【Netty】一行简单的writeAndFlush都做了哪些事(十八)
文章目录
- 前言
- 一、源码分析
- 1.1 ctx.writeAndFlush 的逻辑
- 1.2 writeAndFlush 源码
- 1.3 ChannelOutBoundBuff 类
- 1.4 addMessage 方法
- 1.5 addFlush 方法
- 1.6 AbstractNioByteChannel 类
- 总结
前言
回顾Netty系列文章:
- Netty 概述(一)
- Netty 架构设计(二)
- Netty Channel 概述(三)
- Netty ChannelHandler(四)
- ChannelPipeline源码分析(五)
- 字节缓冲区 ByteBuf (六)(上)
- 字节缓冲区 ByteBuf(七)(下)
- Netty 如何实现零拷贝(八)
- Netty 程序引导类(九)
- Reactor 模型(十)
- 工作原理详解(十一)
- Netty 解码器(十二)
- Netty 编码器(十三)
- Netty 编解码器(十四)
- 自定义解码器、编码器、编解码器(十五)
- Future 源码分析(十六)
- Promise 源码分析(十七)
对于使用netty的小伙伴来说,我们想通过服务端往客户端发送数据,通常我们会调用ctx.writeAndFlush(数据)的方式。那么它都执行了那些行为呢,是怎么将消息发送出去的呢。
一、源码分析
下面的这个方法是用来接收客户端发送过来的数据,通常会使用ctx.writeAndFlush(数据)来向客户端发送数据。
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {System.out.println(" 接收到消息:" + msg);String str = "服务端收到:" + new Date() + msg;ctx.writeAndFlush(str);
}
1.1 ctx.writeAndFlush 的逻辑
private void write(Object msg, boolean flush, ChannelPromise promise) {//...AbstractChannelHandlerContext next = this.findContextOutbound(flush ? 98304 : '耀');Object m = this.pipeline.touch(msg, next);EventExecutor executor = next.executor();if (executor.inEventLoop()) {if (flush) {next.invokeWriteAndFlush(m, promise);} else {next.invokeWrite(m, promise);}} else {Object task;if (flush) {task = AbstractChannelHandlerContext.WriteAndFlushTask.newInstance(next, m, promise);} else {task = AbstractChannelHandlerContext.WriteTask.newInstance(next, m, promise);}if (!safeExecute(executor, (Runnable)task, promise, m)) {((AbstractChannelHandlerContext.AbstractWriteTask)task).cancel();}}}
从上述源码我们可以知道,WriteAndFlush()相对于Write(),它的flush字段是true。
- write:将需要写的 ByteBuff 存储到 ChannelOutboundBuffer中。
- flush:从ChannelOutboundBuffer中将需要发送的数据读出来,并通过 Channel 发送出去。
1.2 writeAndFlush 源码
public ChannelFuture writeAndFlush(Object msg) {return this.writeAndFlush(msg, this.newPromise());
}public ChannelPromise newPromise() {return new DefaultChannelPromise(this.channel(), this.executor());
}
writeAndFlush方法里提供了一个默认的 newPromise()作为参数传递。在Netty中发送消息是一个异步操作,那么可以通过往hannelPromise中注册回调监听listener来得到该操作是否成功。
在发送消息时添加监听
ctx.writeAndFlush(str,ctx.newPromise().addListener(new ChannelFutureListener(){@Overridepublic void operationComplete(ChannelFuture channelFuture) throws Exception{channelFuture.isSuccess();}
}));
继续向下一层跟进代码,AbstractChannelHandlerContext中的invokeWriteAndFlush的源码。
private void invokeWriteAndFlush(Object msg, ChannelPromise promise) {if (this.invokeHandler()) {this.invokeWrite0(msg, promise);this.invokeFlush0();} else {this.writeAndFlush(msg, promise);}}
从上述源码我们可以能够知道:
1、首先通过invokeHandler()判断通道处理器是否已添加到管道中。
2、执行消息处理 invokeWrite0方法:
- 首先将消息内容放入输出缓冲区中 invokeFlush0;
- 然后将输出缓冲区中的数据通过socket发送到网络中。
分析invokeWrite0执行的内容,源码如下:
private void invokeWrite0(Object msg, ChannelPromise promise) {try {((ChannelOutboundHandler)this.handler()).write(this, msg, promise);} catch (Throwable var4) {notifyOutboundHandlerException(var4, promise);}}
((ChannelOutboundHandler)this.handler()).write是一个出站事件ChannelOutboundHandler,会由ChannelOutboundHandlerAdapter处理。
@Skip
public void write(ChannelHandlerContext ctx, Object msg, ChannelPromise promise) throws Exception {ctx.write(msg, promise);
}
接下来会走到ChannelPipeline中,来执行网络数据发送;我们来看DefaultChannelPipeline 中HeadContext的write方法源码
public void write(ChannelHandlerContext ctx, Object msg, ChannelPromise promise) {this.unsafe.write(msg, promise);
}
