TiDB亿级数据亚秒响应查询集群部署
目录
- 1 集群部署
- 1.1 环境要求
- 1.1.1 操作系统建议配置
- 1.1.2 服务器建议配置
- 1.2 环境准备
- 1.3 安装TiUP
- 1.3.1 什么是TiUP
- 1.3.2 安装TiUP组件
- 1.3.3 配置TiUP环境
- 1.3.4 检查TiUP 工具是否安装
- 1.3.5 安装 cluster 组件
- 1.3.6 升级cluster组件
- 1.4 编辑部署文件
- 1.4.1 常见的部署场景
- 1.4.2 单机极简部署
- 1.5 执行集群部署命令
- 1.5.1 命令格式
- 1.5.2 检查TiDB最新版本
- 1.5.3 执行部署命令
- 1.5.4 启动集群
- 1.5.5 查看节点状态
- 2. 测试TiDB集群
- 2.1 Mysql连接集群
- 2.1.1 安装MySql客户端
- 2.1.2 第三方客户端访问Mysql
- 2.2 访问Grafana监控
- 2.3 访问Dashboard
- 2.4 查看集群列表
- 2.5 查看集群拓扑
1 集群部署

1.1 环境要求
1.1.1 操作系统建议配置
TiDB 作为一款开源分布式 NewSQL 数据库,可以很好的部署和运行在 Intel 架构服务器环境、ARM 架构的服务器环境及主流虚拟化环境,并支持绝大多数的主流硬件网络。作为一款高性能数据库系统,TiDB 支持主流的 Linux 操作系统环境。
| Linux 操作系统平台 | 版本 |
|---|---|
| Red Hat Enterprise Linux | 7.3 及以上 |
| CentOS | 7.3 及以上 |
| Oracle Enterprise Linux | 7.3 及以上 |
| Ubuntu LTS | 16.04 及以上 |
1.1.2 服务器建议配置
TiDB 支持部署和运行在 Intel x86-64 架构的 64 位通用硬件服务器平台或者 ARM 架构的硬件服务器平台。对于开发,测试,及生产环境的服务器硬件配置(不包含操作系统 OS 本身的占用)有以下要求和建议:
开发及测试环境
| 组件 | CPU | 内存 | 本地存储 | 网络 | 实例数量(最低要求) |
|---|---|---|---|---|---|
| TiDB | 8 核+ | 16 GB+ | 无特殊要求 | 千兆网卡 | 1(可与 PD 同机器) |
| PD | 4 核+ | 8 GB+ | SAS, 200 GB+ | 千兆网卡 | 1(可与 TiDB 同机器) |
| TiKV | 8 核+ | 32 GB+ | SSD, 200 GB+ | 千兆网卡 | 3 |
| TiFlash | 32 核+ | 64 GB+ | SSD, 200 GB+ | 千兆网卡 | 1 |
| TiCDC | 8 核+ | 16 GB+ | SAS, 200 GB+ | 千兆网卡 | 1 |
生产环境
| 组件 | CPU | 内存 | 硬盘类型 | 网络 | 实例数量(最低要求) |
|---|---|---|---|---|---|
| TiDB | 16 核+ | 32 GB+ | SAS | 万兆网卡(2 块最佳) | 2 |
| PD | 4核+ | 8 GB+ | SSD | 万兆网卡(2 块最佳) | 3 |
| TiKV | 16 核+ | 32 GB+ | SSD | 万兆网卡(2 块最佳) | 3 |
| TiFlash | 48 核+ | 128 GB+ | 1 or more SSDs | 万兆网卡(2 块最佳) | 2 |
| TiCDC | 16 核+ | 64 GB+ | SSD | 万兆网卡(2 块最佳) | 2 |
| 监控 | 8 核+ | 16 GB+ | SAS | 千兆网卡 | 1 |
1.2 环境准备
准备一台部署主机,确保其软件满足需求:
- 推荐安装 CentOS 7.3 及以上版本
- Linux 操作系统开放外网访问,用于下载 TiDB 及相关软件安装包
最小规模的 TiDB 集群拓扑
| 实例 | 个数 | IP | 配置 |
|---|---|---|---|
| TiKV | 3 | 192.168.10.30 | 避免端口和目录冲突 |
| TiDB | 1 | 192.168.10.30 | 默认端口 全局目录配置 |
| PD | 1 | 192.168.10.30 | 默认端口 全局目录配置 |
| TiFlash | 1 | 192.168.10.30 | 默认端口 全局目录配置 |
| Monitoring & Grafana | 1 | 192.168.10.30 | 默认端口 全局目录配置 |
1.3 安装TiUP
1.3.1 什么是TiUP
从 TiDB 4.0 版本开始,TiUP 作为新的工具,承担着包管理器的角色,管理着 TiDB 生态下众多的组件,如 TiDB、PD、TiKV 等。用户想要运行 TiDB 生态中任何组件时,只需要执行 TiUP 一行命令即可,相比以前,极大地降低了管理难度。
1.3.2 安装TiUP组件
使用普通用户登录中控机,以 tidb 用户为例,后续安装 TiUP 及集群管理操作均通过该用户完成
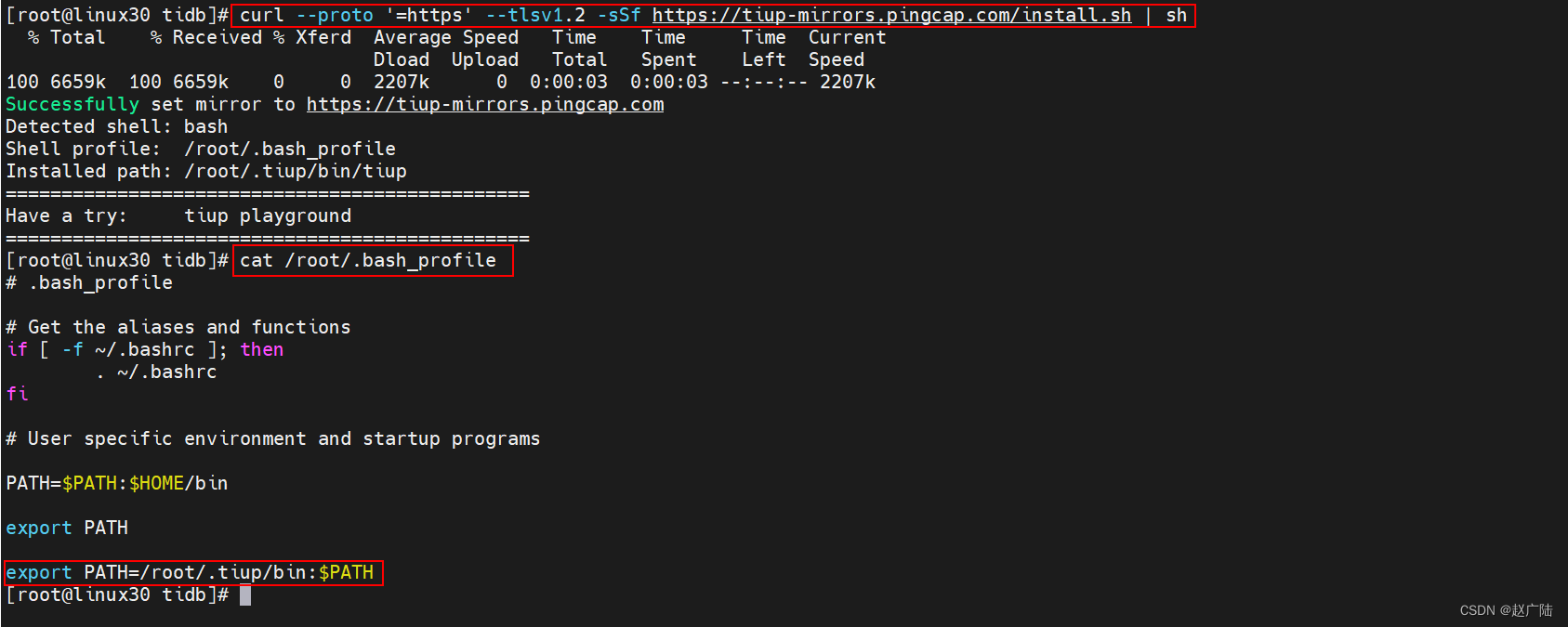
TiUP 安装过程十分简洁,无论是 Darwin 还是 Linux 操作系统,执行一行命令即可安装成功:
[root@linux30 ~]# curl --proto '=https' --tlsv1.2 -sSf https://tiup-mirrors.pingcap.com/install.sh | sh
该命令将 TiUP 安装在 `$HOME/.tiup` 文件夹下,之后安装的组件以及组件运行产生的数据也会放在该文件夹下。同时,它还会自动将 `$HOME/.tiup/bin` 加入到 Shell Profile 文件的 PATH 环境变量中,这样你就可以直接使用 TiUP 了。
1.3.3 配置TiUP环境
重新声明全局环境变量
[root@linux30 tidb]# source /root/.bash_profile
1.3.4 检查TiUP 工具是否安装
[root@linux30 tidb]# which tiup
/root/.tiup/bin/tiup
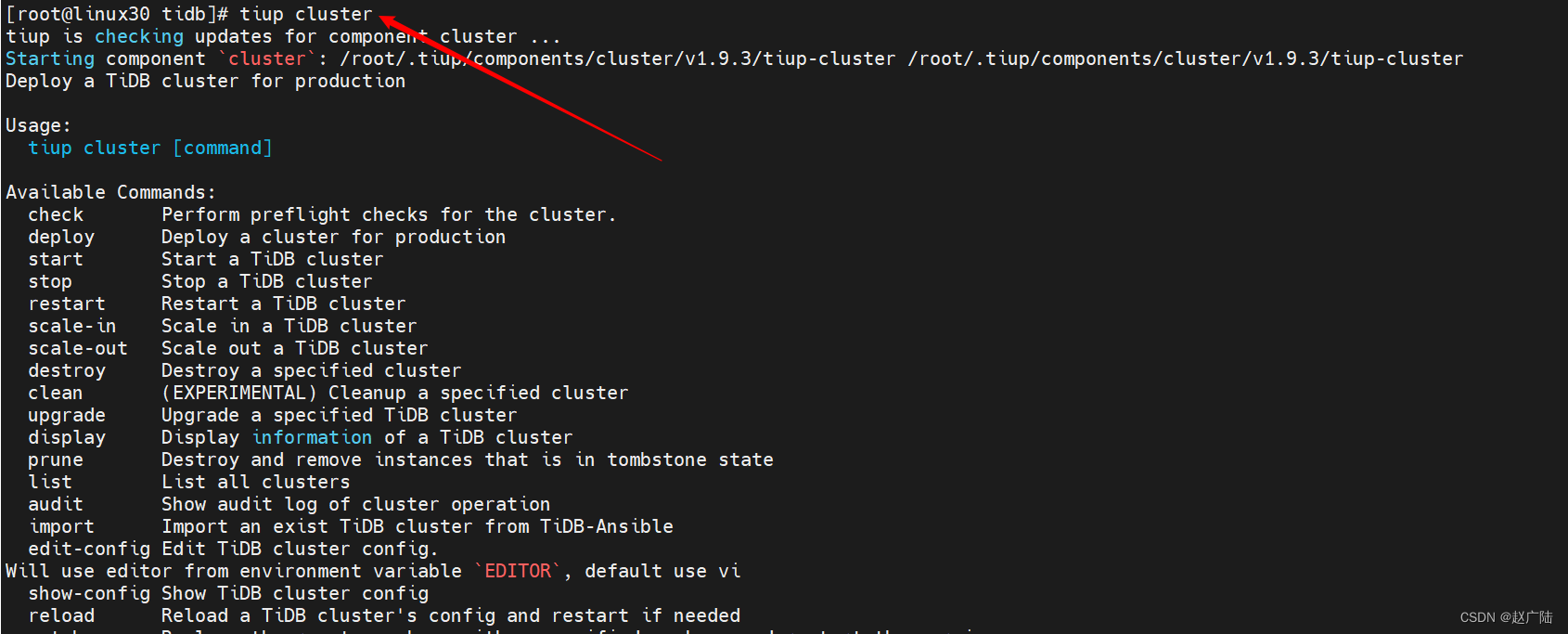
1.3.5 安装 cluster 组件
[root@linux30 tidb]# tiup cluster
1.3.6 升级cluster组件
如果机器已经安装 TiUP cluster,需要更新软件版本
[root@linux30 tidb]# tiup update --self && tiup update cluster
预期输出
“Update successfully!”字样。

