数据类型.
数据类型
数据类型分类

数值类型
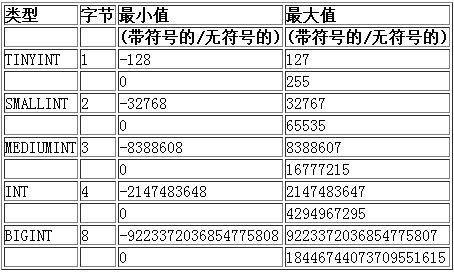
tinyint类型
数值越界测试:
mysql> create table tt1(num tinyint);
Query OK, 0 rows affected (0.02 sec)mysql> insert into tt1 values(1);
Query OK, 1 row affected (0.00 sec)mysql> insert into tt1 values(128); -- 越界插入,报错
ERROR 1264 (22003): Out of range value for column 'num' at row 1mysql> select * from tt1;
+------+
| num |
+------+
| 1 |
+------+
1 row in set (0.00 sec)说明:
- 在MySQL中,整型可以指定是有符号的和无符号的,默认是有符号的。
- 可以通过UNSIGNED来说明某个字段是无符号的
- 无符号案例
mysql> create table tt2(num tinyint unsigned);
mysql> insert into tt2 values(-1); -- 无符号,范围是: 0 - 255
ERROR 1264 (22003): Out of range value for column 'num' at row 1
mysql> insert into tt2 values(255);
Query OK, 1 row affected (0.02 sec)mysql> select * from tt2;
+------+
| num |
+------+
| 255 |
+------+
1 row in set (0.00 sec)
注意:尽量不使用unsigned,对于int类型可能存放不下的数据,int unsigned同样可能存放不下,与其如此,还不如设计时,将int类型提升为bigint类型。
bit类型
基本语法:
bit[(M)] : 位字段类型。M表示每个值的位数,范围从1到64。如果M被忽略,默认为1。
举例:
mysql> create table tt4 ( id int, a bit(8));
Query OK, 0 rows affected (0.01 sec)mysql> insert into tt4 values(10, 10);
Query OK, 1 row affected (0.01 sec)mysql> select * from tt4; #发现很怪异的现象,a的数据10没有出现
+------+------+
| id | a |
+------+------+
| 10 | |
+------+------+
1 row in set (0.00 sec)
bit使用的注意事项:
- bit字段在显示时,是按照ASCII码对应的值显示。
mysql> insert into tt4 values(65, 65);
mysql> select * from tt4;
+------+------+
| id | a |
+------+------+
| 10 | |
| 65 | A |
+------+------+
- 如果我们有这样的值,只存放0或1,这时可以定义bit(1)。这样可以节省空间。
mysql> create table tt5(gender bit(1));
mysql> insert into tt5 values(0);
Query OK, 1 row affected (0.00 sec)mysql> insert into tt5 values(1);
Query OK, 1 row affected (0.00 sec)mysql> insert into tt5 values(2); -- 当插入2时,已经越界了
ERROR 1406 (22001): Data too long for column 'gender' at row 1
小数类型
float
语法:
float[(m, d)] [unsigned] : M指定显示长度,d指定小数位数,占用空间4个字节
案例:
小数:float(4,2)表示的范围是-99.99 ~ 99.99,MySQL在保存值时会进行四舍五入。
mysql> create table tt6(id int, salary float(4,2));
Query OK, 0 rows affected (0.01 sec)
mysql> insert into tt6 values(100, -99.99);
Query OK, 1 row affected (0.00 sec)
mysql> insert into tt6 values(101, -99.991); #多的这一点被拿掉了
Query OK, 1 row affected (0.00 sec)
mysql> select * from tt6;
+------+--------+
| id | salary |
+------+--------+
| 100 | -99.99 |
| 101 | -99.99 |
+------+--------+
2 rows in set (0.00 sec)
案例:
如果定义的是float(4,2) unsigned 这时,因为把它指定为无符号的数,范围是 0 ~ 99.99
mysql> create table tt7(id int, salary float(4,2) unsigned);
Query OK, 0 rows affected (0.01 sec)mysql> insert into tt7 values(100, -0.1);
Query OK, 1 row affected, 1 warning (0.00 sec)mysql> show warnings;
+---------+------+-------------------------------------------------+
| Level | Code | Message |
