Flume和Kafka的组合使用
一.安装Kafka
1.1下载安装包
通过百度网盘分享的文件:复制链接打开「百度网盘APP 即可获取」
链接:https://pan.baidu.com/s/1vC6Di3Pml6k1KMbnK0OE1Q?pwd=huan
提取码:huan
也可以访问官网,下载kafka2.4.0的安装文件
1.2解压到“D:\”目录下
因为Kafka的运行依赖于 Zookeeper,因此,还需要下并安装Zookeeper,当然Kafka也内置了Zookeeper服务,因此,也可以不额外安装Zookeep,直接使用内置的Zookeeper服务。
这里为简单起见,直接使用Kafka内置的Zookeeper服务
二.使用Kafka
2.1启动zookeeper
2.1.1新建第一个cmd命令窗口
在Windows操作系统中找到解压的kafka_2.12-2.4.0
在这里输入cmd--->然后回车
会出现一个小黑窗(黑窗口1)
2.1.2在黑窗中1中输入.\bin\windows\zookeeper-server-start.bat .\config\zookeeper.properties然后回车
出现下图表示zookeeper启动成功

2.2启动Kafka
2.2.1新建第二个cmd命令窗口
在Windows操作系统中找到解压的kafka_2.12-2.4.0(这里跟上面是一样的)
在这里输入cmd--->然后回车
会出现一个小黑窗(黑窗口2)
2.2.2在小黑窗2中输入.\bin\windows\kafka-server-start.bat .\config\server.properties然后回车(注:跟启动zookeeper的命令不一样)
出现下图表示Kafka启动成功

[注意:两个小黑窗都不能关闭]
2.3创建名为“test004”的主题,其包含一个分区,只有一个副本
2.3.1新建第三个cmd命令窗口
在Windows操作系统中找到解压的kafka_2.12-2.4.0(跟上面的一样)
在这里输入cmd--->然后回车
会出现一个小黑窗(黑窗口3)
2.3.1.1在小黑窗3中输入.\bin\windows\kafka-topics.bat --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test004然后回车
(若出现Created topic topic_test001表示成功)
2.3.2查看是否创建成功
在黑窗口3中输入.\bin\windows\kafka-topics.bat -list -zookeeper localhost:2181然后回车
如果显示有test004表示创建成功

