Reid strong baseline 代码详解
本项目是对Reid strong baseline代码的详解。项目暂未加入目标检测部分,后期会不定时更新,请持续关注。
本相比Reid所用数据集为Markt1501,支持Resnet系列作为训练的baseline网络。训练采用表征学习+度量学习的方式。
目录
训练参数
训练代码
create_supervised_trainer(创建训练函数)
create_supervised_evaluator(创建测试函数)
do_train代码
训练期权重的保存
获得Loss和acc
获取初始epoch
学习率的调整
loss和acc的打印
时间函数的打印
测试结果的打印以及权重的保存
完整代码
测试
Reid相关资料学习链接
项目代码:
后期计划更新
训练参数
--last stride:作为Resnet 最后一层layer的步长,默认为1;
--model_path:预训练权重
--model_name:模型名称,支持Resnet系列【详见readme】
--neck:bnneck
--neck_feat:after
--INPUT_SIZE:[256,128],输入大小
--INPUT_MEAN:
--INPUT_STD:
--PROB: 默认0.5
--padding:默认10
--num_workers:默认4【根据自己电脑配置来】
--DATASET_NAME:markt1501,数据集名称
--DATASET_ROOT_DIR:数据集根目录路径
--SAMPLER: 现仅支持softmax_triplet
--IMS_PER_BATCH:训练时的batch size
--TEST_IMS_PER_BATCH:测试时的batch size
--NUM_INSTANCE:一个batch中每个ID用多少图像,默认为4
--OPTIMIZER_NAME:优化器名称,默认为Adam,支持SGD
--BASE_LR:初始学习率,默认0.00035
--WEIGHT_DECAY:权重衰减
--MARGIN:用于tripletloss,默认0.3
--IF_LABELSMOOTH:标签平滑
--OUTPUT_DIR:权重输出路径
--DEVICE:cuda or cpu
--MAX_EPOCHS:训练迭代次数,默认120
训练代码
def train(args):# 数据集train_loader, val_loader, num_query, num_classes = make_data_loader(args)# modelmodel = build_model(args, num_classes)# 优化器optimizer = make_optimizer(args, model)# lossloss_func = make_loss(args, num_classes)start_epoch = 0scheduler = WarmupMultiStepLR(optimizer, args.STEPS, args.GAMMA, args.WARMUP_FACTOR,args.WARMUP_ITERS, args.WARMUP_METHOD)print('ready train~')do_train(args,model,train_loader,val_loader,optimizer,scheduler,loss_func,num_query,start_epoch)上述代码中所用处理数据集函数make_data_loader可以参考我另一篇文章:
Reid数据集处理代码详解
在看do_train前需要先看以下内容。
log_period表示为打印Log的周期,默认为1;
checkpoint_period:表示为保存权重周期,默认为1;
output_dir:输出路径
device:cuda or cpu
epochs:训练迭代轮数
代码中的create_supervised_trainer和create_supervised_evaluator两个函数,是分别是用来创建监督训练和测试的,是对ignite.engine内训练和测试方法的重写。
create_supervised_trainer(创建训练函数)
规则是在内部实现一个def _update(engine,batch)方法,最后返回Engine(_update)。代码如下。
'''
ignite是一个高级的封装训练和测试库
'''
def create_supervised_trainer(model, optimizer, loss_fn, device=None):""":param model: (nn.Module) reid model to train:param optimizer:Adam or SGD:param loss_fn: loss function:param device: gpu or cpu:return: Engine"""if device:if torch.cuda.device_count() > 1:model = nn.DataParallel(model)model.to(device)def _update(engine, batch):model.train()optimizer.zero_grad()img, target = batchimg = img.to(device) if torch.cuda.device_count() >= 1 else imgtarget = target.to(device) if torch.cuda.device_count() >= 1 else targetscore, feat = model(img) # 采用表征+度量loss = loss_fn(score, feat, target) # 传入三个值,score是fc层后的(hard),feat是池化后的特征,target是标签loss.backward()optimizer.step()# compute accacc = (score.max(1)[1] == target).float().mean()return loss.item(), acc.item()return Engine(_update)create_supervised_evaluator(创建测试函数)
同理,测试代码也是一样,如下,其中metrics是我们需要计算的评价指标:
# 重写create_supervised_evaluator,传入model和metrics,metrics是一个字典用来存储需要度量的指标
def create_supervised_evaluator(model, metrics, device=None):if device:if torch.cuda.device_count() > 1:model = nn.DataParallel(model)model.to(device)def _inference(engine, batch):model.eval()with torch.no_grad():data, pids, camids = batchdata = data.to(device) if torch.cuda.is_available() else datafeat = model(data)return feat, pids, camidsengine = Engine(_inference)for name, metric in metrics.items():metric.attach(engine, name)return enginedo_train代码
然后看一下do_train中的代码。
训练期权重的保存
这里的trainer就是我们前面创建的监督训练的函数,给该实例添加事件,事件为在每次epoch结束的时候保存一次权重[注意这里保存的权重是将模型的完整结构以及优化器权重都保存下来了]
trainer.add_event_handler(Events.EPOCH_COMPLETED, checkpointer, {'model': model,'optimizer': optimizer})获得Loss和acc
# average metric to attach on trainer
RunningAverage(output_transform=lambda x: x[0]).attach(trainer, 'avg_loss')
RunningAverage(output_transform=lambda x: x[1]).attach(trainer, 'avg_acc')获取初始epoch
训练前获取开始的epoch,默认为0;
@trainer.on(Events.STARTED)def start_training(engine):engine.state.epoch = start_epoch学习率的调整
在训练期间每个epoch开始的时候,会调整学习率
@trainer.on(Events.EPOCH_STARTED)def adjust_learning_rate(engine):scheduler.step()loss和acc的打印
该事件发生在每个iteration完成时,而不是epoch完成时。
@trainer.on(Events.ITERATION_COMPLETED)def log_training_loss(engine):global ITERITER += 1if ITER % log_period == 0:logger.info("Epoch[{}] Iteration[{}/{}] Loss: {:.3f}, Acc: {:.3f}, Base Lr: {:.2e}".format(engine.state.epoch, ITER, len(train_loader),engine.state.metrics['avg_loss'], engine.state.metrics['avg_acc'],scheduler.get_lr()[0]))if len(train_loader) == ITER:ITER = 0时间函数的打印
该函数是用来在每个epoch完成的时候打印一下用了多长时间
# adding handlers using `trainer.on` decorator API@trainer.on(Events.EPOCH_COMPLETED)def print_times(engine):logger.info('Epoch {} done. Time per batch: {:.3f}[s] Speed: {:.1f}[samples/s]'.format(engine.state.epoch, timer.value() * timer.step_count,train_loader.batch_size / timer.value()))logger.info('-' * 10)timer.reset()测试结果的打印以及权重的保存
该函数用来打印测试结果,比如mAP,Rank,测试后的权重会保存在logs下。命名形式为mAP_xx.pth。【注意这里保存我权重和上面保存的权重是不一样的,这里仅仅保存权重,不包含网络结构和优化器权重】
@trainer.on(Events.EPOCH_COMPLETED)def log_validation_results(engine):if engine.state.epoch % eval_period == 0:evaluator.run(val_loader)cmc, mAP = evaluator.state.metrics['r1_mAP']logger.info("Validation Results - Epoch: {}".format(engine.state.epoch))text = "mAP:{:.1%}".format(mAP)# logger.info("mAP: {:.1%}".format(mAP))logger.info(text)for r in [1, 5, 10]:logger.info("CMC curve, Rank-{:<3}:{:.1%}".format(r, cmc[r - 1]))torch.save(state_dict, 'logs/mAP_{:.1%}.pth'.format(mAP))return cmc, mAP完整代码
def do_train(cfg,model,train_loader,val_loader,optimizer,scheduler,loss_fn,num_query,start_epoch
