Linux文件系统、磁盘I/O是怎么工作的?
同CPU、内存一样,文件系统和磁盘I/O,也是Linux操作系统最核心的功能。磁盘为系统提供了最基本的持久化存储。文件系统则在磁盘基础上,提供了一个用来管理文件的树状结构。
目录:
一. 文件系统
1. 索引节点和目录项
2. 虚拟文件系统
3. 文件系统I/O
4. 文件系统性能观测
二. 磁盘I/O
1. 磁盘
2. 通用块层
3. I/O栈
4. 磁盘性能指标以及观测
一. 文件系统
1. 索引节点和目录项
Linux中的一切都由统一的文件系统来管理,包括普通的文件和目录,以及块设备、套接字、管道等。Linux文件系统为每个文件都分配了两个数据结构,索引节点(index node)和目录项(directory entry),主要用来记录文件的元信息和目录结构。
索引节点,简称为 inode,用来记录文件的元数据,比如inode编号、文件大小、访问权限、修改日期、数据的位置等。索引节点和文件一一对应,它跟文件内容一样会被持久化到磁盘,所以,索引节点同样占磁盘。
目录项,简称为dentry,用来记录的文件的名字、索引节点指针以及与其他目录项的关联关系。多个关联的目录项,就构成了文件系统的目录结构,它是由内核维护的一个内存数据结构,通常也被称为目录项缓存。
换句话说,索引节点是每个文件的唯一标志,目录项维护的是文件系统的树状结构。目录项和索引节点的关系是多对一,或者可理解为一个文件多个别名。举个例子,通过硬链接为文件创建的别名,就会对应不同目录项,这些目录项本质上是连接同一个文件,所以索引节点相同。
更具体地说,文件数据是怎么存储的,是直接保存到磁盘的?实际上磁盘读写的最小单位是扇区,扇区只有512B大小,如果每次读写这么小的单位,效率一定很低。所以,文件系统又把连续的扇区组成逻辑块,再以逻辑块为最小单元去管理数据。常见的逻辑块大小是4KB,即连续的8个扇区。下面展示一张示意图:
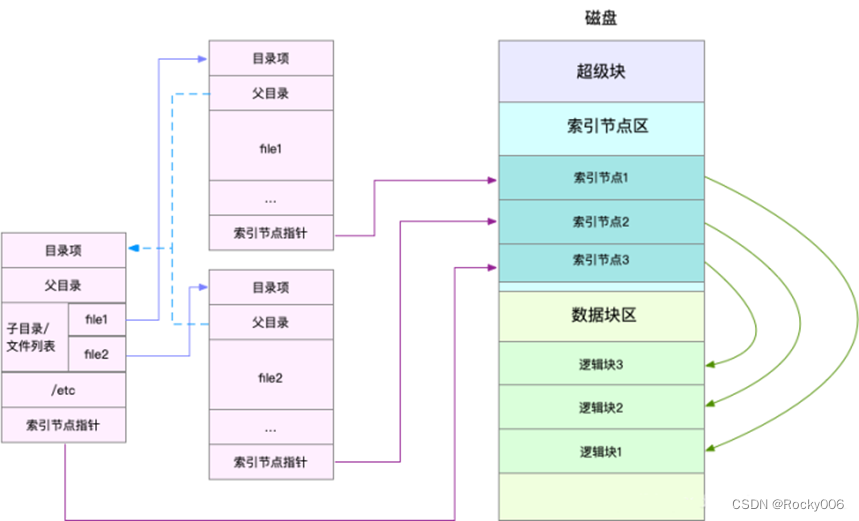
这里需要注意两点:
第一,目录项本身在内存中,索引节点在磁盘中。前面的 Buffer 和 Cache 原理中提到,为了协调慢速磁盘和快速CPU之间的性能差异,文件内容会缓存到页缓存 Cache中。索引节点自然也会缓存到内存中,增加速文件访问。
第二,磁盘在执行文件系统格式化时,会被分成三个存储区域,超级块、索引节点区 和 数据块区。其中,超级块存储整个文件系统状态;索引节点区存储索引节点;数据块区,存储文件数据。
2. 虚拟文件系统
目录项、索引节点、超级块、逻辑块构成Linux文件系统四大基本要素。不过,为了支持各种不同的文件系统,Linux内核在用户进程和文件系统中间,引入了一个抽象层,即虚拟文件系统VFS。VFS定义了一套所有文件系统都支持的数据结构和标准接口。这样,用户层和内核其他子系统都只需要跟 VFS 提供的统一接口交互就可以了,不需要关心底层各种文件系统的实现细节。下图很好展示了Linux文件系统的架构图,能更好的帮助理解系统调用、VFS、缓存、文件系统以及块存储之间的关系:
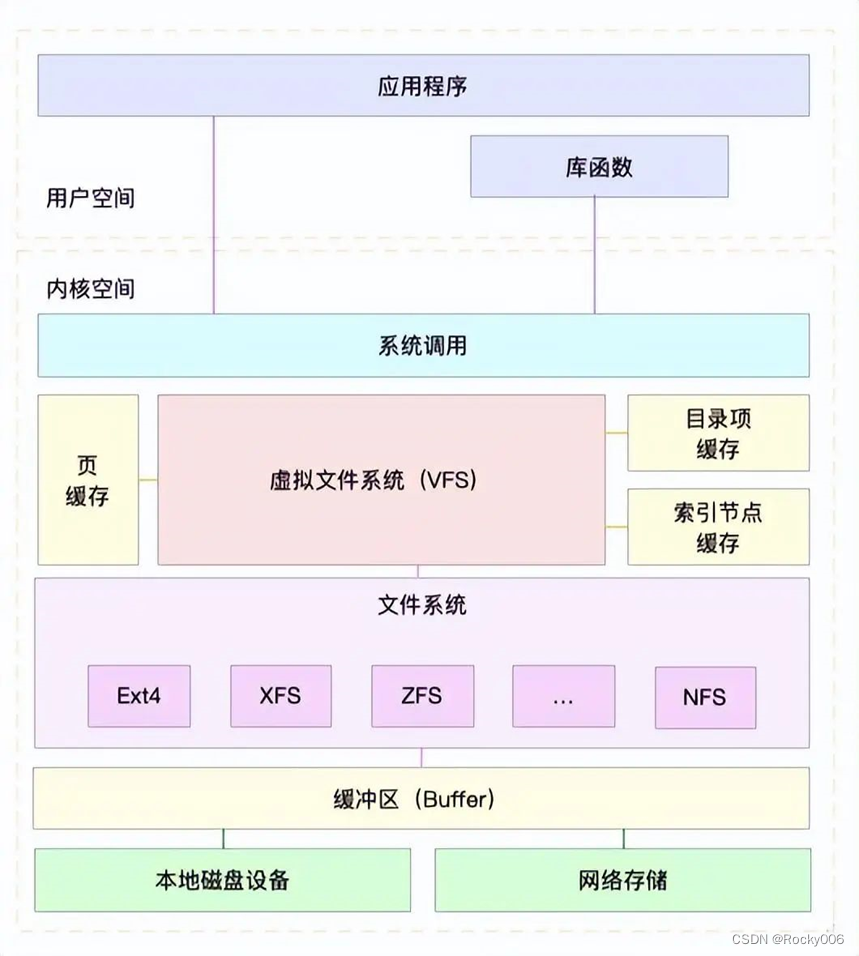
从图中可以看到,在VFS下面Linux可以支持各种文件系统,按照存储位置的不同,可以分为三类:
基于磁盘的文件系统,也就是把数据直接存储到计算机本地挂载的磁盘中。如 EXT4、XFS、OverlayFS等。
基于内存的文件系统,也就是虚拟文件系统,不需要磁盘分配任何存储空间,只占用内存。如 /proc 文件系统、/sys 文件系统(主要向用户空间导出层次化的内核对象)。
网络文件系统,用来访问其他计算机数据的文件系统,如 NFS、SMB、iSCSI等。
这些文件系统,要先挂载到 VFS 目录树中的子目录(挂载点),然后才能访问其中文件。比如安装系统时,要先挂在一个根目录( / ),在根目录下,再把其他文件系统挂在进来。
3. 文件系统I/O
把文件挂到挂载点后,就能通过它去访问它管理的文件了。VFS提供的访问文件的标准接口,以系统调用的方式提供给应用程序使用。比如,cat命令,相继调用 open()、read()、write()。文件读写方式的各种差异,也导致I/O 的分类多种多样。常见的有,缓冲与非缓冲I/O、直接与非直接I/O、阻塞与非阻塞I/O、同步与异步I/O等。下面详细解释下这四种 I/O分类:
第一种,根据是否利用标准库缓存,可以把文件I/O 分为 缓冲I/O 和 非缓冲I/O。这里的“缓冲”,其实指的是标准库内部实现的缓存。例如,很多程序遇到换行时才真正输出,换行前的内容,就是被标准库暂时缓存起来。因此,缓冲I/O 指的是利用标准库缓存来加速文件的访问,在标准库内部再通过系统调用访问文件;非缓冲I/O 指的是直接通过系统调用访问文件,而不通过标准库缓存。无论是缓冲还是非缓冲 I/O,最后都是通过系统调用访问文件。而根据前面内容,系统调用后,还通过页缓存,来减少磁盘I/O操作。
第二种,根据是否利用操作系统的页缓存,可以把文件I/O 分为直接I/O 和 非直接I/O。想要实现直接I/O,需要在系统调用中指定标志 O_DIRECT,如果不指定,默认是非直接I/O。不过注意,这里的直接、非直接I/O,其实最终还是和文件系统交互。如果实在数据库等场景中,还会看到,跳过文件系统读写磁盘的情况,即裸I/O。
