爱奇艺大数据加速:从Hive到Spark SQL
01
导语
爱奇艺自2012年开展大数据业务以来,基于大数据开源生态服务建设了一系列平台,涵盖了数据采集、数据处理、数据分析、数据应用等整个大数据流程,为公司的运营决策和各种数据智能业务提供了强有力的支持。随着数据规模的不断增长和计算复杂度的增加,如何快速挖掘数据的潜在价值,给大数据平台带来了巨大挑战。
针对海量数据的实时分析需求,大数据团队从2020年开始发起大数据加速项目,基于大数据技术加速爱奇艺数据流通,促进更实时的运营决策、更高效的信息分发。其中之一就是推动OLAP数据分析从Hive引擎切换到Spark SQL引擎,取得了明显收益,任务提速67%、资源节省50%,为BI、广告、会员、用户增长等业务带来提效增收。
02
背景
爱奇艺大数据平台建设初期,基于开源的Hadoop生态构建了大数据基础架构和数据仓库,主要使用Hive进行数据处理和分析。Hive是一款基于Hadoop的离线分析工具,它提供了丰富的SQL语言来分析存储在Hadoop分布式文件系统中的数据:支持将结构化的数据文件映射为一张数据库表,并提供完整的SQL查询功能;支持将SQL语句转换为Hadoop MapReduce任务运行,通过SQL查询分析需要的内容,使不熟悉Hadoop MapReduce的用户可以很方便地利用SQL语言查询、汇总和分析数据。然而,Hive处理速度相对较慢,尤其是在处理大规模数据的复杂查询时更为明显。
随着业务的发展与数据量的激增,尤其是广告智能出价、信息流推荐、实时会员运营、用户增长等对时效敏感的新型业务接入后,采用Hive进行离线分析已经不能满足业务对数据时效性的需求。为此,我们引入了Trino、ClickHouse等一系列更加高效的OLAP引擎,但这些引擎更侧重数据分析环节,数据分析所依赖的数据仓库以及前序的数据清洗处理等环节依旧是构建在Hive的基础上。因此,如何提升Hive处理和分析的性能,从而实现爱奇艺大数据链路的整体加速,成为亟待解决的问题。
03
方案选型
我们调研了Hive on Tez、Hive on Spark、Spark SQL等几个主流的替代方案,从功能兼容性、性能、稳定性、改造成本等多个维度进行了系统性地分析比较,最终选型Spark SQL。
Hive on Tez
该方案将Tez作为Hive的一种可插拔的执行引擎,代替MapReduce执行作业。Tez是Apache开源的支持DAG作业的计算框架,它的核心思想是将Map和Reduce两个操作进一步拆分并形成一个大的DAG作业。相对于MapReduce,Tez省去了很多不必要的中间数据存储和读取的过程,直接在一个作业中表达了MapReduce需要多个作业共同协作才能完成的事情。
优势:
无感切换:SQL语法仍然是Hive SQL,通过配置将Hive的执行引擎由MapReduce替换为Tez即可,上层应用无需改造
劣势:
性能较差:该方案对大规模数据集的并行处理能力较差,在发生数据倾斜时表现明显
社区不活跃:该方案在业界落地相对较少,社区交流讨论不多
运维成本高:Tez引擎执行出现异常时,可以参考的资料较少
Hive on Spark
该方案将Spark作为Hive的一种可插拔的执行引擎,代替MapReduce执行作业。Spark是一种基于内存计算的大规模数据处理引擎,相对于MapReduce,Spark具备可伸缩、充分利用内存、计算模型灵活等特点,在处理复杂任务时效率更高。
优势:
无感切换:SQL语法仍然是Hive SQL,通过配置将Hive的执行引擎由MapReduce替换为Spark即可,上层应用无需改造
劣势:
版本兼容性差:仅支持Spark 2.3以下版本,没法利用Spark 3.x以上版本的新特性,不符合未来升级需求
性能不理想:Hive on Spark 仍然使用Hive Calcite解析SQL为MapReduce原语,只是它会用Spark引擎而非MapReduce引擎执行这些原语,性能并非十分理想
社区不活跃:该方案在业界落地较少,社区不活跃
资源申请不灵活:Hive on Spark 的方案在提交Spark 任务时,资源只能固定设置,难以适用于多租户、多队列场景
Spark SQL
Spark SQL是Spark面向结构化数据的解决方案,它提供了兼容Hive的SQL语法,支持使用Hive Metastore元数据,能够提供完整的SQL查询功能。因此,基于Hive的数据仓库仍可以在Spark SQL场景下使用,现有大部分Hive SQL任务都可以平滑切换到Spark SQL。
Spark SQL将SQL语句转换为Spark任务运行,采用基于内存的模式组织数据计算与缓存,相比于将中间数据落盘的Hive on MapReduce方案,Disk IO开销更小,同时执行效率更高。
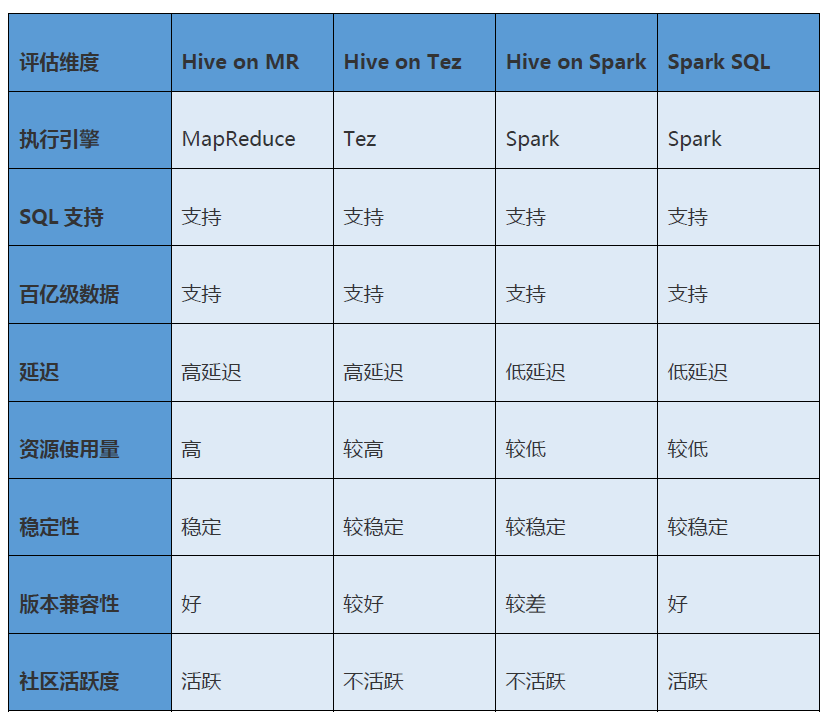
选型小结
下表展示了Hive on MapReduce、Hive on Tez、Hive on Spark及Spark SQL几套方案之间的详细对比,可以看出,Spark SQL最适合我们的场景。
04
技术改造
从Hive迁移到Spark SQL面临多个方面的挑战和改造工作,包括Spark兼容性改造与性能优化、SQL任务的语法调整、数据一致性保障、系统集成和依赖项的改造等。
Spark兼容性改造
Spark SQL与Hive SQL存在一定的语法差异,在迁移过程中发现了很多兼容性的问题,我们通过Spark Extension 方式,对 SQL 各阶段执行计划进行拦截改写,实现语法、执行逻辑、方法函数等方面的兼容,提高了迁移成功率。
以下罗列了几项主要的差异:
支持UDF多线程:先前Hive上的UDF,如遇SimpleDateFormat类型日期处理时不会抛出异常,然而使用Spark执行会报错,原因是Spark引擎采用了多线程方式执行此类函数。通过修改UDF的代码,把SimpleDateFormat设置成ThreadLocal可以解决该问题。
