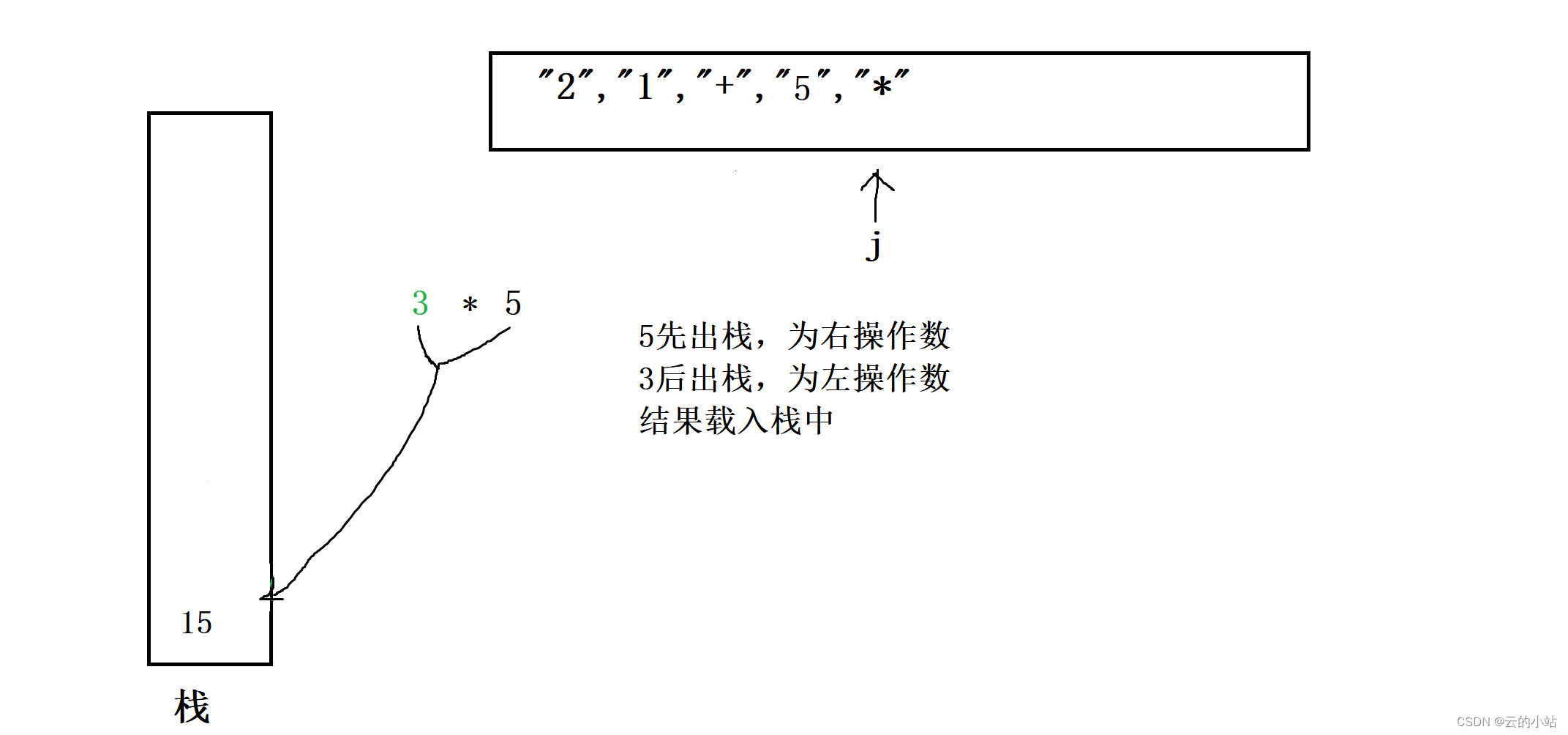
C++-stack题型->最小栈,栈的压入与弹出,逆波兰表达式
目录 最小栈 栈的压入与弹出 逆波兰表达式 最小栈 155. 最小栈 - 力扣(Leetcode) 设计一个支持 push ,pop ,top 操作,并能在常数时间内检索到最小元素的栈。 实现 MinStack 类: MinStack() 初始化堆栈对象。void …...
【计算机网络实验】BGP和OSPF协议仿真实验
实验内容 BGP和OSPF协议仿真实验 实验目的 (1)学习BGP协议的配置方法; (2)验证BGP协议的工作原理; (3)掌握网络自治系统的划分方法; (4)验证…...