第三种,根据应用程序是否阻塞自身运行,可以把文件I/O 分为阻塞I/O 和 非阻塞I/O。在应用程序执行I/O 操作后,如果没获得响应,就阻塞当前线程,自然不能执行其他任务,这是阻塞I/O;如果没获得响应,却不阻塞当前线程,继续执行其他任务,随后通过轮询或者时间通知的形式,获得之前调用的结果。比如,访问管道或者网络套接字时,设置 O_NONBLOCK 标志,表示非阻塞方式访问,若不做任何设置,默认就是阻塞方式访问。
第四种,根据是否等待响应结果,可以把文件I/O 分为同步I/O 和 异步I/O。在应用程序执行I/O 操作后,如果一直等到 整个 I/O完成后才获得响应,就是同步I/O;如果不等待 I/O 完成以及完成后的响应,继续往下执行,等到 I/O 完成后,响应会用事件通知的方式,告诉应用程序。比如,在操作文件时,如果设置了 O_SYNC 或 O_DSYNC标志,就代表同步I/O,后者是等待文件数据写入磁盘后才返回,而前者是在后者基础上,要求文件元数据也要写入磁盘后才能返回。再比如,在访问管道或者网络套接字时,设置选项 O_ASYNC后,就是异步 I/O内核会通过 SIGIO 或者 SIGPOLL,来通知进程,文件是否可读写。
总之,无论是普通文件和块设备、还是网络套接字和管道等,都通过统一的VFS接口来被访问。
4. 文件系统性能观测
$ df /dev/sda1Filesystem 1K-blocks Used Available Use% Mounted on/dev/sda1 30308240 3167020 27124836 11% /$ df -h /dev/sda1Filesystem Size Used Avail Use% Mounted on/dev/sda1 29G 3.1G 26G 11% /$ df -i /dev/sda1Filesystem Inodes IUsed IFree IUse% Mounted on/dev/sda1 3870720 157460 3713260 5% /加上-i 参数查看索引节点的使用情况,索引节点的容量,(也就是 Inode个数)是在格式化磁盘时设定好的,由格式化工具自动生成。当你发现索引节点空间不足时,但磁盘空间充足时,很可能是过多的小文件导致的,一般的删除它们或者移到其他的索引节点充足的磁盘上,就能解决问题。
接下来,文件系统的目录项和索引节点的缓存,如何查看呢?
实际上,内核使用 Slab 机制,管理目录项和索引节点的缓存。/proc/meminfo 只给出了Slab整体大小,具体到每一种Slab缓存,就要查看 /proc/slabinfo。运行下面命令可以得到,所有目录项和各种文件系统的索引节点的缓存情况:
$ cat /proc/slabinfo | grep -E '^#|dentry|inode'# name <active_objs> <num_objs> <objsize> <objperslab> <pagesperslab> : tunables <limit> <batchcount> <sharedfactor> : slabdata <active_slabs> <num_slabs> <sharedavail>xfs_inode 0 0 960 17 4 : tunables 0 0 0 : slabdata 0 0 0...ext4_inode_cache 32104 34590 1088 15 4 : tunables 0 0 0 : slabdata 2306 2306 0hugetlbfs_inode_cache 13 13 624 13 2 : tunables 0 0 0 : slabdata 1 1 0sock_inode_cache 1190 1242 704 23 4 : tunables 0 0 0 : slabdata 54 54 0shmem_inode_cache 1622 2139 712 23 4 : tunables 0 0 0 : slabdata 93 93 0proc_inode_cache 3560 4080 680 12 2 : tunables 0 0 0 : slabdata 340 340 0inode_cache 25172 25818 608 13 2 : tunables 0 0 0 : slabdata 1986 1986 0dentry 76050 121296 192 21 1 : tunables 0 0 0 : slabdata 5776 5776 0dentry 行表示目录项缓存,inode_cache 行,表示VFS 索引节点缓存,其余的则是各种文件系统的缓存。这里列比较多,可查询man slabinfo。实际性能分析时,更多使用 slabtop,来找到占用内存最多的缓存类型:
# 按下c按照缓存大小排序,按下a按照活跃对象数排序$ slabtopActive / Total Objects (% used) : 277970 / 358914 (77.4%)Active / Total Slabs (% used) : 12414 / 12414 (100.0%)Active / Total Caches (% used) : 83 / 135 (61.5%)Active / Total Size (% used) : 57816.88K / 73307.70K (78.9%)Minimum / Average / Maximum Object : 0.01K / 0.20K / 22.88KOBJS ACTIVE USE OBJ SIZE SLABS OBJ/SLAB CACHE SIZE NAME69804 23094 0% 0.19K 3324 21 13296K dentry16380 15854 0% 0.59K 1260 13 10080K inode_cache58260 55397 0% 0.13K 1942 30 7768K kernfs_node_cache485 413 0% 5.69K 97 5 3104K task_struct1472 1397 0% 2.00K 92 16 2944K kmalloc-2048从这个结果可以看到,目录项和索引节点占用最多的 Slab缓存,但其实并不大,约23MB。
思考:find / -name file-name 命令导致会不会导致缓存升高,如果会,导致哪类缓存升高呢?
find / -name 命令是全盘扫描(包括内存文件系统、磁盘文件系统等),所以这里会导致 xfs_inode 、proc_inode_cache、dentry、 inode_cache这几类缓存的升高,而且在下次执行 find 命令时,就会快很多,因为它大部分会直接在缓存中查找结果。这里你可以在执行find命令前后,比较slabtop、free、vmstat输出结果,又会有更深的理解。
二. 磁盘 I/O
1. 磁盘
首先,根据存储介质的不同,可以分为两类,机械磁盘 和 固态磁盘。
机械磁盘:也称为硬盘驱动器(Hard Disk Driver,缩写HDD),机械磁盘由盘片和读写磁头组成,数据存储在盘片的环状磁道中,最小读写单位 扇区,一般大小为512B。在读写数据时,需要移动磁头,定位到数据所在的盘片磁道中,然后才访问数据。如果 I/O 请求刚好连续,那就不需要磁道寻址,可获得最佳性能,这就是顺序I/O 的工作原理。随机 I/O,需要不停地移动磁头,来定位数据位置,读写速度比较慢。
固态磁盘:Solid State Driver,缩写SSD,由固态电子元器件组成,最小读写单位 页,一般大小4KB、8KB等。固态磁盘不需要磁道寻址,不管是连续I/O,还是随机I/O的性能,都比机械磁盘好得多。
另外,相同磁盘的顺序I/O 都要比 随机I/O 快得多,原因如下:
对于机械磁盘来说,随机 I/O需要更多的磁头寻道和盘片旋转,性能比顺序I/O 慢。
对于固态盘来说,虽然随机I/O 性能比机械盘好很多,但是它也会有“先擦除、再写入”的限制。随机读写也有大量的垃圾回收,所以还是会比顺序I/O 慢很多。
另外,顺序I/O 可以通过预读的方式,来减少 I/O请求的次数,这也是其性能优异的原因之一。
在上一节提到过,如果每次都读写 512B 数据,效率会很低。文件系统会把连续的扇区或页组成逻辑块,作为最小单元管理数据,常见的逻辑块是 4KB,即连续的8个扇区,或者一个页。
其次,还可以按照接口来分类,可以把硬盘分为 IDE、SCSI、SAS、SATA、FC等。不同的接口,分配不同的设备名称。比如 IDE的会分配一个前缀为 hd 的设备名,SCSI 和 SATA会分配一个 sd 前缀的设备名。如果是多块同类型的磁盘,会按照a、b、c等字母顺序编号。
第三,还可以根据使用方式,将磁盘划分为不同架构。最简单的就是,作为独立磁盘来使用。然后再根据需要,将磁盘划分成多个逻辑分区,再给分区编号。比如前面多次用到的 /dev/sda,还可以分成两个分区 /dev/sda1 和 /dev/sda2。另一个比较常用的架构是,将多块磁盘组成一个逻辑磁盘,构成冗余独立 的磁盘阵列,RAID,提高数据访问性能,增强数据存储的可靠性。
根据容量、性能、可靠性的不同,RAID可以分为多个级别,如RAID0、RAID1、RAID5、RAID10等。RAID0有最优的读写性能,但不提供数据冗余的功能,其他级别的 RAID,在数据冗余的基础上,对读写性能有一定的优化。
最后一种架构,把磁盘组合成网络存储集群,再通过NFS、SMB、iSCSI等网络存储协议,暴露给服务器使用。
其实,在Linux下,磁盘是作为块设备来管理的,也就是以块为单位来读写数据,且支持随机读写。每个块设备都被赋予主、次两个设备号,主设备号用在驱动程序中区别设备类型,次设备号用来给多个同类设备编号。
2. 通用块层
为了减少不同块设备的差异带来的影响,Linux通过一个统一的通用块层,来管理各种不同的块设备。通用块层其实是处在文件系统和磁盘驱动中间的一个块设备抽象层。有两个功能:
第一个跟虚拟文件系统的功能类似。向上,为文件系统和应用程序,提供访问块设备的标准接口;向下,把各种异构的磁盘设备抽象成统一的块设备,并提供统一框架来管理这些设备的驱动程序。
第二个功能,通用块层还给文件系统和应用程序发来的I/O请求排队,并通过请求排队、合并等,提高磁盘读写的效率。
对 I/O请求排序也是 I/O调度。事实上,Linux内核支持四种 I/O调度算法,NONE、NOOP、CFQ、DeadLine。
NONE:确切的说并不能算调度,因为它完全不使用任何调度器,对文件系统和应用程序的 I/O不作任何处理,常用在虚拟机中(此时磁盘 I/O调度完全由物理机支持)。