Grouping ID支持:Spark不支持Hive的grouping_id,使用自带的grouping_id()来代替,但是这会引发兼容性问题,我们通过改造Spark,实现了在解析SQL的时候把grouping_id自动转换成grouping_id()
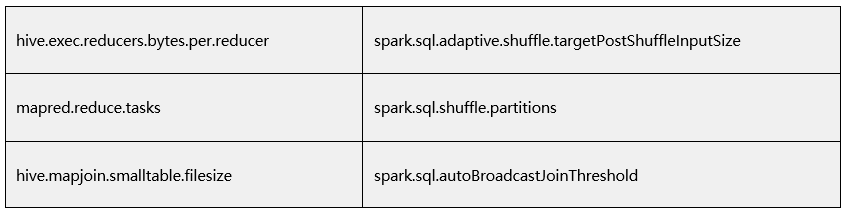
参数兼容性:Hive特定的参数需要映射到Spark中相应的参数
复杂函数不起别名:在Hive当中,如果没有给某个通过计算得到的列起别名的话,Hive默认会起一个以_c开头的列名,但是Spark却不会,当调用到某些可能会返回逗号的函数的时候(比如get_json_object),会报列个数不匹配的问题。该问题的work around建议是给所有的列都起别名,拒绝使用_c0的这样的别名。
不支持永久函数:Spark不支持永久函数的原因是代码里没有去HDFS上把jar包下载下来。另外临时函数是不需要指定库名的,但是永久函数是需要的,为了推广永久函数特增加了一个功能:在当前库找不到对应函数的时候,会去查找default库下的永久函数。
不支持reset参数:线上任务有使用reset命令的场景,我们通过改造Spark,使Spark SQL支持reset命令。
Spark新特性启用与配置优化
开启动态资源分配策略(DRA):任务根据当前程序的需求自动申请或释放 Executor 实现动态资源调整,解决了资源分配不合理的问题。自动回收空闲资源极大地降低了集群资源浪费,另外通过限制最大 Executor 数量来避免大查询占用过多资源导致队列阻塞。
开启自适应查询优化(AQE):记录任务执行阶段的相关统计指标,根据统计的指标优化后续执行阶段的执行计划,如:动态合并小的 Shuffle 分区、动态选择合适的 Join 策略、动态优化倾斜的分区等,提高了数据处理效率。
自动合并小文件:在写入前插入 Rebalance 算子,再结合 Spark 的 AQE 优化,自动的合并小分区、拆分大分区,进而很好地解决了大量小文件问题。
Spark 架构改进
在我们的场景下,应用通过JDBC方式提交SQL任务到Spark ThriftServer,进而访问Spark集群。然而Spark ThriftServer只支持单用户,限制了多租户访问Spark的能力,存在资源利用率低、UDF互相干扰等问题。
为了克服这些问题,我们引入了Apache Kyuubi。Kyuubi是一个开源的Spark ThriftServer解决方案,支持使用独立的SparkSession处理SQL请求,具备与Spark Thrift Server相同的能力。相较于Spark ThriftServer,Apache Kyuubi支持用户、队列、资源隔离,具备服务化、平台化能力。
对于Apache Kyuubi,我们也进行了一些个性化改造,以更好地服务于生产场景:
基于标签配置:对于不同的计算场景或平台预定义一些标签绑定一些特定的配置,在任务执行时只需要带上对应的标签,就会自动在配置中心补充预设的配置。例如:即席查询任务,配置共享引擎和大查询限制等配置;ETL 任务,配置独立引擎和小文件合并配置等。
并发限制:在一些异常情况下,某个客户端可能发送大量的请求导致 Kyuubi 服务工作线程被占满。我们在 Kyuubi 中实现了 User 和 IP 级别的连接并发限制,避免某个用户或客户端发送大量请求导致服务被打满,此功能也已经贡献给社区。
事件采集:Kyuubi 在 SQL 执行的各阶段暴露了各种事件,通过这些事件可以很方便的进行 SQL 审计和异常分析,为小文件优化、SQL 优化等提供很好的数据支撑。
05
自动化迁移工具
在Hive向Spark SQL迁移时,除了解决上述已知的兼容性问题外,还可能遇到一些未知的问题,需要确保引擎切换后能够运行成功、切换不会造成数据不一致,并在运行失败时提供自动降级回原方案的能力,避免影响到线上数据。常用的方法一般是两套引擎双跑一段时间对数,对数结果一致后再进行切换。
切换前,大数据平台上运行着2万多个Hive任务,纯靠人工一个个切换到Spark SQL显然是不现实的。为了提升迁移效率,我们设计开发了一套基于Pilot的自动化切换引擎、双跑、对数的迁移工具。
Pilot是爱奇艺大数据团队与BI魔镜团队联合自研的智能SQL引擎,提供了OLAP数据分析的统一入口,集成Hive、Spark SQL、Impala、Trino、ClickHouse、Kylin等各种OLAP分析引擎,支持不同集群/不同引擎间的自动路由、自动降级、限流、拦截、智能分析诊断、审计等功能。目前Pilot已对接到Babel数据开发平台、Gear定时工作流引擎、广告数据平台、BI portal报表系统、魔镜、庖丁刃、Venus日志服务中心等数据开发和分析平台。
通过Pilot自动切换SQL引擎,我们可以在用户无感知的情况下将Hive SQL切换为Spark SQL,保障数据一致性,并且具备回滚能力:
通过Pilot收集Hive任务的信息,获取SQL语句、队列、工作流名称等信息
SQL解析:使用SparkParser分析Hive任务的SQL语句,找到输入输出所对应的数据库、数据表等信息
构建输出映射表:为双跑任务创建输出数据的映射表,与线上数据表区分开来,避免影响线上数据
引擎替换:将双跑任务的执行引擎替换为Spark SQL
模拟运行:使用Hive、Spark引擎执行对应的SQL任务,并将任务运行结果输出到上述映射表里,用于对数校验
一致性校验:通过比较两张表的行数、循环冗余码(基于CRC32算法)进行数据一致性校验。
其中,CRC32算法是一种简单快速的数据校验算法。Spark中提供了内置函数CRC32,该函数的值是Long类型,最大值不超过10^19。在我们的应用场景下,首先将表中每行的各列数据concat_ws起来计算其CRC32,并将该CRC32转换为Decimal(19, 0);接着对表各行计算所得的CRC32值求和得到可反映整表内容的checksum CRC32值,用于一致性比较。该条校验SQL具体为:

映射表中部分字段为Map、List等集合类型,会存在两张实际数据一致的表,由于集合类型字段内部数据排序的不同,导致CRC32统计结果发生偏移并影响到一致性校验结果。针对这类情况,我们开发了专门的UDF对集合内部排序后进行一致性校验。

映射表中有部分字段为Float、Double等浮点类型,在数据一致性校验环节,由于统计精度的问题,两张表的CRC32统计结果可能存在差异,导致一致性校验环节发生误判。为此,我们优化了校验算法,在计算CRC32统计值时,对浮点字段保留小数点后4位。

自动降级:Hive任务切换到当SparkSQL运行失败后,通过Pilot自动降级到Hive并重新提交运行,保证无论如何任务都能顺利执行。
我们提供了平台化的手段来执行上述流程:用户根据项目名称,找到所属工作流。

对项目进行简单配置,输入公共参数在任务模拟运行时使用。
在模拟运行阶段,支持监控运行状态

在模拟运行完成后,可以获得具备迁移条件的任务集合。在此基础上通过简单操作实现一键迁移。
06
迁移效果
经过一段时间的努力,我们已经将90% Hive任务平滑迁移到Spark SQL,取得了明显的收益。任务性能提升了67%,CPU使用量减少了50%,内存使用量降低了44%。
以下是一些业务的效果:
广告:离线任务整体性能提升约 38%,计算资源节省30%,计算效率提升20%,加快广告数据产出,促进增收
BI:总耗时降低 79%,资源节省 43%,保障 P0 任务的产出时效,核心报表提前半小时至1小时产出,同时,提升补数效率,快速解决数据故障、数据回溯等日常问题
用户增长:数据生产提早2小时,帮助用户增长核心报表在10点前产出,提升UG运营效率
会员:订单数据生产提早8小时产出,数据分析提速10倍以上,帮助会员提升运营分析效率
爱奇艺号:平均执行时间缩短 40%,日执行时间减少约 100 小时
07
未来计划
升级迁移工具
对于部分不具备平滑迁移条件的Hive任务,需要先改写成兼容Spark SQL语法的SQL后才能继续迁移,我们正在完善迁移工具,支持对运行失败的任务提取关键错误信息,并匹配自动诊断根因标签,给出优化建议甚至自动化改写,帮助加快迁移。
引擎优化
Spark引擎层面目前还有一些遗留问题需要继续跟进和优化:
存储变大问题:由于小文件优化中引入了 Repartition 使得数据被打散,导致部分任务写入的数据压缩率降低,后续对社区提供的 Z-order 优化进行调研自动优化数据分布。
DPP 导致 SQL 解析过慢问题:在迁移中发现 DPP 优化可能导致部分多表 Join 的 SQL 解析非常慢,目前是通过限制 DPP 优化的 Join 个数来避免这个问题,Spark 3.2 以及后续的版本中对 Spark SQL 解析进行加速,并且也有一些相关的 Patch,计划对这些 Patch 进行分析并应用到当前版本。
任务关键指标完善:我们目前已经在平台侧采集了一些 Spark SQL 的执行指标,如:输入输出文件大小和文件数、Spark SQL 各阶段运行时间等,可以直观的看到有问题的任务以及一些优化的效果。后续还需要对这些指标进行完善,例如:Shuffle 数据量、数据倾斜、数据膨胀等指标,探索更多的优化手段,提升 Spark SQL 计算效率。
模拟测试引擎
在服务版本升级、SQL引擎参数优化、集群迁移等场景中,往往需要对业务数据进行重跑测试以确保数据处理的准确性和一致性。传统的重跑测试方法依赖业务人员亲自设计与手动实施,往往效率低下。
Pilot的模拟双跑工具可以解决上述这些痛点,我们计划将该工具独立提供成服务,改造成更加通用的模拟测试引擎,帮助用户快速构建双跑任务并进行自动化对数。