1.4 编辑部署文件
请根据不同的集群拓扑,编辑 TiUP 所需的集群初始化配置文件。
1.4.1 常见的部署场景
最小拓扑架构
最基本的集群拓扑,包括 tidb-server、tikv-server、pd-server,适合 OLTP 业务。
增加 TiFlash 拓扑架构
包含最小拓扑的基础上,同时部署 TiFlash。TiFlash 是列式的存储引擎,已经逐步成为集群拓扑的标配。适合 Real-Time HTAP 业务。
增加 TiCDC 拓扑架构
包含最小拓扑的基础上,同时部署 TiCDC。TiCDC 是 4.0 版本开始支持的 TiDB 增量数据同步工具,支持多种下游 (TiDB/MySQL/MQ)。相比于 TiDB Binlog,TiCDC 有延迟更低、天然高可用等优点。在部署完成后,需要启动 TiCDC,通过 `cdc cli` 创建同步任务。
增加 TiDB Binlog 拓扑架构
包含最小拓扑的基础上,同时部署 TiDB Binlog。TiDB Binlog 是目前广泛使用的增量同步组件,可提供准实时备份和同步功能。
增加 TiSpark 拓扑架构
包含最小拓扑的基础上,同时部署 TiSpark 组件。TiSpark 是 PingCAP 为解决用户复杂 OLAP 需求而推出的产品。TiUP cluster 组件对 TiSpark 的支持目前为实验性特性。
混合部署拓扑架构
适用于单台机器,混合部署多个实例的情况,也包括单机多实例,需要额外增加目录、端口、资源配比、label 等配置。
1.4.2 单机极简部署
部署主机软件和环境要求:
- 部署需要使用部署主机的 root 用户及密码
- 部署主机关闭防火墙或者开放 TiDB 集群的节点间所需端口
单机极简拓扑
| 实例 | IP | 开放端口 |
|---|---|---|
| grafana | 192.168.10.30 | 3000 |
| pd | 192.168.10.30 | 2379/2380 |
| prometheus | 192.168.10.30 | 9090 |
| tidb | 192.168.10.30 | 4000/10080 |
| tiflash | 192.168.10.30 | 9000/8123/3930/20170/20292/8234 |
| tikv | 192.168.10.30 | 20160/20180 |
| tikv | 192.168.10.30 | 20161/20181 |
| tikv | 192.168.10.30 | 20162/20182 |
编辑配置文件
按下面的配置模板,编辑配置文件,命名为
topo.yaml
user: "tidb":表示通过tidb系统用户(部署会自动创建)来做集群的内部管理,默认使用 22 端口通过 ssh 登录目标机器replication.enable-placement-rules:设置这个 PD 参数来确保 TiFlash 正常运行host:设置为本部署主机的 IP
# # Global variables are applied to all deployments and used as the default value of
# # the deployments if a specific deployment value is missing.
global:user: "tidb"ssh_port: 22deploy_dir: "/opt/tidb/tidb-deploy"data_dir: "/opt/tidb/tidb-data"# # Monitored variables are applied to all the machines.
