尚硅谷大数据hadoop教程_mapReduce
p67 课程介绍

p68概述




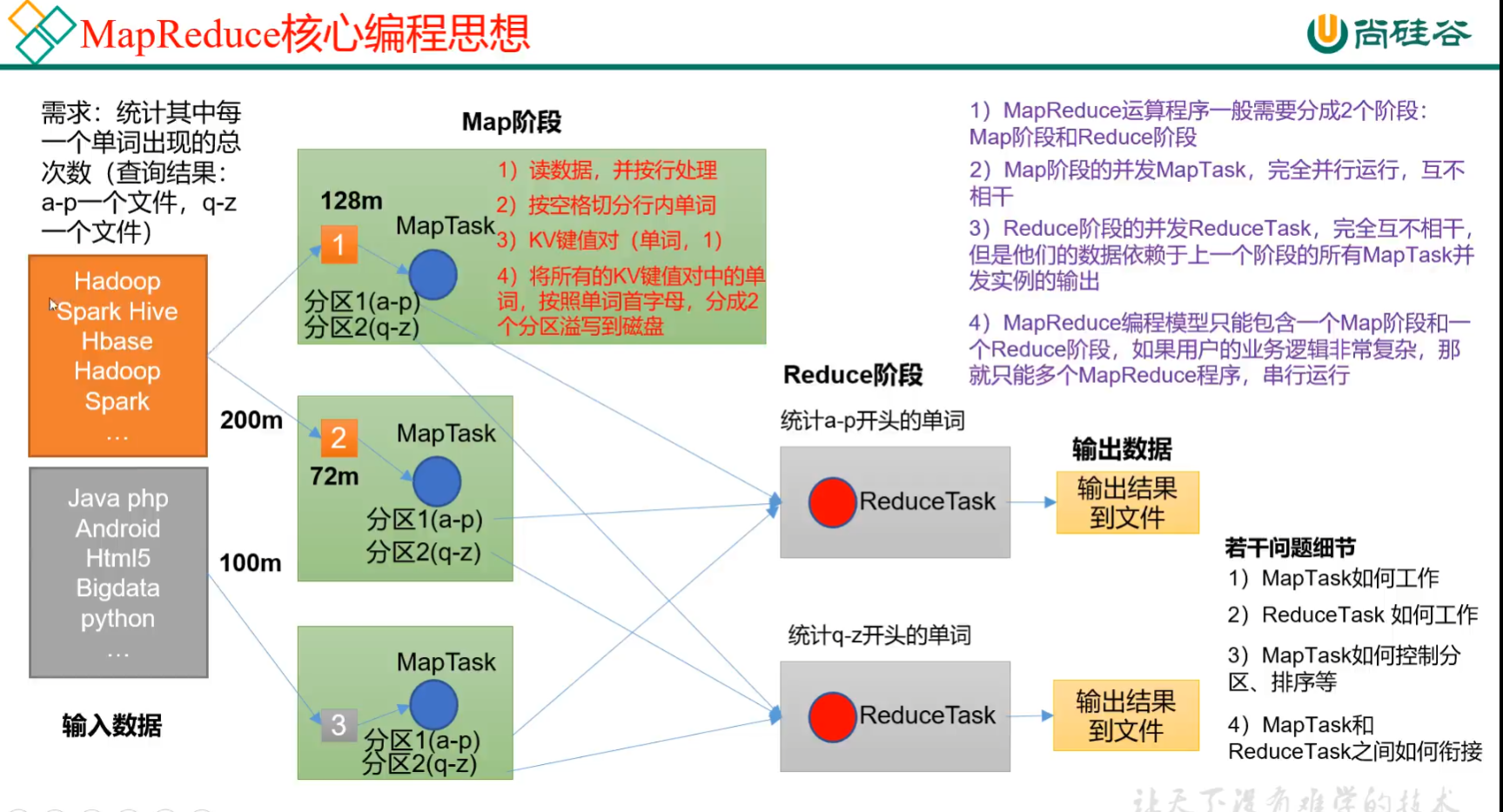
p69 mapreduce核心思想
p70 wordcount源码 序列化类型
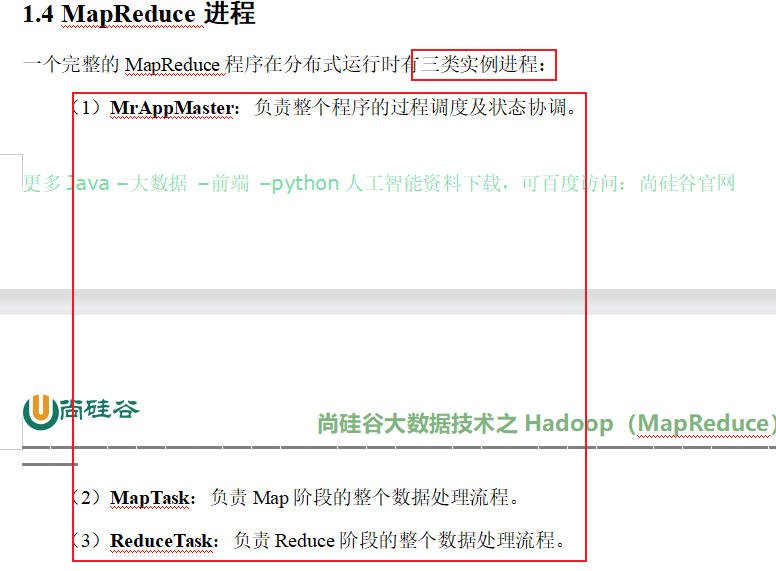
mapReduce三类进程