NOOP:最简单的一种调度算法,是一个先进先出的队列,只做一些最基本的请求合并,常用于SSD盘。
CFQ:完全公平调度器,是现在很多发行版的默认 I/O调度器。它为每个进程维护了一个 I/O调度队列,并按时间片来均匀分布每个进程的 I/O请求。类似于进程的CPU调度,CFQ调度还支持进程 I/O的优先级调度,所以适用运行着大量进程的系统,像桌面环境、多媒体应用等。
DeadLine:分别为读、写请求创建不同的 I/O 队列,可以提高机械磁盘的吞吐量,并确保达到最终期限的请求被优先处理。这种调度算法 多用在 I/O 压力比较大的场合,如数据库等。
3. I/O栈
结合上面讲的文件系统、磁盘和通用块层的工作原理,我们可以整体来看 Linux存储系统的 I/O原理了。事实上,我们可以把 Linux存储系统的 I/O栈,由上至下分为三层:文件系统层、通用块层、设备层。看图:
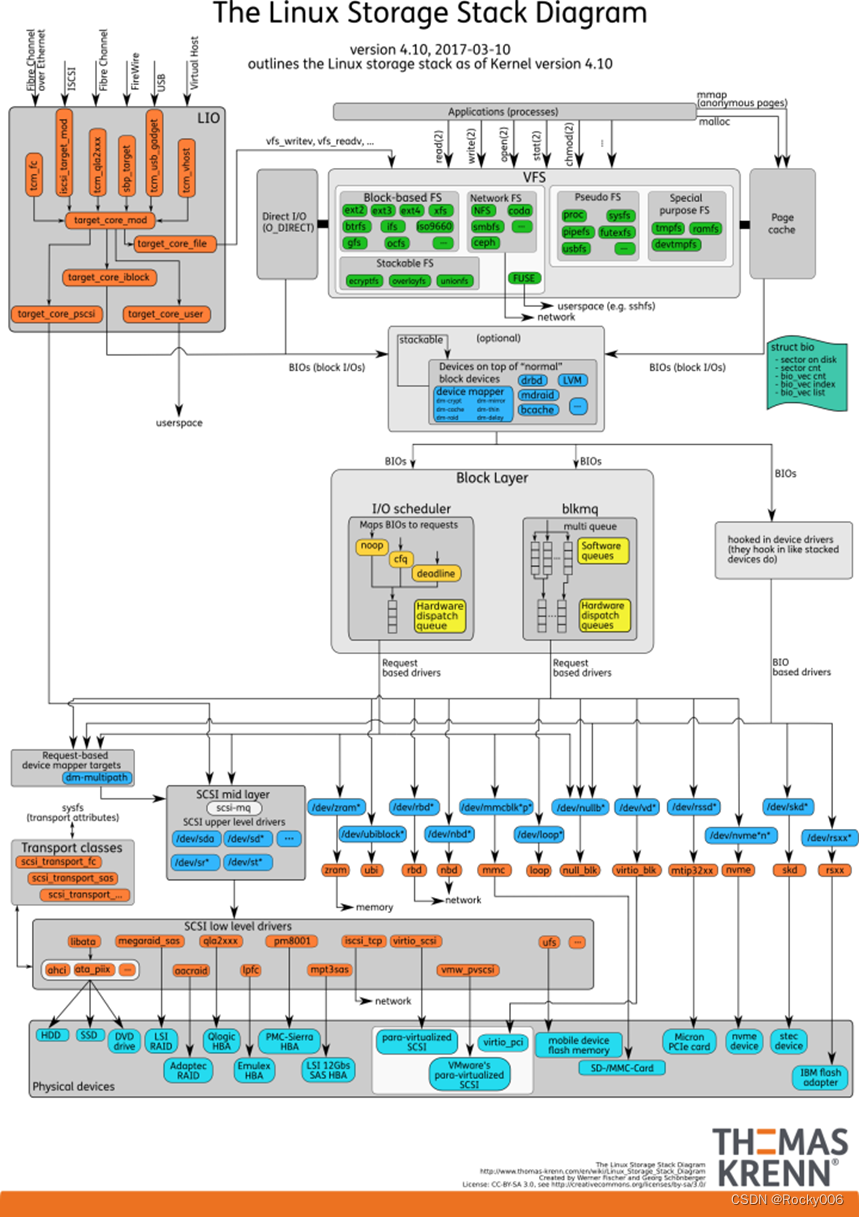
根据这张全景图,我们可以更清楚理解,存储系统的 I/O的工作原理:
文件系统层,包括虚拟文件系统和其他各种文件系统的具体实现。首先为上层的应用程序提供标准的文件访问接口,对下会通过通用块层,来存储和管理磁盘数据。
通用块层,是Linux磁盘 I/O的核心,包括设备 I/O队列和 I/O调度器。会对文件系统的 I/O请求进行排队,再通过重新排序和请求合并,再发给下一级设备层。
设备层,包括存储设备和相应的驱动程序,负责最终物理设备的 I/O操作。
存储系统的 I/O,通常是整个Linux系统中最慢的一环。所以,Linux通过多种缓存机制来优化 I/O 效率。比如,为了优化文件访问性能,会使用页缓存、索引节点缓存、目录项缓存等多种缓存机制,减少对下层块设备的直接调用。同样,为了优化块设备的访问性能,会使用缓冲区,来缓存块设备的数据。
4. 磁盘性能指标以及观测
这里说一下常见的五个指标,使用率、饱和度、IOPS、吞吐量以及响应时间等,这五个指标是衡量磁盘性能的基本指标。
使用率,是指磁盘处理 I/O的时间百分比。过高的使用率(如超过80%),通常意味着磁盘 I/O的性能瓶颈。
饱和度,磁盘处理 I/O的繁忙程度,过高的饱和度,意味着磁盘存在严重的性能瓶颈。当达到100%时,磁盘就无法接受新的 I/O请求。
IOPS,每秒的 I/O请求数。
吞吐量,每秒的 I/O请求大小。
响应时间,从发出请求到收到响应的时间间隔。
注意,使用率只考虑有没有 I/O,而不考虑 I/O大小,即使达到100%,也有可能接受新的 I/O请求。在数据库、大量小文件等这类随机读写比较多的场景中,IOPS更能反应系统整体性能。在多媒体等顺序读写较多的场景中,吞吐量更能反应系统整体性能。
一般来说,我们在为应用程序的服务器选型时,要先对磁盘 I/O的性能进行基准测试,推荐的性能测试工具 fio,来测试磁盘的 IOPS,吞吐量以及响应时间等核心指标。用性能工具得到的指标,作为后续分析应用程序的性能依据。一旦发生性能问题,就可以把它们作为磁盘性能的极限值,进而评估磁盘 I/O的使用情况。
接下来看看怎么观测磁盘 I/O?首推的工具 iostat,它提供每个磁盘的使用率、IOPS、吞吐量等各种常见的性能指标,当然这些指标来自 /proc/diskstats。iostats 的输出界面如下:
# -d -x表示显示所有磁盘I/O的指标$ iostat -d -x 1Device r/s w/s rkB/s wkB/s rrqm/s wrqm/s %rrqm %wrqm r_await w_await aqu-sz rareq-sz wareq-sz svctm %utilloop0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00loop1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00sda 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00sdb 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00下图说明了这些列的具体含义:
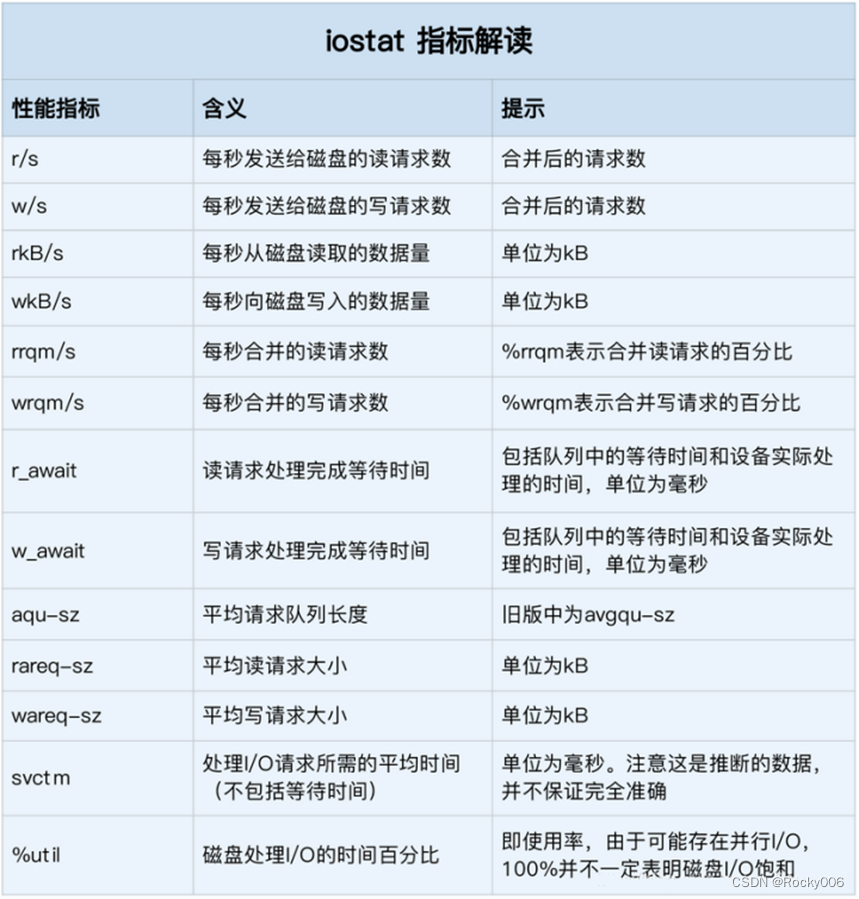
这些指标,你要注意,%util 磁盘使用率,r/s + w/s IOPS,rkB/s + wkB/s 吞吐量, r_await + w_await 响应时间。另外从 iostat 并不能直接得到磁盘的饱和度,但是可以把观测到的,平均请求队列长度 或者 读写请求完成的等待时间,跟基准测试的结果进行对比,综合来评估。
我们再来看看,每个进程的 I/O情况。iostat只能看到磁盘整体的 I/O性能数据,并不能知道具体哪些进程 在进行磁盘读写,推荐两个工具:pidstat 和 iotop。具体使用这里略过。
如果文章对您有所帮助,欢迎点赞转发收藏,感谢!!
-End-
相关文章:
Linux文件系统、磁盘I/O是怎么工作的?
同CPU、内存一样,文件系统和磁盘I/O,也是Linux操作系统最核心的功能。磁盘为系统提供了最基本的持久化存储。文件系统则在磁盘基础上,提供了一个用来管理文件的树状结构。 目录: 一. 文件系统 1. 索引节点和目录项 2. 虚拟文件系…...

