Spark大数据处理学习笔记(3.2.1)掌握RDD算子
该文章主要为完成实训任务,详细实现过程及结果见【http://t.csdn.cn/FArNP】
文章目录
- 一、准备工作
- 1.1 准备文件
- 1. 准备本地系统文件
- 2. 把文件上传到
- 1.2 启动Spark Shell
- 1. 启动HDFS服务
- 2. 启动Spark服务
- 3. 启动Spark Shell
- 二、掌握转换算子
- 2.1 映射算子 - map()
- 1. 映射算子功能
- 2. 映射算子案例
- 任务1、将rdd1每个元素翻倍得到rdd2
- 任务2、将rdd1每个元素平方得到rdd2
- 任务3、利用映射算子打印菱形
- 2.2 过滤算子 - filter()
- 1. 过滤算子功能
- 2. 过滤算子案例
- 任务1、过滤出列表中的偶数
- 任务2、过滤出文件中包含spark的行
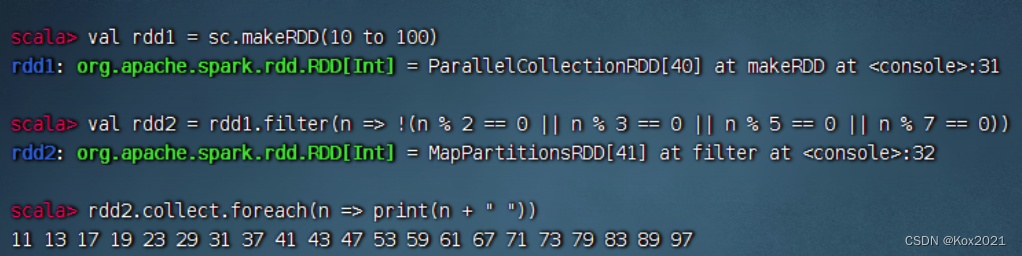
- 任务3、利用过滤算子输出[2000, 2500]之间的全部闰年
- 任务4、利用过滤算子输出[10, 100]之间的全部素数
- 2.3 扁平映射算子 - flatMap()
- 1. 扁平映射算子功能
- 2. 扁平映射算子案例
- 任务1、统计文件中单词个数
- 方法一、利用Scala来实现
- 方法二、利用Spark RDD来实现
- 2.4 按键归约算子 - reduceByKey()
- 1. 按键归约算子功能
- 2. 按键归约算子案例
- 任务1、在Spark Shell里计算学生总分
- 任务2、在IDEA里计算学生总分
- 2.5 合并算子 - union()
- 1. 合并算子功能
- 2. 合并算子案例
- 2.6 排序算子 - sortBy()
- 1. 排序算子功能
- 2. 排序算子案例
- 2.7 按键排序算子 - sortByKey()
- 1. 按键排序算子功能
- 2. 按键排序算子案例
- 2.8 连接算子
- 1. 内连接算子 - join()
- 2. 左外连接算子 - leftOuterJoin()
- 3. 右外连接算子 - rightOuterJoin()
- 4. 全外连接算子 - fullOuterJoin()
- 2.9 交集算子 - intersection()
- 2.10 去重算子 - distinct()
- 1. 去重算子案例
- 2. IP地址去重案例
- (十一)组合分组算子 - cogroup()
一、准备工作
1.1 准备文件
1. 准备本地系统文件
- 在
\home目录里创建words.txt

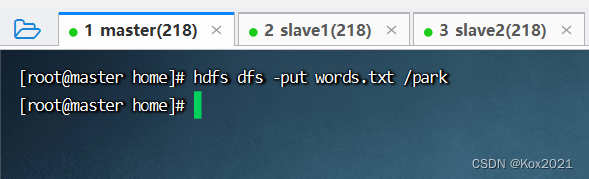
2. 把文件上传到
- 将
words.txt上传到HDFS系统的/park目录里
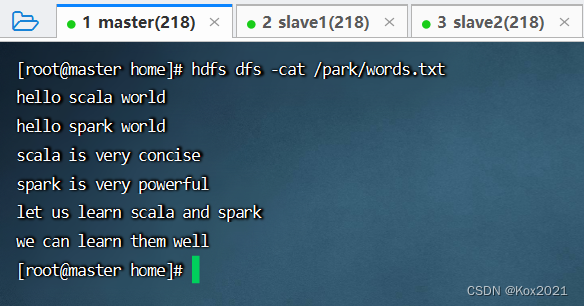
- 查看文件内容
1.2 启动Spark Shell
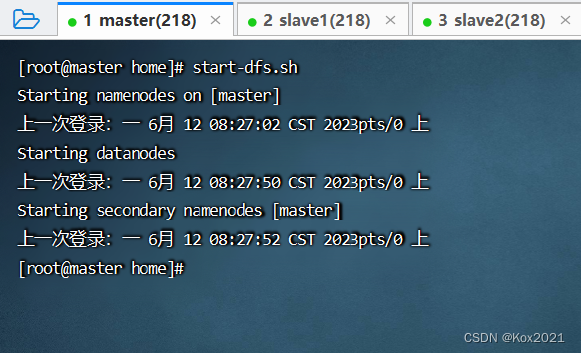
1. 启动HDFS服务
- 执行命令:
start-dfs.sh
2. 启动Spark服务
- 执行命令:
start-all.sh

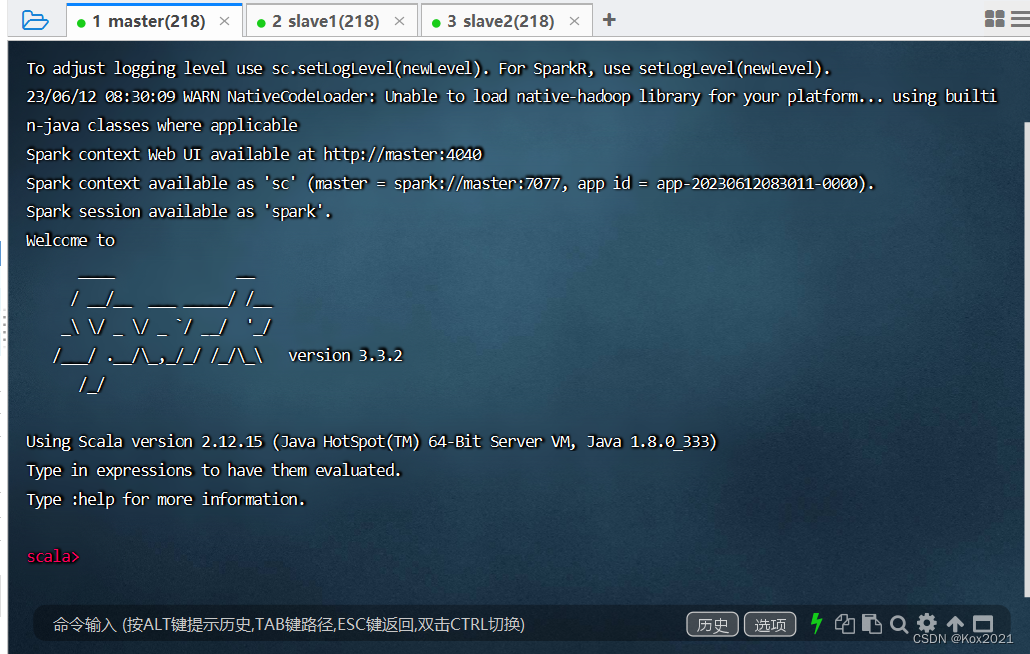
3. 启动Spark Shell
- 执行名命令:
spark-shell --master spark://master:7077
二、掌握转换算子
2.1 映射算子 - map()
1. 映射算子功能
- map()是一种转换算子,它接收一个函数作为参数,并把这个函数应用于RDD的每个元素,最后将函数的返回结果作为结果RDD中对应元素的值。
2. 映射算子案例
- 预备工作:创建一个RDD -
rdd1 - 执行命令:
val rdd1 = sc.parallelize(List(1, 2, 3, 4, 5, 6))

任务1、将rdd1每个元素翻倍得到rdd2
- 对rdd1应用map()算子,将rdd1中的每个元素平方并返回一个名为rdd2的新RDD
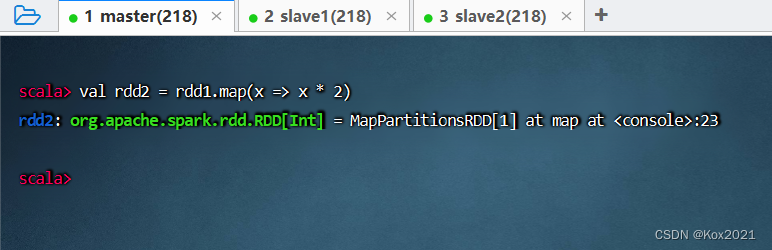
- 查看结果
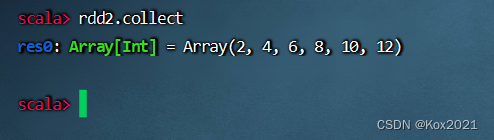
任务2、将rdd1每个元素平方得到rdd2
- 方法一、采用普通函数作为参数传给map()算子