p71 编程规范
用户编写的程序分成三个部分:Mapper、Reducer和Driver。


P72 wordcount需求案例分析

p 73 -78 案例环境准备
(1)创建maven工程,MapReduceDemo
(2)在pom.xml文件中添加如下依赖
<dependencies><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>3.1.3</version></dependency><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.12</version></dependency><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-log4j12</artifactId><version>1.7.30</version></dependency>
</dependencies>
(2)在项目的src/main/resources目录下,新建一个文件,命名为“log4j.properties”,在文件中填入。
log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
(3)创建包名:com.atguigu.mapreduce.wordcount
4)编写程序
(1)编写Mapper类
package com.atguigu.mapreduce.wordcount;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable>{Text k = new Text();IntWritable v = new IntWritable(1);@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {// 1 获取一行String line = value.toString();// 2 切割String[] words = line.split(" ");// 3 输出for (String word : words) {k.set(word);context.write(k, v);}}
}
(2)编写Reducer类
package com.atguigu.mapreduce.wordcount;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable>{int sum;
IntWritable v = new IntWritable();@Overrideprotected void reduce(Text key, Iterable<IntWritable> values,Context context) throws IOException, InterruptedException {// 1 累加求和sum = 0;for (IntWritable count : values) {sum += count.get();}// 2 输出v.set(sum);context.write(key,v);}
}
(3)编写Driver驱动类
package com.atguigu.mapreduce.wordcount;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;public class WordCountDriver {public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {// 1 获取配置信息以及获取job对象Configuration conf = new Configuration();Job job = Job.getInstance(conf);// 2 关联本Driver程序的jarjob.setJarByClass(WordCountDriver.class);// 3 关联Mapper和Reducer的jarjob.setMapperClass(WordCountMapper.class);job.setReducerClass(WordCountReducer.class);// 4 设置Mapper输出的kv类型job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(IntWritable.class);// 5 设置最终输出kv类型job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);// 6 设置输入和输出路径FileInputFormat.setInputPaths(job, new Path(args[0]));FileOutputFormat.setOutputPath(job, new Path(args[1]));// 7 提交jobboolean result = job.waitForCompletion(true);System.exit(result ? 0 : 1);}
}
本地测试
(1)需要首先配置好HADOOP_HOME变量以及Windows运行依赖
(2)在IDEA/Eclipse上运行程序
提交到集群测试
集群上测试
(1)用maven打jar包,需要添加的打包插件依赖
<build><plugins><plugin><artifactId>maven-compiler-plugin</artifactId><version>3.6.1</version><configuration><source>1.8</source><target>1.8</target></configuration></plugin><plugin><artifactId>maven-assembly-plugin</artifactId><configuration><descriptorRefs><descriptorRef>jar-with-dependencies</descriptorRef></descriptorRefs></configuration><executions><execution><id>make-assembly</id><phase>package</phase><goals><goal>single</goal></goals></execution></executions></plugin></plugins>
</build>
(2)将程序打成jar包
(3)修改不带依赖的jar包名称为 wc.jar,并拷贝该jar包到Hadoop集群的 /opt/module/hadoop-3.1.3 路径。
(4)启动Hadoop集群
[atguigu@hadoop102 hadoop-3.1.3]sbin/start-dfs.sh
[atguigu@hadoop103 hadoop-3.1.3]$ sbin/start-yarn.sh
(5)执行WordCount程序
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop jar wc.jar
com.atguigu.mapreduce.wordcount.WordCountDriver /user/atguigu/input /user/atguigu/output
p79-86 序列化案例


