爬虫利器 Beautiful Soup 之遍历文档
Beautiful Soup 简介
Beautiful Soup 是一个可以从 HTML 或 XML 文件中提取数据的 Python 库,它提供了一些简单的操作方式来帮助你处理文档导航,查找,修改文档等繁琐的工作。因为使用简单,所以 Beautiful Soup 会帮你节省不少的工作时间。
Beautiful Soup 安装
你可以使用如下命令安装 Beautiful Soup。二选一即可。
$ easy_install beautifulsoup4$ pip install beautifulsoup4
Beautiful Soup 不仅支持 Python 标准库中的 HTML 解析器,还支持很多第三方的解析器,比如 lxml,html5lib 等。初始化 Beautiful Soup 对象时如果不指定解析器,那么 Beautiful Soup 将会选择最合适的解析器(前提是你的机器安装了该解析器)来解析文档,当然你也可以手动指定解析器。这里推荐大家使用 lxml 解析器,功能强大,方便快捷,而且该解析器是唯一支持 XML 的解析器。
你可以使用如下命令来安装 lxml 解析器。二选一即可。
$ easy_install lxml$ pip install lxml
Beautiful Soup 小试牛刀
Beautiful Soup 使用来起来非常简单,你只需要传入一个文件操作符或者一段文本即可得到一个构建完成的文档对象,有了该对象之后,就可以对该文档做一些我们想做的操作了。而传入的文本大都是通过爬虫爬取过来的,所以 Beautiful Soup 和 requests 库结合使用体验更佳。
# demo 1from bs4 import BeautifulSoup# soup = BeautifulSoup(open("index.html"))soup = BeautifulSoup("<html><head><title>index</title></head><body>content</body></html>", "lxml") # 指定解析器print(soup.head)# 输出结果<head><title>index</title></head>
Beautiful Soup 将复杂的 HTML 文档转换成一个复杂的树形结构,每个节点都是 Python 对象,所有对象可以归纳为 4 种: Tag,NavigableString,BeautifulSoup,Comment。
Tag 就是 HTML 的一个标签,比如 div,p 标签等,也是我们用的最多的一个对象。
NavigableString 指标签内部的文字,直译就是可遍历的字符串。
BeautifulSoup 指一个文档的全部内容,可以当成一个 Tag 来处理。
Comment 是一个特殊的 NavigableString,其输出内容不包括注视内容。
为了故事的顺利发展,我们先定义一串 HTML 文本,下文的所有例子都是基于这段文本的。
html_doc = """<html><head><title>index</title></head><body><p class="title"><b>首页</b></p><p class="main">我常用的网站<a href="https://www.google.com" class="website" id="google">Google</a><a href="https://www.baidu.com" class="website" id="baidu">Baidu</a><a href="https://cn.bing.com" class="website" id="bing">Bing</a></p><div><!--这是注释内容--></div><p class="content1">...</p><p class="content2">...</p></body>"""
子节点
Tag 有两个很重要的属性,name 和 attributes。期中 name 就是标签的名字,attributes 是标签属性。标签的名字和属性是可以被修改的,注意,这种修改会直接改变 BeautifulSoup 对象。
# demo 2soup = BeautifulSoup(html_doc, "lxml");p_tag = soup.pprint(p_tag.name)print(p_tag["class"])print(p_tag.attrs)p_tag.name="myTag" # attrs 同样可被修改,操作同字典print(p_tag)#输出结果p['title']{'class': ['title']}<myTag class="title"><b>首页</b></myTag>
由以上例子我么可以看出,可以直接通过点属性的方法来获取 Tag,但是这种方法只能获取第一个标签。同时我们可以多次调用点属性这个方法,来获取更深层次的标签。
# demo 3soup = BeautifulSoup(html_doc, "lxml");print(soup.p.b)#输出结果<b>首页</b>
如果想获得所有的某个名字的标签,则可以使用 find_all(tag_name) 函数。
# demo 4soup = BeautifulSoup(html_doc, "lxml");a_tags=soup.find_all("a")print(a_tags)#输出结果[<a class="website" href="https://www.google.com" id="google">Google</a>, <a class="website" href="https://www.baidu.com" id="baidu">Baidu</a>, <a class="website" href="https://cn.bing.com" id="bing">Bing</a>]
我们可以使用 .contents 将 tag 以列表方式输出,即将 tag 的子节点格式化为列表,这很有用,意味着可以通过下标进行访问指定节点。同时我们还可以通过 .children 生成器对节点的子节点进行遍历。
# demo 5soup = BeautifulSoup(html_doc, "lxml");head_tag=soup.headprint(head_tag)print(head_tag.contents)for child in head_tag.children:print("child is : ", child)#输出结果<head><title>index</title></head>[<title>index</title>]child is : <title>index</title>
.children 只可以获取 tag 的直接节点,而获取不到子孙节点,.descendants 可以满足你。
