Mybatis之批处理流式查询
文章目录
- 1 批处理查询
- 1.1 引言
- 1.2 流式查询
- 1.2.1 定义
- 1.2.2 流式查询接口
- 1.2.3 使用流式查询关闭问题
- 1.2.3.1 SqlSessionFactory
- 1.2.3.2 TransactionTemplate
- 1.2.3.3 @Transactional 注解
- 1.2.4 完整示例
- 1.2.4.1 mapper接口和SQL
- 1.2.4.2 Service操作
- 1.3 游标查询
- 1.3.1 定义
- 1.3.2 注解查询
- 1.3.3 XML查询
- 1.3.3.1 示例
1 批处理查询
1.1 引言
动态数据导出是一般项目都会涉及到的功能。它的基本实现逻辑就是从mysql查询数据,加载到内存,然后从内存创建 excel 或者 csv ,以流的形式响应给前端。但是全量加载不可行,那我们的目标就是如何实现数据的分批加载了。实事上,Mysql本身支持 Stream 查询,我们可以通过Stream流获取数据,然后将数据逐条刷入到文件中,每次刷入文件后再从内存中移除这条数据,从而避免OOM。
由于采用了数据逐条刷入文件,而且数据量达到百万级,所以文件格式就不要采用 excel 了,excel2007最大才支持104万行的数据。这里推荐,以csv代替excel
1.2 流式查询
1.2.1 定义
流式查询 指的是查询成功后不是返回一个集合而是返回一个迭代器,应用每次从迭代器取一条查询结果。流式查询的好处是能够降低内存使用。
如果没有流式查询,我们想要从数据库取 1000 万条记录而又没有足够的内存时,就不得不分页查询,而分页查询效率取决于表设计,如果设计的不好,就无法执行高效的分页查询。因此流式查询是一个数据库访问框架必须具备的功能。
MyBatis 中使用流式查询避免数据量过大导致 OOM ,但在流式查询的过程当中,数据库连接是保持打开状态的,因此要注意的是:
- 执行一个流式查询后,数据库访问框架就不负责关闭数据库连接了,需要应用在取完数据后自己关闭。
- 必须先读取(或关闭)结果集中的所有行,然后才能对连接发出任何其他查询,否则将引发异常。
为什么要用流式查询?
如果有一个很大的查询结果需要遍历处理,又不想一次性将结果集装入客户端内存,就可以考虑使用流式查询;
分库分表场景下,单个表的查询结果集虽然不大,但如果某个查询跨了多个库多个表,又要做结果集的合并、排序等动作,依然有可能撑爆内存;详细研究了sharding-sphere的代码不难发现,除了group by与order by字段不一样之外,其他的场景都非常适合使用流式查询,可以最大限度的降低对客户端内存的消耗。
1.2.2 流式查询接口
MyBatis 提供了一个叫 org.apache.ibatis.cursor.Cursor 的接口类用于流式查询,这个接口继承了 java.io.Closeable 和 java.lang.Iterable 接口,由此可知:
Cursor 是可关闭的;Cursor 是可遍历的。
除此之外,Cursor 还提供了三个方法:
isOpen(): 用于在取数据之前判断Cursor对象是否是打开状态。只有当打开时 Cursor 才能取数据;isConsumed(): 用于判断查询结果是否全部取完。getCurrentIndex(): 返回已经获取了多少条数据
使用流式查询,则要保持对产生结果集的语句所引用的表的并发访问,因为其查询会独占连接,所以必须尽快处理
1.2.3 使用流式查询关闭问题
我们举个实际例子。下面是一个 Mapper 类:
@Mapper
public interface FooMapper {@Select("select * from foo limit #{limit}")Cursor<Foo> scan(@Param("limit") int limit);
}
方法 scan() 是一个非常简单的查询。通过指定 Mapper 方法的返回值为 Cursor 类型,MyBatis 就知道这个查询方法一个流式查询。
然后我们再写一个 SpringMVC Controller 方法来调用 Mapper(无关的代码已经省略):
@GetMapping("foo/scan/0/{limit}")
public void scanFoo0(@PathVariable("limit") int limit) throws Exception {try (Cursor<Foo> cursor = fooMapper.scan(limit)) { // 1cursor.forEach(foo -> {}); // 2}
}
上面的代码中,fooMapper 是 @Autowired 进来的。注释 1 处调用 scan 方法,得到 Cursor 对象并保证它能最后关闭;2 处则是从 cursor 中取数据。
上面的代码看上去没什么问题,但是执行 scanFoo0() 时会报错:
java.lang.IllegalStateException: A Cursor is already closed.
这是因为我们前面说了在取数据的过程中需要保持数据库连接,而 Mapper 方法通常在执行完后连接就关闭了,因此 Cusor 也一并关闭了。
1.2.3.1 SqlSessionFactory
我们可以用 SqlSessionFactory 来手工打开数据库连接,将 Controller 方法修改如下:
@Autowired
private SqlSessionFactory sqlSessionFactory;
@GetMapping("foo/scan/1/{limit}")
public void scanFoo1(@PathVariable("limit") int limit) throws Exception {try (SqlSession sqlSession = sqlSessionFactory.openSession(); // 1Cursor<Foo> cursor =sqlSession.getMapper(FooMapper.class).scan(limit) // 2) {cursor.forEach(foo -> { });}
}
上面的代码中,1 处我们开启了一个 SqlSession (实际上也代表了一个数据库连接),并保证它最后能关闭;2 处我们使用 SqlSession 来获得 Mapper 对象。这样才能保证得到的 Cursor 对象是打开状态的。
1.2.3.2 TransactionTemplate
在 Spring 中,我们可以用 TransactionTemplate 来执行一个数据库事务,这个过程中数据库连接同样是打开的。代码如下:
@GetMapping("foo/scan/2/{limit}")
public void scanFoo2(@PathVariable("limit") int limit) throws Exception {TransactionTemplate transactionTemplate =new TransactionTemplate(transactionManager); // 1transactionTemplate.execute(status -> { // 2try (Cursor<Foo> cursor = fooMapper.scan(limit)) {cursor.forEach(foo -> { });} catch (IOException e) {e.printStackTrace();}return null;});