编写MapReduce程序
package com.atguigu.mapreduce.writable;import org.apache.hadoop.io.Writable;import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;public class FlowBean implements Writable {private long upFlow;private long downFlow;private long sumFlow;public FlowBean() {}public long getUpFlow() {return upFlow;}public void setUpFlow(long upFlow) {this.upFlow = upFlow;}public long getDownFlow() {return downFlow;}public void setDownFlow(long downFlow) {this.downFlow = downFlow;}public long getSumFlow() {return sumFlow;}public void setSumFlow() {sumFlow= upFlow+downFlow;}@Overridepublic void write(DataOutput out) throws IOException {out.writeLong(upFlow);out.writeLong(downFlow);out.writeLong(sumFlow);}@Overridepublic void readFields(DataInput in) throws IOException {upFlow = in.readLong();downFlow = in.readLong();sumFlow = in.readLong();}@Overridepublic String toString() {return upFlow + "\t" + downFlow + "\t" + sumFlow;}
}package com.atguigu.mapreduce.writable;import com.sun.org.apache.bcel.internal.generic.NEW;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;import javax.sound.sampled.Line;
import java.io.IOException;public class FlowMapper extends Mapper<LongWritable, Text,Text,FlowBean> {FlowBean flowBean = new FlowBean();Text keyPhone = new Text();@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {String line = value.toString();String[] arr = line.split("\t");String phone=arr[1];String up=arr[arr.length-3];String down=arr[arr.length-2];keyPhone.set(phone);flowBean.setUpFlow(Long.parseLong(up));flowBean.setDownFlow(Long.parseLong(down));flowBean.setSumFlow();context.write(keyPhone,flowBean);}
}package com.atguigu.mapreduce.writable;import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;public class FlowReducer extends Reducer<Text,FlowBean,Text,FlowBean> {private FlowBean reduceFlowBean=new FlowBean();@Overrideprotected void reduce(Text key, Iterable<FlowBean> values, Context context) throws IOException, InterruptedException {long up=0;long down=0;for (FlowBean flowBean: values) {up+=flowBean.getUpFlow();down+=flowBean.getDownFlow();}reduceFlowBean.setUpFlow(up);reduceFlowBean.setDownFlow(down);reduceFlowBean.setSumFlow();context.write(key,reduceFlowBean);}
}package com.atguigu.mapreduce.writable;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;public class FlowDriver {public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {Configuration config = new Configuration();Job job = Job.getInstance(config);job.setJarByClass(FlowDriver.class);job.setMapperClass(FlowMapper.class);job.setReducerClass(FlowReducer.class);job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(FlowBean.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(FlowBean.class);FileInputFormat.setInputPaths(job,new Path("D:\\inputFlow"));FileOutputFormat.setOutputPath(job,new Path("D:\\outputFlow"));boolean completion = job.waitForCompletion(true);System.exit(completion?0:1);}
}p87 88 切片机制与并行度决定机制
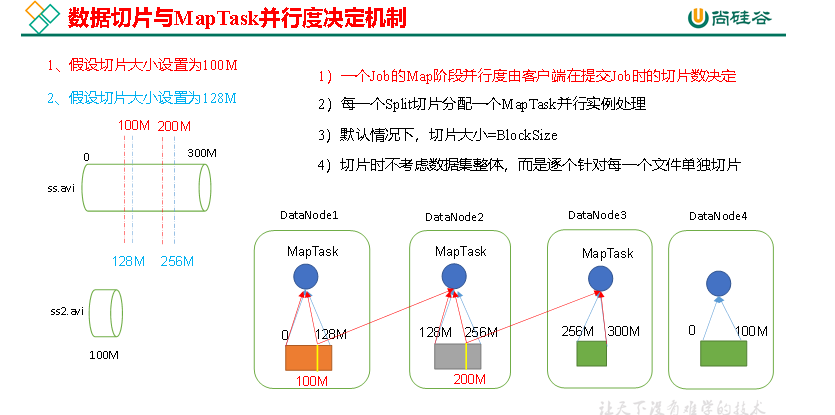
1)问题引出
MapTask的并行度决定Map阶段的任务处理并发度,进而影响到整个Job的处理速度。
思考:1G的数据,启动8个MapTask,可以提高集群的并发处理能力。那么1K的数据,也启动8个MapTask,会提高集群性能吗?MapTask并行任务是否越多越好呢?哪些因素影响了MapTask并行度?
2)MapTask并行度决定机制
数据块:Block是HDFS物理上把数据分成一块一块。数据块是HDFS存储数据单位。
数据切片:数据切片只是在逻辑上对输入进行分片,并不会在磁盘上将其切分成片进行存储。数据切片是MapReduce程序计算输入数据的单位,一个切片会对应启动一个MapTask。