三、安装Flume
1.1访问Flume的官网(http://flume.apache.org/download.html),下载Flume安装apache-flume-1.9.0-bin.tar.gz。或者下载我的百度网盘资源。把安装文件解压缩到windows操作“D:\”目录下,然后执行如下命令测试是否安装成功:
>e: 切换盘符
> cd E:\bigdataCol\apache-flume-1.9.0-bin\bin 切换到flume的bin目录
> flume-ng version 执行该命令测试
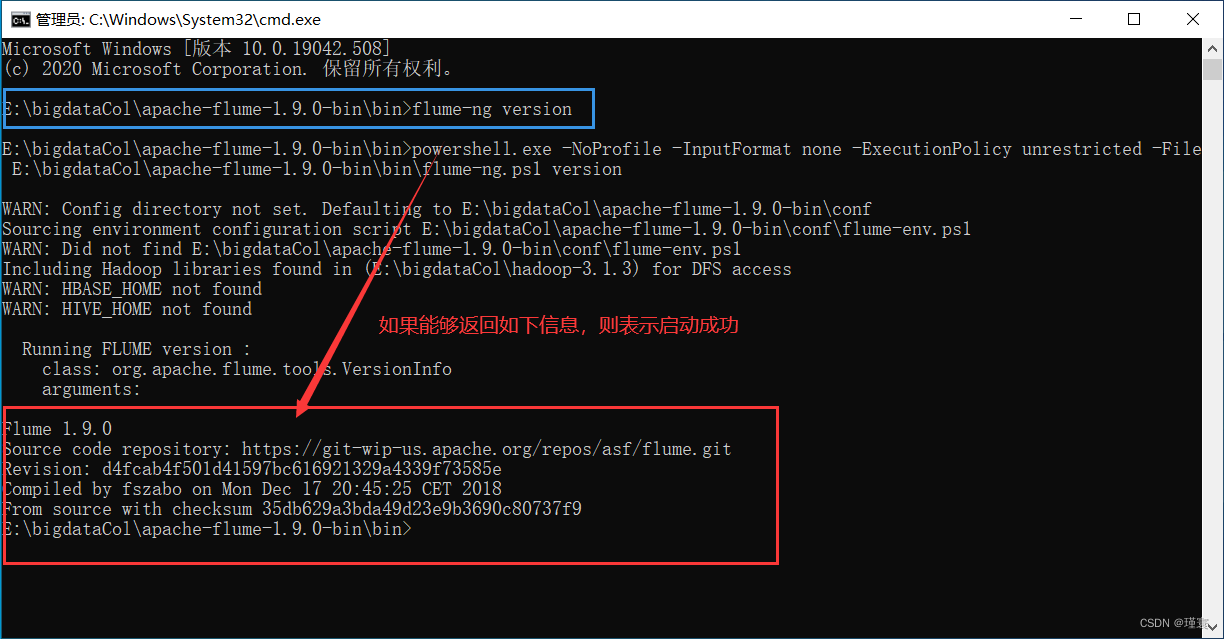
如果启动中提示PathNotFount: java.exe,则需要配置java的环境变量,JAVA_HOME=java的安装路径,在Path中配置%JAVA_HOME%\bin。注意:java的安装路径中尽量不要有空格。
1.2在Flume的安装目录的conf子目录下创建一个配置文件kafka.conf,内容如下:
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1# source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444# sink
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.topic = test
a1.sinks.k1.kafka.bootstrap.servers = localhost:9092
a1.sinks.k1.kafka.flumeBatchSize = 20
a1.sinks.k1.kafka.producer.acks = 1
a1.sinks.k1.kafka.producer.linger.ms = 1
a1.sinks.k1.kafka.producer.compression.type = snappy
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1# channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
1.3打开第4个cmd窗口,执行如下命令启动Flume:
> cd E:\bigdataCol\apache-flume-1.9.0-bin
> .\bin\flume-ng agent --conf .\conf --conf-file .\conf\kafka.conf --name a1 -property flume.root.logger=INFO,console

1.4打开第5个cmd窗口,执行如下命令:
> telnet localhost 44444
执行上面命令以后,在该窗口内用键盘输入一些单词,比如“hadoop”。这个单词会发送给Flume,然后,Flume发送给Kafka。