}
上面的代码中,1 处我们创建了一个 TransactionTemplate 对象,2 处执行数据库事务,而数据库事务的内容则是调用 Mapper 对象的流式查询。注意这里的 Mapper 对象无需通过 SqlSession 创建。
1.2.3.3 @Transactional 注解
这个本质上和方案二一样,代码如下:
@GetMapping("foo/scan/3/{limit}")
@Transactional
public void scanFoo3(@PathVariable("limit") int limit) throws Exception {try (Cursor<Foo> cursor = fooMapper.scan(limit)) {cursor.forEach(foo -> { });}
}
它仅仅是在原来方法上面加了个 @Transactional 注解。这个方案看上去最简洁,但请注意 Spring 框架当中注解使用的坑:只在外部调用时生效 。在当前类中调用这个方法,依旧会报错。
点击此处了解Spring事务
1.2.4 完整示例
mybatis的所谓流式查询,就是服务端程序查询数据的过程中,与远程数据库一直保持连接,不断的去数据库拉取数据,提交事务并关闭sqlsession后,数据库连接断开,停止数据拉取,需要注意的是使用这种方式,需要自己手动维护sqlsession和事务的提交。
实现方式很简单,原来返回的类型是集合或对象,流式查询返回的的类型Curor,泛型内表示实际的类型,其他没有变化;
1.2.4.1 mapper接口和SQL
@Mapper
public interface PersonDao {Cursor<Person> selectByCursor();Integer queryCount();}
对应SQL文件
<select id="selectByCursor" resultMap="personMap">select * from sys_person order by id desc
</select>
<select id="queryCount" resultType="java.lang.Integer">select count(*) from sys_person
</select>
1.2.4.2 Service操作
dao层向service层返回的是Cursor类型对象,只要不提交关闭sqlsession,服务端程序就可以一直从数据数据库读取数据,直到查询sql匹配到数据全部读取完;
示例里的主要业务逻辑是:从sys_person表中读取所有的人员信息数据,然后按照每1000条数据为一组,读取到内存里进行处理,以此类推,直到查询sql匹配到数据全部处理完,再提交事务,关闭sqlSession;
@Service
@Slf4j
public class PersonServiceImpl implements IPersonService {@Autowiredprivate SqlSessionFactory sqlSessionFactory;@Overridepublic void getOneByAsync() throws InterruptedException {new Thread(new Runnable() {@SneakyThrows@Overridepublic void run() {//使用sqlSessionFactory打开一个sqlSession,在没有读取完数据之前不要提交事务或关闭sqlSessionlog.info("----开启sqlSession");SqlSession sqlSession = sqlSessionFactory.openSession();try {//获取到指定mapperPersonDao mapper = sqlSession.getMapper(PersonDao.class);//调用指定mapper的方法,返回一个cursorCursor<Person> cursor = mapper.selectByCursor();//查询数据总量Integer total = mapper.queryCount();//定义一个list,用来从cursor中读取数据,每读取够1000条的时候,开始处理这批数据;//当前批数据处理完之后,清空list,准备接收下一批次数据;直到大量的数据全部处理完;List<Person> personList = new ArrayList<>();int i = 0;if (cursor != null) {for (Person person : cursor) {if (personList.size() < 1000) {
// log.info("----id:{},userName:{}", person.getId(), person.getUserName());personList.add(person);} else if (personList.size() == 1000) {++i;log.info("----{}、从cursor取数据达到1000条,开始处理数据", i);log.info("----处理数据中...");Thread.sleep(1000);//休眠1s模拟处理数据需要消耗的时间;log.info("----{}、从cursor中取出的1000条数据已经处理完毕", i);personList.clear();personList.add(person);}if (total == (cursor.getCurrentIndex() + 1)) {++i;log.info("----{}、从cursor取数据达到1000条,开始处理数据", i);log.info("----处理数据中...");Thread.sleep(1000);//休眠1s模拟处理数据需要消耗的时间;log.info("----{}、从cursor中取出的1000条数据已经处理完毕", i);personList.clear();}}if (cursor.isConsumed()) {log.info("----查询sql匹配中的数据已经消费完毕!");}}sqlSession.commit();log.info("----提交事务");}catch (Exception e){e.printStackTrace();sqlSession.rollback();}finally {if (sqlSession != null) {//全部数据读取并且做好其他业务操作之后,提交事务并关闭连接;sqlSession.close();log.info("----关闭sqlSession"); }}}}).start();}
}
1.3 游标查询
1.3.1 定义
对大量数据进行处理时,为防止内存泄漏情况发生,也可以采用游标方式进行数据查询处理。
当查询百万级的数据的时候,还可以使用游标方式进行数据查询处理,不仅可以节省内存的消耗,而且还不需要一次性取出所有数据,可以进行逐条处理或逐条取出部分批量处理。一次查询指定 fetchSize 的数据,直到把数据全部处理完。
1.3.2 注解查询
Mybatis 的处理加了两个注解:@Options 和 @ResultType
@Mapper