unsafe是构建NioServerSocketChannel或NioSocketChannel对象时,一并构建一个成员属性,它会完成底层真正的网络操作等。
我们跟进HenderContext的write() ,而HenderContext的中依赖的是unsafe.wirte()。所以直接去 AbstractChannel的Unsafe 源码如下:
public final void write(Object msg, ChannelPromise promise) {this.assertEventLoop();ChannelOutboundBuffer outboundBuffer = this.outboundBuffer;if (outboundBuffer == null) {// 缓存 写进来的 bufferthis.safeSetFailure(promise, this.newWriteException(AbstractChannel.this.initialCloseCause));ReferenceCountUtil.release(msg);} else {int size;try {// buffer Dirct化 , (我们查看 AbstractNioByteBuf的实现)msg = AbstractChannel.this.filterOutboundMessage(msg);size = AbstractChannel.this.pipeline.estimatorHandle().size(msg);if (size < 0) {size = 0;}} catch (Throwable var6) {this.safeSetFailure(promise, var6);ReferenceCountUtil.release(msg);return;}// 插入写队列 将 msg 插入到 outboundBuffer// outboundBuffer 这个对象是 ChannelOutBoundBuff 类型的,它的作用就是起到一个容器的作用// 下面看, 是如何将 msg 添加进 ChannelOutBoundBuff 中的outboundBuffer.addMessage(msg, size, promise);}
}
从上述源码中,我们可以看出,首先调用 assertEventLoop 确保该方法的调用是在reactor线程中;然后,调用 filterOutboundMessage() 方法,将待写入的对象过滤。下面我们来看看filterOutboundMessage方法的源码。
protected final Object filterOutboundMessage(Object msg) {if (msg instanceof ByteBuf) {ByteBuf buf = (ByteBuf)msg;return buf.isDirect() ? msg : this.newDirectBuffer(buf);} else if (msg instanceof FileRegion) {return msg;} else {throw new UnsupportedOperationException("unsupported message type: " + StringUtil.simpleClassName(msg) + EXPECTED_TYPES);}
}
从上述源码可以看出,只有ByteBuf以及 FileRegion可以进行最终的Socket网络传输,其他类型的数据是不支持的,会抛UnsupportedOperationException异常。并且会把堆 ByteBuf 转换为一个非堆的 ByteBuf 返回。也就说,最后会通过socket传输的对象时非堆的 ByteBuf 和 FileRegion。
在发送数据时,我们需要估算出需要写入的 ByteBuf 的size,我们来看看 DefaultMessageSizeEstimator 的HandleImpl类中的size()方法。
public final class DefaultMessageSizeEstimator implements MessageSizeEstimator {private static final class HandleImpl implements Handle {private final int unknownSize;private HandleImpl(int unknownSize) {this.unknownSize = unknownSize;}public int size(Object msg) {if (msg instanceof ByteBuf) {return ((ByteBuf)msg).readableBytes();} else if (msg instanceof ByteBufHolder) {return ((ByteBufHolder)msg).content().readableBytes();} else {return msg instanceof FileRegion ? 0 : this.unknownSize;}}}
}
通过ByteBuf.readableBytes()判断消息内容大小,估计待发送消息数据的大小,如果是FileRegion的话直接返回0,否则返回ByteBuf中可读取字节数。
接下来我们来看看是如何将 msg 添加进 ChannelOutBoundBuff 中的。
1.3 ChannelOutBoundBuff 类
ChannelOutboundBuffer类主要用于存储其待处理的出站写请求的内部数据。当 Netty 调用 write时数据不会真正地去发送而是写入到ChannelOutboundBuffer 缓存队列,直到调用 flush方法 Netty 才会从ChannelOutboundBuffer取数据发送。每个 Unsafe 都会绑定一个ChannelOutboundBuffer,也就是说每个客户端连接上服务端都会创建一个 ChannelOutboundBuffer 绑定客户端 Channel。
观察 ChannelOutBoundBuff 源码,可以看到以下四个属性:
public final class ChannelOutboundBuffer {//...private ChannelOutboundBuffer.Entry flushedEntry;private ChannelOutboundBuffer.Entry unflushedEntry;private ChannelOutboundBuffer.Entry tailEntry;private int flushed;//...}
-
flushedEntry :指针表示第一个被写到操作系统Socket缓冲区中的节点;
-
unFlushedEntry:指针表示第一个未被写入到操作系统Socket缓冲区中的节点;
-
tailEntry:指针表示ChannelOutboundBuffer缓冲区的最后一个节点。
-
flushed:表示待发送数据个数。
下面分别是三个指针的作用,示意图如下:
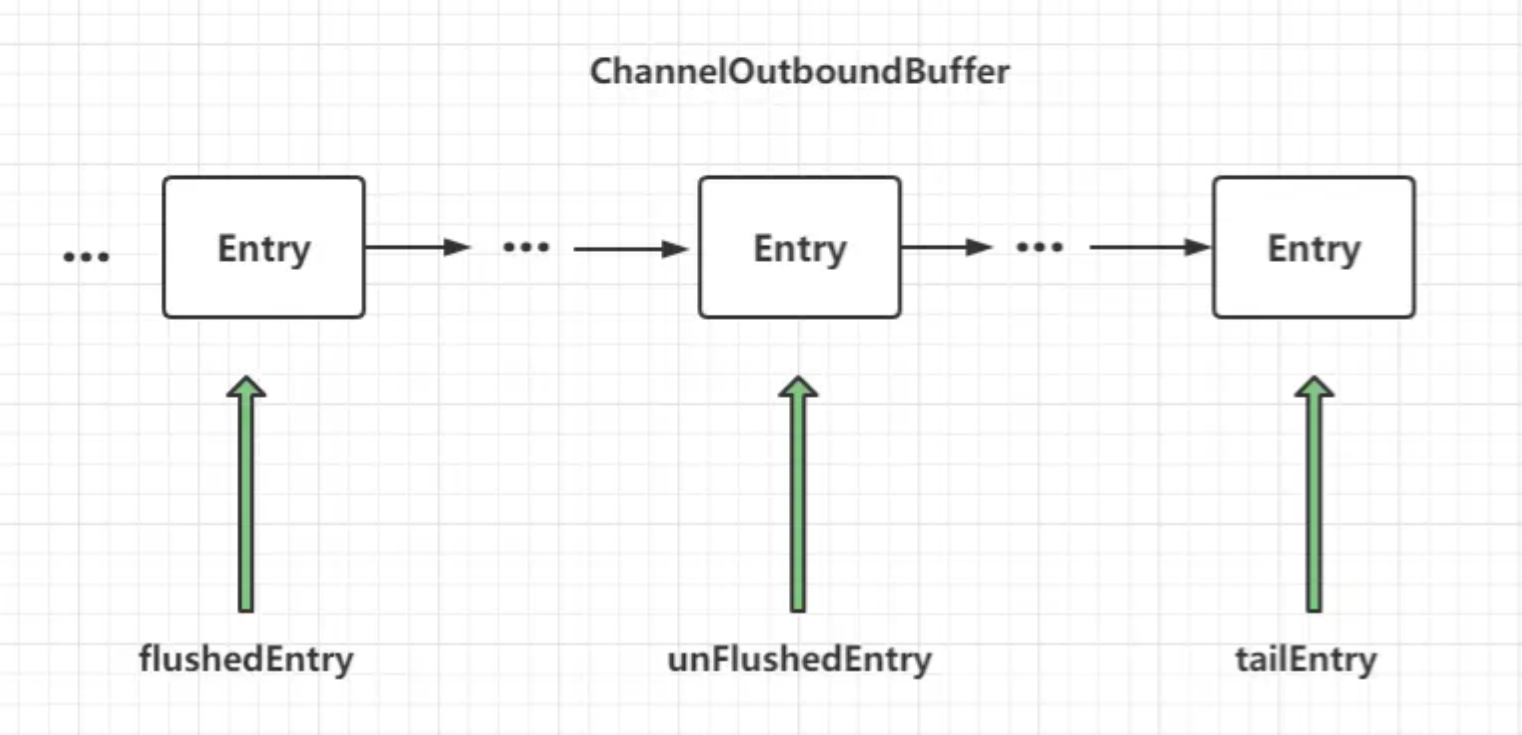
- flushedEntry 指针表示第一个被写到操作系统Socket缓冲区中的节点;
- unFlushedEntry指针表示第一个未被写入到操作系统Socket缓冲区中的节点;
- tailEntry指针表示ChannelOutboundBuffer缓冲区的最后一个节点。
初次调用 addMessage 之后,各个指针的情况为:
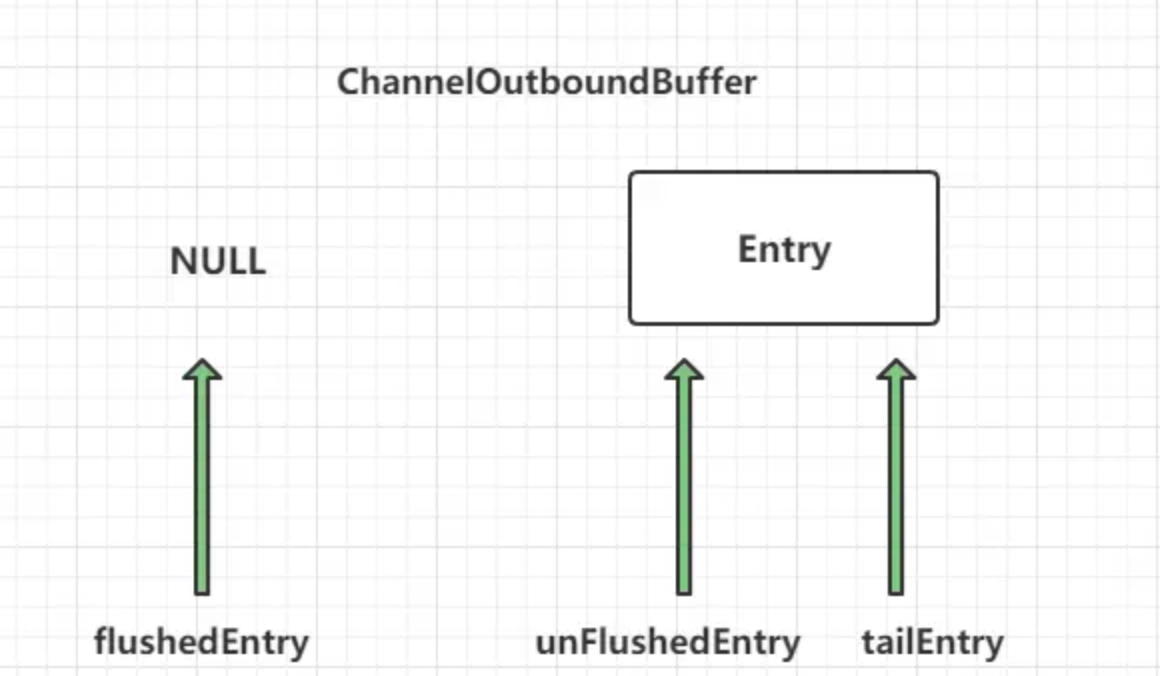
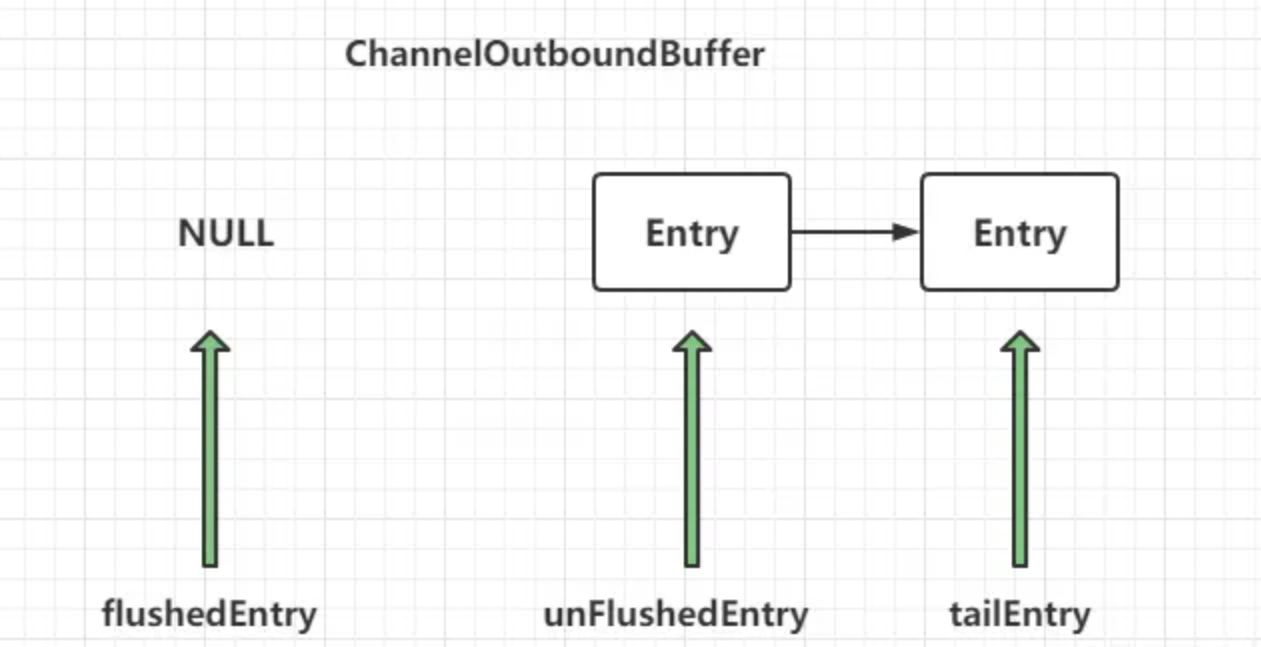