也许你还想看
Prometheus监控指标查询性能调优
爱奇艺DRM修炼之路
组件化设计在会员业务的应用和实践
相关文章:
爱奇艺大数据加速:从Hive到Spark SQL
01 导语 爱奇艺自2012年开展大数据业务以来,基于大数据开源生态服务建设了一系列平台,涵盖了数据采集、数据处理、数据分析、数据应用等整个大数据流程,为公司的运营决策和各种数据智能业务提供了强有力的支持。随着数据规模的不断增长和计算…...

c++构造函数的多个细节拷问
提问1 能在 构造函数里面调用 虚函数吗? 调用的 是这个类自己的 虚函数吗? 这个问题 等价于 虚函数表什么时候形成的? 回答1 答:在构造函数里面 可以调用虚函数哈 不过是父类的 子类对象还没有创建完成 所以 尽量不要在 构造里…...
Redis入门 - Lua脚本
原文首更地址,阅读效果更佳! Redis入门 - Lua脚本 | CoderMast编程桅杆https://www.codermast.com/database/redis/redis-scription.html Redis 脚本使用 Lua 解释器来执行脚本。 Redis 2.6 版本通过内嵌支持 Lua 环境。执行脚本的常用命令为 EVAL。 …...
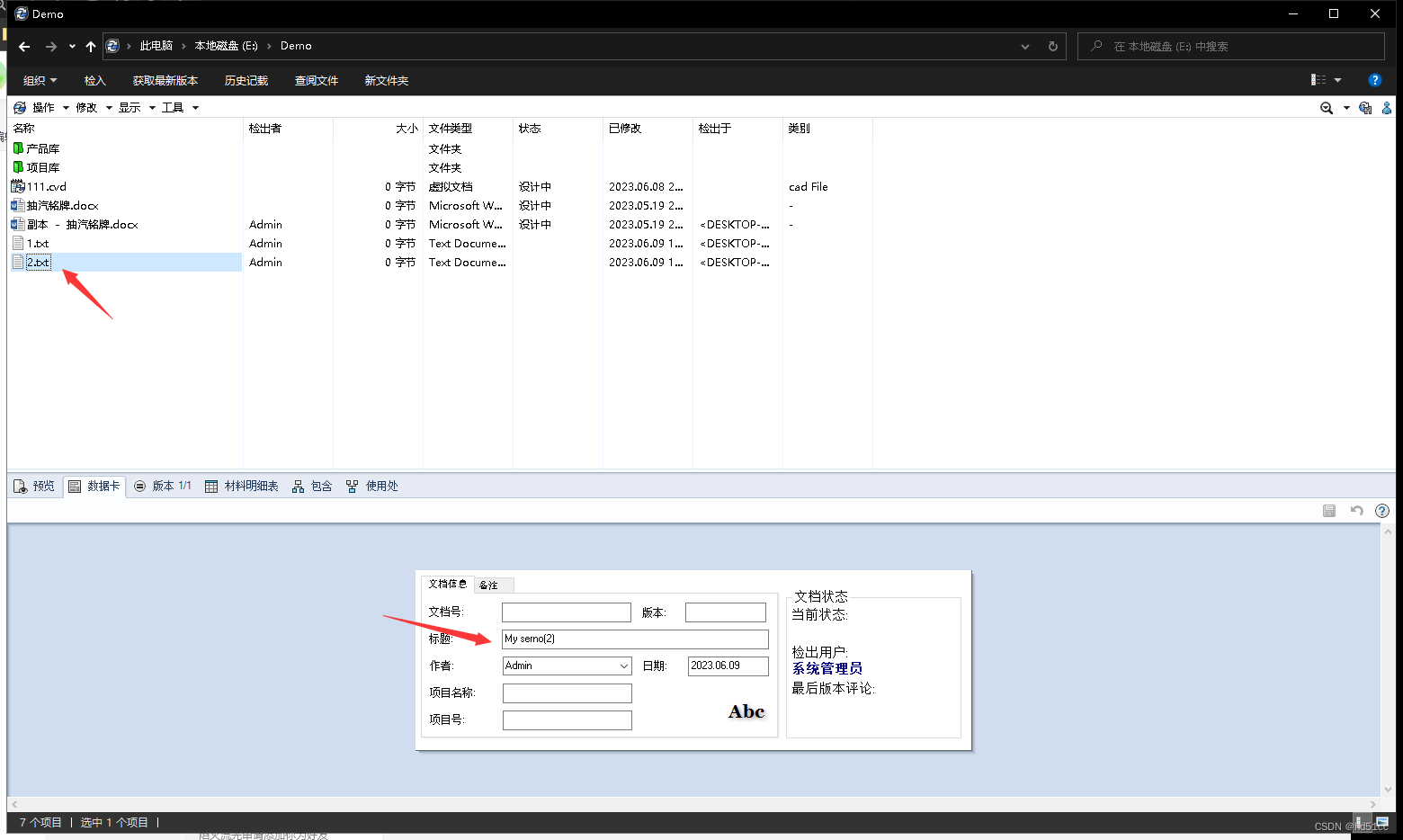
Creating Serial Numbers (C#)
此示例展示如何使用Visual C#编写的Add-ins为文件数据卡生成序列号。 注意事项: SOLIDWORKS PDM Professional无法强制重新加载用.NET编写的Add-ins,必须重新启动所有客户端计算机,以确保使用Add-ins的最新版本。 SOLIDWORKS PDM Professio…...