public interface BigDataSearchMapper extends BaseMapper<BigDataSearchEntity> {// 方式一 多次获取,一次多行@Select("SELECT bds.* FROM big_data_search bds ${ew.customSqlSegment} ")@Options(resultSetType = ResultSetType.FORWARD_ONLY, fetchSize = 1000000)Page<BigDataSearchEntity> pageList(@Param("page") Page<BigDataSearchEntity> page, @Param(Constants.WRAPPER) QueryWrapper<BigDataSearchEntity> queryWrapper);// 方式二 一次获取,一次一行@Select("SELECT bds.* FROM big_data_search bds ${ew.customSqlSegment} ")@Options(resultSetType = ResultSetType.FORWARD_ONLY, fetchSize = 100000)@ResultType(BigDataSearchEntity.class)void listData(@Param(Constants.WRAPPER) QueryWrapper<BigDataSearchEntity> queryWrapper, ResultHandler<BigDataSearchEntity> handler);}
@Options:
ResultSet.FORWORD_ONLY:结果集的游标只能向下滚动
ResultSet.SCROLL_INSENSITIVE:结果集的游标可以上下移动,当数据库变化时,当前结果集不变
ResultSet.SCROLL_SENSITIVE:返回可滚动的结果集,当数据库变化时,当前结果集同步改变
fetchSize:每次获取量@ResultType:
@ResultType(BigDataSearchEntity.class):转换成返回实体类型
注意:返回类型必须为 void ,因为查询的结果在 ResultHandler 里处理数据,所以这个 hander 也是必须的,可以使用 lambda 实现一个依次处理逻辑。
注意:虽然上面的代码中都有 @Options 但实际操作却有不同:
方式一是多次查询,一次返回多条;
方式二是一次查询,一次返回一条;
原因:
Oracle 是从服务器一次取出 fetch size 条记录放在客户端,客户端处理完成一个批次后再向服务器取下一个批次,直到所有数据处理完成。
MySQL 是在执行 ResultSet.next() 方法时,会通过数据库连接一条一条的返回。flush buffer 的过程是阻塞式的,如果网络中发生了拥塞,send buffer 被填满,会导致 buffer 一直 flush 不出去,那 MySQL 的处理线程会阻塞,从而避免数据把客户端内存撑爆。
1.3.3 XML查询
MyBatis实现逐条获取数据,必须要自定义ResultHandler,然后在mapper.xml文件中,对应的select语句中添加 fetchSize="-2147483648"或者Integer.MIN_VALUE。最后将自定义的ResultHandler传给SqlSession来执行查询,并将返回的结果进行处理。
注意:
fetchSize设为-2147483648(Integer.MIN_VALUE) 一开始希望或许fetchSize能够自己指定一次从服务器端获取的数据量;发现修改fetchSize的值并没有差别;结果是MYSQL并不支持自定义fetchSize,由于其他大型数据库(oracl db2)是支持的;mysql使用服务器端游标只能一条一条取数据。
如果接口方法参数没有声明回调函数 ResultHandler ,声明 fetchSize 也是没有任何作用的,依然会返回完整结果集
1.3.3.1 示例
以下是基于MyBatis Stream导出的完整的工程样例,我们将通过对比Stream文件导出和传统方式导出的内存占用率的差异,来验证Stream文件导出的有效性。
我们先定义一个工具类DownloadProcessor,它内部封装一个HttpServletResponse对象,用来将对象写入到csv。
public class DownloadProcessor {private final HttpServletResponse response;public DownloadProcessor(HttpServletResponse response) {this.response = response;String fileName = System.currentTimeMillis() + ".csv";this.response.addHeader("Content-Type", "application/csv");this.response.addHeader("Content-Disposition", "attachment; filename="+fileName);this.response.setCharacterEncoding("UTF-8");}public <E> void processData(E record) {try {response.getWriter().write(record.toString()); //如果是要写入csv,需要重写toString,属性通过","分割response.getWriter().write("\n");}catch (IOException e){e.printStackTrace();}}
}
然后通过实现 org.apache.ibatis.session.ResultHandler,自定义我们的ResultHandler,它用于获取java对象,然后传递给上面的DownloadProcessor处理类进行写文件操作:
public class CustomResultHandler implements ResultHandler {private final DownloadProcessor downloadProcessor;public CustomResultHandler(DownloadProcessor downloadProcessor) {super();this.downloadProcessor = downloadProcessor;}@Overridepublic void handleResult(ResultContext resultContext) {Authors authors = (Authors)resultContext.getResultObject();downloadProcessor.processData(authors);}
}
实体类:
@Data
public class Authors {private Integer id;private String firstName;private String lastName;private String email;private Date birthdate;private Date added;}
