Mysql InnoDB的Buffer Pool
Buffer Pool
在MySQL服务器启动的时候就向操作系统申请了⼀⽚连续的内存,他们给这⽚内存起了个名,叫做Buffer Pool(中⽂名
是缓冲池)。
默认情况下Buffer Pool只有128M⼤⼩,最⼩值为5M,通过修改配置文件设置其大小(256M):
[server]
innodb_buffer_pool_size = 268435456
Buffer Pool内部组成
Buffer Pool中默认的缓存⻚⼤⼩和在磁盘上默认的⻚⼤⼩是⼀样的,都是16KB。为了更好的管理这些在Buffer Pool中的缓存⻚,设计InnoDB的为每⼀个缓存⻚都创建了⼀些所谓的控制信息,这些控制信息包括该⻚所属的表空间编号、⻚号、缓存⻚在Buffer Pool中的地址、链表节点信息、⼀些锁信息以及LSN信息。
每个缓存⻚对应的控制信息占⽤的内存⼤⼩是相同的,每个⻚对应的控制信息占⽤的⼀块内存称为⼀个控制块吧,控制块和缓存⻚是⼀⼀对应的,它们都被存放到 Buffer Pool 中,其中控制块被存放到 Buffer Pool 的前边,缓存⻚被存放到 Buffer Pool 后边,所以整个Buffer Pool对应的内存空间。
每⼀个控制块都对应⼀个缓存⻚,那在分配⾜够多的控制块和缓存⻚后,可能剩余的那点⼉空间不够⼀对控制块和缓存⻚的⼤⼩,这个⽤不到的那点⼉内存空间就被称为碎⽚了

free链表的管理
把所有空闲的缓存⻚对应的控制块作为⼀个节点放到⼀个链表中,这个链表也可以被称作free链表,如下:

每当需要从磁盘中加载⼀个⻚到Buffer Pool中时,就从free链表中取⼀个空闲的缓存⻚,并且把该缓存⻚对应的控制块的信息填上(就是该⻚所在的表空间、⻚号之类的信息),然后把该缓存⻚对应的free链表节点从链表中移除,表示该缓存⻚已经被使⽤了。
缓存页的哈希处理
当我们需要访问某个⻚中的数据时,就会把该⻚从磁盘加载到Buffer Pool中,⽤表空间号 + ⻚号作为key,缓存⻚作为value创建⼀个哈希表,在需要访问某个⻚的数据时,先从哈希表中根据表空间号 + ⻚号看看有没有对应的缓存⻚,如果有,直接使⽤该缓存⻚就好,如果没有,那就从free链表中选⼀个空闲的缓存⻚,然后把磁盘中对应的⻚加载到该缓存⻚的位置。
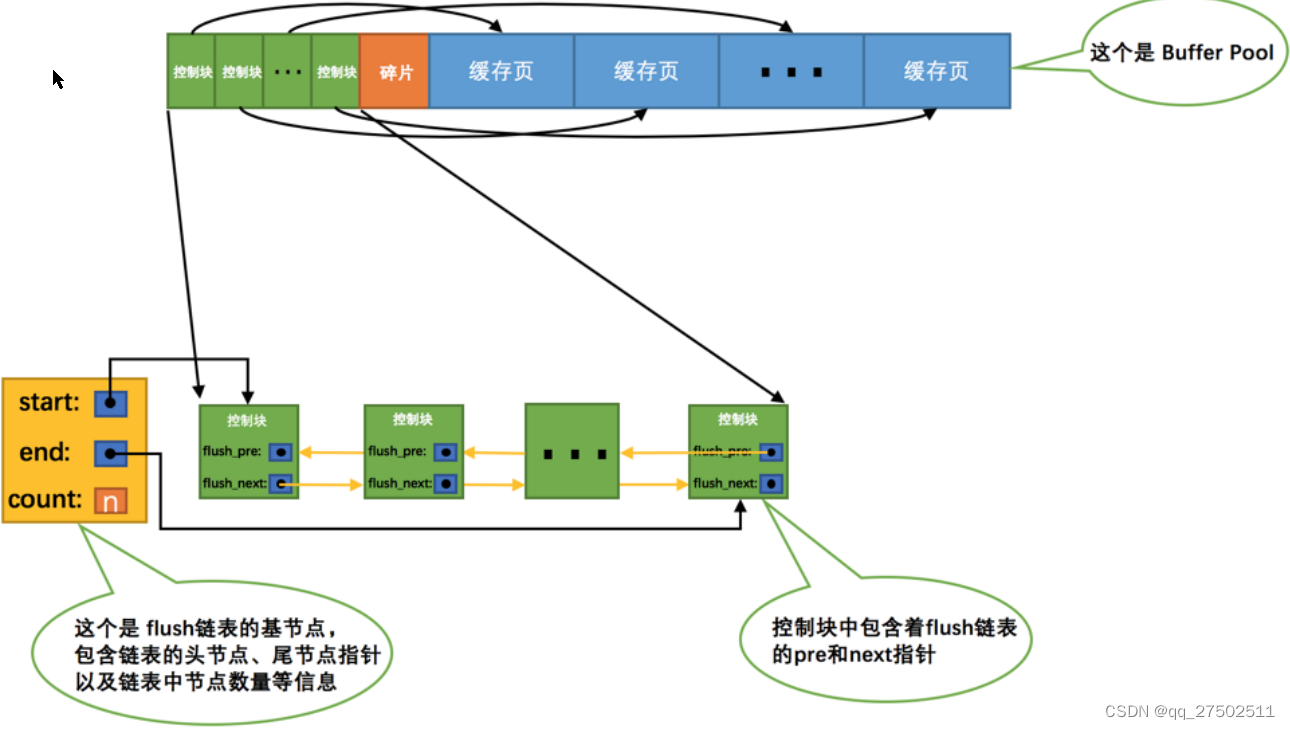
flush链表的管理
如果我们修改了Buffer Pool中某个缓存⻚的数据,那它就和磁盘上的⻚不⼀致了,这样的缓存⻚也被称为脏页(英⽂名:dirty page)。
凡是修改过的缓存⻚对应的控制块都会作为⼀个节点加⼊到⼀个链表中,因为这个链表节点对应的缓存⻚都是需要被刷新到磁盘上的,所以也叫flush链表。链表的构造和free链表差不多,假设某个时间点Buffer Pool中的脏⻚数量为n。
LRU链表的管理
当Buffer Pool中不再有空闲的缓存⻚时,就需要淘汰掉部分最近很少使⽤的缓存⻚。
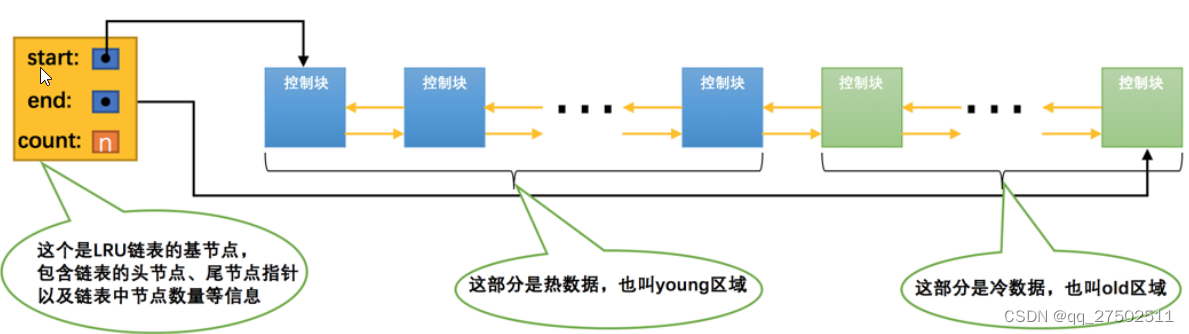
简单的LRU链表
只要我们使⽤到某个缓存⻚,就把该缓存⻚调整到LRU链表的头部,这样LRU链表尾部就是最近最少使⽤的缓存⻚。
划分区域的LRU链表
⼀部分存储使⽤频率⾮常⾼的缓存⻚,所以这⼀部分链表也叫做热数据,或者称young区域。
另⼀部分存储使⽤频率不是很⾼的缓存⻚,所以这⼀部分链表也叫做冷数据,或者称old区域。
young和old可以修改“innodb_old_blocks_pct”进行调整连个区的比例。
mysql> SHOW VARIABLES LIKE 'innodb_old_blocks_pct';
+-----------------------+-------+
| Variable_name | Value |
+-----------------------+-------+
| innodb_old_blocks_pct | 37 |
+-----------------------+-------+
1 row inset (0.01 sec)
这样修改配置⽂件:
[server]
innodb_old_blocks_pct = 40
为了避免只读取一次的数据,占领了young的数据,所以设计一下模式:
在对某个处在old区域的缓存⻚进⾏第⼀次访问时就在它对应的控制块中记录下来这个访问时间,如果后续的访问时间与第⼀次访问的时间在某个时间间隔内,那么该⻚⾯就不会被从old区域移动到young区域的头部,否则将它移动到young区域的头部。上述的这个间隔时间是由系统变量innodb_old_blocks_time控制的。
mysql> SHOW VARIABLES LIKE 'innodb_old_blocks_time';
+------------------------+-------+
| Variable_name | Value |
+------------------------+-------+
| innodb_old_blocks_time | 1000 |
+------------------------+-------+
1 row inset (0.01 sec)
更进⼀步优化LRU链表
对于young区域的缓存⻚来说,我们每次访问⼀个缓存⻚就要把它移动到LRU链表的头部,这样开销有点大了,毕竟在young区域的缓存⻚都是热点数据,也就是可能被经常访问的,这样频繁的对LRU链表进⾏节点移动操作是不是不太好啊?是的,为了解决这个问题其实我们还可以提出⼀些优化策略,⽐如只有被访问的缓存⻚位于young区域的1/4的后边,才会被移动到LRU链表头部,这样就可以降低调整LRU链表的频率,从⽽提升性能(也就是说如果某个缓存⻚对应的节点在young区域的1/4中,再次访问该缓存⻚时也不会将其移动到LRU链表头部)