- 方法二、采用下划线表达式作为参数传给map()算子

任务3、利用映射算子打印菱形
(1)Spark Shell里实现
-
右半菱形

-
加上前导空格,左半菱形

-
前导空格折半,显示菱形

(2)在IDEA里创建项目实现 -
创建Maven项目
-
将
java目录改成scala目录
-
在
pom.xml文件里添加相关依赖和设置源程序目录
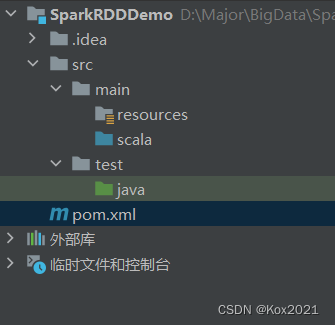
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>cn.kox.rdd</groupId><artifactId>SparkRDDDemo</artifactId><version>1.0-SNAPSHOT</version><dependencies><dependency><groupId>org.scala-lang</groupId><artifactId>scala-library</artifactId><version>2.12.15</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.12</artifactId><version>3.1.3</version></dependency></dependencies><build><sourceDirectory>src/main/scala</sourceDirectory></build><properties><maven.compiler.source>8</maven.compiler.source><maven.compiler.target>8</maven.compiler.target><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding></properties></project>
- 添加日志属性文件

log4j.rootLogger=ERROR, stdout, logfile
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/rdd.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n- 创建
hdfs-site.xml文件,允许客户端访问集群数据节点

<?xml version="1.0" encoding="UTF-8"?>
<configuration><property><description>only config in clients</description><name>dfs.client.use.datanode.hostname</name><value>true</value></property>
</configuration>- 创建
cn.kox.rdd.day01包
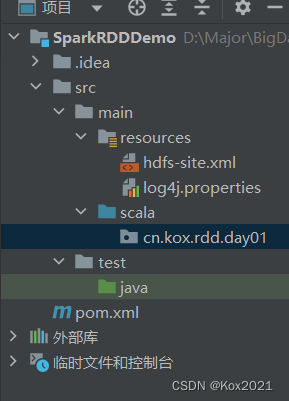
- 在
cn.kox.rdd.day01包里创建Example01单例对象

package cn.kox.rdd.day01import org.apache.spark.{SparkConf, SparkContext}import scala.collection.mutable.ListBuffer
import scala.io.StdIn/*** @ClassName: Example01* @Author: Kox* @Data: 2023/6/12* @Sketch:*/
object Example01 {def main(args: Array[String]): Unit = {// 创建Spark配置对象val conf = new SparkConf().setAppName("PrintDiamond") // 设置应用名称.setMaster("local[*]") // 设置主节点位置(本地调试)// 基于Spark配置对象创建Spark容器val sc = new SparkContext(conf)// 输入一个奇数print("输入一个奇数:")val n = StdIn.readInt()//判断n的奇偶性if (n % 2 == 0) {println("温馨提示:你输入的不是奇数")return }// 创建一个可变列表val list = new ListBuffer[Int]()// 给列表赋值(1 to n by 2).foreach(list.append(_))(n - 2 to 1 by -2).foreach(list.append(_))// 基于列表创建rddval rdd = sc.makeRDD(list)// 对rdd进行映射操作val rdd1 = rdd.map(i => " " * ((n - i) / 2) + "*" * i)// 输出rdd1结果rdd1.collect.foreach(println)}
}
- 运行程序,查看结果

2.2 过滤算子 - filter()
1. 过滤算子功能
- filter(func):通过函数func对源RDD的每个元素进行过滤,并返回一个新RDD,一般而言,新RDD元素个数会少于原RDD。
2. 过滤算子案例
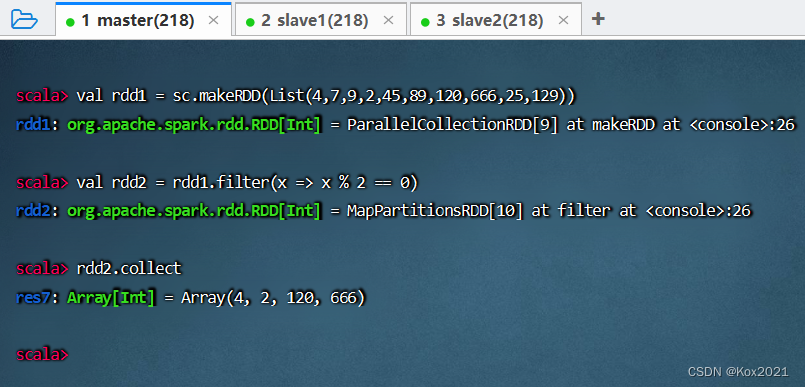
任务1、过滤出列表中的偶数
- 整数(Integer):奇数(odd number)+ 偶数(even number)
- 基于列表创建RDD,然后利用过滤算子得到偶数构成的新RDD
- 方法一、将匿名函数传给过滤算子
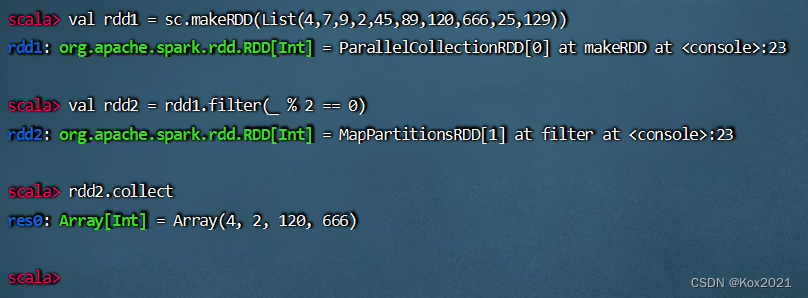
- 方法二、用神奇占位符改写传入过滤算子的匿名函数
任务2、过滤出文件中包含spark的行
- 查看源文件
/park/words.txt内容

- 执行命令:
val lines= sc.textFile("/park/words.txt"),读取文件/park/words.txt生成RDD -lines

- 执行命令:
val sparkLines = lines.filter(_.contains("spark")),过滤包含spark的行生成RDD - sparkLines

- 执行命令:
sparkLines.collect,查看sparkLines内容,可以采用遍历算子,分行输出内容
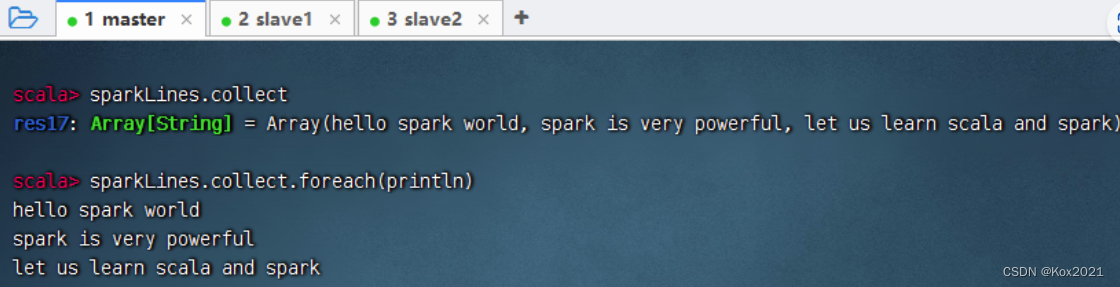
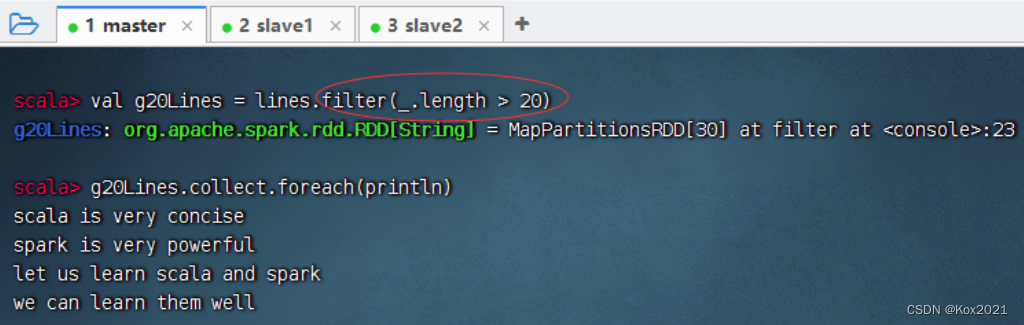
- 输出长度超过20的行
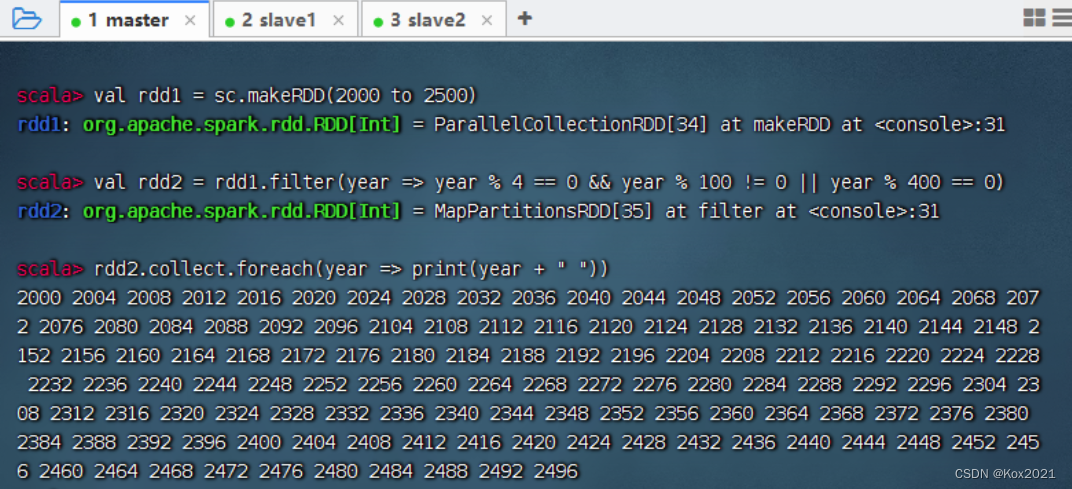
任务3、利用过滤算子输出[2000, 2500]之间的全部闰年
- 传统做法,利用循环结构嵌套选择结构来实现

