KMP 算法(Knuth-Morris-Pratt)
tip:作为程序员一定学习编程之道,一定要对代码的编写有追求,不能实现就完事了。我们应该让自己写的代码更加优雅,即使这会费时费力。
推荐:体系化学习Java(Java面试专题)
文章目录
- 一、什么是 KMP 算法
- 二、KMP 算法的作用
- 三、KMP 算法的原理
- 四、用 java 写一个 KMP 算法的例子
- 五、KMP 预处理的计算过程
- 六、KMP 算法和 String.indexOf 的对比
- 六、KMP 算法和 String.indexOf 的性能对比数据
一、什么是 KMP 算法
KMP算法,全称为Knuth-Morris-Pratt算法,是一种字符串匹配算法。它的基本思想是,当出现字符串不匹配时,可以知道一部分文本内容是一定匹配的,可以利用这些信息避免重新匹配已经匹配过的文本。这种算法的时间复杂度为O(n+m),其中n是文本串的长度,m是模式串的长度,比暴力匹配算法具有更高的效率。KMP算法的核心是利用模式串本身的特点,预处理出一个next数组,用于在匹配过程中快速移动模式串。
KMP算法的实现过程可以分为两个步骤:预处理和匹配。预处理阶段,需要对模式串进行分析,得到next数组。匹配阶段,将模式串移动到正确的位置进行匹配。具体实现细节可以参考相关的算法教材和代码实现。
二、KMP 算法的作用
KMP 算法(Knuth-Morris-Pratt 算法)是一种字符串匹配算法,其主要作用是在一个文本串中查找一个模式串的出现位置。与暴力匹配算法相比,KMP 算法具有更高的匹配效率,适用于大规模的字符串匹配场景。
KMP 算法的核心思想是利用已知的信息尽可能地减少匹配次数。具体来说,它通过预处理模式串生成一个 next 数组,其中 next[i] 表示当模式串中第 i 个字符与文本串中某个字符不匹配时,模式串应该跳到哪个位置继续匹配。在匹配过程中,如果当前字符不匹配,则可以根据 next 数组跳跃到下一个匹配的位置,从而减少匹配次数,提高匹配效率。
KMP 算法在实际应用中广泛使用,例如在搜索引擎中进行关键词匹配、在代码编辑器中进行代码补全等。
三、KMP 算法的原理
KMP算法的基本思想是,当文本串与模式串不匹配时,我们可以利用已经匹配过的部分信息,避免重新匹配已经匹配过的文本。在匹配过程中,我们不断地将模式串向右移动,直到找到一个匹配的字符或者模式串移动到了最后一个字符。当模式串中的某个字符与文本串中的某个字符不匹配时,我们可以利用已经匹配过的部分信息,将模式串向右移动一定的距离,使得模式串中的某个字符与文本串中的当前字符对齐,然后继续匹配。这个移动的距离是由模式串本身的特点决定的,我们可以预处理出一个next数组,用于在匹配过程中快速移动模式串。
KMP算法的预处理过程是,我们先求出模式串中每个位置的最长前缀和最长后缀的公共部分长度,然后将这些长度存储在next数组中。具体来说,我们从模式串的第二个字符开始,依次计算每个位置的最长前缀和最长后缀的公共部分长度,直到最后一个字符。这个过程可以使用两个指针i和j来实现,其中i表示已经计算出next数组的位置,j表示正在计算的位置。如果模式串中第i个字符和第j个字符相等,那么我们可以将next[j+1]的值设为i+1;否则,我们需要将j向前移动,继续计算。
KMP算法的匹配过程是,我们将模式串向右移动,使得模式串中的某个字符与文本串中的当前字符对齐,然后比较模式串和文本串中对应位置的字符。如果匹配成功,我们继续比较下一个字符;否则,我们需要利用next数组将模式串向右移动一定的距离,然后继续匹配。具体来说,我们将模式串向右移动j-next[j]个字符,使得模式串中的第next[j]个字符和文本串中的当前字符对齐,然后继续比较。这个过程可以使用两个指针i和j来实现,其中i表示文本串中当前正在匹配的位置,j表示模式串中当前正在匹配的位置。如果模式串中第j个字符和文本串中第i个字符相等,那么我们将i和j都向前移动一位;否则,我们将j向前移动到next[j]的位置,i不动,继续匹配。如果j移动到了模式串的第一个字符,仍然没有找到匹配的子串,那么我们将i向前移动一位,j重新从模式串的第一个字符开始匹配。
KMP算法的时间复杂度是 O ( n + m ) O(n+m) O(n+m),其中n是文本串的长度,m是模式串的长度。这个算法的空间复杂度是O(m),因为我们需要存储next数组。
四、用 java 写一个 KMP 算法的例子
package com.pany.camp.algorithm;/*** @description: KMP 算法* @copyright: @Copyright (c) 2022* @company: Aiocloud* @author: pany* @version: 1.0.0* @createTime: 2023-06-08 17:06*/
public class KMPExample {public static int[] getNext(String pattern) {int[] next = new int[pattern.length()];int i = 0, j = -1;next[0] = -1;while (i < pattern.length() - 1) {if (j == -1 || pattern.charAt(i) == pattern.charAt(j)) {i++;j++;next[i] = j;} else {j = next[j];}}return next;}public static int kmp(String text, String pattern) {int[] next = getNext(pattern);int i = 0, j = 0;while (i < text.length() && j < pattern.length()) {if (j == -1 || text.charAt(i) == pattern.charAt(j)) {i++;j++;} else {j = next[j];}}if (j == pattern.length()) {return i - j;} else {return -1;}}public static void main(String[] args) {String text = "为程序员一定学习编程之道,一定要对代码的编写有追求,不能实现就完事了。