):log_period = 1checkpoint_period = 1eval_period = 1output_dir = cfg.OUTPUT_DIRdevice = cfg.DEVICEepochs = cfg.MAX_EPOCHSprint("Start training~")trainer = create_supervised_trainer(model, optimizer, loss_fn, device)evaluator = create_supervised_evaluator(model,metrics={'r1_mAP': R1_mAP(num_query, max_rank=50, feat_norm='yes')},device=device)checkpointer = ModelCheckpoint(output_dir, cfg.model_name, checkpoint_period, n_saved=10, require_empty=False)state_dict = model.state_dict()timer = Timer(average=True)trainer.add_event_handler(Events.EPOCH_COMPLETED, checkpointer, {'model': model,'optimizer': optimizer})timer.attach(trainer, start=Events.EPOCH_STARTED, resume=Events.ITERATION_STARTED,pause=Events.ITERATION_COMPLETED, step=Events.ITERATION_COMPLETED)# average metric to attach on trainerRunningAverage(output_transform=lambda x: x[0]).attach(trainer, 'avg_loss')RunningAverage(output_transform=lambda x: x[1]).attach(trainer, 'avg_acc')@trainer.on(Events.STARTED)def start_training(engine):engine.state.epoch = start_epoch@trainer.on(Events.EPOCH_STARTED)def adjust_learning_rate(engine):scheduler.step()@trainer.on(Events.ITERATION_COMPLETED)def log_training_loss(engine):global ITERITER += 1if ITER % log_period == 0:logger.info("Epoch[{}] Iteration[{}/{}] Loss: {:.3f}, Acc: {:.3f}, Base Lr: {:.2e}".format(engine.state.epoch, ITER, len(train_loader),engine.state.metrics['avg_loss'], engine.state.metrics['avg_acc'],scheduler.get_lr()[0]))if len(train_loader) == ITER:ITER = 0# adding handlers using `trainer.on` decorator API@trainer.on(Events.EPOCH_COMPLETED)def print_times(engine):logger.info('Epoch {} done. Time per batch: {:.3f}[s] Speed: {:.1f}[samples/s]'.format(engine.state.epoch, timer.value() * timer.step_count,train_loader.batch_size / timer.value()))logger.info('-' * 10)timer.reset()@trainer.on(Events.EPOCH_COMPLETED)def log_validation_results(engine):if engine.state.epoch % eval_period == 0:evaluator.run(val_loader)cmc, mAP = evaluator.state.metrics['r1_mAP']logger.info("Validation Results - Epoch: {}".format(engine.state.epoch))text = "mAP:{:.1%}".format(mAP)# logger.info("mAP: {:.1%}".format(mAP))logger.info(text)for r in [1, 5, 10]:logger.info("CMC curve, Rank-{:<3}:{:.1%}".format(r, cmc[r - 1]))torch.save(state_dict, 'logs/mAP_{:.1%}.pth'.format(mAP))return cmc, mAPtrainer.run(train_loader, max_epochs=epochs)训练命令如下:
python tools/train.py --model_name resnet50_ibn_a --model_path weights/ReID_resnet50_ibn_a.pth --IMS_PER_BATCH 8 --TEST_IMS_PER_BATCH 4 --MAX_EPOCHS 120会出现如下形式:
=> Market1501 loaded Dataset statistics:----------------------------------------subset | # ids | # images | # cameras----------------------------------------train | 751 | 12936 | 6query | 750 | 3368 | 6gallery | 751 | 15913 | 6----------------------------------------2023-05-15 14:30:55.603 | INFO | engine.trainer:log_training_loss:119 - Epoch[1] Iteration[227/1484] Loss: 6.767, Acc: 0.000, Base Lr: 3.82e-05 2023-05-15 14:30:55.774 | INFO | engine.trainer:log_training_loss:119 - Epoch[1] Iteration[228/1484] Loss: 6.761, Acc: 0.000, Base Lr: 3.82e-05 2023-05-15 14:30:55.946 | INFO | engine.trainer:log_training_loss:119 - Epoch[1] Iteration[229/1484] Loss: 6.757, Acc: 0.000, Base Lr: 3.82e-05 2023-05-15 14:30:56.134 | INFO | engine.trainer:log_training_loss:119 - Epoch[1] Iteration[230/1484] Loss: 6.760, Acc: 0.000, Base Lr: 3.82e-05 2023-05-15 14:30:56.305 | INFO | engine.trainer:log_training_loss:119 - Epoch[1] Iteration[231/1484] Loss: 6.764, Acc: 0.000, Base Lr: 3.82e-05
每个epoch训练完成后会测试一次mAP:
我这里第一个epoch的mAP达到75.1%,Rank-1:91.7%, Rank-5:97.2%, Rank-10:98.2%。
测试完成后会在log文件下保存一个pth权重,名称为mAPxx.pth,也是用该权重进行测试。
2023-05-15 14:35:59.753 | INFO | engine.trainer:print_times:128 - Epoch 1 done. Time per batch: 261.820[s] Speed: 45.4[samples/s]
2023-05-15 14:35:59.755 | INFO | engine.trainer:print_times:129 - ----------
The test feature is normalized
2023-05-15 14:39:51.025 | INFO | engine.trainer:log_validation_results:137 - Validation Results - Epoch: 1
2023-05-15 14:39:51.048 | INFO | engine.trainer:log_validation_results:140 - mAP:75.1%
2023-05-15 14:39:51.051 | INFO | engine.trainer:log_validation_results:142 - CMC curve, Rank-1 :91.7%
2023-05-15 14:39:51.051 | INFO | engine.trainer:log_validation_results:142 - CMC curve, Rank-5 :97.2%
2023-05-15 14:39:51.052 | INFO | engine.trainer:log_validation_results:142 - CMC curve, Rank-10 :98.2%
测试
测试代码在tools/test.py中,代码和train.py差不多,这里不再细说,该代码是可对评价指标进行测试复现。
命令如下:其中TEST_IMS_PER_BATCH是测试时候的batch size,model_name是网络名称,model_path是你训练好的权重路径。
python tools/test.py --TEST_IMS_PER_BATCH 4 --model_name [your model name] --model_path [your weight path]Reid相关资料学习链接
Reid损失函数理论讲解:Reid之损失函数理论学习讲解_爱吃肉的鹏的博客-CSDN博客
Reid度量学习Triplet loss代码讲解:Reid度量学习Triplet loss代码解析。_爱吃肉的鹏的博客-CSDN博客
yolov5 reid项目(支持跨视频检索):yolov5_reid【附代码,行人重识别,可做跨视频人员检测】_yolov5行人重识别_爱吃肉的鹏的博客-CSDN博客
yolov3 reid项目(支持跨视频检索):ReID行人重识别(训练+检测,附代码),可做图像检索,陌生人检索等项目_爱吃肉的鹏的博客-CSDN博客
预权重链接:
链接:百度网盘 请输入提取码 提取码:yypn
项目代码:
GitHub - YINYIPENG-EN/reid_strong_baselineContribute to YINYIPENG-EN/reid_strong_baseline development by creating an account on GitHub. https://github.com/YINYIPENG-EN/reid_strong_baseline
https://github.com/YINYIPENG-EN/reid_strong_baseline
后期计划更新
1.引入知识蒸馏训练(已更新:Reid strong baseline知识蒸馏【附代码】_爱吃肉的鹏的博客-CSDN博客)
2.加入YOLOX进行跨视频检测
相关文章:
Reid strong baseline 代码详解
本项目是对Reid strong baseline代码的详解。项目暂未加入目标检测部分,后期会不定时更新,请持续关注。 本相比Reid所用数据集为Markt1501,支持Resnet系列作为训练的baseline网络。训练采用表征学习度量学习的方式。 目录 训练参数 训练代…...
宝塔面板搭建网站教程:Linux下使用宝塔一键搭建网站,内网穿透发布公网上线
文章目录 前言1. 环境安装2. 安装cpolar内网穿透3. 内网穿透4. 固定http地址5. 配置二级子域名6. 创建一个测试页面 转载自cpolar内网穿透的文章:使用宝塔面板快速搭建网站,并内网穿透实现公网远程访问 前言 宝塔面板作为简单好用的服务器运维管理面板&…...