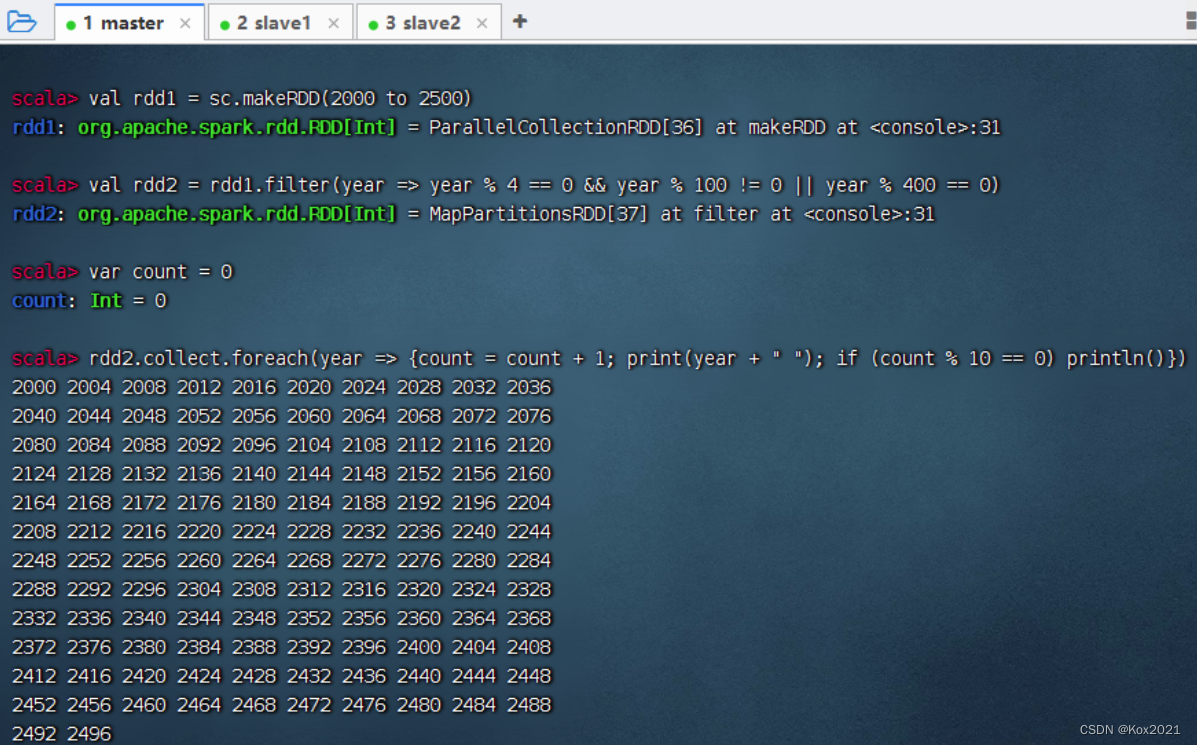
- 要求每行输出10个数

- 采用过滤算子来实现
- 要求每行输出10个数
任务4、利用过滤算子输出[10, 100]之间的全部素数
- 过滤算子:
filter(n => !(n % 2 == 0 || n % 3 == 0 || n % 5 == 0 || n % 7 == 0))
2.3 扁平映射算子 - flatMap()
1. 扁平映射算子功能
- flatMap()算子与map()算子类似,但是每个传入给函数func的RDD元素会返回0到多个元素,最终会将返回的所有元素合并到一个RDD。
2. 扁平映射算子案例
任务1、统计文件中单词个数
- 读取文件,生成RDD - rdd1,查看其内容和元素个数

- 对于rdd1按空格拆分,做映射,生成新RDD - rdd2
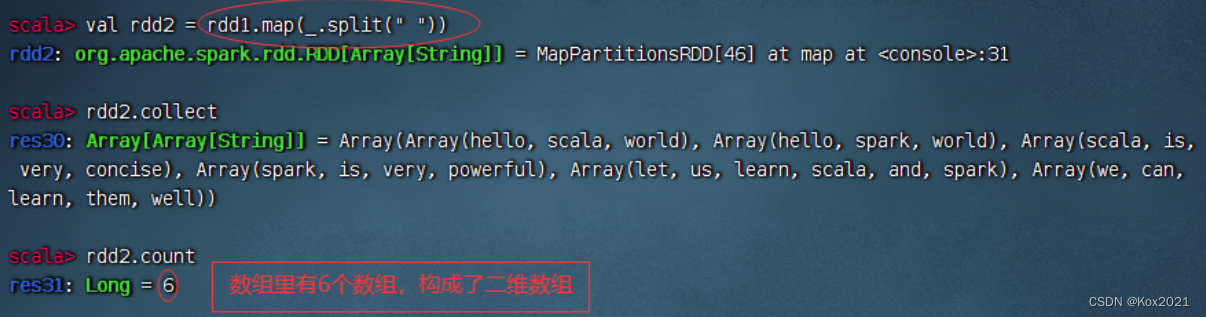
- 对于rdd1按空格拆分,做扁平映射,生成新RDD - rdd3,有一个降维处理的效果

- 统计结果:文件里有25个单词
方法一、利用Scala来实现
- 利用列表的
flatten函数 - 在
cn.kox.rdd.day01包里创建Example02单例对象
package cn.kox.rdd.day01import org.apache.spark.{SparkConf, SparkContext}/*** @ClassName: Example02* @Author: Kox* @Data: 2023/6/12* @Sketch:*/
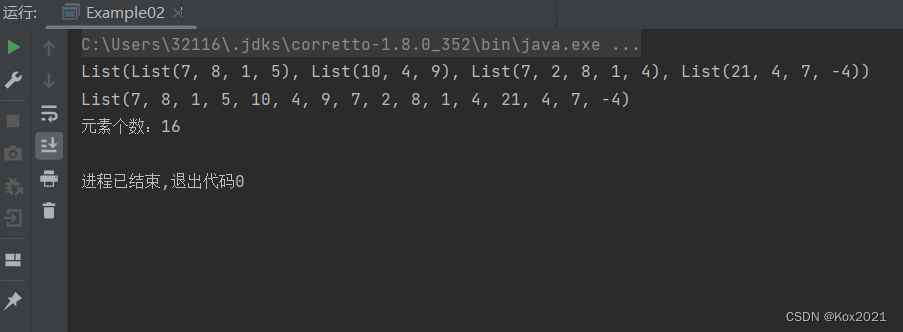
object Example02 {def main(args: Array[String]): Unit = {// 创建不规则二维列表val mat = List(List(7, 8, 1, 5),List(10, 4, 9),List(7, 2, 8, 1, 4),List(21, 4, 7, -4))// 输出二维列表println(mat)// 将二维列表扁平化为一维列表val arr = mat.flatten// 输出一维列表println(arr)// 输出元素个数println("元素个数:" + arr.size)}
}- 运行程序,查看结果
方法二、利用Spark RDD来实现
- 利用flatMap算子
- 在
cn.kox.rdd.day01包里创建Example03单例对象
package cn.kox.rdd.day01import org.apache.spark.{SparkConf, SparkContext}
/*** @ClassName: Example03* @Author: Kox* @Data: 2023/6/12* @Sketch:*/
object Example03 {def main(args: Array[String]): Unit = {// 创建Spark配置对象val conf = new SparkConf().setAppName("PrintDiamond") // 设置应用名称.setMaster("local[*]") // 设置主节点位置(本地调试)// 基于Spark配置对象创建Spark容器val sc = new SparkContext(conf)// 创建不规则二维列表val mat = List(List(7, 8, 1, 5),List(10, 4, 9),List(7, 2, 8, 1, 4),List(21, 4, 7, -4))// 基于二维列表创建rdd1val rdd1 = sc.makeRDD(mat)// 输出rdd1rdd1.collect.foreach(x => print(x + " "))println()// 进行扁平化映射val rdd2 = rdd1.flatMap(x => x.toString.substring(5, x.toString.length - 1).split(", "))// 输出rdd2rdd2.collect.foreach(x => print(x + " "))println()// 输出元素个数println("元素个数:" + rdd2.count)}
}- 运行程序,查看结果

