【Leetcode -225.用队列实现栈 -232.用栈实现队列】
Leetcode
- Leetcode -225.用队列实现栈
- Leetcode -232.用栈实现队列
Leetcode -225.用队列实现栈
题目:仅使用两个队列实现一个后入先出(LIFO)的栈,并支持普通栈的全部四种操作(push、top、pop 和 empty)。
实现 MyStack 类:
void push(int x) 将元素 x 压入栈顶。
int pop() 移除并返回栈顶元素。
int top() 返回栈顶元素。
boolean empty() 如果栈是空的,返回 true ;否则,返回 false 。
注意:
你只能使用队列的基本操作 —— 也就是 push to back、peek / pop from front、size 和 is empty 这些操作。
你所使用的语言也许不支持队列。 你可以使用 list (列表)或者 deque(双端队列)来模拟一个队列 , 只要是标准的队列操作即可。
示例:
输入:
[“MyStack”, “push”, “push”, “top”, “pop”, “empty”]
[[], [1], [2], [], [], []]
输出:
[null, null, null, 2, 2, false]
解释:
MyStack myStack = new MyStack();
myStack.push(1);
myStack.push(2);
myStack.top(); // 返回 2
myStack.pop(); // 返回 2
myStack.empty(); // 返回 False
提示:
1 <= x <= 9
最多调用100 次 push、pop、top 和 empty
每次调用 pop 和 top 都保证栈不为空
思路:思路是先写一个队列的数据结构,我们知道,栈的结构是先进后出,而队列的结构是先进先出,所以我们可以用两个队列,一个队列的数据导到另外一个队列中,然后留最后一个,这最后一个就是要出栈的数据,出栈就是这样实现;而入栈就是直接找到非空的队列入即可;
例如两个队列实现入栈,如果两个都为空,就随便进一个:
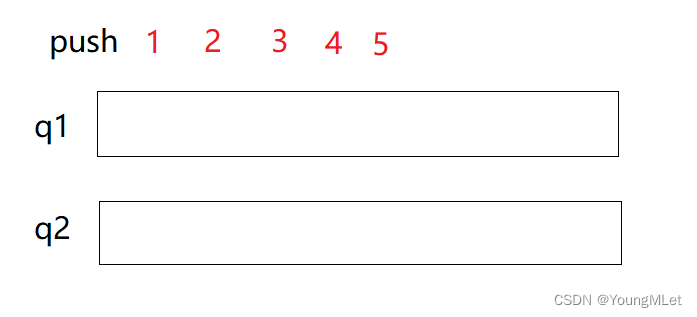
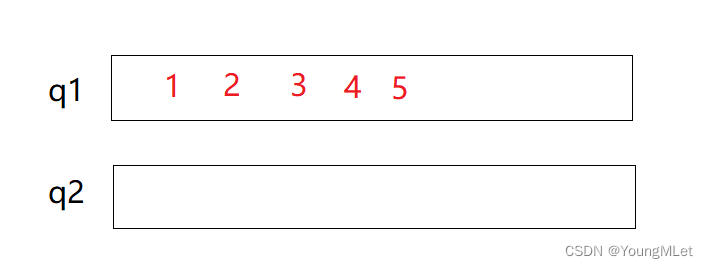
入栈完成后,如果要出栈,就将q1的5个数据的前4个导入q2中:
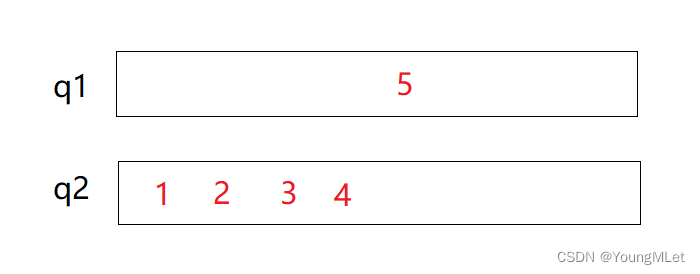
再出q1中的数据即可;
下面参考代码的实现:
创建队列的数据结构,以及实现队列的基本操作
typedef int QDataType;typedef struct QueueNode{struct QueueNode* next;QDataType data;}QNode;typedef struct Queue{QNode* phead;QNode* ptail;QDataType size;}Queue;//初始化队列void QueueInit(Queue* pq){assert(pq);pq->phead = NULL;pq->ptail = NULL;pq->size = 0;}//入队void QueuePush(Queue* pq, QDataType x){assert(pq);//新节点QNode* newnode = (QNode*)malloc(sizeof(QNode));assert(newnode);newnode->data = x;newnode->next = NULL;//队列为空if (pq->ptail == NULL){assert(pq->phead == NULL);pq->phead = pq->ptail = newnode;}//队列不为空else{pq->ptail->next = newnode;pq->ptail = newnode;}pq->size++;}//判断队列是否为空bool