常微分方程(ODE)求解方法总结
常微分(ODE)方程求解方法总结 1 常微分方程(ODE)介绍1.1 微分方程介绍和分类1.2 常微分方程的非计算机求解方法1.3 线性微分方程求解的推导过程 2 一阶常微分方程(ODE)求解方法2.1 欧拉方法2.1.1 欧拉方法2…...

【华为OD机试】区间交集【2023 B卷|200分】
【华为OD机试】-真题 !!点这里!! 【华为OD机试】真题考点分类 !!点这里 !! 题目描述 给定一组闭区间,其中部分区间存在交集。 任意两个给定区间的交集,称为公共区间 (如:[1,2],[2,3]的公共区间为[2,2],[3,5],[3,6]的公共区间为[3,5])。 公共区间之间若存在交集,则需…...

Vue3 | Element Plus resetFields不生效
Vue3 | Element Plus resetFields不生效 1. 简介 先打开创建对话框没有问题,但只要先打开编辑对话框,后续在打开对话框就会有默认值,还无法使用resetFields()重置。 下面是用来复现问题的示例代码和示例GIF。 <script setup> import…...

机器视觉特点 机器视觉实际应用
机器视觉特点 1、机器视觉是一项综合技术,其中包括数字图像处理技术,机械工程技术,控制技术,电光源照明技术,光学成像技术,传感器技术,模拟与数字视频技术,计算机硬件技术ÿ…...
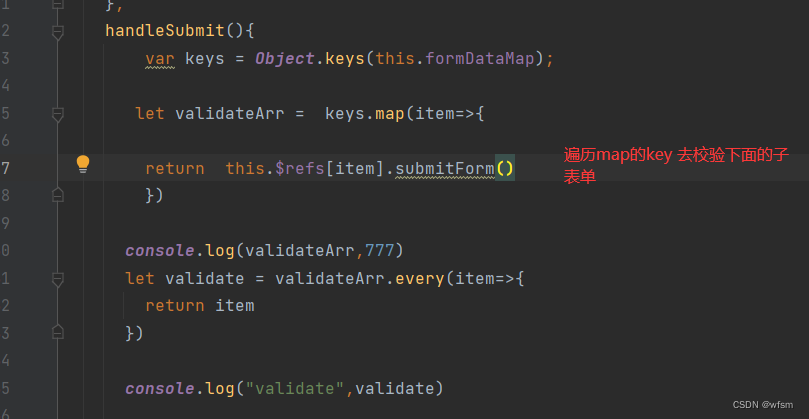
elementui大型表单校验
一般很大的表单都会被拆解开,校验,,不会写在一个页面,,就会有多个 el-form ,,主页要集合所有el-form的数据,,所以有一个map来接收,传送表单数据,&…...

Linux+Selenium
SeleniumLinux 开源社区已无CentOS7.0以下rpm维护。升级测试机器到CentOS7.X。 Selenium安装 python环境:pip3 install selenium 浏览器插件:http://chromedriver.storage.googleapis.com/index.html yum instlal google-chrome 使用以下命令确定是…...
)
2023-06-01 LeetCode每日一题(礼盒的最大甜蜜度)
2023-03-29每日一题 一、题目编号 二、题目链接 点击跳转到题目位置 三、题目描述 给你一个正整数数组 price ,其中 price[i] 表示第 i 类糖果的价格,另给你一个正整数 k 。 商店组合 k 类 不同 糖果打包成礼盒出售。礼盒的 甜蜜度 是礼盒中任意两…...

