大模型入门(三)—— 大模型的训练方法
参考hugging face的文档介绍:https://huggingface.co/docs/transformers/perf_train_gpu_many#naive-model-parallelism-vertical-and-pipeline-parallelism,以下介绍聚焦在pytorch的实现上。
随着现在的模型越来越大,训练数据越来越多时,单卡训练要么太慢,要么无法存下整个模型,导致无法训练。当你拥有多张GPU(单机多卡,多机多卡)时,你就可以通过一些并行训练的方式来解决你的问题。常见的并行方法有以下四种:
数据并行(DP):每个GPU都加载全量模型参数,将数据分割成多块输入到每个GPU中单独处理,但在计算loss和梯度时会有同步机制。
模型张量并行(TP):每个tensor被分割成多块(根据场景按行或者列分割)存储在不同的GPU上,每个GPU单独计算,最后同步汇总到一块,类似于transformer中的多头,假如每个头的计算都在一张单独的gpu上,计算完后将所有gpu的结果concat到一起再分发到每张gpu上。
流水线并行(PP):将模型按照层拆分,不同的层存储在不同的gpu上,类似于流水线的形式,数据先进入到前面的层,输出结果传到其他GPU上进入到后面的层。反传同理。
ZeRO:属于数据并行的范畴,但又很不一样,在ZeRO中会将模型参数、优化器参数、梯度等分片到不同的GPU上,ZeRO的方法可以配合张量并行或者流水线并行一起使用,但在配合TP或者PP时,通常只启用优化器参数的分片,其他的分片可能会带来不好的效果。此外ZeRO-offload还可以将一些计算量小且使用低频的参数放置在CPU上,比如优化器参数和参数更新的计算,或者混合精度训练时,fp32的参数,这些都可以放在CPU上,在不明显影响计算效果的同时,节约GPU显存。
数据并行
数据并行最常见的是DP(Data Parallel)和DDP(Distributed Data Parallel),DP和DDP的不同在于:
1)DP是基于多线程实现的,DDP是基于多进程实现的,每个GPU受单独的进程控制,不受GIL锁的限制。
2)DP只能在单机上使用,DDP单机和多机都可以使用。
3)DDP相比于DP训练速度要快,但并不绝对,有些场景下当GPU的通讯效率低时可能会更慢。
4)DP存在多次数据交换,DDP只存在一次梯度交换,且是通过GPU之间相互交换的方式融合所有的数据。
ZeRO数据并行
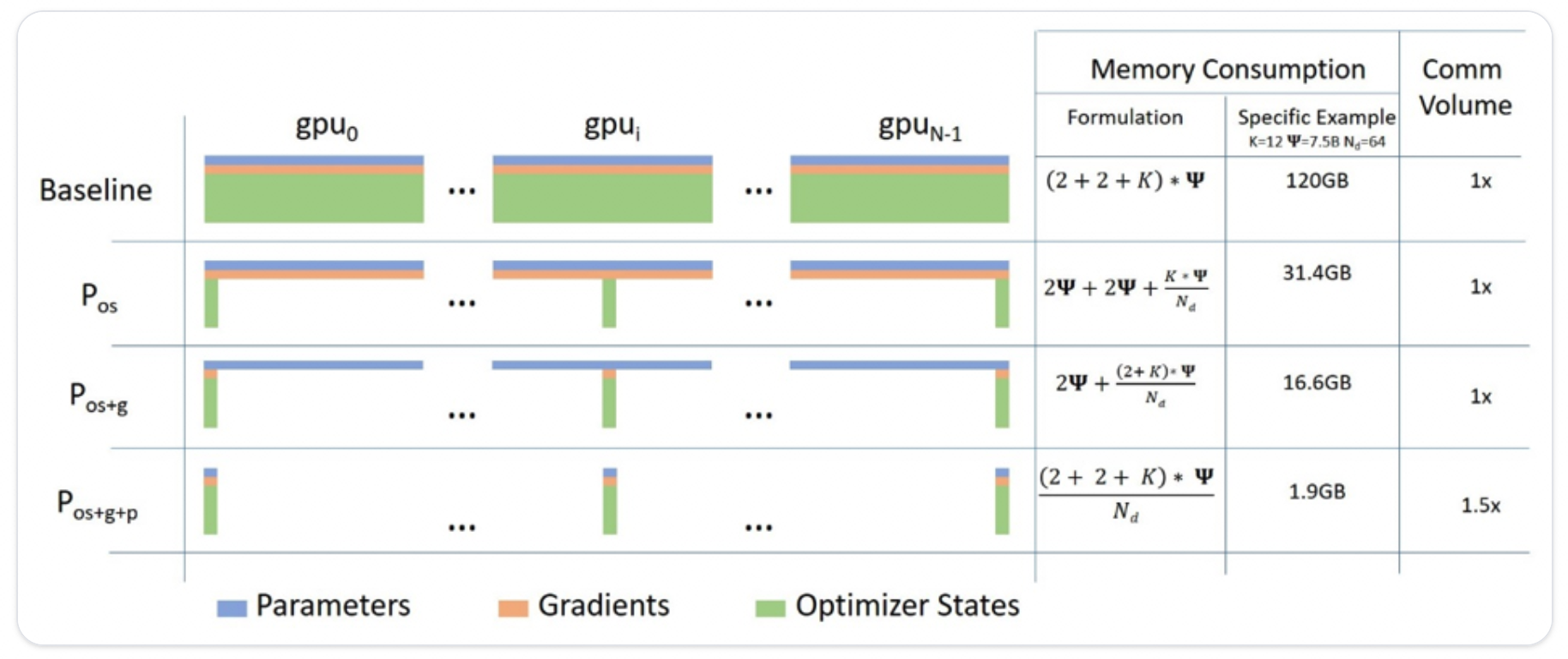
如上图所示,Baseline是指每张GPU都存储所有的参数,包括模型权重、梯度、优化器状态,除此之外其实还有激活层、临时存储,不可用的内存碎片等。
Pos:优化器状态分片
Pos+g:优化器状态和梯度分片
Pos+g+p:优化器状态、梯度和权重参数分片。
ZeRO相比于DP来说,主要在于各种参数分布在不同的GPU上,当在运行计算时,每个GPU会去同步完整的参数去计算。假如给定一个3层的模型,每层有3个参数:

给定3个GPU去分片存储不同的权重块:

给定输入当到达La层时,在GPU0上只有a0参数,此时GPU0会从GPU1和GPU2上同步a1和a2组合成完整的参数进行计算,计算完后就释放参数,对于GPU1和GPU2同理。所以这里和张量并行是不太一样的,这里会同步全量的参数。
流水线并行
流水线并行是将模型按层拆分存储到不同的GPU上,假定给定一个8层的模型和2个GPU,如下所示:前4层在GPU0上,后4层在GPU1上,在前向计算过程中先在GPU0上计算,然后将GPU0上的输出同步到GPU1上计算。反向传播同理。

流水线并行的方式存在一个问题,后面层需要等前面的计算完才能开始计算,会导致GPU在一段时间是闲置的,如下图所示:
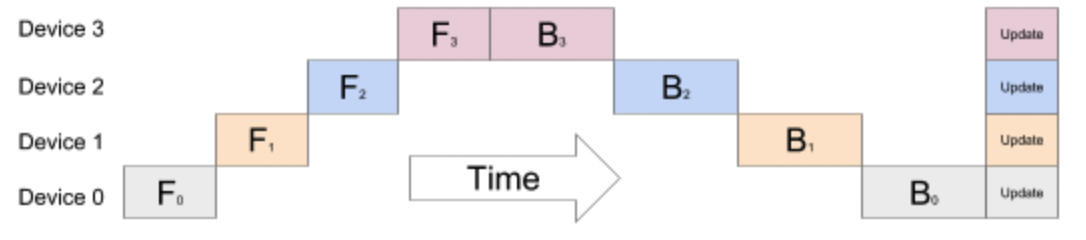
为了让GPU的闲置时间减少,在流水线并行的思路上引入数据并行,将原来的mini batch分割成更小的macro batch,让整个训练如下图所示:

张量并行
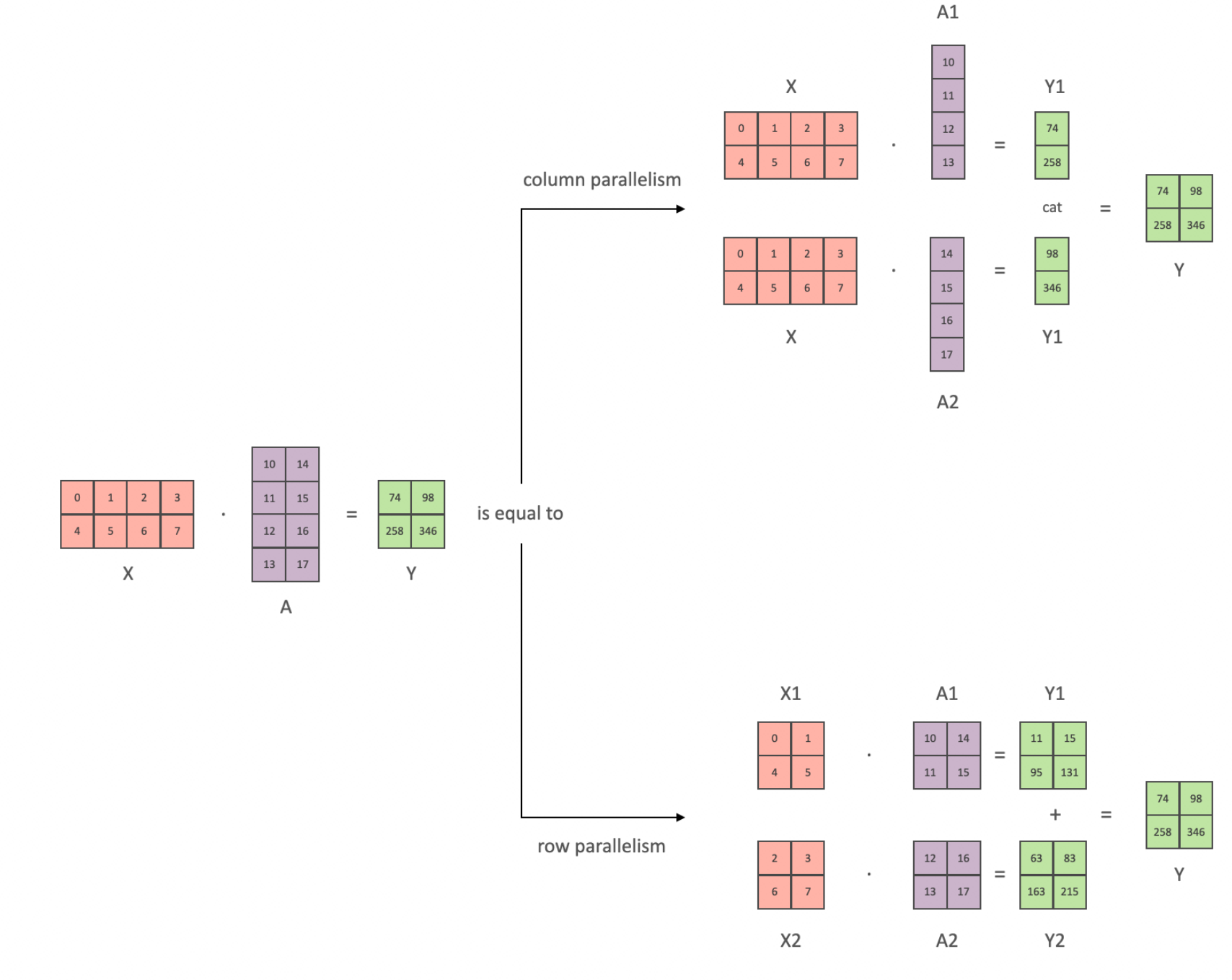
张量并行是将一个完整的tensor分割成多块存储到不同的GPU上,流水线并行解决不了一个GPU无法存储一个模型layer的情况,而张量并行可以解决这类问题。详见Megatron-LM的论文。
在transformer架构中主要是有线性层和GeLU一类的激活函数组成,对模型的权重按照行或者列分块时,线性矩阵运算如下:按照列拆分权重时,输入不需要拆分,最终通过concat组合结果;按行拆分权重时,输入也需要拆分,最终通过相加组合结果。从这里的特性也可以知道,假定一个函数为GeLU(XA)B,对于激活函数里面的A按列拆分可以在单个GPU中完成激活计算,此时对应的B可以按行计算,以上所有操作都可以只在各自的GPU中完成,较少通信操作,最后才同步合并结果。
适用场景
单GPU
当模型可以存储在单GPU上:正常训练;
当模型不能存储在单GPU上:可以使用ZeRO-Offload CPU等方法,让CPU去承载部分参数。
单机多GPU
当模型可以存储在单GPU上:DDP(推荐),ZeRO(可能会提效);
当模型不能存储在单GPU上:PP,ZeRO,TP。但最大层无法放在单GPU上时,就只能使用TP、ZeRO。
多机多GPU
当节点间通讯比较快时:ZeRO,PP+TP+DP;
当节点间通讯比较慢时:DP+TP+PP+ZeRO-1(ZeRO-1是指只对优化器参数做分片)。
相关文章:
大模型入门(三)—— 大模型的训练方法
参考hugging face的文档介绍:https://huggingface.co/docs/transformers/perf_train_gpu_many#naive-model-parallelism-vertical-and-pipeline-parallelism,以下介绍聚焦在pytorch的实现上。 随着现在的模型越来越大,训练数据越来越多时&…...

