大数据Doris(三十八):Spark Load 导入Hive数据

文章目录
Spark Load 导入Hive数据
一、Spark Load导入Hive非分区表数据
1、在node3hive客户端,准备向Hive表加载的数据
2、启动Hive,在Hive客户端创建Hive表并加载数据
3、在Doris中创建Hive外部表
4、创建Doris表
5、创建Spark Load导入任务
6、Spark Load任务查看
7、查看Doris结果
二、Spark Load 导入Hive分区表数据
1、在node3 hive客户端,准备向Hive表加载的数据
2、创建Hive分区表并,加载数据
3、创建Doris分区表
4、创建Spark Load导入任务
5、Spark Load任务查看
6、查看Doris结果
Spark Load 导入Hive数据
一、Spark Load导入Hive非分区表数据
1、在node3hive客户端,准备向Hive表加载的数据
hive_data1.txt:
1,zs,18,100
2,ls,19,101
3,ww,20,102
4,ml,21,103
5,tq,22,1042、启动Hive,在Hive客户端创建Hive表并加载数据
#配置Hive 服务端$HIVE_HOME/conf/hive-site.xml
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
注意:此配置项为关闭metastore版本验证,避免在doris中读取hive外表时报错。#在node1节点启动hive metastore
[root@node1 ~]# hive --service metastore &#在node3节点进入hive客户端建表并加载数据
create table hive_tbl (id int,name string,age int,score int) row format delimited fields terminated by ',';load data local inpath '/root/hive_data1.txt' into table hive_tbl;#查看hive表中的数据
hive> select * from hive_tbl;
1 zs 18 100
2 ls 19 101
3 ww 20 102
4 ml 21 103
5 tq 22 104
3、在Doris中创建Hive外部表
使用Spark Load 将Hive非分区表中的数据导入到Doris中时,需要先在Doris中创建hive 外部表,然后通过Spark Load 加载这张外部表数据到Doris某张表中。
#Doris中创建Hive 外表
CREATE EXTERNAL TABLE example_db.hive_doris_tbl
(
id INT,
name varchar(255),
age INT,
score INT
)
ENGINE=hive
properties
(
"dfs.nameservices"="mycluster",
"dfs.ha.namenodes.mycluster"="node1,node2",
"dfs.namenode.rpc-address.mycluster.node1"="node1:8020",
"dfs.namenode.rpc-address.mycluster.node2"="node2:8020",
"dfs.client.failover.proxy.provider.mycluster" = "org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider",
"database" = "default",
"table" = "hive_tbl",
"hive.metastore.uris" = "thrift://node1:9083"
);
注意:
- 在Doris中创建Hive外表不会将数据存储到Doris中,查询hive外表数据时会读取HDFS中对应hive路径中的数据来展示,向hive表中插入数据时,doris中查询hive外表也能看到新增数据。
- 如果Hive表中是分区表,doris创建hive表将分区列看成普通列即可。
以上hive外表结果如下:
mysql> select * from hive_doris_tbl;
+------+------+------+-------+
| id | name | age | score |
+------+------+------+-------+
| 1 | zs | 18 | 100 |
| 2 | ls | 19 | 101 |
| 3 | ww | 20 | 102 |
| 4 | ml | 21 | 103 |
| 5 | tq | 22 | 104 |
+------+------+------+-------+
4、创建Doris表
#创建Doris表
create table spark_load_t2(
id int,
name varchar(255),
age int,
score double
)
ENGINE = olap
DUPLICATE KEY(id)
DISTRIBUTED BY HASH(`id`) BUCKETS 8;
5、创建Spark Load导入任务
创建Spark Load任务后,底层Spark Load转换成Spark任务进行数据导入处理时,需要连接Hive,所以需要保证在Spark node1-node3节点客户端中SPARK_HOME/conf/目录下有hive-site.xml配置文件,以便找到Hive ,另外,连接Hive时还需要MySQL 连接依赖包,所以需要在Yarn NodeManager各个节点保证$HADOOP_HOME/share/hadoop/yarn/lib路径下有mysql-connector-java-5.1.47.jar依赖包。
#把hive客户端hive-site.xml 分发到Spark 客户端(node1-node3)节点$SPARK_HOME/conf目录下
[root@node3 ~]# scp /software/hive-3.1.3/conf/hive-site.xml node1:/software/spark-2.3.1/conf/
[root@node3 ~]# scp /software/hive-3.1.3/conf/hive-site.xml node2:/software/spark-2.3.1/conf/
[root@node3 ~]# cp /software/hive-3.1.3/conf/hive-site.xml /software/spark-2.3.1/conf/#将mysql-connector-java-5.1.47.jar依赖分发到NodeManager 各个节点$HADOOP_HOME/share/hadoop/yarn/lib路径中
[root@node3 ~]# cp /software/hive-3.1.3/lib/mysql-connector-java-5.1.47.jar /software/hadoop-3.3.3/share/hadoop/yarn/lib/
[root@node3 ~]# scp /software/hive-3.1.3/lib/mysql-connector-java-5.1.47.jar node4:/software/hadoop-3.3.3/share/hadoop/yarn/lib/
[root@node3 ~]# scp /software/hive-3.1.3/lib/mysql-connector-java-5.1.47.jar node5:/software/hadoop-3.3.3/share/hadoop/yarn/lib/
编写Spark Load任务,如下:
LOAD LABEL example_db.label2
(
DATA FROM TABLE hive_doris_tbl
INTO TABLE spark_load_t2
)
WITH RESOURCE 'spark1'
(
"spark.executor.memory" = "1g",
"spark.shuffle.compress" = "true"
)
PROPERTIES
(
"timeout" = "3600"
);
6、Spark Load任务查看
登录Yarn Web UI查看对应任务执行情况:

执行命令查看Spark Load 任务执行情况:
mysql> show load order by createtime desc limit 1\G;
*************************** 1. row ***************************JobId: 37128Label: label2State: FINISHEDProgress: ETL:100%; LOAD:100%Type: SPARKEtlInfo: unselected.rows=0; dpp.abnorm.ALL=0; dpp.norm.ALL=0TaskInfo: cluster:spark1; timeout(s):3600; max_filter_ratio:0.0ErrorMsg: NULLCreateTime: 2023-03-10 18:13:19EtlStartTime: 2023-03-10 18:13:34EtlFinishTime: 2023-03-10 18:15:27LoadStartTime: 2023-03-10 18:15:27
LoadFinishTime: 2023-03-10 18:15:30URL: http://node1:8088/proxy/application_1678424784452_0007/JobDetails: {"Unfinished backends":{"0-0":[]},"ScannedRows":0,"TaskNumber":1,"LoadBytes":0,"All backends":{"0-0":[-1]},"FileNumber":0,"FileSi
ze":0} TransactionId: 24081ErrorTablets: {}
1 row in set (0.00 sec)
7、查看Doris结果
mysql> select * from spark_load_t2;
+------+------+------+-------+
| id | name | age | score |
+------+------+------+-------+
| 5 | tq | 22 | 104 |
| 4 | ml | 21 | 103 |
| 1 | zs | 18 | 100 |
| 3 | ww | 20 | 102 |
| 2 | ls | 19 | 101 |
+------+------+------+-------+
二、Spark Load 导入Hive分区表数据
导入Hive分区表数据到对应的doris分区表就不能在doris中创建hive外表这种方式导入,因为hive分区列在hive外表中就是普通列,所以这里我们使用Spark Load 直接读取Hive分区表在HDFS中的路径,将数据加载到Doris分区表中。
1、在node3 hive客户端,准备向Hive表加载的数据
hive_data2.txt:
1,zs,18,100,2023-03-01
2,ls,19,200,2023-03-01
3,ww,20,300,2023-03-02
4,ml,21,400,2023-03-02
5,tq,22,500,2023-03-02
2、创建Hive分区表并,加载数据
#在node3节点进入hive客户端建表并加载数据
create table hive_tbl2 (id int, name string,age int,score int) partitioned by (dt string) row format delimited fields terminated by ','load data local inpath '/root/hive_data2.txt' into table hive_tbl2;#查看hive表中的数据
hive> select * from hive_tbl2;
OK
1 zs 18 100 2023-03-01
2 ls 19 200 2023-03-01
3 ww 20 300 2023-03-02
4 ml 21 400 2023-03-02
5 tq 22 500 2023-03-02hive> show partitions hive_tbl2;
OK
dt=2023-03-01
dt=2023-03-02
当hive_tbl2表创建完成后,我们可以在HDFS中看到其存储路径格式如下:


3、创建Doris分区表
create table spark_load_t3(
dt date,
id int,
name varchar(255),
age int,
score double
)
ENGINE = olap
DUPLICATE KEY(dt,id)
PARTITION BY RANGE(`dt`)
(
PARTITION `p1` VALUES [("2023-03-01"),("2023-03-02")),
PARTITION `p2` VALUES [("2023-03-02"),("2023-03-03"))
)
DISTRIBUTED BY HASH(`id`) BUCKETS 8;
4、创建Spark Load导入任务
创建Spark Load任务后,底层Spark Load转换成Spark任务进行数据导入处理时,需要连接Hive,所以需要保证在Spark node1-node3节点客户端中SPARK_HOME/conf/目录下有hive-site.xml配置文件,以便找到Hive ,另外,连接Hive时还需要MySQL 连接依赖包,所以需要在Yarn NodeManager各个节点保证HADOOP_HOME/share/hadoop/yarn/lib路径下有mysql-connector-java-5.1.47.jar依赖包。
#把hive客户端hive-site.xml 分发到Spark 客户端(node1-node3)节点$SPARK_HOME/conf目录下
[root@node3 ~]# scp /software/hive-3.1.3/conf/hive-site.xml node1:/software/spark-2.3.1/conf/
[root@node3 ~]# scp /software/hive-3.1.3/conf/hive-site.xml node2:/software/spark-2.3.1/conf/
[root@node3 ~]# cp /software/hive-3.1.3/conf/hive-site.xml /software/spark-2.3.1/conf/#将mysql-connector-java-5.1.47.jar依赖分发到NodeManager 各个节点$HADOOP_HOME/share/hadoop/yarn/lib路径中
[root@node3 ~]# cp /software/hive-3.1.3/lib/mysql-connector-java-5.1.47.jar /software/hadoop-3.3.3/share/hadoop/yarn/lib/
[root@node3 ~]# scp /software/hive-3.1.3/lib/mysql-connector-java-5.1.47.jar node4:/software/hadoop-3.3.3/share/hadoop/yarn/lib/
[root@node3 ~]# scp /software/hive-3.1.3/lib/mysql-connector-java-5.1.47.jar node5:/software/hadoop-3.3.3/share/hadoop/yarn/lib/
编写Spark Load任务,如下:
LOAD LABEL example_db.label3
(
DATA INFILE("hdfs://node1:8020/user/hive/warehouse/hive_tbl2/dt=2023-03-02/*")
INTO TABLE spark_load_t3
COLUMNS TERMINATED BY ","
FORMAT AS "csv"
(id,name,age,score)
COLUMNS FROM PATH AS (dt)
SET
(
dt=dt,
id=id,
name=name,
age=age
)
)
WITH RESOURCE 'spark1'
(
"spark.executor.memory" = "1g",
"spark.shuffle.compress" = "true"
)
PROPERTIES
(
"timeout" = "3600"
);
注意:
- 以上HDFS路径不支持HA模式,需要手动指定Active NameNode节点