+---------+------+-------------------------------------------------+
| Warning | 1264 | Out of range value for column 'salary' at row 1 |
+---------+------+-------------------------------------------------+
1 row in set (0.00 sec)mysql> insert into tt7 values(100, -0);
Query OK, 1 row affected (0.00 sec)mysql> insert into tt7 values(100, 99.99);
Query OK, 1 row affected (0.00 sec)
decimal
语法:
decimal(m, d) [unsigned] : 定点数m指定长度,d表示小数点的位数
- decimal(5,2) 表示的范围是 -999.99 ~ 999.99
- decimal(5,2) unsigned 表示的范围 0 ~ 999.99
- decimal和float很像,但是有区别: float和decimal表示的精度不一样
mysql> create table tt8 ( id int, salary float(10,8), salary2
decimal(10,8));
mysql> insert into tt8 values(100,23.12345612, 23.12345612);
Query OK, 1 row affected (0.00 sec)
mysql> select * from tt8;
+------+-------------+-------------+
| id | salary | salary2 |
+------+-------------+-------------+
| 100 | 23.12345695 | 23.12345612 | # 发现decimal的精度更准确,因此如果我们希望某个数据表示高精度,选择decimal
+------+-------------+-------------+
说明:float表示的精度大约是7位。
- decimal整数最大位数m为65。支持小数最大位数d是30。如果d被省略,默认为0.如果m被省略,默认是10。
- 建议:如果希望小数的精度高,推荐使用decimal。
字符串类型
char
语法:
char(L): 固定长度字符串,L是可以存储的长度,单位为字符,最大长度值可以为255
案例(char):
mysql> create table tt9(id int, name char(2));
Query OK, 0 rows affected (0.00 sec)mysql> insert into tt9 values(100, 'ab');
Query OK, 1 row affected (0.00 sec)mysql> insert into tt9 values(101, '中国');
Query OK, 1 row affected (0.00 sec)mysql> select * from tt9;
+------+--------+
| id | name |
+------+--------+
| 100 | ab |
| 101 | 中国 |
+------+--------+
说明:
- char(2) 表示可以存放两个字符,可以是字母或汉字,但是不能超过2个, 最多只能是255
mysql> create table tt10(id int ,name char(256));
ERROR 1074 (42000): Column length too big for column 'name' (max = 255); use BLOB or TEXT instead
varchar
语法:
varchar(L): 可变长度字符串,L表示字符长度,最大长度65535个字节
案例:
mysql> create table tt10(id int ,name varchar(6)); --表示这里可以存放6个字符mysql> insert into tt10 values(100, 'hello');mysql> insert into tt10 values(100, '我爱你,中国');mysql> select * from tt10;
+------+--------------------+
| id | name |
+------+--------------------+
| 100 | hello |
| 100 | 我爱你,中国 |
+------+--------------------+
说明:
关于varchar(len),len到底是多大,这个len值,和表的编码密切相关:
- varchar长度可以指定为0到65535之间的值,但是有1 - 3 个字节用于记录数据大小,所以说有效字节数是65532。
- 当我们的表的编码是utf8时,varchar(n)的参数n最大值是65532/3=21844[因为utf中,一个字符占用3个字节],如果编码是gbk,varchar(n)的参数n最大是65532/2=32766(因为gbk中,一个字符占用2字节)。
mysql> create table tt11(name varchar(21845))charset=utf8; --验证了utf8确实是不能超过21844
ERROR 1118 (42000): Row size too large. The maximum row size for the used table type, not counting BLOBs, is 65535. You have to change some columns to TEXT or BLOBsmysql> create table tt11(name varchar(21844)) charset=utf8;
Query OK, 0 rows affected (0.01 sec)
char和varchar比较

