【Kafka】超详细介绍
文章目录
- 概念
- 部署方案
- 磁盘
- 网络
- CPU
- partition的数量
- 命令
- 查看版本
- 找kafka和zookeeper的ip/port
- topic
- 创建 topic
- 查看
- get topic 列表
- get topic 详情
- 修改topic
- 修改分区级别参数(如增加partition)
- 删除topic
- 设置消息大小上限
- 生产
- 查看生产
- 生产消息
- 查看消费
- server
- 查看 offset
- 查看积压
- server
- client has run out of available brokers to talk to (Is your cluster reachable?)报错的调试
- 原理
- UI 工具
- go sarama库使用
- consumer
概念
Kafka 是消息引擎(Messaging System),其是一组规范。企业利用这组规范在不同系统之间传递语义准确的消息,实现松耦合的异步式数据传递。
实现的目标,就是 系统A 发消息给 消息引擎,系统B 从消息引擎读取 A发送的消息。
Kafka 用二进制存储数据。其同时支持点对点模型、发布/订阅模型两种。
- 点对点模型:也叫消息队列模型。如果拿上面那个“民间版”的定义来说,那么系统 A 发送的消息只能被系统 B 接收,其他任何系统都不能读取 A 发送的消息。日常生活的例子比如电话客服就属于这种模型:同一个客户呼入电话只能被一位客服人员处理,第二个客服人员不能为该客户服务。
- 发布 / 订阅模型:与上面不同的是,它有一个主题(Topic)的概念,你可以理解成逻辑语义相近的消息容器。该模型也有发送方和接收方,只不过提法不同。发送方也称为发布者(Publisher),接收方称为订阅者(Subscriber)。和点对点模型不同的是,这个模型可能存在多个发布者向相同的主题发送消息,而订阅者也可能存在多个,它们都能接收到相同主题的消息。生活中的报纸订阅就是一种典型的发布 / 订阅模型。
消息引擎的作用:
- 削峰填谷:缓冲上下游瞬时突发流量,使其更平滑。特别是对于那种发送能力很强的上游系统,如果没有消息引擎的保护,“脆弱”的下游系统可能会直接被压垮导致全链路服务“雪崩”。但是,一旦有了消息引擎,它能够有效地对抗上游的流量冲击,真正做到将上游的“峰”填满到“谷”中,避免了流量的震荡。
- 发送方和接收方的松耦合,这也在一定程度上简化了应用的开发,减少了系统间不必要的交互。
名词术语如下:
- 消息:Record。Kafka 是消息引擎嘛,这里的消息就是指 Kafka 处理的主要对象。
- 主题:Topic。主题是承载消息的逻辑容器,在实际使用中多用来区分具体的业务。
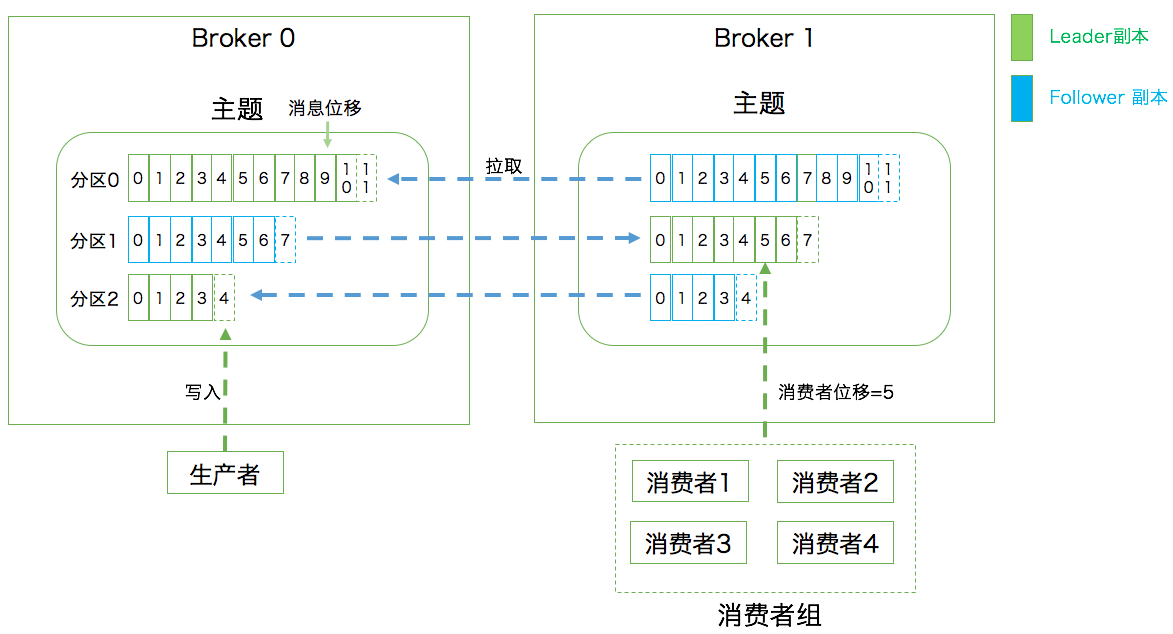
- 分区:Partition。一个有序不变的消息序列。每个主题下可以有多个分区。
- 消息位移:Offset。表示分区中每条消息的位置信息,是一个单调递增且不变的值。
- 副本:Replica。Kafka 中同一条消息能够被拷贝到多个地方以提供数据冗余,这些地方就是所谓的副本。副本还分为领导者副本和追随者副本,各自有不同的角色划分。副本是在分区层级下的,即每个分区可配置多个副本实现高可用。
- 生产者:Producer。向主题发布新消息的应用程序。
- 消费者:Consumer。从主题订阅新消息的应用程序。
- 消费者位移:Consumer Offset。表征消费者消费进度,每个消费者都有自己的消费者位移。
- 消费者组:Consumer Group。多个消费者实例共同组成的一个组,同时消费多个分区以实现高吞吐。
- 重平衡:Rebalance。消费者组内某个消费者实例挂掉后,其他消费者实例自动重新分配订阅主题分区的过程。Rebalance 是 Kafka 消费者端实现高可用的重要手段。
Kafka的副本为何不允许对外提供服务?
- 如果允许follower副本对外提供读服务(主写从读),首先会存在数据一致性的问题,消息从主节点同步到从节点需要时间,可能造成主从节点的数据不一致。主写从读无非就是为了减轻leader节点的压力,将读请求的负载均衡到follower节点,如果Kafka的分区相对均匀地分散到各个broker上,同样可以达到负载均衡的效果,没必要刻意实现主写从读增加代码实现的复杂程度
Consumer Group:
- 在一个消费者组下,一个分区只能被一个消费者消费,但一个消费者可能被分配多个分区,因而在提交位移时也就能提交多个分区的位移。
- 如果Consumer Group内 consumer的数量 > partition 的数量,则有一个消费者将无法分配到任何分区,处于idle状态。
Producer:
- 如果producer指定了要发送的目标分区,消息自然是去到那个分区;否则就按照producer端参数partitioner.class指定的分区策略来定;如果你没有指定过partitioner.class,那么默认的规则是:看消息是否有key,如果有则计算key的murmur2哈希值%topic分区数;如果没有key,按照轮询的方式确定分区。
监控:
- JMXTrans + InfluxDB + Grafana(推荐)
- Kafka manager
- kafka eagle
部署方案
磁盘
根据保留的消息数量,预估磁盘占用:
- 新增消息数
- 消息留存时间
- 平均消息大小
- 备份数
- 是否启用压缩
假设你所在公司有个业务每天需要向 Kafka 集群发送 1 亿条消息,每条消息保存两份以防止数据丢失,另外消息默认保存两周时间。现在假设消息的平均大小是 1KB,那么你能说出你的 Kafka 集群需要为这个业务预留多少磁盘空间吗?我们来计算一下:每天 1 亿条 1KB 大小的消息,保存两份且留存两周的时间,那么总的空间大小就等于 1 亿 * 1KB * 2 / 1000 / 1000 = 200GB。一般情况下 Kafka 集群除了消息数据还有其他类型的数据,比如索引数据等,故我们再为这些数据预留出 10% 的磁盘空间,因此总的存储容量就是 220GB。既然要保存两周,那么整体容量即为 220GB * 14,大约 3TB 左右。Kafka 支持数据的压缩,假设压缩比是 0.75,那么最后你需要规划的存储空间就是 0.75 * 3 = 2.25TB。
网络
根据QPS和带宽,预估服务器数量:(注意:业界带宽资源一般用Mbps而不是MBps衡量)