monitored:node_exporter_port: 9100blackbox_exporter_port: 9115server_configs:tidb:log.slow-threshold: 300tikv:readpool.storage.use-unified-pool: falsereadpool.coprocessor.use-unified-pool: truepd:replication.enable-placement-rules: truereplication.location-labels: ["host"]tiflash:logger.level: "info"pd_servers:- host: 192.168.10.30tidb_servers:- host: 192.168.10.30tikv_servers:- host: 192.168.10.30port: 20160status_port: 20180config:server.labels: { host: "logic-host-1" }- host: 192.168.10.30port: 20161status_port: 20181config:server.labels: { host: "logic-host-2" }- host: 192.168.10.30port: 20162status_port: 20182config:server.labels: { host: "logic-host-3" }tiflash_servers:- host: 192.168.10.30monitoring_servers:- host: 192.168.10.30grafana_servers:- host: 192.168.10.301.5 执行集群部署命令
1.5.1 命令格式
tiup cluster deploy <cluster-name> <tidb-version> ./topo.yaml --user root -p
参数解释
- 参数
<cluster-name>表示设置集群名称 - 参数
<tidb-version>表示设置集群版本,可以通过tiup list tidb命令来查看当前支持部署的 TiDB 版本 - 参数:
--use.r root通过 root 用户登录到目标主机完成集群部署,该用户需要有 ssh 到目标机器的权限,并且在目标机器有 sudo 权限。也可以用其他有 ssh 和 sudo 权限的用户完成部署。
1.5.2 检查TiDB最新版本
可以通过执行
tiup list tidb来查看 TiUP 支持的版本
[root@linux30 tidb]# tiup list tidb
经过执行发现 可用的TiDB版本有 v5.3.0
1.5.3 执行部署命令
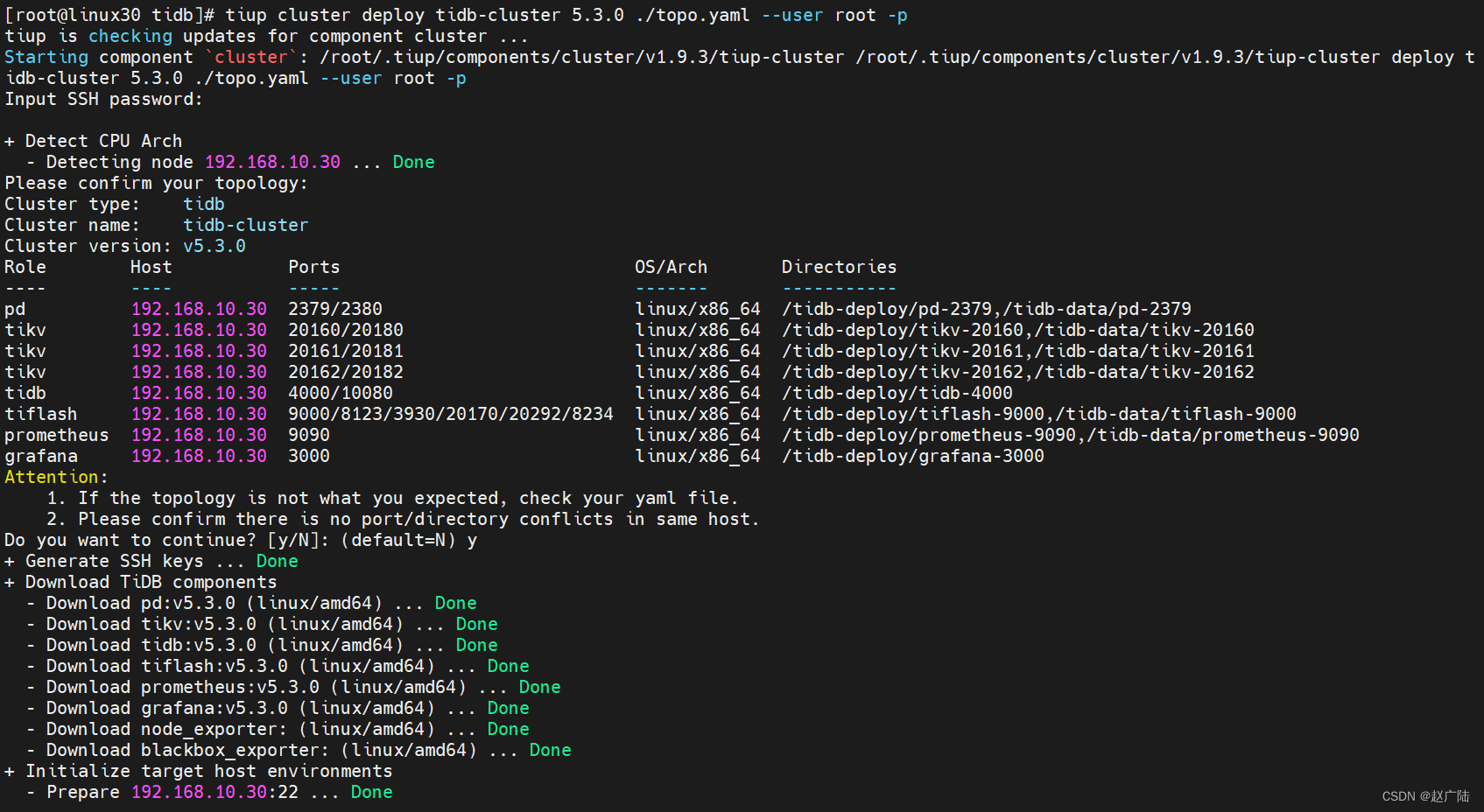
[root@linux30 tidb]# tiup cluster deploy tidb-cluster 5.3.0 ./topo.yaml --user root -p
下面输入
y继续后输入密码进行安装界面
进入安装界面,等待安装即可
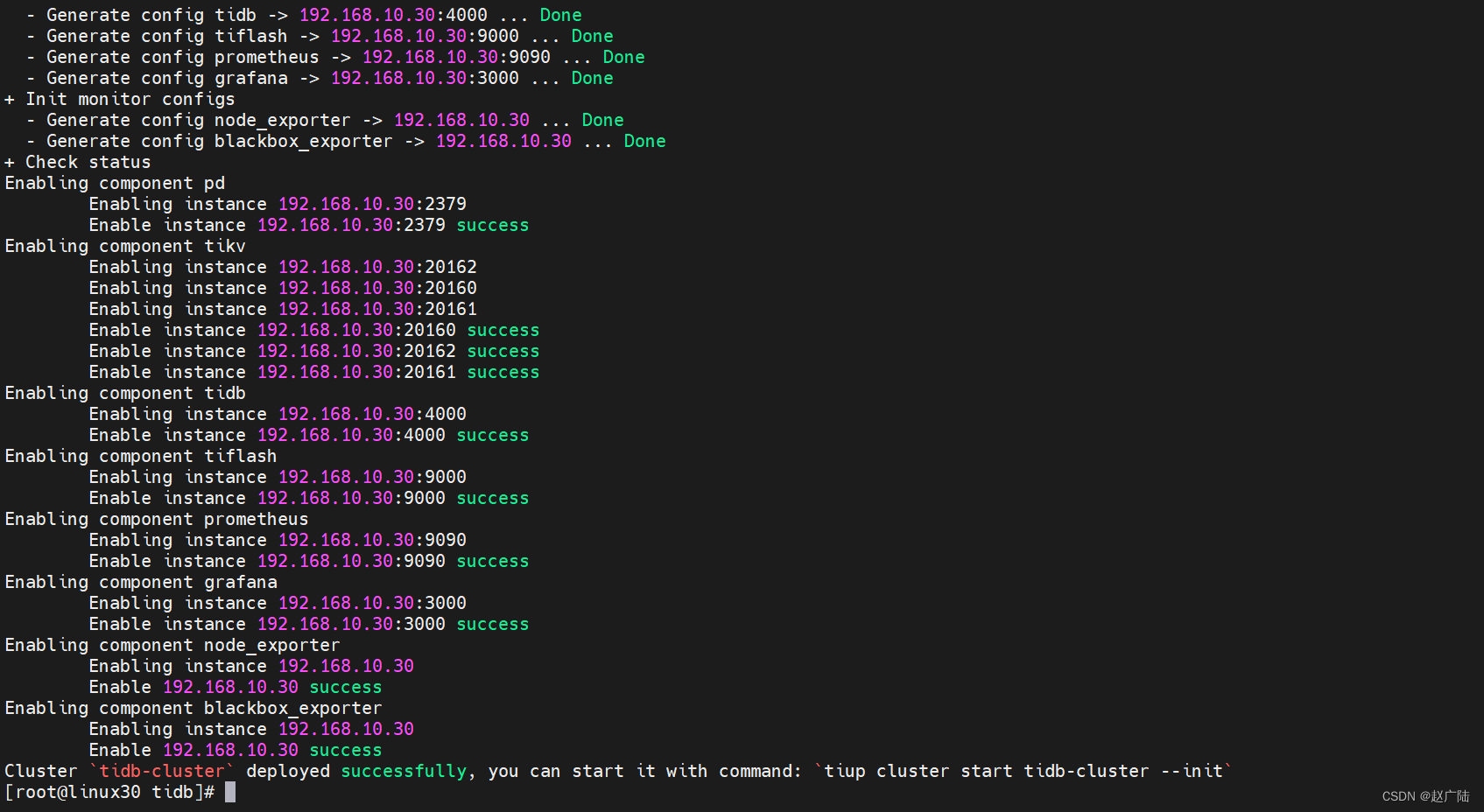
如果出现
deployed successfully表示部署成功,集群名称是tidb-cluster
1.5.4 启动集群
[root@linux30 tidb]# tiup cluster start tidb-cluster
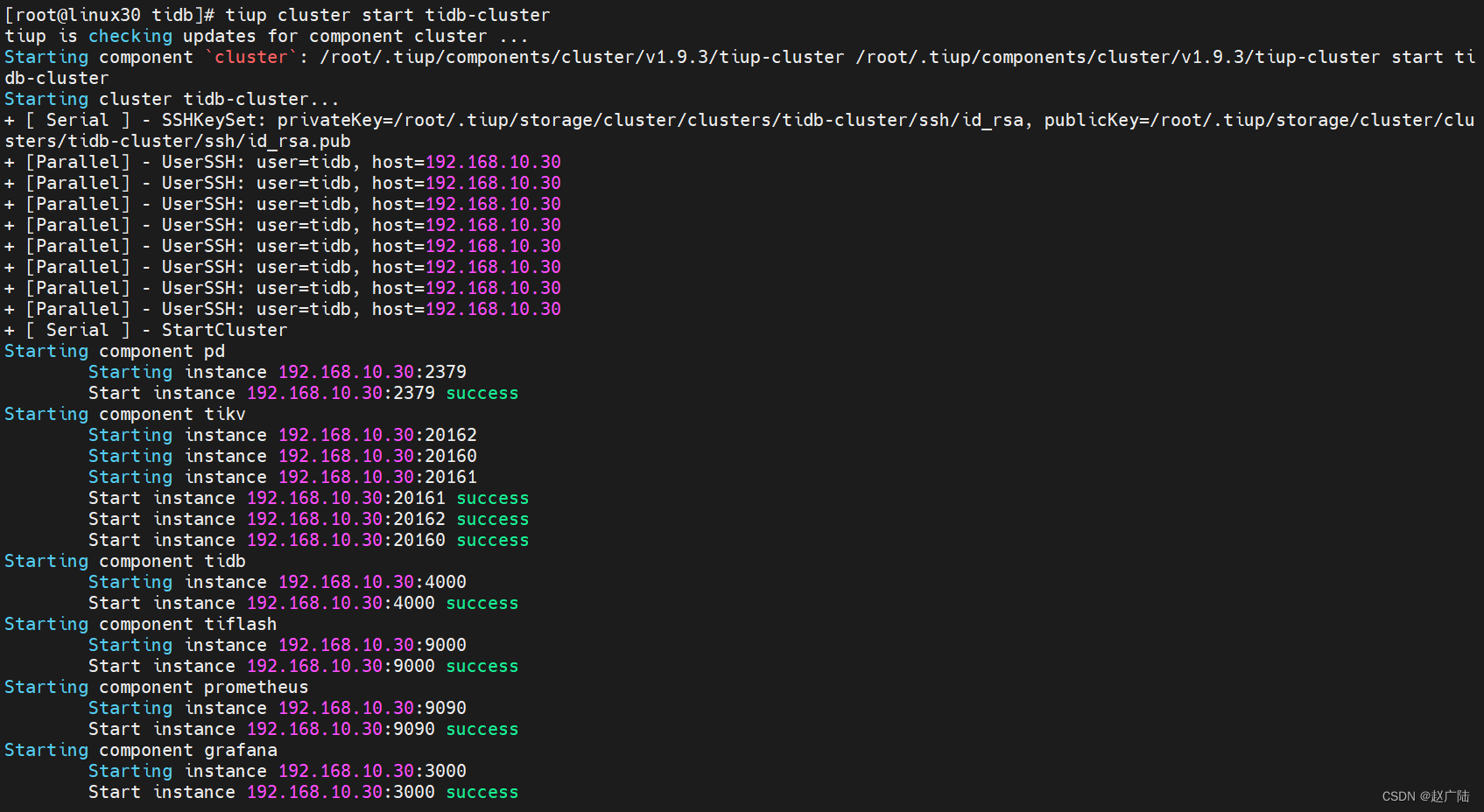
1.5.5 查看节点状态
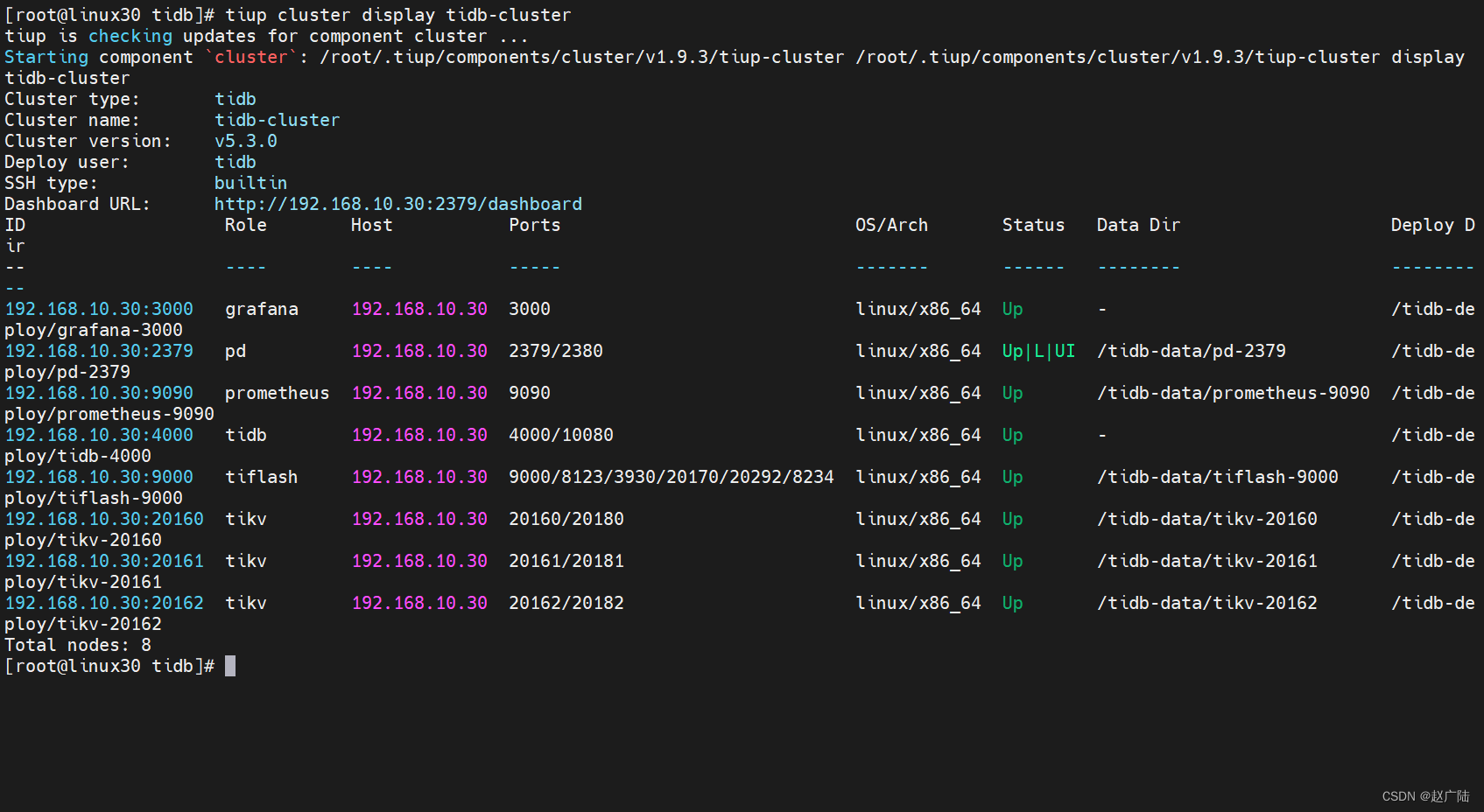
[root@linux30 tidb]# tiup cluster display tidb-cluster
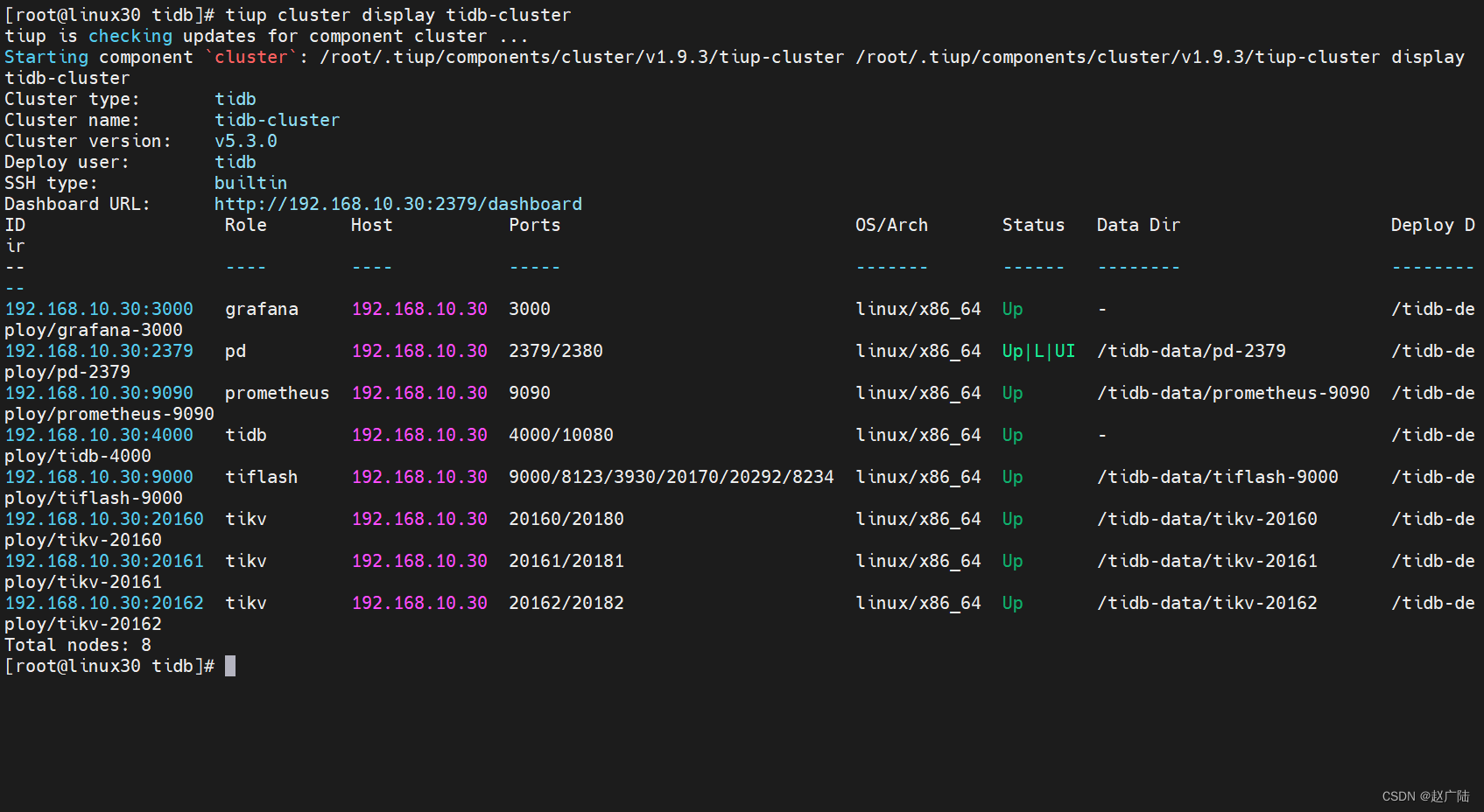
所有节点都是Up状态说明都已经启动就绪了
2. 测试TiDB集群
2.1 Mysql连接集群
TiDB的连接端口默认是4000, 密码是空,可用使用Mysql客户端以及第三方工具进行连接
2.1.1 安装MySql客户端
yum -y install mysql
MySql客户端连接
访问 TiDB 数据库,密码为空
[root@linux30 tidb]# mysql -uroot -p -P 4000 -h 192.168.10.30