2.4 按键归约算子 - reduceByKey()
1. 按键归约算子功能
- reduceByKey()算子的作用对像是元素为(key,value)形式(Scala元组)的RDD,使用该算子可以将相同key的元素聚集到一起,最终把所有相同key的元素合并成一个元素。该元素的key不变,value可以聚合成一个列表或者进行求和等操作。最终返回的RDD的元素类型和原有类型保持一致。
2. 按键归约算子案例
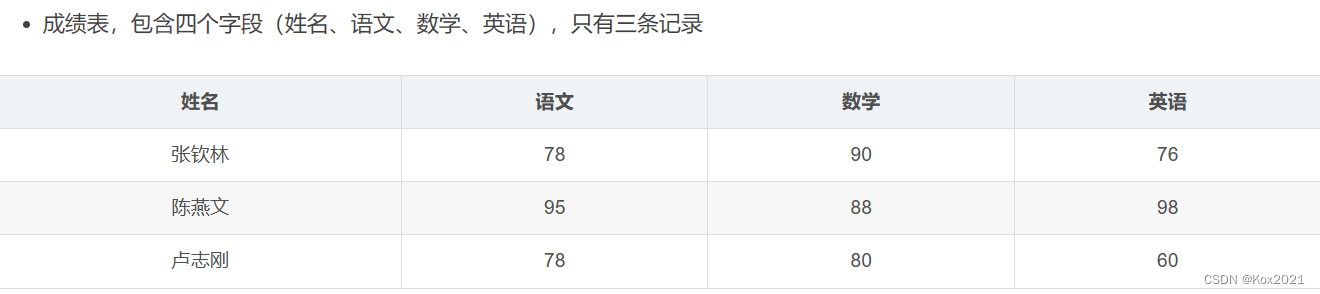
任务1、在Spark Shell里计算学生总分
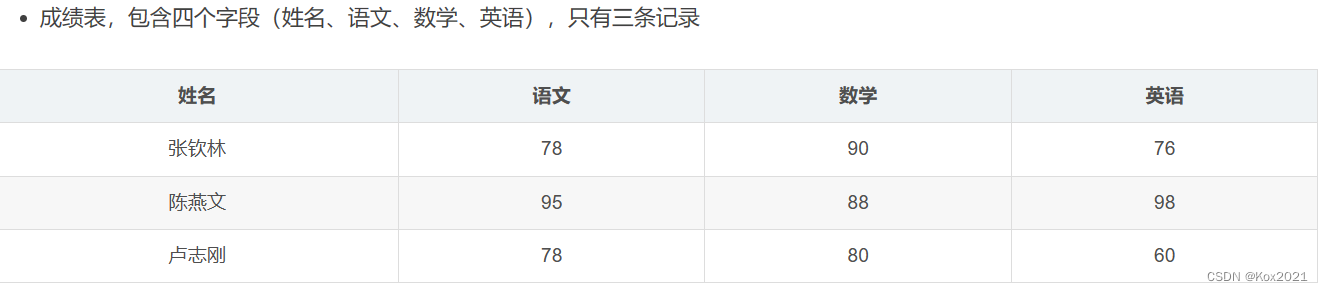
- 创建成绩列表scores,基于成绩列表创建rdd1,对rdd1按键归约得到rdd2,然后查看rdd2内容
- agg: aggregation 聚合值
- cur: current 当前值
val scores = List(("张钦林", 78), ("张钦林", 90), ("张钦林", 76),("陈燕文", 95), ("陈燕文", 88), ("陈燕文", 98),("卢志刚", 78), ("卢志刚", 80), ("卢志刚", 60))
val rdd1 = sc.makeRDD(scores)
val rdd2 = rdd1.reduceByKey((x, y) => x + y)
rdd2.collect.foreach(println)
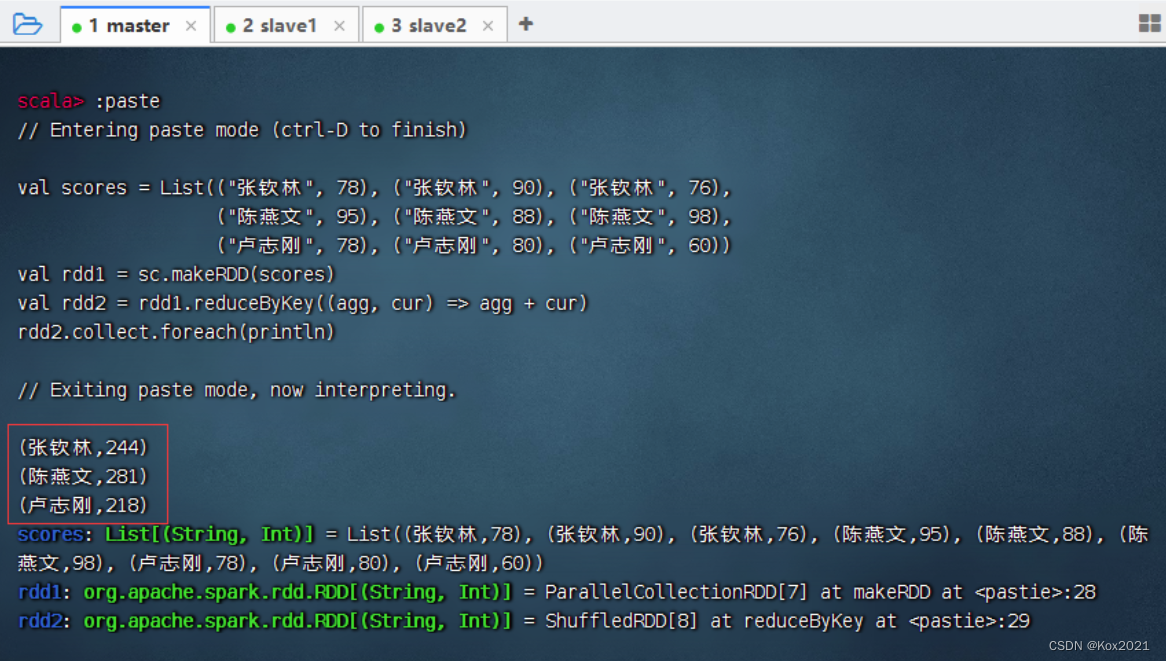
- 可以采用神奇的占位符
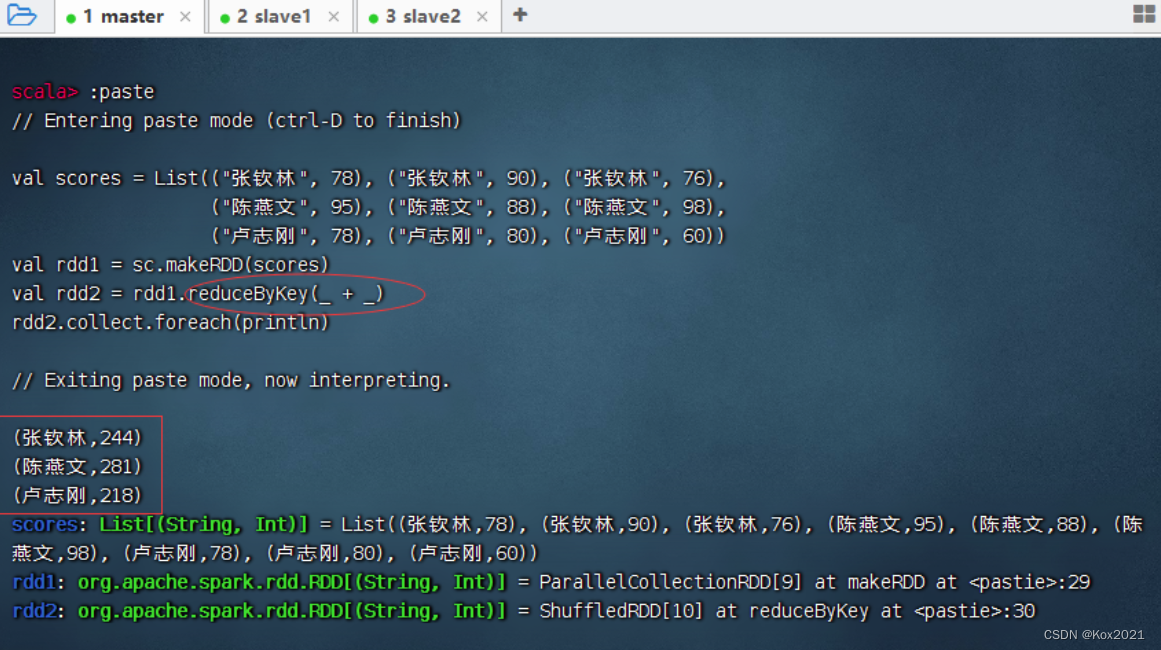
任务2、在IDEA里计算学生总分
第一种方式:读取二元组成绩列表
- 在
cn.kox.rdd.day02包里创建CalculateScoreSum01单例对象
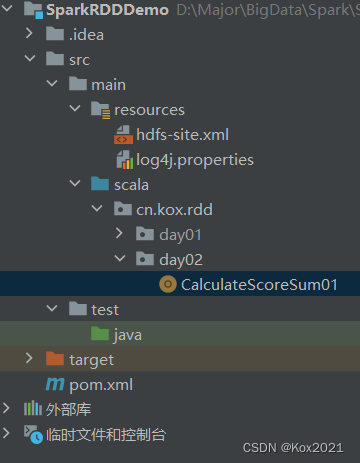
package cn.kox.rdd.day02import org.apache.spark.{SparkConf, SparkContext}/*** @ClassName: CalculateScoreSum01* @Author: Kox* @Data: 2023/6/12* @Sketch:*/
object CalculateScoreSum01 {def main(args: Array[String]): Unit = {// 创建Spark配置对象val conf = new SparkConf().setAppName("PrintDiamond") // 设置应用名称.setMaster("local[*]") // 设置主节点位置(本地调试)// 基于Spark配置对象创建Spark容器val sc = new SparkContext(conf)// 创建二元组成绩列表val scores = List(("张钦林", 78), ("张钦林", 90), ("张钦林", 76),("陈燕文", 95), ("陈燕文", 88), ("陈燕文", 98),("卢志刚", 78), ("卢志刚", 80), ("卢志刚", 60))// 基于二元组成绩列表创建RDDval rdd1 = sc.makeRDD(scores)// 对成绩RDD进行按键归约处理val rdd2 = rdd1.reduceByKey(_ + _)// 输出归约处理结果rdd2.collect.foreach(println)}
}- 运行程序,查看结果