人机交互学习-4 交互设计过程
交互设计过程 交互设计过程基本活动关键特征 设计过程中的问题如何选取用户?如何明确需求?如何提出候选方案?如何在候选方案中选择? 交互设计生命周期模型星型生命周期模型可用性工程生命周期模型 交互设计过程管理界面设计的4个支…...

大话Stable-Diffusion-Webui之kohya-ss主题更改
文章目录 kohya-sskohya-ss主题更改添加背景图片更改组件样式自定义主题规范更改主题的另一种方式kohya-ss kohya-ss是一个专门用于训练Dreambooth、LoRA等小模型的项目,本身没有GUI界面,需要通过python命令去调用使用,这对于不懂python的同学来说门槛稍微有点高,于是有人…...

搜索在计算机中的地位十分重要
无论是在内部系统还是在外部的互联网站上,都少不了检索系统。数据是为了用户而服务。计算机在采集数据,处理数据,存储数据之后,各种客户端的操作pc机或者是移动嵌入式设备都可以很好的获取数据,得到 想要的数据服务。 …...

多模态深度学习:定义、示例、应用
人类使用五种感官来体验和解读周围的世界。我们的五种感官从五个不同的来源和五种不同的方式捕捉信息。模态是指某事发生、经历或捕捉的方式。 人脑由可以同时处理多种模式的神经网络组成。想象一下进行对话——您大脑的神经网络处理多模式输入(音频、视觉、文本、…...

基于ZCU106平台部署Vitis AI 1.2/2.5开发套件【Vivado+Vitis+Petalinux2020/2022】
Vitis AI是 Xilinx 的开发平台,适用于在 Xilinx 硬件平台(包括边缘设备和 Alveo 卡)上进行人工智能算法推理部署。它由优化的IP、工具、库、模型和示例设计组成。Vitis AI以高效易用为设计理念,可在 Xilinx FPGA 和 ACAP 上充分发…...
ChatGPT原理简介
承接上文GPT前2代版本简介 GPT3的基本思想 GPT2没有引起多大轰动,真正改变NLP格局的是第三代版本。 GPT3训练的数据包罗万象,上通天文下知地理,所以它会胡说八道,会说的贼离谱,比如让你穿越到唐代跟李白对诗,不在一…...
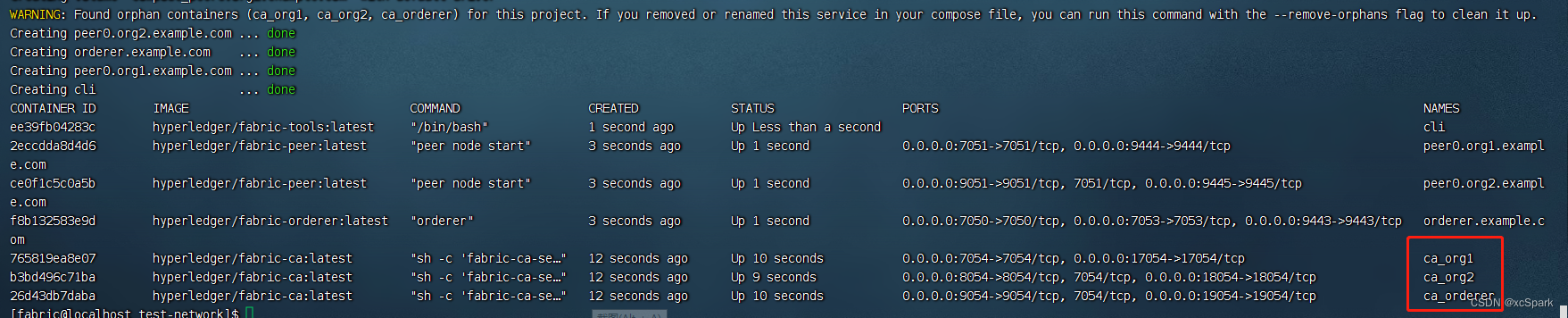
从0搭建Hyperledger Fabric2.5环境
Hyperledger Fabric 2.5环境搭建 一.Linux环境准备 # root登录 yum -y install git curl docker docker-compose tree yum -y install autoconf autotools-dev automake m4 perl yum -y install libtool autoreconf -ivf # 安装jq相关包 cd /opt git clone --recursive https…...