如何选择定长或变长字符串?
- 如果数据确定长度都一样,就使用定长(char),比如:身份证,手机号,md5
- 如果数据长度有变化,就使用变长(varchar), 比如:名字,地址,但是你要保证最长的能存的进去。
- 定长的磁盘空间比较浪费,但是效率高。
- 变长的磁盘空间比较节省,但是效率低。
- 定长的意义是,直接开辟好对应的空间
- 变长的意义是,在不超过自定义范围的情况下,用多少,开辟多少。
日期和时间类型
常用的日期有如下三个:
- date :日期 ‘yyyy-mm-dd’ ,占用三字节
- datetime 时间日期格式 ‘yyyy-mm-dd HH:ii:ss’ 表示范围从 1000 到 9999 ,占用八字节
- timestamp :时间戳,从1970年开始的 yyyy-mm-dd HH:ii:ss 格式和 datetime 完全一致,占用四字节
//创建表
mysql> create table birthday (t1 date, t2 datetime, t3 timestamp);
Query OK, 0 rows affected (0.01 sec)//插入数据:
mysql> insert into birthday(t1,t2) values('1997-7-1','2008-8-8 12:1:1'); --插入两种时间
Query OK, 1 row affected (0.00 sec)mysql> select * from birthday;
+------------+---------------------+---------------------+
| t1 | t2 | t3 |
+------------+---------------------+---------------------+
| 1997-07-01 | 2008-08-08 12:01:01 | 2017-11-12 18:28:55 | --添加数据时,时间戳自动补上当前时间
+------------+---------------------+---------------------+//更新数据:
mysql> update birthday set t1='2000-1-1';
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0mysql> select * from birthday;
+------------+---------------------+---------------------+
| t1 | t2 | t3 |
+------------+---------------------+---------------------+
| 2000-01-01 | 2008-08-08 12:01:01 | 2017-11-12 18:32:09 | -- 更新数据,时间戳会更新成当前时间
+------------+---------------------+---------------------+
enum和set
语法:
- enum:枚举,“单选”类型;
- enum(‘选项1’,‘选项2’,‘选项3’,…);
该设定只是提供了若干个选项的值,最终一个单元格中,实际只存储了其中一个值;而且出于效率考虑,这些值实际存储的是“数字”,因为这些选项的每个选项值依次对应如下数字:1,2,3,…最多65535个;当我们添加枚举值时,也可以添加对应的数字编号。
- set:集合,“多选”类型;
- set(‘选项值1’,‘选项值2’,‘选项值3’, …);
该设定只是提供了若干个选项的值,最终一个单元格中,设计可存储了其中任意多个值;而且出于效率考虑,这些值实际存储的是“数字”,因为这些选项的每个选项值依次对应如下数字:1,2,4,8,16,32,…最多64个。
说明:不建议在添加枚举值,集合值的时候采用数字的方式,因为不利于阅读。
案例:
- 有一个调查表votes,需要调查人的喜好, 比如(登山,游泳,篮球,武术)中去选择(可以多选),(男,女)[单选]
mysql> create table votes(
-> username varchar(30),
-> hobby set('登山','游泳','篮球','武术'), --注意:使用数字标识每个爱好的时候,想想Linux权限,采用比特位位置来个set中的爱好对应起来
-> gender enum('男','女')); --注意:使用数字标识的时候,就是正常的数组下标
Query OK, 0 rows affected (0.02 sec)
- 插入数据:
insert into votes values('雷锋', '登山,武术', '男');
insert into votes values('Juse','登山,武术',2);
select * from votes where gender=2;
+----------+---------------+--------+
| username | hobby | gender |
+----------+---------------+--------+
| Juse | 登山,武术 | 女 |
+----------+---------------+--------+
- 有如下数据,想查找所有喜欢登山的人:
+-----------+---------------+--------+
| username | hobby | gender |
+-----------+---------------+--------+
| 雷锋 | 登山,武术 | 男 |
| Juse | 登山,武术 | 女 |
| LiLei | 登山 | 男 |
| LiLei | 篮球 | 男 |
| HanMeiMei | 游泳 | 女 |
+-----------+---------------+--------+
- 使用如下查询语句:
mysql> select * from votes where hobby='登山';
+----------+--------+--------+
| username | hobby | gender |
+----------+--------+--------+
| LiLei | 登山 | 男 |
+----------+--------+--------+
集合查询使用find_ in_ set函数:
- find_in_set(sub,str_list) :如果 sub 在 str_list 中,则返回下标;如果不在,返回0;
- str_list 用逗号分隔的字符串。
mysql> select find_in_set('a', 'a,b,c');
+---------------------------+
| find_in_set('a', 'a,b,c') |
+---------------------------+
| 1 |
+---------------------------+
mysql> select find_in_set('d', 'a,b,c');
+---------------------------+
| find_in_set('d', 'a,b,c') |
+---------------------------+
| 0 |
+---------------------------+
- 查询爱好登山的人:
mysql> select * from votes where find_in_set('登山', hobby);
+----------+---------------+--------+
| username | hobby | gender |
+----------+---------------+--------+
| 雷锋 | 登山,武术 | 男 |
| Juse | 登山,武术 | 女 |
| LiLei | 登山 | 男 |
+----------+---------------+--------+
相关文章:
数据类型.
数据类型 数据类型分类 数值类型 tinyint类型 数值越界测试: mysql> create table tt1(num tinyint); Query OK, 0 rows affected (0.02 sec)mysql> insert into tt1 values(1); Query OK, 1 row affected (0.00 sec)mysql> insert into tt1 values(128…...

