万字解析PELT算法!
Linux是一个通用操作系统的内核,她的目标是星辰大海,上到网络服务器,下至嵌入式设备都能运行良好。做一款好的linux进程调度器是一项非常具有挑战性的任务,因为设计约束太多了:
- 它必须是公平的
- 快速响应
- 系统的throughput要高
- 功耗要小
3.8版本之前的内核CFS调度器在计算CPU load的时候采用的是跟踪每个运行队列上的负载(per-rq load tracking)。这种粗略的负载跟踪算法显然无法为调度算法提供足够的支撑。为了完美的满足上面的所有需求,Linux调度器在3.8版中引入了PELT(Per-entity load tracking)算法。本文将为您分析PELT的设计概念和具体的实现。
本文出现的内核代码来自Linux5.4.28,如果有兴趣,读者可以配合代码阅读本文。
一、为何需要per-entity load tracking?
完美的调度算法需要一个能够预知未来的水晶球:只有当内核准确地推测出每个进程对系统的需求,它才能最佳地完成调度任务。进程对CPU的需求包括两个方面:
- 任务的利用率(task utility)
- 任务的负载(task load)
跟踪任务的utility主要是为任务寻找合适算力的CPU。例如在手机平台上4个大核+4个小核的结构,一个任务本身逻辑复杂,需要有很长的执行时间,那么随着任务的运行,内核发现其utility越来越大,那么可以根据utility选择提升其所在CPU的频率,输出更大的算力,或者将其迁移到算力更强的大核CPU上执行。Task load主要用于负载均衡算法,即让系统中的每一个CPU承担和它的算力匹配的负载。
3.8版本之前的内核CFS调度器在负载跟踪算法上比较粗糙,采用的是跟踪每个运行队列上的负载(per-rq load tracking)。它并没有跟踪每一个任务的负载和利用率,只是关注整体CPU的负载。对于per-rq的负载跟踪方法,调度器可以了解到每个运行队列对整个系统负载的贡献。这样的统计信息可以帮助调度器平衡runqueue上的负载,但从整个系统的角度看,我们并不知道当前CPU上的负载来自哪些任务,每个任务施加多少负载,当前CPU的算力是否支撑runqueue上的所有任务,是否需要提频或者迁核来解决当前CPU上负载。因此,为了更好的进行负载均衡和CPU算力调整,调度器需要PELT算法来指引方向。
二、PELT算法的基本方法
通过上一章,我们了解到PELT算法把负载跟踪算法从per rq推进到per-entity的层次,从而让调度器有了做更精细控制的前提。这里per-entity中的“entity”指的是调度实体(scheduling entity),其实就是一个进程或者control group中的一组进程。为了做到Per-entity的负载跟踪,时间被分成了1024us的序列,在每一个1024us的周期中,一个entity对系统负载的贡献可以根据该实体处于runnable状态(正在CPU上运行或者等待cpu调度运行)的时间进行计算。任务在1024us的周期窗口内的负载其实就是瞬时负载。如果在该周期内,runnable的时间是t,那么该任务的瞬时负载应该和(t/1024)有正比的关系。类似的概念,任务的瞬时利用率应该通过1024us的周期窗口内的执行时间(不包括runqueue上的等待时间)比率来计算。
当然,不同优先级的任务对系统施加的负载也不同(毕竟在cfs调度算法中,高优先级的任务在一个调度周期中会有更多的执行时间),因此计算任务负载也需要考虑任务优先级,这里引入一个负载权重(load weight)的概念。在PELT算法中,瞬时负载Li等于:
Li = load weight x (t/1024)
利用率和负载不一样,它和任务优先级无关,不过为了能够和CPU算力进行运算,任务的瞬时利用率Ui使用下面的公式计算:
Ui = Max CPU capacity x (t/1024)
在手机环境中,大核最高频上的算力定义为最高算力,即1024。
任务的瞬时负载和瞬时利用率都是一个快速变化的计算量,但是它们并不适合直接调整调度算法,因为调度器期望的是一段时间内保持平稳而不是疲于奔命。例如,在迁移算法中,在上一个1024us窗口中,是满窗运行,瞬时利用率是1024,立刻将任务迁移到大核,下一个窗口,任务有3/4时间在阻塞状态,利用率急速下降,调度器会将其迁移到小核上执行。从这个例子可以看出,用瞬时量来推动调度器的算法不适合,任务会不断在大核小核之间跳来跳去,迁移的开销会急剧加大。为此,我们需要对瞬时负载进行滑动平均的计算,得到平均负载。一个调度实体的平均负载可以表示为:
L = L0 + L1*y + L2*y2 + L3*y3 + ...
Li表示在周期pi中的瞬时负载,对于过去的负载我们在计算的时候需要乘一个衰减因子y。在目前的内核代码中,y是确定值:y ^32等于0.5。这样选定的y值,一个调度实体的负荷贡献经过32个窗口(1024us)后,对当前时间的的符合贡献值会衰减一半。
通过上面的公式可以看出:
(1)调度实体对系统负荷的贡献值是一个序列之和组成
(2)最近的负荷值拥有最大的权重
(3)过去的负荷也会被累计,但是是以递减的方式来影响负载计算。
使用这样序列的好处是计算简单,我们不需要使用数组来记录过去的负荷贡献,只要把上次的总负荷的贡献值乘以y再加上新的L0负荷值就OK了。利用率的计算也是类似的,不再赘述。
三、内核调度器基本知识
为了能够讲清楚PELT算法,我们本章需要科普一点基本的CFS的基础知识。
1、调度实体
内核用struct sched_entity抽象一个调度实体结构:

所有的成员都很直观,除了runnable_weight。Task se的load weight和runnable weight是相等的,但是对于group se这两个值是不同的,具体有什么区别这个我们后文会详述。
2、Cfs任务的运行队列
内核用struct cfs_rq抽象一个管理调度实体的cfs任务运行队列:

Cfs rq有一个成员load保存了挂入该runqueue的调度实体load weight之和。为何要汇总这个load weight值?主要有两个运算需要,一个是在计算具体调度实体需要分配的时间片的时候:
Se Time slice = sched period x se load weight / cfs rq load weight
此外,在计算cfs rq的负载的时候,我们也需要load weight之和,下面会详细描述。
在负载均衡的时候,我们需要根据各个root cfs rq上的负载进行均衡,然而各个task se的load avg并不能真实反映它对root cfs rq(即对该CPU)的负载贡献,因为task se/cfs rq总是在某个具体level上计算其load avg(因为task se的load weight是其level上的load weight,并不能体现到root cfs rq上)。所以,我们在各个cfs rq上引入了hierarchy load的概念,对于顶层cfs rq而言,其hierarchy load等于该cfs rq的load avg,随着层级的递进,cfs rq的hierarchy load定义如下:
下一层的cfs rq的h_load = 上一层cfs rq的h_load X group se 在上一层cfs负载中的占比
在计算task se的h_load的时候,我们就使用如下公式:
Task se的h_load = task se的load avg x cfs rq的h_load / cfs rq的load avg
3、任务组(task group)
内核用struct task_group来抽象属于同一个control group的一组任务(需要内核支持组调度,具体细节可参考其他文章):

在上面的task group成员中,load_avg稍显突兀。虽然task group作为一个调度实体来竞争CPU资源,但是task group是一组task se或者group se(task group可以嵌套)的集合,不可能在一个CPU上进行调度,因此task group的调度实际上在各个CPU上都会发生,因此其load weight(即share成员)需要按照一定的算法分配给各个CPU上的group se,因此这里需要跟踪整个task group的load avg以及该task group在各个CPU上的load avg。
4、基本组件
和调度器相关的基本组件如下:

这是当系统不支持组调度时候的形态,每个任务都内嵌一个sched_entity,我们称之task se,每个CPU runqueue上都内嵌调度类自己的runqueue,对于cfs调度类而言就是cfs rq。Cfs rq有一个红黑树,每个处于runnable状态的任务(se)都是按照vruntime的值挂入其所属的cfs rq。当进入阻塞状态的时候,任务会被挂入wait queue,但是从PELT的角度来看,该任务仍然挂在cfs rq上,该task se的负载(blocked load)仍然会累计到cfs rq的负载(如上图虚线所示),不过既然该task se进入阻塞状态,那么就会按照PELT算法的规则衰减,计入其上次挂入的cfs rq。
5、构建大厦
当系统支持组调度的时候,cfs rq---se这个基本组件会形成层级结构,如下图所示:

一组任务(task group)作为一个整体进行调度的时候,那么它也就是一个sched entity了,也就是说task group对应一个se。这句话对UP是成立的,然而,在SMP的情况下,系统有多个CPU,任务组中的任务可能遍布到各个CPU上去,因此实际上,task group对应的是一组se,我们称之group se。由于task group中可能包含一个task group,因此task group也是形成层级关系,顶层是一个虚拟的root task group,该task group没有对应的group se(都顶层了,不需要挂入其他cfs rq),因而其对应的cfs rq内嵌在cpu runqueue中。
Group se需要管理若干个sched se(可能是task se,也可能是其下的group se),因此group se需要一个对应的cfs rq。对于一个group se,它有两个关联的cfs rq,一个是该group se所挂入的cfs rq:

另外一个是该group se所属的cfs rq:

资料直通车:Linux内核源码技术学习路线+视频教程内核源码
学习直通车:Linux内核源码内存调优文件系统进程管理设备驱动/网络协议栈
四、关于负载权重(load weight)和负载
1、load weight
PELT算法中定义了一个struct load_weight的数据结构来表示调度实体的负载权重:

这个数据结构中的weight成员就是负载权重值。inv_weight没有实际的意义,主要是为了快速运算的。struct load_weight可以嵌入到se或者cfs rq中,分别表示se/cfs rq的权重负载。Cfs rq的load weight等于挂入队列所有se的load weight之和。有了这些信息,我们可以快速计算出一个se的时间片信息(这个公式非常重要,让我们再重复一次):
Sched slice=sched period x se的权重/cfs rq的权重
CFS调度算法的核心就是在target latency(sched period)时间内,保证CPU资源是按照se的权重来分配的。映射到virtual runtime的世界中,cfs rq上的所有se是完全公平的。
2、平均负载
内核用struct sched_avg来抽象一个se或者cfs rq的平均负载:
说是平均负载,但是实际上这个数据结构包括了负载和利用率信息,主要是*_avg成员,其他的成员是中间计算变量。
3、如何确定se的load weight?
对于task se而言,load weight是明确的,该值是和se的nice value有对应关系,但是对于group se,load weight怎么设定?这是和task group相关的,当用户空间创建任务组的时候,在其目录下有一个share属性文件,用户空间通过该值可以配置该task group在分享CPU资源时候的权重值。根据上面的描述,我们知道一个task group对应的group se是若干个(CPU个数),那么这个share值应该是分配到各个group se中去,即task group se的load weight之和应该等于share值。平均分配肯定不合适,task group对应的各个cfs rq所挂入的具体任务情况各不相同,具体怎么分配?直觉上来说应该和其所属cfs rq挂入的调度实体权重相关,calc_group_shares给出了具体的计算方法,其基本的思想是:

这里的grq就是任务组的group cfs rq,通过求和运算可以得到该任务组所有cfs rq的权重之和。而一个group se的权重应该是按照其所属group cfs rq的权重在该任务组cfs rq权重和的占比有关。当然,由于运算量大,实际代码中做了一些变换,把load weight变成了load avg,具体就不描述了,大家可以自行阅读。
4、Se和cfs rq的平均负载
根据上文的计算公式,Task se的平均负载和利用率计算是非常直观的:有了load weight,有了明确的任务状态信息,计算几何级数即可。然而,对于group se而言,任务状态不是那么直观,它是这么定义的:只要其下层层级结构中有一个处于running状态,那么该group se就是running状态(cfs rq->curr == se)。只要其下层层级结构中有一个处于runnable状态,那么该group se就是runnable状态(se->on_rq表示该状态)。定义清楚group se状态之后,group se的load avg计算和task se是一毛一样的。
下面我们看看cfs runqueue的负载计算:

CFS runqueue也内嵌一个load avg数据结构,用来表示cfs rq的负载信息。CFS runqueue定义为其下sched entity的负载之和。这里的负载有两部分,一部分是blocked load,另外一部分是runnable load。我们用一个简单的例子来描述:Cfs rq上挂着B和C两个se,还有一个se A进入阻塞状态。当在se B的tick中更新cfs rq负载的时候,这时候需要重新计算A B C三个se的负载,然后求和就可以得到cfs rq的负载。当然,这样的算法很丑陋,当cfs rq下面有太多的sched se的时候,更新cfs rq的计算量将非常的大。内核采用的算法比较简单,首先衰减上一次cfs rq的load(A B C三个se的负载同时衰减),然后累加新的A和B的负载。因为cfs rq的load weight等于A的load weight加上B的load weight,所以cfs rq的load avg计算和sched entity的load avg计算的基本逻辑是一样的。具体可以参考__update_load_avg_se(更新se负载)和__update_load_avg_cfs_rq(更新cfs rq负载)的代码实现。
5、Runnable weight和Runnable load
struct sched_avg数据结构中有负载(load_sum/load_avg)和运行负载(runnable_load_sum/runnable_load_avg),这两个有什么不同呢?在回答这个问题之前,我们先思考这样的问题:一个任务进入阻塞态后,它是否还对CPU的负载施加影响?从前文的PELT算法来看,即便任务从cpu runqueue摘下,但是该任务的负载依然存在,还是按照PELT规则进行衰减,并计算入它阻塞前所在的CPU runqueue中(这种负载称为blocked load)。因此,load_sum/load_avg在计算的时候是包括了这些blocked load。负载均衡的时候,我们需要在各个CPU runqueue之间均衡负载(runnable load),如果不支持组调度,那么其实也OK,因为我们通过se->on_rq知道其状态,通过累计CPU上所有se->on_rq==1的se负载可以了解各个CPU上的runnable load并进行均衡。然而,当系统支持cgroup的时候,上述算法失效了,对于一个group se而言,只要其下有一个se是处于runnable,那么group se->on_rq==1。这样,在负载均衡的时候,cpu runqueue的负载重计入了太多的blocked load,从而无法有效的执行负载均衡。
为了解决这个问题,我们引入了runnable weight的概念,对于task se而言,runnable weight等于load weight,对于group se而言,runnable weight不等于load weight,而是通过下面的公式计算:

通过这样的方法,在group se内嵌的load avg中,我们实际上可以得到两个负载,一个是全负载(包括blocked load),另外一个是runnable load。
五、如何计算/更新load avg?
1、概述
内核构建了负载的PELT层级结构之后,还需要日常性的维护这个PELT大厦上各个cfs rq和se节点上的load avg,以便让任务负载、CPU负载能够及时更新。update_load_avg函数用来更新CFS任务及其cfs rq的负载。具体的更新的时间点总是和调度事件相关,例如一个任务阻塞的时候,把之前处于running状态的时间增加的负载更新到系统中。而在任务被唤醒的时候,需要根据其睡眠时间,对其负载进行衰减。具体调用update_load_avg函数的时机包括:

在本章的后续小节中,我们选取几个典型的场景具体分析负载更新的细节。
2、一个新建sched entity如何初始化load avg?
Load avg的初始化分成两个阶段,第一个阶段在创建sched entity的时候(对于task se而言就是在fork的时候,对于group se而言,发生在创建cgroup的时候),调用init_entity_runnable_average函数完成初始化,第二个阶段在唤醒这个新创建se的时候,可以参考post_init_entity_util_avg函数的实现。Group se不可能被唤醒,因此第二阶段的se初始化仅仅适用于task se。
在第一阶段初始化的时候,sched_avg对象的各个成员初始化为0是常规操作,不过task se的load avg(以及runnable load avg)初始化为最大负载值,即初始化为se的load weight。随着任务的运行,其load avg会慢慢逼近其真实的负载情况。对于group se而言,其load avg等于0,表示没有任何se附着在该group se上。
一个新建任务的util avg设置为0是不合适的,其设定值应该和该task se挂入的cfs队列的负载状况以及CPU算力相关,但是在创建task se的时候,我们根本不知道它会挂入哪一个cfs rq,因此在唤醒一个新创建的任务的时候,我们会进行第二阶段的初始化。具体新建任务的util avg的初始化公式如下:

完成了新建task se的负载和利用率的初始化之后,我们还会调用attach_entity_cfs_rq函数把这个task se挂入cfs---se的层级结构。虽然这里仅仅是给PELT大厦增加一个task se节点,但是整个PELT hierarchy都需要感知到这个新增的se带来的负载和利用率的变化。因此,除了把该task se的load avg加到cfs的load avg中,还需要把这个新增的负载沿着cfs---se的层级结构向上传播。类似的,这个新增负载也需要加入到task group中。
3、负载/利用率的传播
当一个新的task se加入cfs---se的层级结构(也称为PELT hierarchy)的时候,task se的负载(也包括util,后续用负载指代load和utility)会累计到各个level的group se,直到顶层的cfs rq。此外,当任务从一个CPU迁移到另外的CPU上或者任务从一个cgroup移动到另外的cgroup的时候,PELT hierarchy发生变化,都会引起负载的传播过程。我们下面用新建se加入PELT hierarchy来描述具体的负载传播细节:

attach_entity_cfs_rq的执行过程如下:
(1)确定task se的负载,如果需要的话可以执行更新动作。后续需要把这个新增se负载在整个PELT层级结构中向上传播。
(2)找到该task se所挂入的cfs rq,把task se的负载更新到cfs rq。记录需要向上传播的负载(add_tg_cfs_propagate)
(3)把task se的负载更新到其所属的task group(update_tg_load_avg)
(4)至此底层level的负载更新完成,现在要进入上一层进行负载更新。首先要更新group se的负载
(5)更新group se的负载,同时记录要向上传播的负载,即把level 0 cfs rq的prop_runnable_sum传递到level 1 cfs rq的prop_runnable_sum。
(6)由于task se的加入,level 0的cfs rq的负载和level 1的group se的负载也已经有了偏差,这里需要更新。通过update_tg_cfs_util函数让group se的utility和其所属的group cfs rq保持同步。通过update_tg_cfs_runnable函数让group se的负载和其所属的group cfs rq保持同步。
(7)更新level 1 task group的负载。然后不断重复上面的过程,直到顶层cfs rq。
4、在tick中更新load avg
主要的代码路径在entity_tick函数中:

在tick中更新loadavg是一个层次递进的过程,从页节点的task se开始向上,直到root cfs rq,每次都调用entity_tick来更新该层级的se以及cfs rq的load avg,这是通过函数update_load_avg完成的。更新完load avg之后,由于group cfs rq的状态发生变化,需要重新计算group se的load weight(以及runnable weight),这是通过update_cfs_group函数完成的。
update_load_avg的主要执行过程如下:
(1)更新本层级sched entity的load avg(__update_load_avg_se)
(2)更新该se挂入的cfs rq的load avg(update_cfs_rq_load_avg)
(3)如果是group se,并且cfs---se层级结构有了调度实体的变化,那么需要处理向上传播的负载。在tick场景中,不需要这个传播过程。
(4)更新该层级task group的负载(update_tg_load_avg)。之所以计算task group的load avg,这个值后续会参与计算group se的load weight。
update_cfs_group的主要执行过程如下:
(1)找到该group se所属的cfs rq
(2)调用calc_group_shares计算该group se的load weight
(3)调用calc_group_runnable计算该group se的runnable weight
(4)调用reweight_entity重新设定该group se的load weight和runnable weight,并根据这些新的weight值更新group se所挂入的cfs rq。
5、在任务唤醒时更新load avg
和tick一样,任务唤醒过程中更新load avg也是一个层次递进的过程,从页节点的task se开始向上,直到root cfs rq。不过在遍历中间节点(group se)的时候要判断当前的group se是否在runqueue上,如果没有那么就调用enqueue_entity,否则不需要调用。具体代码在enqueue_task_fair函数中:
(1)如果se->on_rq等于0,那么调用enqueue_entity进行负载更新
(2)如果se->on_rq等于1,那么表示表示该group的子节点至少有一个runnable或者running状态的se,这时候不需要entity入队操作,直接调用update_load_avg和update_cfs_group完成负载更新(过程和tick中一致)
在enqueue_entity函数中,相关负载更新代码如下:

和tick对比,这个场景下的update_load_avg多传递了一个DO_ATTACH的flag,当一个任务被唤醒的时候发生了迁移,那么PELT层级结构发生了变化,这时候需要负载的传播过程。enqueue_runnable_load_avg函数用来更新cfs rq的runnable load weight和runnable load。account_entity_enqueue函数会更新cfs rq的load weight。
6、任务睡眠时更新load avg
这个场景涉及的主要函数是dequeue_task_fair,是enqueue_task_fair的逆过程,这里我们主要看dequeue_entity函数中和负载相关的代码:

(1)更新本level的se及其挂入cfs rq的负载
(2)将该se的runnable load weight以及runnable load avg从cfs rq中减去。这里仅仅是减去了runnable load avg,并没有把load avg从cfs rq中减去,这说明虽然任务阻塞了,但是仍然会对cfs rq的load avg有贡献,只是随着睡眠时间不断衰减。
(3)将该se的load weight从cfs rq的load weight中减去
(4)更新group se的load weight以及runnable weight

相关文章:
万字解析PELT算法!
Linux是一个通用操作系统的内核,她的目标是星辰大海,上到网络服务器,下至嵌入式设备都能运行良好。做一款好的linux进程调度器是一项非常具有挑战性的任务,因为设计约束太多了: 它必须是公平的快速响应系统的throughp…...
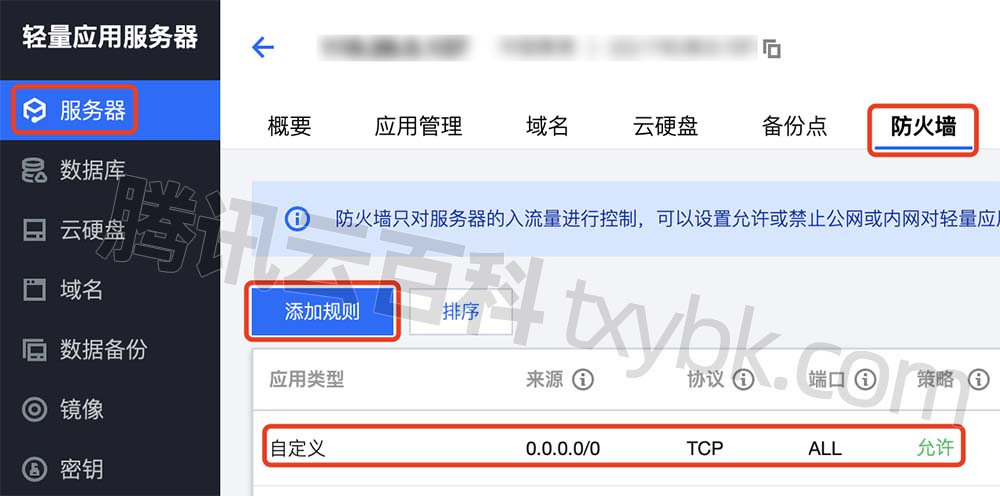
腾讯云服务器端口怎么全开?教程来了
腾讯云服务器端口怎么全开?云服务器CVM在安全组中设置开通,轻量应用服务器在防火墙中设置,腾讯云百科来详细说下腾讯云服务器端口全开放教程: 目录 腾讯云服务器端口全部开通教程 云服务器CVM端口全开放教程 轻量应用服务器开…...

深入理解Java虚拟机:JVM高级特性与最佳实践-总结-13
深入理解Java虚拟机:JVM高级特性与最佳实践-总结-13 Java内存模型与线程Java内存模型原子性、可见性与有序性先行发生原则 Java内存模型与线程 Java内存模型 原子性、可见性与有序性 Java内存模型是围绕着在并发过程中如何处理原子性、可见性和有序性这三个特征来…...