刷新脏页到磁盘
从LRU链表的冷数据中刷新⼀部分⻚⾯到磁盘。
后台线程会定时从LRU链表尾部开始扫描⼀些⻚⾯,扫描的⻚⾯数量可以通过系统变量innodb_lru_scan_depth来指定,如果从⾥边⼉发现脏⻚,会把它们刷
新到磁盘。这种刷新⻚⾯的⽅式被称之为BUF_FLUSH_LRU。
从flush链表中刷新⼀部分⻚⾯到磁盘。
后台线程也会定时从flush链表中刷新⼀部分⻚⾯到磁盘,刷新的速率取决于当时系统是不是很繁忙。这种刷新⻚⾯的⽅式被称之为BUF_FLUSH_LIST。
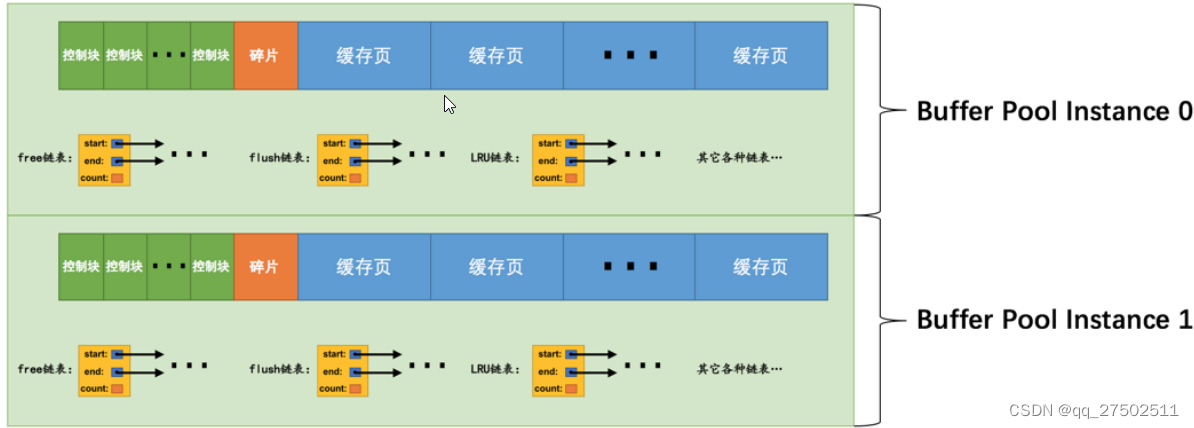
多个Buffer Pool实例
在多线程环境下,访问Buffer Pool中的各种链表都需要加锁处理啥的,在Buffer Pool特别⼤⽽且多线程并发访问特别⾼的情况下,单⼀的Buffer Pool可能会影响请求的处理速度。所以在Buffer Pool特别⼤的时候,我们可以把它们拆分成若⼲个⼩的Buffer Pool,每个Buffer Pool都称为⼀个实例,它们都是独⽴的,独⽴的去申请内存空间,独⽴的管理各种链表,所以在多线程并发访问时并不会相互影响,从⽽提⾼并发处理能⼒。以在服务器启动的时候通过设置innodb_buffer_pool_instances的值来修改Buffer Pool实例的个数,⽐⽅说这样:
[server]
innodb_buffer_pool_instances = 2
配置Buffer Pool时的注意事项
- innodb_buffer_pool_size必须是innodb_buffer_pool_chunk_size × innodb_buffer_pool_instances的倍数(这主要是想保证每⼀个Buffer Pool实例
中包含的chunk数量相同)。
假设我们指定的innodb_buffer_pool_chunk_size的值是128M,innodb_buffer_pool_instances的值是16,那么这两个值的乘积就是2G,也就是说
innodb_buffer_pool_size的值必须是2G或者2G的整数倍。⽐⽅说我们在启动MySQL服务器是这样指定启动参数的:
mysqld --innodb-buffer-pool-size=8G --innodb-buffer-pool-instances=16
默认的innodb_buffer_pool_chunk_size值是128M,指定的innodb_buffer_pool_instances的值是16,所以innodb_buffer_pool_size的值必须是2G或者
2G的整数倍,上边例⼦中指定的innodb_buffer_pool_size的值是8G,符合规定,所以在服务器启动完成之后我们查看⼀下该变量的值就是我们指定的
8G(8589934592字节):
如果我们指定的innodb_buffer_pool_size⼤于2G并且不是2G的整数倍,那么服务器会⾃动的把innodb_buffer_pool_size的值调整为2G的整数倍,⽐⽅说mysql> show variables like 'innodb_buffer_pool_size'; +-------------------------+------------+ | Variable_name | Value | +-------------------------+------------+ | innodb_buffer_pool_size | 8589934592 | +-------------------------+------------+ 1 row inset (0.00 sec)
我们在启动服务器时指定的innodb_buffer_pool_size的值是9G:
mysqld --innodb-buffer-pool-size=9G --innodb-buffer-pool-instances=16