pycharm使用之torch_geometric安装
正式安装之前要先查看一下torch的版本 一、查看torch版本 1、winR ,输入cmd 2、输入python 3、 输入import torch,然后输入torch.__version__,最后回车 可以看到我的torch版本是1.10.0 二、下载合适的版本 1、打开链接 https://pytorch-…...

spring-mvc 工作流程
一、概述 spring-mvc 主要是DispatcherServlet工作流程流程可以分为两块,第一块为DispatcherServlet的加载,第二块为请求处理 二、DispatcherServlet的加载 主要依靠三个对象 DispatcherServletRegistrationBean:实现了ServletContextInit…...

物联网Lora模块从入门到精通(六)OLED显示屏
一、前言 获取到数据后我们常需要在OLED显示屏上显示,本文中我们需要使用上一篇文章(光照与温湿度数据获取)的代码,在其基础上继续完成本文内容。 基础代码: #include <string.h> #include "board.h" #include "hal_ke…...
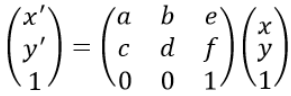
平面坐标变换(单应性变换/Homography变换)
单应性(homography)变换用来描述物体在两个平面之间的转换关系,可以用于描述平移、翻转、缩放、旋转、仿射变换等。其是对应齐次坐标下的线性变换,可以通过矩阵表示: 其中,H为单应性变换矩阵,假设变换前坐标为(x,y)&am…...

大数据项目常识
大数据项目 随着社会的进步,大数据的高需求,高薪资,高待遇,促使很多人都来学习和转行到大数据这个行业。学习大数据是为了什么?成为一名大数据高级工程师。而大数据工程师能得到高薪、高待遇的能力在哪?自…...

Linux系统:常用服务端口
目录 一、理论 1.端口分类 2.传输协议 3.常用端口 一、理论 1.端口分类 一个计算机最多有65535个端口,端口不能重复。Linux 只有 root 用户可以使用1024以下的端口。 表1 端口分类 端口范围说明公认端口(Well-KnownPorts)0 - 1023这类…...

前端和后端分别是什么?
从技术工具来看: 前端:常见的 html5、JavaScript、jQuery... 后端:spring、tomcet、JVM,MySQL... 毕竟,如果这个问题问一个老后端,他掰掰手指可以给你罗列出一堆的名词来,比如设计模式、数据库…...
)
Spring基础知识(一)
目录 1.Spring Framework 2.Spring Framework优点 3.Spring Framework的功能模块 4.Spring配置文件 5.Spring应用配置步骤 6.Spring的IoC是什么 7.IoC的理念 8.IoC体系的好处 9.Spring中的 IoC 容器 10.依赖注入的方式 1.Spring Framework Spring Framework即Spring框…...
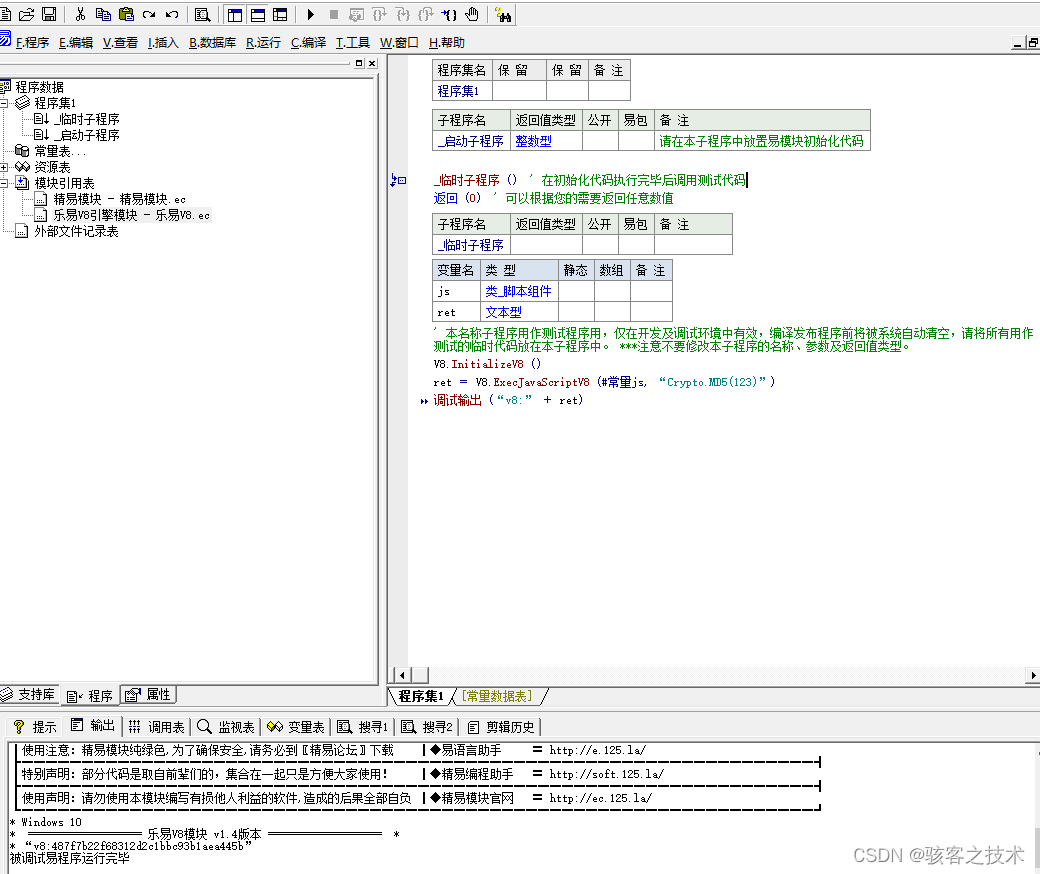
易语言使用node编译的js文件
环境配置 npm install -g cnpm babel-preset-env babel-cli babel-polyfill browserifynpm install -g crypto-js nodejs转js 例如加密模块 browserify -r babel-polyfill -r crypto-js -o es6.txt browserify file.js -o es6.txt易语言 使用v8 推荐 直接生成导入js即…...
)
计算机网络笔记:动态主机配置协议(DHCP)
协议配置: 为了把协议软件做成通用和便于移植的,协议软件的编写者不会把所有的细节都固定在源代码中,相反,他们把协议软件参数化,这就使得在很多台计算机上有可能使用同一个经过编译的二进制代码。一台计算机和另一台…...

