牛客网刷题学习SQL(二)
SQL22 统计每个学校的答过题的用户的平均答题数
描述
运营想要了解每个学校答过题的用户平均答题数量情况,请你取出数据。
用户信息表 user_profile,其中device_id指终端编号(认为每个用户有唯一的一个终端),gender指性别,age指年龄,university指用户所在的学校,gpa是该用户平均学分绩点,active_days_within_30是30天内的活跃天数。
device_id gender
age
university gpa active_days_within_30
2138 male 21 北京大学 3.4 7
3214
male NULL 复旦大学 4 15
6543 female 20 北京大学 3.2 12
2315 female 23 浙江大学 3.6 5
5432 male 25 山东大学 3.8 20
2131 male 28 山东大学 3.3 15
4321 male
28 复旦大学 3.6 9
第一行表示:用户的常用信息为使用的设备id为2138,性别为男,年龄21岁,北京大学,gpa为3.4,在过去的30天里面活跃了7天
最后一行表示:用户的常用信息为使用的设备id为4321,性别为男,年龄28岁,复旦大学,gpa为3.6,在过去的30天里面活跃了9天
答题情况明细表 question_practice_detail,其中question_id是题目编号,result是答题结果。
device_id question_id result
2138 111 wrong
3214 112 wrong
3214 113
wrong
6543 111 right
2315 115 right
2315 116 right
2315 117 wrong
5432 118 wrong
5432 112 wrong
2131 114 right
5432 113 wrong
第一行表示用户的常用信息为使用的设备id为2138,在question_id为111的题目上,回答错误
…
最后一行表示用户的常用信息为使用的设备id为5432,在question_id为113的题目上,回答错误
请你写SQL查找每个学校用户的平均答题数目(说明:某学校用户平均答题数量计算方式为该学校用户答题总次数除以答过题的不同用户个数)根据示例,你的查询应返回以下结果(结果保留4位小数),注意:结果按照university升序排序!!!
university avg_answer_cnt
北京大学 1.0000
复旦大学 2.0000
山东大学 2.0000
浙江大学 3.0000
解释:
第一行:北京大学总共有2个用户,2138和6543,2个用户在question_practice_detail里面答了2题,平均答题数目为2/2=1.0000
…
最后一行:浙江大学总共有1个用户,2315,这个用户在question_practice_detail里面答了3题,平均答题数目为3/1=3.0000
select university,count(question_id)/count(distinct qpd.device_id) avg_answer_cnt
from question_practice_detail qpd
left join user_profile up
on qpd.device_id=up.device_id
group by university# group by university 按学校区分
# count(distinct qpd.device_id) 统计每个学校的总用户,注意:由于两个表都有device_id所以这里需要指出是哪一个
# count(question_id) 统计每个学校总答题的记录数# select university,
# count(question_id) / count(distinct qpd.device_id) as avg_answer_cnt
# from question_practice_detail as qpd
# inner join user_profile as up
# on qpd.device_id=up.device_id
# group by university
==注意:==虽然上面sql返回的结果正确但是这并不意味着就是正确的。
==原因:==题目中提到结果按照university升序排序!!!
所以代码中需要添加一句order by语句
select university,count(question_id)/count(distinct qpd.device_id) avg_answer_cnt
from question_practice_detail qpd
left join user_profile up
on qpd.device_id=up.device_id
group by university
order by avg_answer_cnt asc;
总结一下:
该题考查distinct、join on、left join on、inner join on 、group by、order by这些关键词的使用
去重Distinct
- SELECT DISTINCT语句的作用是查询指定列的所有不同的值,并将其作为结果集返回。也就是说,如果一个表中某个字段有多个重复的值,使用SELECT DISTINCT语句可以去除这些重复的值,只返回该字段的不同值。使用SELECT DISTINCT语句可以方便地对数据进行去重处理,避免重复数据造成的混淆和误操作
按某种属性排序查询 ORDER BY
-
ORDER BY是SQL语句中的一个关键字,用于对查询结果进行排序。它可以对查询结果中的一个或多个字段进行升序或降序排序。ORDER BY的基本语法如下:
SELECT column1, column2, … FROM table_name ORDER BY column_name [ASC|DESC];
其中,column1、column2等是要查询的字段,table_name是要查询的表名,column_name是要排序的字段名。ASC表示升序排序,DESC表示降序排序。默认情况下,ORDER BY按升序排序。
例如,要查询一个学生表,按成绩从高到低排序,可以写成:
SELECT name, score FROM student ORDER BY score DESC;
这样可以将查询结果按照成绩从高到低排序,方便查看学生的排名情况
相关文章:
)
牛客网刷题学习SQL(二)
SQL22 统计每个学校的答过题的用户的平均答题数 描述 运营想要了解每个学校答过题的用户平均答题数量情况,请你取出数据。 用户信息表 user_profile,其中device_id指终端编号(认为每个用户有唯一的一个终端),gender指…...