QIsEmpty(Queue* pq){assert(pq);return pq->phead == NULL && pq->ptail == NULL;}//出队void QueuePop(Queue* pq){assert(pq);assert(!QIsEmpty(pq));//一个节点if (pq->phead->next == NULL){free(pq->phead);pq->phead = pq->ptail = NULL;}//多个节点else{//头删QNode* next = pq->phead->next;free(pq->phead);pq->phead = next;}pq->size--;}//获取队头QDataType QueueFront(Queue* pq){assert(pq);assert(!QIsEmpty(pq));return pq->phead->data;}//获取队尾QDataType QueueBack(Queue* pq){assert(pq);assert(!QIsEmpty(pq));return pq->ptail->data;}//获取队列的长度int Qsize(Queue* pq){assert(pq);return pq->size;}//释放队列void QueueDestroy(Queue* pq){assert(pq);QNode* cur = pq->phead;while (cur){QNode* next = cur->next;free(cur);cur = next;}pq->phead = pq->ptail = NULL;pq->size = 0;}
定义两个队列
typedef struct{Queue q1;Queue q2;} MyStack;
初始化两个队列
MyStack* myStackCreate(){MyStack* obj = (MyStack*)malloc(sizeof(MyStack));QueueInit(&obj->q1);QueueInit(&obj->q2);return obj;}
两个队列实现入栈
void myStackPush(MyStack* obj, int x){//哪个队列不为空就入哪个队列if (!QIsEmpty(&obj->q1)){QueuePush(&obj->q1, x);}else{QueuePush(&obj->q2, x);}}
两个队列实现出栈
int myStackPop(MyStack* obj){//假设q1为空,q2不空Queue* pEmpty = &obj->q1;Queue* pNonEmpty = &obj->q2;//如果假设错误,就改正if (!QIsEmpty(&obj->q1)){pNonEmpty = &obj->q1;pEmpty = &obj->q2;}//导数据,将非空队列中的数据导入空的队列中,非空队列留最后一个数据,即是栈顶的数据while (Qsize(pNonEmpty) > 1){QueuePush(pEmpty, QueueFront(pNonEmpty));QueuePop(pNonEmpty);}//记录栈顶的数据,然后出栈,最后返回这个数据int top = QueueFront(pNonEmpty);QueuePop(pNonEmpty);return top;}
获取两个队列实现的栈顶数据
int myStackTop(MyStack* obj){//获取栈顶的数据即是获取非空队列的队尾数据//我们上面实现了获取队列的队尾的数据,所以直接调用函数即可if (!QIsEmpty(&obj->q1)){return QueueBack(&obj->q1);}else{return QueueBack(&obj->q2);}}
判断两个队列是否是空队列,即是否是空栈
bool myStackEmpty(MyStack* obj){return QIsEmpty(&obj->q1) && QIsEmpty(&obj->q2);}
释放两个队列的内存