fushedEntry指向空,unFushedEntry和 tailEntry 都指向新加入的节点。第二次调用 addMessage之后,各个指针的情况为:
第n次调用 addMessage之后,各个指针的情况为:
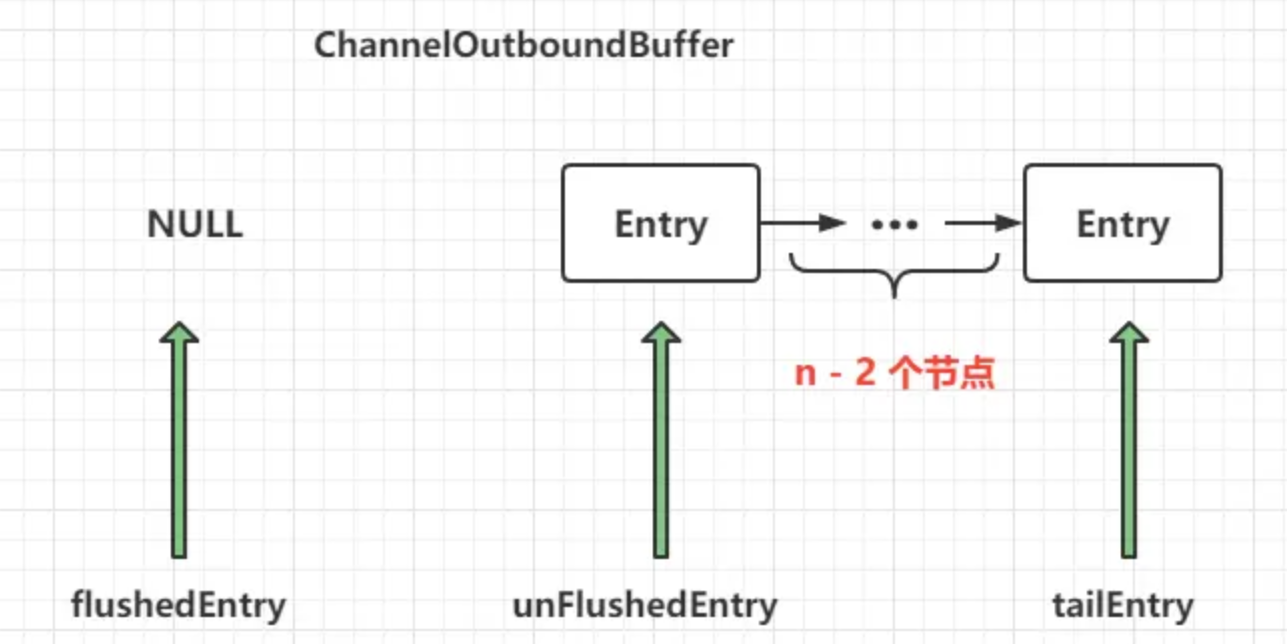
可以看到,调用n次addMessage,flushedEntry指针一直指向NULL,表示现在还未有节点需要写出到Socket缓冲区。
ChannelOutboundBuffer 主要提供了以下方法:
- addMessage方法:添加数据到对列的队尾;
- addFlush方法:准备待发送的数据,在 flush 前需要调用;
- nioBuffers方法:用于获取待发送的数据。在发送数据的时候,需要调用该方法以便拿到数据;
- removeBytes方法:发送完成后需要调用该方法来删除已经成功写入TCP缓存的数据。
1.4 addMessage 方法
addMessage 方法是系统调用write方法时调用,源码如下。
public void addMessage(Object msg, int size, ChannelPromise promise) {ChannelOutboundBuffer.Entry entry = ChannelOutboundBuffer.Entry.newInstance(msg, size, total(msg), promise);if (this.tailEntry == null) {this.flushedEntry = null;} else {ChannelOutboundBuffer.Entry tail = this.tailEntry;tail.next = entry;}this.tailEntry = entry;if (this.unflushedEntry == null) {this.unflushedEntry = entry;}this.incrementPendingOutboundBytes((long)entry.pendingSize, false);
}
上述源码流程如下:
将消息数据包装成 Entry 对象;
如果对列为空,直接设置尾结点为当前节点,否则将新节点放尾部;
unflushedEntry为空说明不存在暂时不需要发送的节点,当前节点就是第一个暂时不需要发送的节点;
将消息添加到未刷新的数组后,增加挂起的节点。
这里需要重点看看第一步将消息数据包装成 Entry 对象的方法。
static final class Entry {private static final Recycler<ChannelOutboundBuffer.Entry> RECYCLER = new Recycler<ChannelOutboundBuffer.Entry>() {protected ChannelOutboundBuffer.Entry newObject(Handle<ChannelOutboundBuffer.Entry> handle) {return new ChannelOutboundBuffer.Entry(handle);}};// ...static ChannelOutboundBuffer.Entry newInstance(Object msg, int size, long total, ChannelPromise promise) {ChannelOutboundBuffer.Entry entry = (ChannelOutboundBuffer.Entry)RECYCLER.get();entry.msg = msg;entry.pendingSize = size + ChannelOutboundBuffer.CHANNEL_OUTBOUND_BUFFER_ENTRY_OVERHEAD;entry.total = total;entry.promise = promise;return entry;}// ...}
其中Recycler类是基于线程本地堆栈的轻量级对象池。这意味着调用newInstance方法时 ,并不是直接创建了一个 Entry 实例,而是通过对象池获取的。
下面我们看看incrementPendingOutboundBytes方法的源码。
private void incrementPendingOutboundBytes(long size, boolean invokeLater) {if (size != 0L) {// TOTAL_PENDING_SIZE_UPDATER 当前缓存中 存在的代写的 字节// 累加long newWriteBufferSize = TOTAL_PENDING_SIZE_UPDATER.addAndGet(this, size);// 判断 新的将被写的 buffer的容量不能超过 getWriteBufferHighWaterMark() 默认是 64*1024 64字节if (newWriteBufferSize > (long)this.channel.config().getWriteBufferHighWaterMark()) {// 超过64 字节,进入这个方法this.setUnwritable(invokeLater);}}
}
在每次添加新的节点后都调用incrementPendingOutboundBytes((long)entry.pendingSize, false)方法,这个方法的作用是设置写状态,设置怎样的状态呢?我们看它的源码,可以看到,它会记录下累计的ByteBuf的容量,一旦超出了阈值,就会传播channel不可写的事件。
1.5 addFlush 方法
addFlush 方法是在系统调用 flush 方法时调用的,addFlush 方法的源码如下。
public void addFlush() {ChannelOutboundBuffer.Entry entry = this.unflushedEntry;if (entry != null) {if (this.flushedEntry == null) {this.flushedEntry = entry;}do {++this.flushed;if (!entry.promise.setUncancellable()) {int pending = entry.cancel();this.decrementPendingOutboundBytes((long)pending, false, true);}entry = entry.next;} while(entry != null);this.unflushedEntry = null;}}
以上方法的主要功能就是暂存数据节点变成待发送节点,即flushedEntry 指向的节点到unFlushedEntry指向的节点(不包含 unFlushedEntry)之间的数据。
上述源码的流程如下:
先获取unFlushedEntry指向的暂存数据的起始节点;
将待发送数据起始指针flushedEntry 指向暂存起始节点;
通过promise.setUncancellable()锁定待发送数据,并在发送过程中取消,如果锁定过程中发现其节点已经取消,则调用entry.cancel()取消节点发送,并减少待发送的总字节数。
下面我们看看decrementPendingOutboundBytes方法的源码。
private void decrementPendingOutboundBytes(long size, boolean invokeLater, boolean notifyWritability) {if (size != 0L) {// 每次 减去 -sizelong newWriteBufferSize = TOTAL_PENDING_SIZE_UPDATER.addAndGet(this, -size);// 默认 getWriteBufferLowWaterMark() -32kb// newWriteBufferSize<32 就把不可写状态改为可写状态if (notifyWritability && newWriteBufferSize < (long)this.channel.config().getWriteBufferLowWaterMark()) {this.setWritable(invokeLater);}}