Rust每日一练(Leetday0026) 最小覆盖子串、组合、子集
目录 76. 最小覆盖子串 Minimum Window Substring 🌟🌟🌟 77. 组合 Combinations 🌟🌟 78. 子集 Subsets 🌟🌟 🌟 每日一练刷题专栏 🌟 Rust每日一练 专栏 Gola…...

c# 从零到精通-ArrayList-Hashtable的操作
c# 从零到精通-ArrayList-Hashtable的操作 1、ArrayList的操作 using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.Collections; namespace Test11 { class Program { static void Main(string[] args) { ArrayList list …...

pnpm带来了什么
首先 pnpm 和 npm yarn 一样是包管理工具,他解决了npm 和 yarn 存在的一些问题 npm3之前每个依赖都是一层嵌套一层的,每个依赖里都有node_modules 用来存放依赖所需的依赖包导致重复下载的依赖包很多,一层层嵌套,嵌套很深&#x…...
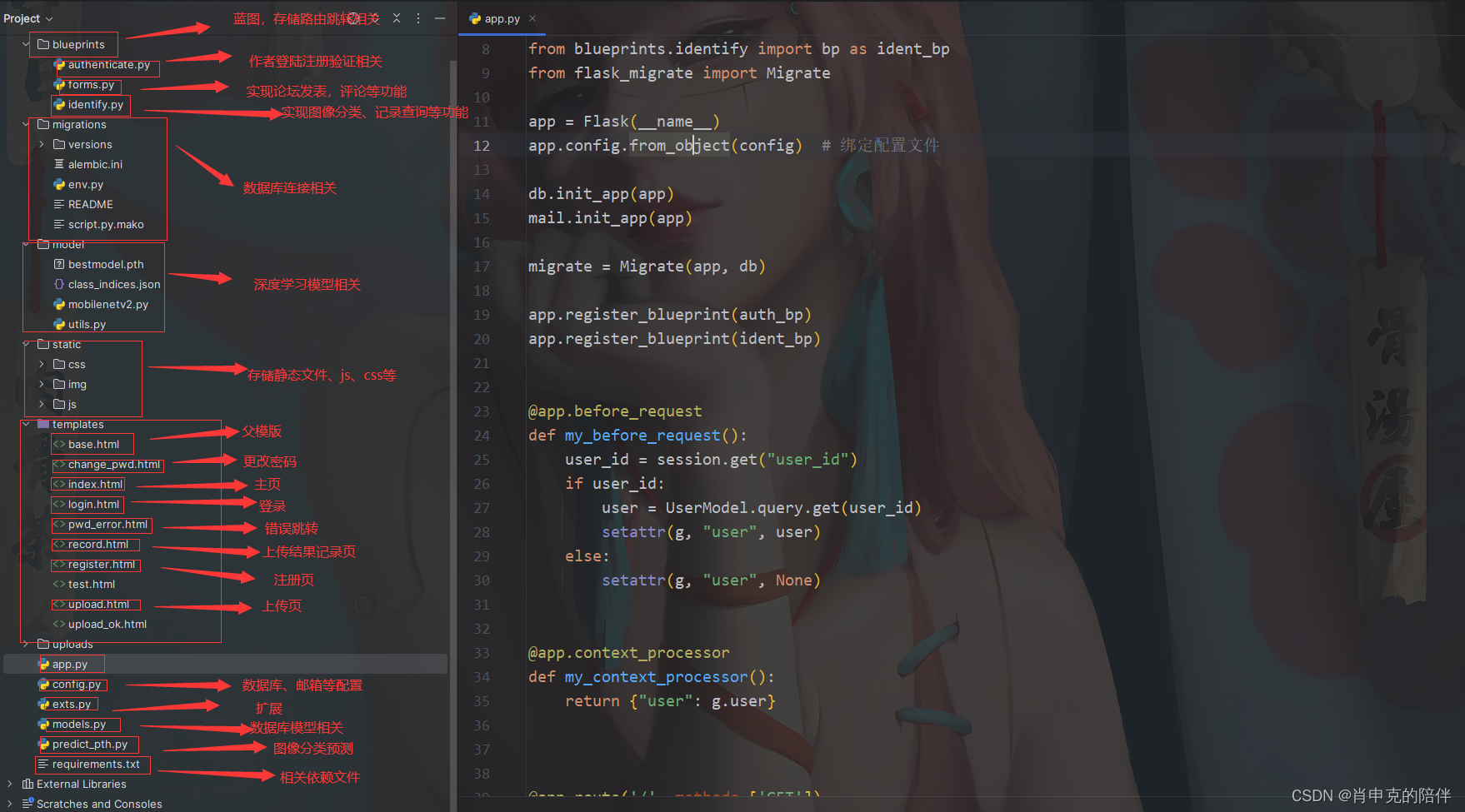
图像分类模型嵌入flask中开发PythonWeb项目
图像分类模型嵌入flask中开发PythonWeb项目 图像分类是一种常见的计算机视觉任务,它的目的是将输入的图像分配到预定义的类别中,如猫、狗、花等。图像分类模型是一种基于深度学习的模型,它可以利用大量的图像数据来学习图像的特征和类别之间…...
GIT安装教程(入门)
目录 前言 Git作者 官网 GIT优点 GIT缺点 为什么要使用 Git 下载以及安装步骤 一、官网下载 二、GIT安装步骤 1、安装get程序 2、许可声明 3、选择安装路径 4、选择git组件 5、创建菜单名称 6、 git文件默认编辑器 7、设置新存储库中初始分支的名称 8、调整Pa…...

全志V3S嵌入式驱动开发(触摸屏驱动)
【 声明:版权所有,欢迎转载,请勿用于商业用途。 联系信箱:feixiaoxing 163.com】 所谓的触摸屏,其实就是在普通的lcd屏幕之上,再加一层屏而已。这个屏是透明的,这样客户就可以看到下面lcd屏幕的…...