深蓝学院 C++笔记 先导篇章 - 绪论
一、介绍-老师寄语 为什么选择C? 高性能解决问题 二、C推荐书目 1. 基础 《C Primer》,Stanley B. Lippman 等著,王刚、杨巨峰等译 2. 进阶 《Effective C》,Scott Meyers 著,侯捷译。 《More Effective C》&am…...

R7-19 天梯赛团队总分
“天梯赛”的竞赛题目一共有 15 道,分为 3 个梯级: 基础级设 8 道题,其中 5 分、10 分、15 分、20 分的题各 2 道,满分为 100 分;题目编号相应为L1-X,X取1,2,3,4,5,6,7,8,分别表示基础级的8道题…...

使用 Kotlin 的 Opt-in (选择加入)功能注解API提示当前非稳定API
前言 之前在给公司项目封装库的时候,领导告诉我封装的漂亮一点,等以后公司发展起来了可能需要把这个库提供给第三方接入使用。 此时,就有这么一个问题:某些功能函数使用条件比较苛刻,直接使用可能会出现意想不到的后…...

webpack配置排除打包
webpack配置排除打包 思路 打包时,不要把类似于element-ui第三方的这些包打进来 从网络上,通过url地址直接引入这些包 操作 (1)先找到 vue.config.js, 添加 externals 项,具体如下: config…...

HNU-操作系统OS-ucoreLab系列-感悟
谨以此片篇,献给熬夜的8个晚上,以及逝去的时光。 感悟: 今天结束了所有的Lab实验(2023.6.3),感慨万千。 喜是这个实验终于结束了,悲是其实有好多地方我都没有理解。 应该指出,由于验收的助教学长学姐们的宽容,HNU实际上在验收这一块的要求还是比较低的。 但是这个…...
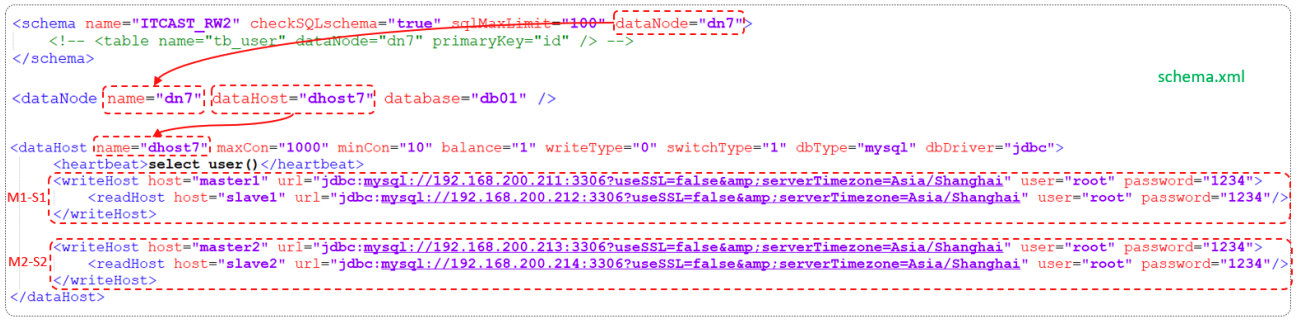
MySQL运维篇(三)
五.读写分离 5.1 介绍 读写分离,简单地说是把对数据库的读和写操作分开,以对应不同的数据库服务器。主数据库提供写操作,从数据库提供读操作,这样能有效地减轻单台数据库的压力。 通过MyCat即可轻易实现上述功能,不仅可以支持MySQL&#x…...