第二种方式:读取四元组成绩列表 - 在
cn.kox.rdd.day02包里创建CalculateScoreSum02单例对象

package cn.kox.rdd.day02import org.apache.spark.{SparkConf, SparkContext}import scala.collection.mutable.ListBuffer
/*** @ClassName: CalculateScoreSum02* @Author: Kox* @Data: 2023/6/12* @Sketch:*/
object CalculateScoreSum02 {def main(args: Array[String]): Unit = {// 创建Spark配置对象val conf = new SparkConf().setAppName("PrintDiamond") // 设置应用名称.setMaster("local[*]") // 设置主节点位置(本地调试)// 基于Spark配置对象创建Spark容器val sc = new SparkContext(conf)// 创建四元组成绩列表val scores = List(("张钦林", 78, 90, 76),("陈燕文", 95, 88, 98),("卢志刚", 78, 80, 60))// 将四元组成绩列表转化成二元组成绩列表val newScores = new ListBuffer[(String, Int)]()// 通过遍历算子遍历四元组成绩列表scores.foreach(score => {newScores.append(Tuple2(score._1, score._2))newScores.append(Tuple2(score._1, score._3))newScores.append(Tuple2(score._1, score._4))})// 基于二元组成绩列表创建RDDval rdd1 = sc.makeRDD(newScores)// 对成绩RDD进行按键归约处理val rdd2 = rdd1.reduceByKey(_ + _)// 输出归约处理结果rdd2.collect.foreach(println)}
}- 运行程序,查看结果

2.5 合并算子 - union()
1. 合并算子功能
- union()算子将两个RDD合并为一个新的RDD,主要用于对不同的数据来源进行合并,两个RDD中的数据类型要保持一致。
2. 合并算子案例
- 创建两个RDD,合并成一个新RDD

- 课堂练习:将两个二元组成绩表合并

- 在集合运算里,并集符号:∪ \cup∪,并集运算:A ∪ B A \cup BA∪B
- 在集合运算里,交集符号:∩ \cap∩,交集运算:A ∩ B A \cap BA∩B
- 在集合运算里,补集运算:A ˉ \bar A
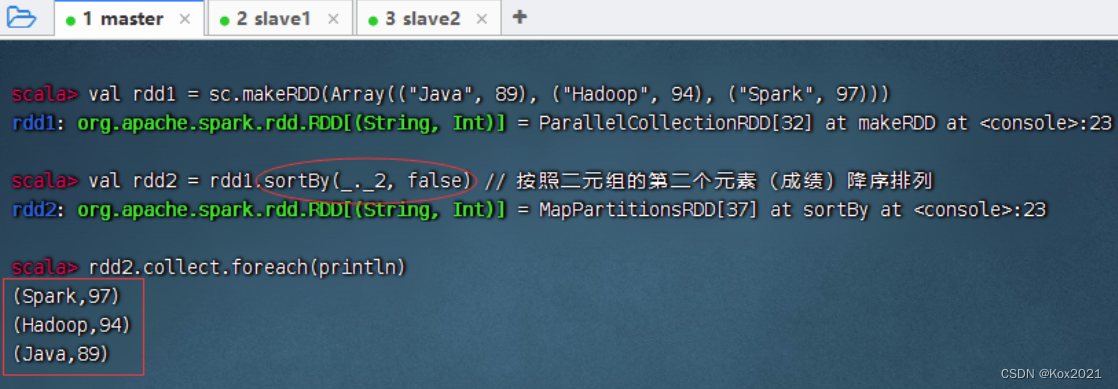
2.6 排序算子 - sortBy()
1. 排序算子功能
- sortBy()算子将RDD中的元素按照某个规则进行排序。该算子的第一个参数为排序函数,第二个参数是一个布尔值,指定升序(默认)或降序。若需要降序排列,则需将第二个参数置为false。
2. 排序算子案例
- 一个数组中存放了三个元组,将该数组转为RDD集合,然后对该RDD按照每个元素中的第二个值进行降序排列。
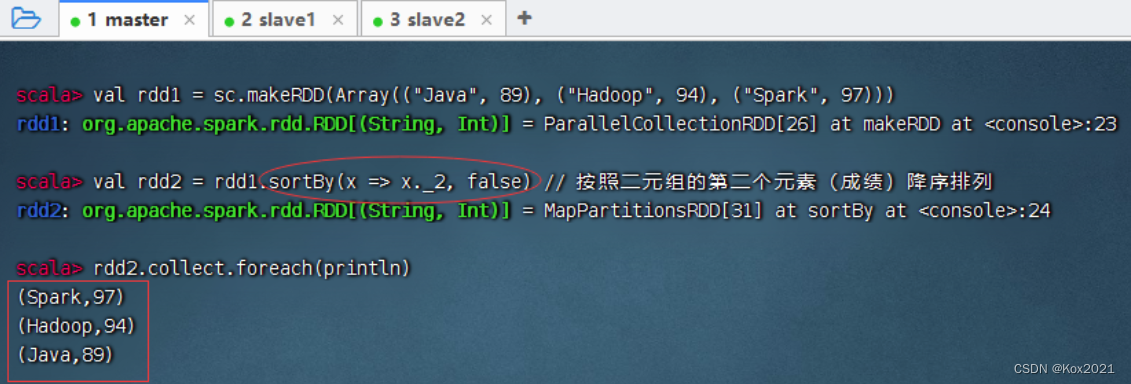
- sortBy(x=>x._2,false)中的x代表rdd1中的每个元素。由于rdd1的每个元素是一个元组,因此使用x._2取得每个元素的第二个值。当然,sortBy(x=>x.2,false)也可以直接简化为sortBy(._2,false)。
2.7 按键排序算子 - sortByKey()
1. 按键排序算子功能
- sortByKey()算子将(key, value)形式的RDD按照key进行排序。默认升序,若需降序排列,则可以传入参数false。
2. 按键排序算子案例
- 将三个二元组构成的RDD按键先降序排列,然后升序排列

- 其实,用排序算子也是可以搞定的

2.8 连接算子
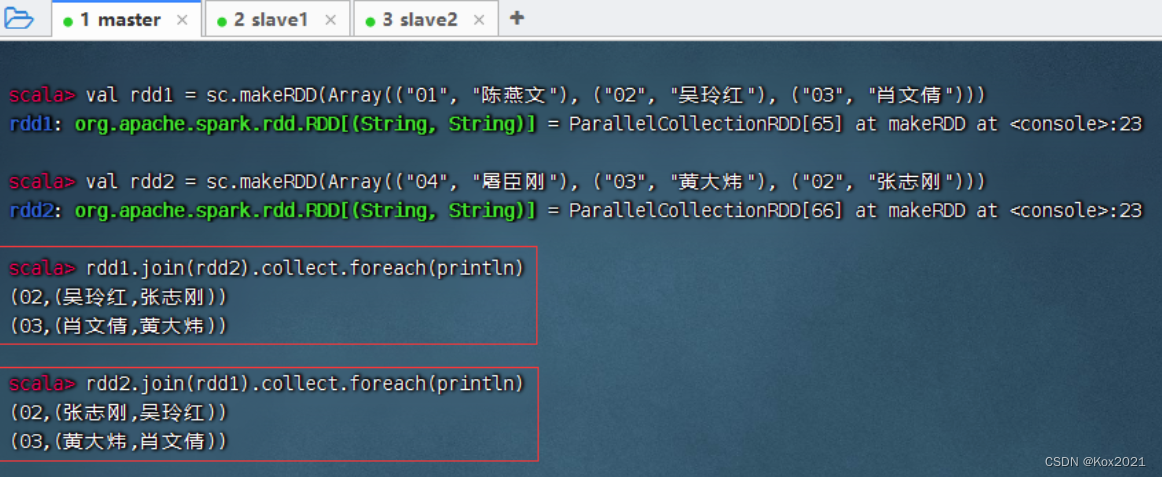
1. 内连接算子 - join()
- join()算子将两个(key, value)形式的RDD根据key进行连接操作,相当于数据库的内连接(Inner Join),只返回两个RDD都匹配的内容。
- 将rdd1与rdd2进行内连接
2. 左外连接算子 - leftOuterJoin()
- leftOuterJoin()算子与数据库的左外连接类似,以左边的RDD为基准(例如rdd1.leftOuterJoin(rdd2),以rdd1为基准),左边RDD的记录一定会存在。例如,rdd1的元素以(k,v)表示,rdd2的元素以(k, w)表示,进行左外连接时将以rdd1为基准,rdd2中的k与rdd1的k相同的元素将连接到一起,生成的结果形式为(k, (v, Some(w))。rdd1中其余的元素仍然是结果的一部分,元素形式为(k,(v, None)。Some和None都属于Option类型,Option类型用于表示一个值是可选的(有值或无值)。若确定有值,则使用Some(值)表示该值;若确定无值,则使用None表示该值。
- rdd1与rdd2进行左外连接