1.5打开第6个cmd窗口,执行如下命令:
>cd E:\bigdataCol\kafka_2.12-2.4.0
>.\bin\windows\kafka-console-consumer.bat --bootstrap-server localhost:9092 --topic test --from-beginning
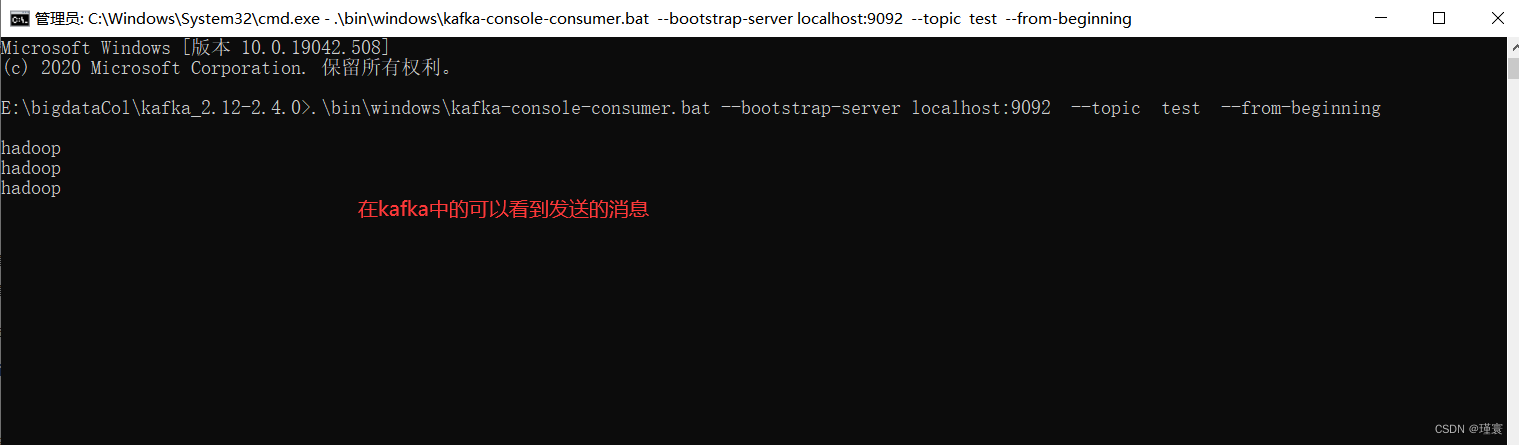
执行成功后在kafka中可以看到hadoop
相关文章:
Flume和Kafka的组合使用
一.安装Kafka 1.1下载安装包 通过百度网盘分享的文件:复制链接打开「百度网盘APP 即可获取」 链接:https://pan.baidu.com/s/1vC6Di3Pml6k1KMbnK0OE1Q?pwdhuan 提取码:huan 也可以访问官网,下载kafka2.4.0的安装文件 1.2解…...
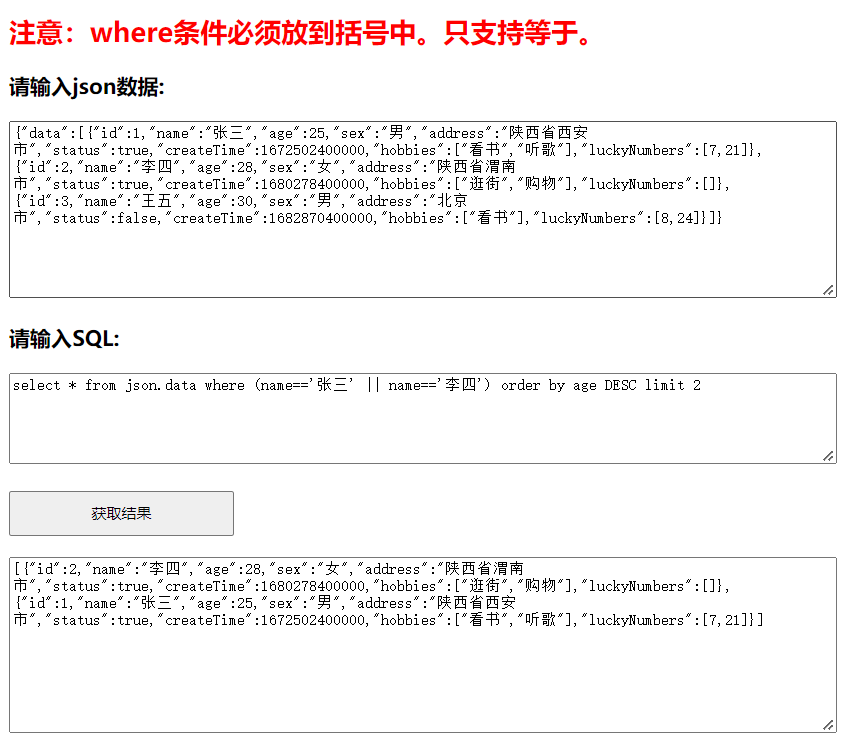
JSONSQL:使用SQL过滤JSON类型数据(支持多种数据库常用查询、统计、平均值、最大值、最小值、求和语法)...
1. 简介 在开发中,经常需要根据条件过滤大批量的JSON类型数据。如果仅需要过滤这一种类型,将JSON转为List后过滤即可;如果相同的条件既想过滤数据库表中的数据、也想过滤内存中JSON数据,甚至想过滤Elasticsearch中的数据ÿ…...
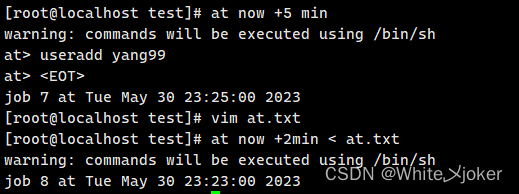
Linux输入输出重定向
目录 Linux输入输出重定向 Linux中的默认设备 输入输出重定向定义 输入输出重定向操作符 实用形式 标准输入、标准输出、标准错误 输出重定向案例 案例1 --- 输出重定向(覆盖) 案例2 --- 输出重定向(追加) 案例3 --- 错误…...
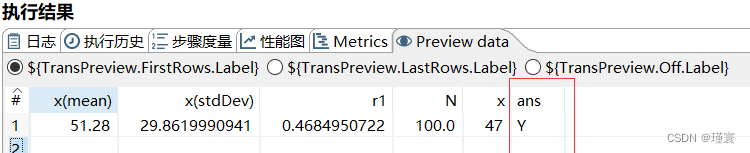
使用kettle进行数据统计
1.使用kettle设计一个能生成100个取值范围为0到100随机整数的转换。 为了完成该转换,需要使用生成记录控件、生成随机数控件、计算器控件及字段选择控件。控件布局如下图所示 生成记录控件可以在限制框内指定生成记录的个数,具体配置如图所示 生成随机数…...