Mapper接口:public interface AuthorsMapper {List<Authors> selectByExample(AuthorsExample example);List<Authors> streamByExample(AuthorsExample example); //以stream形式从mysql获取数据
}
Mapper xml文件核心片段,以下两条select的唯一差异就是在stream获取数据的方式中多了一条属性:fetchSize=“-2147483648”
<select id="selectByExample" parameterType="com.alphathur.mysqlstreamingexport.domain.AuthorsExample" resultMap="BaseResultMap">select<if test="distinct">distinct</if>'false' as QUERYID,<include refid="Base_Column_List" />from authors<if test="_parameter != null"><include refid="Example_Where_Clause" /></if><if test="orderByClause != null">order by ${orderByClause}</if></select><select id="streamByExample" fetchSize="-2147483648" parameterType="com.alphathur.mysqlstreamingexport.domain.AuthorsExample" resultMap="BaseResultMap">select<if test="distinct">distinct</if>'false' as QUERYID,<include refid="Base_Column_List" />from authors<if test="_parameter != null"><include refid="Example_Where_Clause" /></if><if test="orderByClause != null">order by ${orderByClause}</if></select>
获取数据的核心service如下,由于只做个简单演示,就懒得写成接口了。其中 streamDownload 方法即为stream取数据写文件的实现,它将以很低的内存占用从MySQL获取数据;此外还提供traditionDownload方法,它是一种传统的下载方式,批量获取全部数据,然后将每个对象写入文件。
@Service
public class AuthorsService {private final SqlSessionTemplate sqlSessionTemplate;private final AuthorsMapper authorsMapper;public AuthorsService(SqlSessionTemplate sqlSessionTemplate, AuthorsMapper authorsMapper) {this.sqlSessionTemplate = sqlSessionTemplate;this.authorsMapper = authorsMapper;}/*** stream读数据写文件方式* @param httpServletResponse* @throws IOException*/public void streamDownload(HttpServletResponse httpServletResponse)throws IOException {AuthorsExample authorsExample = new AuthorsExample();authorsExample.createCriteria();HashMap<String, Object> param = new HashMap<>();param.put("oredCriteria", authorsExample.getOredCriteria());param.put("orderByClause", authorsExample.getOrderByClause());CustomResultHandler customResultHandler = new CustomResultHandler(new DownloadProcessor (httpServletResponse));sqlSessionTemplate.select("com.alphathur.mysqlstreamingexport.mapper.AuthorsMapper.streamByExample", param, customResultHandler);httpServletResponse.getWriter().flush();httpServletResponse.getWriter().close();}/*** 传统下载方式* @param httpServletResponse* @throws IOException*/public void traditionDownload(HttpServletResponse httpServletResponse)throws IOException {AuthorsExample authorsExample = new AuthorsExample();authorsExample.createCriteria();List<Authors> authors = authorsMapper.selectByExample (authorsExample);DownloadProcessor downloadProcessor = new DownloadProcessor (httpServletResponse);authors.forEach (downloadProcessor::processData);httpServletResponse.getWriter().flush();httpServletResponse.getWriter().close();}
}
下载的入口controller:@RestController
@RequestMapping("download")
public class HelloController {private final AuthorsService authorsService;public HelloController(AuthorsService authorsService) {this.authorsService = authorsService;}@GetMapping("streamDownload")public void streamDownload(HttpServletResponse response)throws IOException {authorsService.streamDownload(response);}@GetMapping("traditionDownload")public void traditionDownload(HttpServletResponse response)throws IOException {authorsService.traditionDownload (response);}
}
相关文章:

Mybatis之批处理流式查询
文章目录 1 批处理查询1.1 引言1.2 流式查询1.2.1 定义1.2.2 流式查询接口1.2.3 使用流式查询关闭问题1.2.3.1 SqlSessionFactory1.2.3.2 TransactionTemplate1.2.3.3 Transactional 注解 1.2.4 完整示例1.2.4.1 mapper接口和SQL1.2.4.2 Service操作 1.3 游标查询1.3.1 定义1.3…...
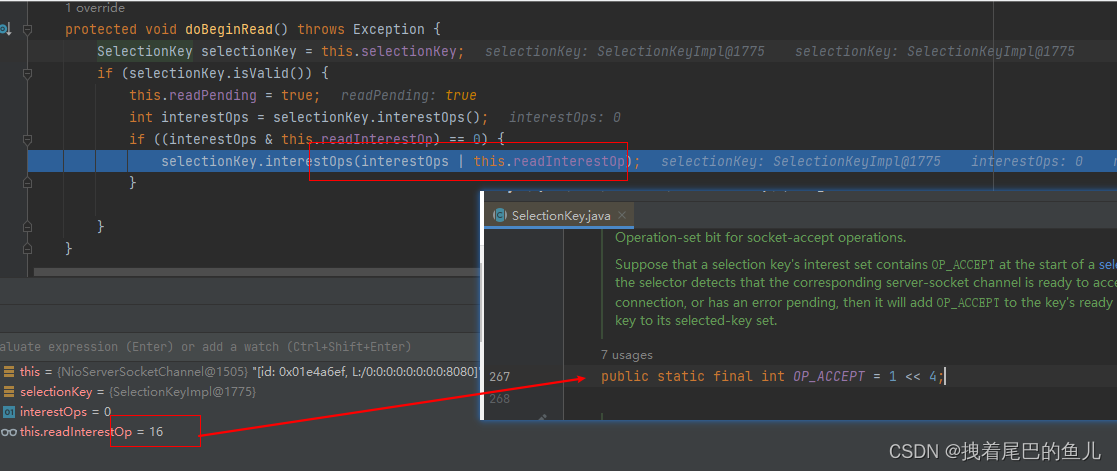
Spring架构篇--2.7.3 远程通信基础--Netty原理--bind实现端口的绑定
前言:在对ServerBootstrap 进行属性赋值之后,通过bind 方法完成端口的绑定,并开始在NioEventLoop中进行轮询进行事件的处理;本文主要探究ServersocketChannel 在netty 中是如何完成注册,以及端口的绑定 1 Nio selecto…...