}
1.6 AbstractNioByteChannel 类
在这个类中,我们主要看doWrite(ChannelOutboundBuffer in)方法,源码如下。
protected void doWrite(ChannelOutboundBuffer in) throws Exception {int writeSpinCount = this.config().getWriteSpinCount();do {Object msg = in.current();if (msg == null) {this.clearOpWrite();return;}writeSpinCount -= this.doWriteInternal(in, msg);} while(writeSpinCount > 0);this.incompleteWrite(writeSpinCount < 0);
}
通过一个无限循环,保证可以拿到所有的节点上的ByteBuf,通过这个函数获取节点,Object msg = in.current();
我们进一步看它的实现,如下,它只会取出我们标记的节点。
public Object current() {ChannelOutboundBuffer.Entry entry = this.flushedEntry;return entry == null ? null : entry.msg;
}
下面我们看下doWriteInternal(in, msg)的方法源码。
private int doWriteInternal(ChannelOutboundBuffer in, Object msg) throws Exception {if (msg instanceof ByteBuf) {ByteBuf buf = (ByteBuf)msg;if (!buf.isReadable()) {in.remove();return 0;}int localFlushedAmount = this.doWriteBytes(buf);if (localFlushedAmount > 0) {in.progress((long)localFlushedAmount);if (!buf.isReadable()) {in.remove();}return 1;}} else {if (!(msg instanceof FileRegion)) {throw new Error();}FileRegion region = (FileRegion)msg;if (region.transferred() >= region.count()) {in.remove();return 0;}long localFlushedAmount = this.doWriteFileRegion(region);if (localFlushedAmount > 0L) {in.progress(localFlushedAmount);if (region.transferred() >= region.count()) {in.remove();}return 1;}}return 2147483647;
}
使用 jdk 的自旋锁,循环16次,尝试往 jdk 底层的ByteBuffer中写数据,调用函数doWriteBytes(buf);他具体的实现是客户端 channel 的封装类NioSocketChannel实现的源码如下:
protected int doWriteBytes(ByteBuf buf) throws Exception {int expectedWrittenBytes = buf.readableBytes();// 将字节数据, 写入到 java 原生的 channel中return buf.readBytes(this.javaChannel(), expectedWrittenBytes);
}
这个readBytes()依然是抽象方法,因为前面我们曾经把从 ByteBuf 转化成了 Dirct 类型的,所以它的实现类是PooledDirctByteBuf 继续跟进如下:
public int readBytes(GatheringByteChannel out, int length) throws IOException {this.checkReadableBytes(length);// 关键的就是 getBytes() 跟进去int readBytes = this.getBytes(this.readerIndex, out, length, true);this.readerIndex += readBytes;return readBytes;
}private int getBytes(int index, GatheringByteChannel out, int length, boolean internal) throws IOException {this.checkIndex(index, length);if (length == 0) {return 0;} else {ByteBuffer tmpBuf;if (internal) {tmpBuf = this.internalNioBuffer();} else {tmpBuf = ((ByteBuffer)this.memory).duplicate();}index = this.idx(index);// 将netty 的 ByteBuf 塞进 jdk的 ByteBuffer tmpBuf;tmpBuf.clear().position(index).limit(index + length);// 调用jdk的write()方法return out.write(tmpBuf);}
}
被使用过的节点会被remove()掉, 源码如下。
private void removeEntry(ChannelOutboundBuffer.Entry e) {if (--this.flushed == 0) { // 如果是最后一个节点,把所有的指针全部设为nullthis.flushedEntry = null;if (e == this.tailEntry) {this.tailEntry = null;this.unflushedEntry = null;}} else { // 如果不是最后一个节点, 把当前节点,移动到最后的节点this.flushedEntry = e.next;}}
总结
- 调用write方法并没有将数据写到 Socket 缓冲区中,而是写到了一个单向链表的数据结构中,flush才是真正的写出。
- writeAndFlush等价于先将数据写到netty的缓冲区,再将netty缓冲区中的数据写到Socket缓冲区中,写的过程与并发编程类似,用自旋锁保证写成功。
相关文章:
【Netty】一行简单的writeAndFlush都做了哪些事(十八)
文章目录 前言一、源码分析1.1 ctx.writeAndFlush 的逻辑1.2 writeAndFlush 源码1.3 ChannelOutBoundBuff 类1.4 addMessage 方法1.5 addFlush 方法1.6 AbstractNioByteChannel 类 总结 前言 回顾Netty系列文章: Netty 概述(一)Netty 架构设…...