假设你公司的机房环境是千兆网络,即 1Gbps,现在你有个业务,其业务目标或 SLA 是在 1 小时内处理 1TB 的业务数据。那么问题来了,你到底需要多少台 Kafka 服务器来完成这个业务呢?让我们来计算一下,由于带宽是 1Gbps,即每秒处理 1Gb 的数据,假设每台 Kafka 服务器都是安装在专属的机器上,也就是说每台 Kafka 机器上没有混布其他服务,毕竟真实环境中不建议这么做。通常情况下你只能假设 Kafka 会用到 70% 的带宽资源,因为总要为其他应用或进程留一些资源。根据实际使用经验,超过 70% 的阈值就有网络丢包的可能性了,故 70% 的设定是一个比较合理的值,也就是说单台 Kafka 服务器最多也就能使用大约 700Mb 的带宽资源。稍等,这只是它能使用的最大带宽资源,你不能让 Kafka 服务器常规性使用这么多资源,故通常要再额外预留出 2/3 的资源,即单台服务器使用带宽 700Mb / 3 ≈ 240Mbps。需要提示的是,这里的 2/3 其实是相当保守的,你可以结合你自己机器的使用情况酌情减少此值。好了,有了 240Mbps,我们就可以计算 1 小时内处理 1TB 数据所需的服务器数量了。根据这个目标,我们每秒需要处理 2336Mb 的数据,除以 240,约等于 10 台服务器。如果消息还需要额外复制两份,那么总的服务器台数还要乘以 3,即 30 台。
CPU
通常情况下Kafka不太占用CPU,因此没有这方面的最佳实践出来。但有些情况下Kafka broker是很耗CPU的:
- server和client使用了不同的压缩算法;
- server和client版本不一致造成消息格式转换;3
- broker端解压缩校验
不过相比带宽资源,CPU通常都不是瓶颈
partition的数量
网上有一些分区制定的建议,我觉得这个粗粒度的方法就很好,值得一试:
- 首先你要确定你业务的SLA,比如说你希望你的producer TPS是10万条消息/秒,假设是T1
- 在你的真实环境中创建一个单分区的topic测试一下TPS,假设是T2
- 你需要的分区数大致可以等于T1 / T2
命令
2.2以上用–bootstrap-server, 2.2以下用–zookeeper
查看版本
cd kafka/libs
其中有kafka_2.12-2.8.0.jar,则版本为2.8.0
找kafka和zookeeper的ip/port
root@master~# kubectl get svc -n kafka -o wide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
bootstrap ClusterIP 10.109.83.55 <none> 9092/TCP 15d app=kafka
broker ClusterIP None <none> 9092/TCP 15d app=kafka
outside-0 NodePort 10.108.34.0 <none> 32400:32400/TCP 15d app=kafka,kafka-broker-id=0
outside-1 NodePort 10.104.65.215 <none> 32401:32401/TCP 15d app=kafka,kafka-broker-id=1
outside-2 NodePort 10.99.118.241 <none> 32402:32402/TCP 15d app=kafka,kafka-broker-id=2
pzoo ClusterIP None <none> 2888/TCP,3888/TCP 15d app=zookeeper,storage=persistent
zoo ClusterIP None <none> 2888/TCP,3888/TCP 15d app=zookeeper,storage=persistent-regional
zookeeper ClusterIP 10.103.22.130 <none> 2181/TCP 15d app=zookeeper
topic
- 如果遇到client向某些topic建立producer时报错
kafka: client has run out of available brokers to talk to (Is your cluster reachable?), 可以手动删掉topic再手动重建topic
创建 topic
./kafka-topics.sh --zookeeper 10.103.22.130:2181 --create --topic ttt1 --partitions 1 --replication-factor 1
查看
get topic 列表
./kafka-topics.sh --list --bootstrap-server 192.168.2.165:9092
./kafka-topics.sh --zookeeper 10.103.22.130:2181/kafka --list# out
__consumer_offsets
topic1
kafka-image-topic2
get topic 详情
./kafka-topics.sh --zookeeper 10.103.22.130:2181 --describe --topic topic-a
修改topic
修改分区级别参数(如增加partition)
./kafka-topics.sh --zookeeper 10.103.22.130:2181 --alter --topic ttt1 --partitions 2## out
WARNING: If partitions are increased for a topic that has a key, the partition logic or ordering of the messages will be affected
Adding partitions succeeded
删除topic
- 前提是把
kafka配置文件server.properties中的delete.topic.enable设置为true
./kafka-topics.sh --zookeeper 192.168.2.165:2181 --delete --topic <topic_name>
设置消息大小上限
- topic级别静态参数用–zookeeper, 动态参数才用–bootstrap-server
./kafka-configs.sh --zookeeper 10.103.22.130:2181 --entity-type topics --entity-name ttt1 --alter --add-config max.message.bytes=10485760## out
Completed Updating config for entity: topic 'ttt1'.
生产
查看生产
./kafka-console-producer.sh --broker-list 192.168.2.158:9092 --topic topic-a
生产消息