设计原则之接口隔离原则
tip: 需要《设计模式之禅》的书籍,可以联系我 作为程序员一定学习编程之道,一定要对代码的编写有追求,不能实现就完事了。我们应该让自己写的代码更加优雅,即使这会费时费力。 相关规则: 1.6大设计规则-迪米特法则 …...
ubuntu20.04 ffmpeg mp4转AES加密的m3u8分片视频
样本视频(时长2分35秒): 大雄兔_百度百科 大雄兔_百度百科不知大家否看过世界上第一部开源电影:Elephants Dream(大象之梦)。这是一部由主要由开源软件Blender制作的电影短片,证明了用开源软件也能制作出效果媲美大公司的作品。…...

Java08——继承
1. 继承 父类: package com.zsq.extend.improve_; //是pupil和graduate的父类 public class Student {public String name;public int age;private double score;public void info(){System.out.println("姓名:" name " 年龄࿱…...

C++高级语法
文章目录 C高级语法面向对象 -- 类/结构体抽象-具体类型 标准I/O流I/O流I/O缓存区 文件操作头文件的重复包含问题深拷贝和浅拷贝,写时复制面向对象的三大特性面向对象是什么 C高级语法 面向对象 – 类/结构体 C使用class定义一个类,使用struct定义一个…...