- 读取HDFS文件路径中的分区路径需要写出来,不能使用*代表,这与Broker Load不同。
- 目前版本测试存在问题:当Data INFILE中指定多个路径时有时会出现只导入第一个路径数据。
5、Spark Load任务查看
执行命令查看Spark Load 任务执行情况:
mysql> show load order by createtime desc limit 1\G;
*************************** 1. row ***************************JobId: 39432Label: label3State: FINISHEDProgress: ETL:100%; LOAD:100%Type: SPARKEtlInfo: unselected.rows=0; dpp.abnorm.ALL=0; dpp.norm.ALL=3TaskInfo: cluster:spark1; timeout(s):3600; max_filter_ratio:0.0ErrorMsg: NULLCreateTime: 2023-03-10 20:11:19EtlStartTime: 2023-03-10 20:11:36EtlFinishTime: 2023-03-10 20:12:21LoadStartTime: 2023-03-10 20:12:21
LoadFinishTime: 2023-03-10 20:12:22URL: http://node1:8088/proxy/application_1678443952851_0026/JobDetails: {"Unfinished backends":{"0-0":[]},"ScannedRows":3,"TaskNumber":1,"LoadBytes":0,"All backends":{"0-0":[-1]},"FileNumber":2,"FileSi
ze":60} TransactionId: 25529ErrorTablets: {}
1 row in set (0.02 sec)
6、查看Doris结果
mysql> select * from spark_load_t3;
+------------+------+------+------+-------+
| dt | id | name | age | score |
+------------+------+------+------+-------+
| 2023-03-02 | 3 | ww | 20 | 300 |
| 2023-03-02 | 4 | ml | 21 | 400 |
| 2023-03-02 | 5 | tq | 22 | 500 |
+------------+------+------+------+-------+
- 📢博客主页:https://lansonli.blog.csdn.net
- 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!
- 📢本文由 Lansonli 原创,首发于 CSDN博客🙉
- 📢停下休息的时候不要忘了别人还在奔跑,希望大家抓紧时间学习,全力奔赴更美好的生活✨
相关文章:
大数据Doris(三十八):Spark Load 导入Hive数据
文章目录 Spark Load 导入Hive数据 一、Spark Load导入Hive非分区表数据 1、在node3hive客户端,准备向Hive表加载的数据 2、启动Hive,在Hive客户端创建Hive表并加载数据 3、在Doris中创建Hive外部表 4、创建Doris表 5、创建Spark Load导入任务 6…...
【Prometheus】mysqld_exporter采集+Grafana出图+AlertManager预警
前提环境:已经安装和配置好prometheus server 所有组件对应的版本: prometheus-2.44.0 mysqld_exporter-0.14.0 grafana-enterprise-9.1.2-1.x86_64.rpm alertmanager-0.25.0 prometheus-webhook-dingtalk-2.1.0 简介 mysql_exporter是用来收集MysQL或…...