那么服务器会⾃动把innodb_buffer_pool_size的值调整为10G(10737418240字节),不信你看:mysql> show variables like 'innodb_buffer_pool_size'; +-------------------------+-------------+ | Variable_name | Value | +-------------------------+-------------+ | innodb_buffer_pool_size | 10737418240 | +-------------------------+-------------+ 1 row inset (0.01 sec) - 如果在服务器启动时,innodb_buffer_pool_chunk_size × innodb_buffer_pool_instances的值已经⼤于innodb_buffer_pool_size的值,那么
innodb_buffer_pool_chunk_size的值会被服务器⾃动设置为innodb_buffer_pool_size/innodb_buffer_pool_instances的值。
⽐⽅说我们在启动服务器时指定的innodb_buffer_pool_size的值为2G,innodb_buffer_pool_instances的值为16,innodb_buffer_pool_chunk_size的值
为256M:
mysqld --innodb-buffer-pool-size=2G --innodb-buffer-pool-instances=16 --innodb-buffer-pool-chunk-size=256M
由于256M × 16 = 4G,⽽4G > 2G,所以innodb_buffer_pool_chunk_size值会被服务器改写为
innodb_buffer_pool_size/innodb_buffer_pool_instances的值,也就是:2G/16 = 128M(134217728字节),不信你看:
mysql> show variables like 'innodb_buffer_pool_size';
+-------------------------+------------+
| Variable_name | Value |
+-------------------------+------------+
| innodb_buffer_pool_size | 2147483648 |
+-------------------------+------------+
1 row inset (0.01 sec)
mysql> show variables like 'innodb_buffer_pool_chunk_size';
+-------------------------------+-----------+
| Variable_name | Value |
+-------------------------------+-----------+
| innodb_buffer_pool_chunk_size | 134217728 |
+-------------------------------+-----------+
1 row inset (0.00 sec)
相关文章:
Mysql InnoDB的Buffer Pool
Buffer Pool 在MySQL服务器启动的时候就向操作系统申请了⼀⽚连续的内存,他们给这⽚内存起了个名,叫做Buffer Pool(中⽂名 是缓冲池)。 默认情况下Buffer Pool只有128M⼤⼩,最⼩值为5M,通过修改配置文件设…...
SMTP简单邮件传输协议(C/C++ 发送电子邮件)
SMTP是用于通过Internet发送电子邮件的协议。电子邮件客户端(如Microsoft Outlook或macOS Mail应用程序)使用SMTP连接到邮件服务器并发送电子邮件。邮件服务器还使用SMTP将邮件从一个邮件服务器交换到另一个。它不用于从服务器下载电子邮件;相…...
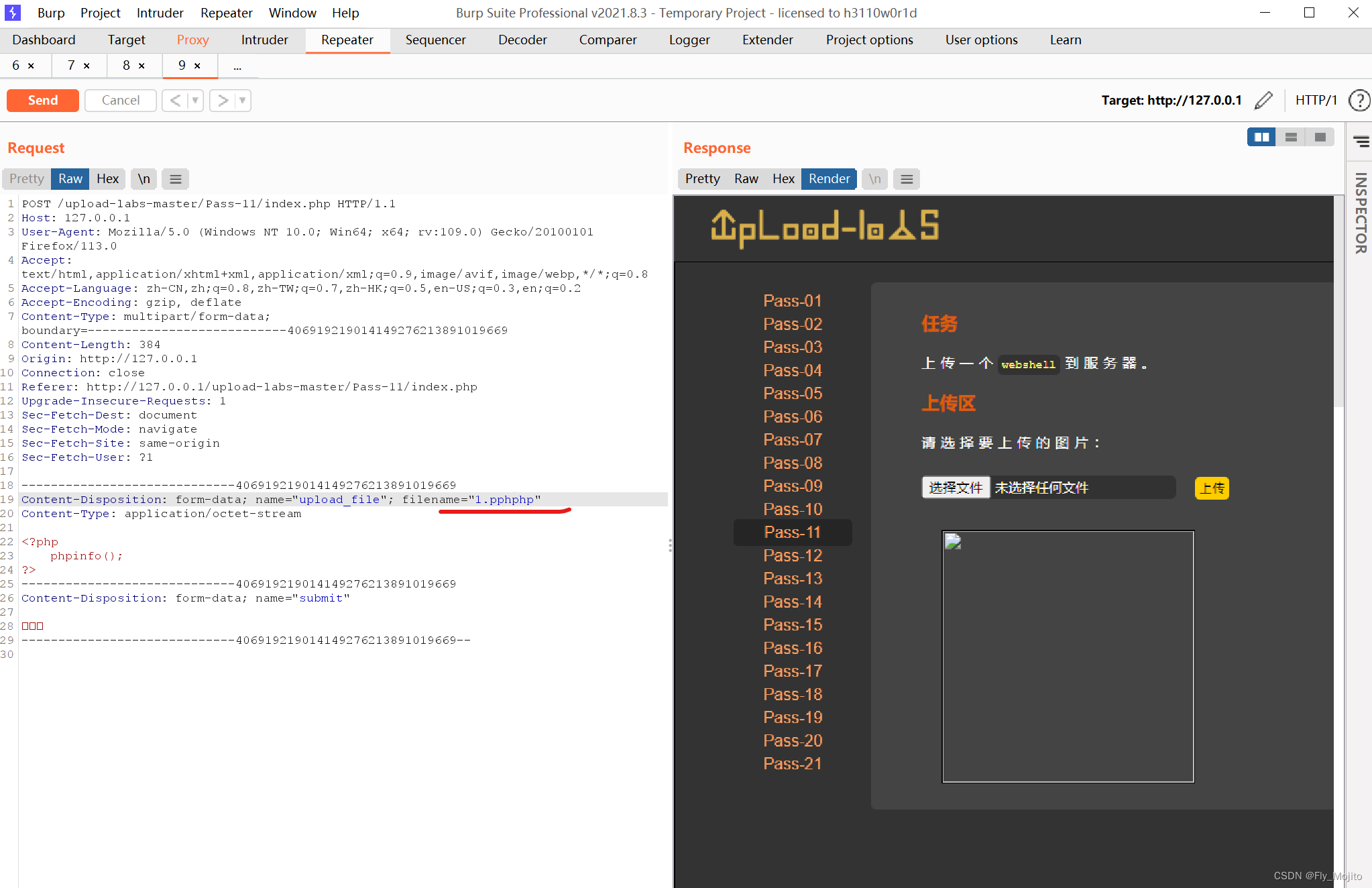
uploads靶场通关(1-11关)
Pass-01(JS校验) 看题目我们准备好我们的php脚本文件,命名为1.php 上传该php文件,发现上传失败 方法一:将浏览器的JavaScript禁用 然后就能上传了 方法二: 查看源码,发现只能上传以下形式的文…...