React学习笔记九-高阶函数与函数柯里化
此文章是本人在学习React的时候,写下的学习笔记,在此纪录和分享。此为第九篇,主要介绍高阶函数与函数柯里化。 高阶函数,和函数的柯里化,是学习react的拓展,方便以后优化代码,更好的学习react。…...

2023年电工杯B题半成品论文使用讲解
注:蓝色字体为说明备注解释字体,不能出现在大家的论文里。黑色字体为论文部分,大家可以根据红色字体的注记进行摘抄。该文件为半成品论文,即引导大家每一步做什么,怎么做,展示按着本团队的解题思路进行建模…...
第1关:ODBC程序设计
第1关:ODBC程序设计 任务描述相关知识ODBC主要功能ODBC接口主要函数ODBC应用程序开发实例DM ODBC应用程序开发总体流程DM ODBC代码编写流程DM ODBC代码编写实例 编程要求测试说明代码参考: 任务描述 本关任务:使用 ODBC 查询表中数据。 相关…...
Kotlin笔记(零)简介
百度百科简介 2017年,google公司在官网上宣布Kotlin成为Android的开发语言,使编码效率大增。Kotlin 语言由 JetBrains 公司推出,这是一个面向JVM的新语言 参考资料 官网:https://kotlinlang.org/中文官网:https://w…...

android 12.0去掉usb授权提示框 默认给予权限
1.概述 在12.0的系统rom产品开发中,在进行iot开发过程中,在插入usb设备时会弹出usb授权提示框,也带来一些不便,这个需要默认授予USB权限,插拔usb都不弹出usb弹窗所以这要从usb授权相关管理页默认给与usb权限 2.去掉usb授权提示框 默认给予权限的相关代码 frameworks/bas…...