void myStackFree(MyStack* obj){QueueDestroy(&obj->q1);QueueDestroy(&obj->q2);free(obj);}
Leetcode -232.用栈实现队列
题目:仅使用两个栈实现先入先出队列。队列应当支持一般队列支持的所有操作(push、pop、peek、empty):
实现 MyQueue 类:
void push(int x) 将元素 x 推到队列的末尾
int pop() 从队列的开头移除并返回元素
int peek() 返回队列开头的元素
boolean empty() 如果队列为空,返回 true ;否则,返回 false
说明:
你 只能 使用标准的栈操作 —— 也就是只有 push to top, peek / pop from top, size, 和 is empty 操作是合法的。
你所使用的语言也许不支持栈。你可以使用 list 或者 deque(双端队列)来模拟一个栈,只要是标准的栈操作即可。
示例 1:
输入:
[“MyQueue”, “push”, “push”, “peek”, “pop”, “empty”]
[[], [1], [2], [], [], []]
输出:
[null, null, null, 1, 1, false]
解释:
MyQueue myQueue = new MyQueue();
myQueue.push(1); // queue is: [1]
myQueue.push(2); // queue is: [1, 2] (leftmost is front of the queue)
myQueue.peek(); // return 1
myQueue.pop(); // return 1, queue is [2]
myQueue.empty(); // return false
提示:
1 <= x <= 9
最多调用 100 次 push、pop、peek 和 empty
假设所有操作都是有效的 (例如,一个空的队列不会调用 pop 或者 peek 操作)
思路:思路是先写一个栈的数据结构,再定义两个栈,一个pushst用来实现入队,另一个popst用来实现出队;
例如实现入队:
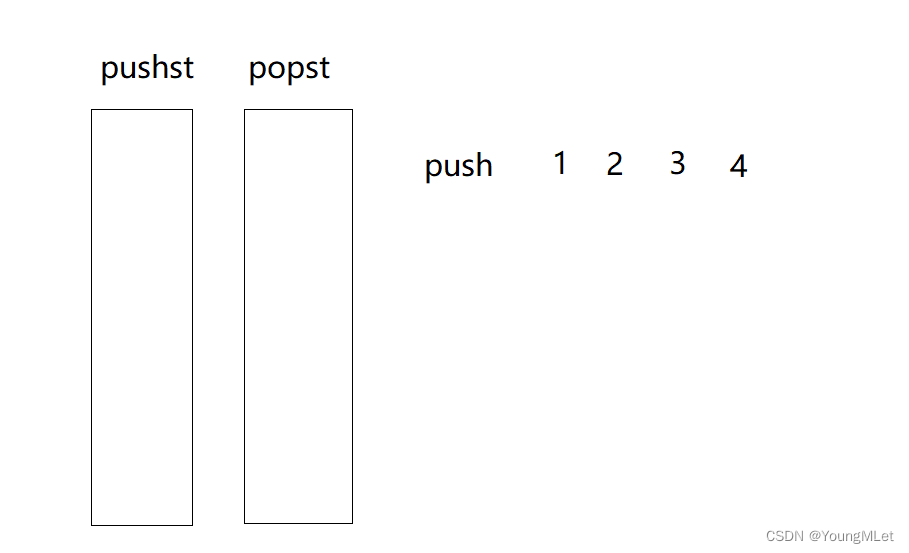
将数据入栈到pushst中:
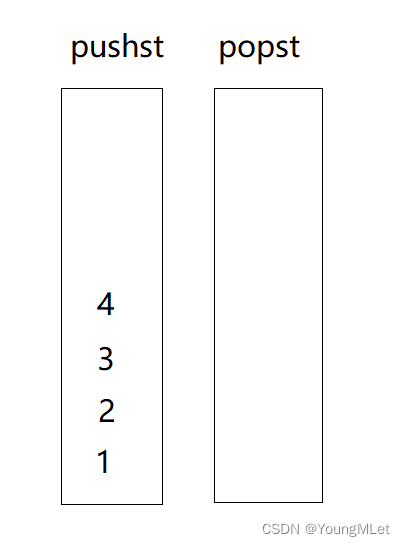
需要出队列的时候,如果popst为空,就将pushst的数据入栈到popst中:
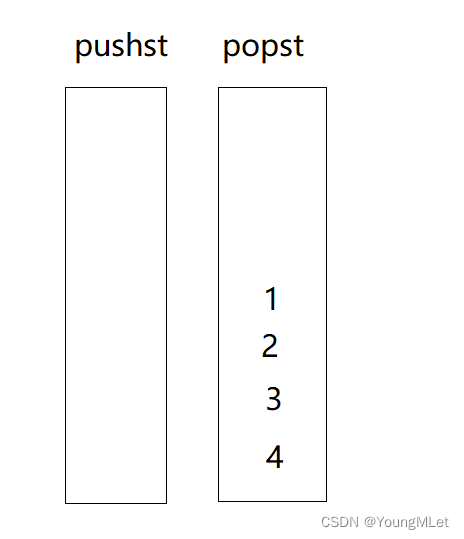
此时的1就是队头,1,2,3,4就是入队的顺序;
下面参考代码的实现:
实现栈的数据结构,以及栈的基本操作
typedef int STDataType;typedef struct Stack{STDataType* stack;int top;int capacity;}ST;//初始化void STInit(ST* pst){assert(pst);pst->stack = NULL;pst->top = 0;pst->capacity = 0;}//判断是否为空栈bool STIsEmpty(ST* pst){return pst->top == 0;}//进栈void STPushTop(ST* pst, STDataType x){assert(pst);//检查容量if (pst->top == pst->capacity){int len = pst->capacity == 0 ? 