生成临时目录 ,split文件和xml配置,如果是集群模式还要上传jar包
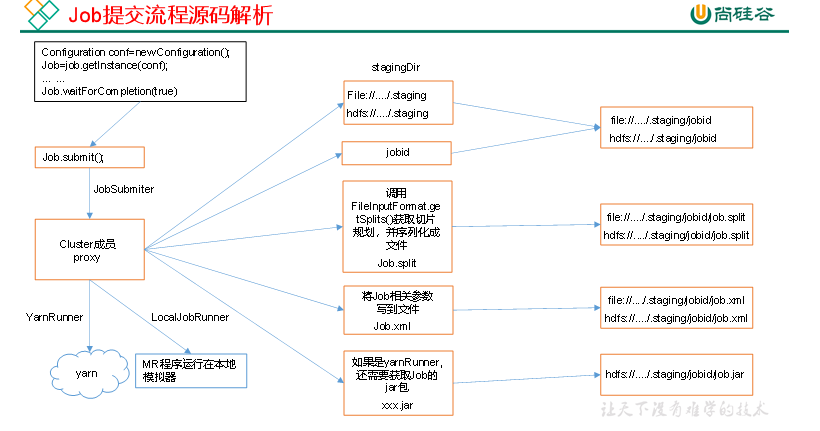
p89-91 切片源码