# demo 6soup = BeautifulSoup(html_doc, "lxml");head_tag=soup.headfor child in head_tag.descendants:print("child is : ", child)# 输出结果child is : <title>index</title>child is : index
父节点
通过 .parent 属性获取标签的父亲节点。title 的父标签是 head,html 的父标签是 BeautifulSoup 对象,而 BeautifulSoup 对象的父标签是 None。
# demo 7soup = BeautifulSoup(html_doc, "lxml");title_tag=soup.titleprint(title_tag.parent)print(type(soup.html.parent))print(soup.parent)# 输出结果<head><title>index</title></head><class 'bs4.BeautifulSoup'>None
同时,我们可以通过 parents 得到指定标签的所有父亲标签。
# demo 8soup = BeautifulSoup(html_doc, "lxml");a_tag=soup.afor parent in a_tag.parents:print(parent.name)# 输出结果pbodyhtml[document]
兄弟节点
通过 .next_sibling 和 .previous_sibling 来获取下一个标签和上一个标签。
# demo 9soup = BeautifulSoup(html_doc, "lxml");div_tag=soup.divprint(div_tag.next_sibling)print(div_tag.next_sibling.next_sibling)# 输出结果<p class="content1">...</p>
你可能会纳闷,调用了两次 next_sibling 怎么只有一个输出呢,这方法是不是有 bug 啊。事实上是 div 的第一个 next_sibling 是div 和 p 之间的换行符。这个规则对于 previous_sibling 同样适用。
另外,我们可以通过 .next_siblings 和 .previous_siblings 属性可以对当前节点的兄弟节点迭代输出。在该例子中,我们在每次输出前加了前缀,这样就可以更直观的看到 dib 的第一个 previous_sibling 是换行符了。
# demo 10soup = BeautifulSoup(html_doc, "lxml");div_tag=soup.divfor pre_tag in div_tag.previous_siblings:print("pre_tag is : ", pre_tag)# 输出结果pre_tag is :pre_tag is : <p class="main">我常用的网站<a class="website" href="https://www.google.com" id="google">Google</a><a class="website" href="https://www.baidu.com" id="baidu">Baidu</a><a class="website" href="https://cn.bing.com" id="bing">Bing</a></p>pre_tag is :pre_tag is : <p class="title"><b>首页</b></p>pre_tag is :
前进和后退
通过 .next_element 和 .previous_element 获取指定标签的前一个或者后一个被解析的对象,注意这个和兄弟节点是有所不同的,兄弟节点是指有相同父亲节点的子节点,而这个前一个或者后一个是按照文档的解析顺序来计算的。
比如在我们的文本 html_doc 中,head 的兄弟节点是 body(不考虑换行符),因为他们具有共同的父节点 html,但是 head 的下一个节点是 title。即soup.head.next_sibling=title soup.head.next_element=title。
# demo 11soup = BeautifulSoup(html_doc, "lxml");head_tag=soup.headprint(head_tag.next_element)title_tag=soup.titleprint(title_tag.next_element)# 输出结果<title>index</title>index
同时这里还需要注意的是 title 下一个解析的标签不是 body,而是 title 标签内的内容,因为 html 的解析顺序是打开 title 标签,然后解析内容,最后关闭 title 标签。
另外,我们同样可以通过 .next_elements 和 .previous_elements 来迭代文档树。由遗下例子我们可以看出,换行符同样会占用解析顺序,与迭代兄弟节点效果一致。
# demo 12soup = BeautifulSoup(html_doc, "lxml");div_tag=soup.divfor next_element in div_tag.next_elements:print("next_element is : ", next_element)# 输出结果next_element is : 这是注释内容next_element is :next_element is : <p class="content1">...</p>next_element is : ...next_element is :next_element is : <p class="content2">...</p>next_element is : ...next_element is :next_element is :
Beautiful Soup 总结
本章节介绍了 Beautiful Soup 的使用场景以及操作文档树节点的基本操作,看似很多东西其实是有规律可循的,比如函数的命名,兄弟节点或者下一个节点的迭代函数都是获取单个节点函数的复数形式。
同时由于 HTML 或者 XML 这种循环嵌套的复杂文档结构,致使操作起来甚是麻烦,掌握了本文对节点的基本操作,将有助于提高你写爬虫程序的效率。
相关文章:

爬虫利器 Beautiful Soup 之遍历文档
Beautiful Soup 简介 Beautiful Soup 是一个可以从 HTML 或 XML 文件中提取数据的 Python 库,它提供了一些简单的操作方式来帮助你处理文档导航,查找,修改文档等繁琐的工作。因为使用简单,所以 Beautiful Soup 会帮你节省不少的工…...

12、Nginx高级之高级模块(secure_link/secure_link_md5)
一、功能 防盗链; ngx_http_secure_link_module模块用于检查所请求链接的真实性,保护资源免受未经授权的访问,并限制链接寿命。 该模块提供两种可选的操作模式。 第一种模式由 secure_link_secret 指令启用,用于检查所请求链接的真…...
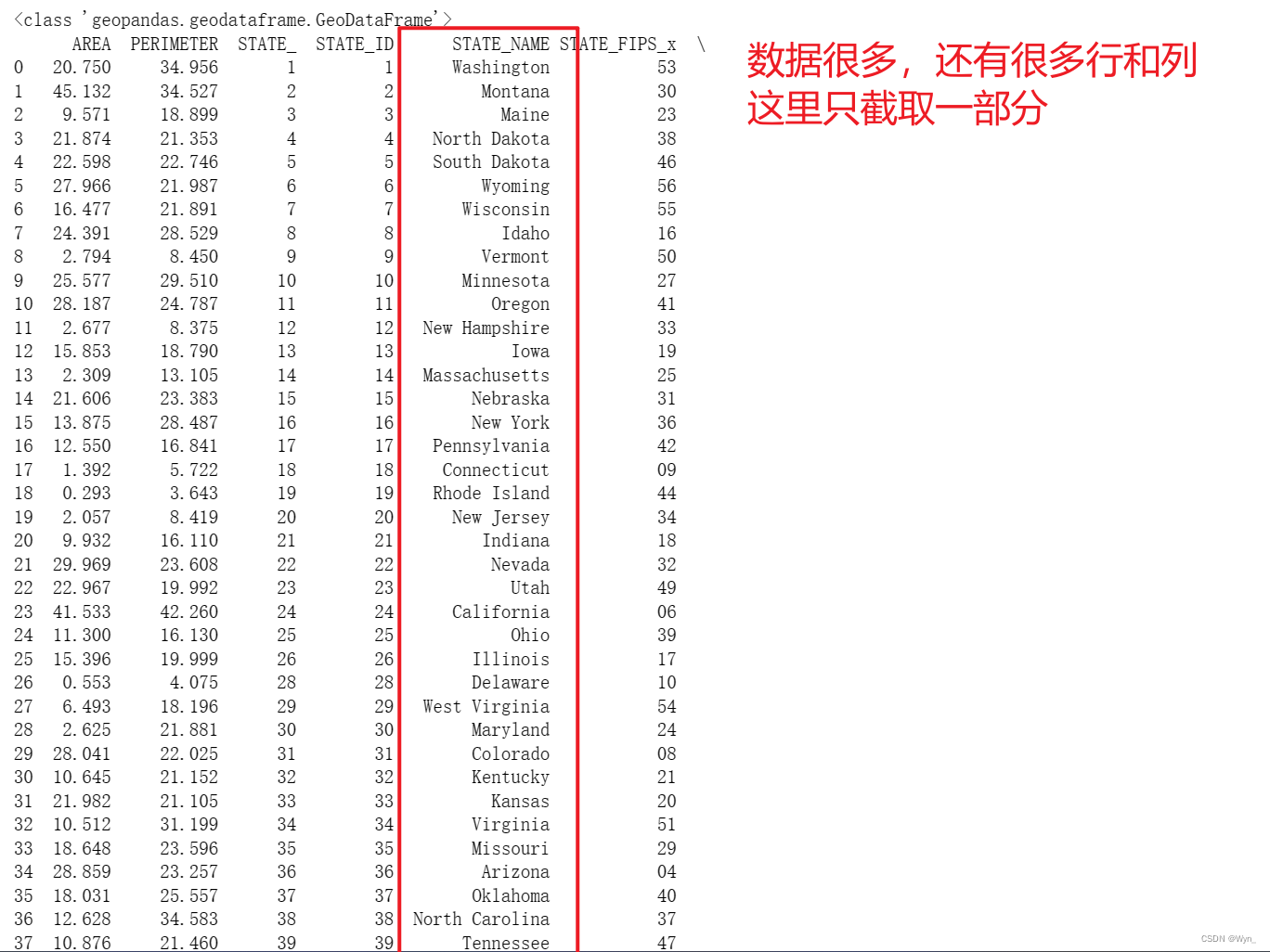