深入了解JavaScript中的Promise
在JavaScript中,异步编程是必不可少的。过去,我们通常使用回调函数来处理异步操作,但回调地狱(callback hell)和复杂的错误处理使得代码难以维护。为了解决这些问题,ES6引入了Promise,它是一种更…...
Solidity基础六
生活本来就是平凡琐碎的,哪有那么多惊天动地的大事,快乐的秘诀就是不管对大事小事都要保持热情 目录 一、Solidity的特殊变量(全局) 二、Solidity的不可变量 immutable的赋值方式 三、Solidity的事件与日志 事件和日志加深理解 四、Solidity的异常…...

自学网络安全解决问题方法
自学网络安全很容易学着学着就迷茫了,找到源头问题,解决它就可以了,所以首先咱们聊聊,学习网络安全方向通常会有哪些问题,看到后面有惊喜哦 1、打基础时间太长 学基础花费很长时间,光语言都有几门…...
)
Java之旅(七)
Java 异常 Java异常(Exception)是在程序运行过程中出现错误或异常情况时,由程序自动抛出,导致程序无法正常运行,用于向上层调用程序传递错误信息或中断程序执行的一种机制。 异常与错误不同,错误是由于程…...

测试报告模板二
项目名称 系统测试报告 平台测试小组 2023年x月xx日 文档信息 文档名称: 作者:...

C语句概述
1 、 C 语句分类: ①控制语句:二个分支语句( if-else 、 switch ),三个循环语句( for 、 while 、 do - while ),四个转移语句( continue 、 break 、 goto 、 return…...

C++ [STL之vector模拟实现]
本文已收录至《C语言和高级数据结构》专栏! 作者:ARMCSKGT STL之vector模拟实现 前言正文空间结构默认成员函数构造函数拷贝构造函数赋值重载析构函数关于数据拷贝问题 迭代器容量操作查询容量容量操作 数据访问下标访问头尾数据访问 数据增删尾插尾删重…...
【算法竞赛进阶指南】141.周期 题解 KMP 最小循环节
题目描述 一个字符串的前缀是从第一个字符开始的连续若干个字符,例如 abaab 共有 5 5 5 个前缀,分别是 a,ab,aba,abaa,abaab。 我们希望知道一个 N N N 位字符串 S S S 的前缀是否具有循环节。 换言之…...

【Springboot 入门培训 】#19 Spring Boot 组件扫描与bean生命周期
目录 1 什么是组件扫描2 何时使用组件扫描3 扫描整个包basePackages与 includeFilters4 Spring boot 的 Bean 生命周期4.1 生命周期4.2 Bean 生命周期4.3 周期各个阶段 首先,我想先为你介绍一下“Spring”,这是一个开放源代码的设计模式解决方案和轻量级…...