4 : pst->capacity * 2;STDataType* newstack = (STDataType*)realloc(pst->stack, sizeof(ST) * len);assert(newstack);pst->capacity = len;pst->stack = newstack;}pst->stack[pst->top] = x;pst->top++;}//出栈void STPopTop(ST* pst){assert(pst);assert(!STIsEmpty(pst));pst->top--;}//获取栈顶的元素STDataType STTop(ST* pst){assert(pst);assert(!STIsEmpty(pst));return pst->stack[pst->top - 1];}//销毁栈void STDestroy(ST* pst){assert(pst);free(pst->stack);pst->stack = NULL;pst->capacity = pst->top = 0;}
定义两个栈,一个栈pushst是专门入数据,另一个popst是专门出数据
typedef struct{ST pushst;ST popst;} MyQueue;
给两个栈初始化
MyQueue* myQueueCreate(){MyQueue* obj = (MyQueue*)malloc(sizeof(MyQueue));STInit(&obj->pushst);STInit(&obj->popst);return obj;}
两个栈实现入队列,只需要入pushst的栈即可
void myQueuePush(MyQueue* obj, int x){STPushTop(&obj->pushst, x);}
从队列的开头移除并返回元素,与下面两个栈实现返回队列的队头数据相似,我们可以直接调用 myQueuePeek 函数,返回队头的元素后,再移除队头
int myQueuePop(MyQueue* obj){int front = myQueuePeek(obj);STPopTop(&obj->popst);return front;}
两个栈实现返回队列的队头数据
int myQueuePeek(MyQueue* obj){//如果popst栈为空,就将pushst的数据导过来if (STIsEmpty(&obj->popst)){while (!STIsEmpty(&obj->pushst)){STPushTop(&obj->popst, STTop(&obj->pushst));STPopTop(&obj->pushst);}}//返回popst的栈顶元素,即是队列的头return STTop(&obj->popst);}
两个栈实现判断队列是否是空,判断两个栈是否为空即可
bool myQueueEmpty(MyQueue* obj){return STIsEmpty(&obj->pushst) && STIsEmpty(&obj->popst);}
释放两个栈的内存
void myQueueFree(MyQueue* obj){STDestroy(&obj->pushst);STDestroy(&obj->popst);free(obj);}
相关文章:
【Leetcode -225.用队列实现栈 -232.用栈实现队列】
Leetcode Leetcode -225.用队列实现栈Leetcode -232.用栈实现队列 Leetcode -225.用队列实现栈 题目:仅使用两个队列实现一个后入先出(LIFO)的栈,并支持普通栈的全部四种操作(push、top、pop 和 empty)。 …...
悟道3.0全面开源!LeCun VS Max 智源大会最新演讲
夕小瑶科技说 原创 作者 | 小戏 2023 年智源大会如期召开! 这场汇集了 Geoffery Hinton、Yann LeCun、姚期智、Joseph Sifakis、Sam Altman、Russell 等一众几乎是 AI 领域学界业界“半壁江山”的大佬们的学术盛会,聚焦 AI 领域的前沿问题,…...
2023蓝桥杯大学A组C++决赛游记+个人题解
Day0 发烧了一晚上没睡着,感觉鼻子被打火机烧烤一样难受,心情烦躁 早上6点起来吃了个早饭,思考能力完全丧失了,开始看此花亭奇谭 看了六集,准备复习数据结构考试,然后秒睡 一睁眼就是下午2点了 挂了个…...

