MapReduce实战案例(3)

案例三: MR实战之TOPN(自定义GroupingComparator)
项目准备
- 需求+测试数据
有如下订单数据
| 订单id | 商品id | 成交金额 |
|---|---|---|
| Order_0000001 | Pdt_01 | 222.8 |
| Order_0000001 | Pdt_05 | 25.8 |
| Order_0000002 | Pdt_03 | 522.8 |
| Order_0000002 | Pdt_04 | 122.4 |
| Order_0000002 | Pdt_05 | 722.4 |
| Order_0000003 | Pdt_01 | 222.8 |
现在需要求出每一个订单中成交金额最大的一笔交易
-
分析
a) 利用“订单id和成交金额”作为key,可以将map阶段读取到的所有订单数据按照id分区,按照金额排序,发送到reduce
b) 在reduce端利用groupingcomparator将订单id相同的kv聚合成组,然后取第一个即是最大值
项目实现
a)自定义groupingcomparator
/*** @Author 千锋大数据教学团队* @Company 千锋好程序员大数据* @Description 用于控制shuffle过程中reduce端对kv对的聚合逻辑*/
public class ItemidGroupingComparator extends WritableComparator {protected ItemidGroupingComparator() {super(OrderBean.class, true);}@Overridepublic int compare(WritableComparable a, WritableComparable b) {OrderBean abean = (OrderBean) a;OrderBean bbean = (OrderBean) b;//将item_id相同的bean都视为相同,从而聚合为一组return abean.getItemid().compareTo(bbean.getItemid());}
}
复制代码文末扫码领取福利!
b)定义订单信息bean
/*** @Author 千锋大数据教学团队* @Company 千锋好程序员大数据* @Description 订单信息bean,实现hadoop的序列化机制*/
public class OrderBean implements WritableComparable<OrderBean>{private Text itemid;private DoubleWritable amount;public OrderBean() {}public OrderBean(Text itemid, DoubleWritable amount) {set(itemid, amount);}public void set(Text itemid, DoubleWritable amount) {this.itemid = itemid;this.amount = amount;}public Text getItemid() {return itemid;}public DoubleWritable getAmount() {return amount;}@Overridepublic int compareTo(OrderBean o) {int cmp = this.itemid.compareTo(o.getItemid());if (cmp == 0) {cmp = -this.amount.compareTo(o.getAmount());}return cmp;}@Overridepublic void write(DataOutput out) throws IOException {out.writeUTF(itemid.toString());out.writeDouble(amount.get());}@Overridepublic void readFields(DataInput in) throws IOException {String readUTF = in.readUTF();double readDouble = in.readDouble();this.itemid = new Text(readUTF);this.amount= new DoubleWritable(readDouble);}@Overridepublic String toString() {return itemid.toString() + "\t" + amount.get();}
}
复制代码c) 编写MapReduce处理流程
/*** @Author 千锋大数据教学团队* @Company 千锋好程序员大数据* @Description 利用secondarysort机制输出每种item订单金额最大的记录*/public class SecondarySort {static class SecondarySortMapper extends Mapper<LongWritable, Text, OrderBean, NullWritable>{OrderBean bean = new OrderBean();@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {String line = value.toString();String[] fields = StringUtils.split(line, "\t");bean.set(new Text(fields[0]), new DoubleWritable(Double.parseDouble(fields[1])));context.write(bean, NullWritable.get());}}static class SecondarySortReducer extends Reducer<OrderBean, NullWritable, OrderBean, NullWritable>{//在设置了groupingcomparator以后,这里收到的kv数据 就是: <1001 87.6>,null <1001 76.5>,null .... //此时,reduce方法中的参数key就是上述kv组中的第一个kv的key:<1001 87.6>//要输出同一个item的所有订单中最大金额的那一个,就只要输出这个key@Overrideprotected void reduce(OrderBean key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {context.write(key, NullWritable.get());}}public static void main(String[] args) throws Exception {Configuration conf = new Configuration();Job job = Job.getInstance(conf);job.setJarByClass(SecondarySort.class);job.setMapperClass(SecondarySortMapper.class);job.setReducerClass(SecondarySortReducer.class);job.setOutputKeyClass(OrderBean.class);job.setOutputValueClass(NullWritable.class);FileInputFormat.setInputPaths(job, new Path(args[0]));FileOutputFormat.setOutputPath(job, new Path(args[1]));//指定shuffle所使用的GroupingComparator类job.setGroupingComparatorClass(ItemidGroupingComparator.class);//指定shuffle所使用的partitioner类job.setPartitionerClass(ItemIdPartitioner.class);job.setNumReduceTasks(3);job.waitForCompletion(true);}} 
也可以观看视频:
千锋大数据Hadoop全新增强版-先导片
相关文章:
MapReduce实战案例(3)
案例三: MR实战之TOPN(自定义GroupingComparator) 项目准备 需求测试数据 有如下订单数据 订单id商品id成交金额Order_0000001Pdt_01222.8Order_0000001Pdt_0525.8Order_0000002Pdt_03522.8Order_0000002Pdt_04122.4Order_0000002Pdt_05722.4Order_0000003Pdt_01222.8 现在…...
)
Socket(三)
文章目录 1. 设置Socket选项2. TCP_NODELAY3. SO_LINGER4. SO_TIMEOUT5. SO_RCVBUF和SO_SNDBUF6. SO_KEEPALIVE7. OOBINLINE8. SO_REUSEADDR9. IP_TOS服务类型10. Socket异常 1. 设置Socket选项 Socket选项指定了Java Socket类所依赖的原生socket如何发送和接受数据࿰…...