Lecture 2 Text Preprocessing
目录 Some DefinitionsReasons for PreprocessingPreprocessing StepsSentence Segmentation 句子分割Binary Classifier 二元分类器Word Tokenization: English 英文词元标记化Word Tokenization: Chinese 中文词元标记化Word Tokenization: German 德语词元标记化Subword Tok…...
web练习第二周
前言:(博主个人学习笔记,不用看)web练习第二周,仅做出前3题。相比于第一周,难度大幅增加,写题时就算看了wp还是像个无头苍蝇一样到处乱创,大多都是陌生知识点,工具的使用…...
)
LC-1439. 有序矩阵中的第 k 个最小数组和(二分答案、多路归并)
1439. 有序矩阵中的第 k 个最小数组和 难度困难120 给你一个 m * n 的矩阵 mat,以及一个整数 k ,矩阵中的每一行都以非递减的顺序排列。 你可以从每一行中选出 1 个元素形成一个数组。返回所有可能数组中的第 k 个 最小 数组和。 示例 1:…...

一文1000字从0到1实现Jenkins+Allure+Pytest的持续集成
一、配置 allure 环境变量 1、下载 allure是一个命令行工具,可以去 github 下载最新版:https://github.com/allure-framework/allure2/releases 2、解压到本地 3、配置环境变量 复制路径如:F:\allure-2.13.7\bin 环境变量、Path、添加 F:\…...
)
给一个有序数组生成平衡搜索二叉树(java)
给一个有序数组生成平衡搜索二叉树 给一个有序数组生成平衡搜索二叉树递归生成二叉树专题 给一个有序数组生成平衡搜索二叉树 给定一个有序的数组,用这个数组生成一个平衡搜索二叉树. 这个题还是很简单的,知道什么时平衡搜索二叉树就行了, 左边值小于头节点值,头节点值小于右边…...

【JavaSE】Java基础语法(二十二):包装类
文章目录 1. 基本类型包装类2. Integer类3. 自动拆箱和自动装箱4. int和String类型的相互转换 1. 基本类型包装类 基本类型包装类的作用 将基本数据类型封装成对象的好处在于可以在对象中定义更多的功能方法操作该数据常用的操作之一:用于基本数据类型与字符串之间的…...
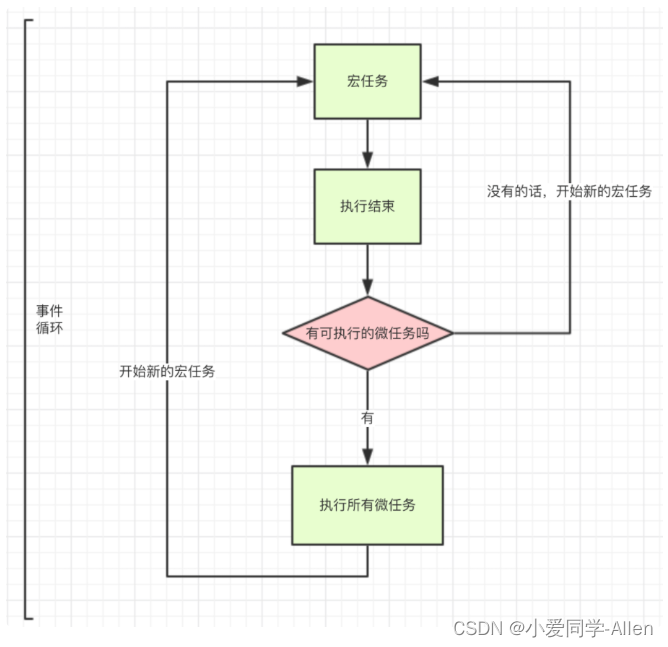
javascript基础十八:说说你对JavaScript中事件循环的理解
一、是什么 JavaScript 在设计之初便是单线程,即指程序运行时,只有一个线程存在,同一时间只能做一件事 为什么要这么设计,跟JavaScript的应用场景有关 JavaScript 初期作为一门浏览器脚本语言,通常用于操作 DOM &#…...