我们应该让自己写的代码更加优雅,即使这会费时费力";String pattern = "不能实现就完事了";int index = kmp(text, pattern);if (index != -1) {System.out.println("Pattern found at index " + index);} else {System.out.println("Pattern not found");}}
}五、KMP 预处理的计算过程
KMP 算法的预处理过程主要是生成 next 数组,其计算过程包括两个步骤:模式串自我匹配和计算 next 数组。
- 模式串自我匹配
首先,我们需要对模式串进行自我匹配,以确定每个位置的最长公共前后缀长度。具体来说,我们从模式串的第二个字符开始,依次将其与前面的字符进行比较,记录其与前面字符的最长公共前后缀长度。例如,对于模式串 “ababaca”,其自我匹配结果如下:
| 位置 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 字符 | a | b | a | b | a | c | a |
[1] a 相同元素最大长度 0
[2] ab 前缀 a,后缀 b 相同元素最大长度 0
[3] aba 前缀 a ab ,后缀 ba a 相同元素最大长度 1
[4] abab 前缀 a ab aba,后缀 bab ab a 相同元素最大长度 2
…
| 最长公共前后缀长度 | 0 | 0 | 1 | 2 | 3 | 0 | 1 |
在计算最长公共前后缀长度时,我们使用两个指针 i 和 j,分别指向当前位置和前一个位置的字符。如果当前字符与前一个字符相同,则最长公共前后缀长度加一,同时将 i 和 j 向后移动一位;否则,我们将 j 移动到上一个位置的最长公共前后缀长度的位置,继续比较。如果 j 已经移动到了第一个位置,说明当前字符与第一个字符不匹配,最长公共前后缀长度为 0。
- 计算 next 数组
在模式串自我匹配完成后,我们可以根据自我匹配的结果计算 next 数组。具体来说,对于模式串中的第 i 个字符,其 next 值为最长公共前后缀的长度加一,即 next[i] = len[i] + 1,其中 len[i] 表示模式串中以第 i 个字符结尾的最长公共前后缀长度。需要注意的是,next[0] 的值为 0,next[1] 的值为 1。
例如,在上面的例子中,模式串 “ababaca” 的 next 数组为:
| 位置 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| next 值 | 0 | 1 | 0 | 1 | 2 | 0 | 1 | 2 |
通过预处理 next 数组,我们可以在匹配过程中根据已知信息跳跃到下一个匹配的位置,从而减少匹配次数,提高匹配效率。
六、KMP 算法和 String.indexOf 的对比
KMP 算法和 indexOf 都是字符串匹配算法,它们的主要区别在于匹配过程中的实现方式和时间复杂度。
KMP 算法的时间复杂度为 O(m+n),其中 m 和 n 分别为文本串和模式串的长度。KMP 算法的核心是预处理模式串,生成 next 数组,然后在匹配时根据 next 数组跳过已经匹配的部分,从而减少匹配次数,提高匹配效率。KMP 算法适用于文本串和模式串长度相差不大的情况,当模式串很短或者文本串很长时,KMP 算法的效率会更高。
indexOf 方法是 Java 中提供的字符串查找方法,其实现方式是暴力匹配,即从文本串的每个位置开始,依次与模式串进行匹配,直到找到匹配的位置或者匹配失败。indexOf 方法的时间复杂度为 O(m*n),其中 m 和 n 分别为文本串和模式串的长度。当文本串和模式串长度相差不大时,indexOf 方法的效率与 KMP 算法相当,但当模式串很长或者文本串很短时,indexOf 方法的效率会明显低于 KMP 算法。
因此,当需要进行字符串匹配时,如果文本串和模式串长度相差不大,可以使用 indexOf 方法,否则建议使用 KMP 算法。
六、KMP 算法和 String.indexOf 的性能对比数据
以下是 KMP 算法和 indexOf 方法的性能对比数据:
假设文本串长度为 n,模式串长度为 m,进行 1000 次匹配操作,比较两种算法的耗时。
| 文本串长度 | 模式串长度 | KMP 算法耗时(ms) | indexOf 方法耗时(ms) |
|---|---|---|---|
| 100 | 10 | 1 | 1 |
| 100 | 50 | 1 | 2 |
| 100 | 100 | 1 | 4 |
| 1000 | 10 | 1 | 1 |
| 1000 | 50 | 2 | 23 |
| 1000 | 100 | 3 | 118 |
| 10000 | 10 | 2 | 1 |
| 10000 | 50 | 13 | 156 |
| 10000 | 100 | 26 | 1211 |
从上表可以看出,当文本串和模式串长度相差不大时,KMP 算法的效率与 indexOf 方法相当,但当模式串很长或者文本串很短时,KMP 算法的效率明显高于 indexOf 方法。
相关文章:
)
KMP 算法(Knuth-Morris-Pratt)
tip:作为程序员一定学习编程之道,一定要对代码的编写有追求,不能实现就完事了。我们应该让自己写的代码更加优雅,即使这会费时费力。 推荐:体系化学习Java(Java面试专题) 文章目录 一、什么是 …...