wkhtmltopdf踩坑记录
1. 不支持writing-mode。 需求是文字纵向排列,内容从左到右,本来用的是writing-mode: tb-rl;,插件转pdf后发现失效。 解决方法: 让每一列文字单独用一个div容器包裹,对它的宽度进行限制,控制每一行只能出现…...

贪心算法part2 | ● 122.买卖股票的最佳时机II ● 55. 跳跃游戏 ● 45.跳跃游戏II
文章目录 122.买卖股票的最佳时机II思路思路代码官方题解困难 55. 跳跃游戏思路思路代码官方题解代码困难 45.跳跃游戏II思路思路代码困难 今日收获 122.买卖股票的最佳时机II 122.买卖股票的最佳时机II 思路 局部最优:将当天价格和前一天比较,价格涨…...

[C++]异常笔记
我不怕练过一万种腿法的对手,就怕将一种腿法 练一万次的对手。 什么是C的异常 在C中,异常处理通常使用try-catch块来实现。try块用于包含可能会抛出异常的代码,而catch块用于捕获并处理异常。当异常被抛出时,程序会跳过try块中未执行…...

浅谈一级机电管道设计中的压力与介质温度
管道设计是工程设计中的一个非常重要的部分,管道的设计需要考虑到许多因素,其中就包括管道设计压力分类和介质温度分类。这两个因素是在设计管道时必须非常严格考虑的, 首先是管道设计压力分类。在管道设计中,根据工作要求和要传输…...
使用 macvlan 网络)
Docker网络模型(八)使用 macvlan 网络
使用 macvlan 网络 一些应用程序,特别是传统的应用程序或监控网络流量的应用程序,期望直接连接到物理网络。在这种情况下,你可以使用 macvlan 网络驱动为每个容器的虚拟网络接口分配一个MAC地址,使其看起来像一个直接连接到物理网…...
控制视图内容的位置
文本域中的提示内容在默认情况下是垂直居中的,要改变文本在文本域中的位置,可以使用android:gravity来实现。 利用android:gravity可以指定如何在视图中放置视图内容,例如,如何在文本域中放置文本。 如果希望视图文本显示在上方&a…...

【分布式系统与一致性协议】
分布式系统与一致性协议 CAP原理APCPCA总结BASE理论 一致性拜占庭将军问题 分布式系统是一个硬件或软件组件分布在不同的网络计算机上,彼此之间仅仅通过消息传递进行通信和协调的系统。 分布式系统的设计目标一般包含如下: 可用性:可用性是分…...