详解js中的浅拷贝与深拷贝
详解js中的浅拷贝与深拷贝 1、前言1.1 栈(stack)和堆(heap)1.2 基本数据类型和引用数据类型1.2.1 概念1.2.2 区别1.2.3 基本类型赋值方式1.2.4 引用类型赋值方式 2、浅拷贝2.1 概念2.2 常见的浅拷贝方法2.2.1 Object.assign()2.2.…...

Day9 敏捷测试——敏捷开发的特征、什么是敏捷测试?、极限编程、极限测试
Day9 敏捷测试——敏捷开发的特征、什么是敏捷测试?、极限编程、极限测试 文章目录 Day9 敏捷测试——敏捷开发的特征、什么是敏捷测试?、极限编程、极限测试敏捷开发的特征1、迭代式开发2、增量交付3、及时反馈4、持续集成5、自我管理敏捷开发和迭代式开发的根本区别1、性质…...

k8s 维护node与驱逐pod
1.维护node节点 设置节点状态为不可调度状态,执行以下命令后,节点状态会多出一个SchedulingDisabled的状态,即新建的pod不会往该节点上调度,本身存在node中的pod保持正常运行 kubectl cordon k8s-node01 kubectl get node 2.驱…...
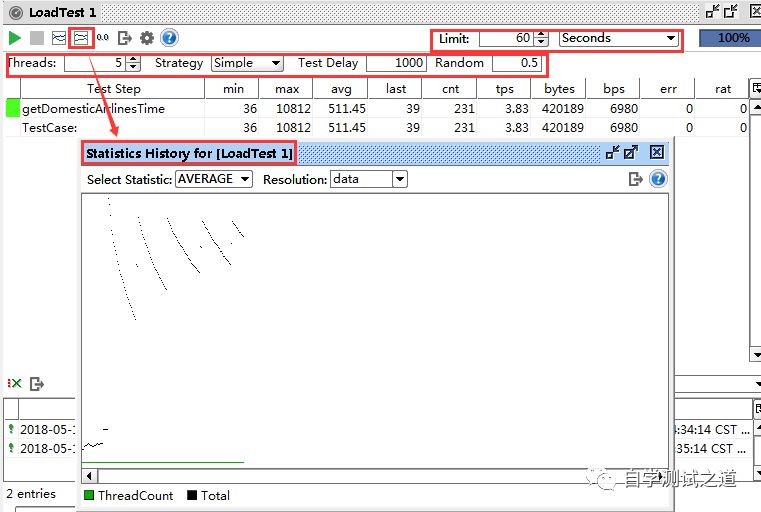