Java泛型详解
泛型的理解 泛型的概念 所谓泛型,就是允许在定义类、接口时通过一个标识表示类中某个属性的类型 或者是 某个方法的返回值类型及参数类型。这个类型参数将在使用时(例如,继承或实现这个接口,用这个类型声明变量、创建对象时&#…...

2023上海国际嵌入式展 | 如何通过人工智能驱动的自动化测试工具提升嵌入式开发效率
2023年6月14日到16日,龙智将在2023上海国际嵌入式展(embedded world China 2023)A055展位亮相。同时,6月14日下午3:00-3:30,龙智资深DevSecOps顾问巫晓光将于创新技术及应用发展论坛第二论坛区(A325展位&am…...
微信小程序个人心得
首先从官方文档给的框架说起,微信小程序官方文档给出了app.js, app.json, app.wxss. 先从这三个文件说起. 复制 app.js 这个文件是整个小程序的入口文件,开发者的逻辑代码在这里面实现,同时在这个文件夹里面可以定义全局变量.app.json 这个文件可以对小程序进行全局配置,决定…...
苹果MacOS系统傻瓜式本地部署AI绘画Stable Diffusion教程
Stable Diffusion的部署对小白来说非常麻烦,特别是又不懂技术的人。今天分享两个一键傻瓜式安装包,对小白来说非常有用。下面两个任选一个安装就可以。 一、DiffusionBee 简单介绍 DiffusionBee是基于stable diffusion的一个安装包,有图形…...
与闪回特性(flashback)[待更新])
DBA之路-- 闪回恢复区FRA(Flash recovery area)与闪回特性(flashback)[待更新]
闪回恢复区FRA(Flash recovery area)与闪回特性(flashback) 1、闪回特性FB 用于快速简单恢复数据库中出现的认为误操作等逻辑错误 Flashback由undo表空间的撤销段内容为基础,受限于UNDO_RETENTON参数。要使用flashb…...

chatgpt赋能python:Python3.6.5到Python3.7.5:升级指南
Python 3.6.5到Python 3.7.5:升级指南 Python是一种广泛使用的编程语言,拥有强大的库和框架,能够开发各种类型的应用程序。在Python的发行版中,版本更新是常见的过程,以提供更好的性能和新的功能。 本文将介绍如何将…...