STM32U575 DMA配置
起个摘要,后期维护 1、DMA原理:参考:【STM32】DMA原理,配置步骤超详细,一文搞懂DMA_dma配置_~Old的博客-CSDN博客 2、STM32U575的DMA资源: (datasheet摘要) 3、UART的使用 4、I2…...

14-Vue3快速上手
目录 1.Vue3简介2. Vue3带来了什么2.1 性能的提升2.2 源码的升级2.3 拥抱TypeScript2.4 新的特性 1、海贼王,我当定了!——路飞 2、人,最重要的是“心”啊!——山治 3、如果放弃,我将终身遗憾。——路飞 4、人的梦想是…...

Docker registry 搭建
1、安装 docker 环境 参考:https://mp.csdn.net/mp_blog/creation/editor/104673841 2、准备 registry 镜像 机器有外网访问权限,直接 docker pull registry 通过 docker images 查看本地镜像 3、启动 registry docker run -d -p 5000:5000 --rest…...

关于三维布尔运算的几点思考
目录 三维布尔运算概述三角网格布尔运算效率提升思考BSPTree方式优化 参考 三维布尔运算概述 三维布尔运算根据三维实体数据结构表达分为CSG布尔运算、Brep布尔运算、三角网格布尔运算等类型。这几种类型算法在不同情境下有不同的优势,根据情况进行选择。但这也不能…...