【python】数据可视化,使用pandas.merge()对dataframe和geopandas类型数据进行数据对齐
目录 0.环境 1.适用场景 2.pandas.merge()函数详细介绍 3.名词解释“数据对齐”(来自chatGPT3.5) 4.本文将给出两种数据对齐的例子 1)dataframe类型数据和dataframe类型数据对齐(对齐NAME列); 数据对…...
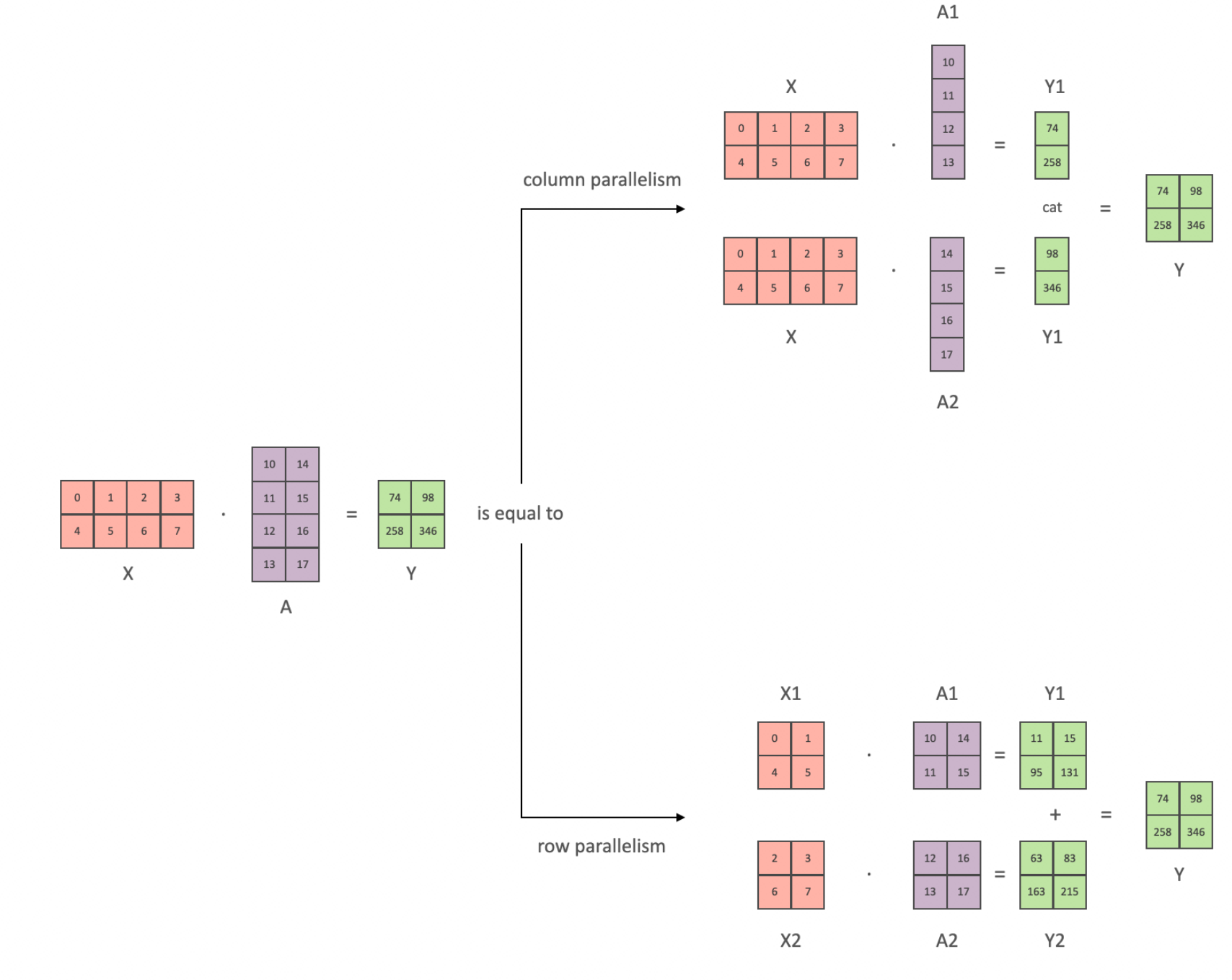
大模型入门(三)—— 大模型的训练方法
参考hugging face的文档介绍:https://huggingface.co/docs/transformers/perf_train_gpu_many#naive-model-parallelism-vertical-and-pipeline-parallelism,以下介绍聚焦在pytorch的实现上。 随着现在的模型越来越大,训练数据越来越多时&…...