2.1.2 第三方客户端访问Mysql
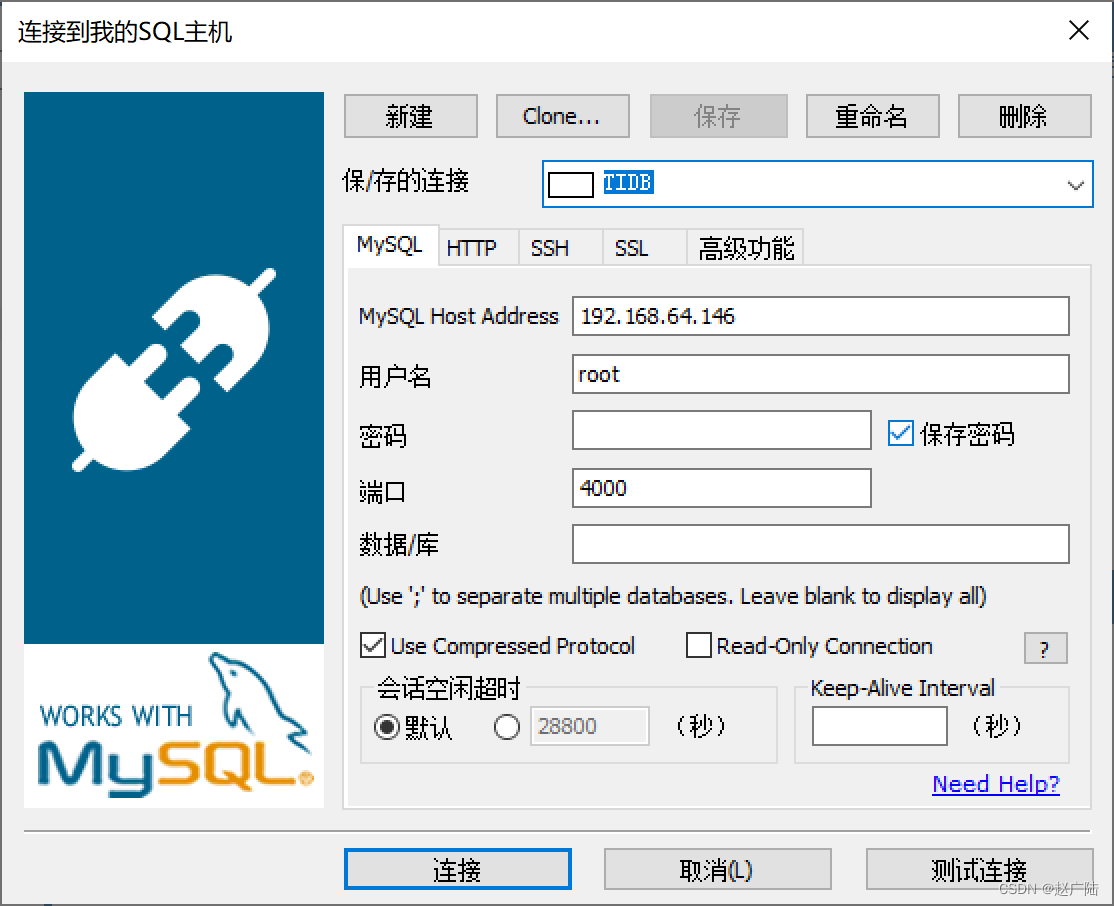
使用SQLyog访问TiDB
2.1.2.1 创建TiDB连接
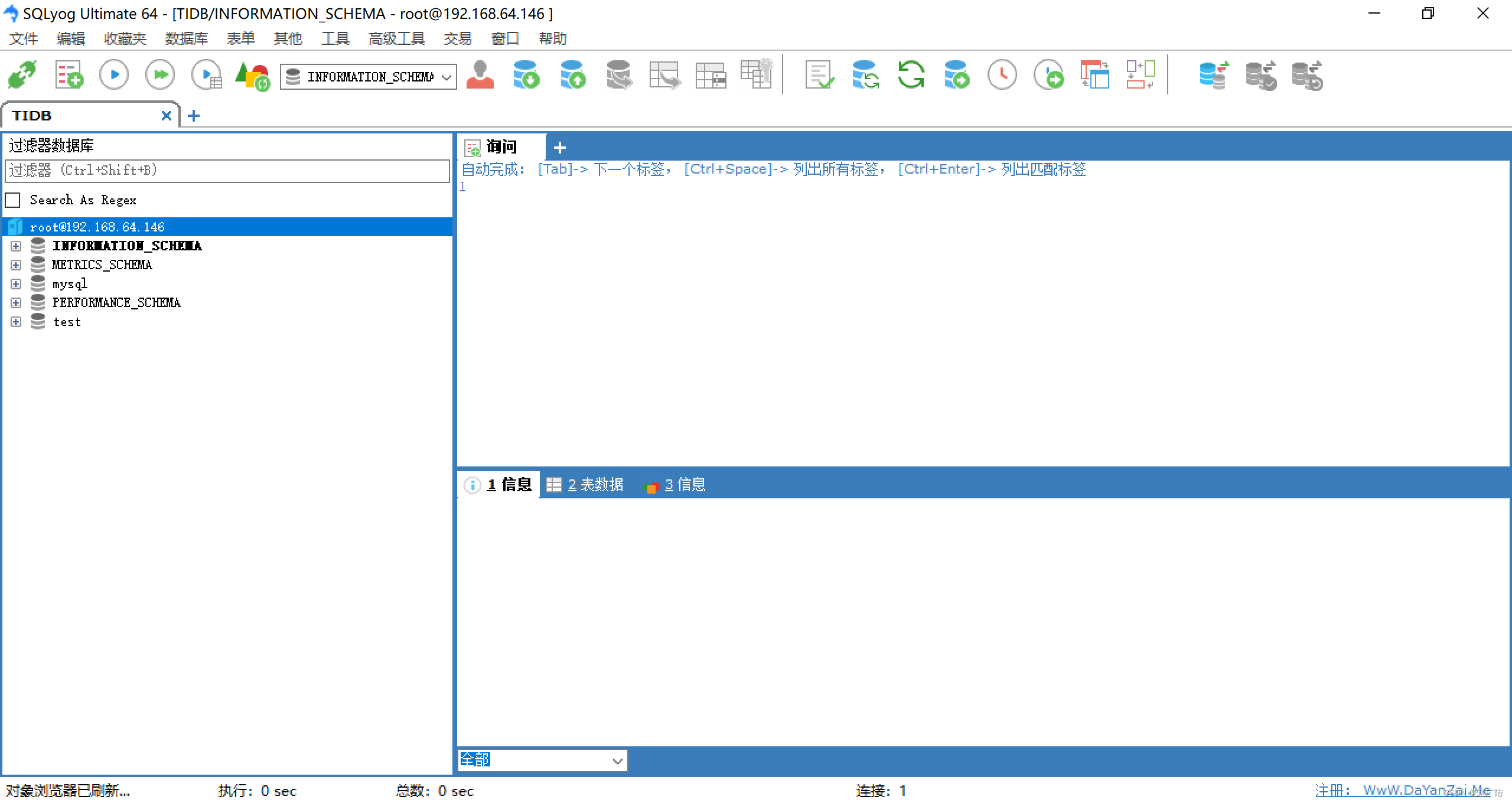
连接后就可以操作数据库了
2.2 访问Grafana监控
通过 http://192.168.10.30:3000 访问集群 Grafana 监控页面,默认用户名和密码均为 admin。
2.3 访问Dashboard
通过 http://192.168.10.30:2379/dashboard 访问集群 TiDB Dashboard监控页面,默认用户名为 root,密码为空。
2.4 查看集群列表
[root@linux30 tidb]# tiup cluster list