Element UI DatePicker 日期选择器
该组件选择周的时候,默认显示‘xxxx年第x周’,但在需求要显示为‘xxxx年x月第x周(mm.dd - mm.dd)’或者‘本周(mm.dd - mm.dd)’,最终效果为 首先需要修改v-model默认展示日期,控件中默认展示为周二&#x…...
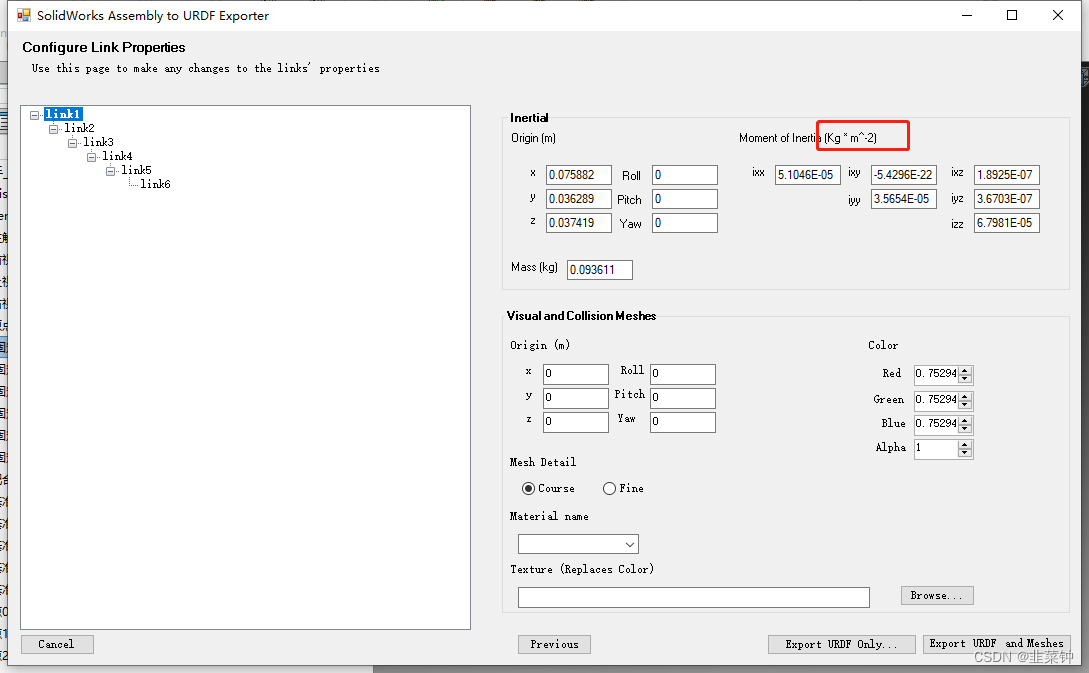
sw2urdf导出的urdf文件中的惯性参数(inertial)错误的问题
现象描述 有时候,当我们使用solidworks建好我们的模型,然后利用【sw2urdf】导出后,发现其中的惯性参数,似乎不正确,ixx、izz这些参数都是很接近0的: 资料查找 其实这个不是我们设置的问题,而…...

AICG - Stable Diffusion 学习思考踩坑实录(待续补充)
关于模型 如果模型中没有各种角度的脚和手,无论你再怎么费劲心思,AI 都画不出来,目前C 站也没有什么好脚的例子,正面脚背面脚,但是没有侧面脚,脚这块还是很欠缺,希望未来有大牛能训练出来美脚 …...
LiangGaRy-学习笔记-Day19
1、回顾知识 1.1、文件系统说明 xfs与ext4文件系统 CentOS7以上:默认的就是XFS文件系统 xfs 使用的就是restore、dump等工具 CentOS6默认的就是ext4文件系统 extundelete工具就是用于ext4系统 1.2、回顾Linux文件系统 Linux文件系统是由三个部分组成 inode文…...
智能指针(1)
智能指针(1) 概念内存泄漏指针指针概念RAII使用裸指针存在的问题 智能指针使用分类unique(唯一性智能指针)介绍智能指针的仿写代码理解删除器 概念 内存泄漏 内存泄漏:程序中已动态分配的堆内存由于某些原因而未释放…...