./kafka-console-producer.sh --topic topic-a --bootstrap-server broker:9092
> 进站去重车数据如下:
> {"Ts":1677507305663,"Data":"99990000","Info":1080}}参考
查看消费
server
# 输入./kafka-console-consumer.sh --bootstrap-server 192.168.2.111:9092 --topic topic-a
或 ./kafka-console-consumer.sh --zookeeper 127.0.0.1:2181/kafka --topic topic-a./kafka-console-consumer.sh --bootstrap-server 192.168.2.142:32400 --topic ttt```bash
zk启动 brew services start zookeeper或zkServer start
/usr/local/Cellar/kafka/2.4.0/libexec/bin
查看 offset
如果希望根据时间,找offset,可以有如下方法:
- 找到指定时间的
*.index和 *.log文件,文件名即为 offset。
-rw-r--r-- 1 root root 43 Nov 28 2021 partition.metadata
-rw-r--r-- 1 root root 10 Nov 8 12:30 00000000000000380329.snapshot
-rw-r--r-- 1 root root 10485756 Nov 8 12:31 00000000000000380329.timeindex
-rw-r--r-- 1 root root 10485760 Nov 8 12:31 00000000000000380329.index
drwxr-xr-x 2 root root 4096 Nov 8 12:31 ./
-rw-r--r-- 1 root root 3622 Nov 8 12:33 00000000000000380329.log
drwxr-xr-x 77 root root 4096 Nov 8 12:34 ../
查看积压
server
# 输入
cd ~/deep/kafka/kafka/bin
watch -n 1 ./kafka-consumer-groups.sh --bootstrap-server 192.168.2.111:9092 --describe --group topic-a# 输出:其中lag有值表示积压。
Note: This will only show information about consumers that use the Java consumer API (non-ZooKeeper-based consumers).
TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID
topic-a 0 159955 159955 0 UBUNTU.local-61e8b3d0-1456-49ce-8656-fe18cab4026a
client has run out of available brokers to talk to (Is your cluster reachable?)报错的调试
- kafka基于zookeeper做一致性校验,一个topic必须对应一个broker才行,如果importer出现报错
[ERROR] kafka %v create producer failed:client has run out of available brokers to talk to (Is your cluster reachable?)的话,可能是kafka有问题,可能是因为offset不一致导致紊乱,比较暴力的方式是删掉zookeeper和kafka的日志。
原理
- producer=》分为多个partition存(例如分为p1、p2、p3…p10)=》每个consumer分别从一个不同的partition读(consumer1读p1的话,consumer2就不能读p1了)。
UI 工具
Kafka Offset Explorer 支持Mac、Win、Linux
go sarama库使用
Shopify/sarama库
consumer
可以用 NewConsumerGroup() 创建,也可以先 NewClient() 再 NewConsumerGroupFromClient() 创建。
我们需要实现 Setup()、ConsumeClaim()、CleanUp() 三个回调函数,sarama 库会调度上述函数。
如果需要重置 Offset,可以在 Setup() 内通过 ResetOffset() 实现。
完整代码如下:
package kafkaimport ("context""github.com/Shopify/sarama"log "github.com/siruspen/logrus""lonk/configs""strconv""time"
)func StartConsumerGroup(ctx context.Context, conf *configs.KafkaInputConfig, msgHandler KafkaMsgHandler) {cli, err := newConsumerGroup(conf) // 新建一个 client 实例if err != nil {log.Fatalf("[newConsumerGroup] conf: %v, err: %v", conf, err)}k := kafkaConsumerGroup{msgHandler: msgHandler,ready: make(chan bool, 0), // 标识 consumer 是否 readypartitionInitialOffsetMap: conf.PartitionInitialOffsetMap,}go func() {defer cli.Close()for {// Consume().newSession().newConsumerGroupSession() 先调用 Setup(); 再开多个协程(每个协程都用for循环持续调用consume().ConsumeClaim()来处理消息); Consume() 内部的 <-sess.ctx.Done() 会阻塞if err := cli.Consume(ctx, []string{conf.Topic}, &k); err != nil {log.Errorln("Error from consumer", err)}if ctx.Err() != nil { // 若 ctx.cancel() 而会引发 cli.Consume() 内部对 ctx.Done() 的监听,从而结束 cli.Consume() 的阻塞, 并return}k.ready = make(chan bool, 0) // 当 rebalanced 时 cli.Consume() 会退出且 ctx.Err() == nil, 则重置此 channel, 继续在下一轮 for 循环调用 Consume()}}()<-k.ready // 直到 close(consumer.ready) 解除阻塞log.Infoln("Sarama consumer up and running!...")