2.5 查看集群拓扑
[root@linux30 tidb]# tiup cluster display tidb-cluster
相关文章:
TiDB亿级数据亚秒响应查询集群部署
目录 1 集群部署1.1 环境要求1.1.1 操作系统建议配置1.1.2 服务器建议配置 1.2 环境准备1.3 安装TiUP1.3.1 什么是TiUP1.3.2 安装TiUP组件1.3.3 配置TiUP环境1.3.4 检查TiUP 工具是否安装1.3.5 安装 cluster 组件1.3.6 升级cluster组件 1.4 编辑部署文件1.4.1 常见的部署场景1.…...

并发——同步访问共享的可变数据
关键字 synchronized 可以保证在同一时刻,只有一个线程可以执行某一个方法,或者某一段代码块。许多程序员把同步的概念仅仅理解为一种互斥的方式。即,当一个对象被一个线程修改的时候,可以阻止另一个线程观察到内部不一致的状态。…...
禁用容器网络)
Docker网络模型(九)禁用容器网络
禁用容器网络 如果你想完全禁用容器上的协议栈,你可以在启动容器时使用 --network none 标志。在容器内,只有回环设备被创建。下面的例子说明了这一点。 创建容器 $ docker run --rm -dit \--network none \--name no-net-alpine \alpine:latest \ash通…...