92 TextInputFormat

p92 93 CombineTextInputFormat切片机制



CombineTextInputFormat案例实操


p94 mapreduce工作流程
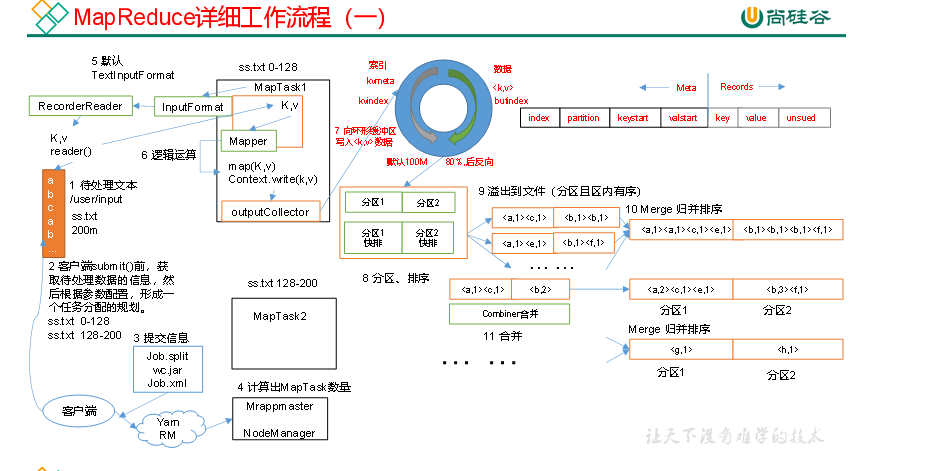
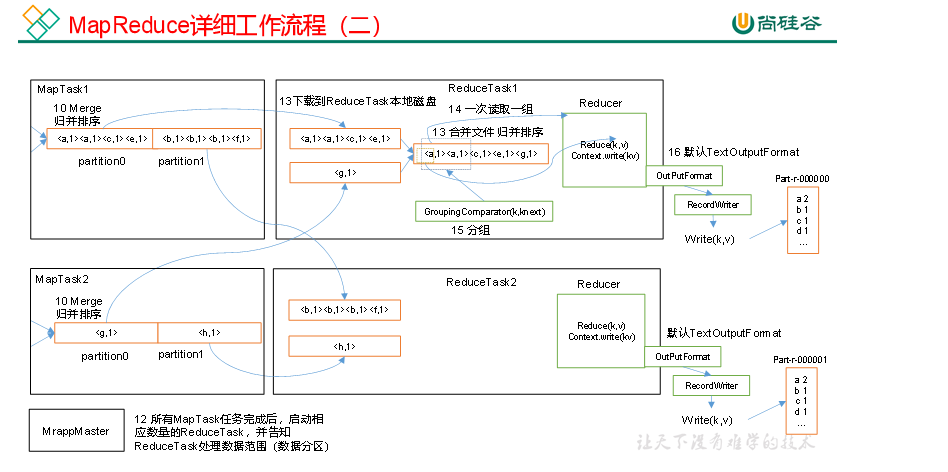
上面的流程是整个MapReduce最全工作流程,但是Shuffle过程只是从第7步开始到第16步结束,具体Shuffle过程详解,如下:
(1)MapTask收集我们的map()方法输出的kv对,放到内存缓冲区中
(2)从内存缓冲区不断溢出本地磁盘文件,可能会溢出多个文件
(3)多个溢出文件会被合并成大的溢出文件
(4)在溢出过程及合并的过程中,都要调用Partitioner进行分区和针对key进行排序
(5)ReduceTask根据自己的分区号,去各个MapTask机器上取相应的结果分区数据
(6)ReduceTask会抓取到同一个分区的来自不同MapTask的结果文件,ReduceTask会将这些文件再进行合并(归并排序)
(7)合并成大文件后,Shuffle的过程也就结束了,后面进入ReduceTask的逻辑运算过程(从文件中取出一个一个的键值对Group,调用用户自定义的reduce()方法)
注意:
(1)Shuffle中的缓冲区大小会影响到MapReduce程序的执行效率,原则上说,缓冲区越大,磁盘io的次数越少,执行速度就越快。
(2)缓冲区的大小可以通过参数调整,参数:mapreduce.task.io.sort.mb默认100M。
p95 shuffle工作机制
相关文章:
尚硅谷大数据hadoop教程_mapReduce
p67 课程介绍 p68概述 p69 mapreduce核心思想 p70 wordcount源码 序列化类型 mapReduce三类进程 p71 编程规范 用户编写的程序分成三个部分:Mapper、Reducer和Driver。 P72 wordcount需求案例分析 p 73 -78 案例环境准备 (1)创建maven…...