工作积极主动分享,善于业务沟通
工作积极主动分享,善于业务沟通 目录概述需求: 设计思路实现思路分析1.工作积极主动承担责任2.善于沟通3.一起常常lauch 参考资料和推荐阅读 Survive by day and develop by night. talk for import biz , show your perfect code,full busy,…...
 : opencv的数据结构)
Opencv-C++笔记 (1) : opencv的数据结构
文章目录 一、OPNECV元素1.CvPoint2、模板类Size模版类Rect模版类RotatedRect模版类 二、MAT1.使用(nrows, ncols, type),初始化2维矩阵如果需要深拷贝,则使用clone方法。 三、Vec类 一、OPNECV元素 1.CvPoint 为了方便使用,opencv又对常用的…...
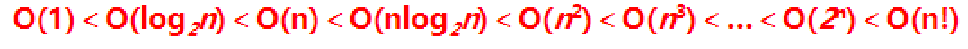
什么是时间复杂度?
时间复杂度定义:在计算机科学中,时间复杂性,又称时间复杂度,算法的时间复杂度是一个函数,它定性描述该算法的运行时间。这是一个代表算法输入值的的长度的函数。时间复杂度常用大O符号表述,不包括这个函数的…...
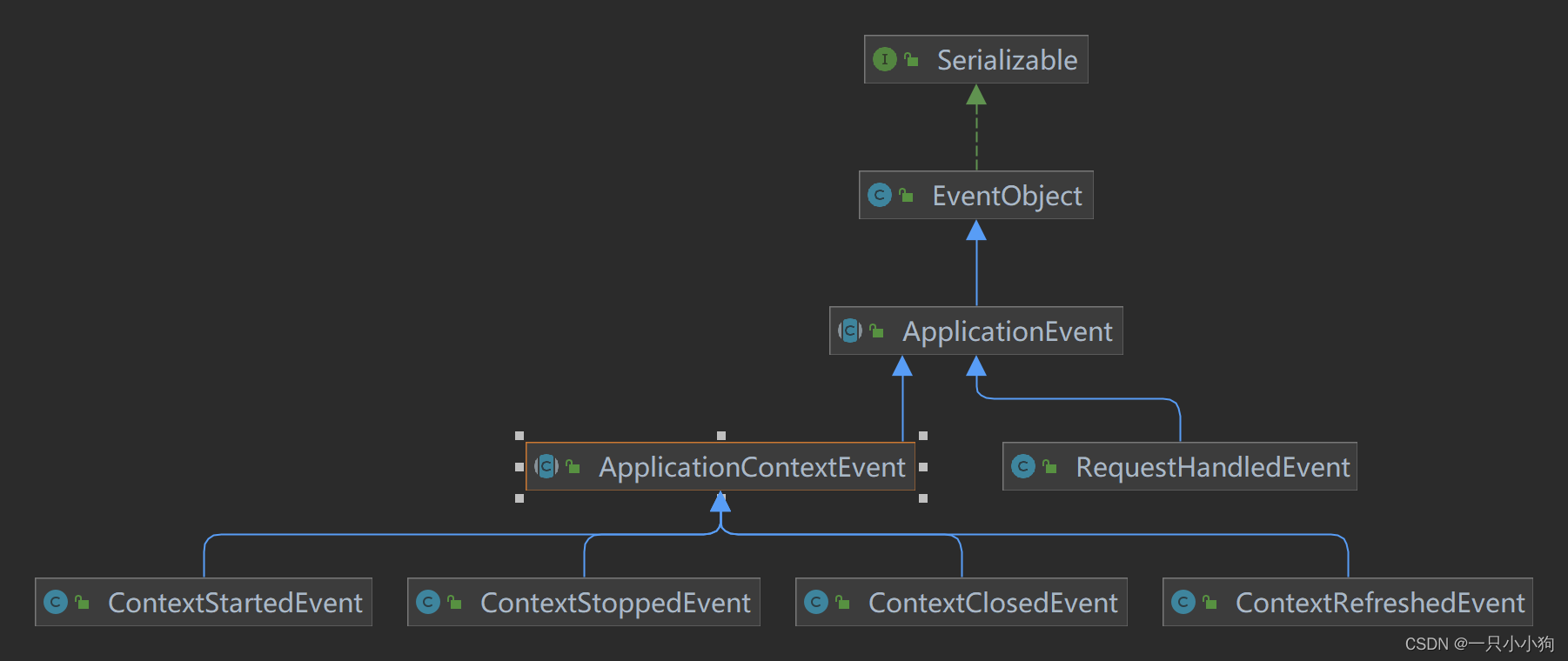
Spring框架中有哪些不同类型的事件
Spring框架中有哪些不同类型的事件 Spring框架中有哪些不同类型的事件 Spring框架中有哪些不同类型的事件 Spring 提供了以下5种标准的事件: 上下文更新事件(ContextRefreshedEvent):在调用ConfigurableApplicationContext 接口…...

Codeforcs 1732C2 暴力
题意 传送门 Codeforcs 1732C2 题解 方便起见,区间表示为左闭右开。观察到 f ( l , r ) ≥ f ( l ′ , r ′ ) , [ l ′ , r ′ ) ∈ [ l , r ) f(l,r)\geq f(l,r),[l,r)\in [l,r) f(l,r)≥f(l′,r′),[l′,r′)∈[l,r),满足单调性,则 […...