人机交互学习-4 交互设计过程
交互设计过程 交互设计过程基本活动关键特征 设计过程中的问题如何选取用户?如何明确需求?如何提出候选方案?如何在候选方案中选择? 交互设计生命周期模型星型生命周期模型可用性工程生命周期模型 交互设计过程管理界面设计的4个支…...

大话Stable-Diffusion-Webui之kohya-ss主题更改
文章目录 kohya-sskohya-ss主题更改添加背景图片更改组件样式自定义主题规范更改主题的另一种方式kohya-ss kohya-ss是一个专门用于训练Dreambooth、LoRA等小模型的项目,本身没有GUI界面,需要通过python命令去调用使用,这对于不懂python的同学来说门槛稍微有点高,于是有人…...

搜索在计算机中的地位十分重要
无论是在内部系统还是在外部的互联网站上,都少不了检索系统。数据是为了用户而服务。计算机在采集数据,处理数据,存储数据之后,各种客户端的操作pc机或者是移动嵌入式设备都可以很好的获取数据,得到 想要的数据服务。 …...

多模态深度学习:定义、示例、应用
人类使用五种感官来体验和解读周围的世界。我们的五种感官从五个不同的来源和五种不同的方式捕捉信息。模态是指某事发生、经历或捕捉的方式。 人脑由可以同时处理多种模式的神经网络组成。想象一下进行对话——您大脑的神经网络处理多模式输入(音频、视觉、文本、…...

基于ZCU106平台部署Vitis AI 1.2/2.5开发套件【Vivado+Vitis+Petalinux2020/2022】
Vitis AI是 Xilinx 的开发平台,适用于在 Xilinx 硬件平台(包括边缘设备和 Alveo 卡)上进行人工智能算法推理部署。它由优化的IP、工具、库、模型和示例设计组成。Vitis AI以高效易用为设计理念,可在 Xilinx FPGA 和 ACAP 上充分发…...
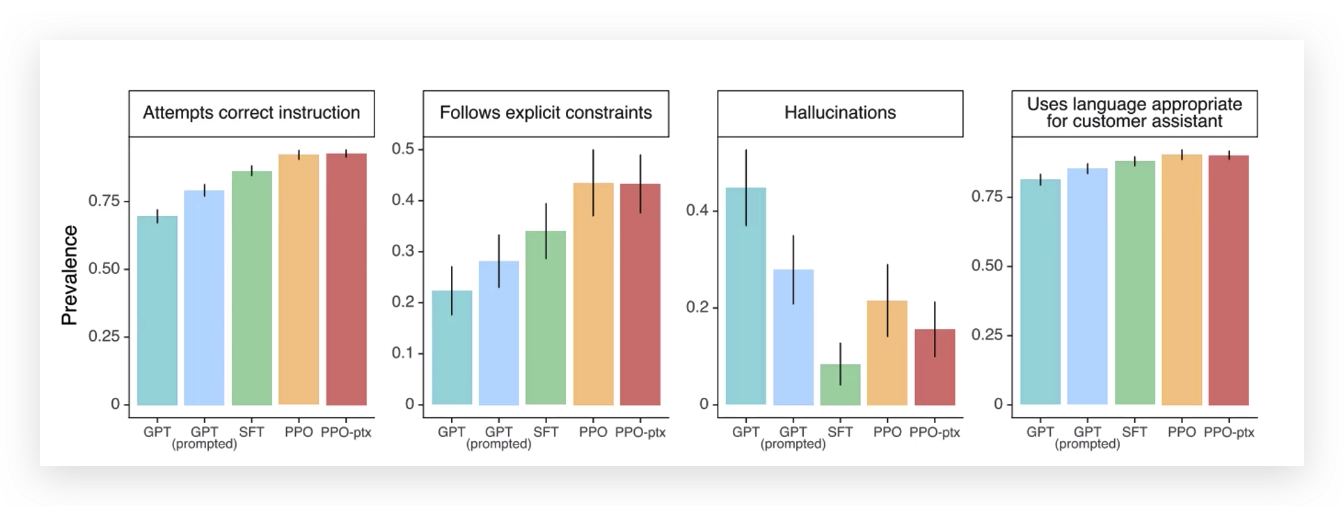
ChatGPT原理简介
承接上文GPT前2代版本简介 GPT3的基本思想 GPT2没有引起多大轰动,真正改变NLP格局的是第三代版本。 GPT3训练的数据包罗万象,上通天文下知地理,所以它会胡说八道,会说的贼离谱,比如让你穿越到唐代跟李白对诗,不在一…...
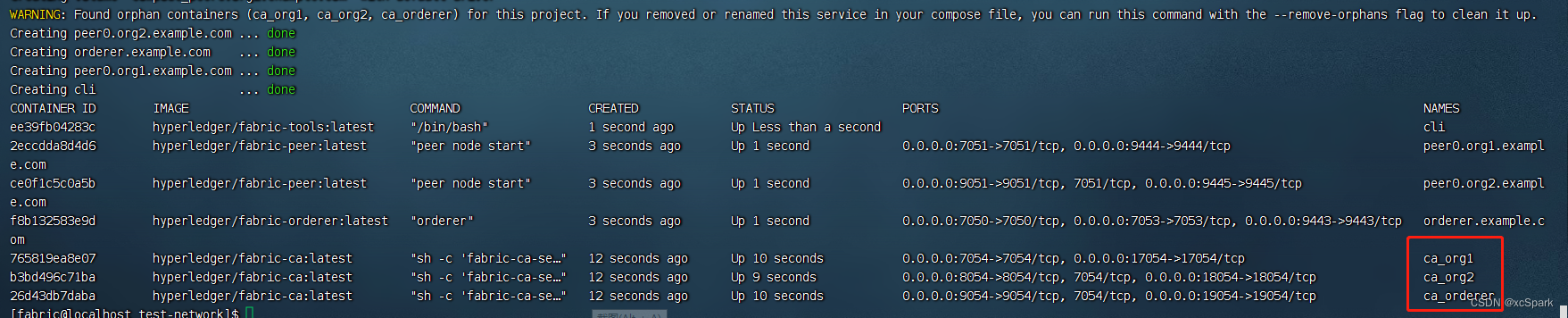
从0搭建Hyperledger Fabric2.5环境
Hyperledger Fabric 2.5环境搭建 一.Linux环境准备 # root登录 yum -y install git curl docker docker-compose tree yum -y install autoconf autotools-dev automake m4 perl yum -y install libtool autoreconf -ivf # 安装jq相关包 cd /opt git clone --recursive https…...