6.1黄金探底回升是否到顶,今日多空如何布局
近期有哪些消息面影响黄金走势?今日黄金多空该如何研判? 黄金消息面解析:周三(5月31日)黄金期货价格攀升,美国国债收益率下降推动金价升至一周最高收盘位。美市尾盘,现货黄金收报1962.42美元/盎司,上升3…...

自定义ViewGroup实现流式布局
目录 1、View的绘制流程 2、自定义ViewGroup构造函数的作用 3、onMeasure 方法 3.1、View的度量方式 3.2、onMeasure方法参数的介绍 3.3、自定义ViewGroup onMeasure 方法的实现 4、onLayout方法 5、onDraw方法 6、自定义View的生命周期 7、自定义流式布局的实现 扩展ÿ…...

Git版本控制
目录 版本控制 概念 为什么需要版本控制? 常见的版本控制工具 Git 1、安装 2、了解基本的Linux命令 3、配置git 用户名和邮箱 4、git 工作模式 5、git 项目管理 6、git 分支 托管平台 远程仓库 Gitee 关联多个远程库 Git服务器 Git GUI 版本控制 概…...
若依之权限处理
若依之权限处理 若依前后端不分离版本使用的是shiro进行权限控制,本文主要是对shiro在若依中的使用进行分析。 RBAC权限模型 RBAC是指基于角色的访问控制。其基本思想是,对系统的各种权限不是直接授予具体的用户,而是在用户集合与权限集合…...