Linux printf 函数输出问题
printf 函数并不会直接将数据输出到屏幕,而是先放到缓冲区中,只有一下三种情况满足,才会输出到屏幕。 1) 缓冲区满 2) 强制刷新缓冲区 fflush 3) 程序结束时 1 #include<stdio.h>2 #include<st…...
皮卡丘Unsafe Fileupload
1.不安全的文件上传漏洞概述 文件上传功能在web应用系统很常见,比如很多网站注册的时候需要上传头像、上传附件等等。当用户点击上传按钮后,后台会对上传的文件进行判断 比如是否是指定的类型、后缀名、大小等等,然后将其按照设计的格式进行…...
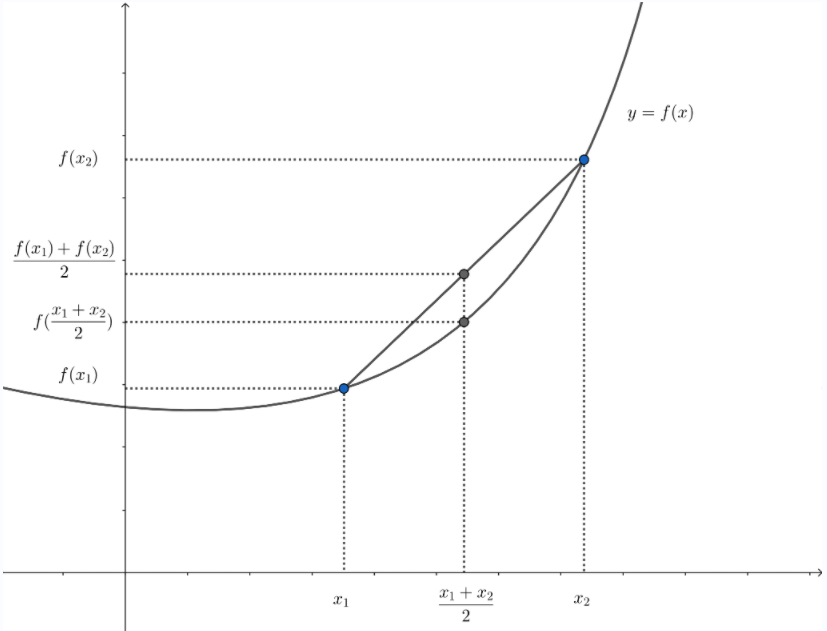
最优化简明版(上)
引言 本文简单地介绍一些凸优化(Convex Optimization)的基础知识,可能不会有很多证明推导,目的是能快速应用到机器学习问题上。 凸集 直线与线段 设 x 1 ≠ x 2 x_1 \neq x_2 x1x2为 R n \Bbb R^n Rn空间中的两个点,那么具有下列形…...

MySQL的一些介绍
1. SQL的select语句完整的执行顺序 SQL Select语句完整的执行顺序: 1、from子句组装来自不同数据源的数据; 2、where子句基于指定的条件对记录行进行筛选; 3、group by子句将数据划分为多个分组; 4、使用聚集函数进行计算&am…...