线程的取消和清理
一、线程的取消 意义:随时杀掉一个线程 int pthread_cancel(pthread_t thread); 注意:线程的取消要有取消点才可以,不是说取消就取消,线程的取消点主要是阻塞的系统调用 二、运行段错误调试 可以使用gdb调试 使用gdb 运行代…...

day8 -- 全文本搜索
brief InnoDB存储引擎从MySQL 5.6开始支持全文本搜索。具体来说,MySQL使用InnoDB存储引擎的全文本搜索功能称为InnoDB全文本搜索(InnoDB Full-Text Search)。InnoDB全文本搜索支持标准的全文本搜索查询语法和多语言分词器,因此可…...

C语言:if-else语句
嗨,今天咱们讲讲C语言控制语句里的条件选择,主要总结下if else语句。 咱们生活里经常会有这样的场景,明天该怎么穿呢,得考虑下具体的天气。如果是晴天,温度还不错,可以穿T恤;如果是阴天…...

C语言---函数
1、函数是什么 学习库函数网站: https://cplusplus.com/reference/http://en.cppreference.comhttp://zh.cppreference.com 我们参考文档,学习几个库函数 2、库函数 3、自定义函数 自定义函数和库函数一样,有函数名,返回值类…...
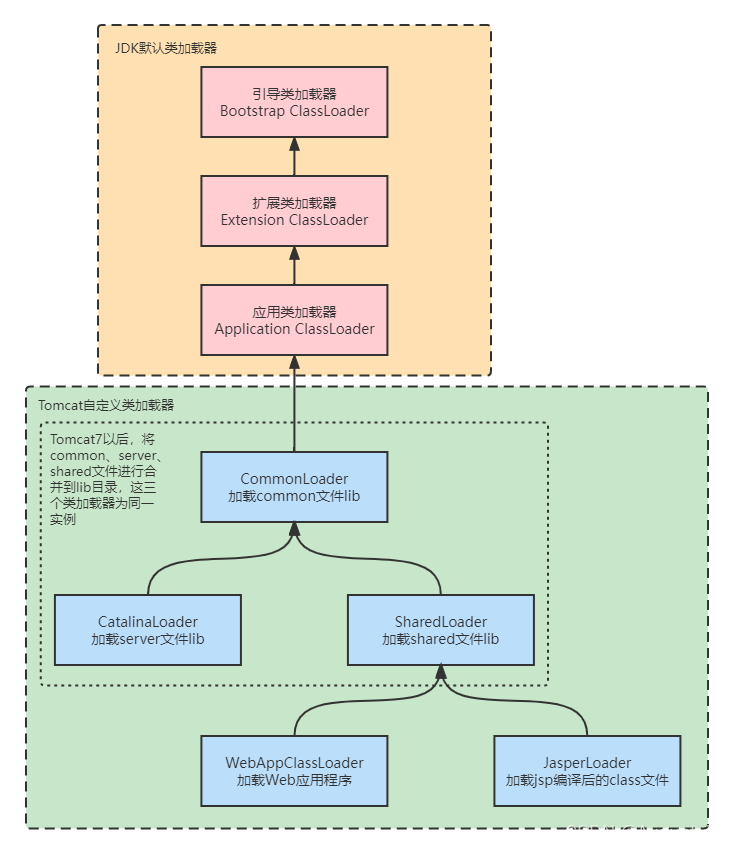
【JVM】什么是双亲委派机制?
一、为什么会有这种机制? 类加载器将.class类加载到内存中时,为了避免重复加载(确保Class对象的唯一性)以及JVM的安全性,需要使用某一种方式来实现只加载一次,加载过就不能被修改或再次加载。 二、什么是双…...