JavaScript 教程---互联网文档计划
学习目标: 每天记录一章笔记 学习内容: JavaScript 教程---互联网文档计划 笔记时间: 2023-6-5 --- 2023-6-11 学习产出: 1.入门篇 1、JavaScript 的核心语法包含部分 基本语法标准库宿主API 基本语法:比如操作符…...

做好功能测试需要的8项基本技能【点工进来】
功能测试是测试工程师的基础功,很多人功能测试还做不好,就想去做性能测试、自动化测试。很多人对功能测试的理解就是点点点,如何自己不用心去悟,去研究,那么你的职业生涯也就停留在点点点上了。在这里,我把…...
在弹出框内三个元素做水平显示
最终效果图要求是这样: js代码: // 显示弹出窗口 function showPopup(node) {var popup document.createElement(div);popup.className popup;var inputContainer1 document.createElement(div);/* inputContainer1.className input-container1; */…...

纠删码技术在vivo存储系统的演进【上篇】
作者:vivo 互联网服务器团队- Gong Bing 本文将学术界和工业界的纠删码技术的核心研究成果进行了相应的梳理,然后针对公司线上存储系统的纠删码进行分析,结合互联网企业通用的IDC资源、服务器资源、网络资源、业务特性进行分析对原有纠删码技…...
如何实现APP自动化测试?
APP测试,尤其是APP的自动化测试,在软件测试工程师的面试中越来越会被问到了。为了更好的回答这个问题,我今天就给大家分享一下,如何进行APP的自动化测试。 一、为了实现JavaAppiumJunit技术用于APP自动化测试,所以需要…...