Python安全和防护:如何保护Python应用程序和用户数据的安全
章节一:引言 在当今数字化时代,数据安全是一个极其重要的话题。随着Python的广泛应用和越来越多的人使用Python构建应用程序,保护Python应用程序和用户数据的安全变得尤为重要。本文将介绍一些关键的Python安全问题,并提供一些保…...
[转载]Nginx 使用 X-Accel-Redirect 实现静态文件下载的统计、鉴权、防盗链、限速等
需求 统计静态文件的下载次数;判断用户是否有下载权限;根据用户指定下载速度;根据Referer判断是否需要防盗链;根据用户属性限制下载速度; X-Accel-Redirect This allows you to handle authentication, logging or …...

继电器的详细分类
继电器的分类方法较多,可以按作用原理、外形尺寸、保护特征、触点负载、产品用途等分类。 一、按作用原理分 1.电磁继电器 在输入电路内电流的作用下,由机械部件的相对运动产生预定响应的一种继电器。 它包括直流电磁继电器、交流电磁继电器、…...

docker的底层原理,带你上天
1、docker的层级怎么看 先查看当前机器上有哪些镜像 docker images 这里选看mysql的层级 docker image inspect mysql:5.7.29 命令。其中RootFS部分则是表示了分层信息。 2、查看docker的系统信息 因为这台机器的docker不是我安装的,所以不知道具体的根目录在哪里…...
HNU-电子测试平台与工具2-串口实验5次
计算机串口使用与测量 【实验属于电子测试平台与工具】 湖南大学信息科学与工程学院 计科 210X wolf (学号 202108010XXX) 0.环境搭建 在实验开始之前,安装好Ubuntu 20.04操作系统。(这个没有难度) 但要提醒的是,这个ubuntu是xubuntu,而且虚拟硬盘只有10GB的大小…...

BU-CVKit:模块化计算机视觉框架赋能跨物种动物行为分析
1. 项目概述:从实验室到旷野,一个框架的野心在计算机视觉研究领域,尤其是动物行为学和生态学方向,我们常常面临一个尴尬的局面:针对小鼠开发的追踪算法,拿到斑马鱼身上就水土不服;为猕猴设计的姿…...

随机计算与ViT硬件加速:混合架构如何突破AI芯片能效墙
1. 项目概述:当ViT遇见随机计算最近在硬件加速领域,一个名为“ASCEND”的项目引起了我的注意。这本质上是一个专门为Vision Transformer(ViT)模型设计的硬件加速器,但其核心创新点在于采用了“随机计算”这种非常规的电…...

AI时代版权新范式:智能代理如何重塑数据交易与创作者权益
1. 项目概述:当AI遇见版权,一场静默的“数据战争”正在上演如果你是一位内容创作者,无论是撰写深度文章的记者、绘制插画的艺术家,还是谱写旋律的音乐人,过去几年可能都经历过一种复杂的情绪:看着自己的作品…...

实测天下工厂:用它找工厂客户,数据准不准、覆盖全不全?
做 B2B 销售的人都知道,找到一份"高质量工厂名单"有多难。 不是因为工厂数量少,而是因为现有渠道普遍存在一个结构性问题:工厂和非工厂混在一起,分不清楚。用通用企业查询工具检索某个行业,跑出来的结果里&a…...

WSA-Pacman:让Windows安卓应用管理变得前所未有的简单
WSA-Pacman:让Windows安卓应用管理变得前所未有的简单 【免费下载链接】wsa_pacman A GUI package manager and package installer for Windows Subsystem for Android (WSA) 项目地址: https://gitcode.com/gh_mirrors/ws/wsa_pacman 想要在Windows电脑上安…...

2026年论文党必备:盘点2026年倾心之选的的降AIGC网站
轻松降低论文AI率在2026年已不再是天方夜谭。以下是2026年最炸裂、实测效果显著的降AIGC网站神器,覆盖AI痕迹消除、文本改写润色、降重优化、学术合规检测四大核心场景,帮你稳妥搞定毕业论文。 一、全流程王者:一站式搞定论文全链路 这类工具…...

工业级房价预测实战:从数据清洗到可解释模型部署
1. 这不是“调个模型就完事”的房价预测——而是一次完整的工业级回归建模实战复盘你打开Kaggle,下载一个带“house price”字样的CSV文件,pandas读进来,train_test_split切两刀,RandomForestRegressor.fit()跑完,R显示…...

CANN算子开发调试实战:从“Segmentation Fault“到定位根因的完整流程
写Ascend C算子最怕的不是编译失败——编译失败有明确的错误信息。最怕的是运行时Segmentation Fault,什么都没告诉你,NPU直接挂了。没有堆栈、没有日志、只有一行"Killed"。 这篇整理了算子开发中常见的运行时错误、调试方法、以及定位根因的…...
)
【限时公开】我们压测了23个开源AI Agent框架,仅2个支持亚秒级SQL生成+自动schema纠错(测试报告PDF已备)
更多请点击: https://codechina.net 第一章:AI Agent数据分析应用 AI Agent 正在重塑数据分析的范式——它不再依赖人工编写 SQL 或手动配置 ETL 流程,而是通过自然语言理解任务意图、自主调用工具、迭代验证结果,并生成可解释的…...

2026 河北 GEO 优化服务商测评:理性看实力,盘古开物AI智推适配才是硬道理
覆盖石家庄、唐山、保定、邯郸、邢台,立足华北,辐射全国,不搞噱头,只讲真实能力随着生成式 AI 全面融入商业营销,GEO 优化已经从河北企业的可选服务,变成抢占区域流量、提升线上可见度的重要方式。尤其制造…...