租售keysight E8257D 50G模拟信号发生器 销售/回收
是德(Keysight) E8257D 模拟信号发生器 Keysight E8257D (Agilent) PSG 模拟信号发生器提供业界领先的输出功率、电平精度和高达 67 GHz 的相位噪声性能(工作频率可达 70 GHz)。Agilent PSG 模拟信号发生器的高输出功率和卓越的电…...
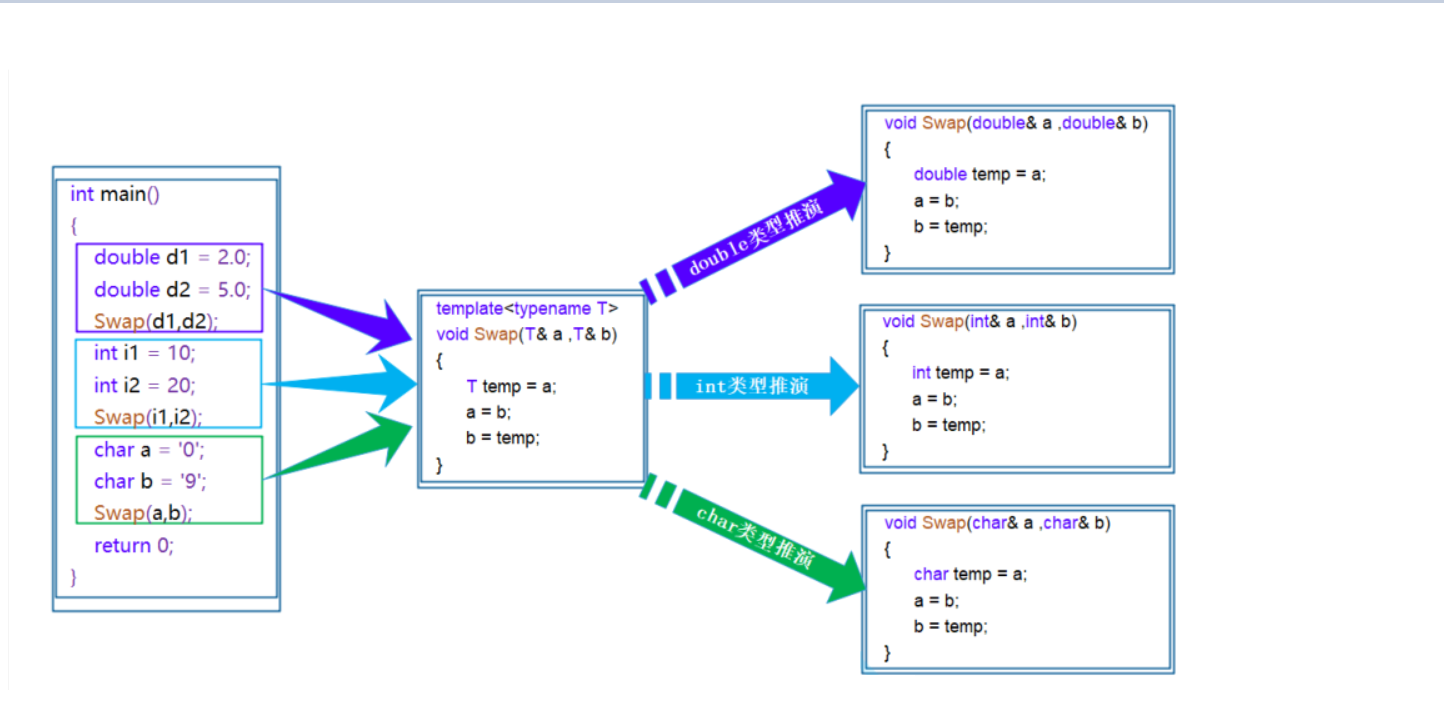
【C++】什么是函数模板/类模板?
文章目录 一、函数模板1.什么是函数模板?2.函数模板格式3.函数模板原理4.函数模板实例化(1)隐式实例化(2)显示实例化 二.类模板1.类模板定义格式2.类模板的实例化 总结 一、函数模板 1.什么是函数模板? 函…...

为什么是ChatGPT引发了AI浪潮?
目录 BERT和GPT简介 BERT和GPT核心差异 GPT的优势 GPT的劣势 总结 随着近期ChatGPT的火热,引发各行各业都开始讨论AI,以及AI可以如何应用到各个细分场景。为了不被时代“抛弃”,我也投入了相当的精力用于研究和探索。但在试验的过程中&…...
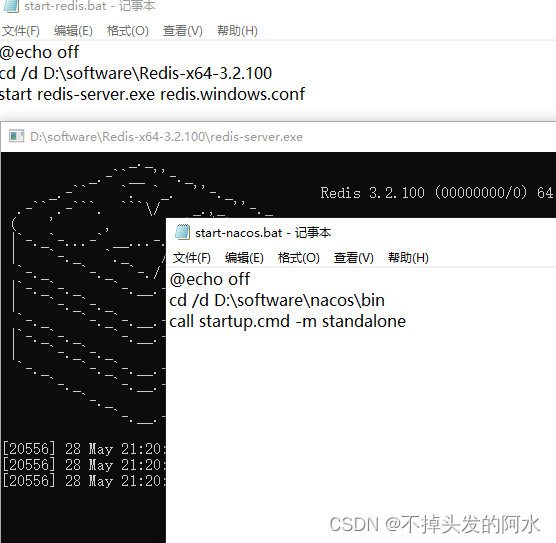
批处理文件(.bat)启动redis及任何软件(同理)
批处理文件 每次从文件根目录用配置文件格式来启动redis太麻烦了 可以在桌面上使用批处理文件(.bat)启动Redis,请按照以下步骤进行操作: 打开文本编辑器,如记事本。 在编辑器中输入以下内容: 将文件保存…...