【改进的多同步挤压变换】基于改进多同步挤压的高分辨率时频分析工具,用于分析非平稳信号(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

有关 python 切片的趣事
哈喽大家好,我是咸鱼 今天来讲一个我在实现 python 列表切片时遇到的趣事 在正式开始之前,我们先来了解一下切片(slice) 切片操作是访问序列(列表、字符串…)中元素的另一种方法,它可以访问一…...

ChatGPT 会带来失业潮吗?
(永久免费,扫码加入) 最近在翻知乎上的一些文章,很多都是跟ChatGPT有关的。因为本身是搞Python编程的,知乎推荐系统给我推荐了一篇廖雪峰老师的文章,觉得很有意思。 一共1119个赞,还是很厉害的&…...

如何对待工作中的失误
在日复一日的工作中,我们免不了会产生一些失误,会因此感到沮丧和失望。但如何正确地对待和处理这些失误才是最重要的,它直接影响到我们的工作表现和个人成长。一起来谈谈作为职场人的你时如何处理工作中的失误的吧! 一、在面对失…...

微信小程序快速入门【一】
微信小程序快速入门【一】 文章目录 微信小程序快速入门【一】👨🏫内容1:背景👨⚖️内容2:准备工作👨💻内容3:新建一个小程序🍉文末推荐 👨…...
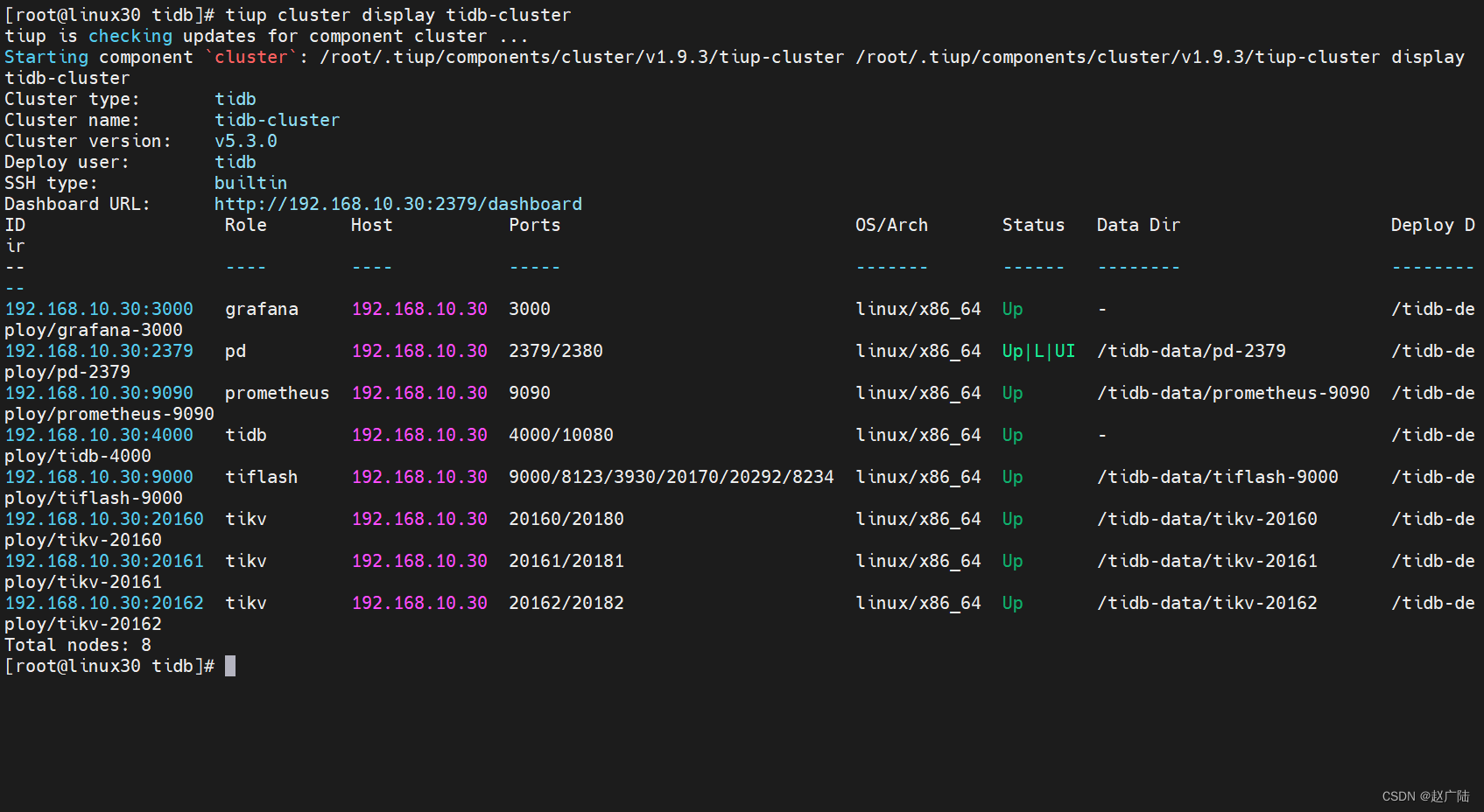
TiDB亿级数据亚秒响应查询集群部署
目录 1 集群部署1.1 环境要求1.1.1 操作系统建议配置1.1.2 服务器建议配置 1.2 环境准备1.3 安装TiUP1.3.1 什么是TiUP1.3.2 安装TiUP组件1.3.3 配置TiUP环境1.3.4 检查TiUP 工具是否安装1.3.5 安装 cluster 组件1.3.6 升级cluster组件 1.4 编辑部署文件1.4.1 常见的部署场景1.…...

并发——同步访问共享的可变数据
关键字 synchronized 可以保证在同一时刻,只有一个线程可以执行某一个方法,或者某一段代码块。许多程序员把同步的概念仅仅理解为一种互斥的方式。即,当一个对象被一个线程修改的时候,可以阻止另一个线程观察到内部不一致的状态。…...
禁用容器网络)
Docker网络模型(九)禁用容器网络
禁用容器网络 如果你想完全禁用容器上的协议栈,你可以在启动容器时使用 --network none 标志。在容器内,只有回环设备被创建。下面的例子说明了这一点。 创建容器 $ docker run --rm -dit \--network none \--name no-net-alpine \alpine:latest \ash通…...

JavaScript 教程---互联网文档计划
学习目标: 每天记录一章笔记 学习内容: JavaScript 教程---互联网文档计划 笔记时间: 2023-6-5 --- 2023-6-11 学习产出: 1.入门篇 1、JavaScript 的核心语法包含部分 基本语法标准库宿主API 基本语法:比如操作符…...

做好功能测试需要的8项基本技能【点工进来】
功能测试是测试工程师的基础功,很多人功能测试还做不好,就想去做性能测试、自动化测试。很多人对功能测试的理解就是点点点,如何自己不用心去悟,去研究,那么你的职业生涯也就停留在点点点上了。在这里,我把…...
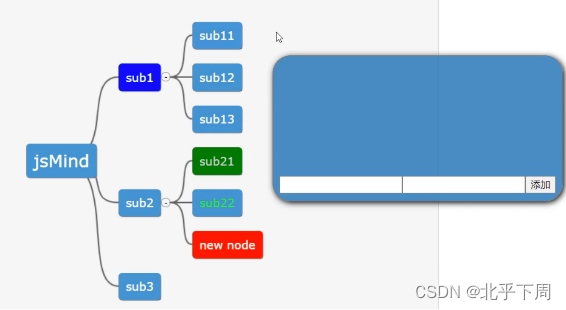
在弹出框内三个元素做水平显示
最终效果图要求是这样: js代码: // 显示弹出窗口 function showPopup(node) {var popup document.createElement(div);popup.className popup;var inputContainer1 document.createElement(div);/* inputContainer1.className input-container1; */…...

纠删码技术在vivo存储系统的演进【上篇】
作者:vivo 互联网服务器团队- Gong Bing 本文将学术界和工业界的纠删码技术的核心研究成果进行了相应的梳理,然后针对公司线上存储系统的纠删码进行分析,结合互联网企业通用的IDC资源、服务器资源、网络资源、业务特性进行分析对原有纠删码技…...
如何实现APP自动化测试?
APP测试,尤其是APP的自动化测试,在软件测试工程师的面试中越来越会被问到了。为了更好的回答这个问题,我今天就给大家分享一下,如何进行APP的自动化测试。 一、为了实现JavaAppiumJunit技术用于APP自动化测试,所以需要…...