【JVM】12. 垃圾回收相关概念
文章目录 12.1. System.gc()的理解12.2. 内存溢出与内存泄露内存溢出(OOM)内存泄漏(Memory Leak) 12.3. Stop The World12.4. 垃圾回收的并行与并发并发(Concurrent)并行(Parallel)并…...
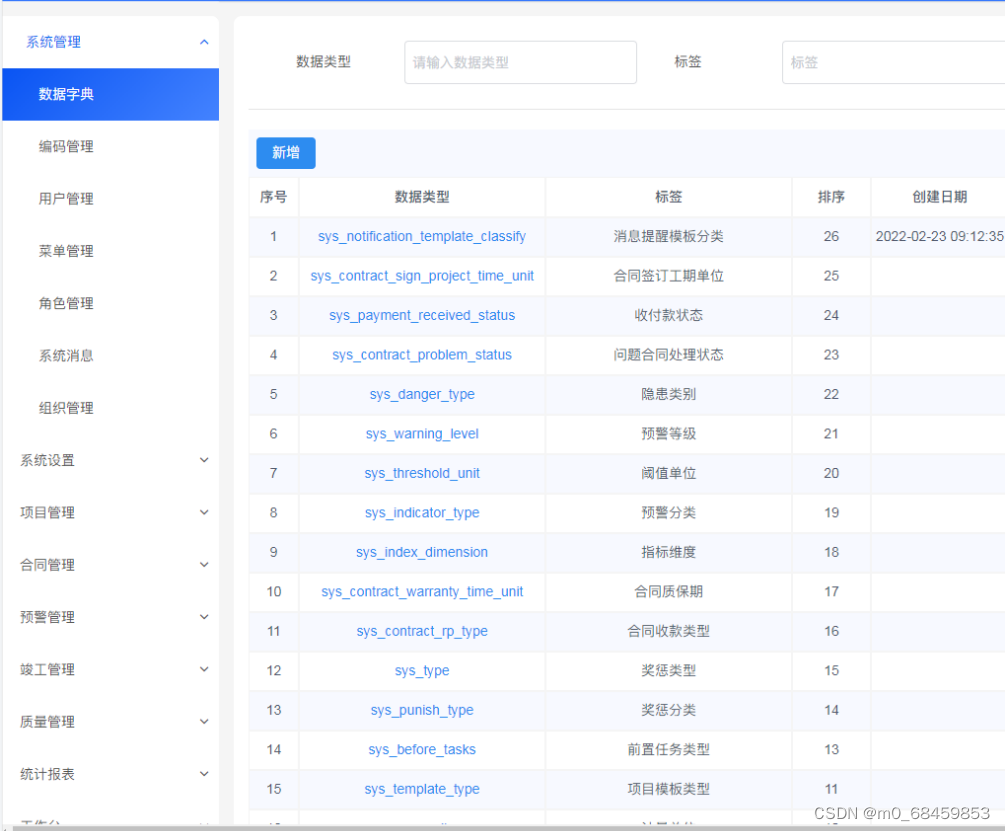
Java 版 spring cloud 工程系统管理 工程项目管理系统源码 工程项目各模块及其功能点清单
工程项目各模块及其功能点清单 一、系统管理 1、数据字典:实现对数据字典标签的增删改查操作 2、编码管理:实现对系统编码的增删改查操作 3、用户管理:管理和查看用户角色 4、菜单管理:实现对系统菜单的增删改查操…...