死信队列详解
什么是死信队列? 在消息队列中,执行异步任务时,通常是将消息生产者发布的消息存储在队列中,由消费者从队列中获取并处理这些消息。但是,在某些情况下,消息可能无法正常地被处理和消耗,例如&…...
:北京卷I)
我用ChatGPT写2023高考语文作文(五):北京卷I
2023年 北京卷 I 适用地区:北京 “续航”一词,原指连续航行,今天在使用中被赋予了新的含义,如为青春续航、科技为经济发展续航等。 请以“续航”为题目,写一篇议论文。 要求:论点明确,论据充实&…...
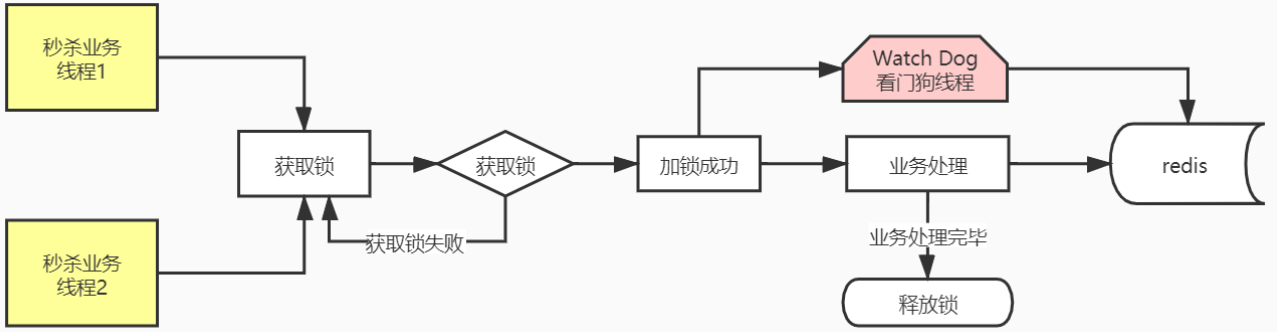
《微服务实战》 第二十八章 分布式锁框架-Redisson
前言 Redisson 在基于 NIO 的 Netty 框架上,充分的利⽤了 Redis 键值数据库提供的⼀系列优势,在Java 实⽤⼯具包中常⽤接⼝的基础上,为使⽤者提供了⼀系列具有分布式特性的常⽤⼯具类。使得原本作为协调单机多线程并发程序的⼯具包获得了协调…...

局部搜索,变邻域搜索算法