softmax 函数
https://blog.csdn.net/m0_37769093/article/details/107732606 softmax 函数如下所示: y i exp ( x i ) ∑ j 1 n exp ( x j ) y_{i} \frac{\exp(x_{i})}{\sum_{j1}^{n}{\exp(x_j)}} yi∑j1nexp(xj)exp(xi) softmax求导如下: i j…...

【SpringMVC】拦截器和过滤器之间的区别
过滤器 拦截器 调用机制 基于函数的回调 基于反射机制(动态代理) 依赖关系 依赖Servlet容器 不依赖Servlet容器 作用范围 对几乎所有的请求起作用 只对action请求起作用 访问范围 不能访问action上下文、栈 可以访问action上下文、栈 action生命周期 中的调用次数…...
springboot第25集:实体类定义规则
PO:持久化对象,一个PO对象对应一张表里面的一条记录。全部对应 VO:View视图对象,用来在页面中展示数据的,页面需要哪些字段属性就添加哪些,查询出来之后赋值操作比PO对象要简单。所以提高性能。 DTO&#x…...

【python】—— python的基本介绍并附安装教程
前言: 今天,我将给大家讲解关于python的基本知识,让大家对其有个基本的认识并且附上相应的安装教程以供大家参考。接下来,我们正式进入今天的文章!!! 目录 前言 (一)P…...

浏览器跨域请求
跨域是浏览器的一种同源策略,所以该概念只存在于通过浏览器访问服务里。 如果缺少了同源策略,则浏览器的正常功能可能都会受到影响。可以说Web是构建在同源策略基础之上的,浏览器只是针对同源策略的一种实现 请求的url地址,必须与浏览器上的…...
什么,你还在用 momentJs 处理相对时间
我想,下面这段代码,你是不是在开发中常常这样使用来计算距离现在过去了多长时间: import moment from moment // 61k (gzipped:19.k) function Relative(props) {const timeString moment(props.date).fromNow()return <>{timeString…...

三维模型 工程图
飞机 Crankshaft飞机发动机手动冲压机包装成型机械-充填机械设备10数控等离子切割机床铜线缠绕机机床-磨床08机床-磨床04(附工程图)机床-车床数字纤维缠绕机机械臂液压钳机床-车床06挤出机机械手-09机械手模型库六柴油发动机中央空调机柜空调机机床-钻床三维设计电脑服务器机箱…...
:全国乙卷)
我用ChatGPT写2023高考语文作文(二):全国乙卷
2023年 全国乙卷 适用地区:河南、江西、甘肃、青海、内蒙古、宁夏、新疆、陕西 吹灭别人的灯,并不会让自己更加光明;阻挡别人的路,也不会让自己行得更远。 “一花独放不是春,百花齐放春满园。”如果世界上只有一种花朵…...

java版本工程项目管理系统平台源码,助力工程企业实现数字化管理
鸿鹄工程项目管理系统 Spring CloudSpring BootMybatisVueElementUI前后端分离构建工程项目管理系统 1. 项目背景 一、随着公司的快速发展,企业人员和经营规模不断壮大。为了提高工程管理效率、减轻劳动强度、提高信息处理速度和准确性,公司对内部工程管…...

代码随想录第55天
1.判断子序列: 动态规划五部曲分析如下: 确定dp数组(dp table)以及下标的含义 dp[i][j] 表示以下标i-1为结尾的字符串s,和以下标j-1为结尾的字符串t,相同子序列的长度为dp[i][j]。 注意这里是判断s是否…...
)
算法设计与分析(填空专题)
文章目录 填空题填空题 设有一稀疏图 G,则 G 采用 邻接表 存储较省空间。 算法的时间复杂性是指算法中 元运算 执行次数。 分治法的基本思想是将一个规模为 n 的问题分解为与原问题 相同 的 k 个规模较小且互相独立的子问题。 贪心算法中每次做出的贪心选择都是 当前的 最优选…...