}func newConsumerGroup(conf *configs.KafkaInputConfig) (sarama.ConsumerGroup, error) {sConf := sarama.NewConfig()sConf.Version = sarama.V2_8_0_0sConf.Consumer.Offsets.Initial = sarama.OffsetOldestsConf.Consumer.Offsets.Retention = 7 * 24 * time.Hourcli, err := sarama.NewClient(conf.Brokers, sConf)if err != nil {log.Fatalf("[NewClient] conf: %v, err: %v", sConf, err)}consumerGroup, err := sarama.NewConsumerGroupFromClient(conf.Group, cli)if err != nil {log.Fatalf("[NewConsumerGroupFromClient] conf: %v, err: %v", sConf, err)}return consumerGroup, nil
}// Consumer represents a Sarama consumer group consumer
type kafkaConsumerGroup struct {msgHandler func(message *sarama.ConsumerMessage)ready chan boolpartitionInitialOffsetMap map[string]int64
}// Setup 回调函数 is run at the beginning of a new session, before ConsumeClaim
func (k *kafkaConsumerGroup) Setup(session sarama.ConsumerGroupSession) error {for topic, partitions := range session.Claims() {for _, partition := range partitions {initialOffset, ok := k.partitionInitialOffsetMap[strconv.Itoa(int(partition))]if !ok {log.Fatalf("invalid topic:%v, partition: %v", topic, partition)}log.Infof("Sarama Consumer is resetting offset to %v:%v:%v", topic, partition, initialOffset)session.ResetOffset(topic, partition, initialOffset, "")}}close(k.ready) // 启动后此处会标记 ready, 使 StartKafkaConsumer() 不再阻塞return nil
}// Cleanup 回调函数 is run at the end of a session, once all ConsumeClaim goroutines have exited
func (k *kafkaConsumerGroup) Cleanup(sarama.ConsumerGroupSession) error {log.Infoln("Sarama Consumer is cleaning up!...")return nil
}// ConsumeClaim 回调函数 must start a consumer loop of ConsumerGroupClaim's Messages().
func (k *kafkaConsumerGroup) ConsumeClaim(session sarama.ConsumerGroupSession, claim sarama.ConsumerGroupClaim) error {// NOTE: Do not move the code below to a goroutine. The `ConsumeClaim` itself is called within a goroutine, see: https://github.com/Shopify/sarama/blob/master/consumer_group.go#L27-L29for {select {case message := <-claim.Messages():k.msgHandler(message)session.MarkMessage(message, "")// Should return when `session.Context()` is done. If not, will raise `ErrRebalanceInProgress` or `read tcp <ip>:<port>: i/o timeout` when kafka rebalance. see: https://github.com/Shopify/sarama/issues/1192case <-session.Context().Done():return nil}}
}
参考:官方 consumerGroup 的 example
参考:sarama consumer group 的使用
参考:sarama partition consumer 根据 time 指定 offset
相关文章:
【Kafka】超详细介绍
文章目录 概念部署方案磁盘网络CPUpartition的数量 命令查看版本找kafka和zookeeper的ip/porttopic创建 topic查看get topic 列表get topic 详情 修改topic修改分区级别参数(如增加partition) 删除topic设置消息大小上限 生产查看生产生产消息 查看消费server 查看 offset查看积…...