INNODB和MyISAM区别
1 存储引擎是MyISAM 如下: CREATE table test_myisam (cli int ) ENGINEMyISAM 存储目录里会有三个文件 test_myisam.frm为“表定义”,是描述数据表结构的文件 test_myisam.MYI文件是表的索引 test_myisam.MYD文件是表的数据 2 存储引擎是INNODB…...
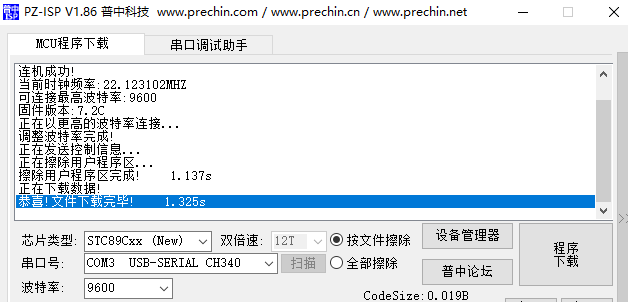
普中自动下载软件1.86下载程序失败案例
今天在用开发板做一个功能,下载的时候报错了,说芯片超时 确定驱动安装好了的 波特率也试了一圈 线也换过了 最后发现是芯片类型选错了,这个开发板是用的stc89c52,所以我选了图里这个,但是翻了开发板配套的资料,发现…...

JavaScript HTML DOM
JavaScript HTML DOM(文档对象模型)是一种用于访问和操作HTML文档元素的编程接口。它将HTML文档表示为一个树形结构,使开发人员可以使用JavaScript来操作和修改HTML元素、属性、样式和事件。 通过使用HTML DOM,你可以使用JavaScr…...
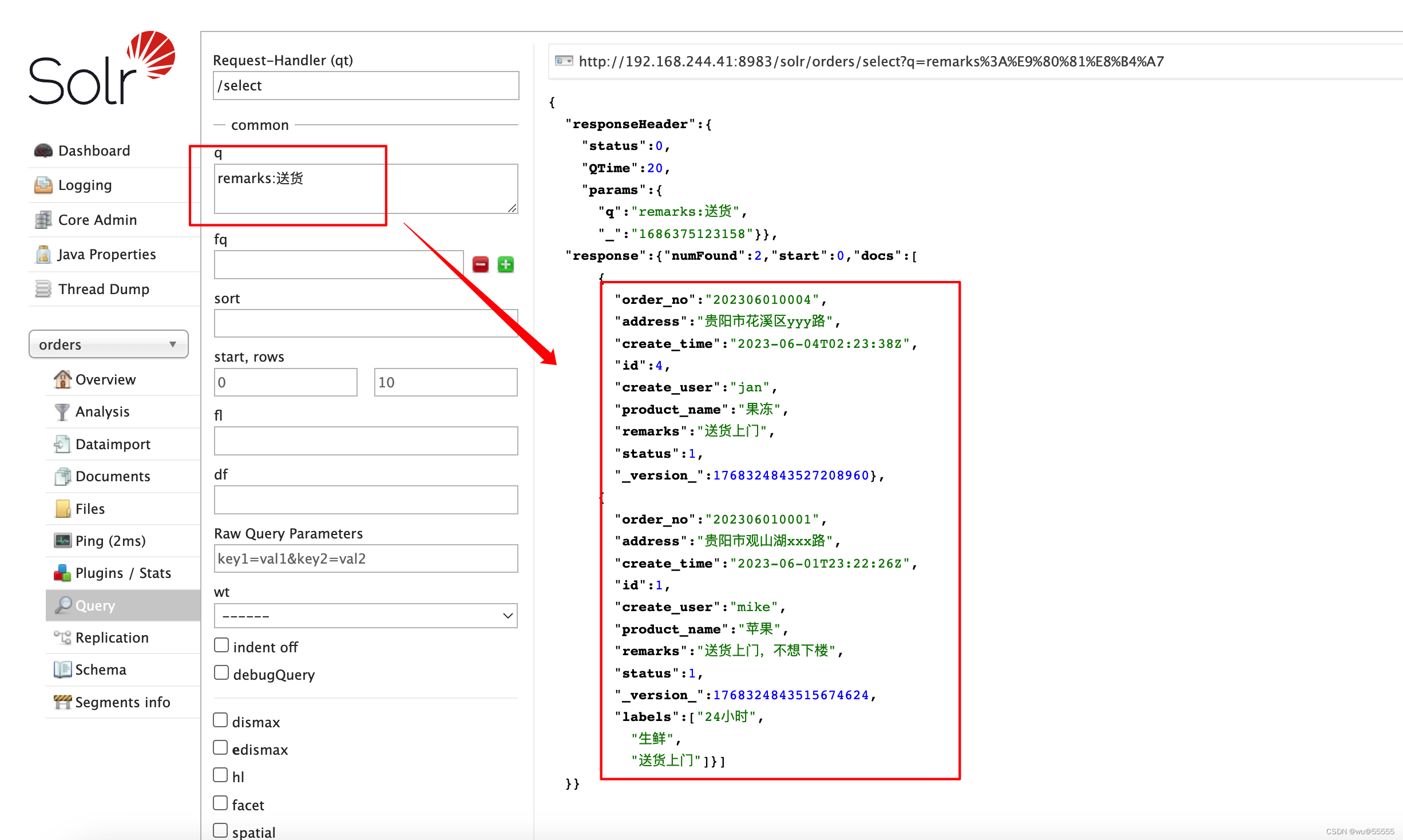
solr快速上手:配置IK中文分词器(七)
0. 引言 solr作为搜索引擎,常用在我们对于搜索速度有较高要求且大数据量的业务场景,我们之前已经配置过英文分词器,但是针对中文分词不够灵活和实用,要实现真正意义上的中文分词,还需要单独安装中文分词器 solr快速上…...

【软件测试】接口测试工具APIpost
说实话,了解APIpost是因为,我的所有接口相关的文章下,都有该APIpost水军的评论,无非就是APIpost是中文版的postman,有多么多么好用,虽然咱也还不是什么啥网红,但是不知会一声就乱在评论区打广告…...

第六章 假言:那么、就、则;才。
第六章 假言:那么、就、则;才。 第一节 假言-公式化转换-等价矛盾 真题(2012-38)-假言-A→B的公式化转换-A→B的等价命题:①逆否命题:非B→非A。 38.经理说:“有了自信不一定赢。”董事长回…...

[干货] 如何解决慢SQL?详细分析和优化实践!
慢SQL优化实践 本篇博客将分享如何通过慢SQL分析工具和常用优化手段,来解决慢SQL的问题。首先让我们看一下慢SQL的定义。 什么是慢SQL 简单来说,慢SQL指的是执行时间较长的SQL语句。在数据库中,一个查询的运行时间往往会受到多种因素的影响…...

数据库实验三 数据查询二
任务描述 本关任务:查询来自借阅、图书、读者数据表的数据 为了完成本关任务,你需要掌握: 如何多表查询 相关知识 查询多个数据表 在实际应用中,查询经常会涉及到几个数据表。 基于多个相关联的数据表进行的查询称为连接查询…...

论文笔记与实战:对比学习方法MOCO
目录 1. 什么是MOCO2. MOCO是干吗用的3. MOCO的工作原理3.1 一些概念1. 无监督与有监督的区别2. 什么是对比学习3. 动量是什么 3.2 MOCO工作原理1. 字典查找2. 如何构建一个好的字典3. 工作流程 3.3 (伪)代码分析 4. 其他一些问题5. MOCO v2和MOCO v35.1…...