【03.04】大数据教程--html+css基础
当谈到大数据时,HTML和CSS可能并不是最相关的技术。HTML和CSS主要用于构建网页和应用程序的用户界面,而大数据则涉及处理和分析大规模数据集。但是,如果您想展示有关大数据的信息或结果,并在网页上呈现,那么HTML和CSS可…...

深入理解与实践Seata:分布式事务解决方案
✅作者简介:热爱Java后端开发的一名学习者,大家可以跟我一起讨论各种问题喔。 🍎个人主页:Hhzzy99 🍊个人信条:坚持就是胜利! 💞当前专栏:微服务 🥭本文内容&…...
Python学习笔记 - 探索元组Tuple的使用
欢迎各位,我是Mr数据杨,你们的Python导游。今天,我要为大家讲解一段特殊的旅程,它与《三国演义》有关,而我们的主角是元组(tuple)。 让我们想象这样一个场景,三国演义中的诸葛亮&am…...

JAVA网络编程(一)
一、什么是网络编程 定义:在网络通信协议下,不同计算机上运行的程序,进行的数据传输。 应用场景:即时通信,网游,邮件等 不管什么场景,都是计算机与计算机之间通过网络在进行数据传输 java提供一…...

Python 线程队列
文章目录 Python 中的线程在 Python 中使用队列限制线程 本篇文章将介绍限制 Python 中的活动线程数。 Python 中的线程 Python 中的线程允许多个执行线程在单个进程中同时运行。 每个线程独立于其他线程运行,允许并发执行并提高性能。 线程对于执行受 I/O 限制或…...

创建web后端程序(servlet程序搭建)
目录 一、Servlet概述 二、创建servlet程序 1.创建类继承HttpServlet 2.重写HttpServlet类中 service、destroy、init方法 3.重新启动服务器 一、Servlet概述 Server Applet的简称,用Java编写的服务器端的程序。它运行在web服务器中,web服务器负责…...
【章节1】git commit规范 + husky + lint-staged实现commit的时候格式化代码
创建项目我们不多说,可以选择默认的,也可以用你们现有的项目。注意章节1和章节2请一起看! 章节1: commit规范 husky lint-staged格式化代码 章节2: husky 检测是否有未解决的冲突 预检查debugger 自动检查是否符合commit规范 前言&#x…...