2023 华为 Datacom-HCIE 真题题库 07/12--含解析
多项选择题 1.[试题编号:190187] (多选题)如图所示的拓扑采用了VXLAN分布式网关,SW1上的VBDIF10配置了:arp-proxy local enable命令,则以下描述中正确的有哪些项? A、SW1收到PC1发往PC2的报文&…...

Spring的作用域和生命周期
目录 1.Bean的作用域 2.Bean的作用域的分类 3.设置作用域 4.Spring的执行流程(生命周期) 5.Bean的生命周期 1.Bean的作用域 lombok (dependency依赖) 是为了解决代码的冗余(比如说get和set方法)那些构造…...
岭回归有看点:正则化参数解密,显著性不再成问题!
一、概述 「L2正则化(也称为岭回归)」 是一种用于线性回归模型的正则化方法,它通过在模型的损失函数中添加一个惩罚项来防止过拟合。L2正则化的惩罚项是模型参数的平方和,乘以一个正则化参数λ,即: L2正则化…...

Android 12.0修改recovery 菜单项字体大小
1.概述 在Android 12.0进入recovery模式后,界面会g_menu_actions 菜单选项和 提示文字,而这些文字的大小不像上层一样是通过设置属性来表示大小的 而它确是通过字体png图片的大小来计算文字的宽和高的,然后可以修改字体大小 2. 修改recovery 菜单项字体大小的核心类 buil…...
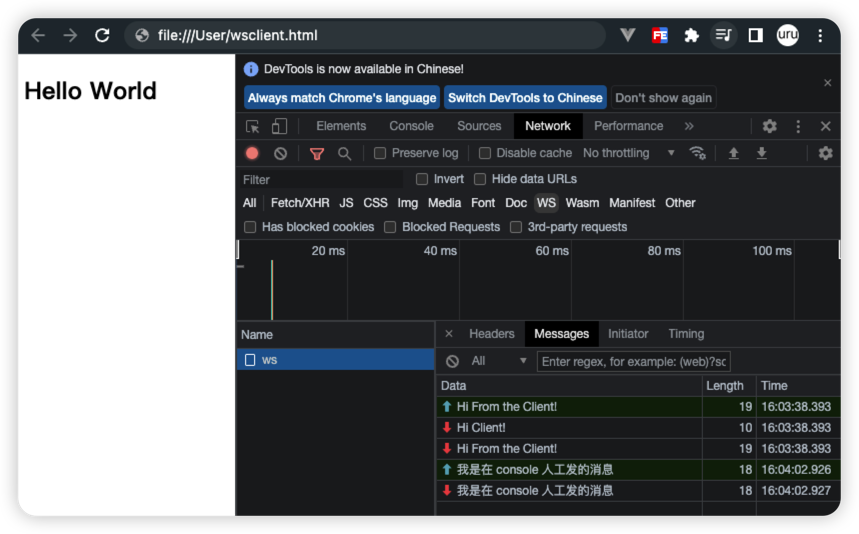
【计算机网络】 7、websocket 概念、sdk、实现
文章目录 一、背景二、简介三、client3.1 ws 构造函数3.2 ws.readyState3.3 ws.onopen3.4 ws.onclose3.5 ws.onmessage3.6 ws.send3.7 ws.bufferedAmount3.8 ws.onerror 四、server4.1 go4.1.1 apifox client4.1.2 js client 五、范式 一、背景 已经有了 http 协议,…...
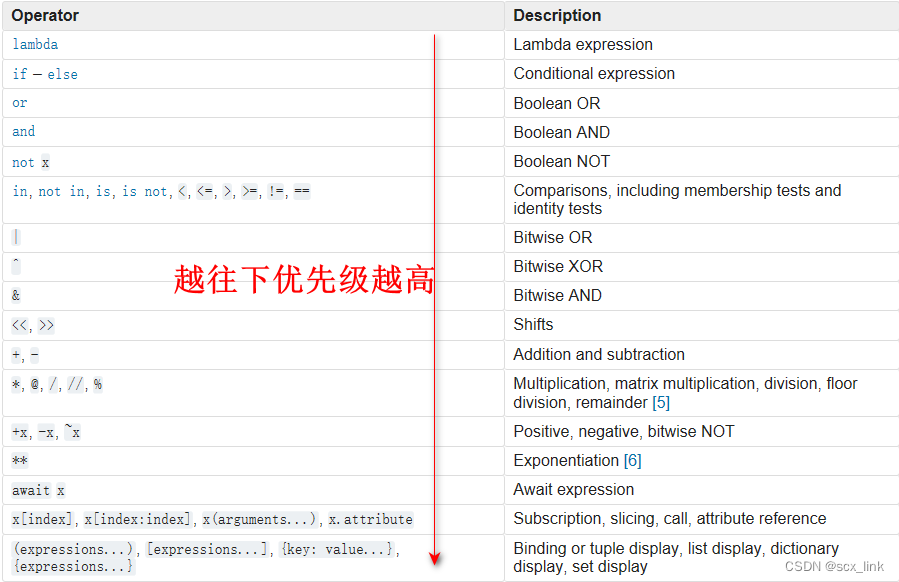
python中的常见运算符
文章目录 算数运算符赋值运算关系运算符逻辑运算符非布尔值的与或非运算条件运算符(也叫三元运算符)运算符的优先级 算数运算符 加法运算符(如果两个字符串之间进行加法运算,则会进行拼串操作) - 减法运算符 * 乘法运算符(如果将字…...