3. 右外连接算子 - rightOuterJoin()
- rightOuterJoin()算子的使用方法与leftOuterJoin()算子相反,其与数据库的右外连接类似,以右边的RDD为基准(例如rdd1.rightOuterJoin(rdd2),以rdd2为基准),右边RDD的记录一定会存在。
- rdd1与rdd2进行右外连接
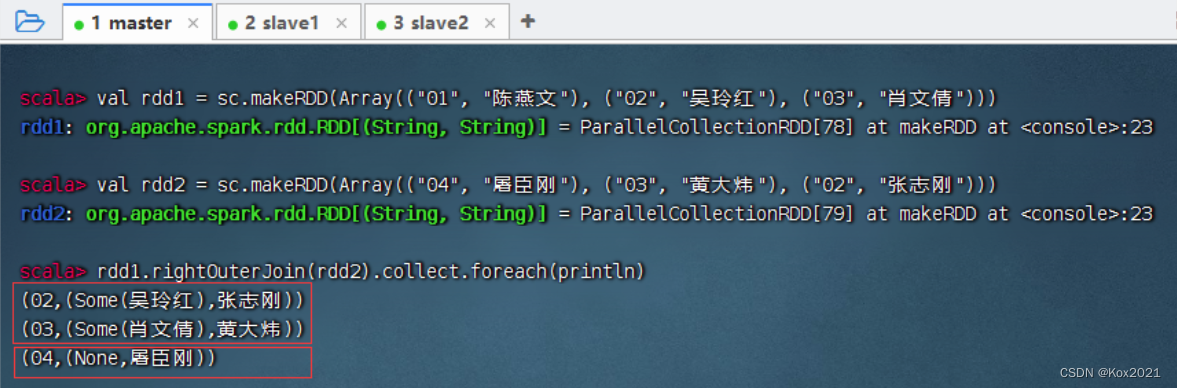
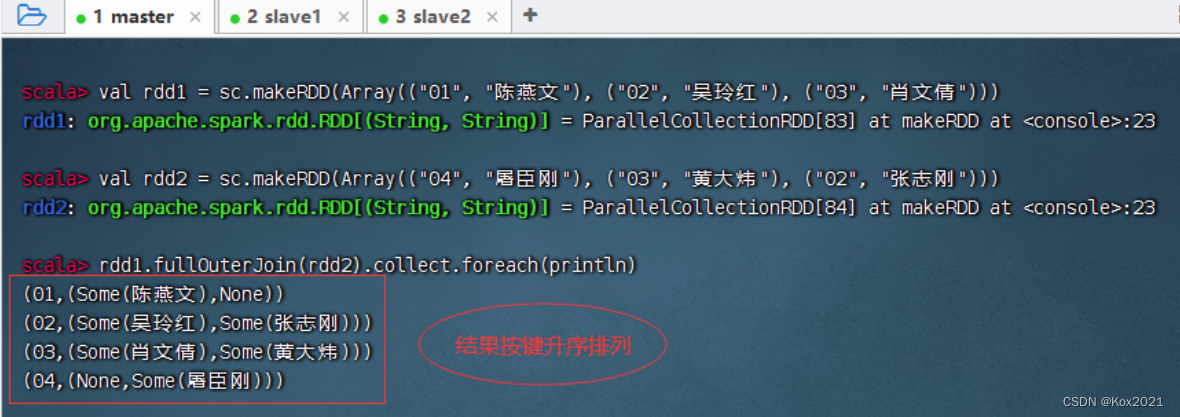
4. 全外连接算子 - fullOuterJoin()
- fullOuterJoin()算子与数据库的全外连接类似,相当于对两个RDD取并集,两个RDD的记录都会存在。值不存在的取None。
- rdd1与rdd2进行全外连接
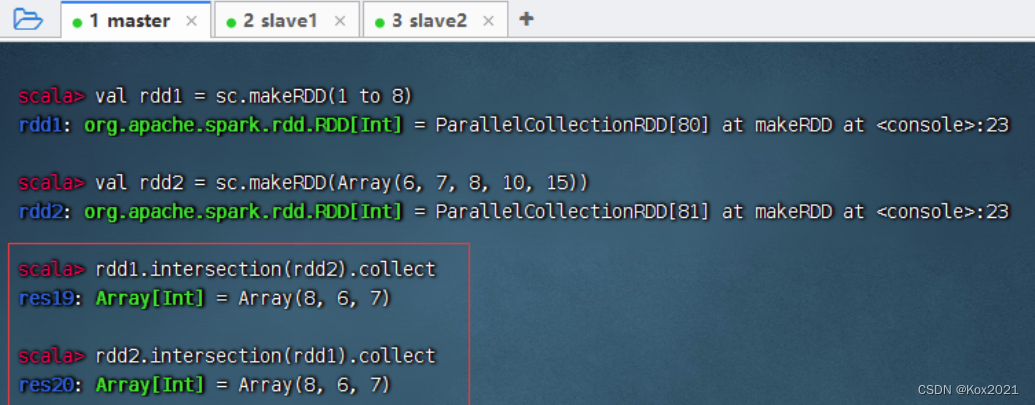
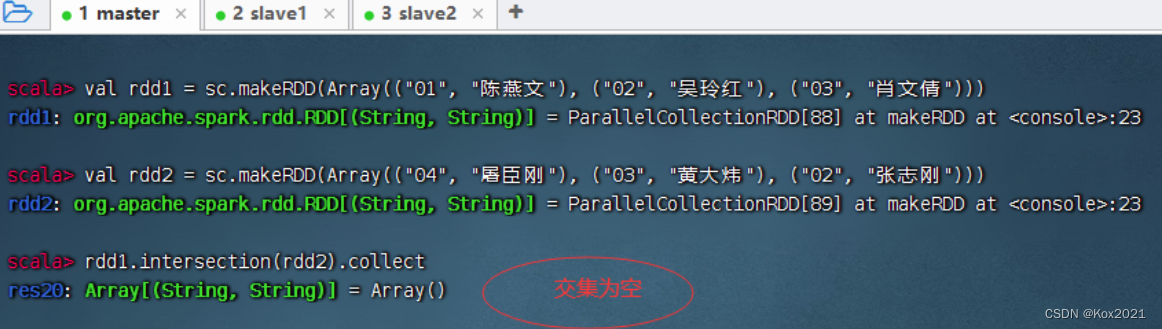
2.9 交集算子 - intersection()
- intersection()算子对两个RDD进行交集操作,返回一个新的RDD。要求两个算子类型要一致。
- rdd1与rdd2进行交集操作,满足交换律
- A ∩ B ≠ ϕ
2.10 去重算子 - distinct()
- distinct()算子对RDD中的数据进行去重操作,返回一个新的RDD。有点类似与集合的不允许重复元素。
1. 去重算子案例
- 去掉rdd中重复的元素

2. IP地址去重案例
- 在项目根目录创建ips.txt文件

192.168.234.21
192.168.234.22
192.168.234.21
192.168.234.21
192.168.234.23
192.168.234.21
192.168.234.21
192.168.234.21
192.168.234.25
192.168.234.21
192.168.234.21
192.168.234.26
192.168.234.21
192.168.234.27
192.168.234.21
192.168.234.27
192.168.234.21
192.168.234.29
192.168.234.21
192.168.234.26
192.168.234.21
192.168.234.25
192.168.234.25
192.168.234.21
192.168.234.22
192.168.234.21- 在
cn.kox.rdd.day03包里创建DistinctIPs单例对象
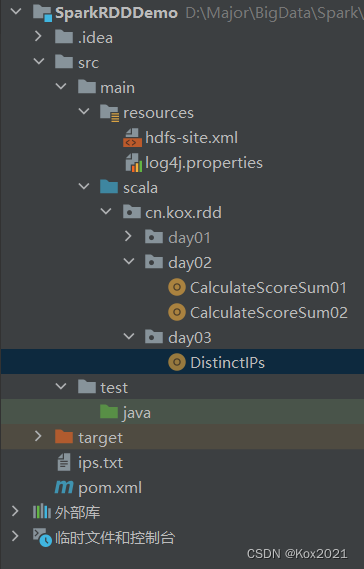
package cn.kox.rdd.day03import org.apache.spark.{SparkConf, SparkContext}/*** @ClassName: DistinctIPs* @Author: Kox* @Data: 2023/6/12* @Sketch:*/
object DistinctIPs {def main(args: Array[String]): Unit = {// 创建Spark配置对象val conf = new SparkConf().setAppName("DistinctIPs ") // 设置应用名称.setMaster("local[*]") // 设置主节点位置(本地调试)// 基于Spark配置对象创建Spark容器val sc = new SparkContext(conf)// 读取本地IP地址文件,得到RDDval ips = sc.textFile("D:\\Major\\BigData\\Spark\\SparkLesson2023U\\SparkRDDDemo\\ips.txt")// rdd去重再输出ips.distinct.collect.foreach(println)}
}- 运行程序,查看结果