unity发布webGL后无法预览解决
众所周知,unity发布成webgl后是无法直接预览的。因为一般来说浏览器默认都是禁止webgl运行的。 直接说我最后的解决方法:去vscode里下载一个live server ,安装好。 下载vscode地址Visual Studio Code - Code Editing. Redefined 期间试过几种方法都不管…...
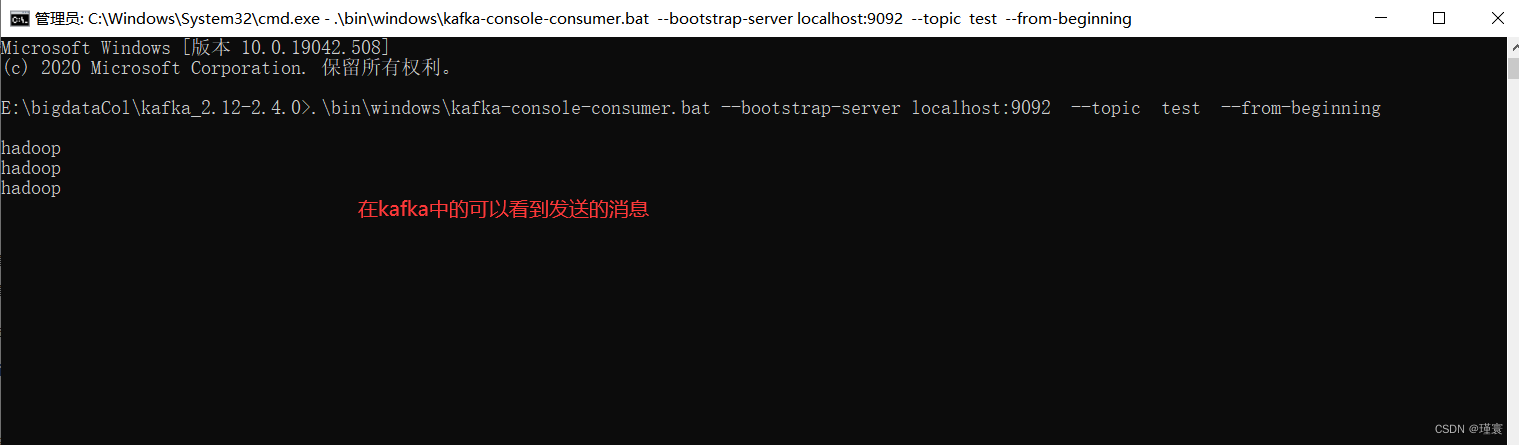
Flume和Kafka的组合使用
一.安装Kafka 1.1下载安装包 通过百度网盘分享的文件:复制链接打开「百度网盘APP 即可获取」 链接:https://pan.baidu.com/s/1vC6Di3Pml6k1KMbnK0OE1Q?pwdhuan 提取码:huan 也可以访问官网,下载kafka2.4.0的安装文件 1.2解…...
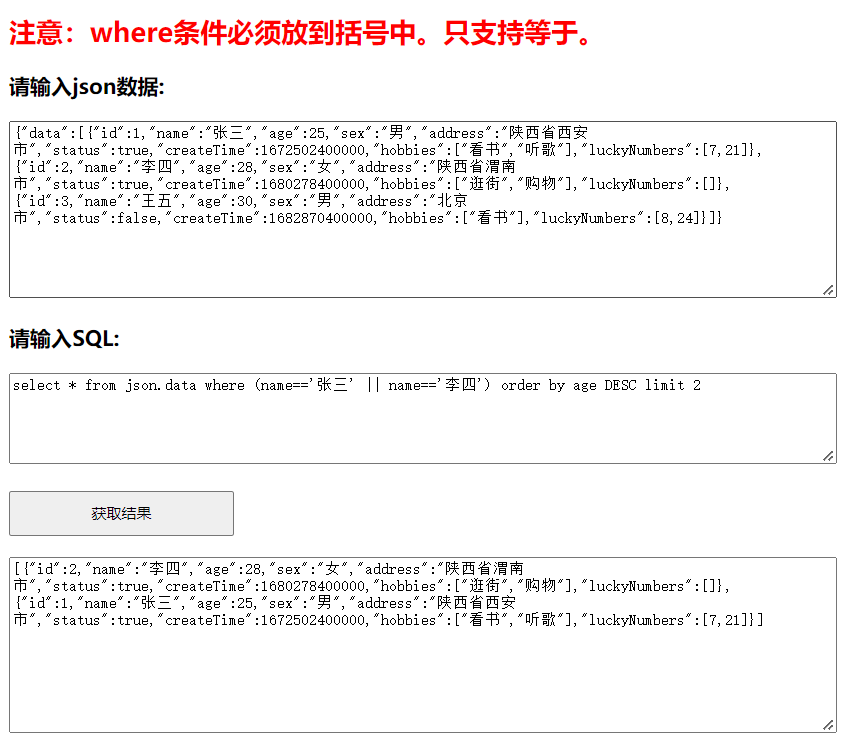
JSONSQL:使用SQL过滤JSON类型数据(支持多种数据库常用查询、统计、平均值、最大值、最小值、求和语法)...
1. 简介 在开发中,经常需要根据条件过滤大批量的JSON类型数据。如果仅需要过滤这一种类型,将JSON转为List后过滤即可;如果相同的条件既想过滤数据库表中的数据、也想过滤内存中JSON数据,甚至想过滤Elasticsearch中的数据ÿ…...
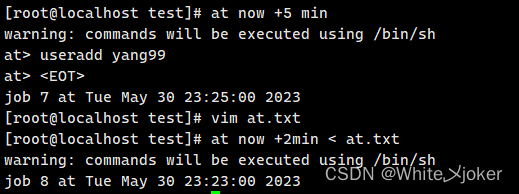
Linux输入输出重定向
目录 Linux输入输出重定向 Linux中的默认设备 输入输出重定向定义 输入输出重定向操作符 实用形式 标准输入、标准输出、标准错误 输出重定向案例 案例1 --- 输出重定向(覆盖) 案例2 --- 输出重定向(追加) 案例3 --- 错误…...
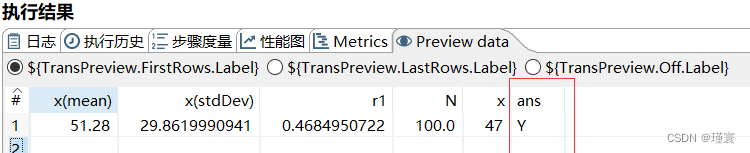
使用kettle进行数据统计
1.使用kettle设计一个能生成100个取值范围为0到100随机整数的转换。 为了完成该转换,需要使用生成记录控件、生成随机数控件、计算器控件及字段选择控件。控件布局如下图所示 生成记录控件可以在限制框内指定生成记录的个数,具体配置如图所示 生成随机数…...