一键启停脚本
在/root 目录下创建bin文件夹再创建你的文件 文件里面写如下命令 #!/bin/bash if [ $# -lt 1 ] then echo "No Args Input..." exit ; fi case $1 in "start") echo " 启动集群 " echo " --------------- 启动 -------…...

20230604_Hadoop命令操作练习
20230604_Hadoop命令操作示例 再HDFS中创建文件夹:/itcast/it heima,如存在请删除(跳过回收站)。 hdfs dfs -mkdir -p /itcast/itheima上传/etc/hosts文件到hdfs的/itcast/itheima内。 hadoop fs -put /etc/hosts /itcast/itheima…...
?)
hashCode 与 equals(重要)?
hashCode () 作用是获取哈希码,也称为散列码,实际上是返回一个int 整数,哈希码作用是确定该对象在哈希表中的索引位置;hashCode() 定义在JDK的Object.java中,意味着Java中的任何类都包含有hashCode() 函数。 散列表存…...
 需要打开多少监控器(java,py,c++,js))
华为OD机试(2023.5新题) 需要打开多少监控器(java,py,c++,js)
华为OD机试真题目录:真题目录 本文章提供java、python、c++、jsNode四种代码 题目描述 某长方形停车场,每个车位上方都有对应监控器,当且仅当在当前车位或者前后左右四个方向任意一个车位范围停车时,监控器才需要打开 给出某一时刻停车场的停车分布,请统计最少需要打开…...

209.长度最小的子数组
2023.6.1 这道题的关键是滑动窗口法,滑动窗口法应设定好窗口左侧的右移条件与窗口右侧的移动条件 本例中先初始化好用到的各种值 循环的终止条件是滑动窗口右侧超出列表的范围 走来 cur_sum nums[right] 是将cur_sum的值更新为当前滑动窗口[left,right]的值之和 接…...

react antd Modal里Form设置值不起作用
问题描述: react antd Modal里Form设置值不起作用,即使用form的api。比如:编辑时带出原有的值。 造成的原因:一般设置值都是在声明周期里设置,比如:componentDidMounted里设置,hook则在useEff…...
idea连接Linux服务器
一、 介绍 配置idea的ssh会话和sftp可以实现对linux远程服务器的访问和文件上传下载,是替代Xshell的理想方式。这样我们就能在idea里面编写文件并轻松的将文件上传到linux服务器中。而且还能远程编辑linux服务器上的文件。掌握并熟练使用,能够大大提高我…...

在windows环境下使用winsw将jar包注册为服务(实现开机自启和配置日志输出模式)
前言 Windows系统使用java -jar m命令行运行Java项目会弹出黑窗。首先容易误点导致程序关闭,其次我们希望能在Windows系统做到开机自动启动。因此对于SpringBoot程序,目前主流的方法是采用winsw,简单容易配置 1.下载winsw工具 https://git…...

汽车通用款一键启动舒适进入拓展蓝牙4G网络手机控车系统
1.PKE无钥匙舒适进入功能,靠近车门自动开锁,离开车门自动上锁 2.一键启动/熄火 3.远程遥控启动/熄火 4.遥控设防盗/解除防盗 5.遥控开后尾箱锁负信号输出(需要原车自带尾箱马达和继电器) 6.静音防盗/解除防盗 7.启动车后踩脚刹自动上锁 8.熄火车辆后自动开锁…...

QSettings Class
QSettings类 QSettings类公共类型(枚举)公有成员函数静态成员函数函数作用这个类写文件的特征 QSettings类 QSettings类提供持久的独立于平台的应用程序设置。 头文件:#include< QSettings >qmake:QT core继承(父):QObje…...

【vue】关于vue中的插槽
当在Vue.js中构建可复用的组件时,有时候需要在父组件中传递内容给子组件。Vue的插槽(slot)机制提供了一种灵活的方式来实现这种组件间通信。 插槽允许你在父组件中编写子组件的内容,然后将其传递给子组件进行渲染。这样ÿ…...
Springboot整合Mybatis Plus【超详细】
文章目录 Mybatis Plus简介快速整合1,导入依赖2,yml文件中配置信息3,启动类上加上扫描mapper接口所在包的注解4,编写配置类5,实现自动注入通用字段接口(非必需)6,编写生成器工具类 使…...