- 修改代码,保存去重结果到本地目录
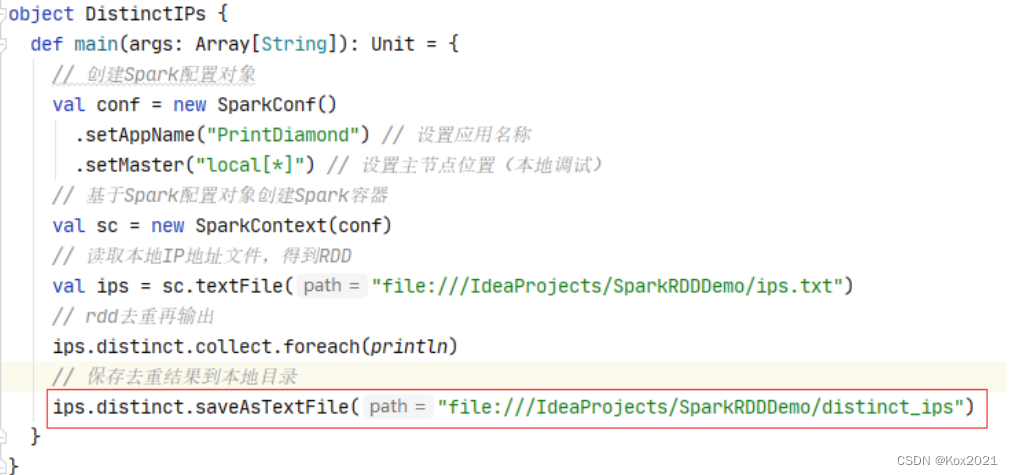
(十一)组合分组算子 - cogroup()
- cogroup()算子对两个(key, value)形式的RDD根据key进行组合,相当于根据key进行并集操作。例如,rdd1的元素以(k, v)表示,rdd2的元素以(k, w)表示,执行rdd1.cogroup(rdd2)生成的结果形式为(k, (Iterable, Iterable))。
- rdd1与rdd2进行组合分组操作

相关文章:
Spark大数据处理学习笔记(3.2.1)掌握RDD算子
该文章主要为完成实训任务,详细实现过程及结果见【http://t.csdn.cn/FArNP】 文章目录 一、准备工作1.1 准备文件1. 准备本地系统文件2. 把文件上传到 1.2 启动Spark Shell1. 启动HDFS服务2. 启动Spark服务3. 启动Spark Shell 二、掌握转换算子2.1 映射算子 - map()…...

lammps初级:石墨烯、金属材料、纳米流体、热传导、多成分体系、金属、半导体材料的辐照、自建分子力场、MOFS、H2/CO2混合气体等模拟
1 LAMMPS的基础入门——初识LAMMPS是什么?能干什么?怎么用? 1.1 LAMMPS在win10和ubuntu系统的安装及使用 1.2 in文件结构格式 1.3 in文件基本语法:结合实例,讲解in文件常用命令 1.4 data文件格式 1.5 LAMMPS常见错误解…...

【MarkerDown】CSDN Markdown之时序图sequenceDiagram详解
CSDN Markdown之时序图sequenceDiagram详解 序列图 sequenceDiagram参与者与组参与者 participant拟人符号 actor别名 as组 box 消息(连线)激活/失活 activate/deactivate备注 Note循环 loop备选 Alt并行 par临界区 critical中断 break背景高亮 rect注释 %%转义字符的实体代码序…...
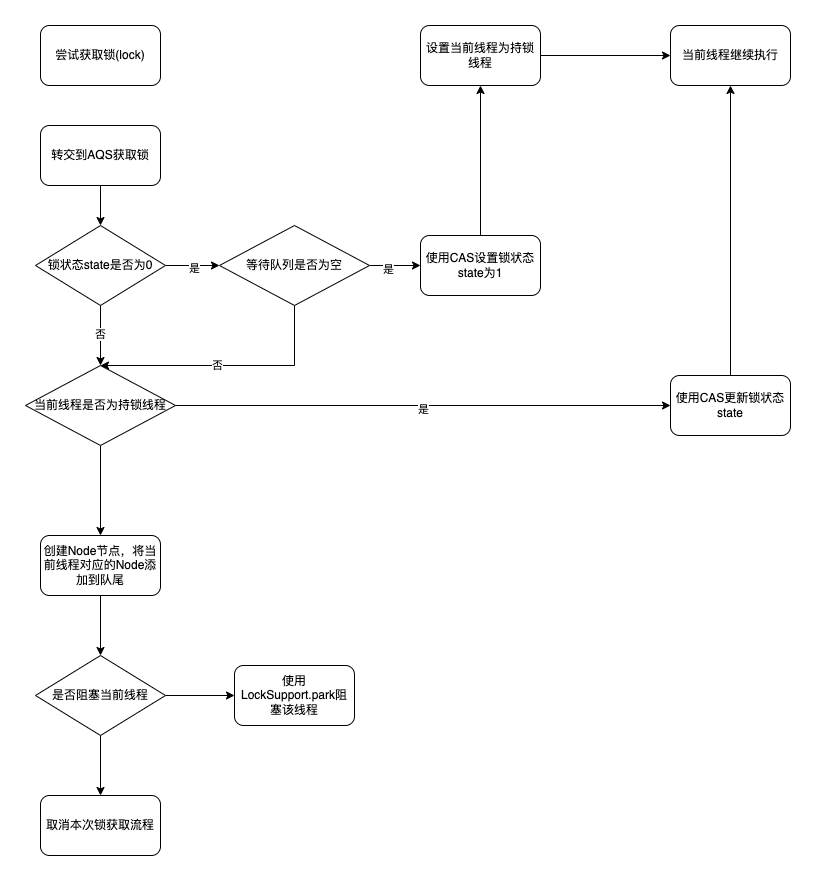
ReentrantLock实现原理-公平锁
在ReentrantLock实现原理(1)一节中,我们了解了ReentrantLock非公平锁的获取流程,在本节中我们来看下ReentrantLock公平锁的创建以及锁管理流程 创建ReentrantLock公平锁 创建公平锁代码如下: ReentrantLock reentrantLock new ReentrantL…...

掌握Scala数据结构(2)MAP、TUPLE、SET
一、映射 (Map) (一)不可变映射 1、创建不可变映射 创建不可变映射mp,用键->值的形式 创建不可变映射mp,用(键, 值)的形式 注意:Map是特质(Scala里的trait,相当于Java里的interface&#…...

flutter:文件系统目录、文件读写
参考 参考:老孟 文件存储和网络请求 数据存储 Dart的 IO 库包含了文件读写的相关类,它属于 Dart 语法标准的一部分,所以通过 Dart IO 库,无论是 Dart VM 下的脚本还是 Flutter,都是通过 Dart IO 库来操作文件的。但…...

计算机提示“找不到vcruntime140.dll,无法继续执行代码可”以这样子修复
首先,对于那些不熟悉的人来说,vcruntime140.dll是一个关键文件,用于在Windows操作系统上运行使用C语言编写的大型应用程序。如果你正在运行或安装这样的应用程序,但找不到vcruntime140.dll文件,那么你的应用程序可能无…...
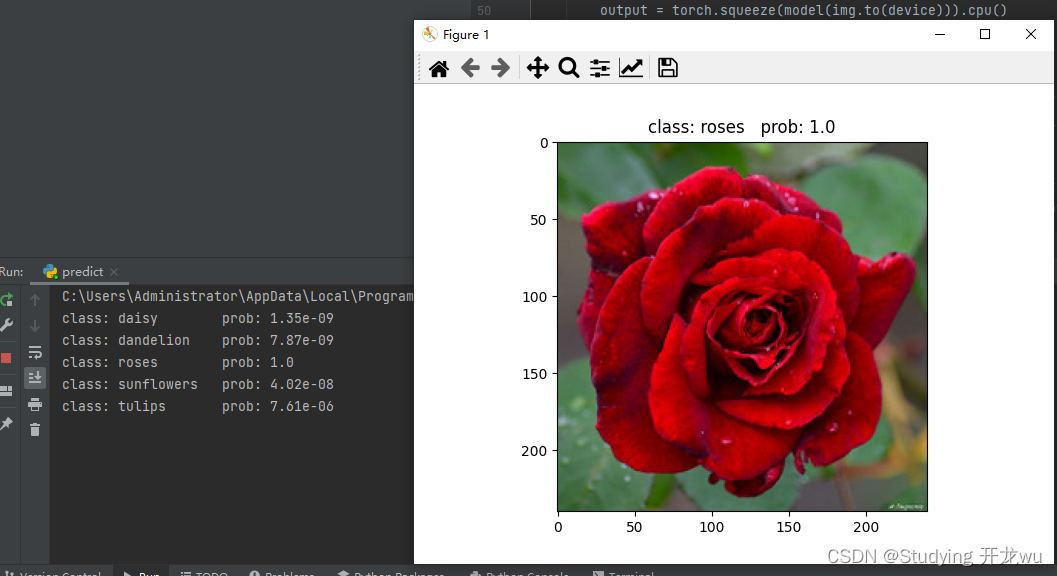
深度学习pytorch实战五:基于ResNet34迁移学习的方法图像分类篇自建花数据集图像分类(5类)超详细代码
1.数据集简介 2.模型相关知识 3.split_data.py——训练集与测试集划分 4.model.py——定义ResNet34网络模型 5.train.py——加载数据集并训练,训练集计算损失值loss,测试集计算accuracy,保存训练好的网络参数 6.predict.py——利用训练好的网…...
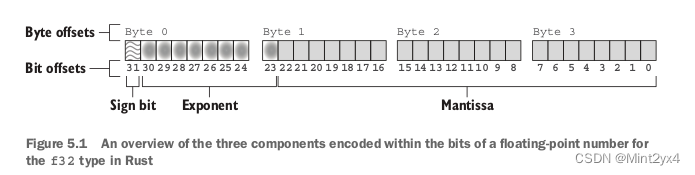
Rust in Action笔记 第五章 深入理解数据
如果希望看到f32类型的数转换成整型数字u32类型,需要在unsafe包裹下调用std::mem::transmute(data),因为在安全的Rust语法中没有把整型数据按照bit转换成浮点数据的实现,如果想要看到浮点数的二进制输出(通过{:b})&…...