【入门】拐角III
【入门】拐角III Description 输入整数N,输出相应方阵。 Input 一个整数N。( 0 < n < 10 ) Output 一个方阵,每个数字的场宽为3。 Sample Input 1 5 Sample Output 1 5 5 5 5 55 4 4 4 45 4 3 3 35 4 3 2 25 4…...
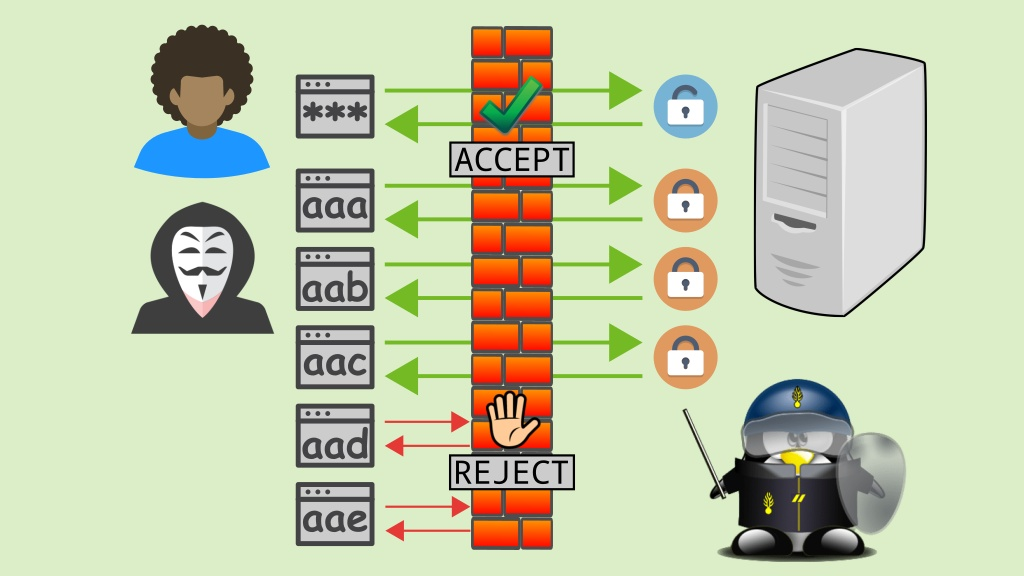
如何使用 Fail2ban 防止对 Linux 的暴力攻击?
在当今数字化世界中,网络安全成为了一个极其重要的话题。Linux 作为一种广泛使用的操作系统,也面临着各种网络攻击的风险,包括暴力攻击、密码破解和恶意登录等。为了保护 Linux 系统的安全,我们可以使用 Fail2ban 这样的工具来防止…...

2023年,真的别裸辞....
作为IT行业的大热岗位——软件测试,只要你付出了,就会有回报。说它作为IT热门岗位之一是完全不虚的。可能很多人回说软件测试是吃青春饭的,但放眼望去,哪个工作不是这样的呢?会有哪家公司愿意养一些闲人呢?…...
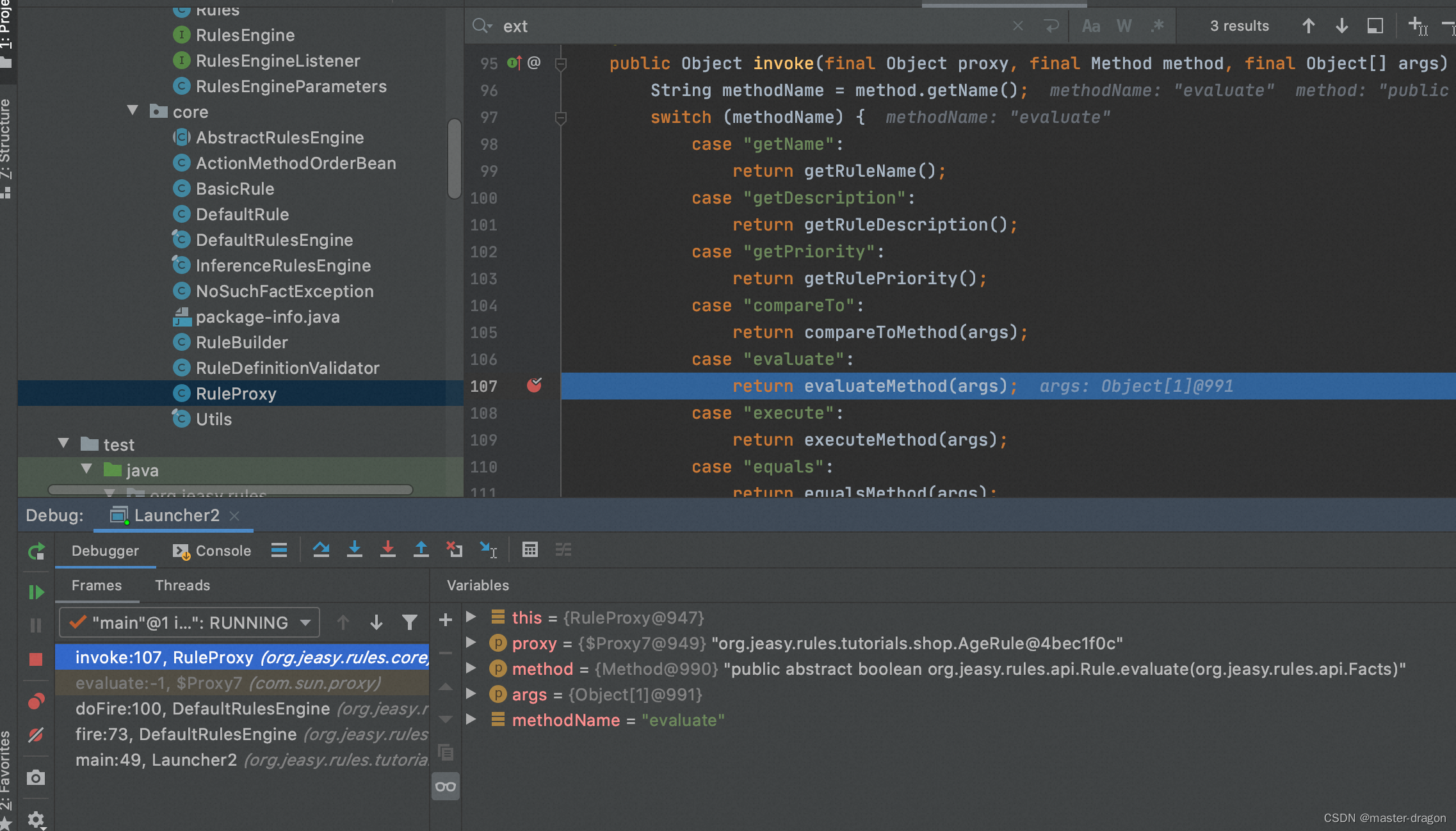
规则引擎架构-基于easy-rules
目录 概念理解实例和编码抽象出2条规则简单的规则引擎事实1的处理事实2的处理 easy-rules 规则的抽象和执行事实描述规则的抽象默认的规则 动态代理执行规则和动作规则的执行:org.jeasy.rules.core.DefaultRulesEngine#doFirepublic class RuleProxy implements Inv…...
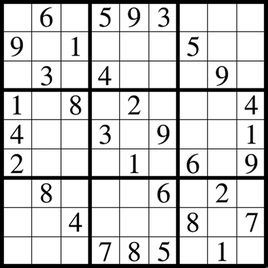
【数据结构】第七周
目录 稀疏矩阵快速转置 三元组的矩阵加法 九宫格数独游戏 数组主元素 螺旋数字矩阵 蛇形矩阵 数组循环右移K位 稀疏矩阵快速转置 【问题描述】 稀疏矩阵的存储不宜用二维数组存储每个元素,那样的话会浪费很多的存储空间。所以可以使用一个一维数组存…...