线程的取消和清理
一、线程的取消 意义:随时杀掉一个线程 int pthread_cancel(pthread_t thread); 注意:线程的取消要有取消点才可以,不是说取消就取消,线程的取消点主要是阻塞的系统调用 二、运行段错误调试 可以使用gdb调试 使用gdb 运行代…...

CANN/asc-devkit最新管理器模块
latest_manager Module Description 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地…...
FlashAttention 在昇腾NPU上到底快在哪?一次拆透 ops-transformer 的核心算子
这是一篇关于昇腾NPU上FlashAttention技术深度解析的CSDN博客文章。文章结合了您提供的网页信息(特别是ops-transformer仓库的上下文)以及深度学习算子优化的专业知识,旨在帮助开发者理解其原理、优势及在昇腾生态中的应用。 FlashAttention …...

抖音无水印下载器全解析:从零构建你的个人视频收藏库
抖音无水印下载器全解析:从零构建你的个人视频收藏库 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback suppor…...

终极指南:ViGEmBus虚拟游戏控制器驱动,Windows游戏输入革命性解决方案
终极指南:ViGEmBus虚拟游戏控制器驱动,Windows游戏输入革命性解决方案 【免费下载链接】ViGEmBus Windows kernel-mode driver emulating well-known USB game controllers. 项目地址: https://gitcode.com/gh_mirrors/vi/ViGEmBus 想要在Windows…...

嵌入式开发通用工具包设计:提升效率与代码质量的核心架构
1. 项目概述:为什么嵌入式开发需要一个“工具箱”?干了十几年嵌入式,从8位单片机玩到多核ARM Cortex-A,我最大的感受就是:重复造轮子和调试效率低下是拖慢项目进度的两大元凶。每次新项目启动,都得重新搭建…...

设计模式之建造者
问题:构造函数参数太多(「伸缩构造」),或步骤必须按顺序、且步骤组合多变。做法:Director(可选)规定步骤顺序;Builder 提供 setA()、setB()… 最后 build() 返回产品。C 要点&#x…...

基于Windows Defender遥测数据与机器学习预测恶意软件感染风险
1. 项目概述:当Windows Defender遇见机器学习在网络安全这个没有硝烟的战场上,恶意软件(Malware)始终是悬在个人用户和企业头顶的达摩克利斯之剑。从勒索软件加密关键文件,到间谍软件窃取商业机密,每一次成…...

C++链接与符号管理
C链接与符号管理链接是将编译后的目标文件组合成可执行程序的过程。理解链接机制和符号管理对于解决链接错误和优化程序结构至关重要。外部链接允许符号在多个翻译单元间共享。#include extern int global_variable; extern void external_function();void external_linkage_ex…...

AI大模型核心:Prompt、Tool、Skill、Agent,一篇彻底搞懂它们之间的区别与实战应用!
如果你最近在用AI大模型,一定会被这四个词绕晕:Prompt、Tool、Skill、Agent。 这篇文章用最通俗的语言,一次性讲透四个概念的本质、核心区别。一、讲清楚每个概念到底是什么? 1、Prompt 本质上是人类给大模型的单次文本指令&#…...

谷歌收录怎么做比较快?Shopify过滤5个无效参数提升商品页收录
一个拥有5000个SPU的Shopify独立站,在Google Search Console后台的网页报告中,未收录网页数量高达45000个。索引分配明细标明,超过32000个URL带有“已抓取 - 目前未索引”标签。谷歌浏览器爬虫每天分配给该站点的抓取请求固定在4000次左右。检…...