SouapUI接口测试之创建性能测试
SouapUI也是一个能生动的体现一个系统(项目)性能状态的工具,本篇就来说说如何在SouapUI工具下创建性能测试 一、创建测试用例 由于在《SouapUI接口测试之使用Excel进行参数化》篇已经创建好了测试用例,本篇就不讲解如何创建测试…...
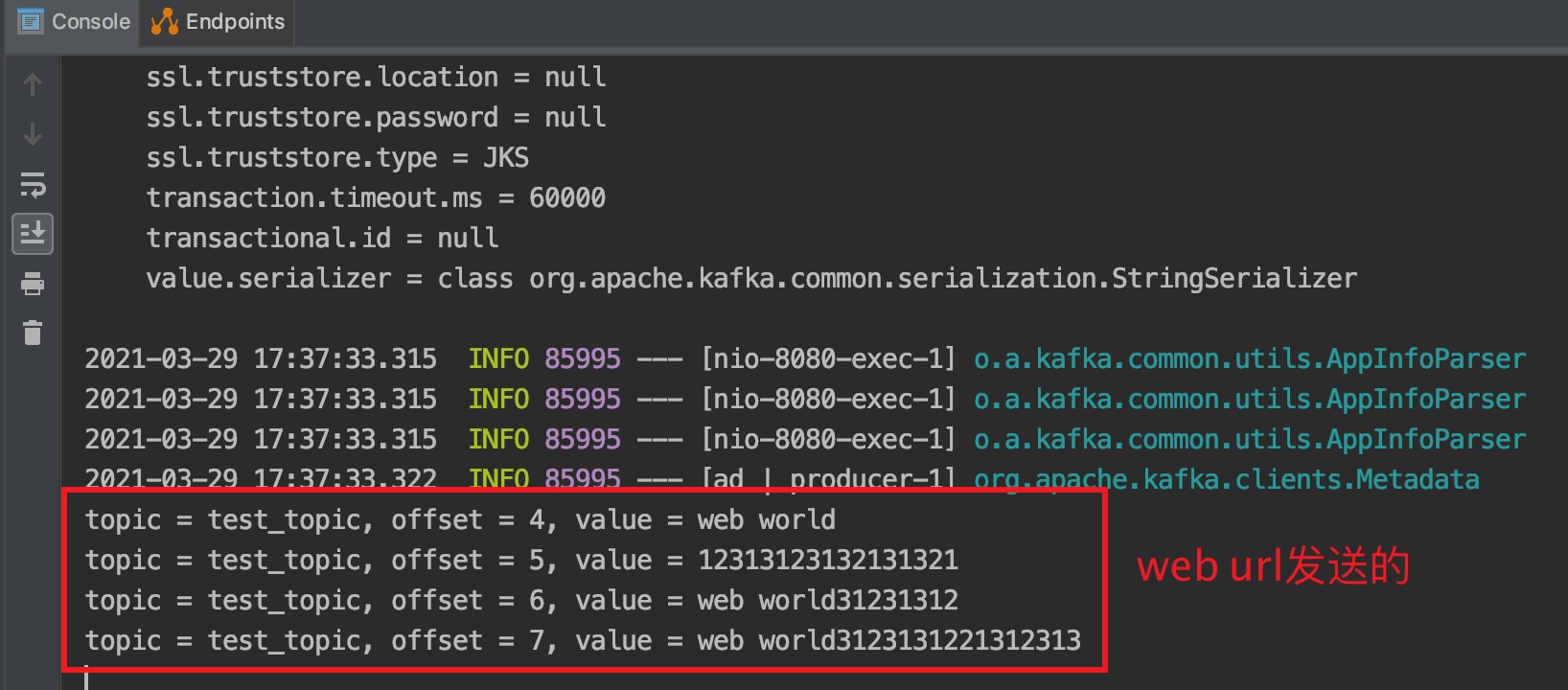
springboot整合kafka入门
kafka基本概念 producer: 生产者,负责发布消息到kafka cluster(kafka集群)中。生产者可以是web前端产生的page view,或者是服务器日志,系统CPU、memory等。 consumer: 消费者,每个consumer属于一个特定的c…...

Rust 笔记:Rust 语言中的字符串
Rust 笔记 Rust 语言中的字符串 作者:李俊才 (jcLee95):https://blog.csdn.net/qq_28550263?spm1001.2101.3001.5343 邮箱 :291148484163.com 本文地址:https://blog.csdn.net/qq_28550263/article/detail…...