华为OD机试真题 Java 实现【矩阵最大值】【2023 B卷 100分】,附详细解题思路
一、题目描述 给定一个仅包含0和1的N*N的二维矩阵,请计算二维矩阵的最大值。 计算规则如下: 1、每行元素按下标顺序组成一个二进制数(下标越大越排在低位),二进制数的值就是该行的值。矩阵各行值之和为矩阵的值。 2、允许通过向左或向右整体循环移动每行元素来改变各元…...

ModuleNotFoundError: No module named ‘transformers_modules.chatglm-6b_v1‘的解决方案
大家好,我是爱编程的喵喵。双985硕士毕业,现担任全栈工程师一职,热衷于将数据思维应用到工作与生活中。从事机器学习以及相关的前后端开发工作。曾在阿里云、科大讯飞、CCF等比赛获得多次Top名次。现为CSDN博客专家、人工智能领域优质创作者。喜欢通过博客创作的方式对所学的…...
MMPretrain代码课
安装注意事项 训练时需要基于算法库源码进行开发,所以需要git clone mmpretrain仓库。如果只调用,则pip install 即可。 from mmpretrain import get_model, list_models,inference_model分别用于模型的获取、例举、推理 此时还没加载预训练权重 tor…...

Selenium自动化程序被检测为爬虫,怎么屏蔽和绕过
Selenium 操作被屏蔽 使用selenium自动化网页时,有一定的概率会被目标网站识别,一旦被检测到,目标网站会拦截该客户端做出的网页操作。 比如淘宝和大众点评的登录页,当手工打开浏览器,输入用户名和密码时,…...