目录 局部搜索 02 变邻域搜索算法 局部搜索 1.1 局部搜索是什么玩意儿? 官方一点:局部搜索是解决优化问题的一种启发式算法。对于某些计算起来非常复杂的优化问题,比如各种NP-难问题,要找到最优解需要的时间随问题规模呈指数增长,因此诞生了各种启发式算法来退而求其次…...

软件工程实训——第一天
第一天 前后分离 前端:android 后端:springbootmbatis-plus 高心星 软件工程的思维来开发项目 问题定义 可行性研究 需求分析 概要设计 详细设计 编码 测试 维护 需求分析 1.用户的信息管理 2.新增支出 3.新增收入 4.支出统计 5.收入…...
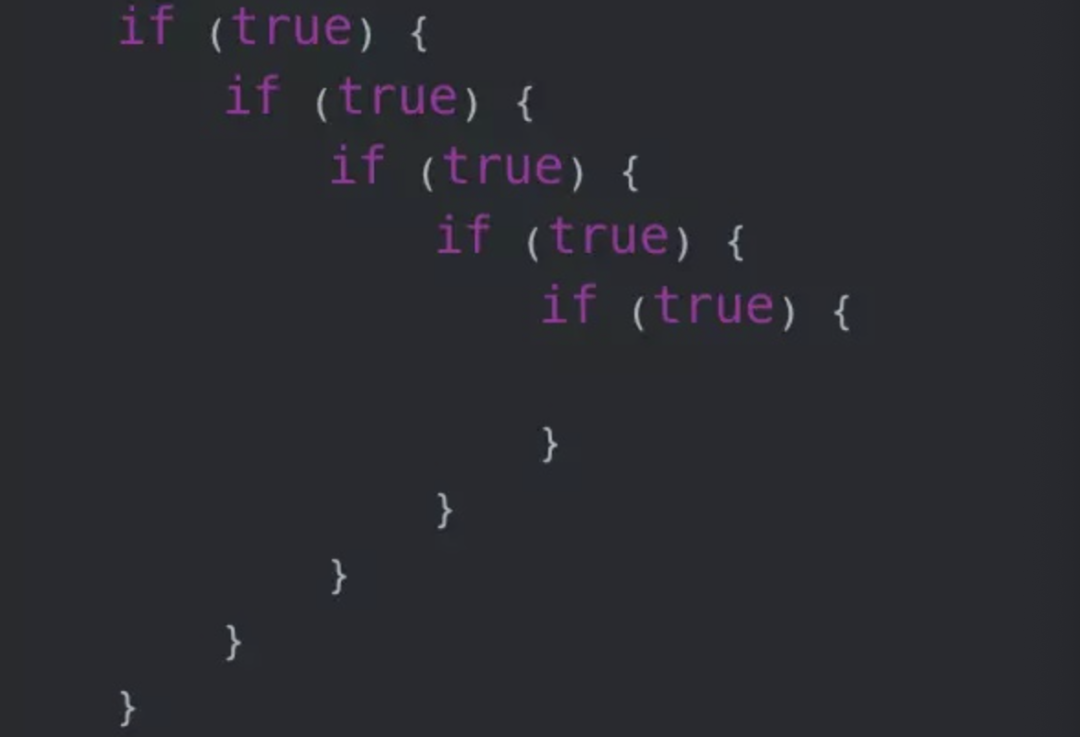
嵌入式C语言中if/else如何优化详解
观点一(灵剑): 前期迭代懒得优化,来一个需求,加一个if,久而久之,就串成了一座金字塔。 当代码已经复杂到难以维护的程度之后,只能狠下心重构优化。那,有什么方案可以优雅…...
)
基于Javaweb的医院在线挂号系统(10007)
有需要的同学,源代码和配套文档领取,加文章最下方的名片哦 一、项目演示 项目演示视频 二、资料介绍 完整源代码(前后端源代码SQL脚本)配套文档(LWPPT开题报告/任务书)远程调试控屏包运行一键启动项目&…...