Ubuntu22.04 K8s1.27.2
Ubuntu22.04 && K8s1.27.2 1. 服务器配置 IpServerMEM192.168.56.11k8smaster6G192.168.56.16k8snode14G192.168.56.17k8snode24G 2. 获取源 $ sudo apt-get update $ sudo apt-get install -y apt-transport-https ca-certificates curl# packages.cloud.google.c…...
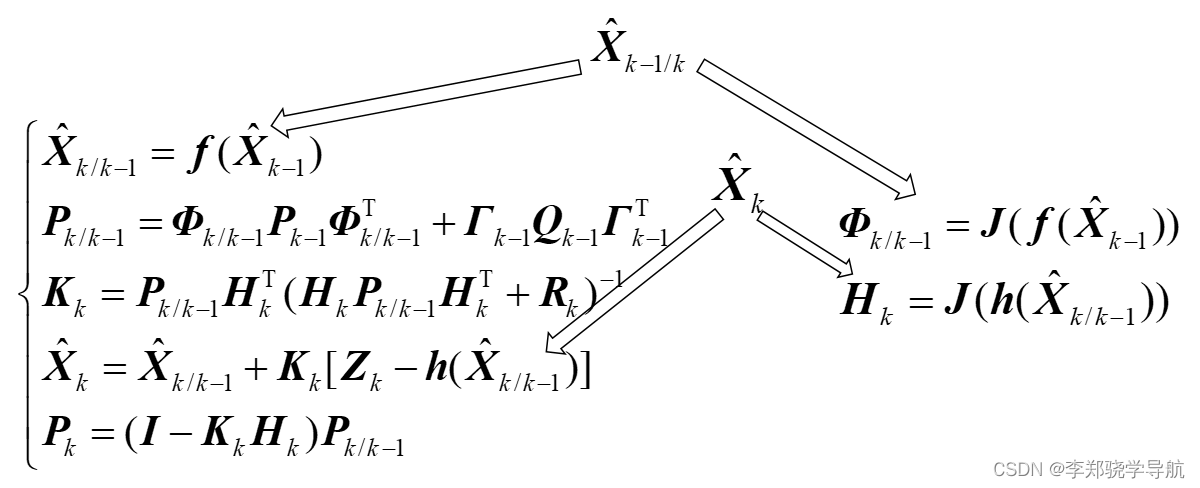
卡尔曼滤波与组合导航原理(十二)扩展卡尔曼滤波:EKF、二阶EKF、迭代EKF
文章目录 一、多元向量的泰勒级数展开二、扩展Kalman滤波三、二阶滤波四、迭代EKF滤波 一、多元向量的泰勒级数展开 { y 1 f 1 ( X ) f 1 ( x 1 , x 2 , ⋯ x n ) y 2 f 2 ( X ) f 2 ( x 1 , x 2 , ⋯ x n ) ⋮ y m f m ( X ) f m ( x 1 , x 2 , ⋯ x n ) \left\{\begin{…...
基于蒙特卡洛模拟法的电动汽车充电负荷研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...
自学黑客【网络安全】,一般人我劝你还是算了吧
一、自学网络安全学习的误区和陷阱 1.不要试图先成为一名程序员(以编程为基础的学习)再开始学习 我在之前的回答中,我都一再强调不要以编程为基础再开始学习网络安全,一般来说,学习编程不但学习周期长,而…...

编程中的心理策略:如何从错误中学习并实现自我成长
在日复一日的工作中,我们免不了会产生一些失误,会因此感到沮丧和失望。但如何正确地对待和处理这些失误才是最重要的,它直接影响到我们的工作表现和个人成长。 一、面对失误而带来的指责和沮丧的策略 在程序设计领域,我们经常面临…...
Rocket面试(五)Rocketmq发生流量控制的情况有哪些?
在使用rocketmq过程中总能看见一下异常 [TIMEOUT_CLEAN_QUEUE]broker busy, start flow control for a while, period in queue: 206ms, size of queue: 5这是因为Rocketmq出发了流量控制。 触发流量控制就是为了防止Broker压力过大挂掉。主要分为Broker流控,Consu…...

Tableau招聘信息数据可视化
获取的招聘信息数据为某招聘网站发布的大数据及数据分析相关岗位,对其他计算机相关岗位的招聘信息数据分析也有一定的参考价值。因为所获取的招聘信息数据数量只有1万左右,实际的招聘信息数量肯定不止1万,所以可能会与实际信息有一定的误差。…...
为你的五子棋项目加个‘智能大脑’)
从AlphaGo到你的小游戏:如何用MCTS(蒙特卡洛树搜索)为你的五子棋项目加个‘智能大脑’
从AlphaGo到你的小游戏:如何用MCTS为五子棋项目构建智能决策引擎 当你在手机上下棋输给AI时,是否好奇过这些"电子大脑"如何思考?2016年AlphaGo击败李世石的关键技术之一——蒙特卡洛树搜索(MCTS),…...