Spring架构篇--2.7.2 远程通信基础--Netty原理--ServerBootstrap
前言:已经初始化了NioEventLoopGroup 的boosGroup 和 workerGroup ,那么ServerBootstrap的作用是干嘛的呢 ,本文在Spring架构篇–2.7.1 远程通信基础–Netty原理–NioEventLoopGroup 之后继续进行探究 1 首先回顾下 nettt 的使用demo&#x…...

awk编辑器
文章目录 一.awk概述1.概述2.作用3.awk的工作过程4.awk 工作原理及命令格式5.awk的基本操作及其内置变量5.1 awk的-F操作5.2 awk的-v操作5.3 内置变量 二.awk 打印1.基本打印用法1.1 默认打印1.2打印文件内容 2.对行进行操作2.1 只打印行号(有多少行)2.2…...
DicomObjects.Core 3.0.17 Crack
DicomObjects.NET 核心版简介 DicomObjects.Core Assembly DicomObjects.NET 核心版简介 DicomObjects.Core 由一组相互关联但独立的 .核心兼容的“对象”,使开发人员能够快速轻松地将DICOM功能添加到其产品中,而无需了解或编程DICOM标准的复杂性。此帮助…...
电脑怎么通过网络传输文件?
可以通过网络在电脑之间传输文件吗? “由于天气的原因,我的老板决定让所有员工在家工作。但是我很多工作文件都在公司的电脑中,怎么才能将公司的文件远程传输到我家里的电脑上?电脑可以通过网络远程传输文件吗?” …...

人工智能之深度学习
第一章 人工智能概述 1.1人工智能的概念和历史 1.2人工智能的发展趋势和挑战 1.3人工智能的伦理和社会问题 第二章 数学基础 1.1线性代数 1.2概率与统计 1.3微积分 第三章 监督学习 1.1无监督学习 1.2半监督学习 1.3增强学习 第四章 深度学习 1.1神经网络的基本原理 1.2深度…...

性能测试设计阶段
性能测试设计阶段 性能测试是软件测试中的关键环节,它可以帮助我们评估软件系统在压力下的运行稳定性和性能表现。性能测试设计阶段是性能测试的基础,只有经过充分的设计,才能保证性能测试的有效性和准确性。 在性能测试设计阶段,…...

leetCode !! word break
方法一:字典树动态规划 首先,创建node类,每个对象应该包含:一个node array nexts(如果有通往’a’的路,那么对应的nexts[0]就不该为null); 一个boolean 变量(如果到达的这个字母恰好是字典中某个候选串的结尾,那么 标记…...

基础学习——关于list、numpy、torch在float和int等数据类型转换方面的总结
系列文章目录 Numpy学习——创建数组及常规操作(数组创建、切片、维度变换、索引、筛选、判断、广播) Tensor学习——创建张量及常规操作(创建、切片、索引、转换、维度变换、拼接) 基础学习——numpy与tensor张量的转换 基础学习…...

华纳云美国Linux服务器常用命令分享
美国Linux服务器系统目前也是跟Windows操作系统一样用户量非常多,其简单的纯命令操作模式可以节省很多系统空间,本文小编就来分享一些美国Linux服务器系统常用的命令,希望能够给刚入门的美国Linux服务器系统的用户提供一些操作参考。 1、系统…...

【minio】8.x版本与SpringBoot版本不兼容报错
错误异常: <minio.version>8.4.3</minio.version><spring-boot.version>2.6.13</spring-boot.version>Description:An attempt was made to call a method that does not exist. The attempt was made from the following location:io.min…...
如何用chatGPT赚钱?
赚钱思路 1)初级-账号 对于新事物的出现,很多人对此都是抱着一个看热闹的态度,大家对于这个东西的整体认知水平是很低的! 所以这个时候的思路就是快速去抢占市场,去各个平台发一些和ChatGPT相关的视频和文章去抢占市…...