Steemit 会颠覆 Quora/知乎 甚至 Facebook 吗?
Steemit是基于区块链技术的社交媒体平台,其独特的激励机制吸引了众多用户。然而,是否能够真正颠覆Quora、知乎甚至Facebook这些已经成为社交巨头的平台,仍然存在着许多未知因素。本文将探讨Steemit的优势和挑战,以及其在社交领域中…...
002Mybatis初始化引入
引入依赖 <dependency><groupId>org.mybatis.spring.boot</groupId><artifactId>mybatis-spring-boot-starter</artifactId> </dependency> 自动检测工程中的DataSource创建并注册SqlSessionFactory实例创建并注册SqlSessionTemplate实例自…...
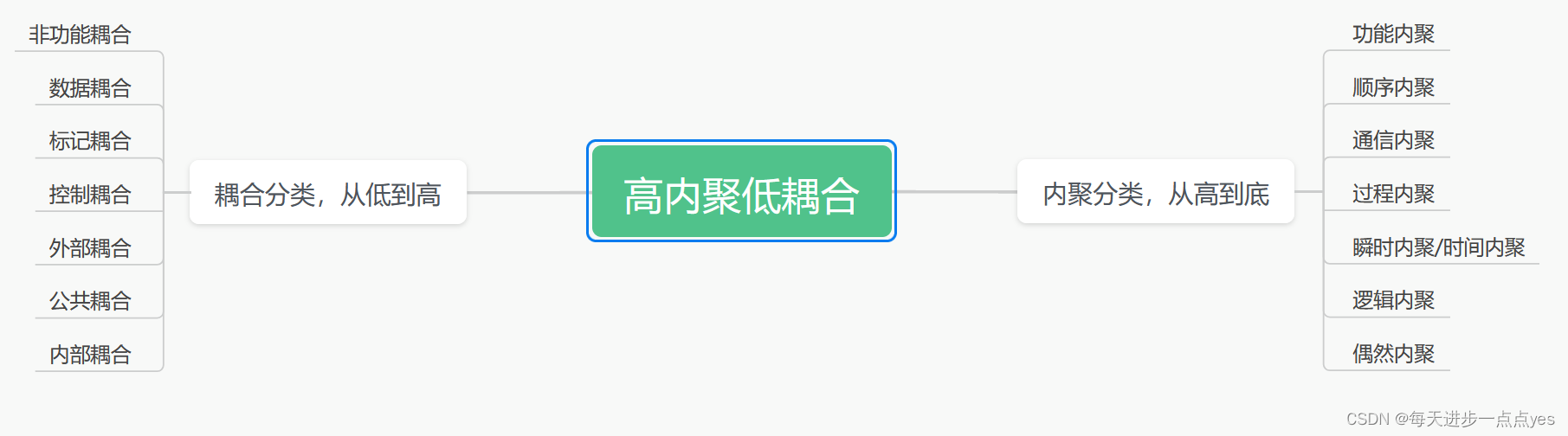
系统架构师之高内聚低耦合
一、概念: 标记耦合(Stamp Coupling)和数据耦合(Data Coupling)是软件设计中两种不同的耦合类型,它们之间的区别如下: 标记耦合:标记耦合是指模块之间通过参数传递标记或标识符来进…...
)
Netty核心源码剖析(二)
1.Netty接受请求过程源码剖析 1>.从之前的Netty启动过程源码剖析中,我们得知服务器最终注册了一个Accept事件等待客户端的连接.我们也知道,NioServerSocketChannel将自己注册到了bossGroup单例线程池(reactor线程)上,也就是EventLoop; 2>.先简单说下EventLoop的逻辑,Ev…...