新买的电脑怎么用U盘重装系统?新买的电脑用U盘重装系统教程
新买的电脑怎么用U盘重装系统?用户新买了电脑,想知道怎么用U盘来重装新买的电脑,用U盘来重装电脑其实非常简单,用户需要准备一个U盘,然后完成U盘启动盘的安装,接着按照以下分享的新买的电脑用U盘重装系统教…...
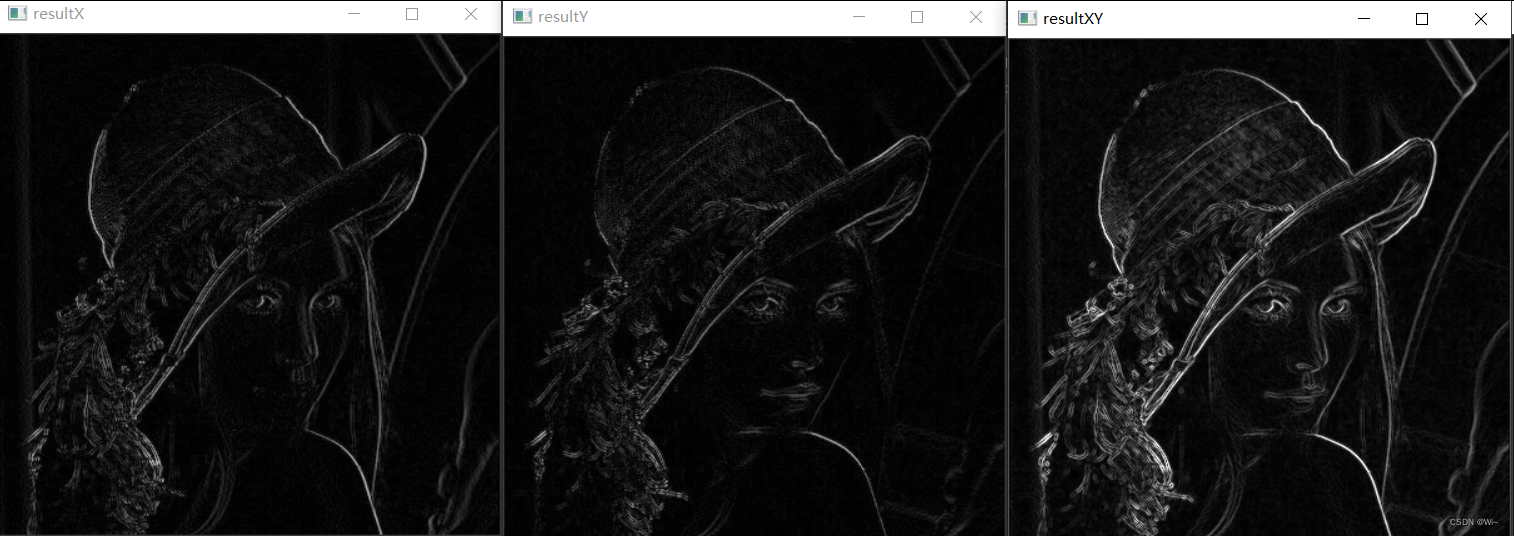
图像边缘检测原理
文章目录 图像边缘检测原理1:2:3:基本边缘检测算子 图像边缘检测原理 1: 图像的边缘指的是图像中像素灰度值突然发生变化的区域,如果将图像的每一行像素和每一列像素都描述成一个关于灰度值的函数,那么图像的边缘对应在灰度值函数中是函数值突然变大的…...

爬虫利器 Beautiful Soup 之遍历文档
Beautiful Soup 简介 Beautiful Soup 是一个可以从 HTML 或 XML 文件中提取数据的 Python 库,它提供了一些简单的操作方式来帮助你处理文档导航,查找,修改文档等繁琐的工作。因为使用简单,所以 Beautiful Soup 会帮你节省不少的工…...