音视频领域的未来发展方向展望
文章目录 音视频领域的未来发展方向全景音视频技术虚拟现实和增强现实的区别 人工智能技术可视化智能分析智能语音交互图像识别和视频分析技术 语音处理智能推荐技术远程实时通信 流媒体技术未来方向 音视频领域的未来发展方向 全景音视频技术:全景音视频技术是近年…...
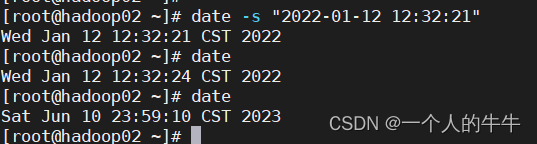
时间同步/集群时间同步/在线/离线
目录 一、能够连接外网 二、集群不能连接外网--同步其它服务器时间 一、能够连接外网 1.介绍ntp时间协议 NTP(Network Time Protocol)网络时间协议,是用来使计算机时间同步的一种协议,它可以使计算机对其服务器或时钟源做同步…...
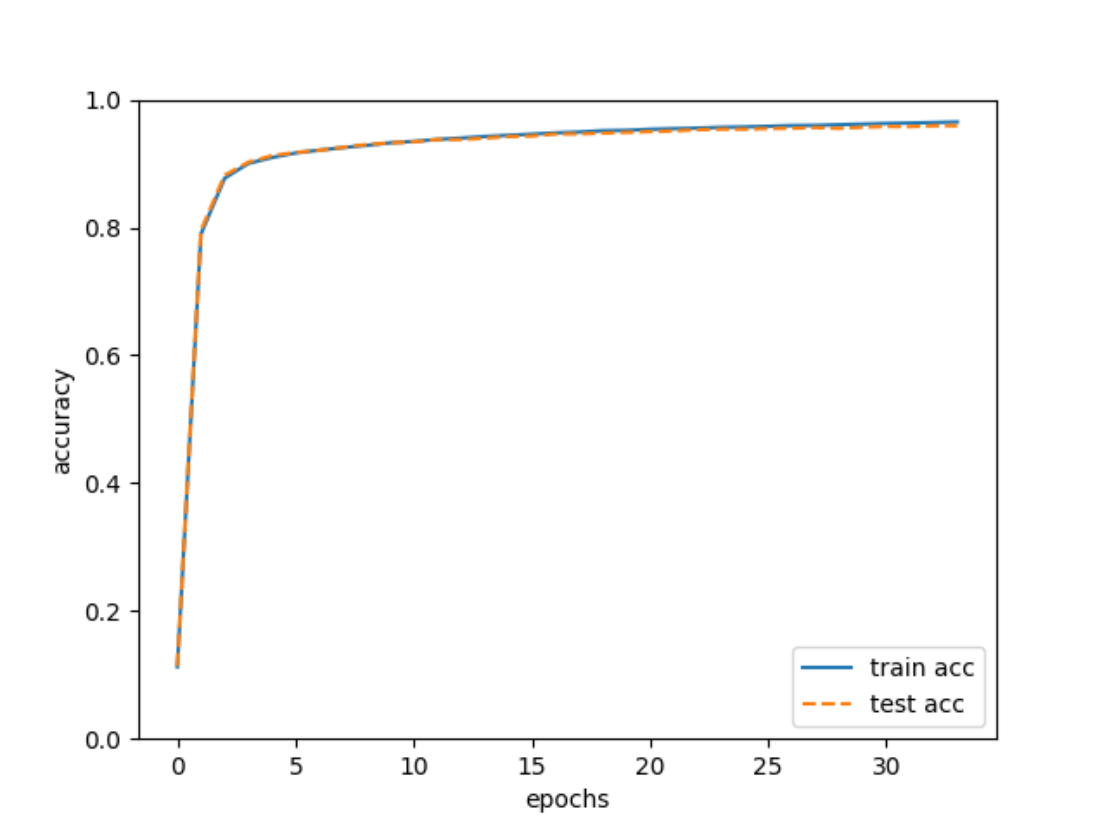
基于BP神经网络对MNIST数据集检测识别(numpy版本)
基于BP神经网络对MNIST数据集检测识别 1.作者介绍2.BP神经网络介绍2.1 BP神经网络 3.BP神经网络对MNIST数据集检测实验3.1 读取数据集3.2 前向传播3.3 损失函数3.4 构建神经网络3.5 训练3.6 模型推理 4.完整代码 1.作者…...
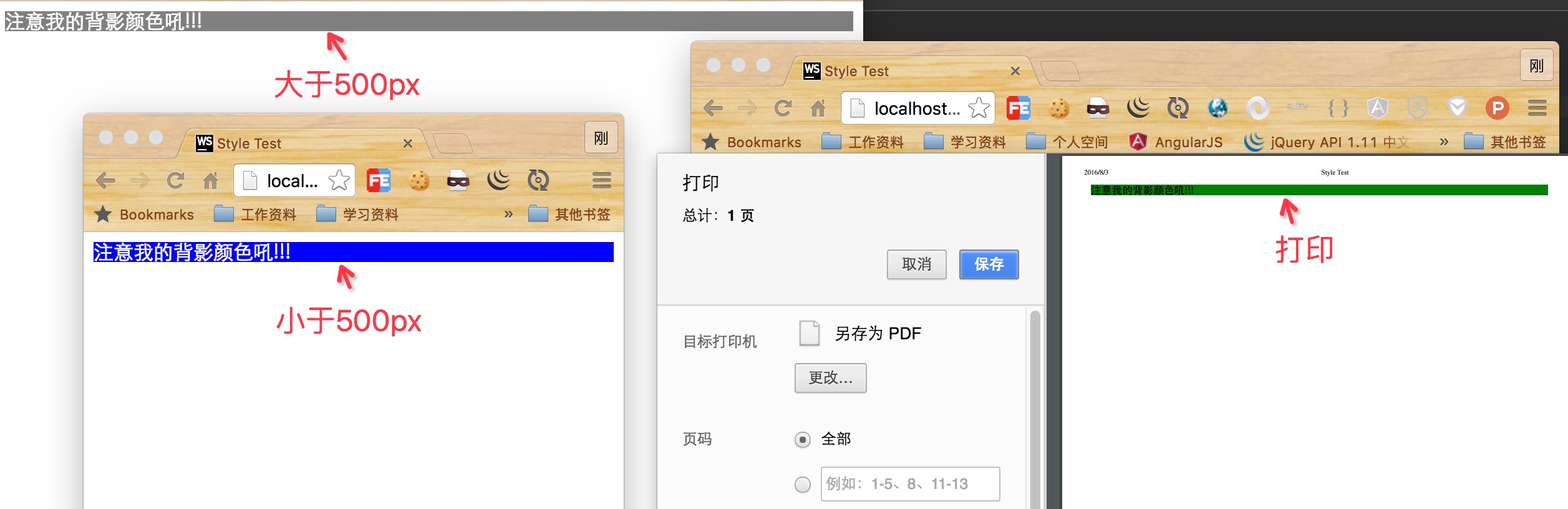
HTML5-创建HTML文档
HTML5中的一个主要变化是:将元素的语义与元素对其内容呈现结果的影响分开。从原理上讲这合乎情理。HTML元素负责文档内容的结构和含义,内容的呈现则由应用于元素上的CSS样式控制。下面介绍最基础的HTML元素:文档元素和元数据元素。 一、构建…...