「C/C++」C/C++ Lamada表达式
✨博客主页:何曾参静谧的博客 📌文章专栏:「C/C」C/C程序设计 相关术语 Lambda表达式:是C11引入的一种函数对象,可以方便地创建匿名函数。与传统的函数不同,Lambda表达式可以在定义时直接嵌入代码ÿ…...
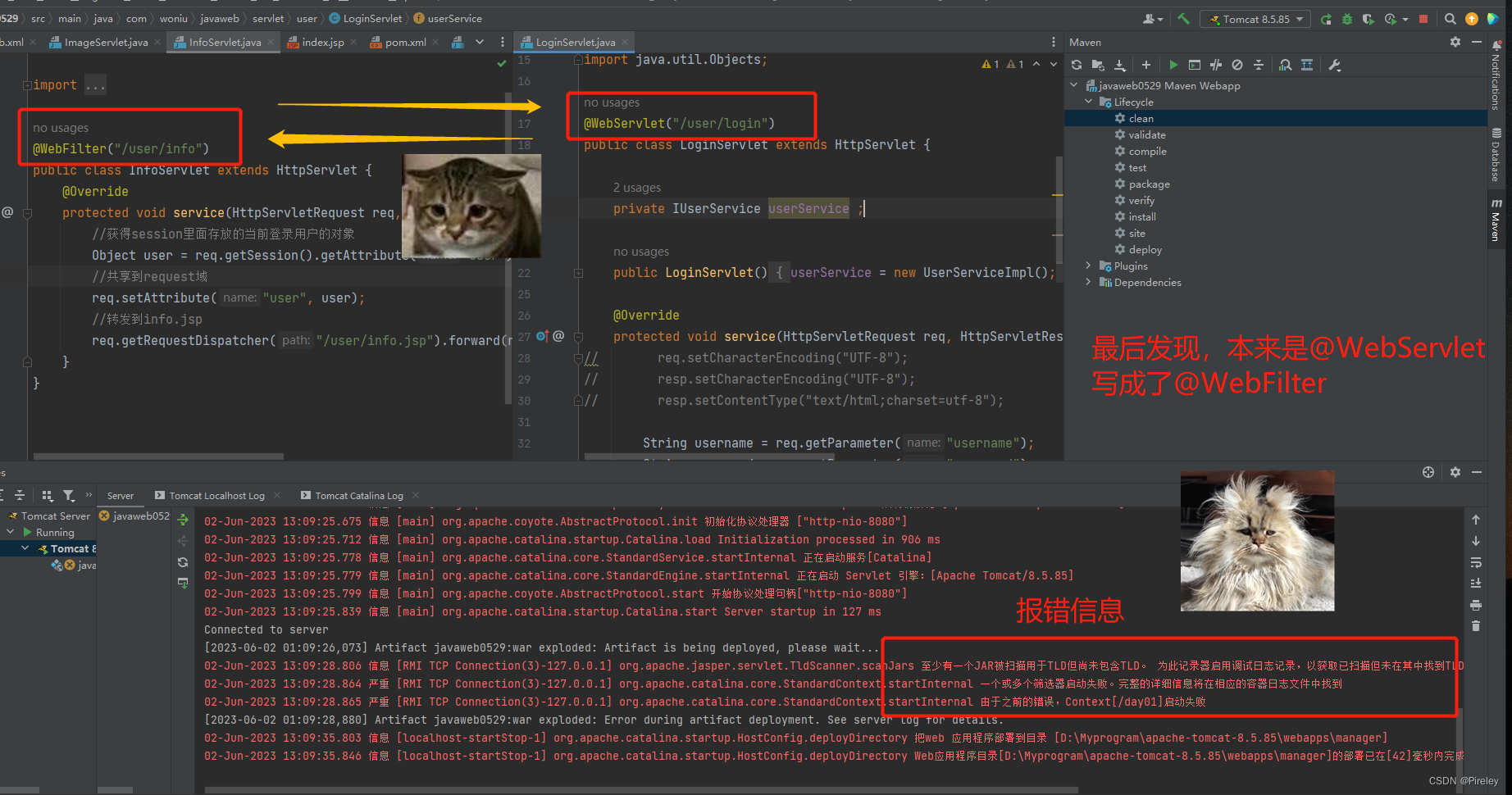
bug(Tomcat):StandardContext.startInternal 由于之前的错误,Context[/day01]启动失败
引出 项目启动失败,一个困扰了一上午的bug 报错信息 org.apache.catalina.core.StandardContext.startInternal 一个或多个筛选器启动失败。完整的详细信息将在相应的容器日志文件中找到 org.apache.catalina.core.StandardContext.startInternal 由于之前的错误…...

Java性能权威指南-总结6
Java性能权威指南-总结6 垃圾收集入门垃圾收集概述GC算法选择GC算法 垃圾收集入门 垃圾收集概述 GC算法 JVM提供了以下四种不同的垃圾收集算法: Serial垃圾收集器 Serial垃圾收集器是四种垃圾收集器中最简单的一种。如果应用运行在Client型虚拟机(Windows平台上的32位JVM或…...