INNODB和MyISAM区别
1 存储引擎是MyISAM 如下: CREATE table test_myisam (cli int ) ENGINEMyISAM 存储目录里会有三个文件 test_myisam.frm为“表定义”,是描述数据表结构的文件 test_myisam.MYI文件是表的索引 test_myisam.MYD文件是表的数据 2 存储引擎是INNODB…...
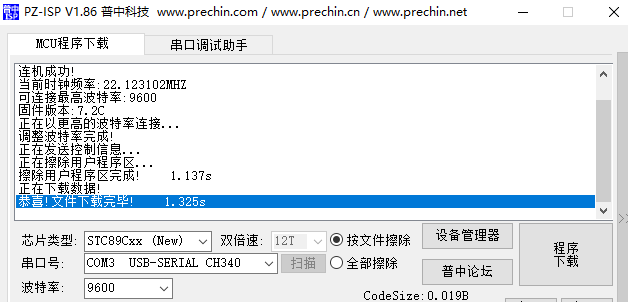
普中自动下载软件1.86下载程序失败案例
今天在用开发板做一个功能,下载的时候报错了,说芯片超时 确定驱动安装好了的 波特率也试了一圈 线也换过了 最后发现是芯片类型选错了,这个开发板是用的stc89c52,所以我选了图里这个,但是翻了开发板配套的资料,发现…...

JavaScript HTML DOM
JavaScript HTML DOM(文档对象模型)是一种用于访问和操作HTML文档元素的编程接口。它将HTML文档表示为一个树形结构,使开发人员可以使用JavaScript来操作和修改HTML元素、属性、样式和事件。 通过使用HTML DOM,你可以使用JavaScr…...
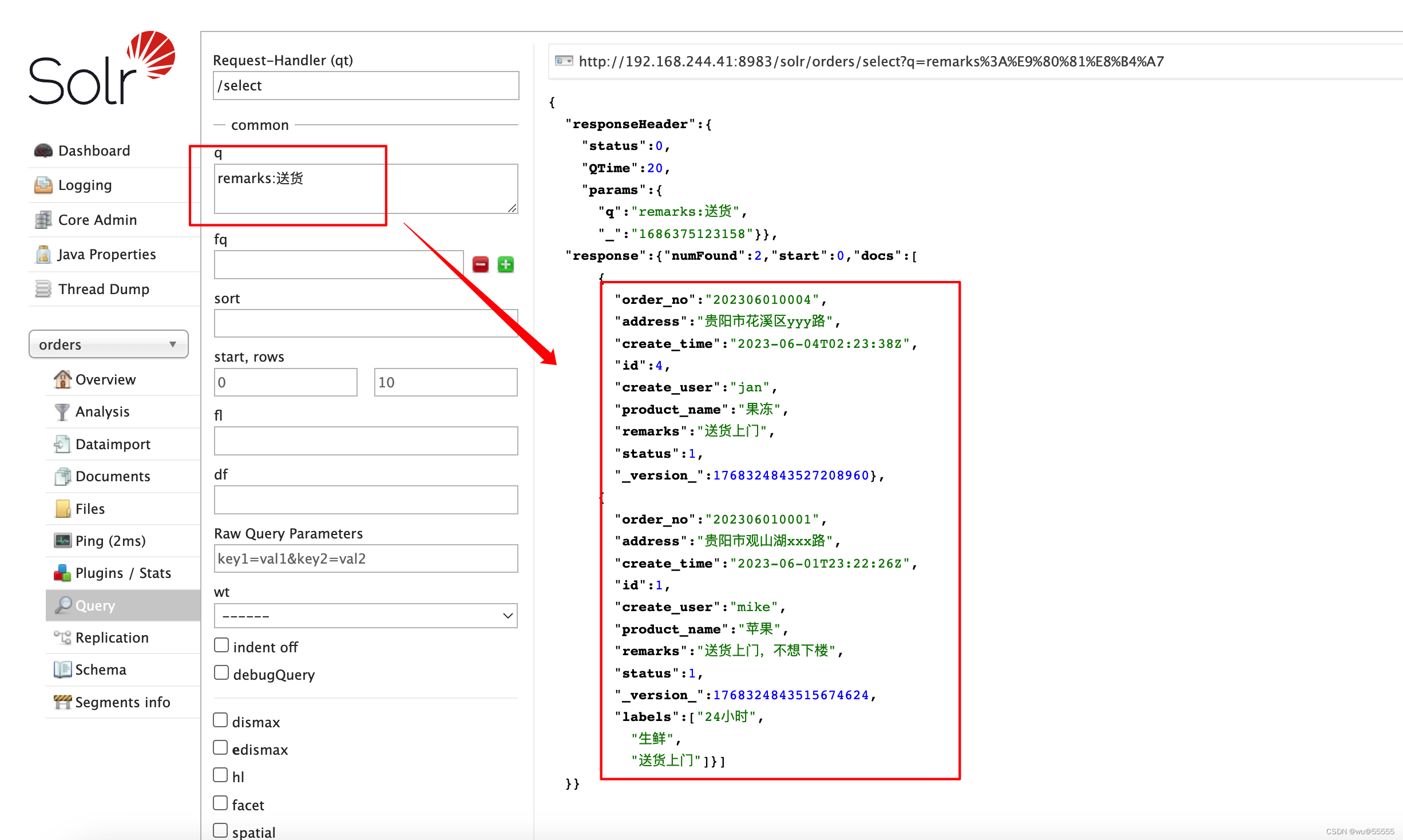
solr快速上手:配置IK中文分词器(七)
0. 引言 solr作为搜索引擎,常用在我们对于搜索速度有较高要求且大数据量的业务场景,我们之前已经配置过英文分词器,但是针对中文分词不够灵活和实用,要实现真正意义上的中文分词,还需要单独安装中文分词器 solr快速上…...