Rust每日一练(Leetday0026) 最小覆盖子串、组合、子集
目录 76. 最小覆盖子串 Minimum Window Substring 🌟🌟🌟 77. 组合 Combinations 🌟🌟 78. 子集 Subsets 🌟🌟 🌟 每日一练刷题专栏 🌟 Rust每日一练 专栏 Gola…...

c# 从零到精通-ArrayList-Hashtable的操作
c# 从零到精通-ArrayList-Hashtable的操作 1、ArrayList的操作 using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.Collections; namespace Test11 { class Program { static void Main(string[] args) { ArrayList list …...

pnpm带来了什么
首先 pnpm 和 npm yarn 一样是包管理工具,他解决了npm 和 yarn 存在的一些问题 npm3之前每个依赖都是一层嵌套一层的,每个依赖里都有node_modules 用来存放依赖所需的依赖包导致重复下载的依赖包很多,一层层嵌套,嵌套很深&#x…...
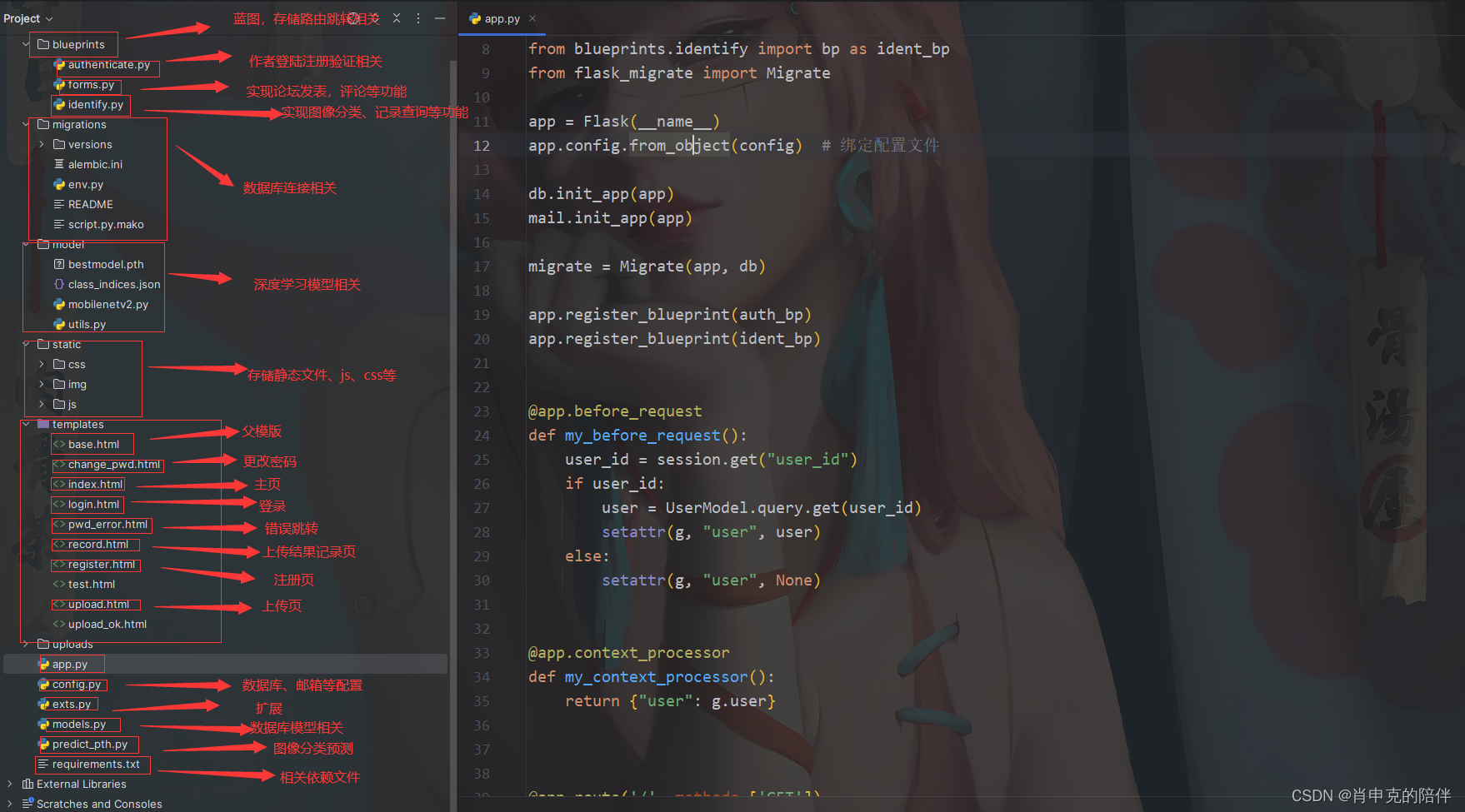
图像分类模型嵌入flask中开发PythonWeb项目
图像分类模型嵌入flask中开发PythonWeb项目 图像分类是一种常见的计算机视觉任务,它的目的是将输入的图像分配到预定义的类别中,如猫、狗、花等。图像分类模型是一种基于深度学习的模型,它可以利用大量的图像数据来学习图像的特征和类别之间…...
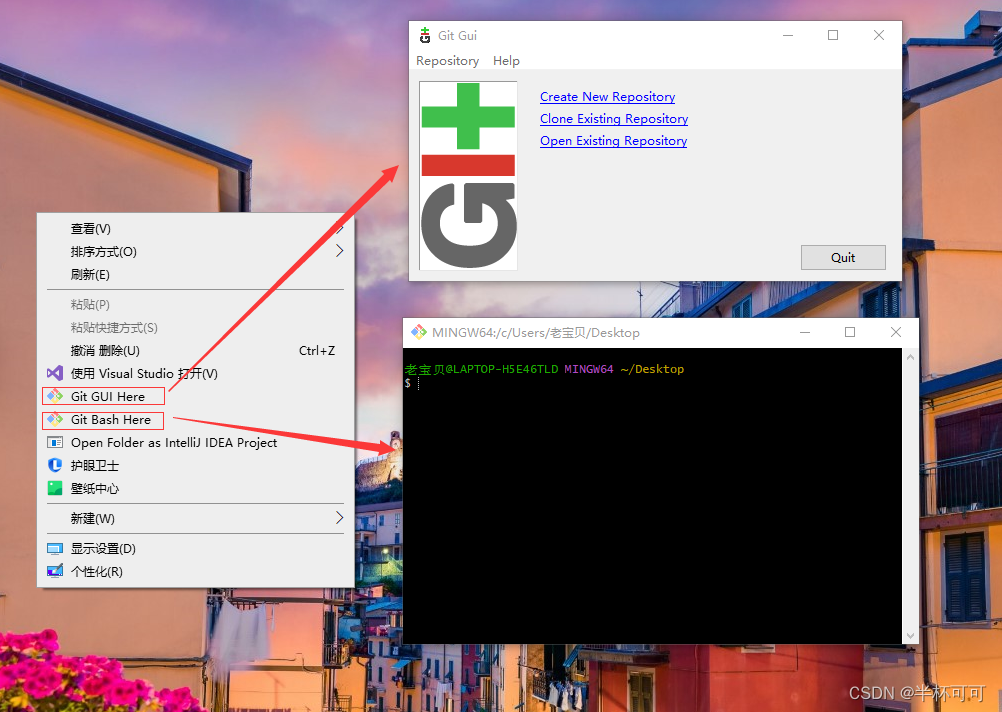
GIT安装教程(入门)
目录 前言 Git作者 官网 GIT优点 GIT缺点 为什么要使用 Git 下载以及安装步骤 一、官网下载 二、GIT安装步骤 1、安装get程序 2、许可声明 3、选择安装路径 4、选择git组件 5、创建菜单名称 6、 git文件默认编辑器 7、设置新存储库中初始分支的名称 8、调整Pa…...