12、Nginx高级之高级模块(secure_link/secure_link_md5)
一、功能 防盗链; ngx_http_secure_link_module模块用于检查所请求链接的真实性,保护资源免受未经授权的访问,并限制链接寿命。 该模块提供两种可选的操作模式。 第一种模式由 secure_link_secret 指令启用,用于检查所请求链接的真…...
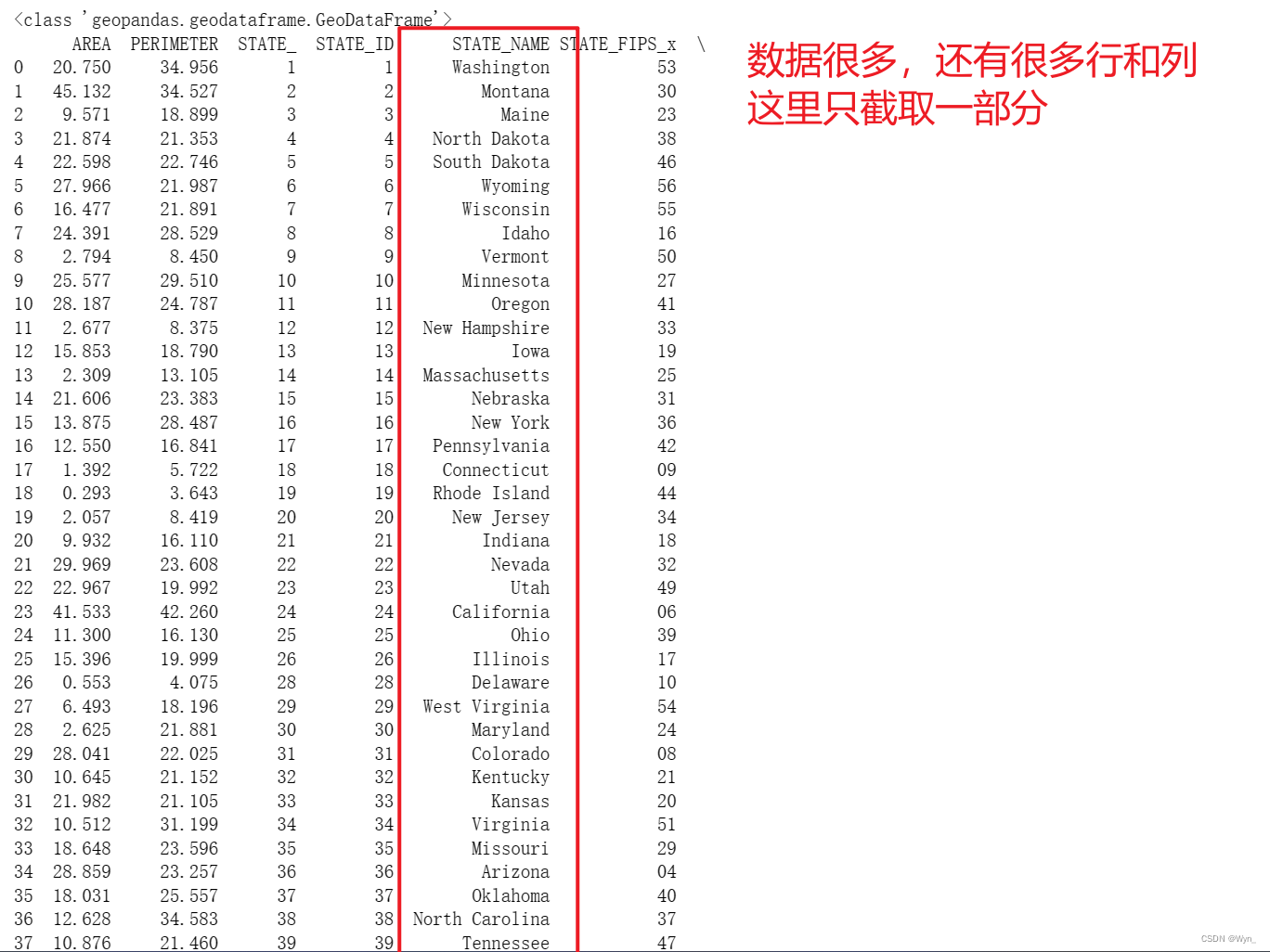
【python】数据可视化,使用pandas.merge()对dataframe和geopandas类型数据进行数据对齐
目录 0.环境 1.适用场景 2.pandas.merge()函数详细介绍 3.名词解释“数据对齐”(来自chatGPT3.5) 4.本文将给出两种数据对齐的例子 1)dataframe类型数据和dataframe类型数据对齐(对齐NAME列); 数据对…...
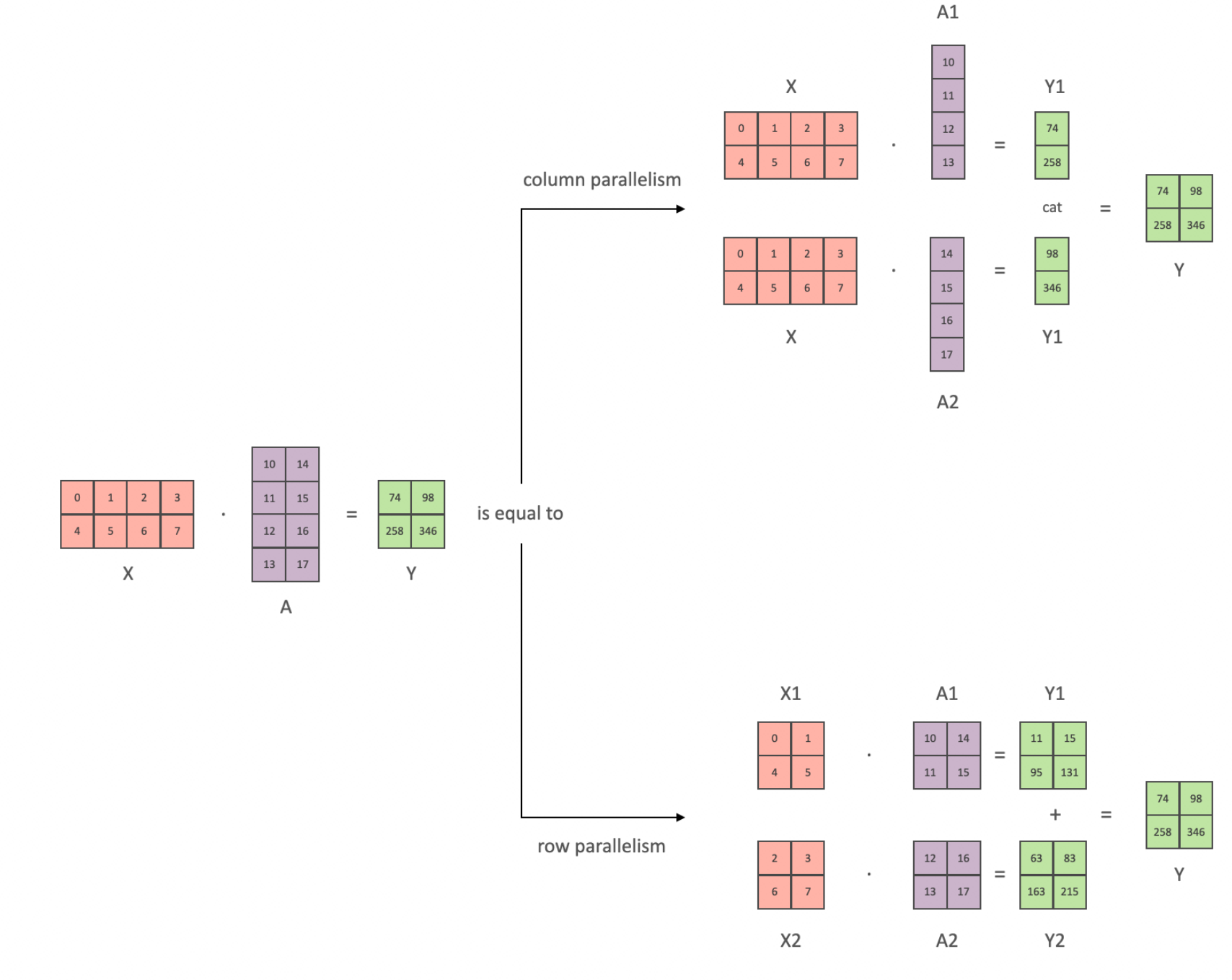
大模型入门(三)—— 大模型的训练方法
参考hugging face的文档介绍:https://huggingface.co/docs/transformers/perf_train_gpu_many#naive-model-parallelism-vertical-and-pipeline-parallelism,以下介绍聚焦在pytorch的实现上。 随着现在的模型越来越大,训练数据越来越多时&…...