深度学习求解稀疏最优控制问题的并行化算法
稀疏最优控制问题 问题改编自论文An FE-Inexact Heterogeneous ADMM for Elliptic Optimal Control Problems with L1-Control Cost { min y ( μ ) , u ( μ )...

牛客网项目—开发社区首页
视频连接:开发社区首页_哔哩哔哩_bilibili 代码地址:Community: msf begin 仿牛客论坛项目 (gitee.com) 本文是对仿牛客论坛项目的学习,学习本文之前需要了解Java开发的常用框架,例如SpringBoot、Mybatis等等。如果你也在学习牛…...

uniapp水文【uniapp】
文章目录 1、前言2、历史3、发展4、功能5、优缺点6、总结7、附录7.1、高频使用7.2、使用注意 1、前言 Uniapp是一种跨平台的移动应用开发框架,它允许开发者使用一套代码库,同时生成iOS、Android等多个平台的应用程序。这种技术方案可以大大降低开发成本…...

Java函数式接口
3 函数式接口 3.1 函数式接口概述 函数式接口:有且仅有一个抽象方法的接口 Java中的函数式编程体现就是Lambda表达式,所以函数式接口就是可以适用于Lambda使用的接口只有确保接口中有且仅有一个抽象方法, Java中的Lambda才能顺利地进行推导…...

安装libevent库
安装libevent库 yum install libevent libevent-devel 自动安装Memcached yum install memcached 源码安装 下载1.6.19版本 wget https://www.memcached.org/files/memcached-1.6.19.tar.gz (若证书过期yum install -y ca-certificates) 解压源码 tar -zxvf…...

vue 截取字符串的方法
vue中的字符串方法,我目前使用最多的是下面两种方法,因为 vue的字符串方法支持断言操作。 1、 vue中截取字符串的方法如下: 2、 vue中截取字符串的方法,这个方法也是需要依赖于 vue库提供的支持。 3、 vue中截取字符串的方法&…...

可数集和不可数集
有限集和无限集 后继集 设 S S S是任一集合,称 S S ∪ { S } S^ S\cup \left\{ S\right\} SS∪{S}为 S S S的后继集 自然数集 自然数集 N \mathbb{N} N的归纳定义是: (1) ∅ ∈ N \empty \in \mathbb{N} ∅∈N (…...
》)
<Linux>《Linux 之 ps 命令详解大全(含实用命令)》
《Linux 之 ps 命令详解大全(含实用命令)》 1 常用命令1.1 显示所有当前进程1.2 显示所有当前进程1.3 显示所有当前进程1.4 根据用户过滤进程1.5 根据 CPU 使用来升序排序1.6 根据用户过滤进程1.7 查询全10个使用cpu和内存最高的应用1.8 通过进程名和PID…...

华为OD机试真题 Java 实现【寻找关键钥匙】【2023Q1 100分】
一、题目描述 小强正在参加《密室逃生》游戏,当前关卡要求找到符合给定 密码K(升序的不重复小写字母组成)的箱子,并给出箱子编号,箱子编号为1~N。 每个箱子中都有一个字符串s,字符串由大写字母,小写字母,数字,标点符号,空格组成,需要在这些字符串中找出所有的字母…...
)
项目中遇到的一些问题总结(十三)
extension-configs 和 shared-configs 的区别 在 Nacos 配置管理中,extension-configs 和 shared-configs 分别是两种不同类型的配置,它们的主要区别在于它们的使用场景和作用。 extension-configs 是一种应用程序向 Nacos 注册的扩展配置。它主要用于给…...
)
药品存销信息管理系统数据设计与实现(包括需求分析,数据库设计,数据表、视图、存储过程等)
前言 可前往链接直接下载: https://download.csdn.net/download/c1007857613/87776664 或者阅读本博文的详细介绍,本博文也包含所有详细内容。 一、需求分析 a.“药品存销信息管理系统”只是对数据库应用技术的一个样本数据库的实例,重在对数据库一些方法的熟悉与掌握,…...
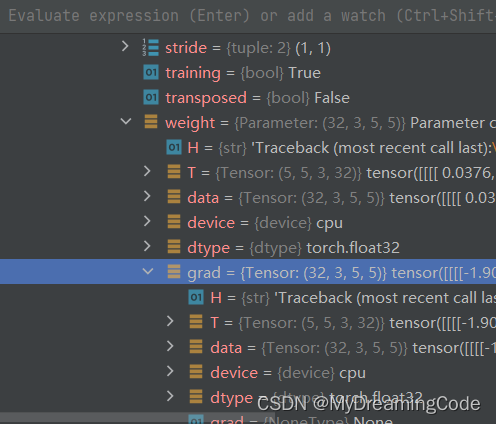
PyTorch-Loss Function and BP
目录 1. Loss Function 1.1 L1Loss 1.2 MSELoss 1.3 CrossEntropyLoss 2. 交叉熵与神经网络模型的结合 2.1 反向传播 1. Loss Function 目的: a. 计算预测值与真实值之间的差距; b. 可通过此条件,进行反向传播。 1.1 L1Loss import torch from …...