人体三维重构论文集合:awesome 3d human reconstruction
A curated list of related resources for 3d human reconstruction. Your contributions are welcome! Contents papers AIGCnerf or pifugeo fusionphoto3D human whole body3D human...

揭秘Redis持久化原理,探索fork与Copy-on-Write的魔法!
大家好,我是小米,今天我将和大家一起探索Redis持久化原理中的两个关键概念:fork和Copy-on-Write。这两个概念对于理解Redis的数据持久化机制至关重要。让我们一起来揭开这些技术的神秘面纱吧! Redis持久化简介 在开始之前&#…...

应届生如何提高职场竞争能力
摘要: 应届生面对竞争激烈的职场,需要不断提高自身的职业素养和竞争能力,才能在激烈的竞争中脱颖而出。本文从积极心态的培养、专业知识的优化、职业规划的制定、团队协作的加强和自我拓展的开展五个方面,提出了提高应届生职场竞争…...

2026大模型技术全景:从“写代码“到“做工程“
2026大模型技术全景:从"写代码"到"做工程"大模型技术正从"炫酷玩具"迈向"核心生产力工具"。本文从技术进展、关键方向、应用场景到未来趋势,全面梳理2026年大模型技术全景。一、引言 2026年,大模型技…...

免费德州扑克GTO求解器终极指南:如何用Desktop Postflop提升你的扑克决策能力
免费德州扑克GTO求解器终极指南:如何用Desktop Postflop提升你的扑克决策能力 【免费下载链接】desktop-postflop [Development suspended] Advanced open-source Texas Holdem GTO solver with optimized performance 项目地址: https://gitcode.com/gh_mirrors/…...

Cortex-M55内存属性与缓存机制深度解析
1. Cortex-M55内存属性与缓存机制解析 在嵌入式系统开发中,正确配置内存属性对于系统性能和功能正确性至关重要。Cortex-M55作为Armv8-M架构的处理器,通过内存保护单元(MPU)和内存属性间接寄存器(MAIR_ATTR)提供了灵活的内存属性配置能力。本文将深入剖析…...

RV1126B开发板GPIO实战:libgpiod驱动与安全操作指南
1. 项目概述与核心思路 最近在折腾一块基于瑞芯微RV1126B芯片的EASY-EAI开发板,项目里需要用到几个GPIO口来控制外部继电器和读取传感器状态。虽然官方文档和网上资料不少,但真上手时发现,关于如何在这块板子上正确、安全地操作GPIOÿ…...

机器学习——聚类评价指标SSE、SC、CH演示案例
一.评价指标简介SSE考虑了簇内因素SSE越越小越好SSE+肘部法常用来确定聚类的最佳K值SC轮廓系数法考虑了簇内和簇间因素,数值越大越好CH考虑簇内,簇间以及K值因素,数值越大越好二.代码部分详解1.SSE+肘部法#1.演示SSE&a…...

如何利用Taotoken的账单追溯功能分析月度模型使用情况
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 如何利用Taotoken的账单追溯功能分析月度模型使用情况 对于依赖大模型API进行开发或运营的团队而言,清晰、透明的成本核…...

Beam Search超参数调优指南:从原理到实践,如何为你的NLP任务选择最佳beam width?
Beam Search超参数调优实战:如何在生成质量与推理效率间找到平衡点 当GPT-3生成那段令人惊艳的诗歌时,背后其实经历了几百次候选序列的评估与筛选——这正是beam search算法的魔力所在。作为自然语言生成任务中最核心的解码策略之一,beam wid…...

ComfyUI-Impact-Pack:AI图像精细化增强的3大突破性技术革命
ComfyUI-Impact-Pack:AI图像精细化增强的3大突破性技术革命 【免费下载链接】ComfyUI-Impact-Pack Custom nodes pack for ComfyUI This custom node helps to conveniently enhance images through Detector, Detailer, Upscaler, Pipe, and more. 项目地址: htt…...

跨平台B站视频下载终极指南:如何用BilibiliDown轻松搞定离线观看
跨平台B站视频下载终极指南:如何用BilibiliDown轻松搞定离线观看 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.com/gh…...

网易2026年Q1财报:游戏增长背后,AI、跨端与全球化面临哪些挑战?
网易发布2026年Q1财报5月21日,网易发布2026年第一季度财报。大体上,网易呈现出基本面企稳、公司效率提升以释放利润的态势。财报显示,网易Q1净收入306亿元,同比增长6.1%,Non - GAAP归母净利润为107亿元。游戏及相关增值…...