【Linux系统基础快速入门详解】Linux系统命令行介绍、命令提示符知识详解: ~/#/@等符号
Linux系统的命令行界面是Linux系统的核心部分,也是最常用的部分。在命令行界面中,用户可以使用各种Linux系统命令进行文件操作、系统管理、网络管理等操作。下面介绍一些常见的Linux系统命令行知识,以及命令提示符中的一些符号的含义。 1. 命令行界面 在Linux系统中,命令…...

Python 面向对象编程笔记:中级面向对象
__super__() 在 Python 中,super 是一个内置函数,用于调用父类方法。该函数可以在子类中调用父类中被重写的方法,从而实现对父类方法的继承并且进行扩展。它能够动态地查找当前子类继承链中的下一个类,从而允许设计者更加灵活地…...
JVM学习笔记(上)
1、总体路线 2、程序计数器 Program Counter Register 程序计数器(寄存器) 作用:是记录下一条 jvm 指令的执行地址行号。 特点: 是线程私有的不会存在内存溢出 解释器会解释指令为机器码交给 cpu 执行,程序计数器会…...

反爬虫技术
预计更新 一、 爬虫技术概述 1.1 什么是爬虫技术 1.2 爬虫技术的应用领域 1.3 爬虫技术的工作原理 二、 网络协议和HTTP协议 2.1 网络协议概述 2.2 HTTP协议介绍 2.3 HTTP请求和响应 三、 Python基础 3.1 Python语言概述 3.2 Python的基本数据类型 3.3 Python的流程控制语句 …...
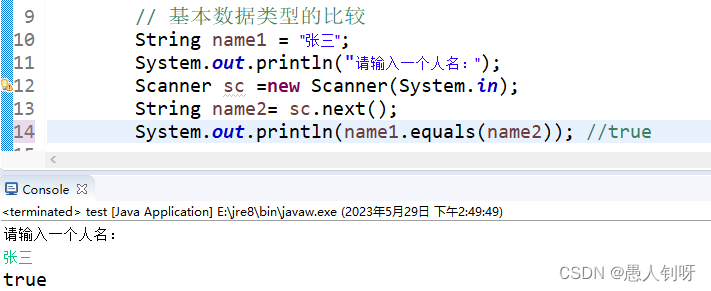
JAVA中.equals()与 ==的区别
1. “”是运算符,如果是基本数据类型,则比较存储的值;如果是引用数据类型,则比较所指向对象的地址值。 2..equals() equals是Object的方法,比较的是所指向的对象的地址值,一般情况下,重写之后比…...

华为OD机试之羊、狼、农夫过河(Java源码)
羊、狼、农夫过河 题目描述 羊、狼、农夫都在岸边,当羊的数量小于狼的数量时,狼会攻击羊,农夫则会损失羊。农夫有一艘容量固定的船,能够承载固定数量的动物。 要求求出不损失羊情况下将全部羊和狼运到对岸需要的最小次数。只计算…...

C++ string的简单应用
C语言的字符串 C的字符串 头文件: #include<string.h> //c #include<string> //C #include<cstring> //C 比较string的大小 两个string对象相加 使用字符串对象来存放字符串 两个string对象相加 string str "Hello,"; st…...

Java中的阻塞队列
阻塞队列的基本概念 1、生产者、消费者的概念 他俩是设计模式的一种,提出这两种概念,通过一个容器的方式能解决强耦合问题 生产者、消费者之间不会直接通讯。通过一个第三方容器、队列的方式进行通讯 生产者生产完数据放入容器之后,不用等待消…...

PriorityBlockingQueue无界阻塞优先级队列
PriorityBlockingQueue无界阻塞优先级队列 PriorityBlockingQueue 是带优先级的无界阻塞队列,每次出队都返回优先级最高的元素,是二叉树最小堆的实 现,研究过数组方式存放最小堆节点的都知道,直接遍历队列元素是无序的。 如图 P…...