提升日期处理效率:day.js 实战经验分享
theme: smartblue 本文简介 点赞 关注 收藏 学会了 本文主要介绍我在工作中使用 day.js 较多的方法。本文并不能代替 day.js 官方文档,日常工作中该查文档的还是要查文档。本文是写给刚接触 day.js 的工友,让这部分工友能更顺利上手 day.js。本文不涉…...

避开这些坑,你的孟德尔随机化分析结果才可靠:以口腔癌研究为例的实操避雷指南
孟德尔随机化分析实战避坑指南:从数据陷阱到稳健结论当你在深夜盯着屏幕上那个意义不明的0.6940093乘数,或是当MR-PRESSO分析结果始终无法收敛时,是否怀疑过自己的分析流程存在致命缺陷?孟德尔随机化(MR)作…...
,第7名99%人从未试过)
【独家实测】12种火焰风格生成成功率排行榜(含燃烧强度/流体轨迹/余烬衰减量化评分),第7名99%人从未试过
更多请点击: https://codechina.net 第一章:火焰风格生成效果的评估体系与实测方法论 火焰风格图像生成质量评估需兼顾视觉感知一致性、物理合理性与算法可复现性。单一指标(如PSNR或LPIPS)无法全面刻画火焰特有的动态纹理、亮度…...

量子机器学习中的偏见:从编码到测量的系统性挑战与缓解策略
1. 量子机器学习中的偏见:一个被忽视的工程挑战量子机器学习(QML)正从理论实验室走向现实应用,从药物分子筛选到金融衍生品定价,其潜力令人兴奋。然而,作为一名长期关注量子算法落地的从业者,我…...

IEMOCAP数据集预处理实战:用Python和Librosa搞定语音情感识别的数据准备
IEMOCAP数据集预处理实战:用Python和Librosa搞定语音情感识别的数据准备语音情感识别(SER)作为人机交互领域的重要研究方向,其核心挑战之一是如何从原始音频中提取有效的特征表示。本文将手把手带你完成IEMOCAP数据集的预处理全流…...

机器学习赋能系统综述:SyROCCo项目实战解析与NLP应用指南
1. 项目概述:当系统综述遇上机器学习如果你做过系统综述,一定对那种“望洋兴叹”的感觉不陌生。面对动辄成千上万的文献,光是筛选、阅读、提取数据这几步,就足以耗掉一个团队数月甚至数年的精力。更头疼的是,等你终于完…...

基于QR分解与肘部法则的稀疏传感器优化布置方法
1. 项目概述:从海量数据到“聪明”的传感器网络在流体动力学、航空航天、环境监测乃至结构健康诊断等众多工程与科学领域,我们常常面临一个共同的困境:我们渴望获得物理场(如速度、压力、温度)在空间和时间上的完整、高…...

DPmoire:为莫尔超晶格定制高精度机器学习力场的自动化方案
1. 项目概述:当莫尔物理遇上机器学习力场 在凝聚态物理和计算材料科学的前沿,莫尔(Moir)超晶格系统正以其丰富而奇特的物理现象吸引着全球研究者的目光。通过简单地扭转两层二维材料(如石墨烯或过渡金属硫族化合物&…...
)
别再死记硬背了!用Python实战案例帮你彻底搞懂假设检验(附代码与避坑指南)
用Python实战拆解假设检验:从数据模拟到结果解读的避坑指南假设检验是数据分析师和机器学习工程师工具箱中最常用的统计工具之一,但很多人在学习过程中都会被各种检验方法、P值解读和原假设设定绕得晕头转向。本文将通过Python代码实战,带你用…...

用Python处理DREAMER脑电数据集:从.mat文件到.npy文件的完整实战教程
用Python处理DREAMER脑电数据集:从.mat文件到.npy文件的完整实战教程在情感计算与神经科学交叉领域,DREAMER数据集因其同时包含脑电信号(EEG)和情感评分而备受研究者青睐。但原始数据以.mat格式存储,这种MATLAB专属格式…...

附录 B:术语表
本术语表面向“从 MM 到 HMM”专栏阅读过程中的快速查阅。它不是内核 API 手册,而是把文章中反复出现的概念放到同一张地图上:先给出直观含义,再说明它在 Linux MM/HMM 语境里的作用。建议阅读方式: 初读专栏时,把它当…...