TypeScript类型
TypeScript 是什么? 是以avaScript为基础构建的语言个一JavaScript的超集。可以在任何支持JavaScript的平台中执行。TypeScript扩展了JavaScript,并添加了类型。TS不能被JS解析器直接执行,需要编译成js。 基本类型 声明完变量直赴进行赋值 let c: boo…...
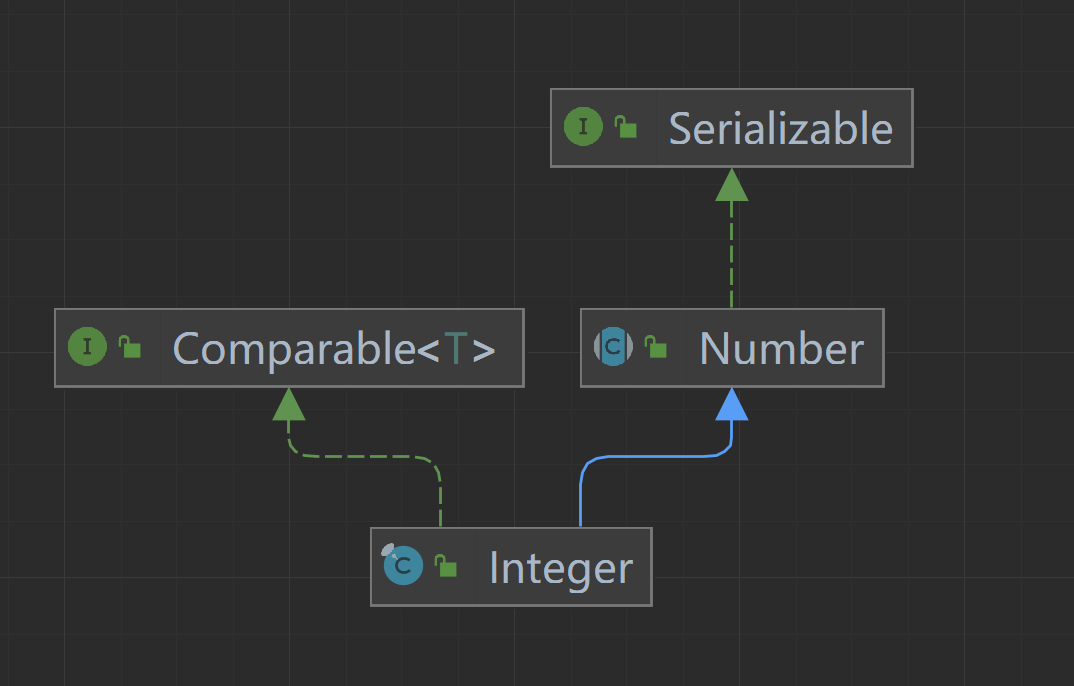
Integer源码
介绍 Integer是int类型的包装类,继承自Number抽象类,实现了Comparable接口。提供了一些处理int类型的方法,比如int到String类型的转换方法或String类型到int类型的转换方法,当然也包含与其他类型之间的转换方法。 Comparable提供…...
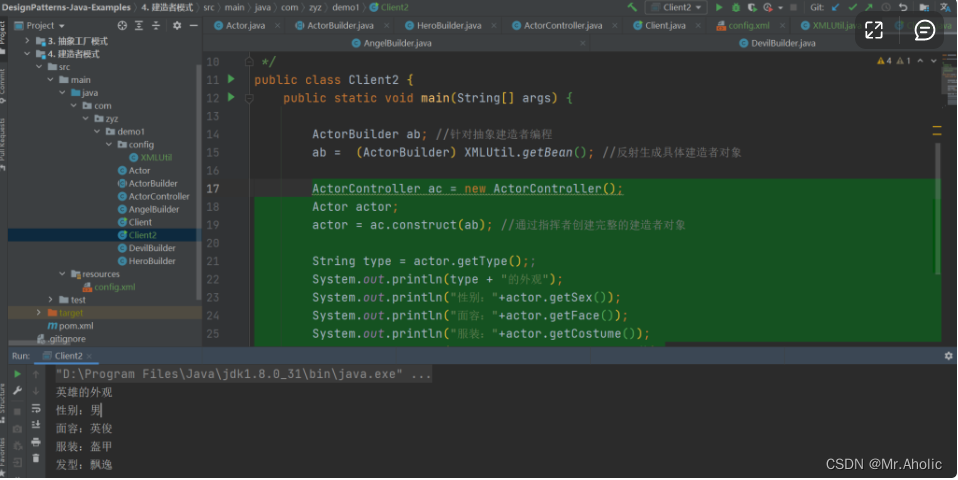
【四】设计模式~~~创建型模式~~~建造者模式(Java)
【学习难度:★★★★☆,使用频率:★★☆☆☆】 4.1. 模式动机 无论是在现实世界中还是在软件系统中,都存在一些复杂的对象,它们拥有多个组成部分,如汽车,它包括车轮、方向盘、发送机等各种部件…...
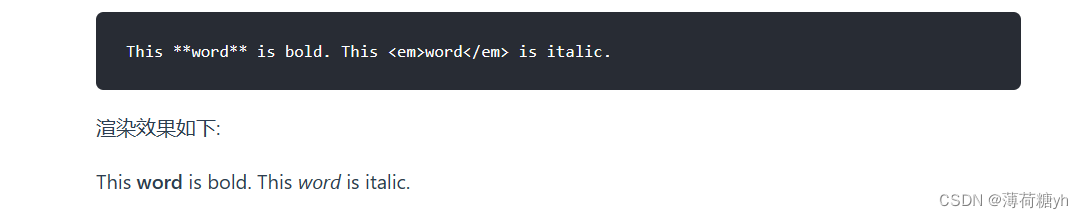
MarkDown的基本使用方法
为了给官方的文档知识总结:Markdown 基本语法 | Markdown 官方教程 #空格内容:‘#’表示标题的等级,越少表示标题级别越高(字越大) 在一行的末尾加两个或多个空格再回车,就是我们普通的文本回车。【还有一…...