「HTML和CSS入门指南」p 标签详解
<p> 标签是什么? HTML5 中的 <p> 标签是用于定义段落的标签。它可以用来标记文章、新闻等长篇内容中的段落,并且可以与其他 HTML 元素配合使用。 <p> 标签的语法和属性 <p> 标签的语法非常简单,只需要在 HTML 文件中插入 <p> 和 </p>…...
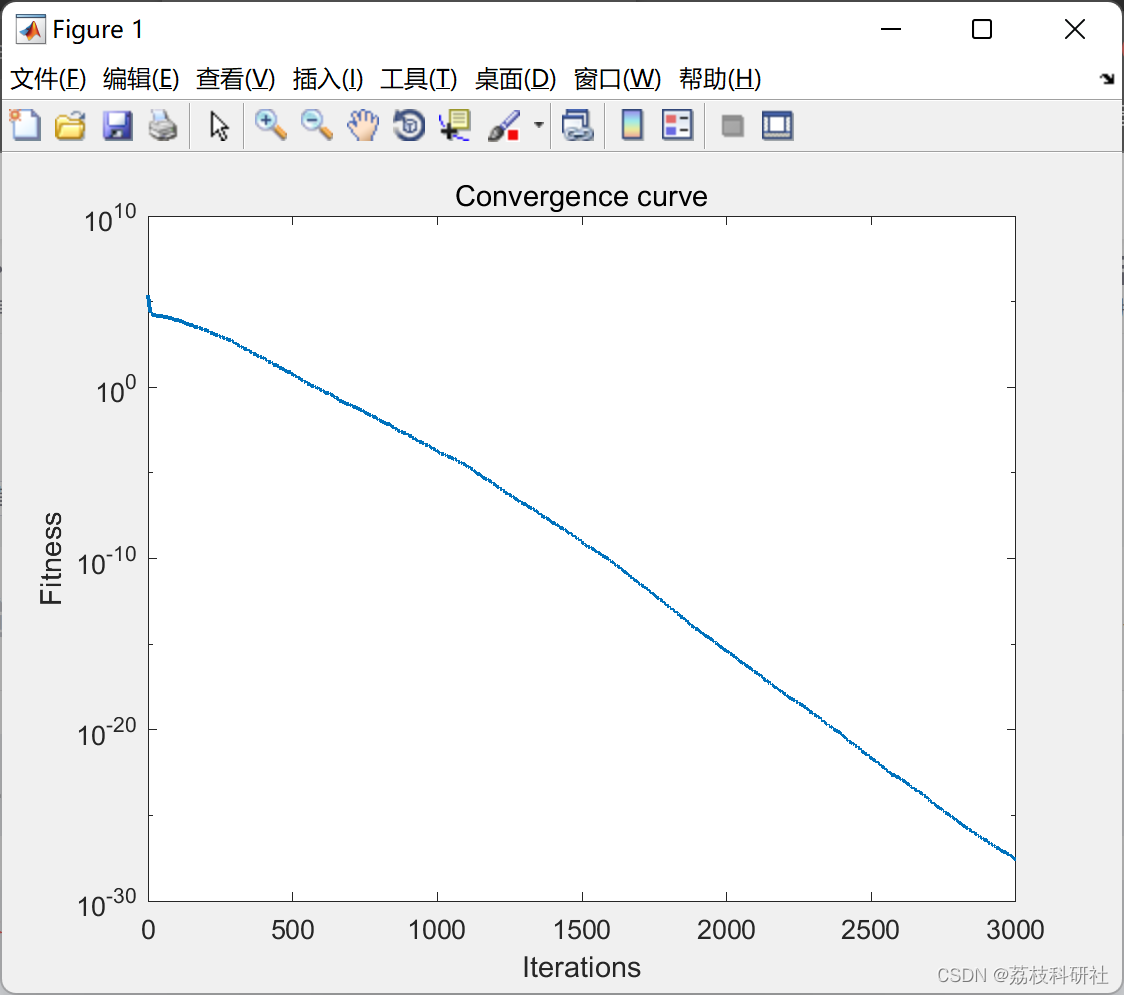
【单目标优化算法】孔雀优化算法(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

chatgpt赋能python:Python同一行多个语句:如何提高你的编程效率?
Python同一行多个语句:如何提高你的编程效率? Python是一种优雅的编程语言,拥有简洁易懂的语法,可以帮助你快速编写可以在各种领域使用的高级代码。其中,Python同一行多个语句,是一种可以大大提高编程效率…...
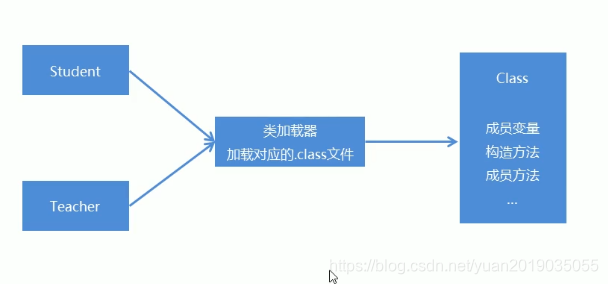
Java反射概述
2 反射 2.1 反射概述 Java反射机制:是指在运行时去获取一个类的变量和方法信息。然后通过获取到的信息来创建对象,调用方法的一种机制。由于这种动态性,可以极大的增强程序的灵活性,程序不用在编译期就完成确定,在运行期仍然可以扩展2.2 反射获取Class类的对象 我们要想通过反…...
)
《网络是怎样连接的》(一)
第一章web浏览器 简介 首先输入网址URL,浏览器进行解析,将我们需要哪些数据告诉服务器。浏览器向服务器发送消息,必须告诉操作系统的接收方的IP地址,所以浏览器先查出web服务器的IP地址,向DNS服务器查询域名对应的IP…...