接口测试-使用mock生产随机数据
在做接口测试的时候,有的接口需要进行大量的数据进行测试,还不能是重复的数据,这个时候就需要随机生产数据进行测试了。这里教导大家使用mock.js生成各种随机数据。 一、什么是mock.js mock.js是用于生成随*机数据,拦截 Ajax 请…...
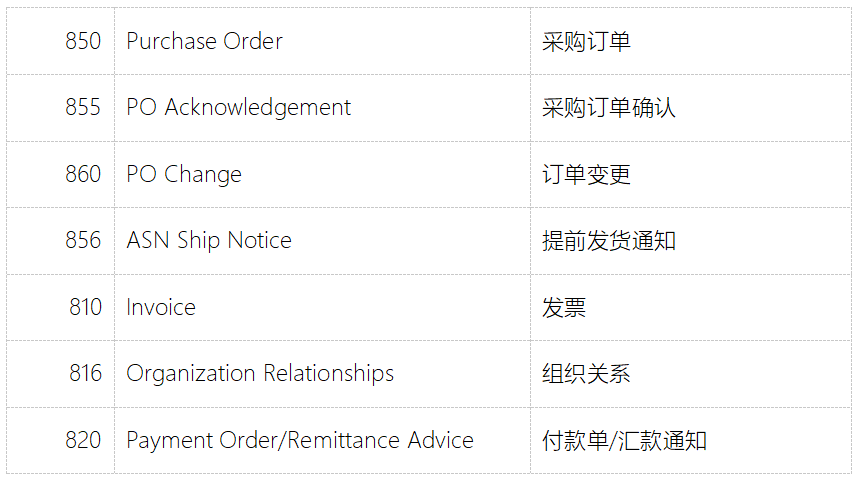
Kohl‘s百货的EDI需求详解
Kohls是一家美国的连锁百货公司,成立于1962年,总部位于美国威斯康星州的门多西。该公司经营各种商品,包括服装、鞋子、家居用品、电子产品、化妆品等,并拥有超过1,100家门店,分布在美国各地。本文将为大家介绍Kohls的E…...

二叉树part6 | ● 654.最大二叉树 ● 617.合并二叉树 ● 700.二叉搜索树中的搜索 ● 98.验证二叉搜索树
文章目录 654.最大二叉树思路代码 617.合并二叉树思路代码 700.二叉搜索树中的搜索思路代码 98.验证二叉搜索树思路官方题解代码困难 今日收获 654.最大二叉树 思路 前序遍历构造二叉树。 找出数组中最大值,然后递归处理左右子数组。 时间复杂度On2 空间复杂度On …...

Linux命令记录
Shells 查看当前系统shell cat /etc/shells # 输出 # /etc/shells: valid login shells /bin/sh /bin/bash /usr/bin/bash /bin/rbash /usr/bin/rbash /bin/dash /usr/bin/dash查看正在使用的shell echo $SHELL # 输出 /bin/bashLinux文件结构 bin:系统可执行文件b…...

eBPF 入门实践教程十五:使用 USDT 捕获用户态 Java GC 事件耗时
eBPF (扩展的伯克利数据包过滤器) 是一项强大的网络和性能分析工具,被广泛应用在 Linux 内核上。eBPF 使得开发者能够动态地加载、更新和运行用户定义的代码,而无需重启内核或更改内核源代码。这个特性使得 eBPF 能够提供极高的灵活性和性能,…...

Linux :: vim 编辑器的初次体验:三种 vim 常用模式 及 使用:打开编辑、退出保存关闭vim
前言:本篇是 Linux 基本操作篇章的内容! 笔者使用的环境是基于腾讯云服务器:CentOS 7.6 64bit。 学习集: C 入门到入土!!!学习合集Linux 从命令到网络再到内核!学习合集 目录索引&am…...