Vue中Axios的封装和API接口的管理
一、axios的封装 在vue项目中,和后台交互获取数据这块,我们通常使用的是axios库,它是基于promise的http库,可运行在浏览器端和node.js中。他有很多优秀的特性,例如拦截请求和响应、取消请求、转换json、客户端防御XSR…...

MLIR面试题
1、请简要解释MLIR的概念和用途,并说明MLIR在编译器领域中的重要性。 MLIR(Multi-Level Intermediate Representation)是一种多级中间表示语言,提供灵活、可扩展和可优化的编译器基础设施。MLIR的主要目标是为不同的编程语言、领域专用语言(DSL)和编译器…...
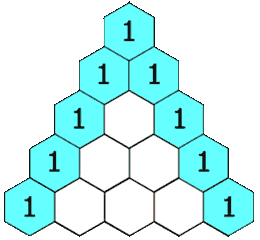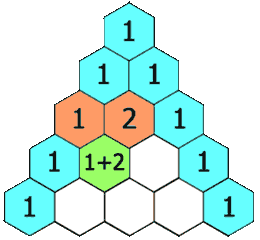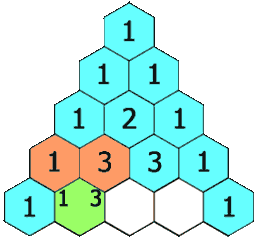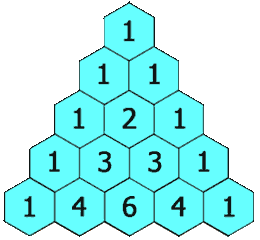
***杨辉三角_yyds_LeetCode_python***
1.题目描述: 给定一个非负整数 numRows,生成「杨辉三角」的前 numRows 行。 在「杨辉三角」中,每个数是它左上方和右上方的数的和。 示例 1: 输入: numRows 5 输出: [[1],[1,1],[1,2,1],[1,3,3,1],[1,4,6,4,1]] 示例 2: 输入: numRows …...
Mac使用DBeaver连接达梦数据库
Mac使用DBeaver连接达梦数据库 下载达梦驱动包 达梦数据库 在下载页面随便选择一个系统并下载下来。 下载下来的是zip的压缩包解压出来就是一个ISO文件,然后我们打开ISO文件进入目录:/dameng/source/drivers/jdbc 进入目录后找到这几个驱动包&#x…...

spring.expression 随笔0 概述
0. 我只是个普通码农,不值得挽留 Spring SpEL表达式的使用 常见的应用场景:分布式锁的切面借助SpEL来构建key 比较另类的的应用场景:动态校验 个人感觉可以用作控制程序的走向,除此之外,spring的一些模块的自动配置类,也会在Cond…...