Vulkan Tutorial 7 纹理贴图
目录 23 图像 图片库 暂存缓冲区 纹理图像 布局转换 将缓冲区复制到图像上 准备纹理图像 传输屏障掩码 清除 24 图像视图和采样器 纹理图像视图 采样器 Anisotropy 设备特征 25 组合图像采样器 更新描述符 纹理坐标系 着色器 23 图像 添加纹理将涉及以下步骤&am…...

LinkedBlockingQueue阻塞队列
➢ LinkedBlockingQueue阻塞队列 LinkedBlockingQueue类图 LinkedBlockingQueue 中也有两个 Node 分别用来存放首尾节点,并且里面有个初始值为 0 的原子变量 count 用来记录队列元素个数,另外里面有两个ReentrantLock的独占锁,分别用来控制…...

面试-Redis 常见问题,后续面试遇到新的在补充
面试-Redis 1.谈谈Redis 缓存穿透,击穿,雪崩及如何避免 缓存穿透:是指大量访问请求在访问一个不存在的key,由于key 不存在,就会去查询数据库,数据库中也不存在该数据,无法将数据存储到redis 中…...

2023年上半年数据库系统工程师上午真题及答案解析
1.计算机中, 系统总线用于( )连接。 A.接口和外设 B.运算器、控制器和寄存器 C.主存及外设部件 D.DMA控制器和中断控制器 2.在由高速缓存、主存和硬盘构成的三级存储体系中,CPU执行指令时需要读取数据,那么DMA控制器和中断CPU发出的数据地…...

设计模式概念
设计模式是软件工程领域中常用的解决问题的经验总结和最佳实践。它们提供了一套被广泛接受的解决方案,用于处理常见的设计问题,并促进可重用、可扩展和易于维护的代码。 设计模式的主要目标是提高软件的可重用性、可扩展性和灵活性,同时降低…...

arcpy批量对EXCE经纬度L进行投点,设置为wgs84坐标系,并利用该点计算每个区域内的核密度
以下是在 ArcPy 中批量对 Excel 经纬度 L 进行投点,设置为 WGS84 坐标系,并利用该点计算每个区域内的核密度的详细步骤: 1. 准备数据: 准备包含经纬度信息的 Excel 数据表格,我们假设文件路径为 "C:/Data/locations.xlsx&qu…...
Yolov5训练自己的数据集
先看下模型pt说明 YOLOv5s:这是 YOLOv5 系列中最小的模型。“s” 代表 “small”(小)。该模型在计算资源有限的设备上表现最佳,如移动设备或边缘设备。YOLOv5s 的检测速度最快,但准确度相对较低。 YOLOv5m࿱…...

Bert+FGSM中文文本分类
我上一篇博客已经分别用BertFGSM和BertPGD实现了中文文本分类,这篇文章与我上一篇文章BertFGSM/PGD实现中文文本分类(Loss0.5L10.5L2)_Dr.sky_的博客-CSDN博客的不同之处在于主要在对抗训练函数和embedding添加扰动部分、模型定义部分、Loss函数传到部分…...
)
爬楼梯问题-从暴力递归到动态规划(java)
爬楼梯,每次只能爬一阶或者两阶,计算有多少种爬楼的情况 爬楼梯--题目描述暴力递归递归缓存动态规划暴力递归到动态规划专题 爬楼梯–题目描述 一个总共N 阶的楼梯(N > 0) 每次只能上一阶或者两阶。问总共有多少种爬楼方式。 示…...

浏览器如何验证SSL证书?
浏览器如何验证SSL证书?当前SSL证书应用越来越广泛,我们看见的HTTPS网站也越来越多。点击HTTPS链接签名的绿色小锁,我们可以看见SSL证书的详细信息。那么浏览器是如何验证SSL证书的呢? 浏览器如何验证SSL证书? 在浏览器的菜单中…...
】:: ll 指令 :: 查看指定目录下的文件详细信息)
Linux :: 【基础指令篇 :: 文件及目录操作:(10)】:: ll 指令 :: 查看指定目录下的文件详细信息
前言:本篇是 Linux 基本操作篇章的内容! 笔者使用的环境是基于腾讯云服务器:CentOS 7.6 64bit。 学习集: C 入门到入土!!!学习合集Linux 从命令到网络再到内核!学习合集 目录索引&am…...