【软件测试】接口测试工具APIpost
说实话,了解APIpost是因为,我的所有接口相关的文章下,都有该APIpost水军的评论,无非就是APIpost是中文版的postman,有多么多么好用,虽然咱也还不是什么啥网红,但是不知会一声就乱在评论区打广告…...

多说话人场景下的设备定向语音检测技术解析
1. 多说话人场景下的设备定向语音检测技术解析在智能语音交互系统中,准确识别用户何时在对设备说话(设备定向语音)而非与他人交谈,是提升用户体验的关键技术挑战。这项技术被称为设备定向语音检测(Device-Directed Spe…...

独立开发者实战:AI编程的泥泞战壕与生存指南
1. 从“氛围编程”到真实战场:一个独立开发者的自白如果你最近也在关注独立开发或者AI编程工具,那你一定听过“氛围编程”这个词。它听起来很酷,对吧?仿佛你只需要对着AI描述一下心中的“氛围感”,一个完美的应用就能应…...

量子机器学习中的噪声效应与抗噪策略
1. 量子机器学习中的噪声效应全景解析在量子计算与机器学习交叉领域,噪声问题正成为制约实际应用的关键瓶颈。去年我在参与一个医疗影像分类项目时,首次亲身体验到量子噪声的破坏力——当我们将经典卷积神经网络迁移到量子变分电路架构时,准确…...

AI任务自动化五阶段工作流:从需求到代码的可靠实践
1. 项目概述:从混乱到有序的AI任务自动化五阶段工作流上次我们聊了这套自动化系统的技术架构,把JIRA、GitHub和Cursor智能体串了起来。今天咱们不聊“怎么连”,聊聊“怎么跑”——也就是那个能把一个粗糙的需求工单,最终变成一行行…...

VSCode + Cline + Codeium + OpenSpec + DeepSeek 完整配置指南
VSCode Cline Codeium OpenSpec DeepSeek 完整配置指南 📋 最终方案概述 组件用途费用VSCode代码编辑器免费Codeium (Windsurf)Tab 补全 生成注释免费ClineAI Agent(复杂任务、多文件操作)免费OpenSpec规范驱动开发(复杂功…...

XClaw Skill:AI Agent的社交网络与技能市场接入实战指南
1. 项目概述:XClaw Skill,AI Agent的“社交网络”与“技能市场”通行证如果你正在开发或使用AI Agent,并且希望它不再是一个信息孤岛,而是能与其他Agent交流、协作、甚至通过自己的“手艺”赚取收益,那么XClaw.network…...

技术债务的职场政治:谁该为历史遗留问题买单
在软件测试从业者的日常工作中,技术债务是一个绕不开的话题。它像一颗隐藏在代码深处的定时炸弹,随时可能在项目推进的某个节点爆发,引发一系列连锁反应。而当技术债务问题浮出水面时,一场关于“谁该为历史遗留问题买单”的职场政…...

VRM-VRChat双向转换引擎:打破虚拟角色平台壁垒的技术解决方案
VRM-VRChat双向转换引擎:打破虚拟角色平台壁垒的技术解决方案 【免费下载链接】VRMConverterForVRChat 项目地址: https://gitcode.com/gh_mirrors/vr/VRMConverterForVRChat VRM格式转换、VRChat SDK3兼容、Unity编辑器扩展、虚拟角色迁移、跨平台角色转换…...

告别运行库安装烦恼:Visual C++ AIO合集一键搞定所有版本
告别运行库安装烦恼:Visual C AIO合集一键搞定所有版本 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 你是否曾经为了运行某个软件而四处寻找不同版…...

HandheldCompanion:解锁Windows掌机游戏体验的终极钥匙
HandheldCompanion:解锁Windows掌机游戏体验的终极钥匙 【免费下载链接】HandheldCompanion ControllerService 项目地址: https://gitcode.com/gh_mirrors/ha/HandheldCompanion 你是否曾为Windows掌机的游戏兼容性而烦恼?是否梦想着在便携设备上…...