IDEA 安装配置步骤详解
引言 IntelliJ IDEA 是一款功能强大的集成开发环境,它具有许多优势,适用于各种开发过程。本文将介绍 IDEA 的主要优势,并提供详细的安装配置步骤。 介绍 IntelliJ IDEA(以下简称 IDEA)之所以被广泛使用,…...
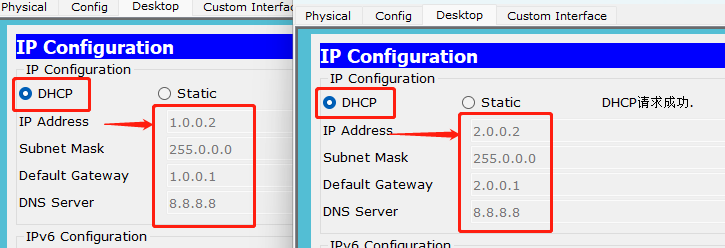
【网络】· 路由器中配置单臂路由和DHCP,VTP原理
目录 🍉单臂路由的工作原理 🥝交换机配置 🥝路由器配置 🍉路由器配置DHCP 🥝配置实例 🥝路由器配置 🥝验证 🍉VTP工作原理 🥝VTP模式 🥝VTP通告 🥝…...

Python 子域名扫描工具:使用多线程优化
部分数据来源:ChatGPT 本文仅用于信息安全的学习,请遵守相关法律法规,严禁用于非法途径。若观众因此作出任何危害网络安全的行为,后果自负,与本人无关。 摘要:子域名扫描是一个重要的安全工作,它可以发现目标网站的更多威胁和漏洞。本文介绍了如何使用 Python 来编写一…...
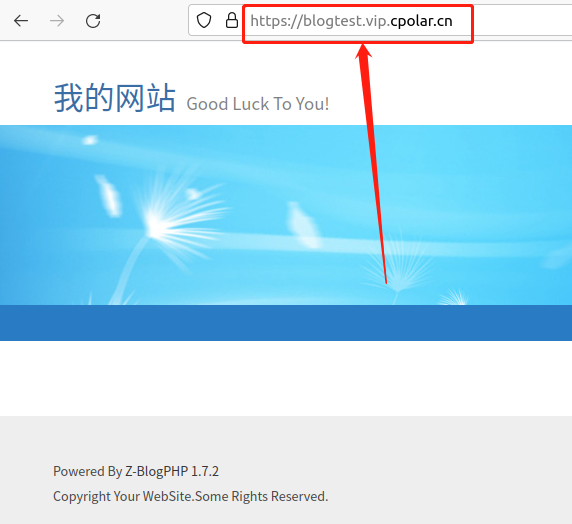
宝塔面板一键部署Z-Blog博客 - 内网穿透实现公网访问
文章目录 1.前言2.网站搭建2.1. 网页下载和安装2.2.网页测试2.3.cpolar的安装和注册 3.本地网页发布3.1.Cpolar临时数据隧道3.2.Cpolar稳定隧道(云端设置)3.3.Cpolar稳定隧道(本地设置) 4.公网访问测试5.结语 转发自cpolar极点云的…...

深入理解设计原则之单一职责原则(SRP)
系列文章目录 C高性能优化编程系列 深入理解设计原则系列 深入理解设计模式系列 高级C并发线程编程 SRP:单一职责原则 系列文章目录1、单一职责原则的定义和解读2、单一职责原则案例解读2.1、违背单一职责原则反面案例2.2、违背单一职责原则反面案例 - 解决方案 3…...