CANN-NPU 显存回收策略:内存碎片整理与显存池化机制实战
一、显存碎片从哪来 1.1 碎片的两种形态 外部碎片——总空闲内存够用,但不连续。比如有 4 块 128MB 空闲,但需要一块 512MB 的连续内存,分配失败。 内部碎片——分配器按固定大小的块分配,实际使用的比分配的小。比如分配 400KB&a…...

Kubernetes StatefulSet深度解析:管理有状态应用的最佳实践
Kubernetes StatefulSet深度解析:管理有状态应用的最佳实践 一、StatefulSet概述 StatefulSet 是Kubernetes中用于管理有状态应用的控制器。它为Pod提供稳定的网络标识和持久化存储,确保Pod的有序部署、扩展和更新。 1.1 StatefulSet vs Deployment …...

无授权不感知、无穿戴可溯源:无感定位重构公安新型治安底座
无授权不感知、无穿戴可溯源:无感定位重构公安新型治安底座镜像视界浙江科技有限公司依托国家十四五重点课题研究成果、镜像视界浙江普陀时空大数据应用技术联合研究院联合研发体系与河南省电检院权威认证资质,以自研空间计算技术为根基打磨无感定位体系…...

PwnKit漏洞深度解析:pkexec环境变量劫持与Linux提权原理
1. 这个漏洞不是“又一个提权”,而是Linux权限模型的照妖镜你可能已经看过不少关于CVE-2021-4034的通报,标题里常带着“高危”“远程可利用”“影响所有主流发行版”这类字眼。但说实话,我第一次在Debian 11上复现成功时,并没有立…...

昇腾CANN manifest:仓库清单与版本管理实战
55 个独立仓库,每个仓库独立迭代——CANN 8.0 里的 ops-transformer 是哪个 commit?hccl 是 v2.1.3 还是 v2.2.0?runtime 和 driver 的版本是否兼容?manifest 仓库用一份 XML 格式的清单文件回答了所有这些问题。它是 CANN 发行版…...
)
从披萨到知识图谱:避开OWL本体建模的3个新手常见坑(Protege避坑指南)
从披萨到知识图谱:避开OWL本体建模的3个新手常见坑(Protege避坑指南) 本体建模是构建知识图谱的核心环节,而OWL(Web Ontology Language)作为W3C推荐的标准本体描述语言,在语义网和知识工程领域扮…...

跨境社媒运营真正难的 不是内容不够而是账号越来越没有“主线感”
很多团队做跨境社媒时,前期最容易把注意力放在内容数量上。 今天发没发,明天补几条,哪个平台还没铺,哪种形式最近更容易起量。 这些当然重要,因为账号在起步阶段,首先得先“动起来”。但真正做一段时间之后…...

写作压力小了!盘点2026年人气爆表的AI论文平台
一天写完毕业论文在2026年已不再是天方夜谭。2026年AI论文平台强势来袭,实测提速效果炸裂,覆盖选题构思、文献综述、降重润色、格式排版等核心场景,助你高效搞定论文,告别熬夜赶稿! 一、全流程王者:一站式搞…...

HTTPS抓包失败根因分析:证书信任链与全平台配置实战
1. 为什么HTTPS抓包不是“装个插件就完事”——从浏览器报错红锁说起你刚在Burp Suite里点开Proxy → Options → Import Burps CA Certificate,双击安装完证书,兴冲冲打开Chrome访问https://example.com,结果地址栏赫然挂着一把刺眼的红色锁…...

深度学习分段逼近实战:激活函数硬件友好型实现指南
1. 项目概述:为什么“分段逼近”不是数学游戏,而是深度学习落地的命脉“Mastering Deep Learning: The Art of Approximating Non-Linearities with Piecewise Estimations Part-2”——这个标题里藏着一个被太多教程刻意绕开的真相:深度学习…...