centos docker安装mysql8
1、创建挂载文件夹 mkdir -p /mydata/mysql/log mkdir -p /mydata/mysql/data mkdir -p /mydata/mysql/conf 2、拉取镜像最新版本,如果写 mysql:8.0.26可以指定版本 docker pull mysql 3、启动命令 docker run -p 3306:3306 --restartalways -v /mydata/mysql/log:…...

Android主流架构演进:从MVC到MVI,聚焦MVVM核心实践
引言 在Android应用开发中,架构设计是确保代码可维护性、可测试性和可扩展性的关键。随着技术演进,主流架构从传统的MVC(Model-View-Controller)逐步过渡到MVP(Model-View-Presenter)、MVVM(Model-View-ViewModel),再到新兴的MVI(Model-View-Intent)。这种演进反映…...
一套代码搞定 App/小程序/H5/PC,私域流量神器)
别再重复造轮子了!这个开源论坛小程序(Java+Uniapp)一套代码搞定 App/小程序/H5/PC,私域流量神器
你是否有过这些想法? 我想做个类似“知识星球”的圈子小程序,但外包报价动辄 5 万起…… 公司要做私域社区,需要同时支持微信小程序和 App,难道要养两个开发团队? 想靠“付费帖子 会员 打赏”变现,去哪…...

React状态管理权威评测:ReactStateMuseum中的10大热门方案
React状态管理权威评测:ReactStateMuseum中的10大热门方案 【免费下载链接】ReactStateMuseum A whirlwind tour of React state management systems by example 项目地址: https://gitcode.com/gh_mirrors/re/ReactStateMuseum ReactStateMuseum是一个全面的…...

SillyTavern终极指南:3步搭建你的AI聊天室,轻松管理所有AI模型
SillyTavern终极指南:3步搭建你的AI聊天室,轻松管理所有AI模型 【免费下载链接】SillyTavern LLM Frontend for Power Users. 项目地址: https://gitcode.com/GitHub_Trending/si/SillyTavern 你是否曾想过拥有一个统一的界面来管理所有AI聊天模型…...

如何高效下载QQ音乐资源:5个简单步骤掌握res-downloader嗅探技术
如何高效下载QQ音乐资源:5个简单步骤掌握res-downloader嗅探技术 【免费下载链接】res-downloader 视频号、小程序、抖音、快手、小红书、直播流、m3u8、酷狗、QQ音乐等常见网络资源下载! 项目地址: https://gitcode.com/GitHub_Trending/re/res-downloader …...

毫米波混合波束成形技术在VR中的应用与优化
1. 毫米波VR中的混合波束成形技术解析在无线VR应用中,用户对低延迟和高带宽的需求日益增长。传统Wi-Fi标准在密集环境下难以满足这些QoS要求,而毫米波技术凭借其高传输速率和低延迟特性成为理想选择。本文将深入探讨毫米波频段下混合波束成形技术的实现原…...

边缘计算与持续学习在机器人导航中的应用与优化
1. 边缘计算与持续学习在机器人导航中的核心价值 机器人导航系统正面临两大核心挑战:实时性要求和环境动态变化。传统云端处理模式由于网络延迟难以满足毫秒级响应需求,而静态训练模型无法适应不断变化的物理环境。边缘计算与持续学习技术的结合为这些问…...

GitHub Copilot X:从代码补全到全流程AI协作者的实战指南
1. 项目概述:当代码编辑器遇见“副驾驶”如果你和我一样,每天有超过一半的时间是在代码编辑器里度过的,那你一定对“效率”这个词有着近乎偏执的追求。从语法高亮、代码补全,到后来的LSP(Language Server Protocol&…...

三分钟完成Taotoken的PythonSDK配置与首次聊天补全调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 三分钟完成Taotoken的Python SDK配置与首次聊天补全调用 对于刚拿到Taotoken API Key的Python开发者来说,最迫切的需求…...

AI时代中小企业还要不要上ERP?2026年最新思考
最近DeepSeek爆火,AI Agent层出不穷,不少老板问我:都2026年了,AI这么厉害,中小企业还有必要上ERP吗?我的答案是:不仅要上,而且要上得更聪明。一、AI再强,也替代不了ERP的…...