Flink on yarn任务日志怎么看
1、jobmanager日志 在yarn上可以直接看 2、taskmanager日志 在flink的webui中可以看,但是flink任务失败后,webui就不存在了,那怎么看? 这是jobmanager的地址 hadoop02:19888/jobhistory/logs/hadoop02:45454/container_e03_16844…...
二次元的登录界面
今天还是继续坚持写博客,然后今天给大家带来比较具有二次元风格的登录界面,也只是用html和css来写的,大家可以来看看! 个人名片: 😊作者简介:一名大一在校生,web前端开发专业 &…...

对比直接使用厂商API,Taotoken在用量观测与账单管理上的便利性
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直接使用厂商API,Taotoken在用量观测与账单管理上的便利性 当开发者或团队同时接入多个大模型厂商的原生API时&…...

终极指南:如何快速实现Daz Studio到Blender的无缝资产迁移
终极指南:如何快速实现Daz Studio到Blender的无缝资产迁移 【免费下载链接】DazToBlender Daz to Blender Bridge 项目地址: https://gitcode.com/gh_mirrors/da/DazToBlender 还在为3D角色创作中的软件壁垒而烦恼吗?Daz Studio以其强大的角色创建…...

从账单明细看Taotoken计费模式的透明与可追溯性
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 从账单明细看Taotoken计费模式的透明与可追溯性 对于将大模型API集成到产品中的团队而言,成本控制与核算是一个核心的工…...

Red Hat和IBM Node.js参考架构:企业级Node.js应用开发的完整指南
Red Hat和IBM Node.js参考架构:企业级Node.js应用开发的完整指南 【免费下载链接】nodejs-reference-architecture The Red Hat and IBM Node.js Reference architecture. The teams opinion on what components our customers and internal teams should use when …...

3个关键问题揭示:为什么你需要DLSS版本管理器提升游戏体验
3个关键问题揭示:为什么你需要DLSS版本管理器提升游戏体验 【免费下载链接】dlss-swapper 项目地址: https://gitcode.com/GitHub_Trending/dl/dlss-swapper 你是否曾因游戏卡顿而烦恼?是否想知道为什么别人的游戏画面更流畅?DLSS Sw…...

Windows使用Powershell自动安装SqlServer2025服务器与SSMS管理工具
下载地址: https://www.microsoft.com/zh-cn/evalcenter/evaluate-sql-server-2025 安装结果: 安装前准备: 1.下载mssql server 2025安装器 2.下载iso镜像 3.下载好SSMS安装程序,并放到iso同目录下...

非标系统控制柜制造:从特殊工况到定制控制的完整解析
一、什么是非标系统控制柜制造?非标系统控制柜制造,是指针对常规PLC控制柜、变频器控制柜、低压配电柜、防爆控制柜之外的特殊控制需求,根据设备工艺、现场环境、控制逻辑、通讯协议、安全要求和安装空间,对柜体结构、电气元件、控…...

三步破解安全研发合规难题:Gitee软件工厂助力GJB5000B与等保三级高标准落地
TL;DR 国家安全领域软件研发需同时满足GJB5000B、等保2.0三级等强制合规要求与智能化装备带来的软件复杂度挑战。传统研发模式在协作、安全、交付三方面日益乏力。Gitee软件工厂通过“统一底座、细粒度权限、标准化流程”三大核心能力,内置SM2/SM4国密加密、IP白名单…...

谷歌SEO全面解析|新手入门 + 排名提升核心要点
如今,无论是企业官网、外贸独立站,还是个人博客,越来越多人开始重视“谷歌 SEO”。 原因很简单: 谁能在 Google 搜索结果中获得排名,谁就能持续获得免费的精准流量。 很多新手第一次接触 SEO 时,会觉得它…...

python 内存管理 内存泄漏及排查方案 内存友好的python代码
Python 内存管理 一、一句话总结 Python 的内存管理就是三件事: 自动分配内存(你不用管变量存在哪)自动回收垃圾(不用的对象自动删掉)靠引用计数 分代垃圾回收实现二、核心机制 1:引用计数(最基…...