Nvidia Jetson Orin:开发技巧
Jetson PXXX定义 P2180 -> Jetson TX1 P3310 -> Jetson TX2 P3489 -> Jetson TX2i P3448 -> Jetson Nano devkit P3448-0020 -> Jetson Nano production module P2888 -> Jetson Xavier P2888-0060 -> Jetson Xavier-8GB P3701 -> Jetson AGX Orin D…...

为什么需要 git 和 相关的小知识
为什么需要git和相关的小知识 先看一个实际需求,引出Git 问题: 公司五一活动计划 ● 先说一个最简单的情况,比如你做了公司五一活动计划书(如图) 解决方案: 版本管理工具(Git) 一句话: Git 是目前最流行的分布式版本控制软件 Git 是怎么来的? Git…...

(详解)vue中实现主题切换的三种方式
目录 一、背景 二、实现思路 方法1:定义全局的CSS变量 方法2:切换已定义好的css文件 方法3:切换顶级CSS类名 (需使用css处理器,如sass、less等) 一、背景 在我们开发中我们会遇到像是需要切换程序风格、主题切换啦这种应用场景。 参考大佬…...
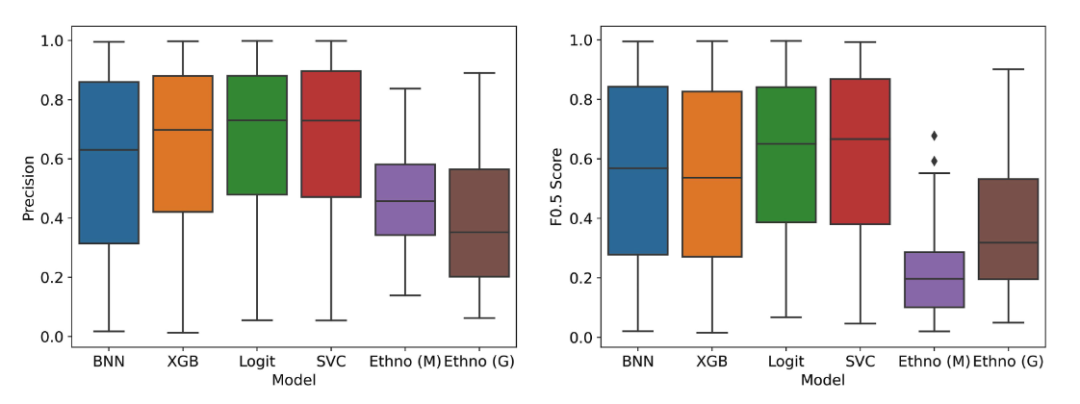
英国皇家植物园采用机器学习预测植物抗疟性,将准确率从 0.46 提升至 0.67
内容一览:疟疾是严重危害人类生命健康的重大传染病,研究人员一直在致力于寻找新的植物源性抗疟疾化合物,以研发相关药物。近期英国皇家植物园利用机器学习 算法 有效预测了植物抗疟性,该研究成果目前已发表在《Frontiers in Plant…...

基于Locust实现MQTT协议服务的压测脚本
一、背景简介 业务背景大概介绍一下,就是按照国标规定,车辆需要上传一些指定的数据到ZF的指定平台,同时车辆也会把数据传到企业云端服务上,于是乎就产生了一些性能需求。 目前我们只是先简单的进行了一个性能场景的测试…...

AURIX TC3XX Cached PFLASH与Non-Cached PFLASH的区别
Cached ? Non-Cached? 在阅读TC3XX的用户手册时,在内存映射表中,有两个segment都是Program Flash,而且大小都一样是3M,一个是segment 8 另一个是segment10 这难免让人产生疑惑,二者区别在哪? …...
uniapp开发小程序-显示左滑删除效果
一、效果图: 二、代码实现: <template><view class"container"><view class"myorderList"><uni-swipe-action><uni-swipe-action-item class"swipe-action-item" :right-options"option…...

FPGA 的数字信号处理:Verilog 实现简单的 FIR 滤波器
该项目介绍了如何使用 Verilog 实现具有预生成系数的简单 FIR 滤波器。 绪论 不起眼的 FIR 滤波器是 FPGA 数字信号处理中最基本的模块之一,因此了解如何将具有给定抽头数及其相应系数值的基本模块组合在一起非常重要。因此,在这个关于 FPGA 上 DSP 基础…...