Windows 11终极清理优化指南:用Win11Debloat快速提升系统性能
Windows 11终极清理优化指南:用Win11Debloat快速提升系统性能 【免费下载链接】Win11Debloat 一个简单的PowerShell脚本,用于从Windows中移除预装的无用软件,禁用遥测,从Windows搜索中移除Bing,以及执行各种其他更改以…...

SDMatte抠图实战教程:玻璃/薄纱/羽毛一键去背景,保姆级Web部署指南
SDMatte抠图实战教程:玻璃/薄纱/羽毛一键去背景,保姆级Web部署指南 1. 为什么选择SDMatte进行专业抠图 在日常设计工作中,抠图是最基础也最耗时的环节之一。特别是遇到玻璃制品、薄纱材质、羽毛边缘这类复杂对象时,传统Photosho…...

打破学术写作边界:NativeOverleaf离线工作流全解析
打破学术写作边界:NativeOverleaf离线工作流全解析 【免费下载链接】NativeOverleaf Next-level academia! Repository for the Native Overleaf project, attempting to integrate Overleaf with native OS features for macOS, Linux and Windows. 项目地址: ht…...

AI神器10秒搞定网申,求职效率翻倍
投简历填表单填到崩溃?这个AI神器帮你10秒搞定网申,海投效率直接拉满! 秋招春招跑过招聘季的朋友,一定都懂这种窒息感: 好不容易筛好了目标公司,点开招聘官网,迎面而来就是几十项的简历表单。姓名、电话、邮箱、教育经历从高中填到大学、实习经历要写清每段的起止时间…...
)
别再手动敲代码了!用Tesseract-OCR在Linux上批量处理图片转文字(附Python脚本)
从图片到结构化数据:基于Tesseract-OCR的Linux批量文本提取实战 在数字化办公和自动化流程中,我们经常需要处理大量图片中的文字信息——可能是扫描的合同文档、会议白板照片或是PDF中的非可编辑页面。传统的手动录入不仅效率低下,还容易出错…...

OpenClaw备份策略:GLM-4.7-Flash模型与技能容灾方案
OpenClaw备份策略:GLM-4.7-Flash模型与技能容灾方案 1. 为什么需要备份OpenClaw环境 去年冬天的一个深夜,我的MacBook突然遭遇硬盘故障。当时OpenClaw正在执行一个长达3小时的自动化数据处理任务,所有中间状态和配置瞬间消失。这次事故让我…...

CTFHub | 解密MySQL、Redis、MongoDB流量中的隐藏Flag
1. 数据库流量分析入门:为什么需要Wireshark? 当你参加CTF比赛时,经常会遇到需要从数据库流量中寻找Flag的题目。这类题目通常会给你一个抓包文件(pcap格式),里面记录了MySQL、Redis或MongoDB等数据库的网络…...

bilibili_live_stream_code:开源直播推流工具 解锁自定义直播新体验
bilibili_live_stream_code:开源直播推流工具 解锁自定义直播新体验 【免费下载链接】bilibili_live_stream_code 用于在准备直播时获取第三方推流码,以便可以绕开哔哩哔哩直播姬,直接在如OBS等软件中进行直播,软件同时提供定义直…...

SDMatte在电商场景落地:商品主图自动去背景+透明PNG生成完整工作流
SDMatte在电商场景落地:商品主图自动去背景透明PNG生成完整工作流 1. 电商场景中的图像处理痛点 在电商运营中,商品主图的质量直接影响转化率。传统处理方式面临三大难题: 人工成本高:专业设计师处理一张图平均耗时15-30分钟边…...

SEO_避开这些常见误区,让你的SEO效果翻倍
<h2>避开这些常见误区,让你的SEO效果翻倍</h2> <p>在当今的互联网时代,搜索引擎优化(SEO)已经成为了每个网站和博客运营者必须掌握的技能之一。许多人在进行SEO时却会犯一些常见的错误,这些错误不仅…...