全志V3S嵌入式驱动开发(触摸屏驱动)
【 声明:版权所有,欢迎转载,请勿用于商业用途。 联系信箱:feixiaoxing 163.com】 所谓的触摸屏,其实就是在普通的lcd屏幕之上,再加一层屏而已。这个屏是透明的,这样客户就可以看到下面lcd屏幕的…...

死信队列详解
什么是死信队列? 在消息队列中,执行异步任务时,通常是将消息生产者发布的消息存储在队列中,由消费者从队列中获取并处理这些消息。但是,在某些情况下,消息可能无法正常地被处理和消耗,例如&…...
:北京卷I)
我用ChatGPT写2023高考语文作文(五):北京卷I
2023年 北京卷 I 适用地区:北京 “续航”一词,原指连续航行,今天在使用中被赋予了新的含义,如为青春续航、科技为经济发展续航等。 请以“续航”为题目,写一篇议论文。 要求:论点明确,论据充实&…...
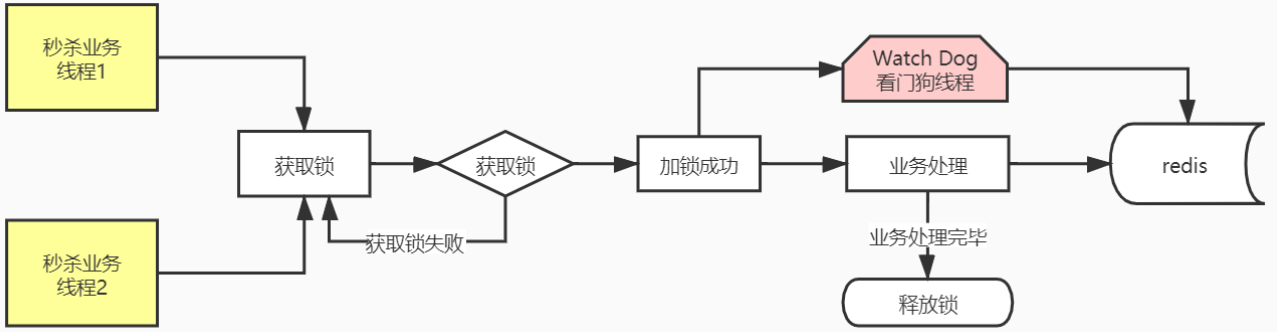
《微服务实战》 第二十八章 分布式锁框架-Redisson
前言 Redisson 在基于 NIO 的 Netty 框架上,充分的利⽤了 Redis 键值数据库提供的⼀系列优势,在Java 实⽤⼯具包中常⽤接⼝的基础上,为使⽤者提供了⼀系列具有分布式特性的常⽤⼯具类。使得原本作为协调单机多线程并发程序的⼯具包获得了协调…...

Taotoken CLI工具一键配置开发环境与团队密钥共享指南
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken CLI工具一键配置开发环境与团队密钥共享指南 在团队协作开发中,统一大模型API的接入配置是一个常见痛点。每位…...

嵌入式软件测试的范式革命——技术体系与工程价值深度解析
第一章 引言:嵌入式软件质量危机的时代背景在汽车电子、航空航天、工业控制、医疗设备等安全关键领域,嵌入式软件的复杂度正以指数级速度增长。一辆高端智能电动汽车的代码量已突破两亿行,超越了波音787客机的软件规模。与此同时,…...

保姆级教程:手把手拆解Android相机启动流程,从点击图标到预览画面发生了什么?
从点击到成像:Android相机启动全链路技术解析 当你在旅行中突然发现值得记录的瞬间,手指本能地点击相机图标的那一刻,手机内部其实已经触发了一场精密协作的"交响乐演出"。作为Android开发者,理解这套从用户界面直达硬件…...

Unity Addressable系统面板配置避坑指南:从Profile到Content Update,新手必看的10个关键设置
Unity Addressable系统配置避坑实战:10个关键设置详解 Addressable系统作为Unity资源管理的重要工具,其配置面板的复杂性常常让开发者望而生畏。本文将聚焦实际项目中最容易出错的10个关键设置,从Profile到Content Update,逐一剖…...

C语言--day14
指针的常见操作 指针变量,有两方面的意思 一个指针指向的内容(数据值,一级) 指针变量本身存储的数据 (地址值) #include <stdio.h> int main() {int a 10;int b 0 ;int c 50;int *p NULL;int *q NULL;p &a; // 对指针变量本身进行修改…...

音频算法调试利器:用Android App实时绘制EQ/DRC曲线,告别Matlab依赖
移动端音频算法调试革命:Android实时EQ/DRC可视化工具开发实战 在音频算法开发领域,调试环节长期被桌面级工具垄断,工程师们不得不忍受开发板与工作站之间的频繁切换。这种工作模式不仅效率低下,更无法满足现代音频产品快速迭代的…...

卡尔曼滤波中的‘信任度’分配:从高斯分布乘积公式看估计与观测谁更重要
卡尔曼滤波中的‘信任度’分配:从高斯分布乘积公式看估计与观测谁更重要 在机器人定位或金融时间序列预测中,我们常常面临一个核心问题:当预测值和观测值都存在不确定性时,如何决定更信任哪一个?这不仅仅是数学问题&a…...

开源协作平台Penny:为女性开发者打造包容性技术社区
1. 项目概述:一个为女性开发者量身定制的开源协作平台最近在GitHub上闲逛,发现了一个挺有意思的项目,叫“WomenBuilt/penny”。光看这个名字,你可能会有点摸不着头脑,这“penny”是啥?一个记账应用…...

别再死记硬背了!用这3个真实网络场景,彻底搞懂华为ACL的配置逻辑
华为ACL实战指南:3个典型场景解锁访问控制精髓 每次看到新手工程师面对ACL配置时一脸茫然的样子,我就想起自己当年在机房通宵排错的经历。访问控制列表(ACL)作为网络安全的"门禁系统",其重要性不言而喻&…...

不止于配置:深入理解AVL Cruise与Matlab Simulink联合仿真的DLL机制
不止于配置:深入理解AVL Cruise与Matlab Simulink联合仿真的DLL机制 在汽车工程仿真领域,AVL Cruise与Matlab Simulink的联合仿真已成为动力系统开发的标准工具链。大多数教程停留在环境配置层面,而真正影响仿真效率与可靠性的,往…...