8. Python 模块与包 深度解析
Python 模块与包 深度解析 目录 模块与包的概念模块基础 2.1 模块即 .py 文件2.2 import 语句与 from ... import2.3 模块搜索路径 sys.path 模块的编译与缓存包 4.1 常规包与 __init__.py4.2 命名空间包4.3 相对导入与绝对导入 __name__ 与 "__main__"模块与包的组…...

Azure机器学习实战:汽车价格预测模型端到端部署
1. 项目概述:在 Azure 上构建一个真正能落地的汽车价格预测模型你有没有试过想买一辆二手车,却在几个平台之间反复比价、查配置、翻论坛,最后还是拿不准这台车到底值不值这个价?或者作为数据新人,手头有份汽车数据集&a…...

使用TaotokenCLI工具一键配置开发环境与模型密钥
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用Taotoken CLI工具一键配置开发环境与模型密钥 在接入大模型进行开发时,手动配置API密钥、Base URL和模型ID是常见的…...

如何快速从图表图片中提取数据?WebPlotDigitizer终极使用指南
如何快速从图表图片中提取数据?WebPlotDigitizer终极使用指南 【免费下载链接】WebPlotDigitizer Computer vision assisted tool to extract numerical data from plot images. 项目地址: https://gitcode.com/gh_mirrors/we/WebPlotDigitizer 你是否曾面对…...

UE5 BaseInput.ini源码级解读:输入配置的底层原理与实战调优
1. 为什么一个INI文件值得花三天逐行精读?在UE5项目刚启动的第三天,我遇到一个看似微不足道却卡住整个输入调试流程的问题:手柄右摇杆的Y轴输入,在PC编辑器里始终返回0,但同一套蓝图逻辑在打包后的Windows平台却完全正…...

从低空协议劫持实战看 MAVLink 二进制审计在飞控发布环节的必要性
攻防实测复盘:协议劫持漏洞成因解析无人机接管攻击的本质不是高危漏洞,而是协议与生俱来的默认信任逻辑。近期多项低空攻防实测中,攻击者依托通用射频采集设备,即可持续捕获空口无线交互数据,实现对飞行设备的非正常控…...

2026年,IP地理位置精准查询的几个硬核技术变化
关于IP定位相关最近和几个同行交流,发现大家对IP定位的理解还停留在之前,想把自己这段时间的一些实践整理出来,希望能给同样在搞网络或风控的同行一些参考。 IPv6流量超过IPv4、住宅代理攻击泛滥、CGNAT覆盖越来越广……这些变化正在悄悄改变…...

用RT-Thread Studio玩转STM32 PWM:从电机控制到呼吸灯,一个框架搞定
用RT-Thread Studio玩转STM32 PWM:从电机控制到呼吸灯,一个框架搞定 在嵌入式开发领域,PWM(脉冲宽度调制)技术堪称"瑞士军刀"般的存在。无论是调节电机转速、控制舵机角度,还是实现LED呼吸灯效果…...
)
别再折腾超级密码了!2024年电信光猫改桥接,打这个电话最快(附完整话术)
2024年电信光猫改桥接最省心方案:一通电话搞定全流程 去年帮邻居调试网络时,发现一个有趣的现象——十个尝试自己破解光猫超级密码的用户里,有九个会卡在第一步。不是密码失效就是界面改版,最后不得不求助运营商。这让我意识到&am…...
)
别再死记硬背了!用Unity可视化工具一步步拆解A*寻路算法(附完整C#源码)
用Unity可视化工具玩转A*寻路算法:从理论到实战的沉浸式学习 在游戏开发的世界里,路径规划算法就像是一位隐形的向导,决定着NPC如何绕过障碍物找到玩家,或是战略游戏中单位如何选择最优行军路线。A*算法作为其中最耀眼的明星&…...