从Cookie到Session: Servlet API中的会话管理详解
文章目录 一. Cookie与Session1. Cookie与Session2. Servlet会话管理操作 二. 登录逻辑的实现 一. Cookie与Session 1. Cookie与Session 首先, 在学习过 HTTP 协议的基础上, 我们需要知道 Cookie 是 HTTP 请求报头中的一个关键字段, 本质上是浏览器在本地存储数据的一种机制,…...

从PTA天梯赛L1真题看起:新手如何用C++快速搞定编程竞赛里的“送分题”?
从PTA天梯赛L1真题看起:新手如何用C快速搞定编程竞赛里的“送分题”? 第一次参加编程竞赛的新手,面对屏幕上密密麻麻的题目,往往会感到无从下手。但仔细观察历届PTA天梯赛L1级别的题目,你会发现一个有趣的现象——总有…...

Axure RP全版本界面本地化:从问题诊断到安全部署的完整指南
Axure RP全版本界面本地化:从问题诊断到安全部署的完整指南 【免费下载链接】axure-cn Chinese language file for Axure RP. Axure RP 简体中文语言包,不定期更新。支持 Axure 9、Axure 10。 项目地址: https://gitcode.com/gh_mirrors/ax/axure-cn …...

Python邮件自动化实战:基于imaplib和email库的高效邮件处理方案
1. Python邮件自动化处理的核心价值 每天早晨打开邮箱,看到堆积如山的未读邮件时,你是否感到头皮发麻?作为曾经每天要处理200封邮件的市场分析师,我完全理解这种痛苦。直到发现Python的imaplib和email这对黄金组合,我的…...

nlp_structbert_sentence-similarity_chinese-large保姆级教程:前端React界面二次开发与定制化UI集成指南
nlp_structbert_sentence-similarity_chinese-large保姆级教程:前端React界面二次开发与定制化UI集成指南 1. 引言:为什么需要定制化UI? 如果你已经体验过基于StructBERT-Large的语义相似度工具,可能会发现它的基础界面虽然功能…...

避开Kaggle糖尿病预测的常见坑:数据预处理、特征解读与模型调优实战指南
避开Kaggle糖尿病预测的常见坑:数据预处理、特征解读与模型调优实战指南 在数据科学竞赛中,Kaggle的Pima印第安人糖尿病预测项目是许多初学者的第一个实战项目。表面上看,这似乎是一个简单的二分类问题——但当你真正开始建模时,…...
)
【英一】考研英语一历年真题及答案解析PDF电子版(1980-2025年)
【英一】考研英语一历年真题及答案解析PDF电子版(1980-2025年)考试时间 2026年全国硕士研究生招生考试定于12月20日-21日进行。小编整理了提供1980-2025年考研英语一完整真题集,含权威答案解析。PDF高清版本支持直接打印,便于考生…...

恒压供水系统:西门子224XP与昆仑TPC7062触摸屏的完美搭档
恒压供水西门子224XP昆仑tpc7062触摸屏.最多控制41泵,可直接用于项目工程 主要功能: 1、1-4台主泵十1辅泵、箱式、无负压式,一拖一,一拖多,一套程序适配多种供水模式。 2、实时报警和历史报警功能。 3、多种传感器支持,…...

论文降AI率完整操作教程:检测→定位→降AI→复查全流程详解
论文降AI率完整操作教程:检测→定位→降AI→复查全流程详解 很多同学一听"降AI率"就觉得很复杂。网上教程要么讲得太笼统(“用工具处理一下就好了”),要么一上来就推荐工具却不讲完整流程。 这篇教程不一样。我把降AI率…...
Stable Diffusion像素艺术工作站实战:Pixel Fashion Atelier Forge Scale调优指南
Stable Diffusion像素艺术工作站实战:Pixel Fashion Atelier Forge Scale调优指南 1. 像素时装锻造坊简介 Pixel Fashion Atelier是一款基于Stable Diffusion与Anything-v5的图像生成工作站,专为像素艺术创作而设计。与传统AI工具不同,它采…...

终极指南:Jellyfin豆瓣插件完整配置手册,30分钟打造中文媒体库
终极指南:Jellyfin豆瓣插件完整配置手册,30分钟打造中文媒体库 【免费下载链接】jellyfin-plugin-douban Douban metadata provider for Jellyfin 项目地址: https://gitcode.com/gh_mirrors/je/jellyfin-plugin-douban 还在为Jellyfin媒体库缺少…...