如何彻底解决Minecraft离线启动限制:PrismLauncher-Cracked完全指南
如何彻底解决Minecraft离线启动限制:PrismLauncher-Cracked完全指南 【免费下载链接】PrismLauncher-Cracked This project is a Fork of Prism Launcher, which aims to unblock the use of Offline Accounts, disabling the restriction of having a functional O…...

从零到一:使用DaVinci Developer进行AUTOSAR SWC设计与ECU集成
1. 认识AUTOSAR与DaVinci Developer工具 第一次接触汽车电子开发的朋友,可能会被AUTOSAR这个术语吓到。其实它就像汽车软件界的"普通话"——各家厂商用统一的标准交流,避免出现"鸡同鸭讲"的情况。而DaVinci Developer就是Vector公司…...

从原型到优化:基于LoRa SX1278与STM32的音频对讲系统实战剖析
1. 项目背景与原型机搭建 记得第一次用STM32F103C8T6驱动LoRa SX1278模块时,手边只有个简易麦克风模块和杜邦线。当时就想做个能传语音的无线对讲系统,没想到后来踩了这么多坑。这个项目最核心的三部分就是ADC采集声音、SPEEX压缩音频、LoRa传输数据&am…...

从2012年ACE奖看电子产业创新:Zynq、CMOS振荡器与混合域示波器的启示
1. 从一场颁奖礼,看电子产业的创新脉搏前几天翻看资料库,又看到了2012年那场UBM ACE颁奖典礼的旧闻。说实话,每次回顾这种历史性的行业奖项,感觉都像在翻阅一本电子产业的“创新年鉴”。那一年,Xilinx的Zynq-7000、NXP…...
)
想让你的Linux终端也下起‘代码雨’?手把手教你安装配置cmatrix屏保(CentOS/Ubuntu双系统保姆级教程)
让你的Linux终端下起"代码雨":cmatrix屏保终极玩法指南 第一次在《黑客帝国》里看到绿色字符如瀑布般倾泻而下的场景时,那种科技感与未来感是否让你心驰神往?现在,你完全可以在自己的Linux终端里复刻这一经典画面。cmat…...

基于Intelli框架构建智能体应用:从核心原理到电商客服实战
1. 项目概述:从“智能节点”到“智能体”的进化 最近在开源社区里,一个名为 intelligentnode/Intelli 的项目引起了我的注意。乍一看这个名字,你可能会和我最初一样,把它理解为一个“智能节点”框架。但深入探究其代码仓库和设计…...

教育云平台数据泄露与网络钓鱼风险防控研究—— 基于牛津大学 Canvas 安全事件的分析
摘要 教育数字化转型背景下,云学习管理平台的数据安全与风险防控已成为全球高校共同面临的挑战。2026 年 5 月,全球主流教育云平台 Canvas 发生大规模未授权访问事件,牛津大学等多所高校用户数据遭泄露,核心风险直指数据泄露后的…...

凌晨还在改论文?这些降重黑科技帮你一键通关
凌晨对着电脑屏幕改论文,那种既疲惫又焦虑的感觉,经历过的人都懂。好在现在的降重工具已经不只是“替换同义词”那么简单了,像 毕业之家 和 PaperRed 这两款主流工具,各自走了完全不同的技术路线,可以根据你的痛点来选…...

AI Agent Harness Engineering 未来生态:开源 vs 闭源的竞争与合作格局
AI Agent Harness Engineering 未来生态:开源 vs 闭源的竞争与合作格局 引言:AI Agent不是终点,Harness才是通用智能落地的核心阀门 1.1 从“AI大模型(LLM)元年”到“AI Agent生态元年”:技术拐点的悄然发…...