Linux内核进程创建流程
本文代码基于Linux5.10 内容主要参考《Linux内核深度解析》余华兵 当Linux内核要创建一个新进程时, 流程大致如下 ret fork(); if (ret 0) {/* 子进程装载程序 */ret execve(filename, argv, envp); } else if (ret > 0) {/* 父进程 */ } 大致可以分为创建新…...

福州儿童康复推荐
当我们谈论儿童康复时,其实是在谈论一个家庭面对未知时的所有期许与不安。每一个孩子的成长节奏都值得被尊重,尤其是那些在语言、社交或行为上稍显“慢热”的小天使。在福州,有这样一处地方,它不追求“速成”,也不承诺…...

当 AI 学会“说谎“:大模型幻觉问题深度解析
一、真实案例:AI 是如何"一本正经胡说八道"的案例 1:美国顶级律所的 2000 美元/小时错误 2026 年 4 月,纽约联邦法院。 一家时薪超过 2000 美元的顶级律所,在提交给法官的法律文件中,引用了 6 个根本不存在的判例。 这些判例不仅有名有姓,还有完整的案号、判…...

全球化2.0 | ZStack亮相印尼云计算与数据中心大会 以新一代云底座助力数字印尼建设
近日,由 W.Media 主办的印尼云计算和数据中心大会(Indonesia Cloud & Data Center Convention 2026)在雅加达举行。云轴科技 ZStack受邀参会,与来自印尼及国际数据中心行业的专业人士共同探讨企业云底座的最新进展与未来趋势。…...

2026年房建工程管理软件选购指南:7款主流工具横向对比,助你找到最适合的那一款
2025年,房建行业整体营收下滑5.62%,净利润降幅超20%,利润空间持续收窄。越来越多施工企业意识到,精细化管理是穿越周期的唯一路径。然而,数据孤岛、多分包协同混乱、合规要求升级,让选对一款工程管理软件变…...
一键脚本 + 完整配置)
OpenClaw 3 机集群(Windows + Linux 混合)一键脚本 + 完整配置
集群架构规划(1 主 2 从)统一安装脚本(Windows PowerShell / Linux bash)主节点配置(gateway 调度)从节点配置(worker 注册到主)集群通信、端口、令牌、存储一键启停、扩容、状态检…...

Cursor Free VIP技术架构深度解析:机器标识重置系统的实现原理
Cursor Free VIP技术架构深度解析:机器标识重置系统的实现原理 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached …...

实测Taotoken在多模型调用下的延迟与稳定性体感
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 实测Taotoken在多模型调用下的延迟与稳定性体感 1. 引言 在集成多个大模型API到实际业务或开发工作流时,开发者通常需…...

tRPC-Go 框架 01:tRPC-Go 总览与核心架构
tRPC-Go 框架 01:tRPC-Go 总览与核心架构 tRPC 是腾讯开源的多语言 RPC 框架,tRPC-Go 是其 Go 语言实现,已在腾讯内部支撑了海量服务(视频、音乐、新闻、广告等),日均调用量万亿级。本篇我们站高一点&…...

告别环境报错:用Docker 10分钟在本地/服务器部署YOLOv8完整开发环境
告别环境报错:用Docker 10分钟在本地/服务器部署YOLOv8完整开发环境 在计算机视觉领域,YOLOv8作为当前最先进的目标检测模型之一,其强大的性能和易用性吸引了大量开发者和研究者。然而,传统的手动搭建开发环境过程往往令人望而生畏…...

Cortex-Debug终极指南:5分钟掌握VSCode最强STM32调试工具
Cortex-Debug终极指南:5分钟掌握VSCode最强STM32调试工具 【免费下载链接】cortex-debug Visual Studio Code extension for enhancing debug capabilities for Cortex-M Microcontrollers 项目地址: https://gitcode.com/gh_mirrors/co/cortex-debug 还在为…...