钉钉群通过短信转发器接收手机短信消息
1.短信转发器官网下载 下载地址 首发地址:https://github.com/pppscn/SmsForwarder/releases国内镜像:https://gitee.com/pp/SmsForwarder/releases网盘下载:https://wws.lanzoui.com/b025yl86h 访问密码:pppscn 使用文档 首发…...

【C++模版】模版进阶 {非类型模版参数; 模版的特化; 模版的分离编译; 模版总结}
一、非类型模版参数 模板参数分类型形参与非类型形参。 类型形参:出现在模板参数列表中,跟在class或者typename之后的参数类型名称。非类型形参:就是用一个常量作为类(函数)模板的一个参数,在类(函数)模板中可将该参数当成常量来…...
Azure Active Directory 的功能和优势
Azure Active Directory (Azure AD) 是 Microsoft 基于云的多租户目录和标识管理服务。 Azure AD 有助于支持用户访问资源和应用程序,例如: 位于企业网络上的内部资源和应用。 Microsoft 365、Azure 门户和 SaaS 应用程序等外部资源。 为组织开发的云应…...
mysql查询语句执行过程及运行原理命令
Mysql查询语句执行原理 数据库查询语句如何执行? DML语句首先进行语法分析,对使用sql表示的查询进行语法分析,生成查询语法分析树。语义检查:检查sql中所涉及的对象以及是否在数据库中存在,用户是否具有操作权限等视…...
)
别再死记硬背了!用Python实战案例帮你彻底搞懂假设检验(附代码与避坑指南)
用Python实战拆解假设检验:从数据模拟到结果解读的避坑指南假设检验是数据分析师和机器学习工程师工具箱中最常用的统计工具之一,但很多人在学习过程中都会被各种检验方法、P值解读和原假设设定绕得晕头转向。本文将通过Python代码实战,带你用…...

响应式图像:优化不同设备的图片展示
响应式图像:优化不同设备的图片展示 什么是响应式图像? 响应式图像是指能够根据设备特性(屏幕尺寸、分辨率、网络条件等)自动选择最合适的图片版本。 为什么需要响应式图像? 性能优化:小屏幕加载小图片带宽…...

显卡驱动彻底清理解决方案:Display Driver Uninstaller专业使用指南
显卡驱动彻底清理解决方案:Display Driver Uninstaller专业使用指南 【免费下载链接】display-drivers-uninstaller Display Driver Uninstaller (DDU) a driver removal utility / cleaner utility 项目地址: https://gitcode.com/gh_mirrors/di/display-drivers…...

BepInEx配置管理器完整指南:一键管理所有游戏模组设置
BepInEx配置管理器完整指南:一键管理所有游戏模组设置 【免费下载链接】BepInEx.ConfigurationManager Plugin configuration manager for BepInEx 项目地址: https://gitcode.com/gh_mirrors/be/BepInEx.ConfigurationManager 你是否厌倦了为每个游戏模组单…...

Kubernetes自定义资源:扩展Kubernetes API的能力
Kubernetes自定义资源:扩展Kubernetes API的能力 一、Kubernetes自定义资源概述 1.1 自定义资源的定义 Kubernetes自定义资源(Custom Resource,CR)是指用户自定义的资源类型,它扩展了Kubernetes API,允许用…...

从零入门 OpenAI Codex|登录、权限、终端、记忆配置全实操
我先来简单介绍一下Codex。 Codex是 OpenAI 推出的 AI 编程模型与工具系列。Codex 最初于 2021 年作为 OpenAI API 的一部分发布,基于 GPT 架构专门针对代码数据进行了训练。2024 至 2025 年间,OpenAI 推出了独立的 Codex CLI命令行工具,使其…...

CANN-ATB量化推理-昇腾NPU上W8A8量化为什么比W4A16更实用
Llama2-70B 权重 140GB,8 卡 TP 刚好放得下但没什么余量给 KV Cache。W8A8 量化把权重从 fp16 压到 int8,权重体积减半,4 卡就能跑 70B。W4A16 理论上压得更狠(4 倍压缩),但精度损失在实际业务里往往不可接…...

嵌入式C语言开发中的三大致命陷阱
很多人刚开始学习C语言时,会觉得: 会指针 会结构体 会寄存器操作 能驱动外设 似乎就已经掌握了嵌入式开发。 但真正进入项目后才会发现: 嵌入式开发最难的,从来不是语法,而是“代码与硬件现实世界之间的耦合”。 同样一句代码: 在PC上可能只是运行错误; 在单片机里却可…...
)
【云计算学习之路】学习Centos7系统:服务搭建(VSFTP)
FTP简介及快速构建VSFTP服务器FTP简介及快速构建VSFTP服务器一、前言二、FTP服务核心简介2.1 FTP基本概念2.2 FTP两种工作模式1. 主动模式(Active Mode)2. 被动模式(Passive Mode)2.3 VSFTP服务核心优势三、实验环境预处理3.1 网络…...

windows VS工具判断动态库是32位还是64位
dumpbin /headers yourfile.dll | findstr "machine"...