极域电子教室破解终极指南:如何在机房环境中重获电脑控制权
极域电子教室破解终极指南:如何在机房环境中重获电脑控制权 【免费下载链接】JiYuTrainer 极域电子教室防控制软件, StudenMain.exe 破解 项目地址: https://gitcode.com/gh_mirrors/ji/JiYuTrainer 你是否曾在学校机房被极域电子教室的全屏广播困住…...

保姆级教程:手把手拆解Android相机启动流程,从点击图标到预览画面发生了什么?
从点击到成像:Android相机启动全链路技术解析 当你在旅行中突然发现值得记录的瞬间,手指本能地点击相机图标的那一刻,手机内部其实已经触发了一场精密协作的"交响乐演出"。作为Android开发者,理解这套从用户界面直达硬件…...

在Windows上优雅运行Android应用:APK Installer的零门槛解决方案
在Windows上优雅运行Android应用:APK Installer的零门槛解决方案 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否曾为无法在Windows电脑上使用某个心…...

基于reflectt-node的WebSocket RPC实践:构建实时协作待办应用
1. 项目概述与核心价值 最近在折腾一个需要实时双向通信的Web应用,传统的轮询和长轮询方案在性能和资源消耗上总感觉差那么点意思。后来把目光投向了WebSocket,但原生WebSocket的API相对底层,自己管理连接、心跳、重连、消息序列化这些琐事&a…...

LeagueAkari游戏数据分析工具:从新手到高手的完整进阶攻略
LeagueAkari游戏数据分析工具:从新手到高手的完整进阶攻略 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit 你是否曾在英雄联盟游戏…...

【谷歌内部培训材料流出】:Gemini与Workspace Admin Console深度绑定的5类企业级策略配置
更多请点击: https://intelliparadigm.com 第一章:Gemini与Workspace Admin Console深度集成的底层架构解析 Gemini 与 Workspace Admin Console 的深度集成并非简单的 API 调用叠加,而是基于统一身份上下文、双向实时状态同步和策略驱动控制…...

Python热重载工具Reloadium:实现函数级代码热更新与AI辅助开发
1. 项目概述:Reloadium,一个改变Python开发工作流的“时光机”如果你和我一样,是个常年泡在Python项目里的开发者,那你一定对“修改代码 -> 停止程序 -> 重新运行 -> 等待启动”这个循环深恶痛绝。尤其是在调试Web后端&a…...

ChatLLM-Web:快速构建LLM Web应用的轻量级框架解析
1. 项目概述:一个面向开发者的轻量级LLM Web应用框架 最近在折腾大语言模型本地部署和Web应用开发的朋友,可能都遇到过类似的困境:模型推理的后端代码写好了,但想做个界面给非技术同事或者自己用,就得从头搭一套前端&a…...

《jEasyUI 取得选中行数据》
《jEasyUI 取得选中行数据》 引言 jEasyUI 是一个基于 jQuery 的易于使用的开源 UI 库,它为网页开发者提供了丰富的 UI 组件,如表格、表单、菜单、对话框等。在 jEasyUI 的众多组件中,表格组件(Datagrid)是使用频率非常…...