群的定义及性质
群的定义 设 < G , ⋅ > \left<G,\cdot\right> ⟨G,⋅⟩为独异点,若 G G G中每个元素关于 ⋅ \cdot ⋅都是可逆的,则称 < G , ⋅ > \left<G,\cdot\right> ⟨G,⋅⟩为群 由于群中结合律成立,每个元素的逆元是唯一的 …...

2025届最火的十大降重复率工具推荐
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 当前阶段,部分域内有着AIGC被滥用的状况,这毫无疑问增添了运营成本以…...

如何加速下载与捕获视频:Xtreme Download Manager 完全指南
如何加速下载与捕获视频:Xtreme Download Manager 完全指南 【免费下载链接】xdm Powerfull download accelerator and video downloader 项目地址: https://gitcode.com/gh_mirrors/xd/xdm 还在为缓慢的下载速度而烦恼吗?是否曾经想要保存在线视…...

RDP Wrapper完整教程:Windows家庭版免费开启远程桌面多用户功能终极指南
RDP Wrapper完整教程:Windows家庭版免费开启远程桌面多用户功能终极指南 【免费下载链接】rdpwrap RDP Wrapper Library 项目地址: https://gitcode.com/gh_mirrors/rd/rdpwrap 还在为Windows家庭版无法使用远程桌面功能而烦恼吗?RDP Wrapper Lib…...

拉罗替尼Larotrectinib常见副作用ALT升高及疲劳如何有效应对【海得康】
在拉罗替尼(Larotrectinib)治疗NTRK融合阳性实体瘤的临床实践中,ALT升高与疲劳堪称两大最具代表性的不良反应。前者直指肝脏安全底线,后者则如影随形地侵蚀着患者的日常功能与生活质量。根据FDA批准的处方信息、三项关键临床试验&…...

Semper NOR Flash在汽车电子中的功能安全设计与应用
1. Semper NOR Flash在功能安全领域的核心价值 在汽车电子和工业控制系统中,数据存储的可靠性直接关系到人身安全。想象一下,当自动驾驶车辆以120km/h行驶时,如果ADAS系统的关键代码因存储器故障而失效,后果将不堪设想。这正是Sem…...

黑苹果安装实战指南:1000+机型EFI配置与工具集深度解析
黑苹果安装实战指南:1000机型EFI配置与工具集深度解析 【免费下载链接】Hackintosh Hackintosh long-term maintenance model EFI and installation tutorial 项目地址: https://gitcode.com/gh_mirrors/ha/Hackintosh 在非苹果硬件上运行macOS(俗…...

ESP32-S3开发实战:从点灯到Wi-Fi联网的完整指南
1. 项目概述:从点灯到联网的ESP32-S3实战之旅拿到一块新的开发板,第一件事是什么?我的习惯永远是先让它“眨眨眼”。这个看似简单的LED闪烁,在嵌入式开发里,就像程序员的“Hello World”,是检验硬件、软件环…...
)
从服务端到登录器:《传奇世界》单机架设全流程拆解与工具选择指南(AFT/彩虹/凤凰引擎对比)
从服务端到登录器:《传奇世界》单机架设全流程拆解与工具选择指南 在经典网游《传奇世界》的爱好者圈子里,单机架设一直是技术玩家热衷探索的领域。不同于简单的游戏体验,搭建一个完整的单机环境意味着对游戏架构的深度理解和技术掌控。本文将…...

基于GPT-5.5构建智能问答系统的实现方案
概要GPT-5.5 是 OpenAI 于 2026 年 4 月发布的旗舰模型,Terminal-Bench 2.0 得分 82.7%,在 Agent 能力、多步骤自动化、工具调用等方面较前代有显著提升。该模型沿用 Chat Completions API 接口格式,支持文本和图像输入,具备 func…...
)
【C++】继承详解——基类/派生类、作用域、默认函数、菱形继承(超详细)
文章目录一、继承开篇二、继承的概念及定义1. 继承是什么2. 继承定义格式3. 继承后成员访问权限变化(超级重要)三、基类和派生类的赋值转换(切片/切割)四、继承中的作用域(隐藏 / 重定义)1. 成员变量隐藏2.…...