终极指南:如何通过AKShare金融数据接口库快速获取全球交易所数据
终极指南:如何通过AKShare金融数据接口库快速获取全球交易所数据 【免费下载链接】akshare AKShare is an elegant and simple financial data interface library for Python, built for human beings! 开源财经数据接口库 项目地址: https://gitcode.com/gh_mirr…...

CircuitMaker免费PCB设计工具:从开源协议到实战避坑指南
1. 从“Freemium”到“全免费”:CircuitMaker的定位之变与我的选择时间过得真快,距离Altium首次推出免费的CircuitMaker工具,仿佛就在昨天。我记得当时业界一片哗然,大家都在讨论这家以高端、专业的Altium Designer闻名的公司&…...

终极小说下载器:一键离线收藏100+小说网站完整指南
终极小说下载器:一键离线收藏100小说网站完整指南 【免费下载链接】novel-downloader 一个可扩展的通用型小说下载器。 项目地址: https://gitcode.com/gh_mirrors/no/novel-downloader 在数字阅读时代,你是否曾为心爱的小说突然消失而烦恼&#…...

调幅无线传数据:避开这些坑,你的7kHz方波才能传得更远更稳
调幅无线传数据:避开这些坑,你的7kHz方波才能传得更远更稳 在业余无线电和嵌入式通信领域,调幅(AM)无线传输一直是低成本解决方案的热门选择。但许多工程师在尝试用7kHz方波调制高频载波时,总会遇到信号失真…...

3步构建个人知识库:微信读书笔记智能同步终极方案
3步构建个人知识库:微信读书笔记智能同步终极方案 【免费下载链接】obsidian-weread-plugin Obsidian Weread Plugin is a plugin to sync Weread(微信读书) hightlights and annotations into your Obsidian Vault. 项目地址: https://gitcode.com/gh_mirrors/ob…...

告别云服务器:手把手教你用QEMU在Ubuntu 18.04上搭建专属内核调试环境
从零构建QEMU内核调试环境:Ubuntu 18.04下的UEFI开发实战手册 当深夜的调试灯亮起,你是否还在为云服务器高昂的费用和网络延迟苦恼?本文将带你用一台普通Ubuntu机器,打造媲美物理机的内核开发环境。不同于常规教程,我…...

如何在Windows上免费获得流畅的B站观影体验:BiliBili-UWP第三方客户端终极指南
如何在Windows上免费获得流畅的B站观影体验:BiliBili-UWP第三方客户端终极指南 【免费下载链接】BiliBili-UWP BiliBili的UWP客户端,当然,是第三方的了 项目地址: https://gitcode.com/gh_mirrors/bi/BiliBili-UWP 还在为网页版B站卡顿…...

终极模组加载器指南:如何在5分钟内安全扩展《杀戮尖塔》游戏内容
终极模组加载器指南:如何在5分钟内安全扩展《杀戮尖塔》游戏内容 【免费下载链接】ModTheSpire External mod loader for Slay The Spire 项目地址: https://gitcode.com/gh_mirrors/mo/ModTheSpire ModTheSpire是一款专为《杀戮尖塔》设计的开源模组加载器&…...

Sonic搜索集群终极指南:从单机到高可用的完整部署方案
Sonic搜索集群终极指南:从单机到高可用的完整部署方案 【免费下载链接】sonic 🦔 Fast, lightweight & schema-less search backend. An alternative to Elasticsearch that runs on a few MBs of RAM. 项目地址: https://gitcode.com/gh_mirrors/…...
)
Win11精简版系统缺失画图工具?三步教你从微软商店找回(附快速启动技巧)
Win11精简版系统缺失画图工具?三步教你从微软商店找回(附快速启动技巧) 不少追求系统流畅性的用户会选择安装第三方精简版Win11系统,却在需要基础功能时发现连画图工具都找不到了。这并非微软的疏漏,而是精简版系统为了…...