大数据Doris(三十八):Spark Load 导入Hive数据
文章目录 Spark Load 导入Hive数据 一、Spark Load导入Hive非分区表数据 1、在node3hive客户端,准备向Hive表加载的数据 2、启动Hive,在Hive客户端创建Hive表并加载数据 3、在Doris中创建Hive外部表 4、创建Doris表 5、创建Spark Load导入任务 6…...
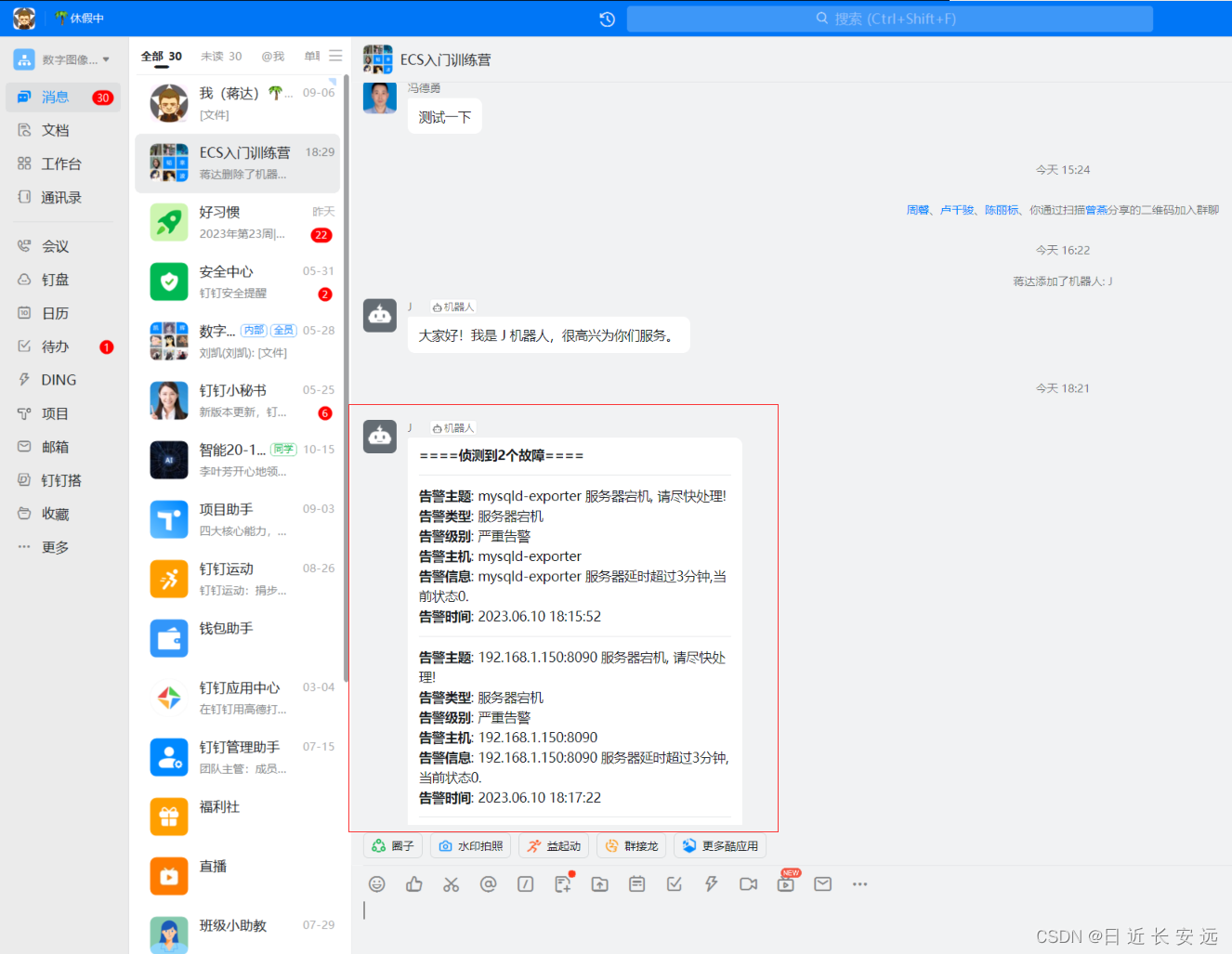
【Prometheus】mysqld_exporter采集+Grafana出图+AlertManager预警
前提环境:已经安装和配置好prometheus server 所有组件对应的版本: prometheus-2.44.0 mysqld_exporter-0.14.0 grafana-enterprise-9.1.2-1.x86_64.rpm alertmanager-0.25.0 prometheus-webhook-dingtalk-2.1.0 简介 mysql_exporter是用来收集MysQL或…...

softmax 函数
https://blog.csdn.net/m0_37769093/article/details/107732606 softmax 函数如下所示: y i exp ( x i ) ∑ j 1 n exp ( x j ) y_{i} \frac{\exp(x_{i})}{\sum_{j1}^{n}{\exp(x_j)}} yi∑j1nexp(xj)exp(xi) softmax求导如下: i j…...

CANN/ops-nn: 原位加法RMS归一化算子
InplaceAddRmsNorm 【免费下载链接】ops-nn 本项目是CANN提供的神经网络类计算算子库,实现网络在NPU上加速计算。 项目地址: https://gitcode.com/cann/ops-nn 产品支持情况 产品是否支持Ascend 950PR/Ascend 950DT√Atlas A3 训练系列产品/Atlas A3 推理系…...

CANN/asc-devkit ReduceProd API文档
ReduceProd 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://gitcode.com…...

AI应用安全实战:使用SecurityLayer构建防护中间件
1. 项目概述:一个为AI应用量身定制的安全防护层最近在折腾AI应用开发,特别是那些需要调用外部API或者处理敏感用户输入的场景,安全问题总是让人头疼。你辛辛苦苦搭了个智能客服,结果用户输入一串精心构造的恶意提示词,…...

为什么向量空间必须是“无限”的?
为什么向量空间必须是“无限”的? 为什么说运算结果总是在 V 中? 向量空间的定义本质上就是划定了一个“无论你怎么加、怎么乘,都逃不出这个圈子”的集合。那么为什么还分V,U 子集呢,这样讲来,不就是一个向量空间包括一切的意思吗? 当数学家说“地板是一个向量空间(子…...

基于储能系统参与电网一次调频的下垂控制仿真示例
目录 手把手教你学Simulink——基于储能系统参与电网一次调频的下垂控制仿真示例 一、 引言:当“新能源浪潮”遇见“频率崩塌”——储能如何化身电网的“速效救心丸”? 二、 问题本质:一次调频的“核心挑战”与“协同逻辑” 1. 核心挑战 …...

AI浪潮下光纤需求爆发,康宁如何从玻璃厂变身光纤之王?
AI光纤需求爆发,英伟达加速布局根据CRU,AI数据中心的光纤需求一年增长75.9%,供需缺口从6%撕开到15%,光纤价格更是在数月间涨超3倍。产能跟不上了,这就是为什么英伟达要投资康宁并加速光纤产能扩张。两个月前࿰…...

终极Notero使用指南:如何快速实现Zotero与Notion文献同步
终极Notero使用指南:如何快速实现Zotero与Notion文献同步 【免费下载链接】notero A Zotero plugin for syncing items and notes into Notion 项目地址: https://gitcode.com/gh_mirrors/no/notero 在学术研究和工作流管理中,我们常常面临一个共…...

AI教材编写工具实测:低查重效果显著,让教材生成更轻松!
教材编写的合规挑战与 AI 工具的解决方案 在教材编写的过程中,原创性与合规性之间的平衡是一个重要的问题。在借鉴优质教材内容的同时,创作者们往往担心查重率过高;而在尝试自主原创知识点时,又可能面临逻辑不严谨或内容不准确的…...

终极免费SQLite在线查看器:零安装、100%数据安全的浏览器解决方案
终极免费SQLite在线查看器:零安装、100%数据安全的浏览器解决方案 【免费下载链接】sqlite-viewer View SQLite file online 项目地址: https://gitcode.com/gh_mirrors/sq/sqlite-viewer 你是否曾为查看SQLite数据库文件而烦恼?传统数据库工具安…...
Translumo:让游戏外语对话秒变母语的神奇翻译助手
Translumo:让游戏外语对话秒变母语的神奇翻译助手 【免费下载链接】Translumo Advanced real-time screen translator for games, hardcoded subtitles in videos, static text and etc. 项目地址: https://gitcode.com/gh_mirrors/tr/Translumo 还在为看不懂…...