Cocos creator实现飞机大战空中大战《战击长空》小游戏资源及代码
Cocos creator实现飞机大战空中大战《战击长空》小游戏资源及代码 最近在学习Cocos Creator,作为新手,刚刚开始学习Cocos Creator,刚刚入门,这里记录一下飞机大战小游戏实现。 https://wxaurl.cn/VEgRy2eTMyi 一 安装CocosDashBo…...

2.4 逻辑代数的基本定理
学习目标: 如果我要学习逻辑代数的基本定理,我会采取以下步骤: 1. 学习基本概念:首先,我会花时间了解逻辑代数的基本概念,如逻辑运算符(合取、析取、否定等)、真值表、逻辑等价性等…...

适用于 Linux 的 Windows 子系统wsl文档
参考链接:https://learn.microsoft.com/zh-cn/windows/wsl/ 鸟哥的Linux私房菜:http://cn.linux.vbird.org/ http://cn.linux.vbird.org/linux_basic/linux_basic.php http://cn.linux.vbird.org/linux_server/ 目录 安装列出可用的 Linux 发行版列出已…...
C++特殊类的设计与类型转换
特殊类的设计与类型转换 特殊类的设计请设计一个类,只能在堆上创建对象请设计一个类,只能在栈上创建对象请设计一个类,只能创建一个对象(单例模式) C的类型转换 特殊类的设计 请设计一个类,只能在堆上创建对象 通过new创建的类就…...

如何通过关键词搜索API接口
如果你是一位电商运营者或者是想要进行1688平台产品调研的人员,你可能需要借助API接口来获取你所需要的信息。在这篇文章中,我们将会讨论如何通过关键词搜索API接口获取1688的商品详情。 第一步:获取API接口的授权信息 在使用API接口前&…...

智驾域控新战争打响,谁在抢跑?
智能驾驶域控制器赛道,已经成为了时下最为火热的市场焦点之一。 最近,头部Tier1均胜电子公布了全球首批基于高通Snapdragon Ride第二代芯片平台的智能驾驶域控制器产品nDriveH,在这一赛道中显得格外引人注意。 就在不久之前,均胜…...

Android 13无源码应用去掉无资源ID的按钮
Android Wifionly项目,客户要求去掉谷歌联系人里的 手机联系人按钮 需求分析 无应用源码,只能通过系统侧去修改 首先通过 Android Studio 工具 uiautomatorviewer 获取父控件资源ID chip_group ,然后通过遍历获取子控件去掉目标按钮 --- a/frameworks/base/core/java/andr…...
,正刊,SCIEEI双检,进化计算、模糊集和人工神经网络在数据不平衡中应用)
【SCI征稿】中科院2区(TOP),正刊,SCIEEI双检,进化计算、模糊集和人工神经网络在数据不平衡中应用
【期刊简介】IF:8.0-9.0,JCR1区,中科院2区(TOP) 【检索情况】SCIE&EI 双检,正刊 【数据库收录年份】2004年 【国人占比】22.78%(期刊国际化程度高) 【征稿领域】进化计算、模…...
)
Android Audio开发——AAudio基础(十五)
AAudio 是一个自 Android O 引入的新的 Android C API。它主要是为需要低延迟的高性能音频应用设计的。应用程序通过直接从流中读取或向流中写入数据来与 AAudio 通信,但它只包含基本的音频输入输出能力。 一、AAudio概述 AAudio 在应用程序和 Android 设备上的音频输入输出之…...
SDK接口远程调试【内网穿透】
文章目录 1.测试环境2.本地配置3. 内网穿透3.1 下载安装cpolar内网穿透3.2 创建隧道 4. 测试公网访问5. 配置固定二级子域名5.1 保留一个二级子域名5.2 配置二级子域名 6. 使用固定二级子域名进行访问 转发自cpolar内网穿透的文章:Java支付宝沙箱环境支付࿰…...

Mybatis学习笔记二
目录 一、MyBatis的各种查询功能1.1 查询一个实体类对象1.2 查询一个List集合1.3 查询单个数据1.4 查询一条数据为map集合1.5 查询多条数据为map集合1.5.1 方法一:1.5.2 方法二: 二、特殊SQL的执行2.1 模糊查询2.2 批量删除2.3 动态设置表名2.4 添加功能…...

Unity签到系统架构设计:配置驱动与状态同步实践
1. 这不是个“签到页面”,而是一套可落地的用户留存引擎很多人看到“Unity七日签到”第一反应是:不就是做个UI面板,点七次按钮,发七种奖励?我试过——真这么干,上线三天就被运营打回来重做。原因很简单&…...

NVIDIA Profile Inspector:解锁显卡700+隐藏设置的终极优化指南
NVIDIA Profile Inspector:解锁显卡700隐藏设置的终极优化指南 【免费下载链接】nvidiaProfileInspector 项目地址: https://gitcode.com/gh_mirrors/nv/nvidiaProfileInspector 你是否曾疑惑,为什么同一款显卡在不同游戏中表现天差地别…...

如何用My-TODOs打造高效跨平台待办清单:免费开源桌面应用终极指南
如何用My-TODOs打造高效跨平台待办清单:免费开源桌面应用终极指南 【免费下载链接】My-TODOs A cross-platform desktop To-Do list. 跨平台桌面待办小工具 项目地址: https://gitcode.com/gh_mirrors/my/My-TODOs 在现代快节奏的工作生活中,高效…...

如果你还在为CAD、SolidWorks的许可发愁,看看这八家
先讲个真事。上个月我一个老同事打电话来,他们公司做非标自动化,四十几个机械工程师,用的主要是SolidWorks和AutoCAD。他说每年买浮动许可的钱快三百万了,结果研发那边还是天天有人排队等许可。他去看了一眼,下午两点半…...

预训练模型技术演进史:从Word2Vec到多模态大模型
1. 项目概述:这本“沙滩读物”到底在讲什么? “Beach Reading: a Short History of Pre-Trained Models”——光看标题,你可能会以为这是本躺在夏威夷躺椅上、椰子水还没喝完就能翻完的轻松小册子。但别被“Beach Reading”这个温柔前缀骗了。…...

Steam创意工坊下载难题终结者:WorkshopDL让你的模组下载从未如此简单
Steam创意工坊下载难题终结者:WorkshopDL让你的模组下载从未如此简单 【免费下载链接】WorkshopDL WorkshopDL - The Best Steam Workshop Downloader 项目地址: https://gitcode.com/gh_mirrors/wo/WorkshopDL 还在为想玩Steam创意工坊的模组却没有Steam账号…...

魔兽争霸3兼容性修复终极指南:告别闪退卡顿的智能解决方案
魔兽争霸3兼容性修复终极指南:告别闪退卡顿的智能解决方案 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为魔兽争霸3这款经典游戏在…...

三步解锁RPG Maker MV/MZ加密资源:新手也能快速提取游戏文件
三步解锁RPG Maker MV/MZ加密资源:新手也能快速提取游戏文件 【免费下载链接】RPG-Maker-MV-Decrypter You can decrypt RPG-Maker-MV Resource Files with this project ~ If you dont wanna download it, you can use the Script on my HP: 项目地址: https://g…...

免费开源鼠标连点器:5分钟上手跨平台自动化点击完整指南
免费开源鼠标连点器:5分钟上手跨平台自动化点击完整指南 【免费下载链接】MouseClick 🖱️ MouseClick 🖱️ 是一款功能强大的鼠标连点器和管理工具,采用 QT Widget 开发 ,具备跨平台兼容性 。软件界面美观 ࿰…...

3分钟搞定M3U8视频下载:免费开源工具的终极懒人包
3分钟搞定M3U8视频下载:免费开源工具的终极懒人包 【免费下载链接】N_m3u8DL-CLI-SimpleG N_m3u8DL-CLIs simple GUI 项目地址: https://gitcode.com/gh_mirrors/nm3/N_m3u8DL-CLI-SimpleG 还在为下载在线视频发愁吗?那些藏在网页里的M3U8格式视频…...