使用粒子群优化算法(PSO)辨识锂电池二阶RC模型参数(附MATLAB代码)
目录 一、原理部分 二、代码详解部分 三、结果及分析 一、原理部分 PSO算法由美国学者于 1995 年提出,因其算法简单、效果良好,而在很多领域得到了广泛应用。该算法的起源是模拟鸟群的觅食过程,形成一种群体智能搜索算法。 其核心是&#…...

AI时代算力、模型与安全的三角博弈:从Nvidia生态到工程实践
1. 项目概述:当算力、智能与安全交织的时代最近和几个在芯片设计、大模型应用以及安全服务公司工作的朋友聊天,大家不约而同地都聊到了一个话题:我们正处在一个由Nvidia芯片驱动的AI浪潮之巅,但这场盛宴似乎并非没有天花板。一方面…...

C# 图像清晰度“核武器”:8个PictureBox永不模糊的硬核实战技巧
在 Windows Forms 开发中,PictureBox 是我们展示视觉效果的窗口。然而,你是否曾因为图片在缩放或背景色不匹配时变得模糊、锯齿横生,甚至出现难看的“黑边”而感到抓狂?这不仅影响用户体验,更是对完美主义开发者的一种…...

终极指南:在Windows上轻松安装安卓应用,告别笨重模拟器
终极指南:在Windows上轻松安装安卓应用,告别笨重模拟器 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否曾经想在Windows电脑上运行安卓应…...

Windows热键侦探:一键定位占用程序,终结快捷键冲突烦恼
Windows热键侦探:一键定位占用程序,终结快捷键冲突烦恼 【免费下载链接】hotkey-detective A small program for investigating stolen key combinations under Windows 7 and later. 项目地址: https://gitcode.com/gh_mirrors/ho/hotkey-detective …...

5分钟掌握TrafficMonitor插件系统:从零开始构建你的桌面监控中心
5分钟掌握TrafficMonitor插件系统:从零开始构建你的桌面监控中心 【免费下载链接】TrafficMonitorPlugins 用于TrafficMonitor的插件 项目地址: https://gitcode.com/gh_mirrors/tr/TrafficMonitorPlugins 还在为Windows桌面上单调的系统监控而烦恼吗&#x…...

企业如何通过API Key管理与审计日志保障大模型调用安全
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 企业如何通过API Key管理与审计日志保障大模型调用安全 对于将大模型能力集成到业务流程中的企业而言,安全与合规是首要…...
PixelAnnotationTool终极指南:如何用智能分水岭算法实现高效像素级图像标注
PixelAnnotationTool终极指南:如何用智能分水岭算法实现高效像素级图像标注 【免费下载链接】PixelAnnotationTool Annotate quickly images. 项目地址: https://gitcode.com/gh_mirrors/pi/PixelAnnotationTool 你是否曾经为图像标注工作感到头疼ÿ…...

构建毫秒级实时传输系统:基于flv.js的低延迟架构优化方案
构建毫秒级实时传输系统:基于flv.js的低延迟架构优化方案 【免费下载链接】flv.js HTML5 FLV Player 项目地址: https://gitcode.com/gh_mirrors/fl/flv.js flv.js作为HTML5 FLV播放器的核心技术方案,通过Media Source Extensions实现浏览器端FLV…...

告别配置烦恼!Qt 5.14.2下QCustomPlot源码集成与QChart开箱即用全攻略
Qt 5.14.2图表库极简集成指南:QCustomPlot源码直连与QChart零配置实战 刚接手一个需要快速实现数据可视化的Qt项目时,开发者往往会在图表库的选择和集成上耗费大量时间。传统方案如Qwt需要繁琐的编译配置,而官方文档又常常默认读者已经熟悉Qt…...

2026购物机器人操作指南:工作原理与使用教程
在电商自动化和AI技术不断发展的背景下,购物机器人(Shopping Bot)正在成为越来越多人关注的工具。无论是用于限量商品抢购、价格监控,还是电商数据采集,它都在改变传统的线上购物方式。本文将从基础概念出发࿰…...